El 28 de mayo, en la conferencia
RootConf 2018, que tuvo lugar como parte del
festival RIT ++ 2018, en la sección "Registro y monitoreo", se entregó un informe "Monitoreo y Kubernetes". Cuenta sobre la experiencia de la configuración de monitoreo con Prometheus, que fue obtenida por Flant como resultado de la operación de docenas de proyectos de Kubernetes en producción.

Por tradición, nos complace presentar un
video con un informe (aproximadamente una hora,
mucho más informativo
que el artículo) y la compresión principal en forma de texto. Vamos!
¿Qué es el monitoreo?
Existen muchos sistemas de monitoreo:

Parece que tomar e instalar uno de ellos, eso es todo, la pregunta está cerrada. Pero la práctica muestra que esto no es así. Y aquí está el por qué:
- Velocímetro muestra la velocidad . Si medimos la velocidad una vez por minuto con el velocímetro, entonces la velocidad promedio, que calculamos sobre la base de estos datos, no coincidirá con los datos del odómetro. Y si en el caso de un automóvil esto es obvio, cuando se trata de muchos indicadores para el servidor, a menudo nos olvidamos de él.
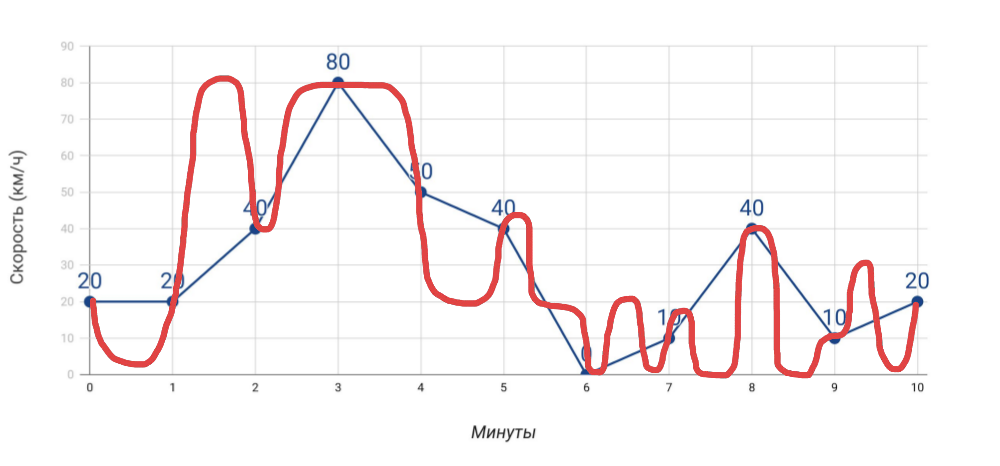
Qué medimos y cómo viajamos realmente - Más medidas Cuantos más indicadores diferentes obtengamos, más preciso será el diagnóstico de problemas ... pero solo con la condición de que estos sean indicadores realmente útiles, y no solo todo lo que logró reunir.
- Alertas No hay nada complicado en enviar alertas. Sin embargo, dos problemas típicos: a) las falsas alarmas ocurren con tanta frecuencia que dejamos de responder a las alertas, b) las alertas llegan en un momento en que es demasiado tarde (todo ya ha explotado). ¡Y lograr en el monitoreo que estos problemas no surgieron es un arte genuino!
El monitoreo es un pastel de tres capas, cada una de las cuales es crítica:
- En primer lugar, este es un sistema que le permite evitar accidentes , notificar sobre accidentes (si no pueden evitarse) y realizar un diagnóstico rápido de problemas.
- ¿Qué se necesita para esto? Datos precisos , gráficos útiles (mírelos y comprenda dónde está el problema), alertas relevantes (lleguen en el momento adecuado y contengan información clara).
- Y para que todo esto funcione, se necesita un sistema de monitoreo .
La configuración adecuada de un sistema de monitoreo que realmente funcione no es una tarea fácil, ya que requiere un enfoque cuidadoso para la implementación incluso sin Kubernetes. ¿Pero qué pasa con su apariencia?
Datos de monitoreo de Kubernetes
No 1. Más grande y más rápido
Kubernetes está cambiando mucho porque la infraestructura se está haciendo más grande y más rápida. Anteriormente, con los servidores de hierro normales, su número era muy limitado y el proceso de adición era muy largo (tomaba días o semanas), luego, con las máquinas virtuales, el número de entidades aumentaba significativamente y el tiempo de su introducción en la batalla se reducía a segundos.
Con Kubernetes, el número de entidades ha crecido en un orden de magnitud, su adición es completamente automática (la gestión de la configuración es necesaria, porque sin una descripción simplemente no se puede crear un nuevo pod), toda la infraestructura se ha vuelto muy dinámica (por ejemplo, con cada despliegue, los pod se eliminan y se crean de nuevo).
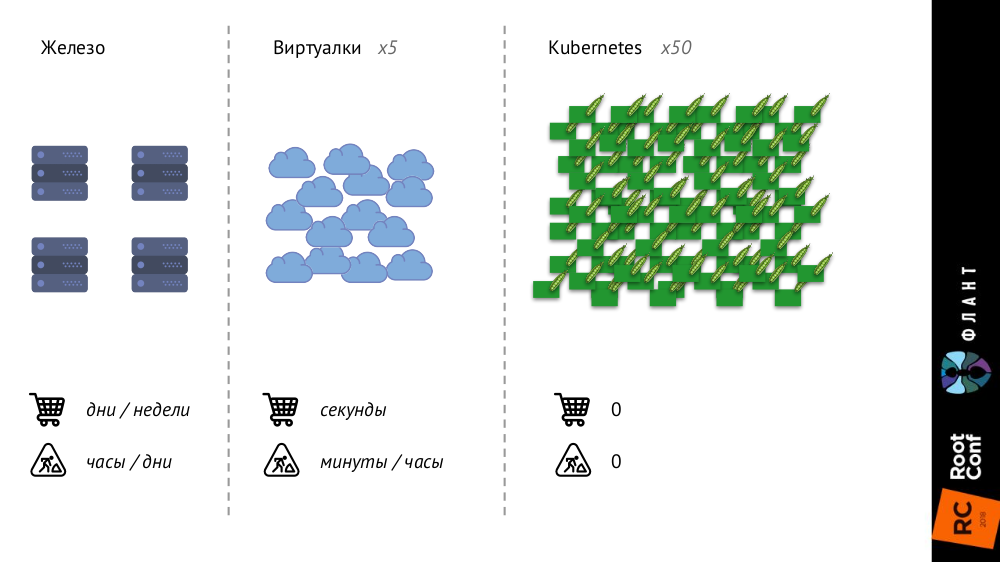
¿Qué cambia eso?
- En principio, dejamos de mirar contenedores o contenedores individuales; ahora solo nos interesan los grupos de objetos .
- Service Discovery se vuelve estrictamente obligatorio , porque las "velocidades" ya son tales que, en principio, no podemos iniciar / eliminar nuevas entidades manualmente, como era antes, cuando se compraron nuevos servidores.
- La cantidad de datos está creciendo significativamente . Si se recopilaron métricas anteriores de servidores o máquinas virtuales, ahora de pods, cuyo número es mucho mayor.
- El cambio más interesante lo llamé el " flujo de metadatos " y le contaré más al respecto.
Comenzaré con esta comparación:
- Cuando envíe a su hijo al jardín de infantes, se le dará una caja personal, que se le asignará para el próximo año (o más) y en la que se indica su nombre.
- Cuando vienes al grupo, tu casillero no está firmado y se te envía para una "sesión".
Entonces,
los sistemas de monitoreo clásicos piensan que son un jardín de infantes , no un grupo: suponen que el objeto de monitoreo les llegó para siempre o durante mucho tiempo, y les dan casilleros en consecuencia. Pero las realidades en Kubernetes son diferentes: la cápsula llegó al grupo (es decir, fue creada), nadó en ella (antes del nuevo despliegue) y se fue (fue destruida); todo esto sucede rápida y regularmente. Por lo tanto, el sistema de monitoreo debe comprender que los objetos que monitorea tienen una vida corta y debe poder olvidarlo por completo en el momento adecuado.
No 2. La realidad paralela existe
Otro punto importante: con el advenimiento de Kubernetes, simultáneamente tenemos dos "realidades":
- Mundo de Kubernetes en el que hay espacios de nombres, implementaciones, pods, contenedores. Este es un mundo complejo, pero es lógico, estructurado.
- El mundo "físico", que consiste en muchos (literalmente - montones) de contenedores en cada nodo.
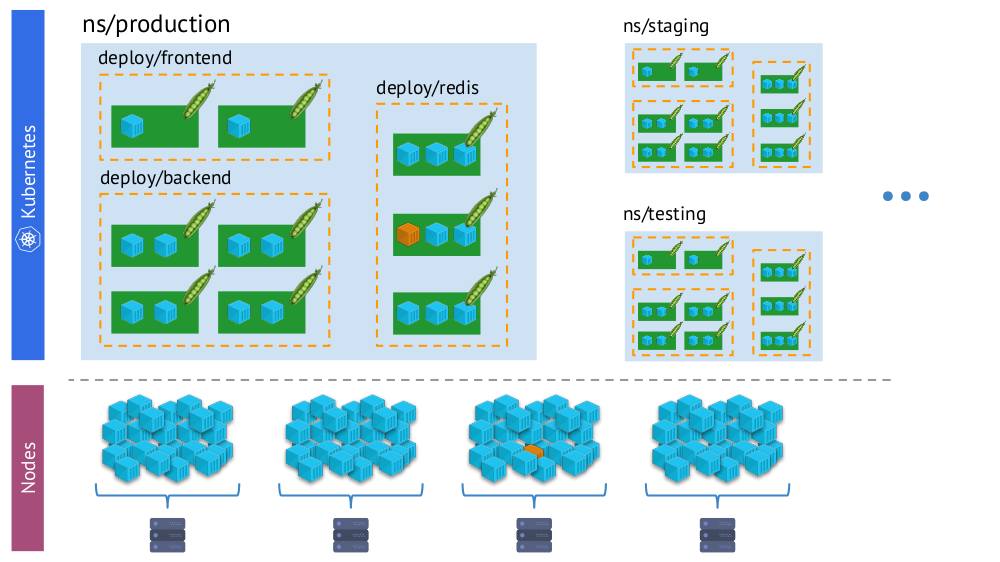 El mismo contenedor en la "realidad virtual" de Kubernetes (arriba) y el mundo físico de los nodos (abajo)
El mismo contenedor en la "realidad virtual" de Kubernetes (arriba) y el mundo físico de los nodos (abajo)Y en el proceso de monitoreo, necesitamos
comparar constantemente
el mundo físico de los contenedores con la realidad de Kubernetes . Por ejemplo, cuando miramos algún espacio de nombres, queremos saber dónde están ubicados todos sus contenedores (o los contenedores de uno de sus hogares). Sin esto, las alertas no serán visuales y cómodas de usar, porque es importante que comprendamos qué objetos están informando.
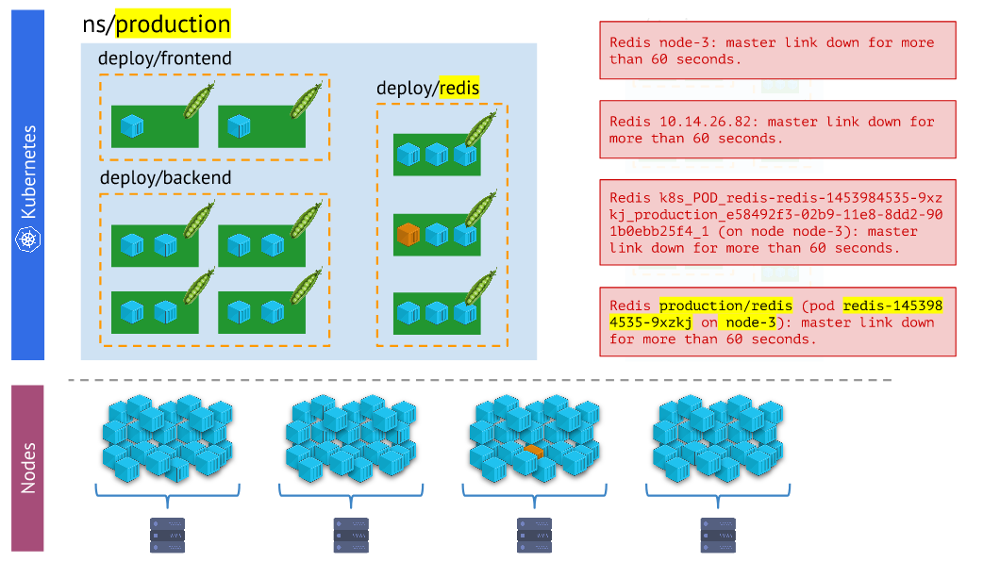 Diferentes tipos de alertas: esta última es más visual y conveniente en el trabajo que el restoLas conclusiones
Diferentes tipos de alertas: esta última es más visual y conveniente en el trabajo que el restoLas conclusiones aquí son:
- El sistema de monitoreo debe usar primitivas integradas de Kubernetes.
- Hay más de una realidad: a menudo los problemas no ocurren con el hogar, sino con un nodo en particular, y necesitamos entender constantemente en qué tipo de "realidad" se encuentran.
- En un clúster, por regla general, hay varios entornos (además de la producción), lo que significa que esto debe tenerse en cuenta (por ejemplo, no recibir alertas por la noche sobre problemas en el desarrollo).
Entonces, tenemos tres condiciones necesarias para que todo funcione:
- Entendemos bien qué es el monitoreo.
- Conocemos sus características, que aparecen con Kubernetes.
- Adoptamos el Prometeo.
Y así, para realmente trabajar, ¡solo queda hacer
un gran esfuerzo! Por cierto, ¿por qué exactamente Prometeo? ..
Prometeo
Hay dos formas de responder la pregunta sobre la elección de Prometeo:
- Vea quién y qué se usa generalmente para monitorear Kubernetes.
- Considere sus ventajas técnicas.
Para el primero, utilicé los datos de la encuesta de The New Stack (del libro electrónico
El estado del ecosistema de Kubernetes ), según el cual Prometheus es al menos más popular que otras soluciones (tanto de código abierto como SaaS), y si nos fijamos, tiene una ventaja estadística quíntuple .
Ahora veamos cómo funciona Prometheus, en paralelo con cómo sus capacidades se combinan con Kubernetes y resuelven desafíos relacionados.
¿Cómo se estructura Prometeo?
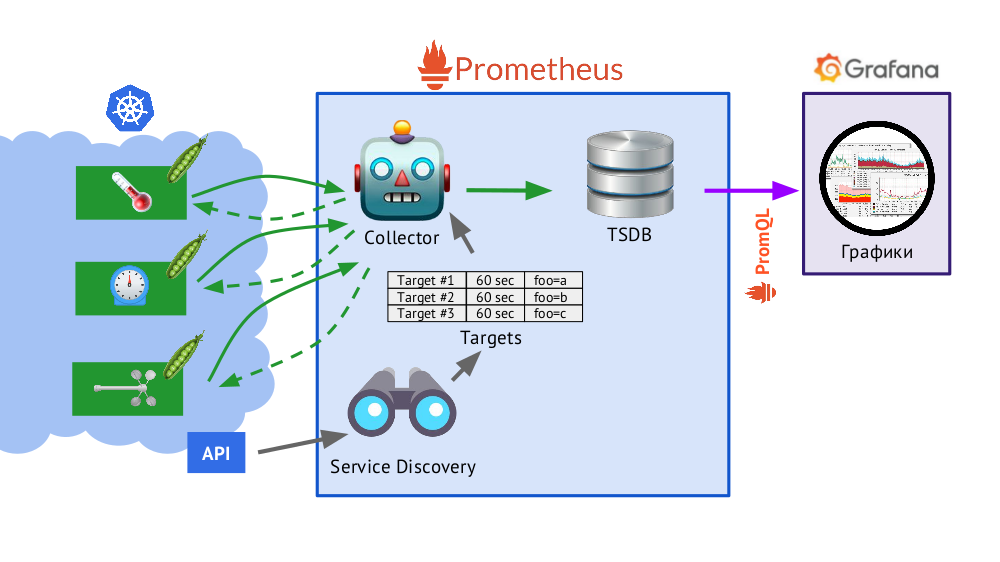
Prometheus está escrito en Go y distribuido como un solo archivo binario, en el que todo está integrado. El algoritmo básico para su funcionamiento es el siguiente:

- Collector lee la tabla de objetivos , es decir Una lista de los objetos a ser monitoreados y la frecuencia de su sondeo (por defecto - 60 segundos).
- Después de eso, el recopilador envía una solicitud HTTP a cada pod que necesita y recibe una respuesta con un conjunto de métricas: puede haber cien, mil, diez mil ... Cada métrica tiene un nombre, valor y etiquetas .
- La respuesta recibida se almacena en la base de datos de TSDB , donde la marca de tiempo de su recibo y las etiquetas del objeto del que se tomó se agregan a los datos métricos recibidos.
Brevemente sobre TSDBTSDB: base de datos de series de tiempo (DB para series de tiempo) en Go, que le permite almacenar datos durante un número específico de días y lo hace de manera muy eficiente (en tamaño, memoria y entrada / salida). Los datos se almacenan solo localmente, sin agrupamiento y replicación, lo cual es un plus (funciona de manera simple y garantizada) y un menos (no hay escala horizontal del almacenamiento), pero en el caso de Prometheus el fragmentación está bien hecho, federación - más sobre esto más adelante.
- Presentado en el esquema, Service Discovery es un motor de descubrimiento de servicios integrado en Prometheus que le permite recibir datos "de la caja" (a través de la API de Kubernetes) para crear una tabla de objetivos.
¿Cómo se ve esta mesa? Para cada entrada, almacena la URL que se utiliza para obtener métricas, la frecuencia de las llamadas y las etiquetas.
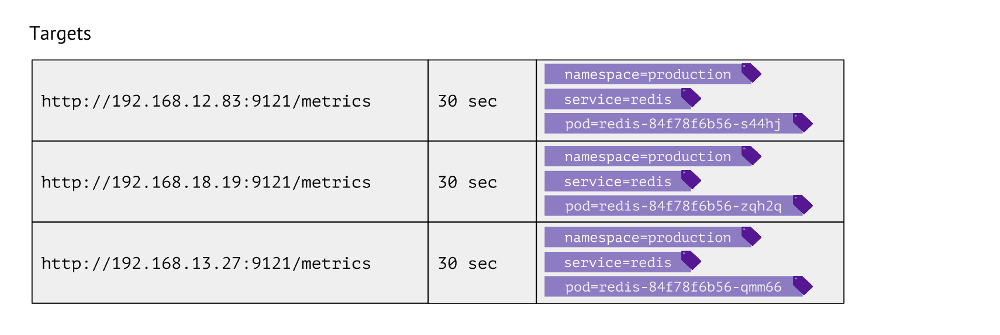
Las etiquetas se usan para la yuxtaposición de los "mundos" de Kubernetes con lo físico. Por ejemplo, para encontrar un pod con Redis necesitamos tener el espacio de nombres de valores, el servicio (utilizado en lugar de la implementación debido a las características técnicas para un caso particular) y el pod real. En consecuencia, estas 3 etiquetas se almacenan en las entradas de la tabla de objetivos para las métricas de Redis.
Estas entradas en la tabla se forman sobre la base de la
scrape_configs Prometheus en la que se describen los objetos de monitoreo: en la sección
scrape_configs , los
scrape_configs definen, lo que indica por qué etiquetas buscar objetos para monitorear, cómo filtrarlos y qué etiquetas registrar.
¿Qué datos recopila Kubernetes?
- En primer lugar, el asistente en Kubernetes es bastante complicado, y es crítico monitorear el estado de su trabajo (kube-apiserver, kube-controller-manager, kube-Scheduler, kube-etcd3 ...), además, está vinculado al nodo del clúster.
- En segundo lugar, es importante saber qué sucede dentro de Kubernetes . Para ello, obtenemos datos de:
- kubelet : este componente de Kubernetes se ejecuta en cada nodo del clúster (y se conecta al asistente K8s); cAdvisor está integrado en él (todas las métricas por contenedores) y también almacena información sobre volúmenes persistentes conectados;
- kube-state-metrics : de hecho, este es el Prometheus Exporter para la API de Kubernetes (le permite obtener información sobre los objetos almacenados en Kubernetes: pods, servicios, implementaciones, etc., por ejemplo, no lo sabremos sin él estado del contenedor o hogar);
- exportador de nodos : proporciona información sobre el propio nodo, métricas básicas en el sistema Linux (cpu, diskstats, meminfo, etc. ).
- Los siguientes son componentes de Kubernetes , como kube-dns, kube-prometheus-operator y kube-prometheus, ingress-nginx-controller, etc.
- La siguiente categoría de objetos a monitorear es en realidad el software lanzado en Kubernetes. Estos son servicios de servidor típicos como nginx, php-fpm, Redis, MongoDB, RabbitMQ ... Lo hacemos nosotros mismos para que cuando agreguemos ciertas etiquetas al servicio, automáticamente comience a recopilar los datos necesarios, lo que crea el tablero actual en Grafana.
- Finalmente, la categoría para todo lo demás es personalizada . Las herramientas de Prometheus le permiten automatizar la recopilación de métricas arbitrarias (por ejemplo, el número de pedidos) simplemente agregando una etiqueta
prometheus-custom-target a la descripción del servicio.

Gráficos
Los datos recibidos
(descritos anteriormente) se utilizan para enviar alertas y crear gráficos. Dibujamos gráficos usando
Grafana . Y un "detalle" importante aquí es
PromQL , el lenguaje de consulta de Prometheus que se integra perfectamente con Grafana.
Es bastante simple y conveniente para la mayoría de las tareas
(pero, por ejemplo, unirlas ya es un inconveniente, pero aún debe hacerlo) . PromQL le permite resolver todas las tareas necesarias: seleccione rápidamente las métricas necesarias, compare valores, realice operaciones aritméticas en ellas, agrupe, trabaje con intervalos de tiempo y mucho más. Por ejemplo:

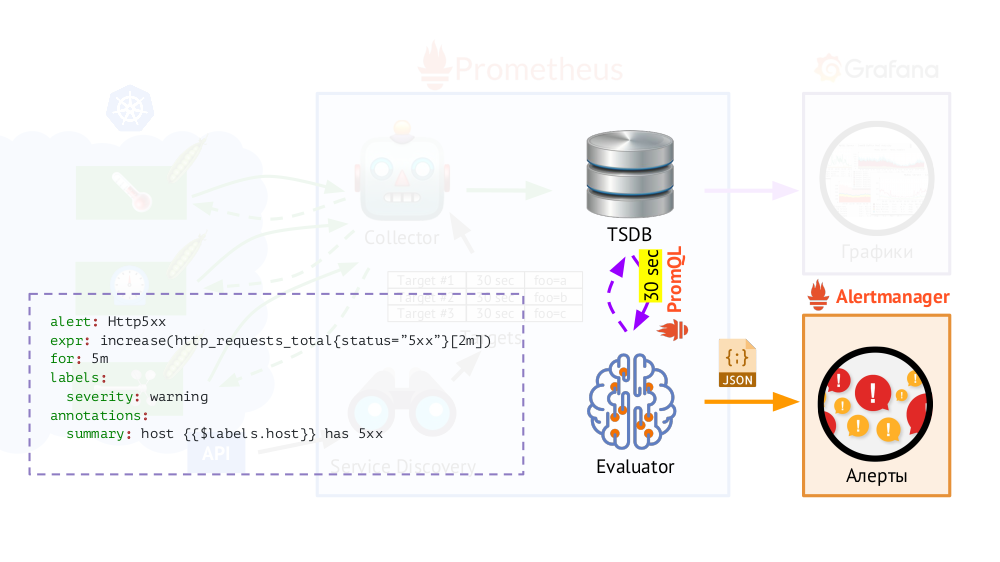
Además, Prometheus tiene un
Evaluador , que, utilizando el mismo PromQL, puede acceder a TSDB con la frecuencia especificada. ¿Por qué es esto? Ejemplo: comience a enviar alertas en los casos en que, según las métricas disponibles, haya un error 500 en el servidor web en los últimos 5 minutos. Además de las etiquetas que estaban en la solicitud, Evaluator agrega etiquetas adicionales a los datos para las alertas (según lo configuramos), después de lo cual se envían en formato JSON a otro componente de Prometheus:
Alertmanager .
Prometheus periódicamente (una vez cada 30 segundos) envía alertas a Alertmanager, que las deduplica (después de recibir la primera alerta, la enviará y las siguientes no se enviarán nuevamente).
 Nota : No utilizamos Alertmanager en casa, sino que enviamos datos de Prometheus directamente a nuestro sistema, con el que trabajan nuestros asistentes, pero esto no importa en el esquema general.
Nota : No utilizamos Alertmanager en casa, sino que enviamos datos de Prometheus directamente a nuestro sistema, con el que trabajan nuestros asistentes, pero esto no importa en el esquema general.Prometeo en Kubernetes: el panorama general
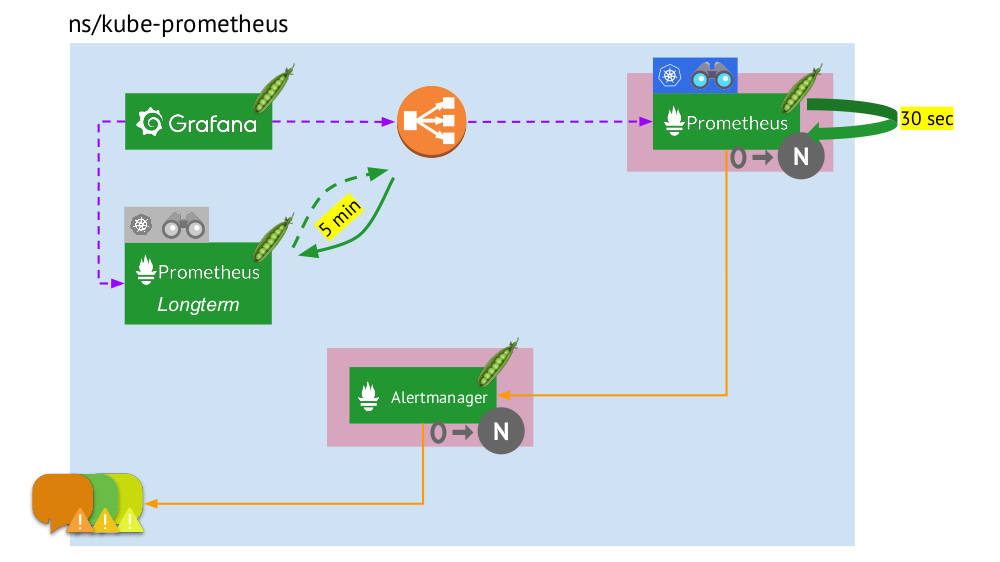
Veamos ahora cómo funciona todo este paquete Prometheus dentro de Kubernetes:
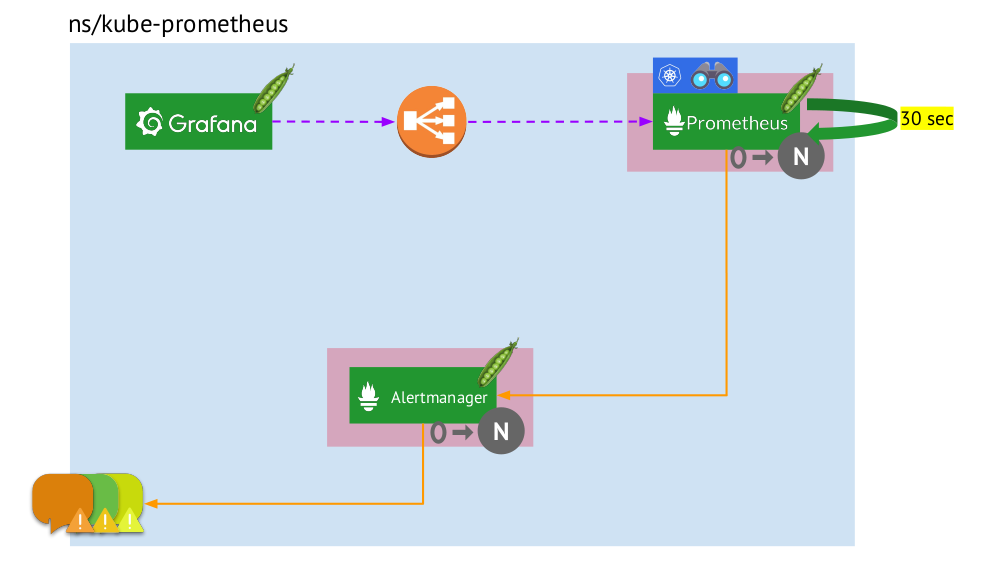
- Kubernetes tiene su propio espacio de nombres para Prometeo (tenemos
kube-prometheus en la ilustración) . - Este espacio de nombres aloja el pod con la instalación de Prometheus, que cada 30 segundos recopila métricas de todos los destinos recibidos a través de Service Discovery en el clúster.
- También alberga un pod con Alertmanager, que recibe datos de Prometheus y envía alertas (por correo, Slack, PagerDuty, WeChat, integración de terceros, etc. ) .
- Prometheus se enfrenta a un equilibrador de carga, un servicio regular en Kubernetes, y Grafana accede a Prometheus a través de él. Para garantizar la tolerancia a fallos, Prometheus utiliza varios pods con instalaciones de Prometheus, cada uno de los cuales recopila todos los datos y los almacena en su TSDB. A través del equilibrador, Grafana golpea a uno de ellos.
- El número de pods con Prometheus está controlado por la configuración StatefulSet : generalmente no hacemos más de dos pods, pero puede aumentar este número. Del mismo modo, Alertmanager se implementa a través de StatefulSet, para cuya tolerancia a fallas ya se requieren al menos 3 pods (ya que se necesita un quórum para tomar decisiones sobre el envío de alertas).
¿Qué falta aquí?
Federación para Prometeo
Cuando los datos se recopilan cada 30 (o 60) segundos, el lugar para almacenarlos termina muy rápidamente y, lo que es peor, requiere muchos recursos informáticos (al recibir y procesar una cantidad tan grande de puntos de TSDB). Pero queremos almacenar y tener la capacidad de descargar información para
grandes intervalos de tiempo . ¿Cómo lograr esto?
Es suficiente agregar
una instalación más de Prometheus (lo llamamos a
largo plazo ) al esquema general, en el que Service Discovery está deshabilitado, y en la tabla de objetivos hay el único registro estático que conduce al Prometheus
principal (
main ).
Esto es posible gracias a la federación : Prometheus le permite devolver los últimos valores de todas las métricas en una sola consulta. Por lo tanto, la primera instalación de Prometheus todavía funciona (accede cada 60 o, por ejemplo, 30 segundos) a todos los objetivos en el clúster de Kubernetes, y la segunda, una vez cada 5 minutos, recibe datos del primero y los almacena para poder ver los datos durante un período prolongado ( pero sin detalles profundos).
 La segunda instalación de Prometheus no necesita Service Discovery, y la tabla de objetivos constará de una línea
La segunda instalación de Prometheus no necesita Service Discovery, y la tabla de objetivos constará de una línea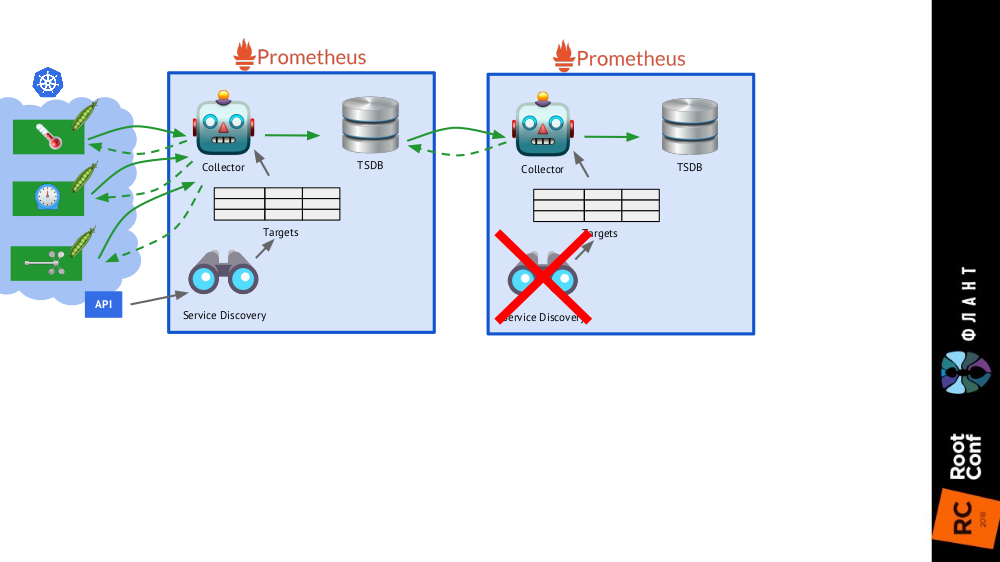 La imagen completa con instalaciones de Prometheus de dos tipos: principal (superior) y a largo plazo
La imagen completa con instalaciones de Prometheus de dos tipos: principal (superior) y a largo plazoEl toque final es
conectar Grafana a las instalaciones de Prometheus y crear paneles de una manera especial para que pueda cambiar entre las fuentes de datos (
principal o a
largo plazo ). Para hacer esto, utilizando el motor de plantillas, sustituya la variable
$prometheus lugar de la fuente de datos en todos los paneles.
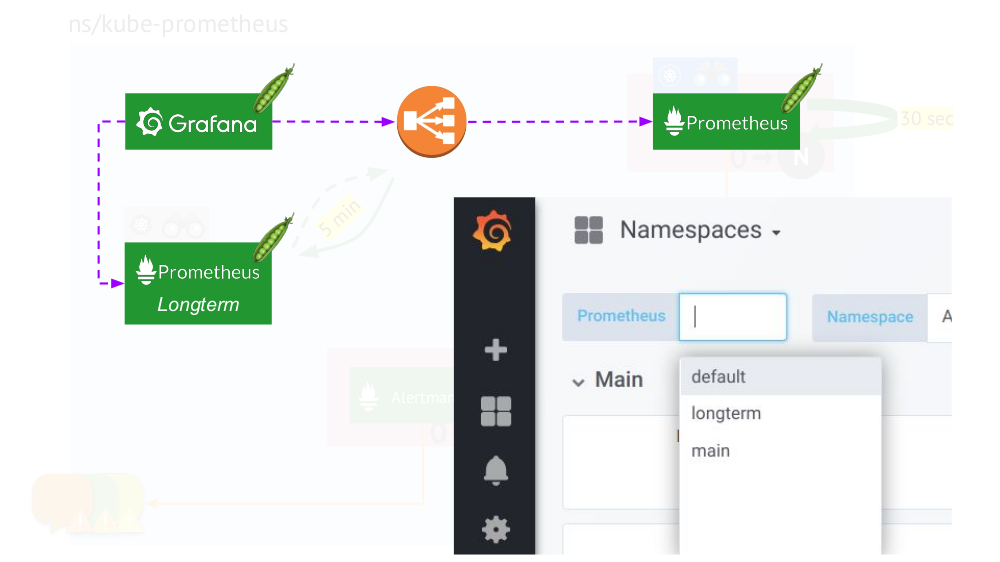
¿Qué más es importante en los gráficos?
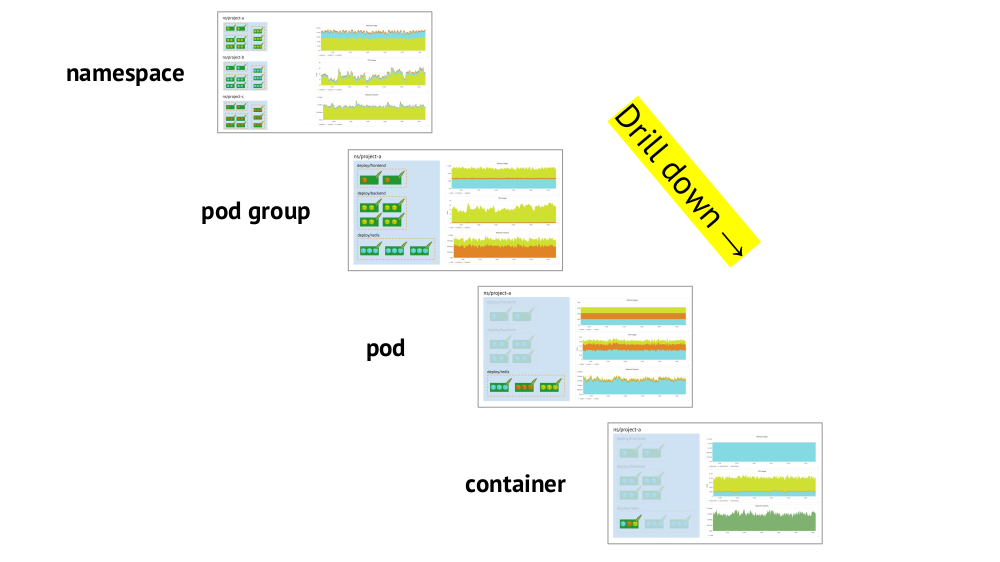
Dos puntos clave a considerar al organizar los horarios son el soporte para las primitivas de Kubernetes y la capacidad de
profundizar rápidamente desde la imagen general (o una "vista" inferior) a un servicio específico y viceversa.
Ya se ha mencionado el soporte para primitivas (espacios de nombres, pods, etc.): esta es una condición necesaria en principio para un trabajo cómodo en las realidades de Kubernetes. Y aquí hay un ejemplo sobre profundizar:
- Observamos los gráficos del consumo de recursos por tres proyectos (es decir, tres espacios de nombres); vemos que la parte principal de la CPU (o memoria, o red, ...) recae en el proyecto A.
- Observamos los mismos gráficos, pero ya para los servicios del Proyecto A: ¿cuál de ellos consume más CPU?
- Pasamos a los gráficos del servicio deseado: ¿qué pod es "culpable"?
- Pasamos a los gráficos de la cápsula deseada: ¿qué contenedor es el "culpable"? Este es el objetivo deseado!
Resumen
- Indique con precisión qué es el monitoreo. (Deje que el "pastel de tres capas" sirva de recordatorio de esto ... ¡así como del hecho de que hornearlo de manera competente no es fácil incluso sin Kubernetes!)
- Recuerde que Kubernetes agrega detalles obligatorios: agrupación de objetivos, descubrimiento de servicios, grandes cantidades de datos, flujo de metadatos. Por otra parte:
- sí, algunos de ellos están resueltos mágicamente ("fuera de la caja") en Prometeo;
- sin embargo, queda otra parte que necesita ser monitoreada de manera independiente y cuidadosa.
Y recuerde que el
contenido es más importante que un sistema , es decir los gráficos y alertas correctos son primarios, y no Prometheus (o cualquier otro software similar) como tal.

Videos y diapositivas
Video de la actuación (aproximadamente una hora):
Presentación del informe:
PS
Otros informes en nuestro blog:
También te pueden interesar las siguientes publicaciones: