Agregado por: buena discusión en Hacker NewsDavid Yu en GitHub ha desarrollado una
prueba de rendimiento interesante para llamadas de función a través de varias interfaces externas (Interfaces de funciones externas,
FFI ).
Creó un archivo de objeto compartido (
.so ) con una función simple de C. Luego escribió un código para llamar repetidamente a esta función a través de cada FFI con una dimensión de tiempo.
Para C "FFI", utilizó el enlace dinámico estándar, no
dlopen() . Esta diferencia es muy importante, ya que realmente afecta los resultados de la prueba. Puede argumentar cuán honesta es esta comparación con el FFI real, pero aún es interesante medirla.
El resultado de referencia más sorprendente es que
el FFI
de LuaJIT es
significativamente más rápido que C. Es aproximadamente un 25% más rápido que una llamada C nativa para una función de objeto compartido. ¿Cómo podría un lenguaje de script tipado débil y dinámicamente superar en el punto de referencia C? ¿El resultado es exacto?
De hecho, esto es bastante lógico. La prueba se ejecuta en Linux, por lo que el retraso proviene de la Tabla de vinculación de procedimientos (PLT). Preparé un experimento realmente simple para demostrar el efecto en la vieja C simple:
https://github.com/skeeto/dynamic-function-benchmarkAquí están los resultados en el Intel i7-6700 (Skylake):
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/callHay tres tipos diferentes de llamadas a funciones:
- Vía PLT.
- Llamada de función indirecta (a través de
dlsym(3) ) - Llamada de función directa (a través de una función compilada JIT)
Como puede ver, este último es el más rápido. Por lo general, no se usa en programas en C, pero es una opción natural en presencia de un compilador JIT, que incluye, obviamente, LuaJIT.
En mi punto de referencia, la función
empty() se llama:
void empty(void) { }
Compilar a un objeto compartido:
$ cc -shared -fPIC -Os -o empty.so empty.c
Al igual que en la
comparación PRNG anterior, el punto de referencia tantas veces como sea posible llama a esta función antes de que suene la alarma.
Tablas de diseño de procedimientos
Cuando un programa o biblioteca llama a una función en otro objeto compartido, el compilador no puede saber dónde estará esta función en la memoria. La información se encuentra solo en tiempo de ejecución cuando el programa y sus dependencias se cargan en la memoria. Por lo general, la función se encuentra en lugares aleatorios, por ejemplo, de acuerdo con la aleatorización del espacio de direcciones (Aleatorización del diseño del espacio de direcciones, ASLR).
¿Cómo resolver tal problema? Bueno, hay varias opciones.
Una de ellas es marcar cada llamada en metadatos binarios. El generador de tiempo de ejecución dinámico
inserta la dirección correcta en cada llamada. El mecanismo específico depende del
modelo de código que se utilizó durante la compilación.
La desventaja de este enfoque es que ralentiza la carga, aumenta el tamaño de los archivos binarios y reduce el
intercambio de páginas de códigos entre diferentes procesos. La descarga se ralentiza porque todos los pares de marcado dinámico deben ser parcheados con la dirección correcta antes de iniciar el programa. El binario está hinchado porque cada entrada necesita un lugar en la tabla. Y la falta de compartir está asociada con un cambio en las páginas de códigos.
Por otro lado, se puede eliminar la sobrecarga de invocar funciones dinámicas, lo que proporciona un rendimiento similar al JIT, como se muestra en el punto de referencia.
La segunda opción es enrutar todas las llamadas dinámicas a través de una tabla. El par de marcado original se refiere al código auxiliar en esta tabla, y desde allí a la función dinámica real. Con este enfoque, el código no necesita ser parcheado, lo que conduce a un
intercambio trivial entre procesos. Para cada función dinámica, necesita parchear solo un registro en la tabla. Además, estas correcciones pueden hacerse
perezosamente , en la primera llamada de la función, lo que acelera aún más la carga.
En los sistemas binarios ELF, esta tabla se denomina Tabla de vinculación de procedimientos (PLT). PLT en sí no está realmente corregido: se muestra como de solo lectura para el resto del código. En cambio, se corrige la tabla de compensación global (GOT). El código auxiliar PLT recupera la dirección de una función dinámica del GOT e
indirectamente salta a esa dirección. Para cargar direcciones de funciones de manera perezosa, estas entradas GOT se inicializan con la dirección de la función que encuentra el carácter de destino, actualiza el GOT con esa dirección y luego pasa a la función. Las llamadas posteriores usan una dirección detectada perezosamente.
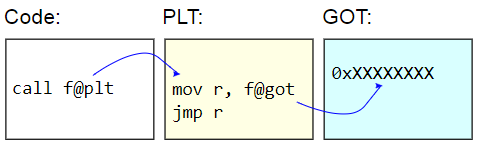
La desventaja de PLT es la sobrecarga adicional de invocar una función dinámica, que es lo que apareció en el punto de referencia. Dado que el punto de referencia
solo mide llamadas a funciones, la diferencia parece bastante significativa, pero en la práctica generalmente es cercana a cero.
Aquí está el punto de referencia:
volatile sig_atomic_t running; static long plt_benchmark(void) { long count; for (count = 0; running; count++) empty(); return count; }
Como
empty() está en un objeto compartido, la llamada pasa por el PLT.
Llamadas Dinámicas Indirectas
Otra forma de invocar dinámicamente funciones es recorrer el PLT y obtener la dirección de la función de destino en el programa, por ejemplo, a través de
dlsym(3) .
void *h = dlopen("path/to/lib.so", RTLD_NOW); void (*f)(void) = dlsym("f"); f();
Si se recibe la dirección de la función, el costo es menor que la función que llama a través de PLT. No hay una función intermedia de código auxiliar y acceso a GOT. (Precaución: si el programa tiene un registro PLT para esta función, entonces
dlsym(3) puede devolver una dirección de código auxiliar).
Pero esto sigue siendo un desafío
indirecto . En arquitecturas convencionales,
las llamadas a funciones
directas reciben su dirección relativa inmediata. Es decir, el propósito de la llamada es un desplazamiento codificado desde el punto de llamada. La CPU puede determinar a dónde irá la llamada mucho antes.
Las llamadas indirectas tienen más gastos generales. Primero, la dirección debe almacenarse en algún lugar. Incluso si es solo un registro, su uso aumenta el déficit de los registros. En segundo lugar, las llamadas indirectas provocan un predictor de rama en la CPU, imponiendo una carga adicional en el procesador. En el peor de los casos, una llamada puede incluso hacer que la tubería se detenga.
Aquí está el punto de referencia:
volatile sig_atomic_t running; static long indirect_benchmark(void (*f)(void)) { long count; for (count = 0; running; count++) f(); return count; }
La función pasada a este punto de referencia se extrae usando
dlsym(3) , por lo que el compilador no puede
hacer algo complicado , como convertir esta llamada indirecta a directa.
Si el cuerpo del bucle es lo suficientemente complejo como para causar un déficit de registros y, por lo tanto, dar la dirección a la pila, entonces este punto de referencia tampoco se puede comparar honestamente con el punto de referencia PLT.
Llamadas directas a funciones
Los dos primeros tipos de llamadas a funciones dinámicas son simples y fáciles de usar.
Las llamadas
directas para funciones dinámicas son más difíciles de organizar, ya que requieren cambios de código durante la ejecución. En mi punto de referencia, armé un
pequeño compilador JIT para generar una llamada directa.
El truco es que en x86-64 las transiciones explícitas están limitadas a un rango de 2 GB debido al operando firmado de 32 bits (firmado inmediatamente). Esto significa que el código JIT debe colocarse casi al lado de la función de destino,
empty() . Si el código JIT debe llamar a dos funciones dinámicas diferentes, divididas por más de 2 GB, entonces es imposible hacer dos llamadas directas.
Para simplificar la situación, mi punto de referencia no está preocupado por la elección exacta o muy cuidadosa de la dirección del código JIT. Después de recibir la dirección de la función de destino, simplemente resta 4 MB, la redondea a la página más cercana, asigna un poco de memoria y le escribe código. Si todo se hace como debería, entonces para buscar un lugar necesita verificar sus propias representaciones del programa en la memoria, y esto no puede hacerse de una manera limpia y portátil. Linux
requiere analizar archivos virtuales en / proc .
Así es como se ve mi asignación de memoria JIT. Asume
un comportamiento razonable para lanzar uintptr_t :
static void jit_compile(struct jit_func *f, void (*empty)(void)) { uintptr_t addr = (uintptr_t)empty; void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK); unsigned char *p = mmap(desired, len, prot, flags, fd, 0); }
Aquí destacan dos páginas: una para escribir y la otra con código que no se puede escribir. Al igual que en mi
biblioteca para cierres , aquí la página inferior se puede escribir y contiene una variable en
running que se restablece a alarma. Esta página debe estar al lado del código JIT para proporcionar un acceso efectivo con respecto al RIP, como una función en los otros dos puntos de referencia. La página superior contiene este código de ensamblaje:
jit_benchmark: push rbx xor ebx, ebx .loop: mov eax, [rel running] test eax, eax je .done call empty inc ebx jmp .loop .done: mov eax, ebx pop rbx ret
call empty es la única instrucción generada dinámicamente, es necesario completar correctamente la dirección relativa (menos 5 se indica en relación con el
final de la instrucción):
// call empty uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5
Si la función
empty() no está en el objeto general, sino en el mismo archivo binario, entonces esta es esencialmente una llamada directa que el compilador generará para
plt_benchmark() , suponiendo que por alguna razón no se haya incorporado en
empty() .
Irónicamente, llamar a un código compilado JIT requiere una llamada indirecta (por ejemplo, a través de un puntero de función), y no hay forma de evitarlo. ¿Qué puedo hacer aquí, compilar JIT otra función para una llamada directa? Afortunadamente, esto no importa porque solo una llamada directa se mide en un bucle.
Ningún secreto
Dados estos resultados, queda claro por qué LuaJIT genera llamadas más eficientes a funciones dinámicas que PLT,
incluso si siguen siendo llamadas indirectas . En mi punto de referencia, las llamadas indirectas sin PLT fueron un 28% más rápidas que con PLT, y las llamadas directas sin PLT fueron un 43% más rápidas que con PLT. Esta pequeña ventaja de los programas JIT sobre los antiguos programas nativos simples se logra debido al rechazo absoluto del intercambio de código entre procesos.