Este blog generalmente está dedicado al reconocimiento de matrículas. Pero, trabajando en esta tarea, llegamos a una solución interesante que se puede aplicar fácilmente a una amplia gama de tareas de visión por computadora. Hablaremos de esto ahora: cómo hacer un sistema de reconocimiento que no lo defraude. Y si fallas, puedes decirle dónde está el error, volver a entrenar y tener una solución un poco más confiable que antes. ¡Bienvenido a cat!

Que paso
Imagínese, se enfrentó a la tarea: encontrar pizza en la foto y determinar qué tipo de pizza es.
Veamos brevemente el camino estándar que seguimos a menudo. Por qué Para entender cómo hacerlo ... no es necesario.
Paso 1: levanta la base
 Paso 2:
Paso 2: para la fiabilidad del reconocimiento, se puede observar que hay pizza y cuál es el fondo (por lo que incluiremos una red neuronal de segmentación en el procedimiento de reconocimiento, pero a menudo vale la pena):
 Paso 3:
Paso 3: lo llevamos a una "forma normalizada" y lo clasificamos utilizando otra red neuronal convolucional:

Genial Ahora tenemos una base de entrenamiento. En promedio, el tamaño de la base de entrenamiento puede ser de varios miles de imágenes.
Tomamos 2 redes de convolución, por ejemplo, Unet y VGG. El primero se entrena en las imágenes de entrada, luego normalizamos la imagen y entrenamos el VGG para su clasificación. Funciona muy bien, lo transferimos al cliente y consideramos el dinero ganado honestamente.
¡No funciona así!
Lamentablemente, casi nunca. Hay varios problemas graves que surgen durante la implementación:
- Variabilidad de los datos de entrada. Estudiamos un ejemplo, en realidad, todo resultó de manera diferente. Sí, solo durante la operación, algo salió mal.
- Muy a menudo, la precisión del reconocimiento sigue siendo insuficiente. Quiero 99.5%, pero va de 60% a 90% en un buen día. Pero, por regla general, querían automatizar una solución que funcionara, ¡e incluso mejor que las personas!
- Tales tareas a menudo se subcontratan, lo que significa que los contratos ya están cerrados, los actos están firmados y el propietario del negocio tiene que decidir si invertir en la revisión o abandonar la decisión por completo.
- Sí, simplemente comienza a degradarse con el tiempo, como en cualquier sistema complejo, si no involucra especialistas que participaron en la creación, o el mismo nivel de calificación.
Como resultado, para muchos que han tocado toda esta mecánica con sus manos, queda claro que todo debería suceder de una manera completamente diferente. Algo como esto:
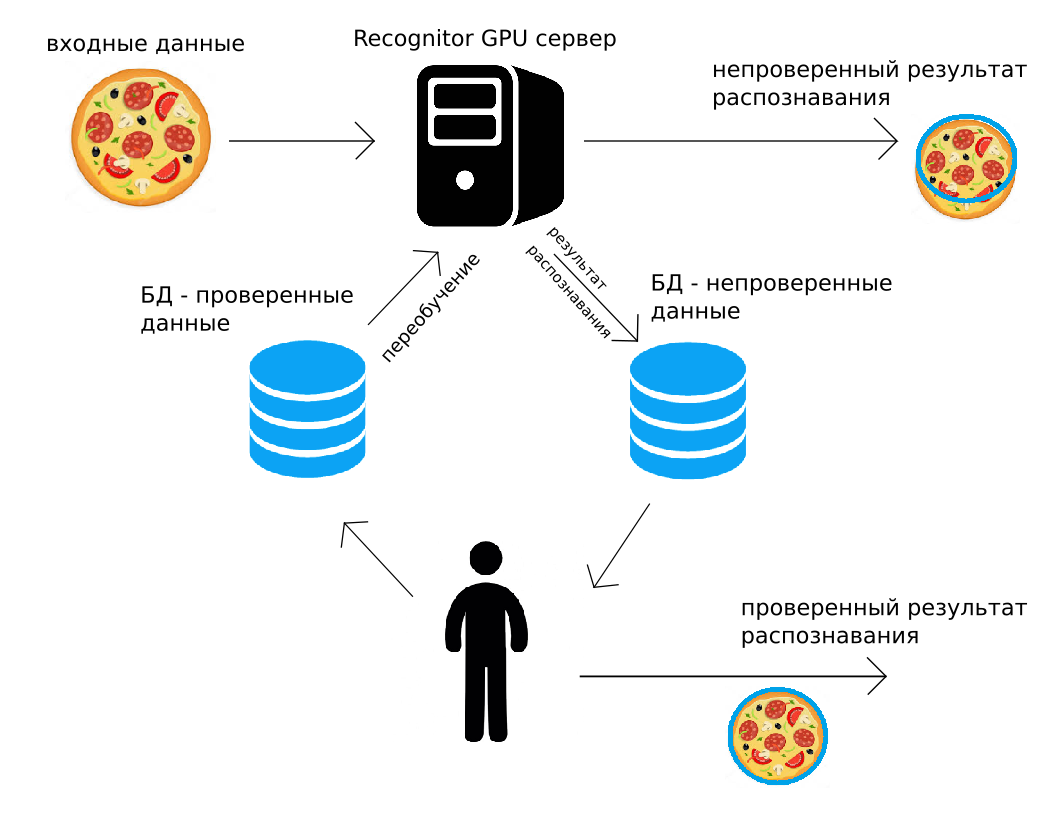
Los datos se envían a nuestro servidor (a través de http POST, o utilizando la API de Python), el servidor de GPU los reconoce "como podría", devolviendo inmediatamente el resultado. En el camino, el mismo resultado de reconocimiento junto con la imagen se agrega al archivo. Luego, una persona controla todos los datos o una parte aleatoria de los mismos, los corrige. El resultado corregido se coloca en el segundo archivo. Y luego, cuando sea conveniente hacer esto (por ejemplo, por la noche), todas las redes neuronales convolucionales utilizadas para el reconocimiento se volverán a entrenar, utilizando los datos que la persona corrigió.
Tal circuito de reconocimiento, supervisión humana y capacitación adicional resuelven muchos de los problemas enumerados anteriormente. Además, en aquellas soluciones donde se necesita una alta precisión, se puede utilizar una salida verificada por el ser humano. Parece que este uso de datos verificados por humanos es demasiado costoso, pero además demostraremos que casi siempre tiene sentido económico.
Ejemplo real
Hemos implementado el principio descrito y lo hemos aplicado con éxito en varias tareas reales. Uno de ellos es el reconocimiento de números en imágenes de contenedores en terminales ferroviarias tomadas de una tableta. Es bastante conveniente: apunte la tableta al contenedor, obtenga el número reconocido y opere con él en el programa de la tableta.
Un ejemplo típico de instantánea:

En la imagen, el número es casi perfecto, solo mucho ruido visual. Pero se producen sombras duras, nieve, diseños de letras inesperados, inclinaciones serias o perspectivas al disparar.
Y entonces parece un conjunto de páginas web en las que ocurre toda la "magia":
1) Subir el archivo al servidor (por supuesto, esto puede hacerse no desde la página html, sino usando Python o cualquier otro lenguaje de programación):
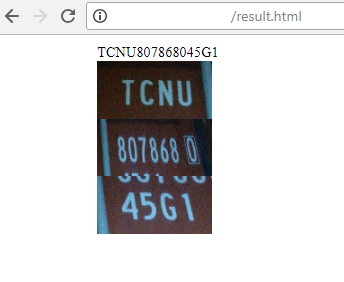
2) El servidor devuelve el resultado del reconocimiento:
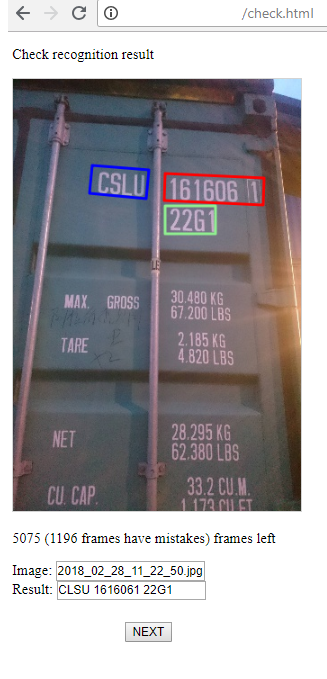
3) Y esta es una página para el operador que monitorea el éxito del reconocimiento y, si es necesario, corrige el resultado. Hay 2 etapas: la búsqueda de áreas de grupos de símbolos, su reconocimiento. El operador puede corregir todo esto si ve un error.
4) Aquí hay una página simple donde puede comenzar a entrenar para cada una de las etapas de reconocimiento y, al correr, ver la pérdida actual.
Duro minimalismo, ¡pero funciona muy bien!
¿Cómo puede verse esto desde el lado de una empresa que planea utilizar el enfoque descrito (o nuestra experiencia y los servidores de Recognitor)?
- Se seleccionan redes neuronales de última generación. Si todo se basa en soluciones depuradas existentes, puede iniciar el servidor y configurar el marcado en una semana.
- Se organiza un flujo de datos (preferiblemente sin fin) en el servidor, se marcan varios cientos de tramas.
- Comienza el entrenamiento. Si todo "encaja", entonces el resultado es el 60-70% de reconocimiento exitoso, lo que ayuda enormemente a marcar más.
- Luego comienza el trabajo sistemático de presentar todas las situaciones posibles, verificar los resultados del reconocimiento, editar, volver a capacitar. A medida que aprende, integrar el sistema en un proceso de negocio es cada vez más rentable.
¿Quién más hace esto?
El tema del ciclo cerrado no es nuevo. Muchas compañías ofrecen sistemas de procesamiento de datos de un tipo u otro. Pero el paradigma del trabajo se puede construir de maneras completamente diferentes:
- Nvidia Digits son algunos modelos bastante buenos y potentes envueltos en una GUI intuitiva donde el usuario necesita adjuntar sus imágenes y JSON. La ventaja principal: un conocimiento mínimo de programación y administración le brinda una buena solución. Menos: esta solución puede estar lejos de ser óptima (por ejemplo, no es posible buscar números de automóviles a través de SSD). Y para comprender cómo optimizar la solución, el usuario no tiene suficiente conocimiento. Si tiene suficiente conocimiento, no necesita DÍGITOS. El segundo inconveniente: debe tener su propio equipo en el que configurar e implementar todo.
- Servicios de marcado como Mechanical Turk, Toloka, Supervise.ly. Los dos primeros le proporcionan herramientas de marcado, así como personas que pueden marcar los datos. Este último proporciona excelentes herramientas, pero sin personas. A través de los servicios, puede automatizar el trabajo humano, pero debe ser un experto en la configuración de la tarea.
- Empresas que ya se han capacitado y brindan una solución fija (Microsoft, Google, Amazon). Lea más sobre ellos aquí (https://habr.com/post/312714/). Sus decisiones no son flexibles, no siempre "bajo el capó" serán las mejores decisiones necesarias en su caso. En general, casi siempre no ayuda.
- Empresas que trabajan específicamente con sus datos, por ejemplo ScaleAPI (https://www.scaleapi.com/). Tienen una gran API, para el cliente será una caja negra. Datos de entrada - resultado de salida. Es muy probable que en el interior haya las mejores soluciones de automatización, pero no le importa. Soluciones bastante caras en términos de un marco, pero si sus datos son realmente valiosos, ¿por qué no?
- Empresas que tienen las herramientas para hacer un ciclo casi completo con sus propias manos. Por ejemplo, PowerAI de IBM . Es casi como DÍGITOS, pero solo tiene que marcar los conjuntos de datos. Además, nadie optimiza las redes neuronales y las soluciones. Pero muchos casos han sido resueltos. El modelo de red neuronal resultante se implementa en usted y se le dará acceso http. Aquí hay el mismo inconveniente que en Dígitos: debe comprender qué hacer. Es su caso que puede "no converger" o simplemente requerir un enfoque inusual para el reconocimiento. En general, la solución es perfecta si tiene una tarea bastante estándar, con objetos bien separables que deben clasificarse.
- Empresas que resuelven exactamente su problema con sus herramientas. No hay muchas empresas de este tipo. En realidad, solo les recomendaría CrowdFlower. Aquí, por dinero razonable, pondrán garabatos, asignarán un administrador, desplegarán sus servidores, donde se lanzarán sus modelos. Y por dinero más serio podrán cambiar u optimizar sus decisiones para su tarea.
Las grandes empresas trabajan con ellos: eBay, Oracle, Tesco, Adobe. A juzgar por su apertura, interactúan con éxito con pequeñas empresas.
¿Cómo difiere esto del desarrollo personalizado que hace EPAM, por ejemplo? El hecho de que todo está listo aquí. El 99% de la solución no está escrita, sino ensamblada a partir de módulos listos para usar: marcado de datos, selección de red, capacitación, desarrollo. Las empresas que se desarrollan por encargo no tienen esa velocidad, la dinámica del desarrollo de soluciones y la infraestructura terminada. Creemos que la tendencia y el enfoque que CrowdFlower ha identificado es cierto.
¿Para qué tareas funciona esto?
Quizás el 70% de las tareas están automatizadas de esta manera. Las tareas más adecuadas son el reconocimiento diverso de áreas que contienen texto. Por ejemplo, placas de matrícula de automóviles, de las que ya
hemos hablado , números de trenes (
este es nuestro ejemplo hace dos años ), inscripciones en contenedores.

Se reconoce una gran cantidad de información técnica simbólica en las fábricas para dar cuenta de los productos y su calidad.
Este enfoque ayuda mucho al reconocer los productos en los estantes de las tiendas y las etiquetas de precios, aunque allí se deben crear soluciones de reconocimiento bastante complicadas.

Pero puede escapar de las tareas con información técnica. Cualquier semántica, ya sea segmentación de instancias, con la detección de automóviles, argali, alces y lobos marinos también se aplicará perfectamente a este enfoque.

Una dirección muy prometedora es mantener la comunicación con las personas en los bots de chat de voz y texto. Habrá una forma bastante inusual de marcar: contexto, tipo de frase, su "relleno". Pero el principio es el mismo: trabajamos en modo automático, una persona controla la exactitud de la comprensión y las respuestas. Puede recurrir a la asistencia del operador en caso de tono insatisfecho o irritado del cliente. A medida que se acumulan datos, volvemos a entrenar.
¿Cómo trabajar con video?
Si usted o dentro de su empresa han desarrollado las competencias necesarias (un poco de experiencia en Machine Learning, trabajando con Zoo Framework, tanto fuera de línea como en línea), no habrá dificultades para resolver problemas simples de visión por computadora: segmentación, clasificación, reconocimiento de texto y otro
Pero para el video, no todo es tan sencillo. ¿Cómo se marcan estas cantidades interminables de datos? Por ejemplo, puede resultar que una vez cada pocos segundos aparece un objeto (o varios objetos) en el cuadro que necesita ser marcado. Como resultado, todo esto puede convertirse en una visualización cuadro por cuadro y ocupa tantos recursos que uno ni siquiera tiene que hablar sobre el control adicional de una persona después de lanzar una solución. Pero esto se puede superar si presenta el video de la manera correcta para resaltar los cuadros con un área de interés.
Por ejemplo, nos encontramos con enormes series de videos en las que era necesario resaltar un solo objeto específico: el acoplamiento de las plataformas ferroviarias. Y realmente no fue fácil. Resultó que no todo es tan aterrador, si tomas el monitor más ancho, eliges una velocidad de cuadro, por ejemplo 10FPS, y colocas 256 cuadros en una imagen, es decir 25.6s en una imagen:

Probablemente se ve aterrador. Pero en realidad, se necesitan unos 15 segundos para hacer clic en un solo cuadro, eligiendo el centro del acoplamiento del automóvil en el cuadro. E incluso una persona en un día o dos puede marcar al menos 10 horas de video. Obtenga más de 30 mil ejemplos de capacitación. Además, el paso de plataformas frente a la cámara en este caso no es un proceso constante (sino bastante raro, debe tenerse en cuenta), ¡es bastante realista incluso en tiempo casi real para corregir la máquina de reconocimiento, reponiendo la base de entrenamiento! Y si el reconocimiento se produce correctamente en la mayoría de los casos, se puede superar una hora de video en un par de minutos. Y luego descuidar el control total de la persona, como regla, no es económicamente rentable.
Todavía es más fácil si el video necesita ser marcado "sí / no" en lugar de la localización del objeto. Después de todo, los eventos a menudo están "pegados", y con solo deslizar el mouse, puede marcar hasta 16 cuadros a la vez.
La única cosa, como regla, es que tiene que usar 2 etapas en el análisis del video: buscar "cuadros o áreas de interés", y luego trabajar con cada cuadro (o secuencia de cuadros) por otros algoritmos.
Economía máquina-humano
¿Cuánto se puede optimizar el costo del procesamiento de datos visuales? De una forma u otra, es estrictamente necesario tener una persona para controlar el reconocimiento de datos. Si este control es selectivo, los costos son insignificantes. Pero si estamos hablando de control total, ¿cuánto puede ser beneficioso? Resulta que esto tiene sentido casi siempre, si antes una persona realizaba la misma tarea sin la ayuda de una máquina.
Tomemos el no el mejor ejemplo dado al principio: busque pizza en la imagen, marcado y selección de tipo (y en realidad, una serie de otras características). Aunque, la tarea no es tan sintética como parece. El control de la apariencia de los productos de la red de franquicias en realidad existe.
Suponga que el reconocimiento usando un servidor GPU requiere 0.5s de tiempo de máquina, para que una persona marque completamente un marco durante aproximadamente 10s (elija el tipo de pizza y su calidad de acuerdo con una serie de parámetros), y para verificar si la computadora detecta todo correctamente, necesita 2s. Por supuesto, habrá un desafío en la conveniencia de presentar estos datos, pero estos tiempos son bastante comparables con nuestra práctica.
Necesitamos más información para el costo del diseño manual y el alquiler de un servidor GPU. Como regla general, no tiene que depender de una carga completa del servidor. Permita que sea posible cargar 100,000 fotogramas por día (tomará el 60% de la potencia de procesamiento de una GPU) con un costo estimado de un alquiler mensual del servidor de 60,000 rublos. Resulta 2 centavos para el análisis de un cuadro en la GPU. Un análisis manual a un costo de 30,000r por 40 horas de tiempo de trabajo costará 26 kopecks por cuadro.
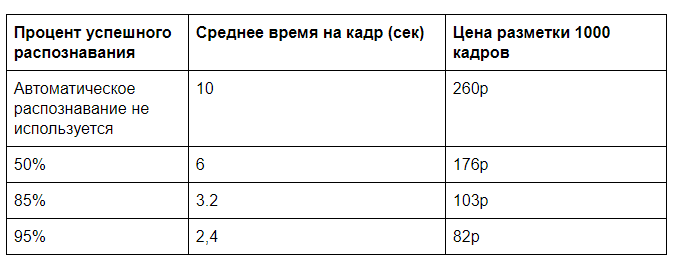
Y si posteriormente elimina el control total, podrá alcanzar un precio de casi 20 rublos por 1000 cuadros. Si hay muchos datos de entrada, entonces es posible optimizar los algoritmos de reconocimiento, trabajar en la transferencia de datos y lograr una eficiencia aún mayor.
En la práctica, descargar a una persona a medida que el sistema de reconocimiento aprende tiene otro significado importante: hace que sea mucho más fácil escalar su producto. Un aumento significativo en la cantidad de datos le permite entrenar mejor el servidor de reconocimiento, la precisión aumenta. Y el número de empleados involucrados en el proceso de procesamiento de datos aumentará no proporcionalmente al volumen de datos, lo que simplificará significativamente el crecimiento de la empresa desde el punto de vista organizacional.
Como regla general, cuanto más texto y contornos tenga que ingresar manualmente, más rentable es el uso del reconocimiento automático.
¿Y todo cambia?
Por supuesto, no todos. Pero ahora algunas áreas del negocio ya no son tan locas como antes.
¿Quiere hacer un servicio fuera de línea sin una persona en la instalación? Plante un operador de forma remota y monitoree
en cámaras para cada cliente? Resultará un poco peor que una persona viva en el lugar. Sí, y los operadores necesitan casi más. ¿Y si descarga el operador cada 5 veces? Este puede ser un salón de belleza sin recepción, y control en la fábrica, y sistemas de seguridad. No se requiere una precisión del 100%: puede excluir completamente al operador de la cadena.
Es posible organizar sistemas de contabilidad bastante complejos para los servicios existentes para aumentar su eficiencia: control de pasajeros, vehículos, tiempo de servicios, donde existe el riesgo de "pasar por alto" la taquilla, etc.
Si la tarea está en el nivel actual de desarrollo de la visión por computadora y no requiere soluciones completamente nuevas, entonces esto no requerirá una inversión seria en el desarrollo.