Los DBMS en columnas se desarrollaron activamente en los años cero, en el momento en que han encontrado su nicho y prácticamente no compiten con los sistemas tradicionales en minúsculas. Debajo del corte, el autor comprende si es posible una solución universal y qué tan práctica es.
"Hay progreso en todo ... no tengas miedo de que te llamen a la oficina y te digan:" Consultamos aquí, y mañana serás descuartizado o quemado a tu elección. "Sería una decisión difícil. Creo que muchos de nosotros lo desconcertaríamos ”.
Yaroslav Hasek. Aventuras del valiente soldado Schweik.
Antecedentes
Cuántas bases de datos existen, tanta es esta confrontación ideológica. Por curiosidad, el autor encontró un libro de J. Martin de IBM [1] en los contenedores en 1975 e inmediatamente se topó con las palabras (p. 183): "Las relaciones binarias se usan en obras [...], es decir, relaciones de solo dos dominios. Se sabe que las relaciones binarias dan la mayor flexibilidad a la base. Sin embargo, en las tareas comerciales, las relaciones de diversos grados son convenientes ". Las relaciones se entienden aquí como relaciones relacionales. Y las obras mencionadas tienen fecha de 1967 ... 1970.
Sea Sybase IQ el primer DBMS de columna utilizado industrialmente, pero al menos a nivel de ideas, todo se habló 25 años antes.
En la actualidad, los siguientes DBMS se admiten en columnas o en un grado u otro (esto se toma principalmente
aquí ):
Comercial
Gratis y de código abierto
Las diferencias
Una relación relacional es una colección de tuplas, esencialmente una tabla bidimensional. En consecuencia, hay dos opciones de almacenamiento: en fila o en columna. La separación es un poco artificial, lógica. Los desarrolladores de bases de datos han dejado de planificar los
tambores y los registros de seguimiento. Es tarea de los administradores de DBMS descomponer de manera óptima los datos de DBMS en uno o varios sistemas de archivos, pero la forma en que los sistemas de archivos organizan los datos en discos físicos es conocida principalmente por los desarrolladores de sistemas de archivos.
Sería lógico dejar que el DBMS decida en qué orden almacenar los datos. Aquí estamos hablando de algunos DBMS hipotéticos que admiten ambas opciones para organizar el almacenamiento de datos y tienen la capacidad de asignar una tabla a cualquiera de ellos. No consideramos una opción bastante popular para admitir dos bases de datos: una para el trabajo, la segunda para análisis / informes. Además de los índices de columna a la Microsoft SQL Server. No porque sea malo, sino para probar la hipótesis de que hay una forma más elegante.
Desafortunadamente, ningún DBMS hipotético puede elegir la mejor manera de almacenar datos. Porque no comprende cómo vamos a utilizar estos datos. Y sin esto, es imposible hacer una elección, aunque es muy importante.
La calidad más valiosa de un DBMS es la capacidad de procesar rápidamente los datos (y los requisitos de
ACID , por supuesto). La velocidad del DBMS está determinada principalmente por el número de operaciones de disco. Dos casos extremos surgen de esto:
- Los datos se cambian / agregan rápidamente, necesita tiempo para escribir. La solución obvia: una línea (tupla), si es posible, se encuentra en una página, no se puede hacer más rápido.
- Los datos cambian extremadamente raramente o no cambian en absoluto, leemos los datos muchas veces, y solo un pequeño número de columnas están involucradas a la vez. En esta situación, es lógico usar una variante de almacenamiento en columnas, luego, al leer, aumentará la cantidad mínima posible de páginas.
Pero estos son casos extremos, en la vida no todo es tan obvio.
- Si desea leer la tabla completa, desde el punto de vista del número de páginas, los datos no son importantes línea por línea o columna. Es decir, hay alguna diferencia, por supuesto, en la versión en columnas tenemos la capacidad de comprimir mejor la información, pero por el momento esto no es importante.
- Pero en términos de rendimiento, hay una diferencia porque Con la grabación línea por línea, la lectura del disco se realizará de forma más lineal. Menos unidades de disco duro avanzan lecturas notablemente más rápidas. Una lectura de archivo más predecible durante la grabación línea por línea permite que el sistema operativo (SO) use la memoria caché del disco de manera más eficiente. Esto es importante incluso para las unidades SSD, porque la carga por suposición ( lectura anticipada ) a menudo conduce al éxito.
- La actualización no siempre cambia todo el registro. Supongamos que un caso común es un cambio en dos columnas. Entonces será bueno si los datos de estas columnas estarán en una página, porque solo necesita un bloqueo de página por registro en lugar de dos. Por otro lado, si los datos se extienden a través de las páginas, esto hace posible que diferentes transacciones cambien los datos de una fila sin conflictos.
Aquí hay una mirada más cercana. Una opción hipotética es hacer que la tabla sea minúscula o columnar, el DBMS debe hacerlo en el momento de su creación. Pero para hacer esta elección, sería bueno saber, por ejemplo, cómo vamos a cambiar esta tabla. Tal vez deberías tirar una moneda?
- Supongamos que usamos una estructura de árbol (ej .: índice agrupado) para el almacenamiento. En este caso, agregar datos o incluso cambiarlos puede llevar a reequilibrar el árbol o su parte. En el almacenamiento de filas, hay (al menos un) bloqueo de escritura, que puede afectar a una parte importante de la tabla. En la versión columnar, tales historias ocurren con mucha más frecuencia, pero causan mucho menos daño porque concierne solo a una columna específica.
- Considere filtrar por índice. Supongamos que la muestra es suficientemente escasa. Entonces, la grabación línea por línea tiene preferencia, porque en este caso la proporción de información útil para leer para la compañía es mejor.
- Si la filtración proporciona un flujo más denso y solo se requiere una pequeña parte de las columnas, la versión en columnas se vuelve más barata. ¿Dónde está la división entre estos casos, cómo determinarlo?
En otras palabras, bajo ninguna circunstancia nuestro hipotético DBMS asumirá la responsabilidad de elegir entre las opciones de almacenamiento línea por línea y columna, el diseñador de la base de datos debe hacerlo.
Sin embargo, dado lo anterior, el diseñador de la base de datos también estará en una elección muy difícil. Él desconcertaría a muchos de nosotros.
Que pasa si
En esencia, las variantes de columna y línea, los casos extremos de una idea, cortan la tabla en "cintas" y almacenan los datos línea por línea dentro de cada cinta. Solo en un caso la cinta es una, en el otro la cinta degenera en una columna.
Entonces, ¿por qué no permitir opciones intermedias, si los datos de algunas columnas se unen / leen juntos, incluso si están en la misma cinta? Y si no había datos (NULL) en la cinta, entonces no es necesario almacenar nada. Al mismo tiempo, se elimina el problema del tamaño máximo de fila: puede dividir la tabla cuando existe el riesgo de que la fila no quepa en una página.
Esta idea no es tan original, el autor tuvo la oportunidad de ver la misma y aplicarla él mismo. El elemento novedoso es permitir que el diseñador de la base de datos determine cómo se dividirá su tabla en partes y de qué forma los datos irán al disco.
Lo hicimos por nosotros mismos de la siguiente manera:
- Al crear una tabla, la información sobre nuestras preferencias se pasa al procesador SQL utilizando pragmas
- Inicialmente, al crear una tabla, se supone que la fila completa se ubicará en una página del árbol B
- sin embargo, puedes usar - - #pragma page_break
para decirle al procesador SQL que las siguientes columnas se ubicarán en otra página (en otro árbol) - uso - - #pragma column_based
nos permite decir de manera concisa que las columnas que van más allá están ubicadas en su propio árbol - - - #pragma basado en filas
cancela la acción basada en columnas - por lo tanto, la tabla consta de uno o más árboles B, cuyo primer elemento clave es un campo IDENTIDAD oculto. Se cree que el orden en que se crean los registros (puede correlacionarse con el orden en que se leen los registros) también es importante y no debe descuidarse. La clave principal es un árbol separado, sin embargo, esto no se aplica al tema.
¿Cómo puede verse esto en la práctica?
Por ejemplo, así:
CREATE TABLE twomass_psc ( ra double precision, decl double precision, …
Por ejemplo,
se toma la tabla principal del atlas
2MASS , la leyenda
aquí y
aquí .
J ,
H ,
K : sub-bandas infrarrojas, tiene sentido almacenar datos en ellas juntas, ya que en la investigación se procesan juntas. Aquí,
por ejemplo :
La primera foto que apareció.
O
aquí , aún más hermoso:
Es hora de confirmar que esto tiene algún sentido práctico.
Resultados
A continuación se presenta:
- diagrama de fase (número X de la página grabada, número Y de la última registrada anteriormente) del procedimiento para escribir páginas (números lógicos) en el disco al crear una tabla en dos versiones
- en una columna, se designa como by_1
- y para una tabla cortada en 16 columnas, se designa como by_16
- columnas totales 181

Echemos un vistazo más de cerca a cómo funciona:
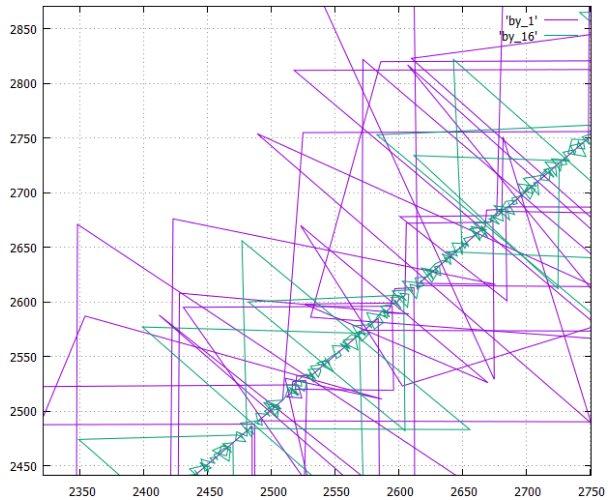
- La opción by_16 es notablemente más compacta, lo cual es lógico, lo último: la opción de línea daría solo una línea recta (con valores atípicos).
- Valores atípicos triangulares: registra páginas intermedias de árboles B.
- Se muestra el registro de datos, obviamente, la lectura se verá más o menos así.
- Se dijo anteriormente que todas las opciones registran la misma cantidad de información y que la secuencia que se debe restar es aproximadamente la misma (± eficiencia de compresión).
Pero aquí se muestra muy claramente que en una versión en columnas, los árboles crecen a diferentes velocidades debido a los detalles de los datos (en una columna a menudo se repiten y comprimen muy bien, en la otra columna, ruido desde el punto de vista del compresor). Como resultado, algunos árboles se adelantan, otros llegan tarde; al leer, obtenemos objetivamente un modo de lectura "desgarrado" que es muy desagradable para el sistema de archivos. - Por lo tanto, by_16 es mucho más preferible para la lectura que en columnas, es casi igual de cómodo que en líneas.
- Pero al mismo tiempo, la variante by_16 tiene las principales ventajas de una variante en columnas en el caso de que se requiera un pequeño número de columnas. Especialmente si no divide la mesa mecánicamente por 16 piezas, sino significativamente, después de analizar las probabilidades de su uso conjunto.
Fuentes
[1] J. Martin. Organización de bases de datos en sistemas informáticos. El mundo, 1978
[2]
Índices de columna, características de uso[3] Daniel J. Abadi, Samuel Madden, Nabil Hachem.
ColumnStores vs. RowStores: ¿Qué tan diferentes son realmente? , Actas de la Conferencia Internacional ACM SIGMOD sobre Gestión de Datos, Vancouver, BC, Canadá, junio de 2008
[4] Michael Stonebraker, Uğur Çetintemel.
"Una talla para todos": una idea cuyo tiempo ha llegado y se ha ido , 2005