 Niveles del juego Montezuma's Revenge Atari
Niveles del juego Montezuma's Revenge AtariDeepMind
demostró el proceso de aprendizaje de IA (su forma débil) para pasar juegos en Atari. La capacitación se realizó demostrando el sistema de pases de videojuegos de YouTube. Este método es utilizado por muchos jugadores humanos que, por una razón u otra, no pudieron superar algún tipo de juego.
Por lo general, para resolver este problema, es necesario utilizar el llamado método de
aprendizaje de refuerzo . Esta técnica es bastante popular, ya que le permite entrenar bots para realizar diversas tareas específicas. Tan pronto como el sistema logra algún resultado, recibe una pequeña recompensa.
Los desarrolladores crean algoritmos y modelos que pueden evaluar el entorno de juego, incluidas las posibles recompensas por completar (puntos, bonificaciones, etc.). Tales sistemas aprenden el juego paso a paso, pasando gradualmente a la final.
El nuevo método desarrollado en DeepMind es diferente de todos los demás. Los especialistas de la compañía pudieron entrenar a la IA para jugar juegos bajo Atari, como Montezuma's Revenge, Pitfall y Private Eye. Al mismo tiempo, no se hizo hincapié en los puntos y los premios: la capacitación se realizó en tutoriales de YouTube. Y esto nos permitió lograr resultados inusuales para la IA.
El hecho es que juegos como el mismo Montezuma's Revenge son difíciles de "entender" para las máquinas. No hay una tarea clara, no está claro a dónde ir, qué artículos recolectar y qué hacer con ellos en el futuro. La máquina simplemente se pierde, porque en el proceso de promoción no recibe recompensas y el entrenamiento con refuerzos aquí se vuelve inútil o casi inútil.
En el juego en cuestión, debes controlar a un personaje llamado Panama Joe. Al final, debe llegar a la tesorería en el antiguo templo. Según la leyenda, estos tesoros pertenecen a Montezuma. Primero debes encontrar el primer elemento crítico para pasar el juego: la llave dorada. Para detectarlo, debe seguir unos 100 pasos. Pero esto es si sabes qué hacer al respecto. Si no, hay una gran cantidad de posibilidades 100 de las
18 acciones iniciales. Esto es demasiado para cualquier IA creada por el hombre. Bueno, no obtendrás una recompensa aquí, todo es muy, muy específico.
Una forma de hacerle saber a la computadora qué hacer es demostrar los escenarios de paso. En realidad, no solo los automóviles, sino también las personas aprenden a realizar diversas tareas con ejemplos. Bailar, las acciones del artista, soldar: todo esto se ve mejor 1 vez, y no 100 veces para escuchar cómo hacerlo.
DeepMind llegó a la conclusión de que esta es la mejor manera de mostrarle a la computadora cómo completar una tarea con un resultado implícito. La tecnología creada por expertos realmente ayudó. Se utilizaron dos métodos para enseñar el ejemplo: TDC (clasificación de distancia temporal) y CDC (clasificación de distancia temporal intermodal).
En el primer caso, los AI están entrenados para determinar la distancia en el entorno del juego, para notar la diferencia entre dos cuadros diferentes. AI también "comprende" lo que hay que hacer para moverse de un lugar a otro. Para el entrenamiento en YouTube, a los videos se les asignan pares de cuadros en orden aleatorio.
En el segundo caso, también se agrega la "comprensión" del acompañamiento de sonido. Los sonidos en casi todos los juegos corresponden al desempeño de ciertas acciones. Por ejemplo, saltar, conseguir objetos, etc. Por lo tanto, la computadora está entrenada para percibir los sonidos como elementos importantes del juego. El video + sonido permite que la computadora funcione bastante bien en el proceso de pasar el juego.
Aquí están las acciones de la IA entrenada en la venganza de Montezuma. El paso de los otros dos juegos mencionados al principio está
aquí .
Es cierto que no era posible abandonar por completo el papel de las recompensas; hasta ahora, la IA depende de los mismos puntos. Pero el método habitual de enseñanza del sistema, que se utilizó anteriormente, no permitía llegar al menos a la llave de oro, para la cual se dan los primeros cien puntos. Entonces, la IA, como un gatito ciego, asomó en todas las direcciones, sin entender qué hacer. Es cierto que el sistema de "refuerzo" también se modifica.
En el proceso de pasar cada 16o cuadro de video del juego de IA, se compara con los cuadros del video que pasa el juego por personas. Si la comparación muestra un alto grado de similitud, entonces la IA recibe una recompensa. Con el tiempo, la IA comienza a realizar la misma secuencia de acciones que una persona, para obtener un marco similar.
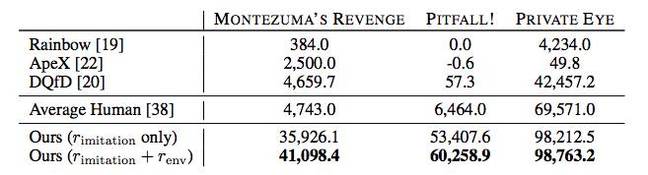
Además, la IA en muchos casos muestra mejores resultados que los jugadores humanos u otros algoritmos de paso, incluidos Rainbow, ApeX y DQfD.
En principio, todo esto es impresionante, pero hasta ahora los beneficios prácticos de los logros de DeepMind no están claros. ¿Es posible usar el método de enseñanza de IA propuesto por la compañía en cualquier otro lugar que no sea pasar juegos antiguos? Pero conociendo los logros de DeepMind en el campo de la IA, no hay duda de que de una forma u otra todo esto se puede usar con fines prácticos; es poco probable que los expertos comiencen a trabajar en el tema por "diversión".