
¿Cuál es la diferencia entre el aprendizaje automático y el análisis de datos, que se encuentra en Odnoklassniki y cómo comenzar su viaje en el aprendizaje automático? Hablamos de esto en el duodécimo número de programas de entrevistas para programadores.
Video en el canal TechnostreamEl anfitrión del programa es Pavel Shcherbinin, director técnico de proyectos de medios, y el invitado es Dmitry Bugaychenko, analista de Odnoklassniki.
00:56 Dmitry Bugaychenko: de la subcontratación al OK y la actividad científica
02:42 ¿Por qué combinar el trabajo en la universidad y en una gran empresa?
02:57 Donde el aprendizaje automático se aplica en OK
03:49 Aprendizaje automático y análisis de datos: ¿cuál es la diferencia?
05:08 Screencast "Analizamos la audiencia OK con la ayuda del análisis de datos"
22:34 ¿Son los compañeros de clase un servicio de citas?
24:07 ¿Dónde comenzar a aprender Machine Learning?
25:33 ¿Debería participar en campeonatos de aprendizaje automático?
26:53 Cómo practicar en OK
28:18 Manual de aprendizaje automático
30:28 Eventos de aprendizaje automático
32:48 ¿Cómo se organiza la canalización de datos en Aceptar (mostrar en la pizarra)
43:42 Encuesta Blitz
Cuéntanos un poco sobre ti.Podemos suponer que mi carrera comenzó en 1999, cuando ingresé a las matemáticas. Durante cinco años, estudió activamente matemáticas, programación y diversas disciplinas relacionadas. Luego trabajó durante bastante tiempo en una empresa de outsourcing. El outsourcing es una experiencia muy interesante. Logré trabajar en una amplia variedad de proyectos, desde escribir un controlador para un refrigerador hasta crear sistemas empresariales distribuidos.
Todo este tiempo, además del trabajo principal, enseñé en la universidad para mantener el contacto con la comunidad académica, lo cual fue bastante difícil. Cuando en 2011 fui invitado a Odnoklassniki para participar en sistemas de recomendación, fue una muy buena oportunidad, que aproveché. Aquí, es posible combinar tanto la preparación matemática de la universidad como la experiencia práctica de la programación. Sin embargo, sigo enseñando en la universidad.
¿La enseñanza lleva mucho tiempo?1.5 días a la semana van a la universidad, pero vale la pena, porque ya tenemos tres de mis antiguos alumnos en el personal. Es decir, la universidad también funciona como una fragua de personal.
En el trabajo, ¿se relaciona con calma con el hecho de que se fue por 1,5 días?Renunció Todos entienden qué beneficio se obtiene de esto, por lo que no encuentro ninguna oposición.
Dime dónde se usa el aprendizaje automático en Odnoklassniki.Tenemos muchas aplicaciones. Históricamente, el primer sistema de aprendizaje automático fue la recomendación musical. Todo comenzó en 2011. Luego hubo un crecimiento simplemente explosivo: la recomendación de las comunidades, la recomendación de amigos, "tal vez se conocen", intenta clasificar el contenido en el feed de la persona. Ahora se están desarrollando muchos proyectos. No importa qué parte de Odnoklassniki toque, hay componentes relacionados con el aprendizaje automático o el análisis de datos.
Ayude a nuestros lectores a separar estos dos conceptos: aprendizaje automático y análisis de datos.Los datos son analizados por una persona para encontrar algunos patrones, conexiones, probar algunas hipótesis. Para esto, se utilizan varios medios de estadística matemática. El aprendizaje automático es un método más avanzado de búsqueda de patrones, utilizando técnicas que generalmente se basan en algún tipo de modelo grande y complejo con una gran cantidad de parámetros.
Estamos tratando de seleccionar los parámetros de este modelo para que describa bien el fenómeno que necesitamos. Existen muchos algoritmos diferentes, métodos para enumerar parámetros, pero todo esto se hace para encontrar cierta regularidad. Por ejemplo, de acuerdo con los datos de una publicación en una red social, evalúe la probabilidad de que una persona en particular ponga una "clase" en esta publicación. Es decir, el aprendizaje automático es una herramienta para el análisis de datos.
¿Podríamos usted y yo desacreditar uno de los mitos sobre Odnoklassniki, según el cual esta audiencia tiene una audiencia muy antigua?No hay problema Este es un mapa que en tiempo real refleja los inicios de sesión de cada usuario específico. Es decir, cada punto es una persona que inició sesión y hace algo en Odnoklassniki.
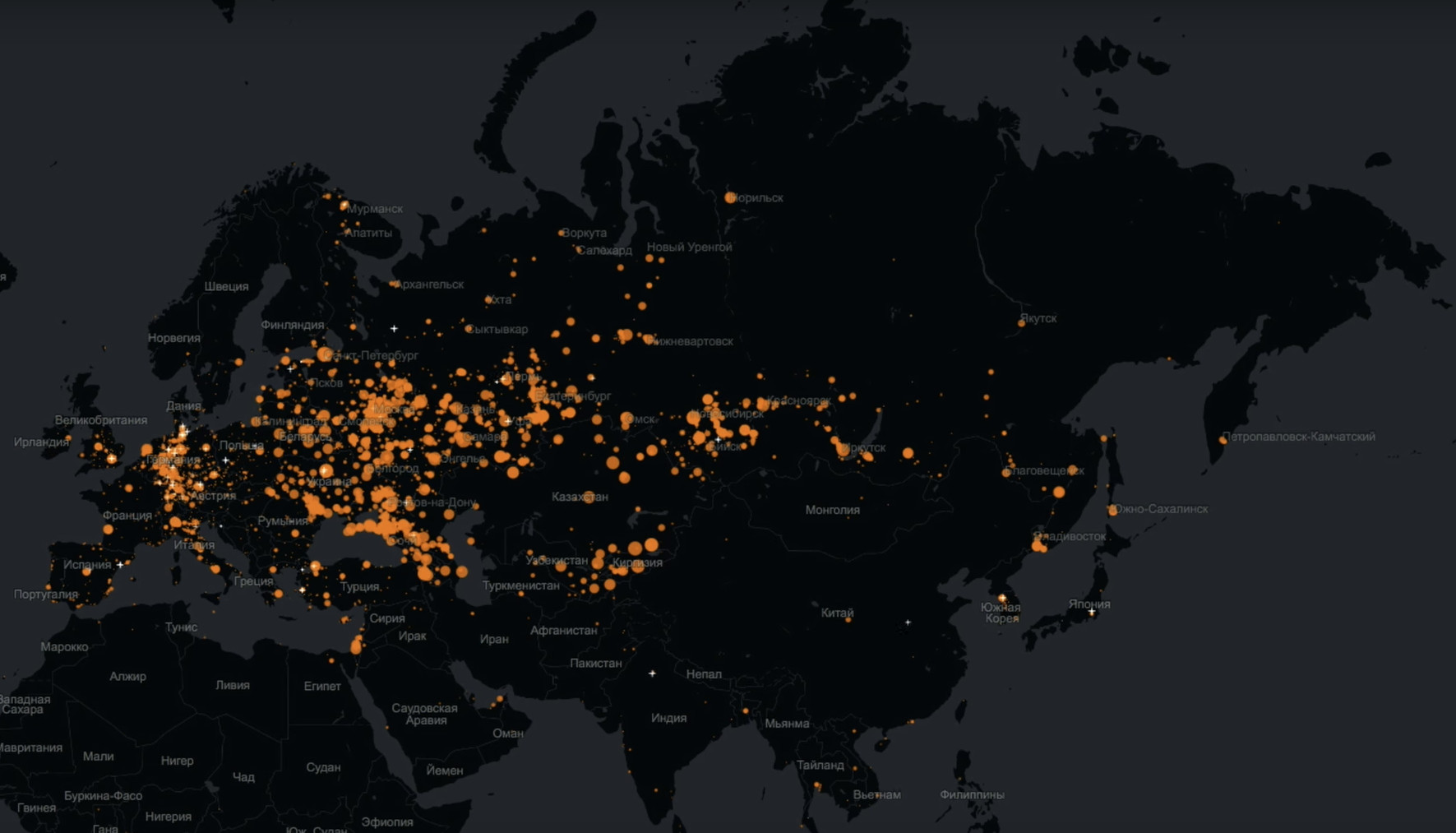
Los grandes círculos rojos son ciudades desde las cuales muchos usuarios nos han visitado. Es muy claramente visible aquí que Odnoklassniki no solo está vivo, sino que cubre casi toda Eurasia.
Calculemos cuántos usuarios pusieron "clase" en Odnoklassniki ayer, y veamos la distribución por edades.
¿Dónde comienza la codificación? Por supuesto, desde la importación de varios datos útiles para futuros cálculos agregados. Nuestra herramienta principal es
Spark , para acceder a la cual usamos el frente web de
Zeppelin . Básicamente, los datos provienen de
Apache Kafka , se empaquetan y se dividen en diferentes bloques. En este caso, estamos interesados en el bloque que describe la actividad del usuario de ayer, en particular, las clases. Hay un campo en el que se almacenan los datos demográficos de los usuarios, incluidos los cumpleaños.

La salida es el año de nacimiento de los primeros diez registros. Ahora intentemos construir algo agregado a partir de esto. Queremos contar la cantidad de usuarios únicos. Necesitamos identificación y año de nacimiento, agrupar por año y calcular el número de usuarios únicos. Y juguemos un poco: seguramente habrá personas cuyo año de nacimiento no está indicado, por lo que los filtraremos para que no creen ruido en el gráfico.
Para realizar el cálculo, el sistema necesita recolectar aproximadamente 1 TB de datos. Obtenemos el resultado y lo presentamos gráficamente:

El pico de edad cae en 1983 - 35 años. Eso es usuarios bastante viejos para ellos mismos.
Para representar mejor la situación, no hay suficiente información de una fuente. Si hablamos de datos demográficos de los usuarios, la fuente más interesante de comparación son las estadísticas sobre la población de Rusia. Desde el sitio web de
Rosstat, descargué los datos sobre los años de nacimiento de los rusos, recopilados en 2016.
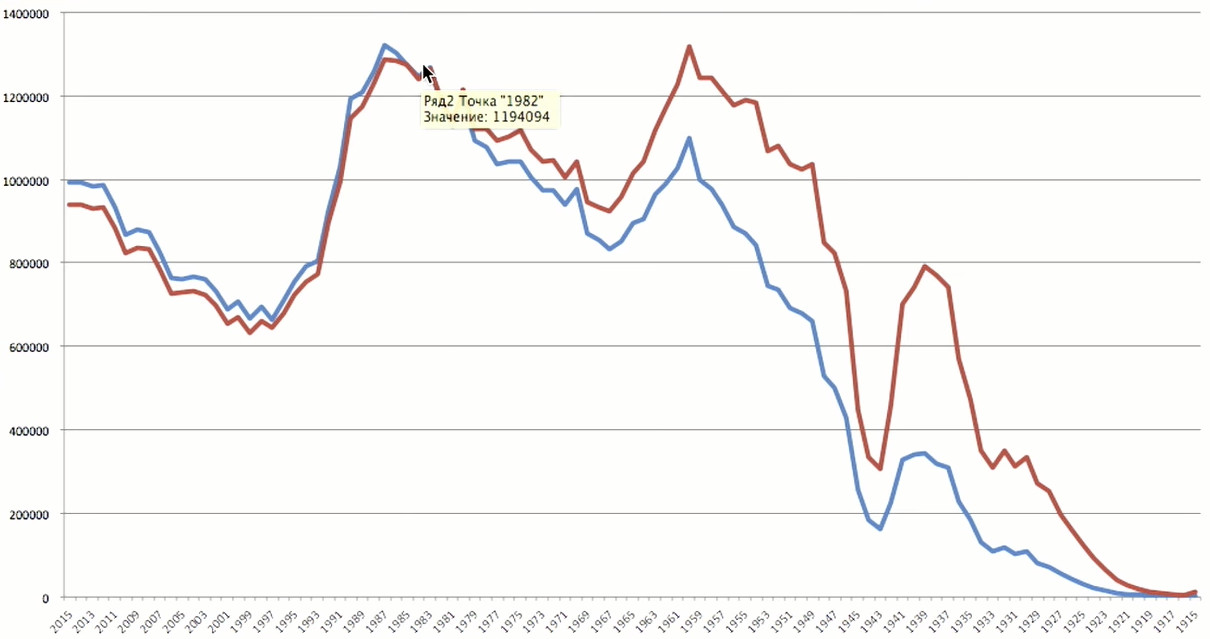
El pico en estadísticas está muy cerca del pico según Odnoklassniki: tenemos usuarios nacidos en 1983 y Rosstat - 1987. Lo que me sorprendió fueron dos grandes fracasos. El pozo de principios de la década de 1940 es la Gran Guerra Patria. La guerra nos costó no solo más de 20 millones de muertos, sino también millones de personas no nacidas. Este es el pozo demográfico que todavía se siente. El segundo pozo: la década de 1990. Y no nos hemos recuperado completamente de esta crisis. Vemos la misma imagen en los datos de Odnoklassniki: después de 1990, hubo un fuerte descenso. Todavía no podemos tener personas nacidas en 2015, porque la edad mínima para registrarse es de 5 años.
Agregue el atributo de género a nuestra muestra y grupo no solo por año, sino también por género.
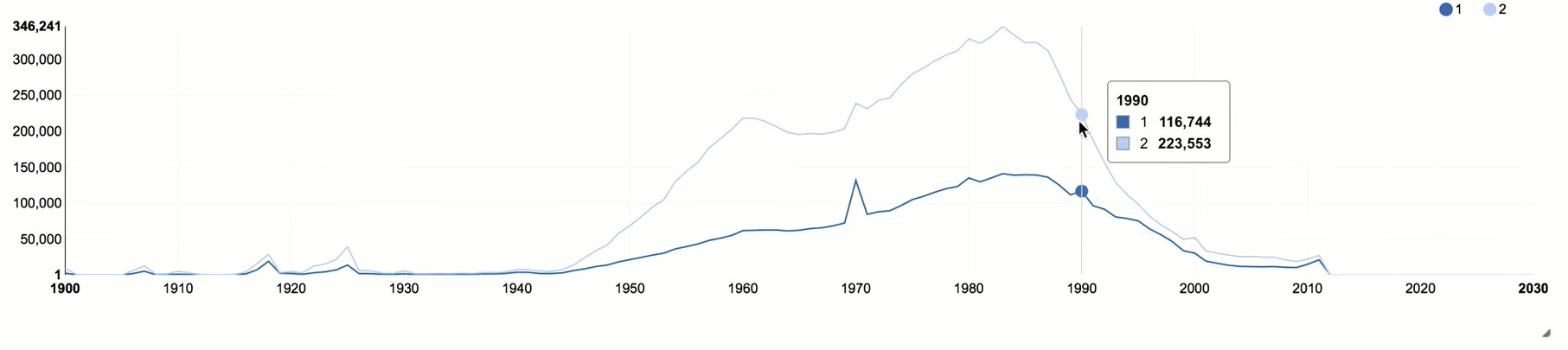
Después de 1990, hay una fuerte disminución, que se correlaciona con la situación general de edad en Rusia. Las mujeres ponen la "clase" mucho más activa, casi el doble que los hombres. Esta es una imagen bastante típica para las redes sociales, porque las mujeres son más activas socialmente que los hombres.
También puede prestar atención a varios picos que se correlacionan con los años "redondos". En base a estos picos, se puede evaluar la influencia de los robots o las personas que distorsionan deliberadamente su edad, porque en tales casos generalmente indican algún tipo de fechas redondas.
También estamos interesados en la distribución geográfica de nuestros usuarios. Necesitamos una identificación de usuario para contar visitantes únicos y las direcciones de residencia indicadas en los perfiles. Agrupe por ciudad y calcule la unidad. Ordene por el número de usuarios en orden descendente y deje solo las primeras 200 ciudades. Ejecutar agregación:

Esta es la ciudad más importante en términos de número de compañeros de clase que han establecido los compañeros de clase. Naturalmente, Moscú está a la cabeza. El sur de Rusia está representado mucho mejor que el noroeste. Tenemos usuarios en los Estados Unidos, Canadá, mucho en Alemania, mucho en Israel. Dato interesante: a 36 mil personas de Yuzhno-Sakhalinsk les gustaba cada día. Y en total, según Wikipedia, 180 mil personas viven en la ciudad. El 20% de la población de Yuzhno-Sakhalinsk fue a Odnoklassniki y colocó una "clase".

Acércate y observa lo que sucede en Moscú y la región de Moscú.

Las repúblicas de Asia Central, Moldavia, Ucrania están muy bien representadas en Odnoklassniki.

Puede ver de inmediato dónde intentaron bloquear el acceso a nuestra red social y dónde no.
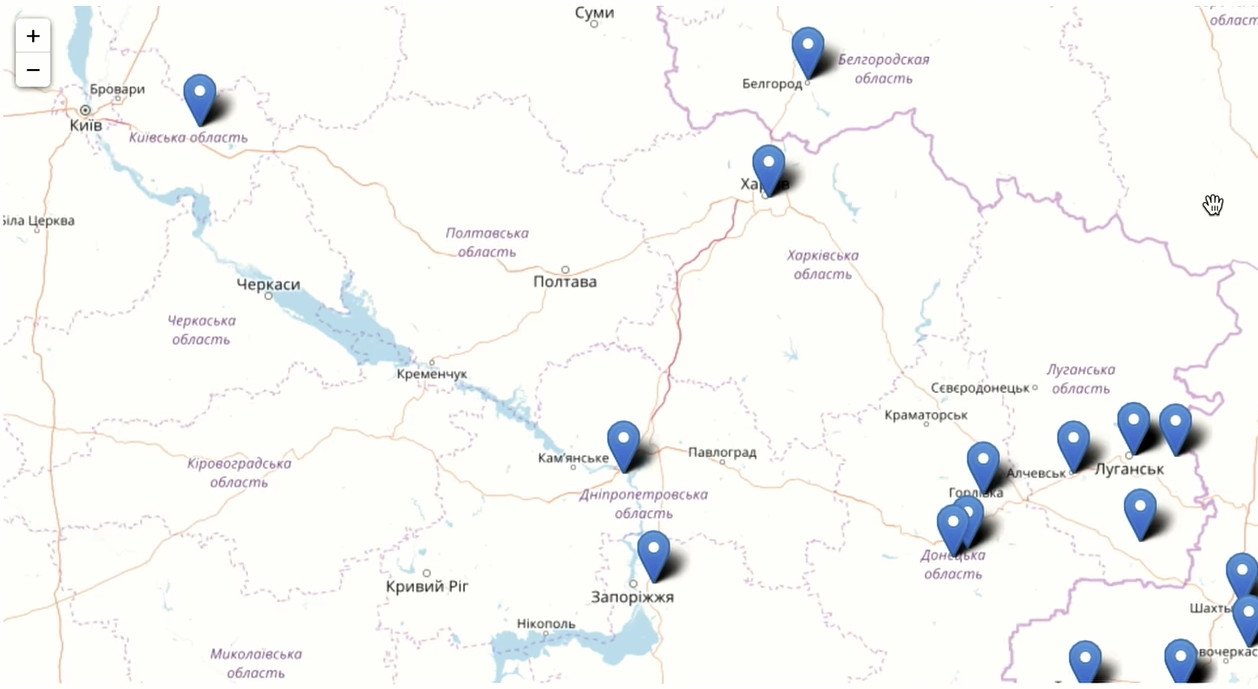
Como puede ver, Odnoklassniki es un producto dinámico y dinámico que utilizan tanto los jóvenes como las personas mayores de todo el mundo, a veces incluso donde no lo esperan. Entre todas las categorías de edad, tenemos la mayoría de las personas de 30 años.
Las redes sociales se construyen alrededor de las comunidades. A menudo sucede que si una comunidad ha ingresado a una determinada red social, sabe muy poco sobre otras redes sociales. Por lo tanto, por ejemplo, la comunidad profesional de periodistas puede tener la ilusión de que Odnoklassniki es principalmente una audiencia de ancianos. De hecho, esta es la opinión subjetiva de alguna comunidad. Tenemos usuarios de 50 a 60 años y más, hay escolares, hay jóvenes de 20 años, hay personas maduras y maduras de 30 a 35 años.
La cobertura de Odnoklassniki abarca todas las regiones de Rusia, países vecinos, Ucrania, Bielorrusia, Asia Central. Hemos representado muy bien a las diásporas, por ejemplo, la diáspora alemana de emigrantes rusos, la diáspora estadounidense y la israelí. Se comunican bastante activamente con sus familiares que han permanecido en Rusia y las antiguas repúblicas soviéticas. Desde este punto de vista, Odnoklassniki contribuye muy bien a la implementación de la función básica de una red social: mantener contactos entre personas que viven lejos unas de otras.
Existe la opinión de que Odnoklassniki es tan atractivo para muchos porque es una manera fácil de conocer amigos y conocidos de sus amigos y familiares. Es decir, Odnoklassniki se presenta como un servicio de citas. ¿Cuánto cuesta esta forma de citas y es parte de la ideología de Odnoklassniki?La necesidad de conocer a otras personas, incluido el sexo opuesto, es una necesidad humana básica. Naturalmente, se expresa en cualquier red social. Pero en Odnoklassniki se expresa ni más ni menos que en otras redes sociales. No tenemos énfasis en los servicios de citas. La ideología del desarrollo de nuestra red social se basa en un valor tan común como la comunicación entre las personas. No es tan importante para nosotros si serán compañeros de clase que se hayan dispersado a diferentes ciudades o personas que estén buscando pareja. Ambas opciones nos quedan perfectamente. Nos alegra que las personas se hayan encontrado y se hayan comunicado. Pero nada mas
Haces mucho aprendizaje automático. Este tema ahora emociona a muchos. ¿Por dónde empezar, cómo entrar en esta profesión?Primero, necesitas obtener algo de conocimiento. No hay problemas con esto, hay cursos maravillosos en
Coursera , en
Stepik y en algunos programas universitarios que brindan muy buenos conocimientos básicos sobre el aprendizaje automático. Para unirse realmente a esta esfera, necesita un objetivo y comprender dónde puede aplicarlo. Porque solo escuchar un curso abstracto está lejos de ser tan efectivo como si realmente resolviera un problema o problema.
En el caso de los estudiantes, la opción ideal son trabajos de fin de curso, disertaciones. E incluso en este caso, trato de no decepcionar la tarea desde arriba, sino de ayudar a que las ideas vengan de los estudiantes, entonces tendrán mucha más motivación.
Es decir, haber establecido una meta, escuchar cursos en línea y luego tratar de aplicar el conocimiento. Y todo saldrá bien.
Me parece que hay suficientes tareas hoy. Una gran cantidad de competiciones de Sberbank, Tinkoff y muchas otras compañías se llevan a cabo en el skittle.Por supuesto Pero se centran, en primer lugar, en aquellos que ya están estrechamente involucrados en el aprendizaje automático. Además, muy a menudo en tales competencias se puede observar no el aprendizaje automático, sino el odio al límite. Esos modelos que están entrenados en el skittle no ayudarán a resolver problemas prácticos, porque manejan demasiados parámetros. Como resultado, los modelos se especializan específicamente para competiciones específicas en el bolo, y solo en ellos se obtienen resultados. Y si transfiere estos modelos al mundo real, no funcionarán.
La mejor práctica es la práctica. ¿Cómo practicar con tu equipo?Hay muchas maneras Si hablamos de equipos de investigación, entonces tenemos un proyecto llamado OK Data Science Lab, en el que brindamos recursos informáticos, datos, nuestro conocimiento y experiencia a las personas que desean desarrollar sus ideas relacionadas con el aprendizaje automático y el análisis de datos. Y no necesariamente para una red social. Por ejemplo, tenemos un estudio en el que el autor intenta comprender qué es lo más interesante para los escolares modernos.
Si es un especialista y busca trabajo, siempre tenemos muchas vacantes relacionadas con el aprendizaje automático. Visítanos para una entrevista.
¿Hay algún libro, un lector de aprendizaje automático?Este es un campo que cambia tan rápidamente que escribir un libro o lector de aprendizaje automático es demasiado ambicioso. Puedo recomendar el clásico trabajo "
Elementos del aprendizaje estadístico ". Se trata de los métodos más básicos de aprendizaje automático, originados en estadísticas.
Sergey Nikolenko publicó un libro sobre aprendizaje automático profundo.En mi opinión, el aprendizaje profundo no es por dónde empezar. Si ya posee el aprendizaje automático clásico, esta es una buena opción. Pero si aún no conoce las técnicas clásicas, es un error comenzar de inmediato con el aprendizaje profundo, ya que a menudo aleja al investigador del problema, esta es una herramienta muy poderosa. Antes de aplicarlo, debe analizar el problema "manualmente" de manera más simple. Y solo entonces, con una comprensión del área temática, continúe con el aprendizaje profundo. De lo contrario, su modelo aprenderá, pero usted no. Cuando te vuelves más tonto que tu modelo, es, por decirlo suavemente, ineficaz. No puede desarrollar más el modelo, y este es un callejón sin salida. Por lo tanto, es mejor ser primero competente en ML clásico. Esto no significa que deba pasar años, es muy posible dominarlo en un tiempo razonable.
¿Tienes algún evento de aprendizaje automático?Tenemos una serie de
hackatones SNA Hackathon . Hasta ahora, han pasado dos veces. Por primera vez, el hackathon se dedicó a analizar el texto e intentar predecir cuántas "clases" ganaría una publicación en particular. El segundo hackathon tuvo lugar hace un año y se dedicó al análisis de gráficos. Ha habido muchos eventos interesantes. Proporcionamos información sobre las "amistades" de algunos de nuestros usuarios, al parecer, un pequeño dato sobre 1 GB. Pero cuando los participantes que querían enviar sus pronósticos intentaron trabajar con él, casi nadie tuvo éxito, incluso en máquinas con 16 y 32 GB de memoria, todo se cayó, se convirtió en un intercambio, no quería trabajar. Incluso tuvimos que explicar apresuradamente cómo y cómo no trabajar con datos.
Resultó que muchos, incluso especialistas en aprendizaje automático bastante avanzados, habían salido de las raíces y comenzaron a olvidar los principios básicos de la programación. Olvide qué es el boxeo, cómo están estructuradas las tablas hash, qué sobrecarga de memoria puede ser si usa tablas hash. Si no piensa en todo esto y lo hace de frente en Python, Java o Scala, se describirán los problemas descritos. Hicimos una demostración en Python, el mismo rastrillo está en otros idiomas. Un gráfico de 40 millones de enlaces, que podría caber en 200 MB de memoria, explota bruscamente a 20 GB simplemente porque olvidó cómo se organizan las estructuras de datos básicas. Fue muy impresionante entonces. Incluso si es un especialista en aprendizaje automático, no debe olvidar los conceptos básicos de la programación.
¿Cómo se organiza su flujo de trabajo de procesamiento de datos?Los usuarios interactúan con todo un ecosistema de nuestros productos. Podemos distinguir condicionalmente dos niveles: aplicaciones front-end (aplicaciones móviles, portal, versión móvil, varias aplicaciones adicionales) y lógica de negocios. Los frentes a menudo interactúan con los usuarios y tienen acceso a un número muy limitado de servidores, por lo que existen algunos métodos especiales en la lógica empresarial que permiten a los frentes registrar datos.
Estos datos caen en el bus de datos único Apache Kafka. Este es el turno que se ha convertido en un estándar de la industria que se utiliza para recopilar datos sin procesar. Naturalmente, es difícil analizar los datos en bruto en Kafka, por lo que se transfieren regularmente al Hadoop grande y grueso. Alguien puede decir que Hadoop es el siglo pasado, ahora gobierna Spark. Pero Hadoop es una plataforma en la que puede ejecutar muchas herramientas. Tenemos varias herramientas de análisis girando sobre Hadoop. A menudo recurro a esta clasificación:
- El estilo de entrada de datos .
- Procesamiento por lotes. Hay cierta cantidad de datos que de alguna manera procesas.
- Procesamiento de flujo. , , Kafka.
— , , — .
- . . production, , .
- . , . : - , .
. , MapReduce, Apache Tez Spark. , Spark SQL Pig Hive.
, , . Apache Samza. LinkedIn. 2014 . , Spark Streaming, -.
- production, . , Kafka, . Kafka — , , . , Kafka , Streaming Index. Kafka : Casandra , SMC.
, , 99 %. - Streaming Index, . , , , «» , . , .
, , -. ?Mac.
IDE?Idea.
: ?.
?, .
, IT- 10 ?, .
?: , . , , , .
?, . . , , . , , .
, . «»?Lo mismo que los periodistas: cuántas personas quedan en Odnoklassniki.¿Qué superhéroe te gustaría ser?Probablemente Tony Stark.Iron Man?Si
Por quéTecnología.