El 29 de mayo,
se celebró una nueva conferencia 2018 : la conferencia anual y más grande de Yandex. Hubo tres secciones en el YaC de este año: tecnologías de marketing, ciudad inteligente y seguridad de la información. En búsqueda, publicamos uno de los informes clave de la tercera sección: de Yuri Leonovich
tracer0tong de la compañía japonesa Rakuten.
¿Cómo nos autenticamos? En nuestro caso, no hay nada extraordinario, pero quiero mencionar un método. Además de los tipos tradicionales (captcha y contraseñas de un solo uso), utilizamos Proof of Work, PoW. No, no extraemos bitcoins en las computadoras de los usuarios. Usamos PoW para ralentizar al atacante y, a veces, incluso bloquearlo por completo, lo que lo obliga a resolver una tarea muy difícil, en la que pasará mucho tiempo.
- Trabajo para Rakuten International Corporation. Quiero hablar sobre varias cosas: un poco sobre mí, sobre nuestra compañía, sobre cómo evaluar el costo de los ataques y entender si es necesario prevenir el fraude. Quiero decir cómo recopilamos nuestra prevención de fraude y qué modelos utilizamos dieron buenos resultados en la práctica, cómo funcionaron y qué se puede hacer para prevenir ataques de fraude.

Sobre mí brevemente. Trabajó en Yandex, participó en la seguridad de aplicaciones web y en Yandex también creó un sistema para prevenir ataques de fraude. Puedo desarrollar servicios distribuidos, tengo un poco de experiencia matemática que ayuda con el uso del aprendizaje automático en la práctica.
Rakuten no es muy conocido en la Federación de Rusia, pero creo que todos ustedes lo saben por dos razones. De los más de 70 de nuestros servicios en Rusia, se conoce a Rakuten Viber, y si hay fanáticos del fútbol aquí, puede saber que nuestra empresa es el patrocinador general del club de fútbol de Barcelona.
Como tenemos tantos servicios, tenemos nuestros propios sistemas de pago, nuestras propias tarjetas de crédito y muchos programas de recompensa, estamos constantemente sujetos a ataques por parte de ciberdelincuentes. Y, naturalmente, siempre tenemos una solicitud de la empresa para sistemas de protección contra fraudes.
Cuando una empresa nos pide que creemos un sistema de protección contra el fraude, siempre nos enfrentamos a un dilema. Por un lado, existe una solicitud de que haya una alta tasa de conversión, para que el usuario pueda autenticarse convenientemente con los servicios y realizar compras. Y por nuestra parte, por parte de los guardias de seguridad, quiero menos quejas, menos cuentas pirateadas. Y nosotros, por nuestra parte, queremos elevar el precio del ataque.
Si va a comprar un sistema de prevención de fraude o intenta hacerlo usted mismo, primero debe evaluar los costos.

En nuestra opinión, ¿necesitamos prevención del fraude? Nos basamos en el hecho de que tenemos algunos tipos de pérdidas financieras por fraude. Estas son pérdidas directas: el dinero que devolverá a sus clientes si los intrusos se los roban. Este es el costo de un servicio de soporte técnico que se comunicará con los usuarios y resolverá conflictos. Esta es una devolución de productos que a menudo se entregan a direcciones falsas. Y hay costos directos de desarrollar el sistema. Si creó un sistema de protección contra el fraude, lo implementó en algunos servidores, pagará la infraestructura, el desarrollo de software. Y hay un tercer aspecto muy importante del daño de los atacantes: la pérdida de ganancias. Se compone de varios componentes.
Según nuestros cálculos, hay un parámetro muy importante: el valor de por vida, LTV, es decir, el dinero que el usuario gasta en nuestros servicios se reduce significativamente. Porque en la mitad de los casos de fraude, los usuarios simplemente dejan su servicio y no regresan.
También pagamos dinero por publicidad, y si el usuario se va, se pierden. Este es el costo de adquisición del cliente, CAC. Y si tenemos muchos usuarios automatizados que no son personas reales, tenemos usuarios activos mensuales falsos, cifras de MAU, que también afectan al negocio.
Miremos desde el otro lado, desde los atacantes.
Algunos oradores dijeron que los atacantes usan activamente botnets. Pero no importa qué método usen, todavía necesitan invertir dinero, pagar el ataque, también gastan algo de dinero. Nuestra tarea, cuando creamos un sistema de prevención de fraude, es encontrar un equilibrio tal que el atacante gaste demasiado dinero y gastemos menos. Esto hace que un ataque contra nosotros no sea rentable, y los atacantes simplemente se van para romper otro servicio.

Para nuestros servicios de daños, dividimos los ataques en cuatro tipos. Esto está dirigido cuando se intenta hackear una cuenta, una cuenta. Ataques de un usuario o un pequeño grupo de personas. O ataques que son más peligrosos para nosotros, masivos y no dirigidos, cuando los atacantes atacan muchas cuentas, tarjetas de crédito, números de teléfono, etc.

Te diré lo que sucede, cómo nos atacan. El principal tipo de ataque más obvio que todos conocen es el descifrado de contraseñas. En nuestro caso, los atacantes están tratando de resolver los números de teléfono, tratando de validar los números de las tarjetas de crédito. Alguna variedad está presente.
Registro masivo de cuentas, para nosotros es obviamente perjudicial. Daré un ejemplo más tarde.
¿Qué se graba? Las cuentas falsas, algunos productos inexistentes, están tratando de enviar spam en los mensajes de comentarios. Creo que esto es relevante y similar para muchas empresas comerciales.
Todavía hay problemas que no son obvios para el comercio electrónico, pero sí para Yandex: ataques al presupuesto publicitario, fraude de clics. Bueno, o simplemente el robo de datos personales.

Daré un ejemplo. Tuvimos un ataque bastante interesante en un servicio que vende libros electrónicos, había una oportunidad para que cualquier usuario se registrara y comenzara a vender su trabajo electrónico, una oportunidad para apoyar a escritores novatos.
El atacante registró una cuenta maestra legal y varios miles de cuentas falsas de súbditos. Y generó un libro falso, solo a partir de oraciones aleatorias, no tenía sentido. Lo puso en el mercado, y teníamos una compañía de marketing, cada minion tenía, condicionalmente, 1 dólar, que podía gastar en un libro. Y este libro falso cuesta $ 1.
Se organizó una redada de secuaces: cuentas falsas. Todos compraron este libro, el libro saltó en las calificaciones, se convirtió en un éxito de ventas, un atacante elevó el precio a $ 10 condicional. Y desde que el libro se convirtió en un éxito de ventas, la gente común comenzó a comprarlo, y nos llegaron quejas de que estábamos vendiendo algunos productos de baja calidad, un libro con un conjunto de palabras sin sentido en su interior. El atacante recibió una ganancia.
No hay noveno punto; luego fue arrestado por la policía. Entonces la ganancia no fue para el futuro.
El objetivo principal de todos los atacantes en nuestro caso es gastar la menor cantidad de dinero posible y tomar la mayor cantidad posible de la nuestra.

Hay atacantes, una persona que simplemente está tratando de eludir la lógica empresarial. Pero noto que no consideramos tales ataques una prioridad, porque en términos de la proporción del número de cuentas pirateadas y dinero robado, conllevan un bajo riesgo para nosotros. Pero el principal problema para nosotros son las botnets.

Estos son sistemas distribuidos masivos, atacan nuestros servicios desde todo el planeta, desde diferentes continentes, pero tienen algunas características que hacen que sea más fácil tratar con ellos. Como en cualquier sistema distribuido grande, los nodos de botnet realizan más o menos las mismas tareas.
Otra cosa importante: ahora, como señalaron muchos colegas, las botnets se distribuyen en todo tipo de dispositivos inteligentes, enrutadores domésticos, altavoces inteligentes, etc. Pero estos dispositivos tienen especificaciones de hardware bajas y no pueden ejecutar scripts complejos.
Por otro lado, para un atacante, alquilar una botnet para DDoS simple es bastante barato, y también requiere buscar contraseñas para las cuentas. Pero si necesita implementar algún tipo de lógica de negocios específicamente para su aplicación o servicio, el desarrollo y soporte de una botnet se vuelve muy costoso. Por lo general, un atacante simplemente alquila parte de una botnet terminada.
Siempre asocio un ataque de botnet con el desfile de Pikachu en Yokohama. Tenemos el 95% del tráfico malicioso proveniente de botnets.
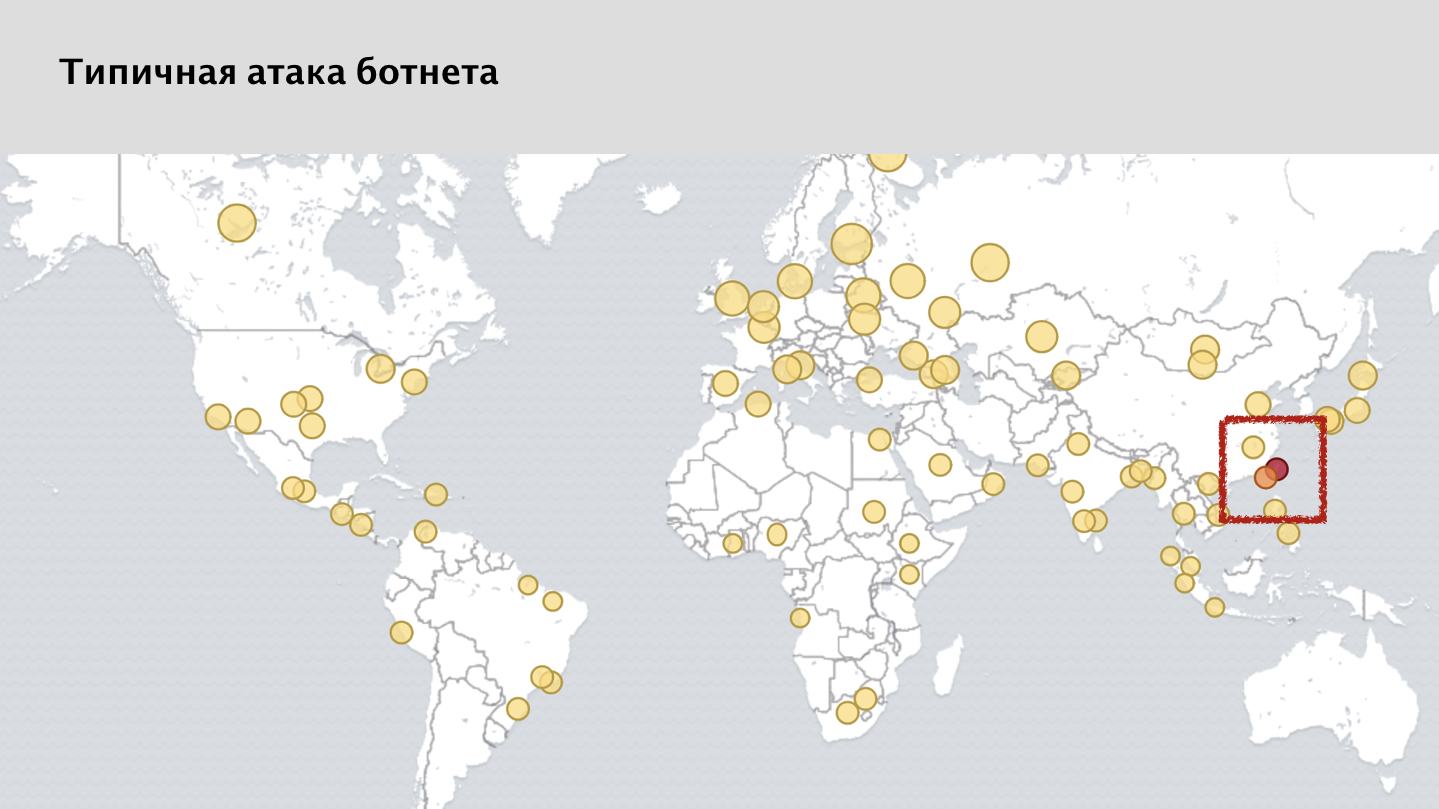
Si mira la captura de pantalla de nuestro sistema de monitoreo, verá muchos puntos amarillos: estas son solicitudes bloqueadas de varios nodos. Y aquí, una persona atenta puede notar que dije que el ataque se distribuye uniformemente por todo el mundo. Pero hay una anomalía clara en el mapa, una mancha roja en el área de Taiwán. Este es un caso bastante curioso.
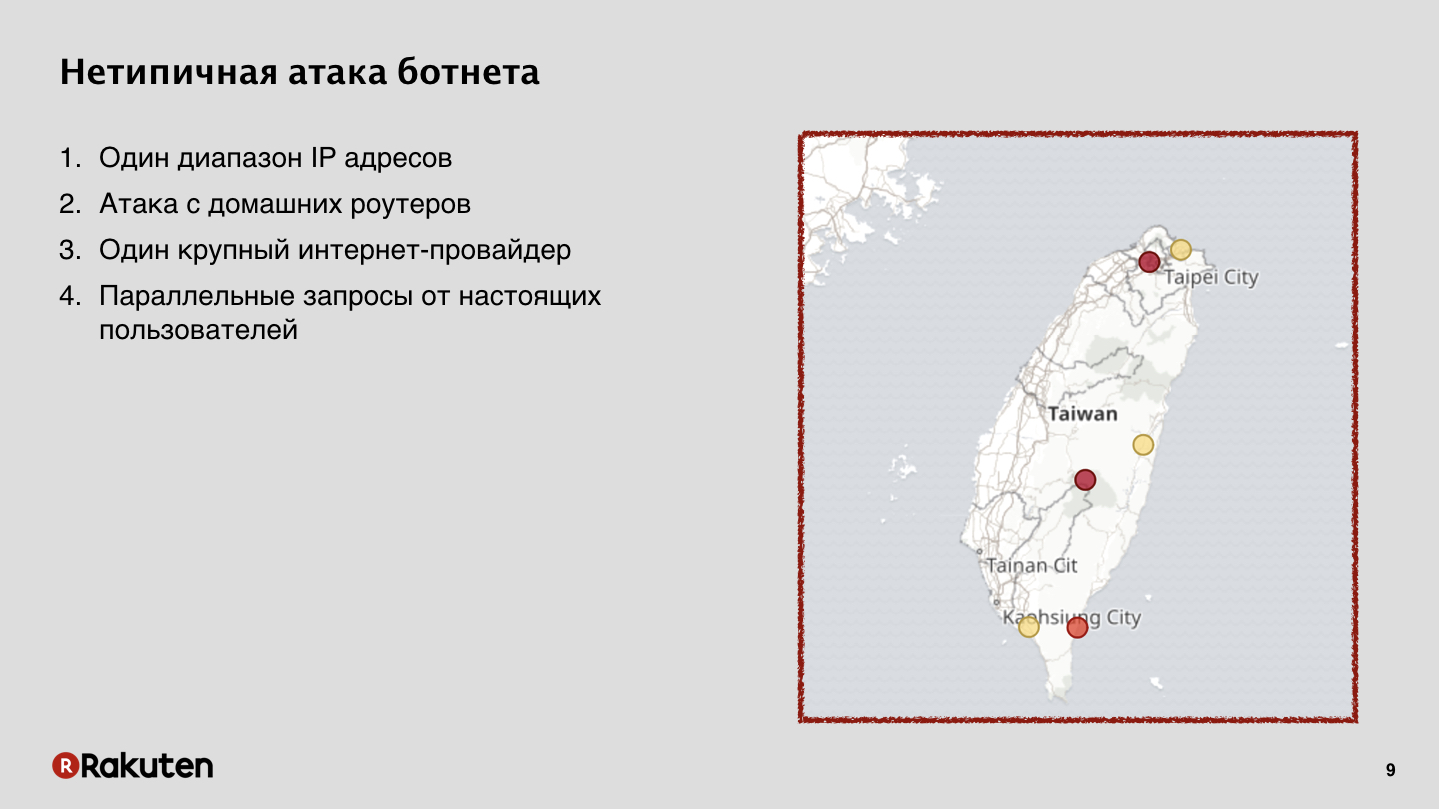
Este ataque vino de enrutadores domésticos. En Taiwán, un importante proveedor de servicios de Internet fue pirateado, lo que proporcionó Internet a la mayoría de los habitantes de la isla. Y para nosotros fue un problema muy grande, relacionado con el hecho de que muchos usuarios legales al mismo tiempo que ocurrió el ataque, acudieron y trabajaron con nuestros servicios desde las mismas direcciones IP. Detuvimos con éxito este ataque, pero fue muy difícil.
Si hablamos de alcance, sobre la superficie, sobre lo que protegemos. Si tiene un pequeño sitio web de comercio electrónico o un pequeño servicio regional, no tiene problemas particulares. Tiene un servidor, quizás varias, o máquinas virtuales en la nube. Bueno, usuarios, malos, buenos, que vienen a ti. No hay ningún problema particular que proteger.
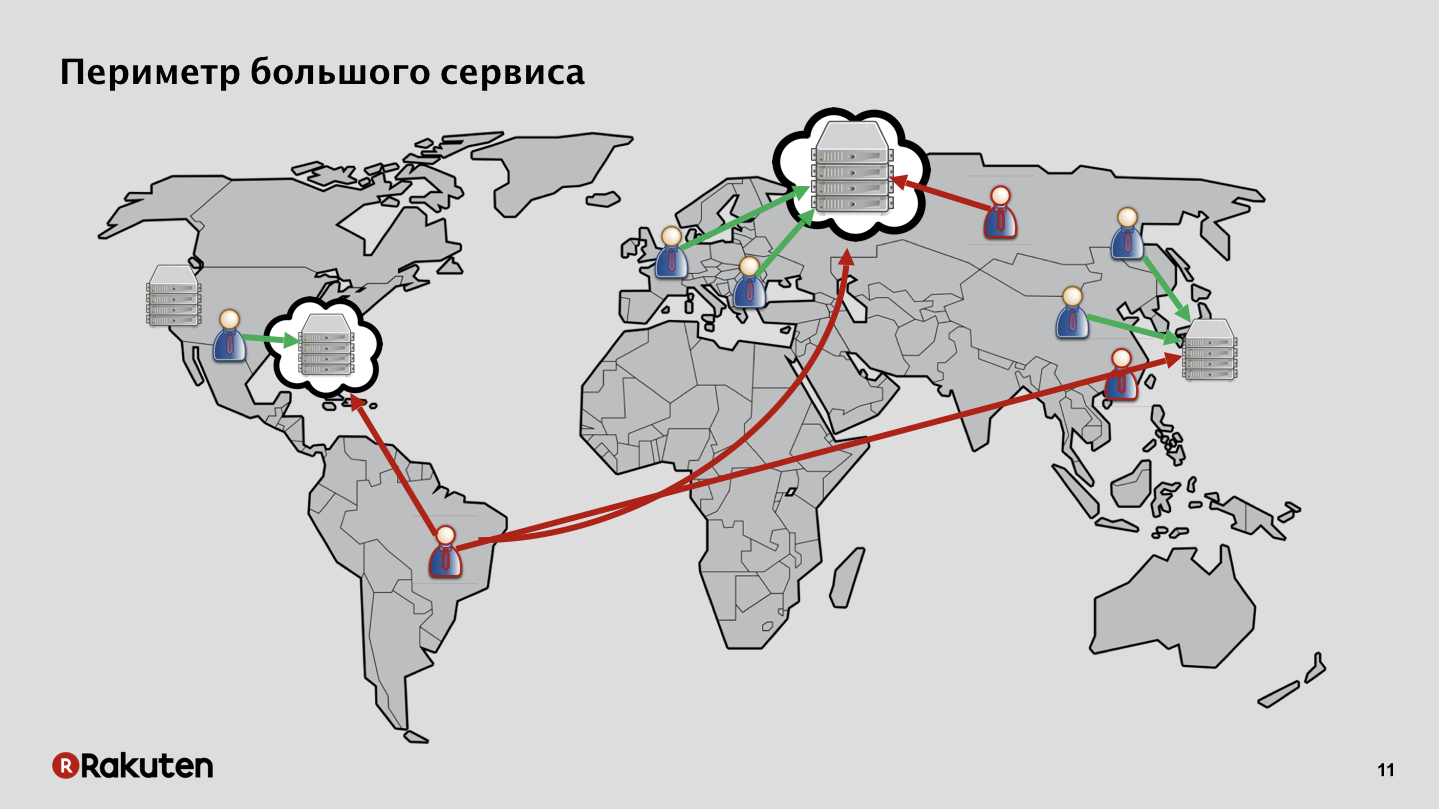
En nuestro caso, todo es más complicado, la superficie de ataque es enorme. Tenemos servicios desplegados en nuestros propios centros de datos, en Europa, en el sudeste asiático, en los Estados Unidos. También tenemos usuarios en diferentes continentes, tanto buenos como malos. Además, algunos servicios se implementan en la infraestructura de la nube, y no en la nuestra.
Con tantos servicios y una infraestructura tan extensa, es muy difícil de defender. Además, muchos de nuestros servicios admiten varios tipos de aplicaciones e interfaces de cliente. Por ejemplo, tenemos un servicio de televisión Rakuten que funciona en televisores inteligentes, y la protección es completamente especial para ello.

Para resumir el problema, una gran cantidad de usuarios circulan en su sistema, como las personas en una tienda en la intersección de Shibuya. Y entre tanta gente, es necesario identificar y atrapar a los atacantes. Al mismo tiempo, hay muchas puertas en su tienda y hay aún más personas.
Entonces, ¿de qué y cómo ensamblamos nuestro sistema?
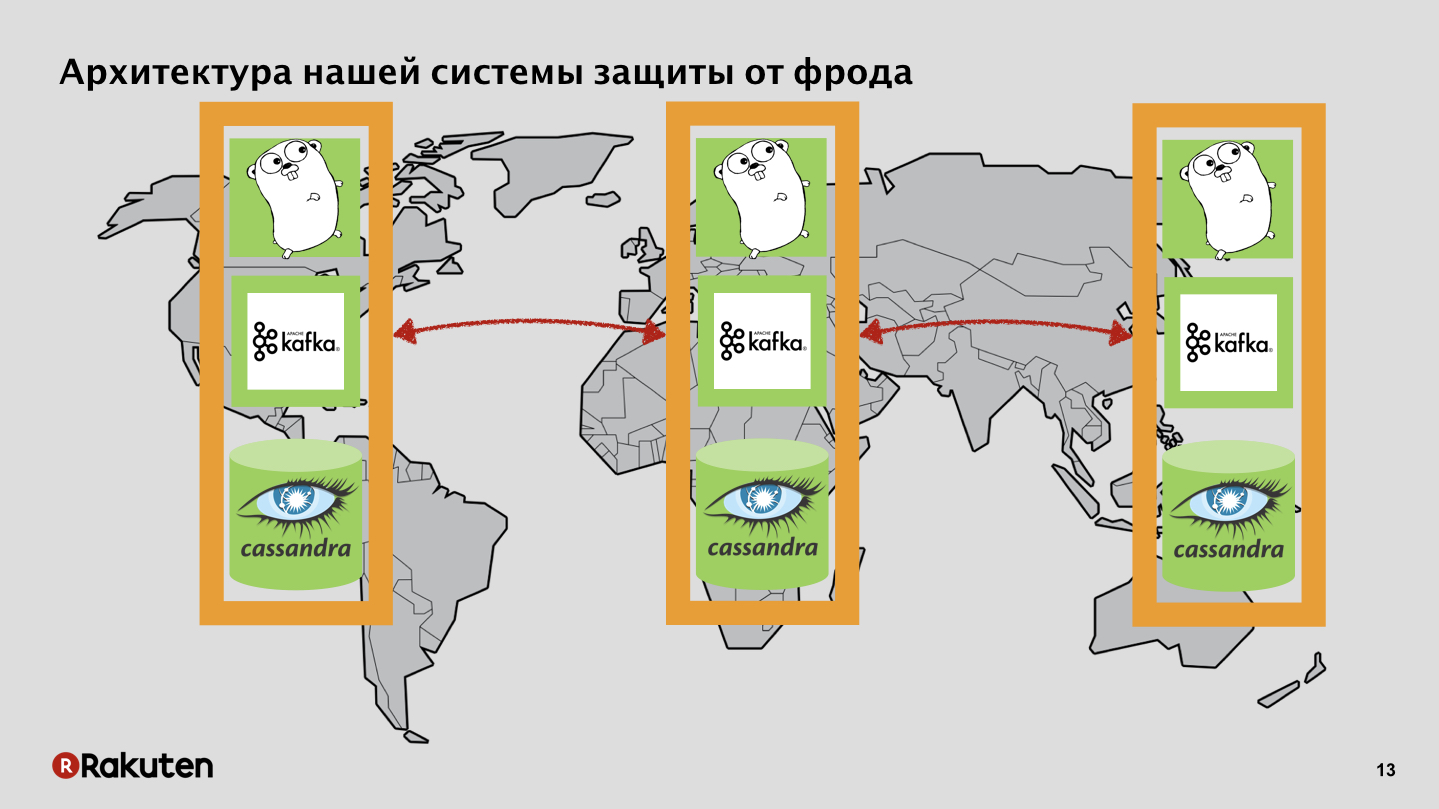
Logramos usar solo componentes de código abierto, era lo suficientemente barato. Usó el poder de muchos "gophers". Una parte significativa del software fue escrita en el idioma Golang. Se utilizan colas de mensajes y bases de datos. ¿Por qué necesitamos esto? Teníamos dos objetivos: recopilar datos sobre el comportamiento del usuario y calcular la reputación, tomar algunas medidas para reconocer si un usuario es bueno o malo.
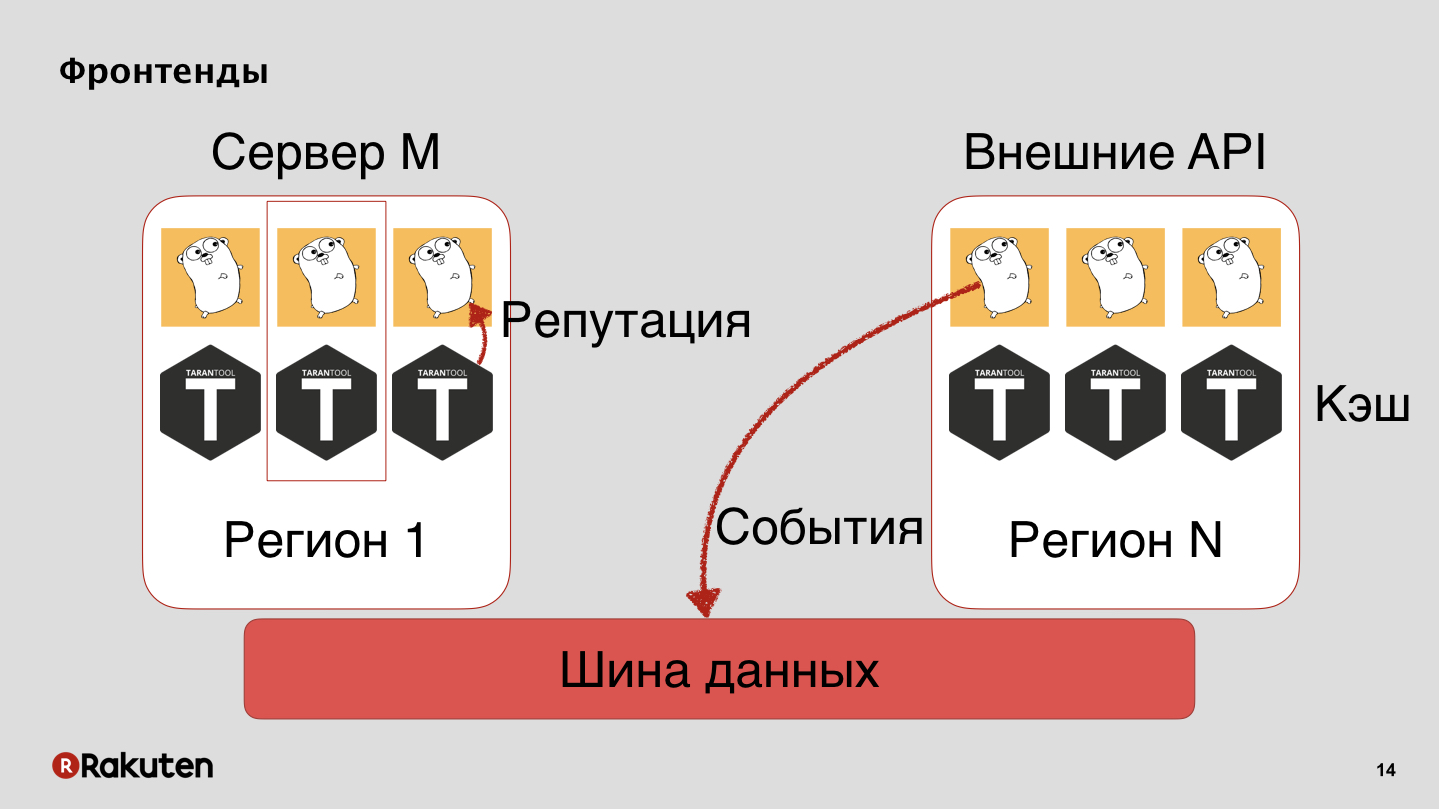
Tenemos muchos niveles en el sistema, utilizamos las interfaces escritas en Golang y Tarantool como base de almacenamiento en caché. Nuestro sistema se implementa en todas las regiones donde se encuentran nuestros negocios. Transmitimos eventos a través del bus de datos, y de él obtenemos reputación.
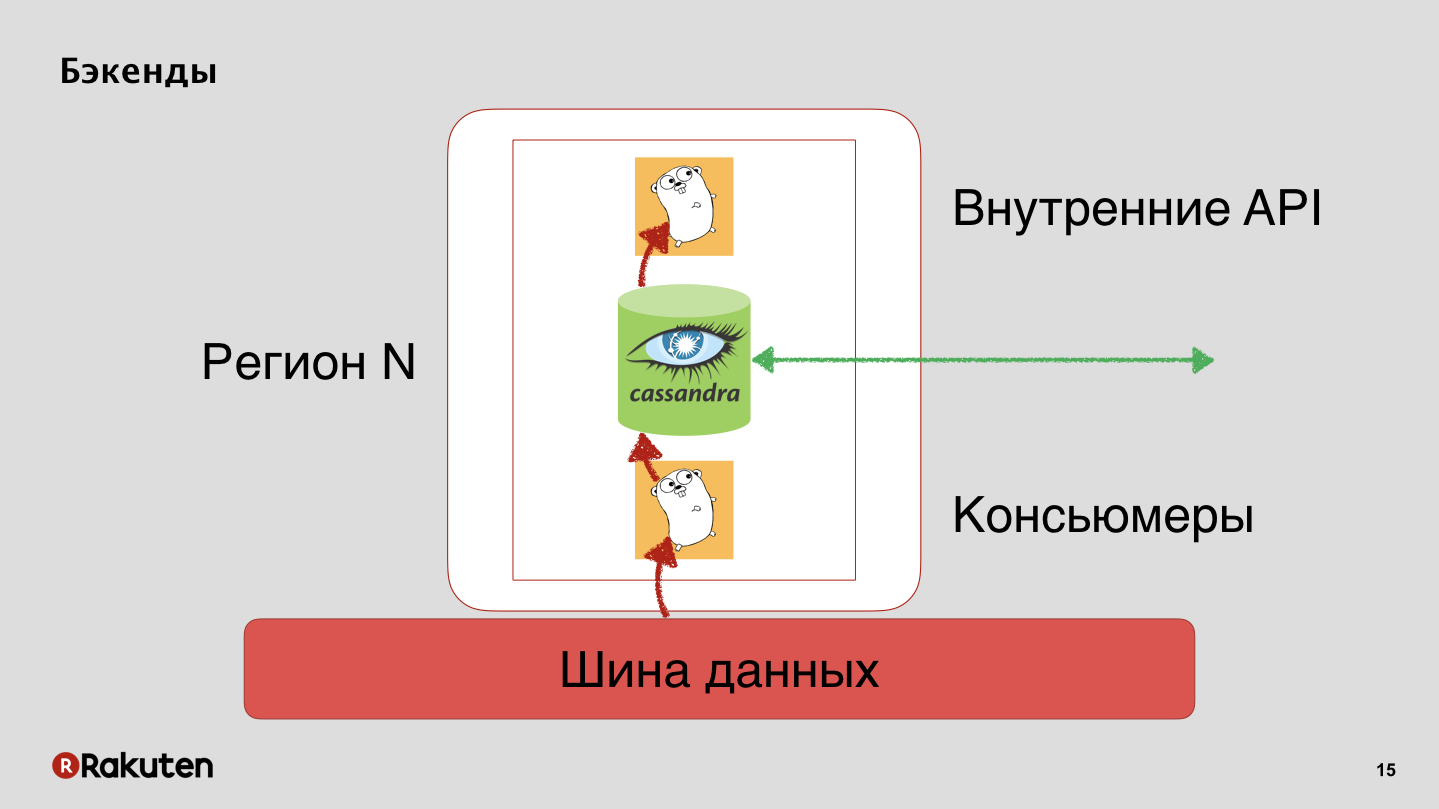
Tenemos backends que también replican el estado de reputación del usuario con Cassandra.
Bus de datos, nada secreto, Apache Kafka.
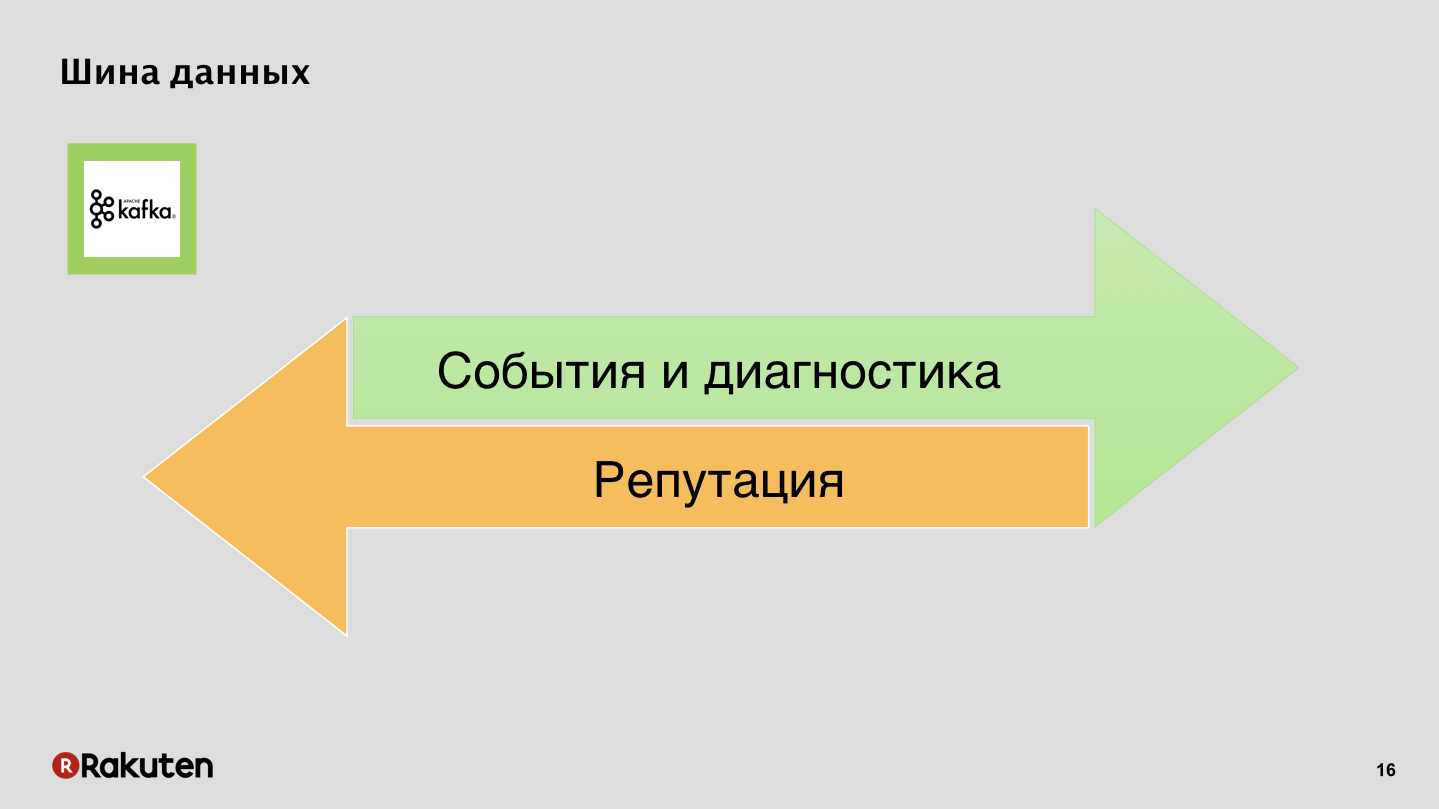
Eventos y registros en una dirección, reputación en la otra.
Y, naturalmente, el sistema tiene un cerebro que piensa si el usuario es malo o bueno, si la actividad es mala o buena. El cerebro está construido sobre Apache Storm, y la parte divertida es lo que sucede adentro.
Pero primero, le diré cómo recopilamos datos y cómo bloquear intrusos.
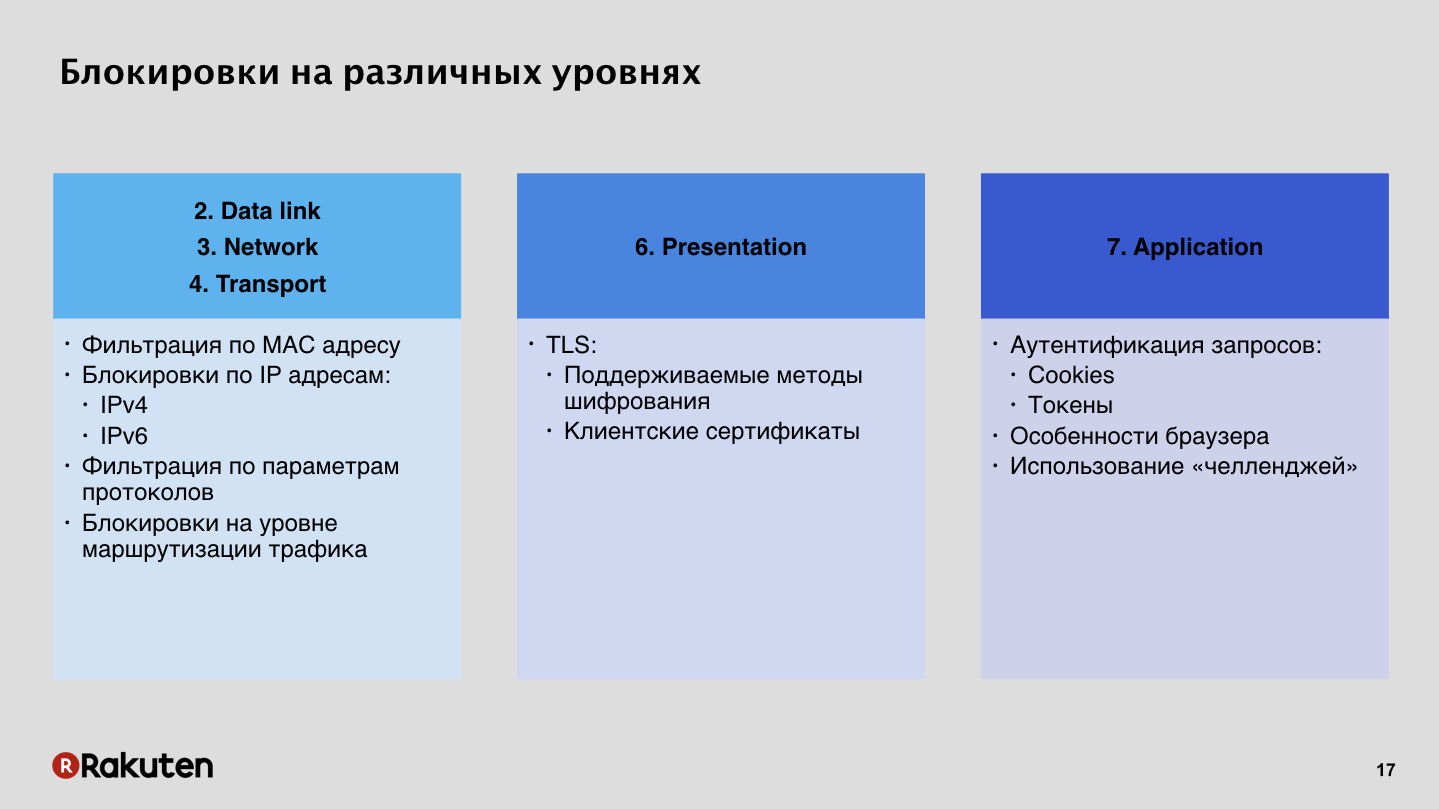
Hay muchos enfoques. Algunos de ellos ya fueron mencionados por colegas de Yandex en su primer informe. ¿Cómo bloquear intrusos? Anton Karpov dijo que los cortafuegos son malos, no nos gustan. De hecho, es posible bloquear por direcciones IP, el tema para Rusia es muy relevante, pero este método no nos conviene en absoluto. Preferimos usar bloqueos de nivel superior, en el séptimo nivel, en el nivel de la aplicación, mediante la autenticación de solicitudes mediante tokens, cookies de sesión.
Por qué Veamos primero las cerraduras bajas.
Esta es una forma barata, todos saben cómo usarla, todos tienen firewalls en los servidores. Un montón de instrucciones en Internet, no hay problemas para bloquear al usuario por IP. Pero cuando bloquea al usuario en un nivel bajo, no tiene forma de eludir de alguna manera su sistema de protección si se trata de un falso positivo. Los navegadores modernos están más o menos intentando mostrar algún mensaje de error hermoso al usuario, pero aún así, una persona no puede omitir su sistema de ninguna manera, porque un usuario común no puede cambiar arbitrariamente sus direcciones IP. Por lo tanto, creemos que este método no es muy bueno y hostil. Y además, IPv6 se mueve por todo el planeta, si tiene alguna tabla bloqueada, luego de un tiempo tomará mucho tiempo buscar direcciones en esas tablas, y no hay futuro para tales bloqueos.

Nuestro método es cerraduras en el nivel superior. Preferimos autenticar las solicitudes, porque para nosotros es una oportunidad para adaptarnos de manera muy flexible a la lógica comercial de nuestras aplicaciones. Tales métodos tienen ventajas y desventajas. La desventaja es el alto costo de desarrollo, la gran cantidad de recursos que tiene que invertir en infraestructura y la arquitectura de dichos sistemas, con toda su aparente simplicidad, sigue siendo complicada.
Usted ha escuchado en informes anteriores acerca de varios métodos basados en la biometría, recolección de datos. Por supuesto, también pensamos en esto, pero aquí es muy fácil violar la privacidad del usuario al recopilar los datos incorrectos que el usuario desea confiarle.
¿Cómo nos autenticamos? En nuestro caso, no hay nada extraordinario, pero quiero mencionar un método. Además de los tipos tradicionales (captcha y contraseñas de un solo uso), utilizamos Proof of Work, PoW. No, no extraemos bitcoins en las computadoras de los usuarios. Usamos PoW para ralentizar al atacante y, a veces, incluso bloquearlo por completo, lo que lo obliga a resolver una tarea muy difícil, en la que pasará mucho tiempo.
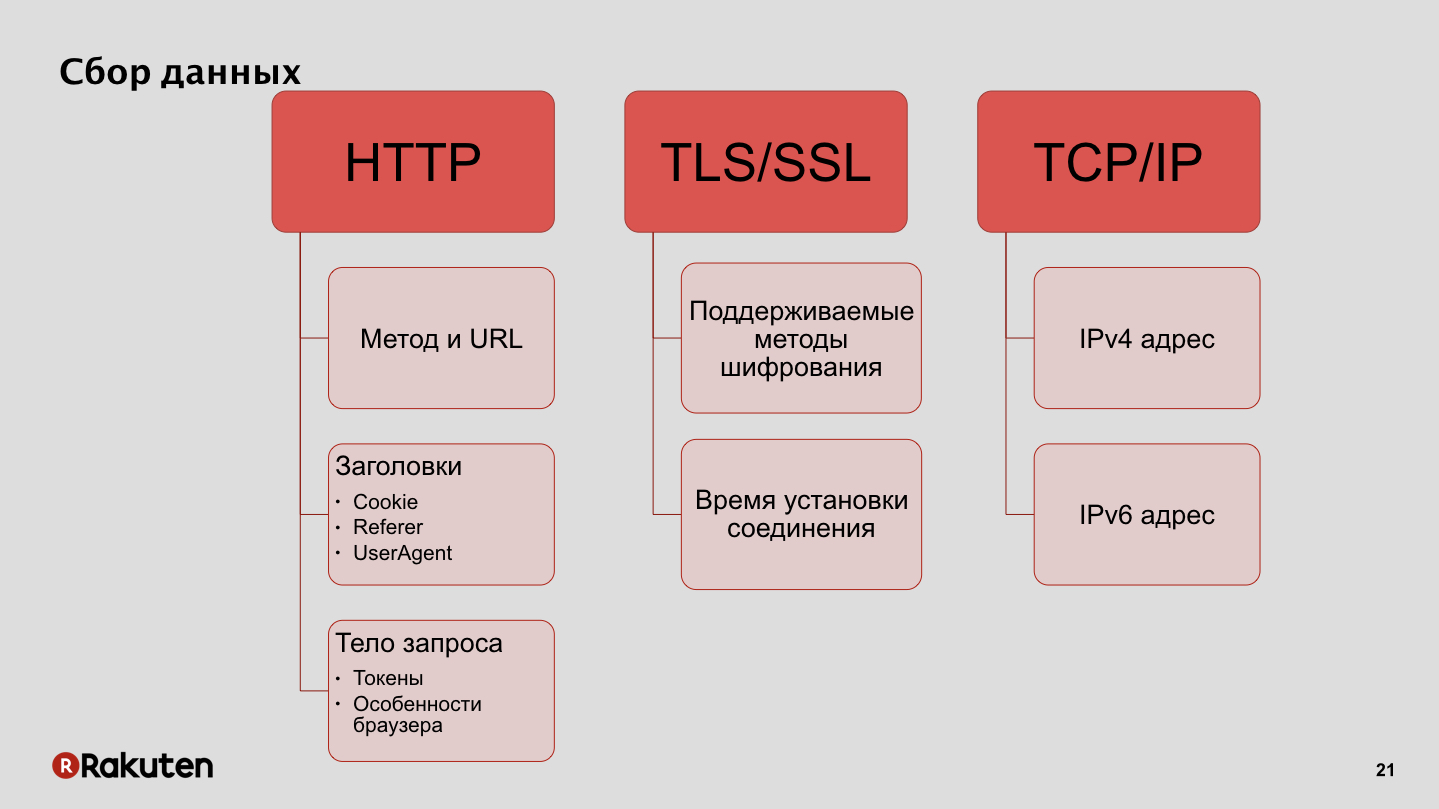
¿Cómo recopilamos datos? Utilizamos las direcciones IP como una de las características, también una de las fuentes de datos para nosotros son los protocolos de cifrado admitidos por los clientes y el tiempo de configuración de la conexión. Además, los datos que recopilamos de los navegadores de los usuarios, las características de estos navegadores y los tokens que utilizamos para autenticar las solicitudes.
¿Cómo detectar intrusos? Probablemente espere que le diga que construimos una gran red neuronal e inmediatamente atrapamos a todos. En realidad no Utilizamos un enfoque multinivel. Esto se debe al hecho de que tenemos muchos servicios, volúmenes de tráfico muy grandes, y si intenta poner un sistema informático complejo en dichos volúmenes de tráfico, lo más probable es que sea muy costoso y disminuya la velocidad de los servicios. Por lo tanto, comenzamos con un método banal simple: comenzamos a contar cuántas solicitudes provienen de diferentes direcciones, desde diferentes navegadores.

Este método es muy primitivo, pero le permite filtrar ataques masivos estúpidos como DDoS, cuando ha aparecido anomalías pronunciadas en el tráfico. En este caso, estás absolutamente seguro de que se trata de un atacante, y puedes bloquearlo. Pero este método solo es adecuado en el nivel inicial, ya que solo evita los ataques más duros.
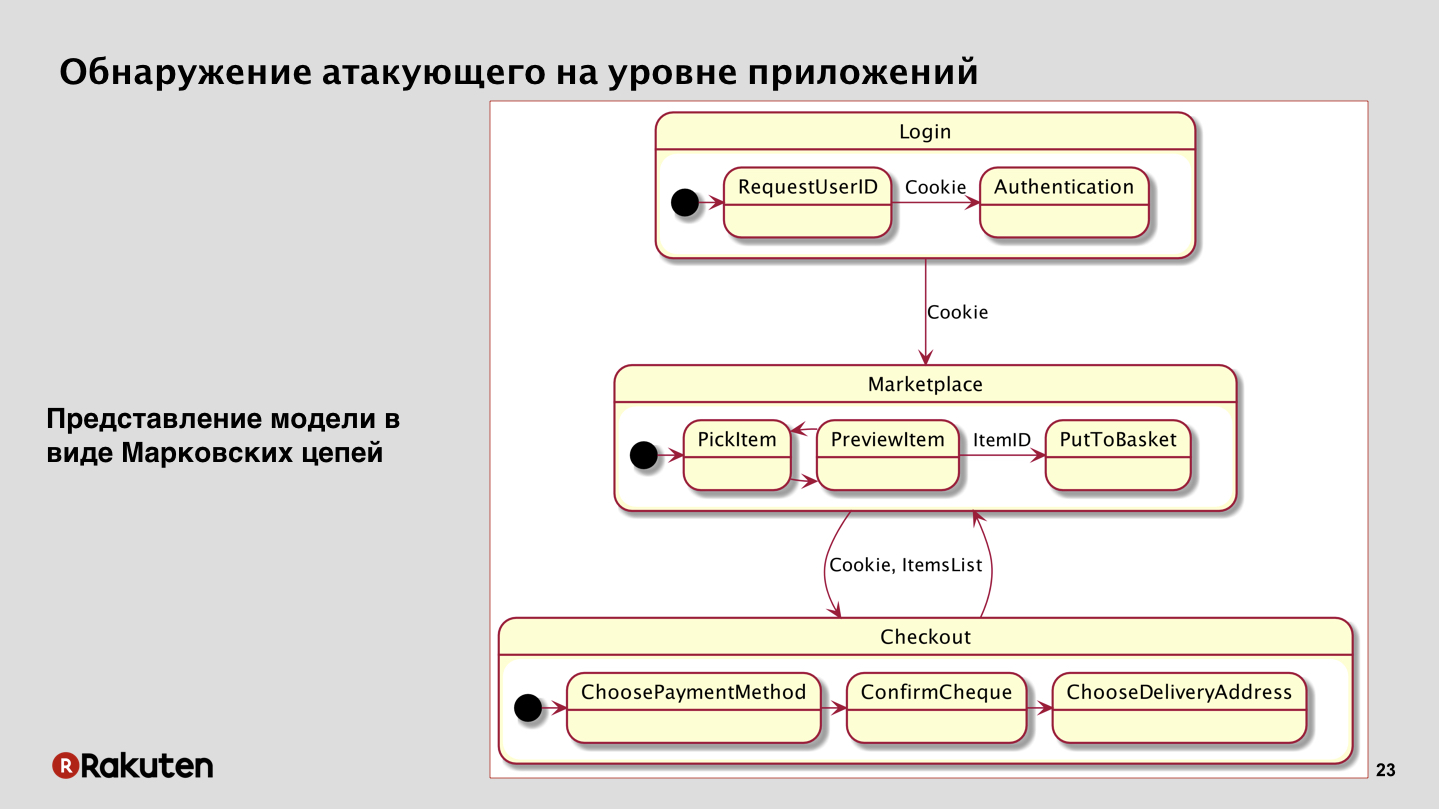
Después de eso, llegamos al siguiente método. Decidimos centrarnos en el hecho de que tenemos una lógica comercial de aplicaciones, y un atacante nunca puede simplemente acudir a su servicio y robar dinero. Si no lo rompió, por supuesto. En nuestro caso, si observa el esquema más simplificado de algún mercado abstracto, veremos que el usuario debe iniciar sesión primero, presentar sus credenciales, recibir cookies de sesión, luego ir al mercado, buscar productos allí, ponerlos en la cesta. Después de eso, pasa a pagar la compra, selecciona la dirección, el método de pago, y al final hace clic en "pagar", y finalmente se produce la compra de bienes.
Usted ve, un atacante tiene que tomar muchos pasos. Y estas transiciones entre estados, entre servicios se asemejan a un modelo matemático: estas son cadenas de Markov, que también se pueden usar aquí. En principio, en nuestro caso mostraron muy buenos resultados.

Puedo dar un ejemplo simplificado. En términos generales, hay un momento en que un usuario se autentica, cuando elige compras y realiza un pago, y por ejemplo, es obvio cómo un atacante puede comportarse de manera anormal, puede intentar iniciar sesión varias veces con diferentes cuentas. O puede agregar los productos incorrectos al carrito que compran los usuarios comunes. O realiza una cantidad anormalmente grande de acciones.
Las cadenas de Markov generalmente consideran estados. También decidimos agregar tiempo a estos estados para nosotros mismos. Los atacantes y los usuarios normales se comportan de manera muy diferente en el tiempo, y esto también ayuda a separarlos.
Las cadenas de Markov son un modelo matemático bastante simple, son muy fáciles de contar sobre la marcha, por lo que le permiten agregar otro nivel de protección y eliminar otra parte del tráfico.
La siguiente etapa. Atrapamos a los estúpidos atacantes, atrapamos a los agresores mentales. Ahora quedan los más inteligentes. Para atacantes difíciles, se necesitan características adicionales. Que podemos hacer
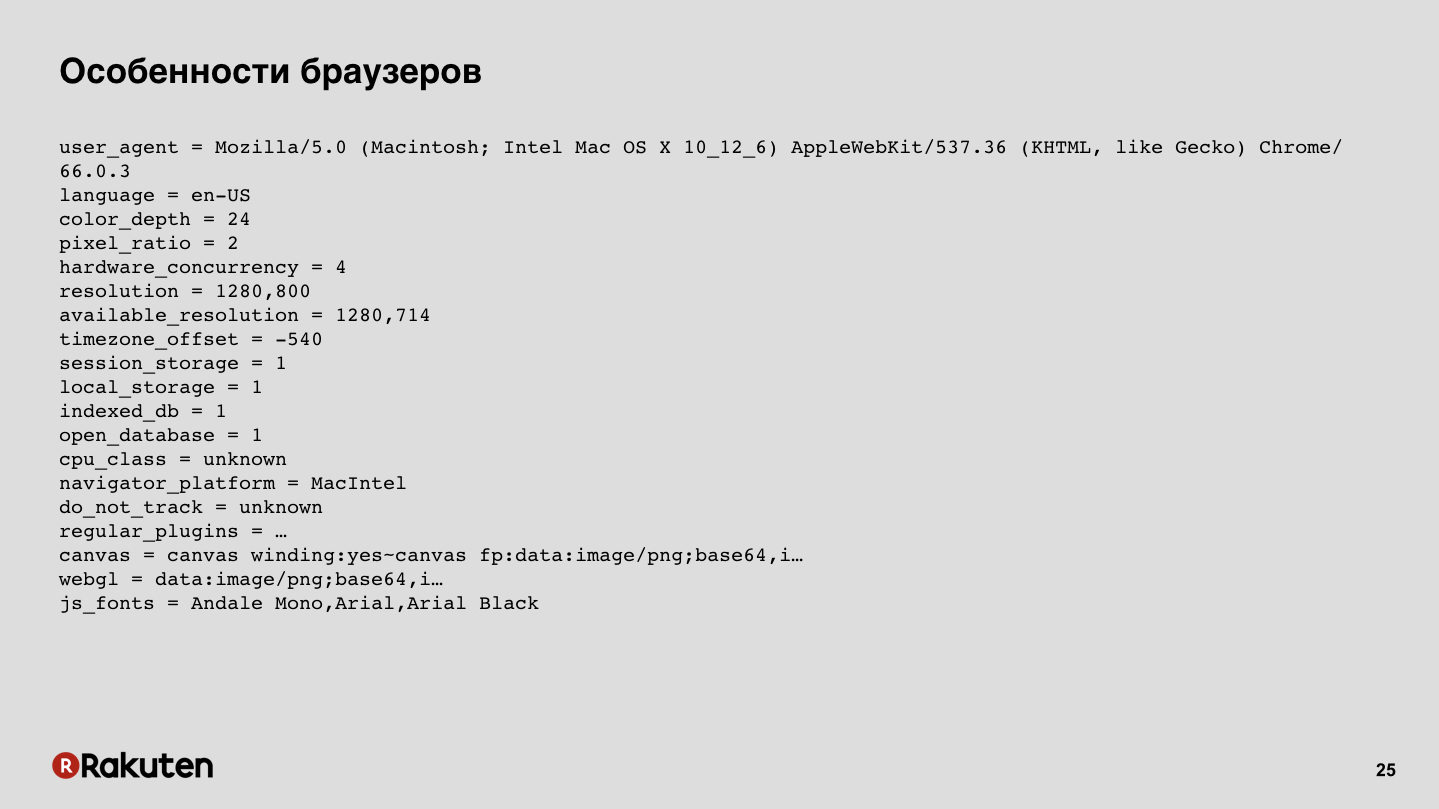
Podemos recoger algunas huellas digitales de los navegadores. Ahora los navegadores son sistemas bastante complejos, tienen muchas características compatibles, ejecutan JS, tienen varias capacidades de bajo nivel, y todo esto se puede recopilar, todos estos datos. En la diapositiva hay un ejemplo de la salida de una de las bibliotecas de código abierto.
Además, puede recopilar datos sobre cómo el usuario interactúa con su servicio, cómo mueve el mouse, cómo toca un dispositivo móvil, cómo desplaza la pantalla. Tales cosas son recopiladas, por ejemplo, por Yandex.Metrica. , , .
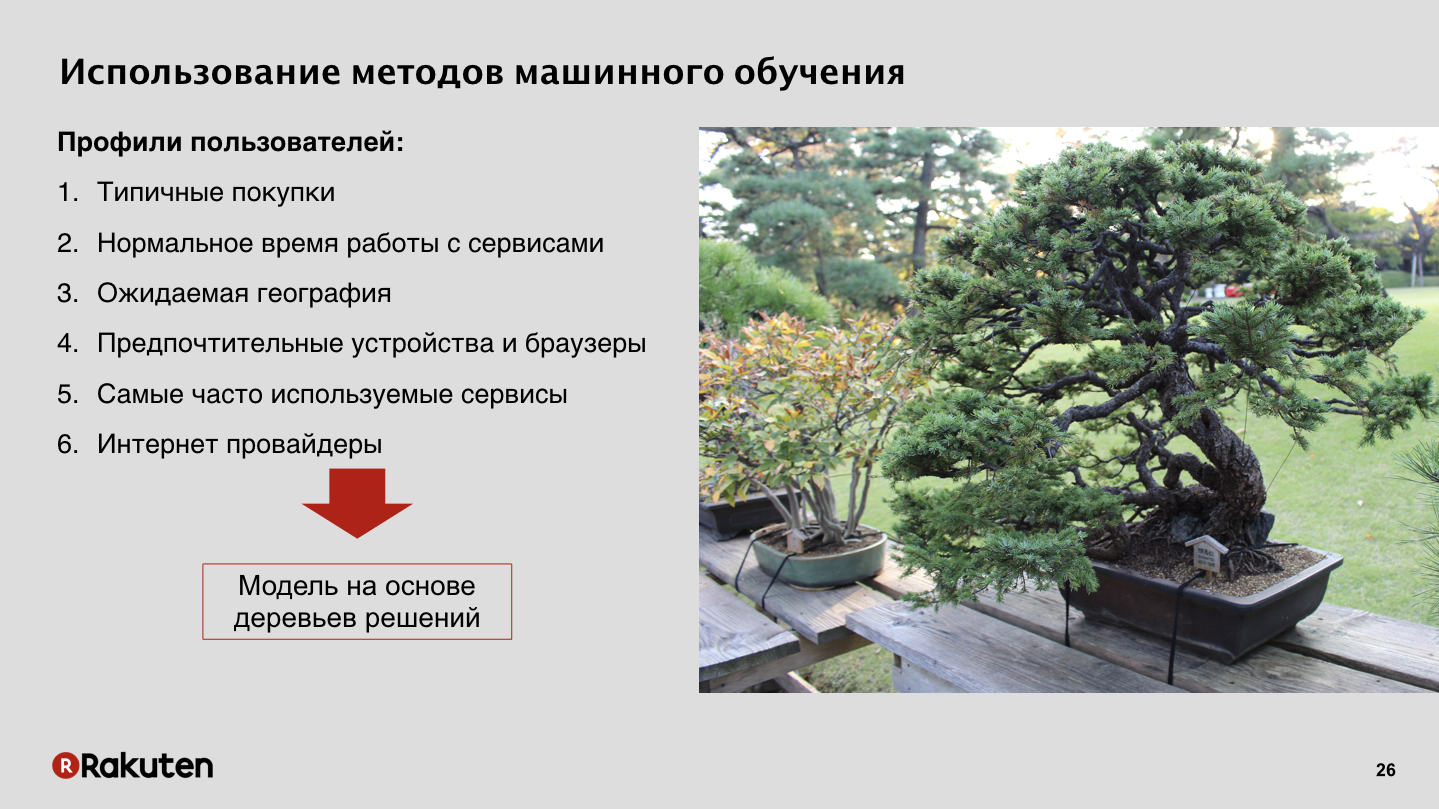
, . ? , , , , . , . machine learning, decision tree, . Decision tree if-else, , . , . - , - — , , .
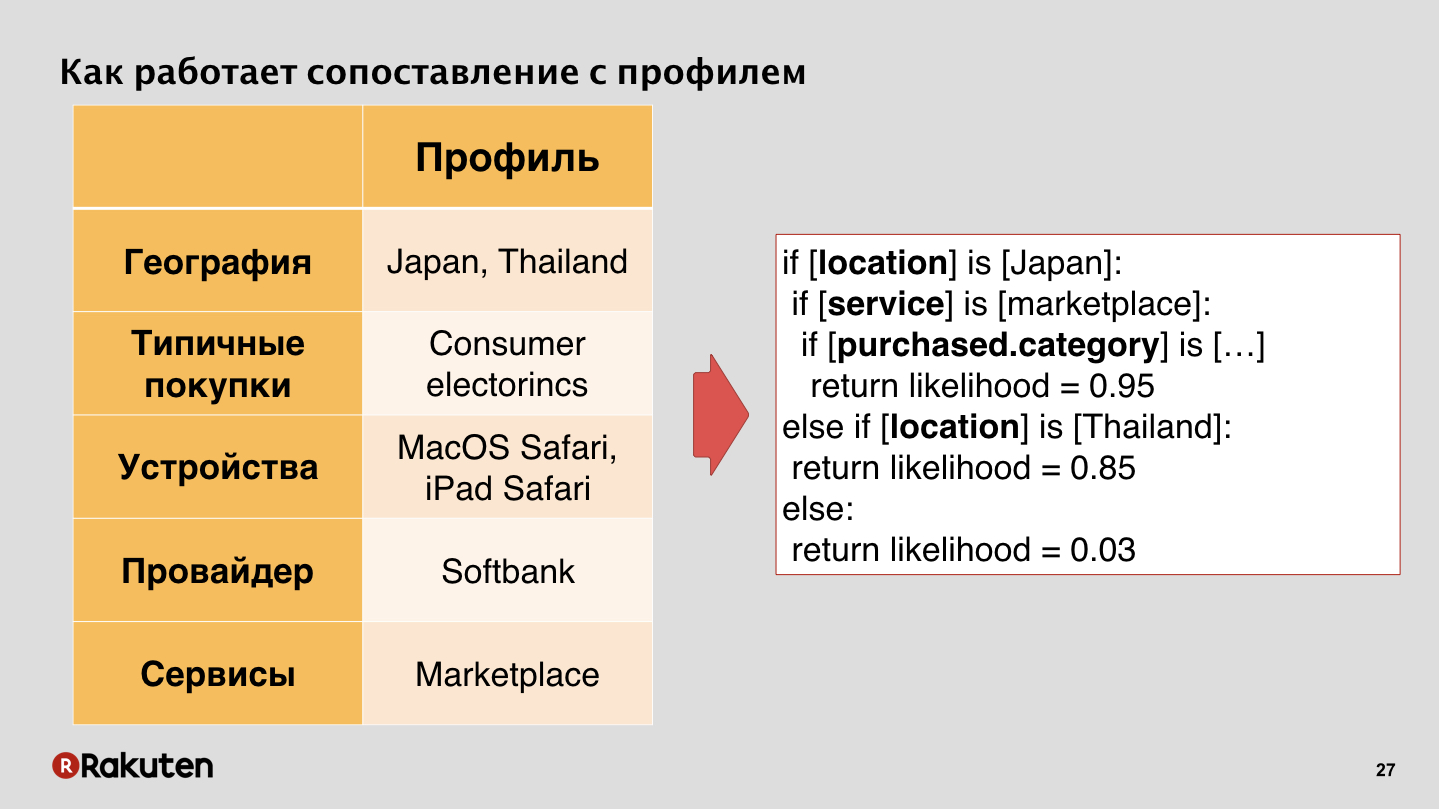
, , , - , , , Softbank, . , , . - , , , .
, , iTunes — , - , .
, , , .

. , ? , . , , , . , .
Nuestro sistema tiene la posibilidad de mejoras flexibles. Actualmente estamos trabajando en algunas opciones, tratando de comenzar a bloquear los ataques lo más cerca posible en tiempo real. Estamos tratando de adaptar nuestro sistema a varias interfaces de usuario. Pero aquí está mi opinión personal: no es necesario confiar solo en el sistema de protección contra el fraude. También es necesario mejorar, agregar varios métodos de autenticación y así protegerse desde diferentes ángulos.