
En un proyecto relacionado con la seguridad de los sistemas Linux, necesitábamos interceptar llamadas a funciones importantes dentro del núcleo (como abrir archivos y ejecutar procesos) para proporcionar la capacidad de monitorear la actividad en el sistema y bloquear preventivamente la actividad de procesos sospechosos.
Durante el proceso de desarrollo, logramos inventar un enfoque bastante bueno, que nos permite interceptar convenientemente cualquier función en el núcleo por nombre y ejecutar nuestro código alrededor de sus llamadas. El interceptor se puede instalar desde un módulo GPL cargable, sin reconstruir el núcleo. El enfoque admite kernels versión 3.19+ para la arquitectura x86_64.
(Imagen de pingüino justo arriba: © En3l con DeviantArt .)Enfoques conocidos
API de seguridad de Linux
Lo más correcto sería utilizar la
API de seguridad de Linux , una interfaz especial creada específicamente para estos fines. En lugares críticos del código del núcleo, se ubican las llamadas a las funciones de seguridad, que, a su vez, llaman a las devoluciones de llamada establecidas por el módulo de seguridad. El módulo de seguridad puede examinar el contexto de una operación y tomar una decisión sobre si está permitido o denegado.
Desafortunadamente, la API de seguridad de Linux tiene un par de limitaciones importantes:
- los módulos de seguridad no pueden cargarse dinámicamente, son parte del núcleo y requieren reconstrucción
- solo puede haber un módulo de seguridad en el sistema (con algunas excepciones)
Si la posición de los desarrolladores del kernel es ambigua con respecto a la multiplicidad de módulos, entonces la prohibición de la carga dinámica es fundamental: el módulo de seguridad debe ser parte del kernel para garantizar la seguridad constantemente, desde el momento de la carga.
Por lo tanto, para usar la API de seguridad, debe suministrar su propio conjunto de kernel, así como integrar el módulo adicional con SELinux o AppArmor, que son utilizados por distribuciones populares. El cliente no quería suscribirse a tales obligaciones, por lo que esta ruta se cerró.
Por estas razones, la API de seguridad no nos convenía, de lo contrario sería una opción ideal.
Modificación de la tabla de llamadas del sistema.
El monitoreo se requería principalmente para las acciones realizadas por las aplicaciones de los usuarios, de modo que, en principio, podría implementarse a nivel de llamadas del sistema. Como sabe, Linux almacena todos los manejadores de llamadas del sistema en la tabla
sys_call_table . La sustitución de valores en esta tabla conduce a un cambio en el comportamiento de todo el sistema. Por lo tanto, manteniendo los valores antiguos del controlador y sustituyendo nuestro propio controlador en la tabla, podemos interceptar cualquier llamada al sistema.
Este enfoque tiene ciertas ventajas:
- Control total sobre cualquier llamada del sistema : la única interfaz con el núcleo para aplicaciones de usuario. Al usarlo, podemos estar seguros de que no perderemos ninguna acción importante realizada por el proceso del usuario.
- Gastos generales mínimos. Hay una inversión de capital única al actualizar la tabla de llamadas del sistema. Además de la inevitable carga útil de monitoreo, el único gasto es una llamada de función adicional (para llamar al manejador de llamadas del sistema original).
- Requisitos mínimos de kernel. Si lo desea, este enfoque no requiere ninguna opción de configuración adicional en el núcleo, por lo que, en teoría, admite la gama más amplia posible de sistemas.
Sin embargo, también sufre algunos defectos:
- La complejidad técnica de la implementación. Por sí solo, reemplazar punteros en una tabla no es difícil. Pero las tareas relacionadas requieren soluciones no obvias y una cierta calificación:
- tabla de llamadas del sistema de búsqueda
- bypass de protección de modificación de tabla
- reemplazo atómico y seguro
Todas estas son cosas interesantes, pero requieren un tiempo de desarrollo valioso, primero para la implementación y luego para el soporte y la comprensión.
- Incapacidad para interceptar algunos manejadores. En los núcleos anteriores a la versión 4.16, el manejo de llamadas del sistema para la arquitectura x86_64 contenía varias optimizaciones. Algunos de ellos exigieron que el manejador de llamadas del sistema sea un adaptador especial implementado en ensamblador. En consecuencia, tales controladores son a veces difíciles, y a veces incluso imposibles de reemplazar con los suyos, escritos en C. Además, se utilizan diferentes optimizaciones en diferentes versiones del núcleo, lo que se suma a las dificultades técnicas de la hucha.
- Solo se interceptan las llamadas del sistema. Este enfoque le permite reemplazar los manejadores de llamadas del sistema, lo que limita los puntos de entrada solo a ellos. Todas las verificaciones adicionales se realizan al principio o al final, y solo tenemos los argumentos de la llamada al sistema y su valor de retorno. A veces esto lleva a la necesidad de duplicar las verificaciones sobre la adecuación de los argumentos y las verificaciones de acceso. A veces causa una sobrecarga innecesaria cuando necesita copiar la memoria del proceso del usuario dos veces: si el argumento se pasa a través de un puntero, primero tenemos que copiarlo nosotros mismos, luego el controlador original copiará el argumento nuevamente por sí mismo. Además, en algunos casos, las llamadas al sistema proporcionan una granularidad muy baja de eventos que deben filtrarse adicionalmente del ruido.
Inicialmente, elegimos e implementamos con éxito este enfoque, buscando los beneficios de soportar la mayor cantidad de sistemas. Sin embargo, en ese momento todavía no sabíamos sobre las características de x86_64 y las restricciones en las llamadas interceptadas. Más tarde, resultó crítico para nosotros admitir llamadas al sistema relacionadas con el inicio de nuevos procesos: clone () y execve (), que son simplemente especiales. Esto es lo que nos llevó a buscar nuevas opciones.
Usando kprobes
Una de las opciones que se consideraron fue el uso de
kprobes : una API especializada diseñada principalmente para depurar y rastrear el núcleo. Esta interfaz le permite configurar controladores previos y posteriores para
cualquier instrucción en el núcleo, así como controladores para ingresar y regresar de una función. Los manejadores obtienen acceso a los registros y pueden cambiarlos. Por lo tanto, podríamos obtener monitoreo y la capacidad de influir en el curso posterior del trabajo.
Beneficios de usar kprobes para interceptar:
- API madura Las sondas K han existido y mejorado desde tiempos inmemoriales (2002). Tienen una interfaz bien documentada, la mayoría de las trampas ya se han encontrado, su trabajo se ha optimizado lo más posible, y así sucesivamente. En general, toda una montaña de ventajas sobre las bicicletas experimentales de fabricación propia.
- Intercepción de cualquier lugar en el núcleo. Los Kprobes se implementan utilizando puntos de interrupción (instrucciones int3) incrustados en el código ejecutable del núcleo. Esto le permite instalar kprobes literalmente en cualquier lugar de cualquier función, si se conoce. Del mismo modo, los kretprobes se implementan mediante la suplantación de la dirección de retorno en la pila y le permiten interceptar el retorno de cualquier función (excepto aquellas que, en principio, no devuelven el control).
Desventajas de kprobes:
- Dificultad técnica Kprobes es solo una forma de establecer un punto de interrupción en cualquier parte del núcleo. Para obtener los argumentos de una función o los valores de las variables locales, debe saber en qué registros o en qué parte de la pila se encuentran, y extraerlos de allí de forma independiente. Para bloquear una llamada de función, debe modificar manualmente el estado del proceso para que el procesador piense que ya ha devuelto el control de la función.
- Las sondas J están en desuso. Jprobes es un complemento para kprobes que le permite interceptar convenientemente llamadas de función. Extraerá independientemente los argumentos de la función de los registros o la pila y llamará a su controlador, que debe tener la misma firma que la función enganchada. El problema es que las jprobes están en desuso y se cortan de los núcleos modernos.
- Gastos indirectos no triviales. Los puntos de interrupción son caros, pero de una sola vez. Los puntos de interrupción no afectan a otras funciones, pero su procesamiento es relativamente costoso. Afortunadamente, la optimización de salto se implementa para la arquitectura x86_64, lo que reduce significativamente el costo de kprobes, pero sigue siendo mayor que, por ejemplo, al modificar la tabla de llamadas del sistema.
- Limitaciones de kretprobes. Los Kretprobes se implementan falsificando la dirección de retorno en la pila. En consecuencia, deben almacenar la dirección original en algún lugar para volver allí después de procesar kretprobe. Las direcciones se almacenan en un búfer de tamaño fijo. En caso de desbordamiento, cuando se ejecutan demasiadas llamadas simultáneas de la función interceptada en el sistema, kretprobes omitirá las operaciones.
- Extrusión desactivada. Dado que kprobes se basa en interrupciones y juegos de malabares con los registros del procesador, para la sincronización todos los manejadores se ejecutan con preferencia deshabilitada. Esto impone ciertas restricciones a los controladores: no puede esperar en ellos: asigne mucha memoria, haga E / S, duerma en temporizadores y semáforos, y otras cosas conocidas.
En el proceso de investigación del tema, nuestros ojos se
centraron en el marco de trabajo, que puede reemplazar a jprobes. Resultó que funciona mejor para nuestras necesidades de interceptación de llamadas de función. Sin embargo, si necesita rastrear instrucciones específicas dentro de las funciones, entonces kprobes no debe descontarse.
Empalme
En aras de la exhaustividad, también vale la pena describir el método clásico de interceptar funciones, que consiste en reemplazar las instrucciones al comienzo de la función con una transición incondicional que conduce a nuestro controlador. Las instrucciones originales se transfieren a otro lugar y se ejecutan antes de volver a la función interceptada. Con la ayuda de dos transiciones, incorporamos (empalmamos) nuestro código adicional en la función, por lo tanto, este enfoque se llama
empalme .
Así es como se implementa la optimización de salto para kprobes. Con el empalme, puede lograr los mismos resultados, pero sin costos adicionales para kprobes y con un control completo de la situación.
Los beneficios del empalme son obvios:
- Requisitos mínimos de kernel. El empalme no requiere ninguna opción especial en el núcleo y funciona al comienzo de cualquier función. Solo necesitas saber su dirección.
- Gastos generales mínimos. Dos transiciones incondicionales: esas son todas las acciones que debe realizar el código interceptado para transferir el control al controlador y viceversa. Dichas transiciones son perfectamente predichas por el procesador y son muy baratas.
Sin embargo, el principal inconveniente de este enfoque nubla seriamente la imagen:
- Dificultad técnica Ella se da vuelta. No puede simplemente tomar y reescribir el código de la máquina. Aquí hay una lista corta e incompleta de tareas a resolver:
- sincronización de la instalación y eliminación de la intercepción (¿qué sucede si la función se llama directamente en el proceso de reemplazar sus instrucciones?)
- omisión de protección en la modificación de regiones de memoria con un código
- Invalidación de caché de CPU después de reemplazar instrucciones
- Desmontaje de instrucciones reemplazables para copiarlas enteras
- comprobar la ausencia de transiciones dentro de la pieza reemplazada
- verificar la capacidad de mover la pieza reemplazada a otra ubicación
Sí, puede espiar kprobes y usar el marco intranuclear livepatch, pero la solución final sigue siendo bastante complicada. Da miedo imaginar cuántos problemas de sueño habrá en cada nueva implementación.
En general, si puede llamar a este demonio, subordinarse solo a los iniciados, y está listo para soportarlo en su código, entonces el empalme es un enfoque completamente funcional para interceptar llamadas de función. Tenía una actitud negativa a la hora de escribir bicicletas, por lo que esta opción seguía siendo una copia de seguridad para nosotros en caso de que no hubiera ningún progreso en absoluto con las soluciones preparadas más fáciles.
Nuevo enfoque con ftrace
Ftrace es un marco de seguimiento de kernel de nivel de función. Se ha desarrollado desde 2008 y tiene una interfaz fantástica para programas de usuario. Ftrace le permite rastrear la frecuencia y la duración de las llamadas a funciones, mostrar gráficos de llamadas, filtrar funciones de interés por plantilla, etc. Puede comenzar a leer sobre las características de ftrace
desde aquí y luego seguir los enlaces y la documentación oficial.
Implementa ftrace en función de las teclas del compilador
-pg y
-mfentry , que insertan la llamada a la función de rastreo especial mcount () o __fentry __ () al comienzo de cada función. Típicamente, en los programas de usuario, esta característica del compilador es utilizada por los perfiladores para rastrear llamadas a todas las funciones. El kernel utiliza estas funciones para implementar el marco ftrace.
Por supuesto, llamar a ftrace desde
cada función no es barato, por lo que la optimización está disponible para arquitecturas populares:
ftrace dinámico . La conclusión es que el núcleo conoce la ubicación de todas las llamadas a mcount () o __fentry __ () y en las primeras etapas de carga reemplaza su código de máquina con
nop , una instrucción especial que no hace nada. Cuando se incluye el rastreo en las funciones requeridas, se vuelven a agregar las llamadas ftrace. Por lo tanto, si no se usa ftrace, su impacto en el sistema es mínimo.
Descripción de las funciones requeridas.
Cada función interceptada puede describirse mediante la siguiente estructura:
struct ftrace_hook { const char *name; void *function; void *original; unsigned long address; struct ftrace_ops ops; };
El usuario debe completar solo los primeros tres campos: nombre, función, original. Los campos restantes se consideran un detalle de implementación. La descripción de todas las funciones interceptadas se puede ensamblar en una matriz y las macros se pueden usar para aumentar la compacidad del código:
#define HOOK(_name, _function, _original) \ { \ .name = (_name), \ .function = (_function), \ .original = (_original), \ } static struct ftrace_hook hooked_functions[] = { HOOK("sys_clone", fh_sys_clone, &real_sys_clone), HOOK("sys_execve", fh_sys_execve, &real_sys_execve), };
Las envolturas sobre las funciones interceptadas son las siguientes:
static asmlinkage long (*real_sys_execve)(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp); static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
Como puede ver, las funciones interceptadas con un mínimo de código adicional. Lo único que requiere una atención cuidadosa son las firmas de funciones. Deben coincidir uno a uno. Sin esto, obviamente, los argumentos se pasarán incorrectamente y todo irá cuesta abajo. Para interceptar llamadas del sistema, esto es menos importante, ya que sus manejadores son muy estables y, para mayor eficiencia, toman los argumentos en el mismo orden en que el sistema se llama a sí mismo. Sin embargo, si planea interceptar otras funciones, debe recordar que
no hay interfaces estables dentro del núcleo .
Inicialización de Ftrace
Primero, necesitamos encontrar y guardar la dirección de la función que vamos a interceptar. Ftrace le permite rastrear funciones por nombre, pero aún necesitamos saber la dirección de la función original para poder llamarla.
Puede obtener la dirección usando
kallsyms , una lista de todos los caracteres en el núcleo. Esta lista incluye
todos los caracteres, no solo exportados para módulos. Obtener la dirección de la función enganchada se parece a esto:
static int resolve_hook_address(struct ftrace_hook *hook) { hook->address = kallsyms_lookup_name(hook->name); if (!hook->address) { pr_debug("unresolved symbol: %s\n", hook->name); return -ENOENT; } *((unsigned long*) hook->original) = hook->address; return 0; }
A continuación, debe inicializar la estructura
ftrace_ops . Es vinculante
el campo es simplemente
funcional , lo que indica una devolución de llamada, pero también necesitamos
establecer algunas banderas importantes:
int fh_install_hook(struct ftrace_hook *hook) { int err; err = resolve_hook_address(hook); if (err) return err; hook->ops.func = fh_ftrace_thunk; hook->ops.flags = FTRACE_OPS_FL_SAVE_REGS | FTRACE_OPS_FL_IPMODIFY; }
fh_ftrace_thunk () es nuestra devolución de llamada que ftrace llamará al rastrear una función. Sobre él más tarde. Las banderas que establezcamos serán necesarias para completar la intercepción. Indican a ftrace que guarde y restaure los registros del procesador, cuyo contenido podemos cambiar en la devolución de llamada.
Ahora estamos listos para permitir la intercepción. Para hacer esto, primero debe habilitar ftrace para la función que nos interese usando ftrace_set_filter_ip (), y luego permitir que ftrace llame a nuestra devolución de llamada usando register_ftrace_function ():
int fh_install_hook(struct ftrace_hook *hook) { err = ftrace_set_filter_ip(&hook->ops, hook->address, 0, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); return err; } err = register_ftrace_function(&hook->ops); if (err) { pr_debug("register_ftrace_function() failed: %d\n", err); ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); return err; } return 0; }
La intercepción se desactiva de manera similar, solo en el orden inverso:
void fh_remove_hook(struct ftrace_hook *hook) { int err; err = unregister_ftrace_function(&hook->ops); if (err) { pr_debug("unregister_ftrace_function() failed: %d\n", err); } err = ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); } }
Una vez completada la llamada a unregister_ftrace_function (), se garantiza la ausencia de activaciones de la devolución de llamada instalada en el sistema (y con ella nuestros envoltorios). Por lo tanto, podemos, por ejemplo, descargar con calma el módulo interceptor, sin temor a que en algún lugar del sistema nuestras funciones se sigan realizando (porque si desaparecen, el procesador se alterará).
Realizar un gancho de función
¿Cómo se realiza realmente la intercepción? Muy simple Ftrace le permite cambiar el estado de los registros después de salir de una devolución de llamada. Al cambiar el registro% rip, un puntero a la siguiente instrucción ejecutable, cambiamos las instrucciones que ejecuta el procesador, es decir, podemos forzarlo a ejecutar una transición incondicional de la función actual a la nuestra. Así tomamos el control.
La devolución de llamada para ftrace es la siguiente:
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); regs->ip = (unsigned long) hook->function; }
Usando la macro container_of (), obtenemos la dirección de nuestra
struct ftrace_hook en la dirección de la
struct ftrace_hook incrustada en ella, después de lo cual reemplazamos el valor de registro% rip en la
struct pt_regs estructura
struct pt_regs con la dirección de nuestro controlador. Eso es todo. Para arquitecturas que no sean x86_64, este registro puede llamarse de manera diferente (como IP o PC), pero la idea es en principio aplicable a ellos.
Tenga en cuenta el
calificador de notrace agregado para la devolución de llamada. Pueden marcar características que no se pueden rastrear con ftrace. Por ejemplo, así es como se marcan las funciones de ftrace que están involucradas en el proceso de rastreo. Esto ayuda a evitar que el sistema se congele en un bucle sin fin al rastrear todas las funciones en el núcleo (ftrace puede hacer esto).
La devolución de llamada ftback generalmente llama con extrusión deshabilitada (como kprobes). Puede haber excepciones, pero no debe confiar en ellas. En nuestro caso, sin embargo, esta restricción no es importante, por lo que solo reemplazamos ocho bytes en la estructura.
La función contenedora, que se llama más adelante, se ejecutará en el mismo contexto que la función original. Por lo tanto, allí puede hacer lo que se permite hacer en la función interceptada. Por ejemplo, si interceptas un controlador de interrupciones, aún no puedes dormir en un contenedor.
Protección de llamadas recursivas
Hay un problema en el código anterior: cuando nuestro contenedor llama a la función original, vuelve a entrar en ftrace, que nuevamente llama a nuestra devolución de llamada, que nuevamente transfiere el control al contenedor. Esta recursión infinita necesita ser interrumpida de alguna manera.La forma más elegante que se nos ocurrió es usar parent_ipuno de los argumentos de la devolución de llamada ftrace, que contiene la dirección de retorno a la función que llamó a la función rastreada. Por lo general, este argumento se usa para construir un gráfico de llamadas a funciones. Podemos usarlo para distinguir la primera llamada de la función interceptada de la repetida.De hecho, al volver a llamarparent_ipdebe apuntar dentro de nuestro contenedor, mientras que al principio, en algún lugar en otro lugar del núcleo. El control debe transferirse solo cuando se llama por primera vez a la función, a todos los demás se les debe permitir ejecutar la función original.La verificación de entrada se puede realizar de manera muy eficiente comparando la dirección con los bordes del módulo actual (que contiene todas nuestras funciones). Esto funciona muy bien si en el módulo solo el contenedor llama a la función interceptada. De lo contrario, debe ser más selectivo.En total, la devolución de llamada correcta de ftrace es la siguiente: static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); if (!within_module(parent_ip, THIS_MODULE)) regs->ip = (unsigned long) hook->function; }
Características distintivas / ventajas de este enfoque:- Bajo gastos generales. Solo algunas restas y comparaciones. Sin spinlocks, lista de pases, etc.
- . . , .
- . kretprobes , ( ). , .
Veamos un ejemplo: escribió el comando ls en la terminal para ver una lista de archivos en el directorio actual. El shell (digamos Bash) usa un par tradicional de funciones fork () + execve () de la biblioteca estándar C para comenzar un nuevo proceso . Internamente, estas funciones se implementan mediante las llamadas al sistema clone () y execve (), respectivamente. Supongamos que interceptamos la llamada al sistema execve () para controlar el inicio de nuevos procesos.En forma gráfica, la intercepción de la función del controlador se ve así: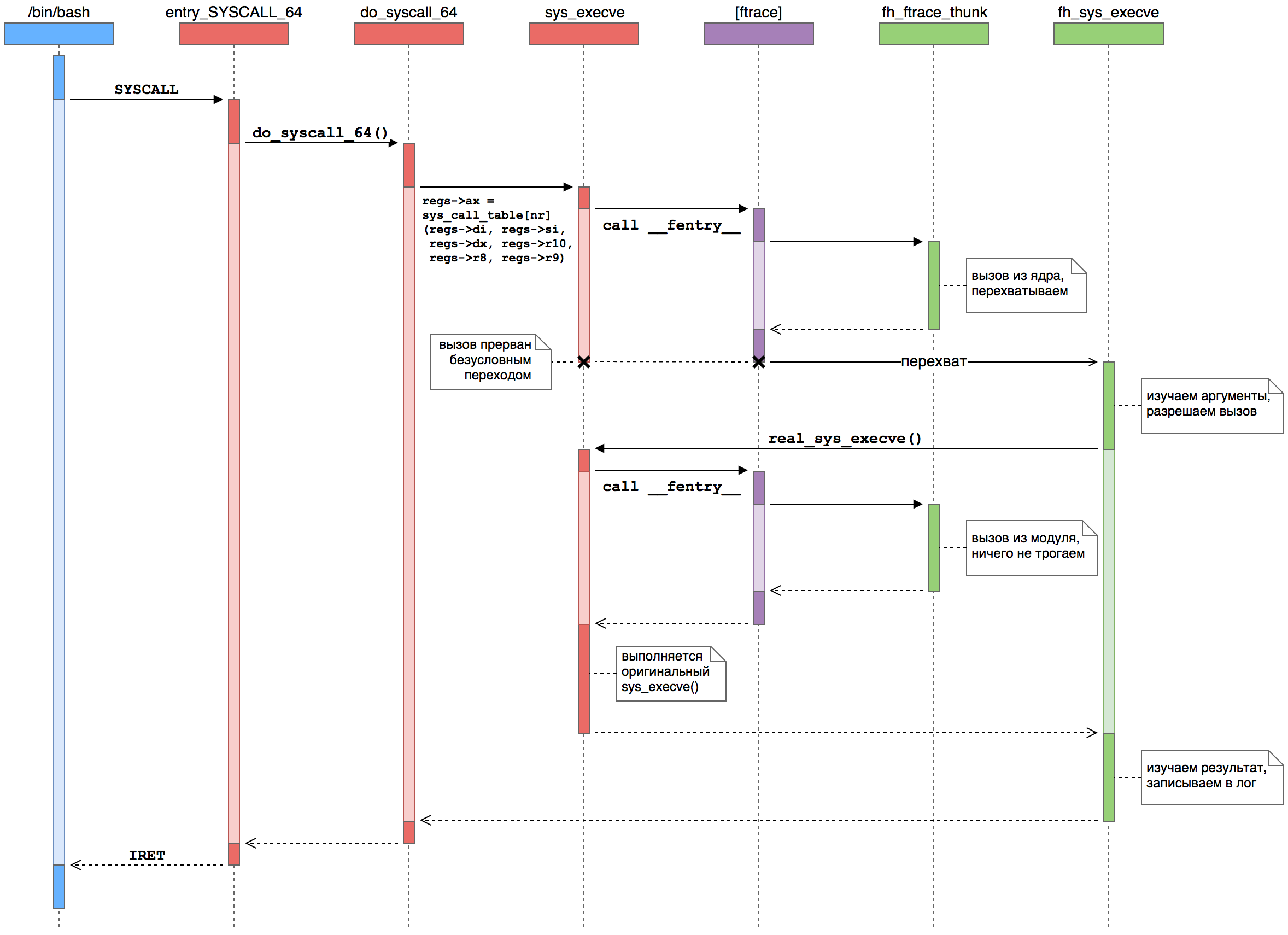 Aquí vemos cómo el proceso del usuario ( azul ) realiza una llamada del sistema al núcleo ( rojo), donde el marco ftrace ( púrpura ) llama a funciones desde nuestro módulo ( verde ).
Aquí vemos cómo el proceso del usuario ( azul ) realiza una llamada del sistema al núcleo ( rojo), donde el marco ftrace ( púrpura ) llama a funciones desde nuestro módulo ( verde ).- El proceso de usuario ejecuta SYSCALL. Con esta instrucción, se transfiere el modo kernel y el control se transfiere al manejador de llamadas del sistema de bajo nivel: entry_SYSCALL_64 (). Es responsable de todas las llamadas al sistema de programas de 64 bits en núcleos de 64 bits.
- . , , do_syscall_64 (), .
sys_call_table — sys_execve ().
- ftrace. __fentry__ (), ftrace. , , nop , sys_execve() .
- Ftrace . ftrace , . , %rip, .
- .
parent_ip , do_syscall_64() — sys_execve() — , %rip pt_regs .
- Ftrace . FTRACE_SAVE_REGS, ftrace
pt_regs . ftrace . %rip — — .
- -. - sys_execve() . fh_sys_execve (). , do_syscall_64().
- . . fh_sys_execve() ( ) . . — sys_execve() , real_sys_execve , .
- . sys_execve(), ftrace . , -…
- . sys_execve() fh_sys_execve(), do_syscall_64(). sys_execve() . : ftrace sys_execve() .
- . sys_execve() fh_sys_execve(). . , execve() , , , . .
- La gerencia vuelve al núcleo. Finalmente, fh_sys_execve () se completa y el control pasa a do_syscall_64 (), que considera que la llamada al sistema se completó como de costumbre. El núcleo continúa su negocio nuclear.
- La gerencia vuelve al proceso del usuario. Finalmente, el núcleo ejecuta la instrucción IRET (o SYSRET, pero para execve () siempre es IRET), configurando registros para el nuevo proceso de usuario y poniendo el procesador central en modo de ejecución de código de usuario. La llamada al sistema (y el inicio de un nuevo proceso) se completa.
Ventajas y desventajas.
Como resultado, obtenemos una forma muy conveniente de interceptar cualquier función en el núcleo, que tiene las siguientes ventajas:- API . . , , . — -, .
- . . - , , , - . ( ), .
- La intercepción es compatible con el rastreo. Obviamente, este método no entra en conflicto con ftrace, por lo que aún puede tomar indicadores de rendimiento muy útiles del núcleo. El uso de kprobes o empalmes puede interferir con los mecanismos de ftrace.
¿Cuáles son las desventajas de esta solución?- Requisitos de configuración del kernel. Para realizar con éxito enlaces de función utilizando ftrace, el núcleo debe proporcionar una serie de características:
- lista de caracteres kallsyms para buscar funciones por nombre
- ftrace framework en general para rastreo
- ftrace opciones de intercepción crítica
. , , , , . , - , .
- ftrace , kprobes ( ftrace ), , , . , ftrace — , «» ftrace .
- . , . , , ftrace . , , .
- Doble llamada ftrace. El enfoque de análisis de puntero descrito anteriormente
parent_ipda como resultado una llamada ftrace nuevamente para funciones enganchadas. Esto agrega un poco de sobrecarga y puede derribar otros rastros que verán el doble de llamadas. Este inconveniente se puede evitar aplicando un poco de magia negra: la llamada ftrace se encuentra al comienzo de la función, por lo que si la dirección de la función original se adelanta en 5 bytes (la longitud de la instrucción de llamada), puede saltar a través de ftrace.
Considere algunas de las desventajas con más detalle.Requisitos de configuración del kernel
Para empezar, el núcleo debe admitir ftrace y kallsyms. Para hacer esto, las siguientes opciones deben estar habilitadas:- CONFIG_FTRACE
- CONFIG_KALLSYMS
Entonces, ftrace debería soportar la modificación dinámica del registro. La opción es responsable de esto.- CONFIG_DYNAMIC_FTRACE_WITH_REGS
Además, el núcleo utilizado debe estar basado en la versión 3.19 o superior para tener acceso al indicador FTRACE_OPS_FL_IPMODIFY. Las versiones anteriores del kernel también pueden reemplazar el registro% rip, pero a partir de 3.19 esto debe hacerse solo después de configurar este indicador. La presencia de un indicador para los núcleos antiguos conducirá a un error de compilación, y su ausencia para los nuevos generará una intercepción inactiva.Finalmente, para realizar la intercepción, la ubicación de la llamada ftrace dentro de la función es crítica: la llamada debe ubicarse al principio, antes del prólogo de la función (donde se asigna espacio para variables locales y se forma un marco de pila). Esta característica de arquitectura se tiene en cuenta por la opciónLa arquitectura x86_64 admite esta opción, pero el i386 no. Debido a las limitaciones de la arquitectura i386, el compilador no puede insertar una llamada ftrace antes del prólogo de la función, por lo tanto, cuando se llama ftrace, la pila de funciones ya está modificada. En este caso, para interceptar, no basta con cambiar el valor del registro% eip; también debe revertir todas las acciones realizadas en el prólogo que difieren de una función a otra.Por esta razón, la intercepción de ftrace no es compatible con la arquitectura x86 de 32 bits. En principio, podría implementarse usando cierta magia negra (generar y ejecutar un "antiprólogo"), pero la simplicidad técnica de la solución se verá afectada, que es una de las ventajas de usar ftrace.Sorpresas no obvias
Durante las pruebas, nos encontramos con una característica interesante : en algunas distribuciones, las funciones de enganche hicieron que el sistema se bloqueara fuertemente. Naturalmente, esto solo sucedió en sistemas distintos a los utilizados por los desarrolladores. El problema tampoco se reprodujo en el prototipo de intercepción original, con ninguna distribución y versiones de kernel.La depuración mostró que el bloqueo ocurre dentro de la función interceptada. Por alguna razón mística, cuando se llamó a la función original dentro de la devolución de llamada ftrace, la dirección parent_ipcontinuó siendo especificada en el código del núcleo en lugar del código de la función de envoltura. Debido a esto, surgió un bucle sin fin, ya que ftrace llamó a nuestro contenedor una y otra vez sin realizar ninguna acción útil.Afortunadamente, teníamos tanto código que funcionaba como roto, por lo que encontrar las diferencias era solo cuestión de tiempo. Después de unificar el código y desechar todo lo innecesario, las diferencias entre las versiones se localizaron en una función de contenedor.Esta opción funcionó: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
pero este - colgó el sistema: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_devel("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_devel("execve() returns: %ld\n", ret); return ret; }
¿Cómo resulta que el nivel de registro afecta el comportamiento? Un estudio cuidadoso del código de máquina de las dos funciones rápidamente aclaró la situación y causó la sensación de que el compilador tenía la culpa. Por lo general, está en la lista de sospechosos en algún lugar cerca de los rayos cósmicos, pero esta vez no.La cosa, como resultó, es que las llamadas a pr_devel () se expanden en el vacío. Esta versión de la macro printk se utiliza para iniciar sesión durante el desarrollo. Tales entradas de registro no son interesantes durante la operación, por lo tanto, se cortan automáticamente del código si no se declara la macro DEBUG. Después de eso, la función para el compilador se convierte en esto: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { return real_sys_execve(filename, argv, envp); }
Y aquí la optimización entra en escena. En este caso se trabajó denominadas llamadas de la cola de optimización (optimización de llamada de cola). Permite que el compilador reemplace una llamada de función honesta con un salto directo a su cuerpo si una función llama a otra e inmediatamente devuelve su valor. En el código de máquina, una llamada honesta se ve así: 0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: ff 15 00 00 00 00 callq *0x0(%rip) b: f3 c3 repz retq
y no funciona, así: 0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax c: ff e0 jmpq *%rax
La primera instrucción CALL es la misma llamada __fentry __ () insertada por el compilador al comienzo de todas las funciones. Pero luego, en el código normal, puede ver la llamada a real_sys_execve (mediante el puntero en la memoria) a través de la instrucción CALL y regresar desde fh_sys_execve () utilizando la instrucción RET. El código roto va a la función real_sys_execve () directamente usando JMP.La optimización de las llamadas de cola le permite ahorrar un poco de tiempo en la formación de un marco de pila "sin sentido", que incluye la dirección de retorno almacenada en la pila por la instrucción CALL. Sin embargo, para nosotros, la exactitud de la dirección del remitente desempeña un papel fundamental: la usamos parent_ippara tomar una decisión sobre la intercepción. Después de la optimización, la función fh_sys_execve () ya no guarda la nueva dirección de retorno en la pila, queda la anterior, apuntando al núcleo. Por lo tantoparent_ipcontinúa apuntando dentro del núcleo, lo que finalmente conduce a la formación de un bucle infinito.Esto también explica por qué el problema solo se reproduce en algunas distribuciones. Al compilar módulos, diferentes distribuciones usan diferentes conjuntos de indicadores de compilación. En distribuciones en dificultades, la optimización de llamadas de cola se habilitó de forma predeterminada.La solución al problema para nosotros fue deshabilitar la optimización de llamadas de cola para todo el archivo con funciones de contenedor: #pragma GCC optimize("-fno-optimize-sibling-calls")
Conclusión
¿Qué más puedo decir? Desarrollar código de bajo nivel para el kernel de Linux es divertido. Espero que esta publicación le ahorre a alguien un poco de tiempo para elegir qué usar para escribir su mejor antivirus del mundo.Si desea experimentar con la intercepción usted mismo, puede encontrar el código completo del módulo del núcleo en Github .