
Los desarrolladores que saben y saben trabajar con git han crecido en un orden de magnitud últimamente. Te acostumbras a la velocidad de ejecución del comando. Te acostumbras a la comodidad de las sucursales y a la fácil reversión de los cambios. La resolución de conflictos es tan común que los programadores están acostumbrados a resolver heroicamente conflictos donde no deberían estar.
Nuestro equipo en Directum está desarrollando una herramienta de desarrollo para soluciones de plataforma. Si vio 1C, puede imaginarse a grandes rasgos el entorno de trabajo de nuestros "clientes": desarrolladores de aplicaciones. Con esta herramienta de desarrollo, un desarrollador de aplicaciones crea una solución de aplicación para los clientes.
Nuestro equipo se enfrentó a la tarea de simplificar la vida de nuestros solicitantes. Estamos mimados con chips modernos de Visual Studio, ReSharper e IDEA. Los solicitantes exigieron que integremos git fuera de la caja en la herramienta.
Esta es la dificultad. En la herramienta para cada tipo de entidad (contrato, informe, directorio, módulo), podría estar presente un bloqueo. Un desarrollador comenzó a editar el tipo de entidad y lo bloqueó hasta que completó los cambios y los confirmó en el servidor. Otros desarrolladores en este momento ven el mismo tipo de entidad de solo lectura. El desarrollo recordaba de alguna manera el trabajo en SVN o el envío de un documento de Word por correo entre varios usuarios. Quiero todo a la vez, pero tal vez solo uno.
Cada tipo de entidad puede tener muchos controladores (abrir un documento, validación antes de guardar, escribir en la base de datos) en los que desea escribir código que funcione con una instancia específica de la entidad. Por ejemplo, bloquee los botones, muestre un mensaje al usuario o cree una nueva tarea para los artistas. Todo el código dentro del marco de la API proporcionado por la plataforma. Los manejadores son clases en las que se encuentran muchos métodos. Cuando dos personas necesitaban arreglar el mismo archivo con el código, no era posible hacerlo, porque la plataforma bloqueó todo el tipo de entidad junto con el código dependiente.
Nuestros practicantes fueron hasta el final. En silencio se bifurcaron una copia "ilegal" de nuestro entorno de desarrollo, comentaron la parte de bloqueo y fusionaron nuestros compromisos con ellos mismos. El código de la aplicación se mantuvo bajo el git, comprometido a través de herramientas de terceros (git bash, SourceTree y otros). Hicimos nuestras conclusiones:
- Nuestro equipo subestimó la disposición de los desarrolladores de aplicaciones para encajar en la plataforma. Enorme respeto y honor!
- La solución que propusieron no es adecuada para la producción. Con git, las manos de una persona se desatan y él puede crear cualquier cosa. Para apoyar toda la diversidad será estúpido, no secuestros. Además, será necesario educar a los clientes de la plataforma. Documentar todos los comandos git para la plataforma volvería loco al equipo de documentación.

Lo que quieres de Git
Por lo tanto, rendirse a la producción con un git out no es bueno. Decidimos encapsular de alguna manera la lógica de las operaciones principales y limitar su número. Al menos para el primer lanzamiento. La lista de equipos se redujo como pudieron y se mantuvo:
- estado
- cometer
- tirar
- empujar
- restablecer - duro a HEAD
- restablecer a la última confirmación de "servidor"
Para el primer lanzamiento, decidieron negarse a trabajar con sucursales. No es que sea muy difícil, solo el equipo no cumplió con el recurso de tiempo.
Periódicamente, nuestros socios envían su desarrollo de aplicaciones y preguntan: "Algo no funciona para nosotros. ¿Qué estamos haciendo mal?". En este caso, la aplicación se carga con el desarrollo de otra persona y analiza el código. Esto solía funcionar así:
- El desarrollador se llevó el archivo con el desarrollo;
- Cambió la base de datos local en configuraciones;
- Vertió el desarrollo de otra persona en su base;
- Depurado, errores encontrados;
- Recomendaciones emitidas;
- Regresó su desarrollo de nuevo.
La nueva metodología no encajaba en el viejo enfoque. Tuve que aplastarme la cabeza. El equipo propuso dos enfoques para resolver este problema:
- Almacene todo el desarrollo en un repositorio de git. Si es necesario, trabaje con la decisión de otra persona de crear una sucursal temporal.
- Almacene el desarrollo de diferentes equipos en diferentes repositorios. Mueva la configuración de las carpetas cargadas en el entorno al archivo de configuración.
Decidimos seguir el segundo camino. El primero parecía más difícil de implementar y, además, era más fácil dispararse en el pie con el cambio de rama.
Pero el segundo tampoco es dulce. Los comandos descritos anteriormente deberían funcionar no solo dentro del mismo repositorio, sino con varios a la vez. ¿Hay un cambio en los tipos de entidad de diferentes repositorios? Los mostramos en una ventana. Esto es más conveniente y transparente para el desarrollador de la aplicación. Al presionar el botón de confirmación, la herramienta confirma los cambios en cada uno de los repositorios. En consecuencia, los comandos de extracción / empuje / reinicio "debajo del capó" funcionan con repositorios físicamente diferentes.

Libgit2sharp
Para trabajar con git, elegimos entre dos opciones:
- Trabaje con git instalado en el sistema, arrastrándolo a través de Process. Inicie y analice la salida.
- Use libgit2sharp, que a través de pinvoke extrae la biblioteca libgit2.
Nos pareció que usar una biblioteca preparada es una solución razonable. En vano Te diré un poco más tarde por qué. Al principio, la biblioteca nos dio la oportunidad de implementar rápidamente un prototipo funcional.
Primera iteración de desarrollo
Fue posible implementar en aproximadamente un mes. En realidad, atornillar el git fue rápido, y la mayoría de las veces tratamos de curar las heridas que se habían abierto porque habíamos cortado el viejo mecanismo para almacenar los archivos de origen. Todo lo que devolvió el git status fue devuelto a la interfaz. Al hacer clic en cada archivo, se muestra diff. Parecía una interfaz git gui.
Segunda iteración de desarrollo
La primera opción fue demasiado informativa. Con cada tipo de entidad, muchos archivos están asociados a la vez. Estos archivos crearon ruido, y no quedó claro qué tipos de entidades cambiaron y qué exactamente.
Archivos agrupados por tipo de entidad. Cada archivo recibió un nombre legible para humanos, el mismo que en la GUI. Los metadatos del tipo de entidad se describen en JSON. También debían presentarse en un formato legible para humanos. El análisis de los cambios en las versiones de json "antes" y "después" se inició utilizando la biblioteca jsondiffpatch, y luego escribieron su propia implementación de comparación JSON (en adelante llamaré jsondiff). Ejecutamos los resultados de la comparación a través de analizadores que producen registros legibles por humanos. Muchos archivos estaban ocultos a la vista, dejando una entrada simple en el árbol de cambios.
El resultado final es el siguiente:
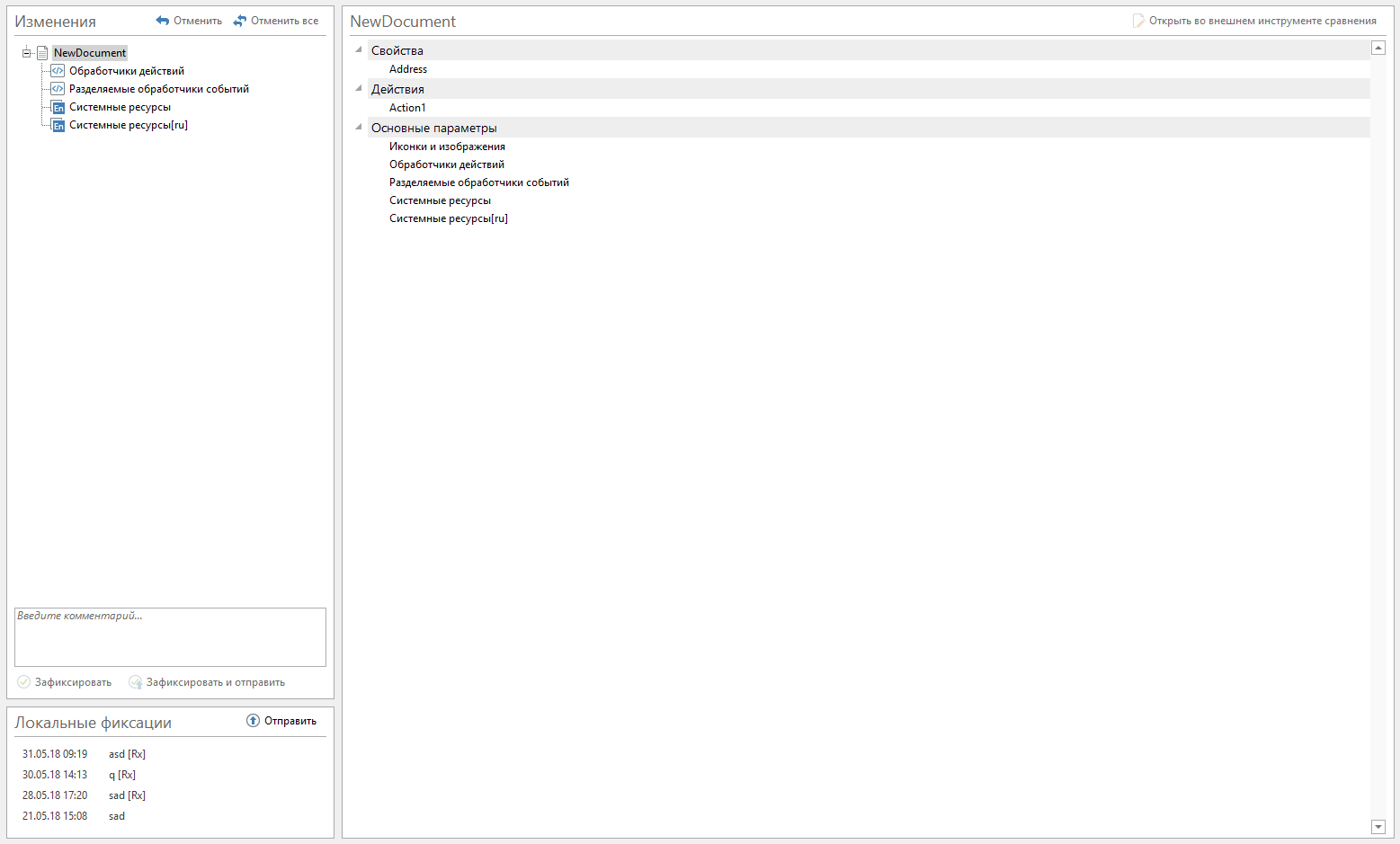
Tener problemas con libgit2
Libgit2 generó una gran cantidad de sorpresas inesperadas. Tratar con algunos estaba más allá del poder de un tiempo razonable. Te diré lo que recuerdo.
Inesperado y difícil de reproducir cae en algunas operaciones estándar. "Ningún error proporcionado por la biblioteca nativa" nos dice el contenedor. Genial Estás maldiciendo, estás reconstruyendo la biblioteca nativa en depuración, estás repitiendo un caso previamente descartado, pero no se bloquea en modo de depuración. Reconstruir en la liberación y caer de nuevo.
Si una herramienta de terceros, por ejemplo, SourceTree, se ejecuta en paralelo con libgit2sharp, entonces commit puede no confirmar algunos archivos. O se congela cuando se muestran diferencias en algunos archivos. Tan pronto como intente depurar, no podrá reproducir.
En una de nuestras aplicaciones, la implementación del git status análogo de git status tomó 40 segundos. Cuarenta Carl! Al mismo tiempo, el git lanzado desde la consola funcionó como debería por un segundo. Pasé un par de días para resolverlo. Al buscar cambios, Libgit2 mira los atributos de archivo de las carpetas y los compara con la entrada en el índice. Si el tiempo de modificación es diferente, entonces algo ha cambiado dentro de la carpeta y debe buscar dentro y / o buscar en los archivos. Y si nada ha cambiado, entonces no debes subir al interior. Esta optimización aparentemente también está en la consola git. No sé por qué razón, pero solo para una persona en el índice git mtime cambió. Debido a esto, git verificó el contenido de TODOS los archivos en el repositorio cada vez por cambios.
Más cerca del lanzamiento, nuestro equipo cedió a los deseos del equipo de aplicaciones y reemplazó git pull con fetch + rebase + autostash . Y luego nos llegaron un montón de errores, incluso con "Ningún error proporcionado por la biblioteca nativa".
status, pull y rebase funcionan mucho más tiempo que llamar a comandos de consola.
Fusión automática
Los archivos en desarrollo se dividen en dos tipos:
- Archivos que la aplicación ve en la herramienta de desarrollo. Por ejemplo, código, imágenes, recursos. Dichos archivos deben fusionarse como lo hace git.
- Los archivos JSON creados por el entorno de desarrollo, pero el desarrollador de la aplicación los ve solo en forma de GUI. Necesitan resolver conflictos automáticamente.
- Archivos generados que se recrean automáticamente cuando se trabaja con la herramienta de desarrollo. Estos archivos no entran en el repositorio, la herramienta inmediatamente coloca cuidadosamente .gitignore.
Con una nueva forma, dos aplicadores diferentes pudieron cambiar el mismo tipo de entidad.
Por ejemplo, Sasha cambiará la información sobre cómo almacenar el tipo de una entidad en la base de datos y escribirá un controlador para el evento guardar, y Sergey diseñará la representación de la entidad. Desde el punto de vista de git, esto no será un conflicto y ambos cambios se fusionarán sin complejidad.
Y luego Sasha cambió la propiedad Property1 y estableció un controlador para ello. Sergey creó la propiedad Property2 y configuró el controlador. Si observa la situación desde arriba, sus cambios no entran en conflicto, aunque desde el punto de vista de git los mismos archivos se ven afectados.
Quería que el instrumento pudiera resolver esta situación por sí solo.
Un algoritmo de ejemplo para fusionar dos JSON en caso de conflicto:
Descargar desde la base de JSON git.
Descargar desde nuestro JSON gita.
Descargando su JSON de un git.
Usando jsondiff, formamos parches de software base-> nuestros y los aplicamos a los suyos. El JSON resultante se llama P1.
Usando jsondiff, formamos parches de software base-> suyo y los aplicamos a los nuestros. El JSON resultante se llama P2.
Idealmente, después de aplicar los parches P1 === P2. Si es así, escriba P1 en el disco.
- En un caso imperfecto (cuando realmente existe un conflicto), sugerimos al usuario que elija entre P1 y P2 con la capacidad de terminar con sus manos. Escribimos la selección en el disco.
Después de la fusión, verificamos si el estado sin errores de validación ha alcanzado. Si no ha llegado, cancele la fusión y solicite al usuario que la repita. Esta no es la mejor solución, pero al menos garantiza que a partir del segundo o tercer intento, la fusión se producirá sin consecuencias desagradables.
Resumen
- Los carniceros están felices de que puedan usar legalmente.
- La introducción de git aceleró el desarrollo.
- Las fusiones automáticas generalmente parecen mágicas.
- Establecemos el futuro rechazo de libgit2 a favor de invocar el proceso git.