
Hoy, el CERN es uno de los usuarios de Kubernetes más grandes del mundo. Según estadísticas recientes, se han lanzado 210 grupos de K8 europeos en esta organización europea detrás del Gran Colisionador de Hadrones (LHC) y una serie de otros proyectos de investigación conocidos, que sirven a cientos de miles de tareas simultáneamente. Esta historia de éxito es sobre ellos.
Contenedores CERN: inicio
Para aquellos que están al menos superficialmente familiarizados con las actividades del CERN, no es ningún secreto que se presta mucha atención en esta organización a las tecnologías de información relevantes: solo recuerde que este es el lugar de nacimiento de la World Wide Web, y entre los méritos más recientes puede recordar los sistemas de red (incluido
LHC Computing Grid ), un
circuito integrado especializado,
distribución Scientific Linux e incluso
su propia licencia de hardware
abierto . Como regla general, estos proyectos, ya sean software o hardware, están conectados con la creación principal del CERN - LHC. Esto también se aplica a la infraestructura de TI del CERN, que atiende en gran medida sus propias necesidades.
 En el centro de datos del CERN en Ginebra
En el centro de datos del CERN en GinebraLa primera información disponible públicamente sobre el uso práctico de los contenedores en la infraestructura de la organización, que se encontró, data de abril de 2016. Como parte de un informe "interno" de
Containers and Orchestration en CERN Cloud , los empleados de CERN hablaron sobre cómo usan OpenStack Magnum
(un componente de OpenStack para trabajar con motores de orquestación de contenedores) para proporcionar soporte para contenedores en su nube (CERN Cloud) y su orquestación. Ya luego de mencionar a Kubernetes, los ingenieros pretendían ser independientes del instrumento de orquestación elegido, apoyando otras opciones: Docker Swarm y Mesos.
Nota : La propia nube OpenStack se introdujo en la infraestructura de producción del CERN varios años antes, en 2013. A febrero de 2017, 188 mil núcleos, 440 TB de RAM estaban disponibles en esta nube, se crearon 4 millones de máquinas virtuales (de las cuales 22 mil estaban activas).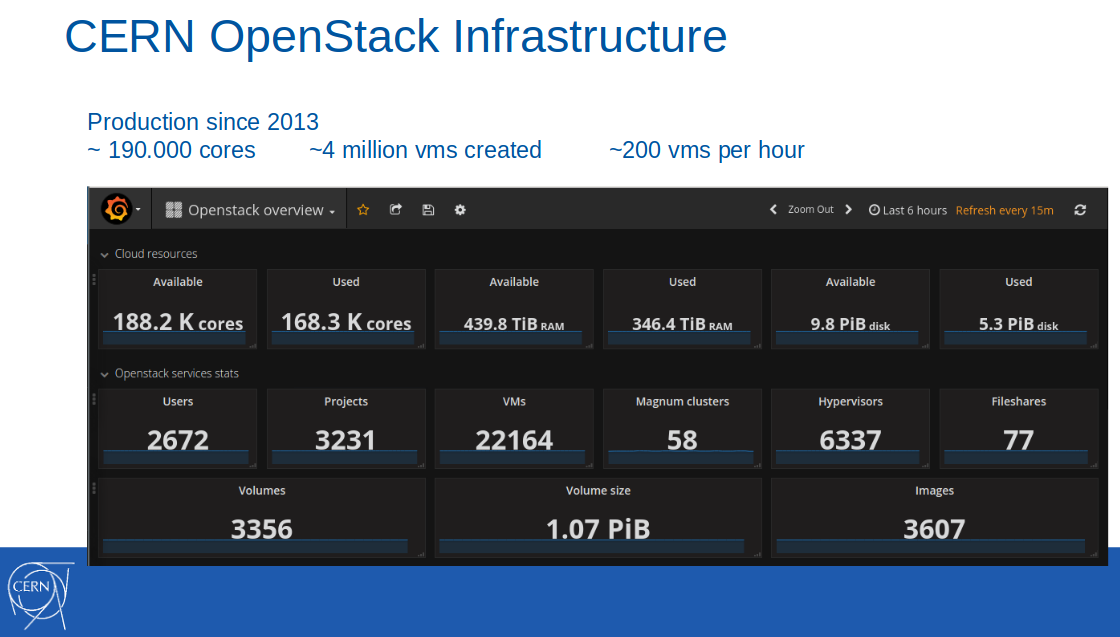
En ese momento, el soporte de contenedores en el formato Contenedores como servicio se posicionó como un servicio piloto y se utilizó en diez proyectos de TI de la organización. Entre los escenarios de aplicación, se solicitó la integración continua con GitLab CI para construir y desplegar aplicaciones en contenedores Docker.
 De la presentación al informe CERN del 8 de abril de 2016
De la presentación al informe CERN del 8 de abril de 2016El lanzamiento de este servicio en producción se esperaba para el tercer trimestre de 2016.
Nota : Vale la pena señalar por separado que los empleados del CERN invariablemente ponen sus mejores prácticas en la corriente ascendente de los proyectos de código abierto utilizados, incluidos y numerosos componentes de OpenStack, que en este caso fueron Magnum, puppet-magnum, Rally, etc.Millones de solicitudes por segundo con Kubernetes
A junio del mismo año (2016), el servicio en el CERN todavía
tenía un estado de preproducción:
"Estamos avanzando gradualmente hacia un modo de producción completo para incluir Contenedores como servicio en el conjunto estándar de servicios de TI disponibles en CERN".
Y luego, inspirados por la
publicación en el blog de Kubernetes sobre el servicio de 1 millón de solicitudes HTTP por segundo sin tiempo de inactividad durante la actualización del servicio en K8, los ingenieros de la organización científica decidieron repetir este éxito en su clúster en OpenStack Magnum, Kubernetes 1.2 y una base de hardware de 800 núcleos de CPU.
Además, decidieron no limitarse a una simple repetición del experimento y aumentaron con éxito el número de solicitudes a 2 millones por segundo, preparando simultáneamente varios parches para el mismo OpenStack Magnum y haciendo pruebas con diferentes números de nodos en el clúster (300, 500 y 1000).
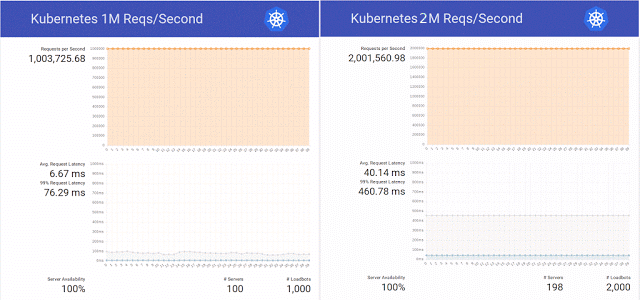
Resumiendo los resultados de estas pruebas, los ingenieros nuevamente notaron que "también hay Enjambre y Mesos, y planeamos realizar pruebas en ellos pronto". Se desconoce si el asunto llegó a estas pruebas, Internet no se conoce, pero a fines de ese año, el experimento con Kubernetes
continuó , con 10 millones de solicitudes por segundo. El resultado fue bastante positivo, pero se limitó a una marca exitosa de poco más de 7 millones, debido a un problema de red no relacionado con OpenStack.
Los ingenieros especializados en OpenStack Heat y Magnum también midieron que tomó 23 minutos escalar el clúster de 1 a 1000 nodos, evaluándolo como un buen resultado
(ver también la presentación Toward 10,000 Containers on OpenStack en OpenStack Summit Barcelona 2016) .
Contenedores en el CERN: transición a producción
En febrero del año siguiente (2017), los contenedores en el CERN ya se usaban ampliamente para resolver problemas de diversos campos: procesamiento por lotes, aprendizaje automático, gestión de infraestructura, implementación continua ... Esto se anunció en el informe "
OpenStack Magnum en el CERN. Escalar grupos de contenedores a miles de nodos "(
video ) en FOSDEM 2017:

También informó que el uso de Magnum en el CERN entró en la fase de producción en octubre de 2016, y nuevamente enfatizó el apoyo de tres instrumentos para la orquestación: Kubernetes, Docker Swarm y Mesos. Por qué era tan importante,
explicó en uno de sus discursos (OpenStack Summit en Boston, mayo de 2017) Ricardo Rocha, del departamento de TI del CERN:
“Magnum también nos permite elegir un motor de contenedor, que fue muy valioso para nosotros. Grupos de personas que abogaron por Kubernetes trabajaron en la organización, pero también hubo quienes ya usaron Mesos, y algunos incluso trabajaron con el Docker habitual, queriendo seguir confiando en la API de Docker, y Swarm tiene un gran potencial aquí. Queríamos lograr la facilidad de uso, no exigir que las personas entiendan patrones complejos para configurar sus clústeres ".
En ese momento, el CERN usaba unos 40 grupos con Kubernetes, 20 con Docker Swarm y 5 con Mesosphere DC / OS.
Un año después, en mayo de 2018, la situación ha cambiado significativamente. A partir de la presentación del
CERN Experiences with Multi-Cloud Federated Kubernetes (
video ) de Ricardo y su colega (Clenimar Filemon) en KubeCon Europe 2018, se dieron a conocer nuevos detalles sobre el uso de Kubernetes. Ahora no es solo una de las herramientas de orquestación de contenedores disponibles para los usuarios de una organización científica, sino también una tecnología importante para toda la infraestructura, que permite, gracias a la federación, expandir significativamente la nube informática al agregar recursos de terceros (GKE, AKS, Amazon, Oracle ...) a sus propias capacidades.
Nota : Federación en Kubernetes es un mecanismo especial que simplifica la administración de múltiples clústeres al sincronizar los recursos ubicados en ellos y detectar automáticamente los servicios en todos los clústeres. Un caso real de su aplicación está trabajando con una variedad de clústeres de Kubernetes distribuidos entre diferentes proveedores (sus centros de datos, servicios en la nube de terceros).Como puede ver en esta diapositiva, que muestra algunas características cuantitativas del centro de datos CERN en Ginebra ...

... la infraestructura interna de la organización ha crecido enormemente. Por ejemplo, el número de núcleos disponibles para el año casi se ha duplicado, ya a 320 mil. Los ingenieros fueron más allá y combinaron varios de sus centros de datos, habiendo logrado la disponibilidad de 700 mil núcleos en la nube CERN, que se dedican a la ejecución paralela de 400 mil tareas (para la reconstrucción de eventos, calibración de detectores, simulaciones, análisis de datos, etc.) ...
Pero en el contexto de este artículo, el hecho de que ya hay 210 grupos de Kubernetes, cuyos tamaños varían mucho (de 10 a 1000 nodos), es de mayor interés.
Federación con Kubernetes
Sin embargo, las capacidades internas del CERN no siempre fueron suficientes, por ejemplo, para períodos de fuertes estallidos de carga: antes de grandes conferencias internacionales sobre física y en el caso de grandes campañas para la reconstrucción de experimentos. Un caso de uso notable que requiere grandes recursos es el servicio por lotes CERN, que representa aproximadamente el 80% de los recursos informáticos de la organización.
El núcleo de este sistema es el marco de código abierto
HTCondor , diseñado para resolver problemas de la categoría HTC (informática de alto rendimiento). El demonio StartD es responsable de los cálculos en él, que comienza en cada nodo y es responsable de iniciar la carga de trabajo en él. Fue él quien fue contenedorizado en el CERN con el objetivo de lanzar en Kubernetes y una mayor federación.
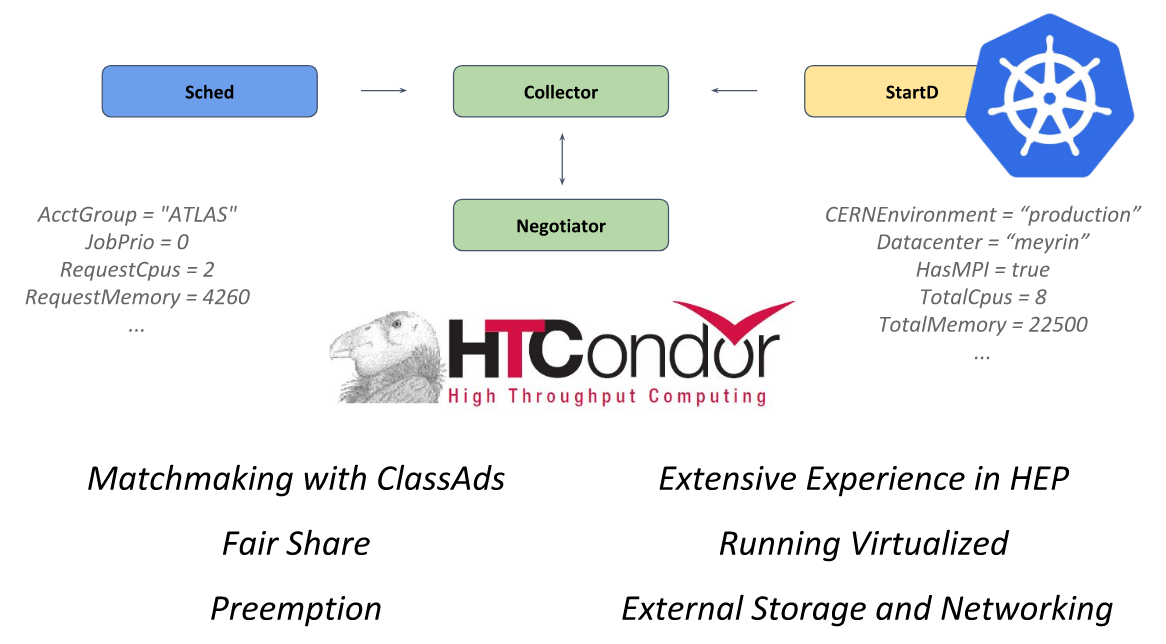 HTCondor de la presentación del CERN en KubeCon Europe 2018
HTCondor de la presentación del CERN en KubeCon Europe 2018Siguiendo este camino, los ingenieros del CERN pudieron describir un único recurso (
DaemonSet con un contenedor donde StartD se inicia desde HTCondor) y desplegarlo en los nodos de todos los grupos federados de Kubernetes: primero como parte de su centro de datos y luego conectando proveedores externos (nube pública de T-Systems y otras empresas):
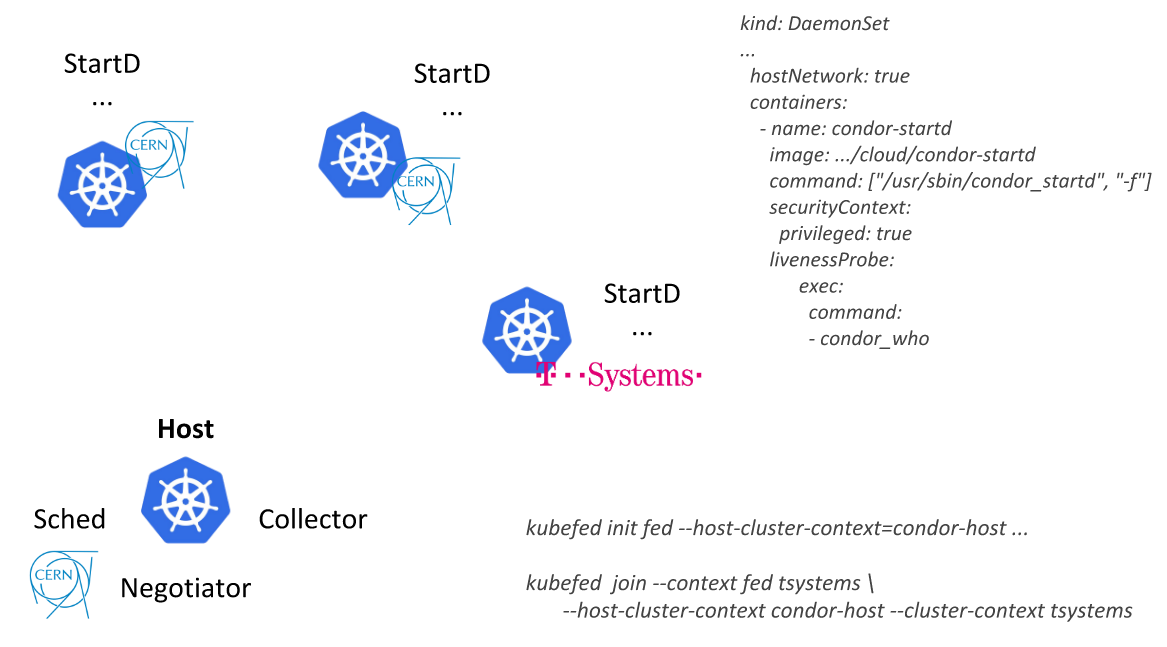
Otra aplicación es una plataforma analítica basada en
REANA ,
RECAST y
Yadage . A diferencia del CERN Batch Service, que es un software "establecido" en la organización, este es un nuevo desarrollo, que inmediatamente tuvo en cuenta los detalles de la aplicación junto con Kubernetes. Los flujos de trabajo en este sistema se implementan de tal manera que cada paso se convierte en
Job para Kubernetes.
Si inicialmente todas estas tareas se ejecutaron en un solo clúster, con el tiempo, las solicitudes crecieron y "hoy es nuestra mejor federación de casos de uso en Kubernetes". Mire un video corto con su demostración en
este fragmento del discurso de Ricardo Rocha.
PS
Puede encontrar información adicional sobre el alcance actual del uso de TI en el CERN en
el sitio web de la organización .
Otros articulos del ciclo