¡Saludos a la distinguida comunidad!
La repetición es la madre del aprendizaje, y comprender el análisis es una habilidad muy útil para cualquier programador, por lo que quiero volver a plantear este tema y hablar esta vez sobre el análisis de descenso recursivo (LL) sin hacer demasiado formalismo (siempre puede usarlos más adelante). volver)
Como escribe el gran D. Strogov, "comprender es simplificar". Por lo tanto, para comprender el concepto de análisis mediante el método de descenso recursivo (también conocido como análisis LL), simplificamos la tarea tanto como sea posible y escribimos manualmente un analizador de un formato similar a JSON, pero más simple (si lo desea, puede expandirlo a un analizador JSON completo si querer hacer ejercicio). Escribámoslo, tomando como base la idea de
cortar la cuerda .
En los libros clásicos y los cursos de diseño de compiladores, generalmente comienzan a explicar el tema del análisis y la interpretación, destacando varias fases:
- Análisis léxico: división del texto de origen en una serie de subcadenas (tokens o tokens)
- Análisis: construir un árbol de análisis a partir de una variedad de tokens
- Interpretación (o compilación): atravesar el árbol resultante en el orden deseado (directo o inverso) y realizar algunas acciones de interpretación o generación de código en algunos pasos de este recorrido
en realidad noporque en el proceso de análisis ya obtenemos una secuencia de pasos, que es una secuencia de visitas a los nodos del árbol, el árbol en forma explícita puede no existir en absoluto, pero aún no profundizaremos. Para aquellos que quieren profundizar, hay enlaces al final.
Ahora quiero usar un enfoque ligeramente diferente para este mismo concepto (análisis LL) y mostrar cómo se puede construir un analizador LL basado en la idea de cortar una cadena: los fragmentos se cortan de la cadena original durante el análisis, se hace más pequeño y luego se analiza expuesto el resto de la línea. Como resultado, llegamos al mismo concepto de descenso recursivo, pero de una manera ligeramente diferente de lo que generalmente se hace. Quizás este camino sea más conveniente para comprender la esencia de la idea. Y si no, entonces todavía es una oportunidad para mirar un descenso recursivo desde un ángulo diferente.
Comencemos con una tarea más simple: hay una línea con delimitadores, y quiero escribir una iteración sobre sus valores. Algo como:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
¿Cómo se puede hacer esto? La forma estándar es convertir la cadena delimitada en una matriz o lista usando String.split (en Java) o names.split (",") (en javascript), e iterar a través de la matriz ya. Pero imaginemos que no queremos o no podemos usar la conversión a una matriz (por ejemplo, bueno, de repente si programamos en el lenguaje de programación AVAJ ++, en el que no hay una estructura de datos de "matriz"). Todavía puede escanear la cadena y rastrear los delimitadores, pero tampoco usaré este método, porque hace que el código del ciclo de iteración sea engorroso y, lo más importante, va en contra del concepto que quiero mostrar. Por lo tanto, nos relacionaremos con una cadena delimitada de la misma manera que con las listas en la programación funcional. Y allí siempre definen las funciones head (obtener el primer elemento de la lista) y tail (obtener el resto de la lista). A partir de los primeros dialectos de Lisp, donde estas funciones se llamaban de manera absolutamente horrible e intuitiva: car y cdr (car = contenido del registro de direcciones, cdr = contenido del registro de decrementos. Las leyendas antiguas son profundas, sí, eheheh).
Nuestra línea es una línea delimitada. Resalta los divisores en púrpura:
Y resalte los elementos de la lista en amarillo:

Asumimos que nuestra línea es mutable (se puede cambiar) y escribimos una función:
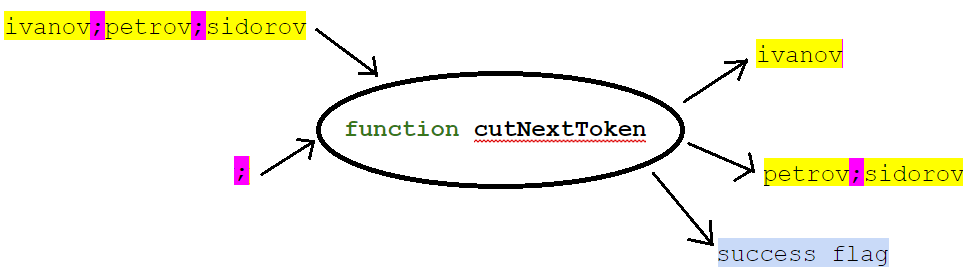
Su firma, por ejemplo, podría ser:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
En la entrada de la función, damos una lista (en forma de una cadena con separadores) y, de hecho, el valor del separador. En la salida, la función devuelve el primer elemento de la lista (segmento de línea al primer separador), el resto de la lista y el signo de si se devolvió el primer elemento. En este caso, el resto de la lista se coloca en la misma variable donde estaba la lista original.
Como resultado, tuvimos la oportunidad de escribir así:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
Salidas como se esperaba:
ivanov
petrov
sidorov
Lo hicimos sin conversión a ArrayList, pero estropeamos la variable de nombres, y ahora tiene una cadena vacía. Todavía no parece muy útil, como si cambiaran el punzón por jabón. Pero vamos más allá. Allí veremos por qué fue necesario y adónde nos llevará.
Ahora analicemos algo más interesante: una lista de pares clave-valor. Esta también es una tarea muy común.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
Conclusión
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
También esperado. Y lo mismo se puede lograr con String.split, sin cortar las líneas.
Pero digamos que ahora queríamos complicar nuestro formato y pasar de un valor clave plano a un formato anidable que recuerda a JSON. Ahora queremos leer algo como esto:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
¿Qué separador dividen? Si es una coma, entonces en una de las fichas tendremos la línea
'birthdate':{'year':'1984'
Obviamente no es lo que necesitamos. Por lo tanto, debemos prestar atención a la estructura de la línea que queremos analizar.
Comienza con una llave y termina con una llave (emparejada, lo cual es importante). Dentro de estos corchetes hay una lista de pares 'clave': 'valor', cada par está separado del siguiente par por una coma. La clave y el valor están separados por dos puntos. Una clave es una cadena de letras encerradas en apóstrofes. El valor puede ser una cadena de caracteres encerrados en apóstrofes, o puede ser la misma estructura, comenzando y terminando con llaves entre pares. Llamamos a dicha estructura la palabra "objeto", como es costumbre llamarla en JSON.
Acabamos de describir informalmente la gramática de nuestro formato similar a JSON. Típicamente, las gramáticas se describen al revés, en forma formal, y la notación BNF o sus variaciones se usan para escribirlas. Pero ahora puedo prescindir de él, y veremos cómo puede "cortar" esta línea para que pueda analizarse de acuerdo con las reglas de esta gramática.
De hecho, nuestro "objeto" comienza con una llave de apertura y termina con un par que lo cierra. ¿Qué puede hacer una función que analiza dicho formato? Lo más probable, lo siguiente:
- verifique que la cadena pasada comience con una llave de apertura
- verifique que la cadena pasada termine con un par de llaves de cierre
- si ambas condiciones son verdaderas, corte los corchetes de apertura y cierre, y lo que queda, pase a la función que analiza la lista de pares 'clave': 'valor'
Nota: aparecieron las palabras "función que analiza este formato" y "función que analiza la lista de pares 'clave': 'valor'”. Tenemos dos características! Estas son las mismas funciones que en la descripción clásica del algoritmo de descenso recursivo se denominan "funciones de análisis de símbolos no terminales", y que dicen que "para cada símbolo no terminal hay una función de análisis". Lo que, de hecho, lo analiza. Podríamos nombrarlos, por ejemplo, parseJsonObject y parseJsonPairList.
También ahora debemos prestar atención a que tenemos el concepto de "par de par" además del concepto de "separador". Si para cortar una línea al siguiente separador (dos puntos entre una clave y un valor, una coma entre los pares "clave: valor"), la función cutNextToken fue suficiente para nosotros, ahora que podemos usar no solo una cadena, sino también un objeto, necesitamos función "cortar al siguiente par de paréntesis". Algo como esto:

Esta función corta un fragmento de la línea del paréntesis de apertura al par que lo cierra, dados los paréntesis, si los hay. Por supuesto, no puede limitarse a los corchetes, sino que utiliza una función similar para cortar varias estructuras de bloques que se pueden anidar: los bloques de operador comienzan ... fin, si ... fin, para ... fin y otros similares.
Dibujemos gráficamente lo que sucederá con la cadena. Color turquesa: esto significa que escaneamos la línea hacia adelante hasta el símbolo resaltado en turquesa para determinar qué debemos hacer a continuación. Violeta es "qué cortar, esto es cuando cortamos los fragmentos resaltados en violeta de la línea y continuamos analizando lo que queda de él más allá".

A modo de comparación, la salida del programa (el texto del programa se proporciona en el apéndice) que analiza esta línea:
Demostración de análisis de estructura similar a JSON
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
En cualquier momento, sabemos lo que esperamos encontrar en nuestra línea de entrada. Si ingresamos a la función parseJsonObject, entonces esperamos que el objeto nos sea pasado allí, y podemos verificar esto por la presencia de los corchetes de apertura y cierre al principio y al final. Si ingresamos la función parseJsonPairList, entonces esperamos una lista de pares "clave: valor" allí, y después de que "mordimos" la clave (antes del separador ":"), esperamos que lo siguiente que "muerdamos" sea valor Podemos ver el primer carácter del valor y sacar una conclusión sobre su tipo (si el apóstrofe, entonces el valor es del tipo "cadena", si el corchete de apertura es el valor es del tipo "objeto").
Por lo tanto, cortando fragmentos de la cadena, podemos analizarlos por el método de análisis de arriba hacia abajo (descenso recursivo). Y cuando podemos analizar, podemos analizar el formato que necesitamos. O cree su propio formato conveniente para nosotros y desmóntelo. O cree un lenguaje específico de dominio (DSL) para nuestra área específica y diseñe un intérprete para ello. Y para construirlo correctamente, sin soluciones tortuosas en regexp o máquinas de estado hechas a sí mismas que surgen para los programadores que intentan resolver algún problema que requiere análisis, pero que no poseen el material.
Aquí Felicitaciones a todos por el próximo verano y les deseo lo mejor, amor y analizadores funcionales :)
Para más lectura:
Ideológico: un par de largos pero valiosos artículos de Steve Yeegge:
Comida rica de programadorUn par de citas a partir de ahí:
Aprendes compiladores y comienzas a escribir tus propios DSL, o obtienes un mejor idioma
La primera gran fase de la canalización de compilación es el análisis
El problema del pinochoCita a partir de ahí:
Las conversiones de tipos, las conversiones de reducción y ampliación, las funciones de amigo para omitir las protecciones de clase estándar, el relleno de minilenguajes en cadenas y el análisis manual , hay docenas de formas de evitar los sistemas de tipos en Java y C ++, y los programadores los usan todo el tiempo , porque (poco saben) están intentando construir software, no hardware.
Técnico: dos artículos sobre análisis sobre la diferencia entre los enfoques LL y LR:
Análisis LL y LR desmitificadosLL y LR en contexto: por qué las herramientas de análisis son difícilesY aún más profundo en el tema: cómo escribir un intérprete Lisp en C ++
Intérprete Lisp en 90 líneas de C ++Solicitud Ejemplo de código (java) que implementa el analizador descrito en el artículo: package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) {