 Publicado por Igor Masternaya, Desarrollador Senior, Líder de la Comunidad DataArt Java
Publicado por Igor Masternaya, Desarrollador Senior, Líder de la Comunidad DataArt JavaDel 18 al 19 de mayo, JEEonf se celebró en Kiev, uno de los eventos más esperados para toda la comunidad Java de Europa del Este. DataArt se asoció con la conferencia. Los oradores de todo el mundo hablaron en cuatro etapas: Volker Simonis, Representante de SAP en
JCP y colaborador de OpenJDK, Jürgen Höller, Ingeniero Jefe Pivotal, padre del querido Spring Framework, Klaus Ibsen, creador de Apache Camel, y Hugh McKee, evangelista en Lightbend.
El horario estaba muy ocupado: en dos días más de 50 actuaciones, 45 minutos cada una. Descanso de 10 minutos y ejecutar un nuevo informe. Verá todos los videos cuando aparezcan en la red. Por lo tanto, describiré brevemente los informes que encontré más interesantes y que visité personalmente.
15 años de primavera
La conferencia fue inaugurada por Jürgen Höller. Habló sobre los 15 años (!) Historia del Spring Framework, desde las configuraciones XML "favoritas" en la versión 0.9 hasta el reactivo Spring WebFlux, que surgió de proyectos de investigación influenciados por el
Manifiesto Reactivo . Jürgen habló sobre la coexistencia de Spring MVC y Spring WebFlux en Spring WEB, explicó por qué decidieron no integrarlos en uno. El punto es que la abstracción principal de Spring MVC es Servlet API 3.0 y bloqueo de E / S, mientras que Spring WebFlux usa la abstracción de flujos reactivos y E / S sin bloqueo. Puede ejecutar su servicio en SpringWebFlux en cualquier servidor que admita IO sin bloqueo: Netty, nuevas versiones de Tomcat (> 8.5), Jetty. Crear controladores reactivos de WebFlux no es muy diferente de crearlos usando Spring MVC, pero todavía hay diferencias. Al procesar una solicitud de usuario, el controlador reactivo no la procesa en el sentido habitual, sino que crea una canalización para procesar la solicitud. Dispatcher llama al método controlador, que crea una canalización e inmediatamente lo proporciona como una secuencia de editor. La secuencia del editor en Reactive Spring se presenta como dos abstracciones: Flux / Mono. Flux devuelve un flujo de objetos, mientras que Mono siempre devuelve un único objeto.
Jürgen también mencionó la conveniencia de usar el estilo Java 8 al trabajar con Spring 5.0 y prometió un candidato de lanzamiento Spring 5.1 en julio de 2018 y un lanzamiento en septiembre, que admitirá Java 11 y trabajará en el ajuste fino de las nuevas características de Spring 5.0
Integración Python / Java
Hubo muchos informes y fue difícil elegir el más interesante en el siguiente espacio. Las descripciones fueron igualmente interesantes, así que confié en mis instintos y decidí escuchar a Tamas Rozman, el vicepresidente de BlackRock de Hungría. Pero sería mejor si volviera a escuchar sobre Sourcing de eventos y CQRS. A juzgar por la descripción, la compañía se dedica a la ciencia de datos para un gran fondo de inversión. El propósito del informe era mostrar cómo crearon un sistema escalable y estable, igualmente conveniente para los analistas de datos con su Python, y para los desarrolladores de Java del sistema principal. Sin embargo, me pareció dudoso que el sistema construido realmente resultara conveniente. Para hacerse amigo de Python y Java, a los ingenieros de BlackRock se les ocurrió la idea de iniciar un intérprete de Python como un proceso desde una aplicación Java. Llegaron a esto por varias razones:
- Jython (Python en la JVM) no se ajustaba debido a la base de código obsoleta 2.7 frente a CPython 3.6.
- Consideraron la opción de reescribir la lógica de Data Science en Java como un proceso demasiado largo.
- Apache Spark decidió no tomarlo porque, como explicó el orador, no se pueden mezclar cargas de trabajo escritas en Java y Python. Aunque no está claro por qué UDF y UDFA no encajaban [ 2 ]. Además, Spark no encajaba, porque ya tenían algún tipo de marco de trabajo, y realmente no querían presentar uno nuevo. Y resultó que tampoco tienen Big Data, y todo el procesamiento se reduce a estadísticas sobre archivos patéticos de 100 MB.
La comunicación de Java con el proceso de Python se organizó utilizando archivos asignados en memoria (un archivo se usa como un archivo de datos de entrada) y comandos (el segundo archivo es la salida del proceso de Python). Por lo tanto, la comunicación era algo en forma de:
Java: calcExr | 1 + javaFunc (sqrt (36))
Python: 1 + javaFunct | 6
Java: 1 + éxito | 64
Python: éxito | 65
Los principales problemas de dicha integración, Tamas llama la sobrecarga durante la serialización y deserialización de los parámetros de entrada / salida.

Java 10 App CDS
Después de una presentación sobre las complejidades de ejecutar Python, realmente quería escuchar algo profundamente técnico del mundo de Java. Así que fui al informe de Volker Simonis, en el que habló sobre la función de intercambio de datos de la clase de aplicación de
Java 10+ . En el mundo moderno basado en microservicios en Docker, la capacidad de compartir Java Codecache y Metaspace acelera el inicio de la aplicación y ahorra memoria. La imagen muestra los resultados del lanzamiento de tomates dockerizados con un archivo compartido / compartido de clases de Tomcat. Como puede ver, para el segundo proceso, algunas páginas en la memoria ya están marcadas como shared_clean, lo que significa que el proceso actual y al menos un proceso (el segundo tomcat en ejecución) se refiere a ellas.

Los detalles sobre cómo jugar con CDS en OpenJDK 10 se pueden encontrar en:
App CDS . Además de dividir las clases de aplicación entre procesos, en el futuro se planea compartir cadenas internas en el
JEP-250 .
Limitaciones clave de AppCDS:
No funciona con clases de hasta 1.5.
- No puede usar clases cargadas desde archivos (solo archivos .jar).
- No se pueden usar las clases modificadas por el cargador de clases.
- Las clases cargadas por múltiples cargadores de clases se pueden reutilizar solo una vez.
- La reescritura de código de bytes no funciona, lo que puede provocar caídas de rendimiento de hasta el 2%. JDK-8074345

Canal de procesamiento de lenguaje natural con Apache Spark
El informe sobre PNL y Apache Spark fue presentado por Vitaliy Kotlyarenko, ingeniero de Grammarly. Vitaliy mostró cómo prototipo Grammarly NLP-Jobs en Apache Zeppelin. Un ejemplo fue la construcción de una tubería simple para el modelado temático basado en el algoritmo
LDA del archivo de Internet de
rastreo común . Los resultados del modelado de temas se usaron para filtrar sitios con contenido inapropiado como un ejemplo de la función de control parental. Para crear la tubería, utilizamos los scripts Terraform y el clúster
AWS EMR Spark, que le permite implementar Spark Cluster con YARN en Amazon. Esquemáticamente, la tubería se ve así:
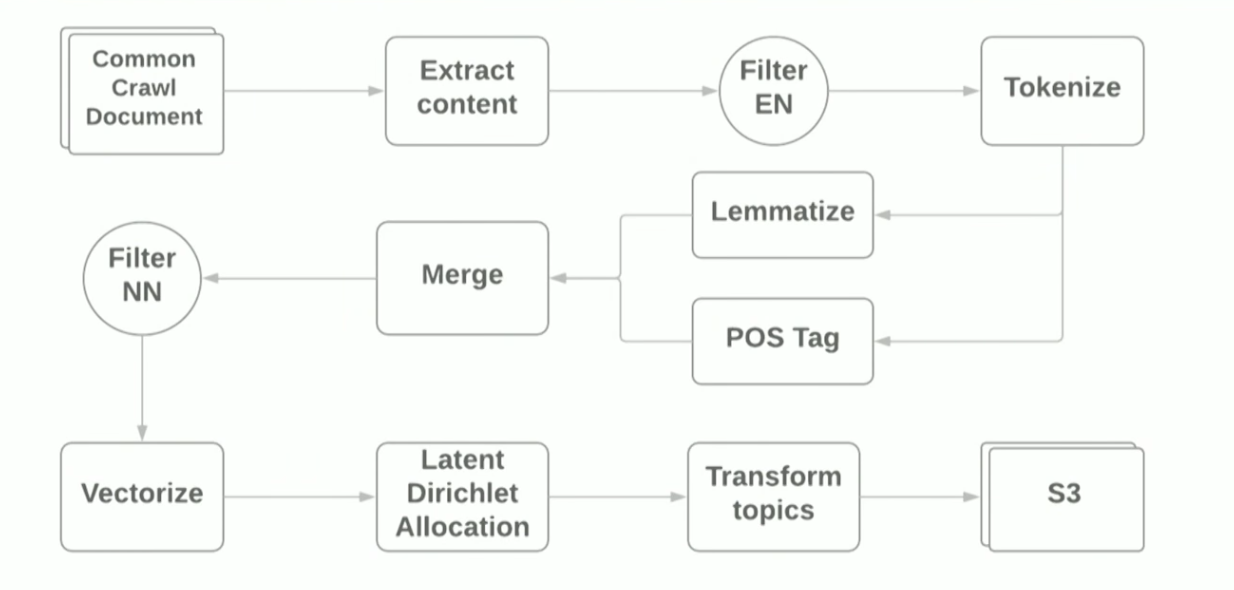
El propósito del informe era mostrar que el uso de marcos modernos para hacer un prototipo para tareas de ML es bastante simple, sin embargo, al usar bibliotecas estándar, aún se encuentra con dificultades. Por ejemplo:
- En el primer paso de leer archivos WARC usando la biblioteca HadoopInputFormat , las IllegalStateExceptions a veces fallaban debido a encabezados de archivo incorrectos, la biblioteca tuvo que ser reescrita y se omitieron los archivos incorrectos.
- Las dependencias de guayaba, la biblioteca de definición de lenguaje, chocaron con las dependencias que Spark arrastra sobre sí. Java 8 ayudó, con la ayuda de la cual fue posible lanzar dependencias de guayaba en la biblioteca utilizada.
Durante la demostración, monitoreamos la ejecución del trabajo utilizando la interfaz de usuario estándar de Spark y el subsistema de monitoreo
Ganglia , que está disponible automáticamente cuando se implementa en AWS EMR. El autor se centró en la distribución de carga del servidor del mapa de calor, que muestra la distribución de carga entre los nodos en el clúster, y dio consejos generales sobre cómo optimizar el trabajo de Spark Job: aumentar el número de particiones, optimizar la serialización de datos, analizar los registros de GC. Puede leer más sobre la optimización de Spark Jobs
aquí . Los archivos de origen para la demostración se pueden encontrar en el
github del autor del informe.
Graal, Truffle, SubstrateVM y otras ventajas: ¿qué son y por qué las necesita?
Lo más esperado para mí fue un informe de Oleg Chirukhin de JUG.ru. Él le dijo cómo optimizar el código terminado usando el Grial. ¿Qué es el grial? The Grail es una marca de
Oracle Labs que combina el compilador JIT (justo a tiempo), el marco para escribir lenguajes DSL - Truffle - y el JVM especial (
SubstrateVM ) - una máquina virtual universal
de mundo cerrado para la que puede escribir en JavaScript, Ruby, Python, Java, Scala. El informe se centró en el compilador JIT y sus pruebas en producción.
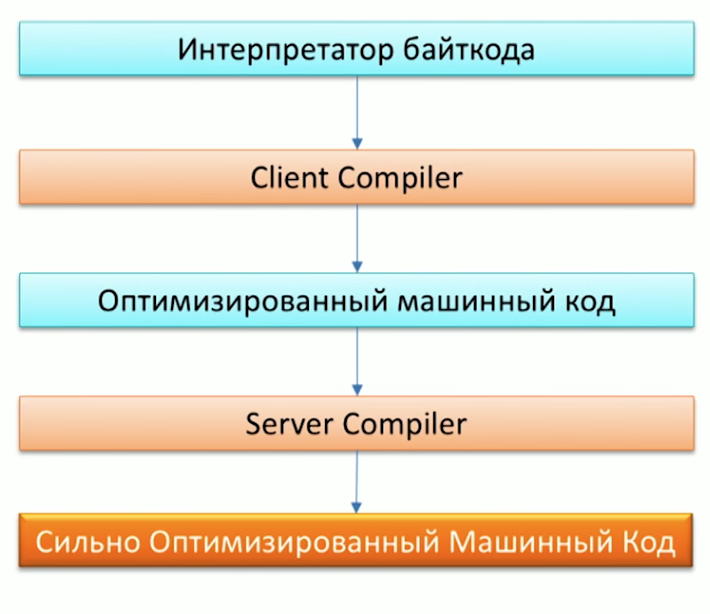
Primero, recuerde el proceso de ejecución de código por la máquina Java y tenga en cuenta que Java ya tiene dos compiladores: C1 (compilador del cliente) y C2 (compilador del servidor). Grail se puede usar como compilador C2.
Cuando se le preguntó por qué necesitábamos otro compilador, uno de los empleados de Oracle Labs, el Dr. Chris Seaton, respondió muy bien en el artículo
Comprender cómo funciona Graal . En resumen, la idea original del proyecto Graal, así como del proyecto
Metropolis , es reescribir partes del código JVM escrito en C ++ en Java. Esto permitirá en el futuro complementar convenientemente el código. Por ejemplo, una de las optimizaciones, P
Artial Escape Analysis , ya está en el Grial, pero no en el Hotspot,
porque expandir el código del Grial es mucho más fácil que el código C2 .
Eso suena genial, pero ¿cómo funcionará esto en la práctica en mi proyecto? Grial es adecuado para proyectos:
- Que ensucia mucho, creando muchos objetos pequeños.
- Escrito al estilo de Java 8, con un montón de secuencias y lambdas.
- Usando diferentes lenguajes: Ruby, Java, R.
Uno de los primeros en producción, el Grial comenzó a usarse en Twitter. Puede leer más sobre esto en una entrevista con Christian Talinger, publicada en Habré (
entrevista_1 y
entrevista_2 ). Allí, explica que al reemplazar C2 con Graal, Twitter comenzó a ahorrar alrededor del 8% de la utilización de la CPU, lo cual es bastante bueno teniendo en cuenta el tamaño de la organización.
En la conferencia, también pudimos verificar la velocidad de Graal al lanzar uno de los puntos de referencia de
Scala :
Scala DaCapo . Como resultado, en Graal, el punto de referencia pasó en ~ 7000 ms, y en una JVM normal en ~ 14000 ms. Puede ver por qué sucedió esto mirando las pruebas de gclog. El número de fallas de asignación cuando se usa Graal es significativamente menor que el de Hotspot. Sin embargo, aún no puede decir que el Grial será la solución a los problemas de rendimiento de su aplicación Java. Oleg también mostró una historia de fracaso en su informe, comparando el trabajo de
Apache Ignite bajo el Grial y sin él, no hubo un cambio notable en el rendimiento.

Diseño de microservicios tolerantes a fallas
Orkhan Gasimov leyó otro informe sobre la arquitectura de microservicios a prueba de fallas de AppsFlyer. Introdujo patrones de diseño populares para crear aplicaciones distribuidas. Es posible que conozcamos muchos de ellos, pero caminar y recordar cada uno de ellos no le hará ningún daño.
Los principales problemas de tolerancia a fallas de los servicios con los cuales los patrones descritos en el informe están llamados a combatir son: red, cargas máximas, mecanismos RPC de comunicación entre servicios.
Para resolver problemas con la red, cuando uno de los servicios ya no está disponible, necesitamos la capacidad de reemplazarlo rápidamente por otro igual. En la práctica, esto se puede lograr con varias instancias del mismo servicio y una descripción de rutas alternativas a estas instancias, que es un patrón de
Descubrimiento de servicio . Participar en los servicios de
heartbeat y registrar nuevos servicios será una instancia separada: Service Registry. Es habitual utilizar el conocido
Zookeeper o
Cónsul como Registro de Servicio. Que, a su vez, también tienen una naturaleza distribuida y soporte para la tolerancia a fallas.
Una vez resueltos los problemas con la red, pasamos al problema de las cargas máximas cuando algunos servicios están bajo carga y procesamos las solicitudes mucho más lentamente que el modo normal. Para resolverlo, puede usar el patrón de
Autoescalado . Asumirá no solo la tarea de escalar automáticamente los servicios altamente cargados, sino que también detendrá las instancias después del período de carga máxima.
El capítulo final del informe del autor fue una descripción de posibles problemas de comunicación interna entre servicios RPC. Urahan prestó especial atención a la tesis "El usuario no debe esperar un mensaje de error durante mucho tiempo". Tal situación puede surgir si su solicitud es procesada por la cadena de servicio y el problema está al final de la cadena: en consecuencia, el usuario puede esperar a que cada uno de los servicios de la cadena procese la solicitud y solo en la última etapa recibe un error. Lo peor de todo, si el servicio final está sobrecargado, y después de una larga espera, el cliente recibirá un HTTP-ERROR sin sentido: 500.
Para combatir tales situaciones, puede usar
Timeout s, sin embargo, las solicitudes que aún se pueden procesar correctamente pueden caer en el tiempo de espera. Para hacer esto, la lógica de tiempo de espera puede ser complicada y se puede agregar un valor de umbral especial para el número de errores de servicio por intervalo de tiempo. Cuando el número de errores excede el valor umbral, entendemos que el servicio está bajo carga y consideramos que no está disponible, lo que le da el tiempo necesario para hacer frente a las tareas actuales. Este enfoque describe el patrón del
disyuntor . También puede usar CircuitBreaker.html "> Circuit Beaker como una métrica adicional para el monitoreo, que le permitirá responder rápidamente a posibles problemas e identificar claramente qué cadenas de servicio los están experimentando. Para hacer esto, cada llamada de servicio debe estar envuelta en un disyuntor.
También en el informe, el autor recordó el patrón de
redundancia N-Modular , diseñado para "procesar solicitudes más rápido si es posible", y proporcionó un hermoso ejemplo de su uso para validar la dirección de un cliente. La solicitud en su sistema a través del caché de direcciones se envió de inmediato a varios proveedores de Geo Map, como resultado de lo cual ganó la respuesta más rápida.
Además de los patrones descritos, se mencionaron los siguientes:
- Patrón de ruta rápida , que se puede aplicar, por ejemplo, al almacenar en caché los resultados de la consulta. Entonces el acceso al caché es una ruta rápida.
- Patrón de Kernel de error : un patrón del mundo de Akka que implica dividir una tarea en subtareas y delegar subtareas a actores intermedios. De esta manera, se logra la flexibilidad de procesar errores de ejecución de subtareas.
- Instance Healer , que supone la existencia de un servicio especial: un supervisor que administra otros servicios y responde a los cambios en su estado. Por ejemplo, en caso de errores en el servicio, el supervisor puede reiniciar el servicio problemático.

Abastecimiento de eventos en clúster y CQRS con Akka y Java
El último informe que quiero llamar su atención fue leído por uno de los evangelistas y arquitectos de Lightbend, Hugh McKee. Lightbend (anteriormente Typesafe) es algo así como Oracle, pero para el lenguaje Scala. La compañía también está desarrollando activamente el marco
Akka.io. En un informe, Hugh habló sobre la implementación del popular
enfoque CQRS (Comandos de Responsabilidad de Consulta de Comando / SEGREGACIÓN) en el marco de Akka. Esquemáticamente, la arquitectura del sistema CQRS se ve así:
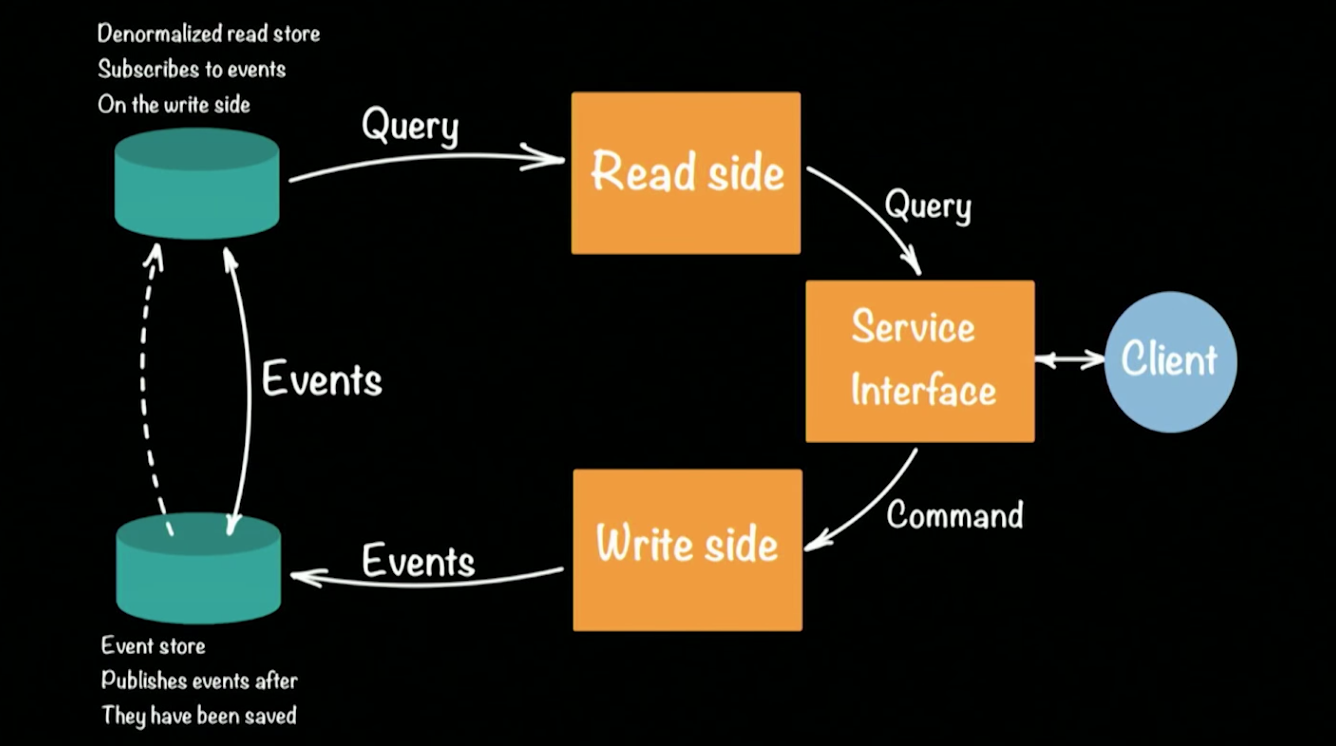
Hugh tomó un prototipo de banco como ejemplo de un sistema de trabajo. Un cliente en la arquitectura CQRS realiza dos operaciones: consulta, comando. Cada equipo (por ejemplo, una transacción bancaria que transfiere dinero de una cuenta a otra) genera un evento (un hecho consumado) que se registrará en EventStore (por ejemplo: Cassandra). La agregación de la cadena (depositar dinero en una cuenta, transferir de una cuenta a otra, retirar en un cajero automático) de eventos forma el estado actual del cliente, su saldo de dinero en la cuenta. Las solicitudes para el estado actual van a un repositorio separado, una instantánea del repositorio de eventos, ya que no tiene sentido mantener un historial completo de una cuenta bancaria. Es suficiente actualizar periódicamente el estado emitido para cada usuario.
Este enfoque permite la recuperación automática cuando se producen errores: para esto necesitamos obtener el último reparto del estado del usuario y aplicarle todos los eventos que ocurrieron antes de que ocurriera el error. Debido a la presencia de dos almacenes, la arquitectura CQRS tolera bien las cargas pico (picos) emergentes. Una gran cantidad de eventos cargará el Almacén de eventos, pero no afectará al Almacén de lectura, y los usuarios aún podrán responder consultas a la base de datos.
Volvamos a la creación de prototipos del sistema bancario en Akka y CQRS. Cada cliente del banco / cuenta / posible equipo en el sistema estará representado por un (!)
Actor . Un banco grande puede soportar cientos de miles de cuentas, y esto no será un problema para Akka. El marco listo para usar admite la agrupación en clúster y se puede ejecutar en cientos de JVM. Si una de las máquinas en el clúster falla, Akka proporciona mecanismos especiales que responden automáticamente a tales situaciones: en nuestro caso, el actor del cliente se puede recrear nuevamente en cualquier máquina disponible en el clúster, y su estado se volverá a leer desde el repositorio.
No se crea un hilo separado para un actor; esto permite admitir decenas de miles de actores dentro de una sola JVM. Al mismo tiempo, el actor garantiza que cada solicitud se procesará por separado (!) En el orden de recepción de las solicitudes. Esta garantía elimina automáticamente las posibles condiciones de carrera al procesar las solicitudes. Puede comprender el prototipo del sistema con más detalle abriendo su código utilizando los enlaces en GitHub. Cada subproyecto muestra la implementación de las etapas más complejas de la construcción de un prototipo:
avispas
Los registros de todos los informes aparecerán en línea en unas pocas semanas. Espero que este artículo te ayude a determinar el orden de visualización, especialmente porque creo que vale la pena ver las actuaciones.