Hola nombre de usuario Todos los días nos enfrentamos a la búsqueda de varios datos. Casi todos los sitios web con mucha información ahora tienen una búsqueda. La búsqueda se realiza en computadoras domésticas, en teléfonos móviles, en varios tipos de software. Por supuesto, si le preguntas a cualquier desarrollador acerca de la búsqueda en términos de tecnología, inmediatamente se te ocurrirá buscar elástico, lucene o sphinx. Hoy quiero mirar con usted "bajo el capó" de una búsqueda de texto completo y descubrir una primera aproximación de cómo funciona, utilizando el ejemplo de hh.ru.
 Descargo de responsabilidad: este artículo no es el único punto de vista verdadero y sirve solo como un punto de introducción para una familiarización inicial con el trabajo de búsqueda de texto y algunas opciones para implementar sus partes individuales.
Descargo de responsabilidad: este artículo no es el único punto de vista verdadero y sirve solo como un punto de introducción para una familiarización inicial con el trabajo de búsqueda de texto y algunas opciones para implementar sus partes individuales.Si observa los detalles de la búsqueda, además de la parte obvia en forma de una cadena de búsqueda, puede ver mucho más:
- pista (ella sugiere)
- contador de resultados de búsqueda (contador),
- varios tipos de clasificación (clasificación),
- facetas: características agrupadas de documentos, por ejemplo, el metro en el que se encuentra una vacante, que también realiza la función de filtros (filtros),
- sinónimos
- paginación
- fragmento (fragmento): una pequeña descripción del documento en la emisión,
- etc.

Y todo esto tiene un propósito: satisfacer la necesidad del usuario de encontrar la información correcta de la manera más rápida y relevante posible. Por ejemplo, el filtrado es importante para limitar los resultados de búsqueda, en nuestro caso puede ser un filtro por la experiencia, ubicación o empleo del candidato. Las facetas son útiles para mostrar cuántas vacantes hay en cada rango de salario. También es importante complementar las consultas y documentos con sinónimos para que, a pedido del "desarrollador de Java", puedan encontrar documentos de "desarrollador de Java".
Además de la búsqueda en sí, siempre hay una gran cantidad de componentes que facilitan la vida del usuario: un tutor responsable de corregir los errores o una respuesta más segura que genera consultas más adecuadas cuando interactúa con la barra de búsqueda. En algunos casos, es importante poder reformular la solicitud. Por ejemplo, mueva una parte de la solicitud a los filtros: desde la solicitud "Programador de Moscú", Moscú se puede sacar al filtro por ciudad.
1. Básico
Ahora al grano. La búsqueda en sí se divide en dos grandes etapas:
- indexación (procesamiento de documentos y disposición de acuerdo con estructuras de índice especiales, para que pueda realizar rápidamente la búsqueda en sí),
- búsqueda (aplicación de filtros, búsqueda booleana, clasificación, etc.).
1.1. Indexación
Una ligera digresión lírica. Además, presentaré el concepto de término, ya que es habitual llamar a la unidad mínima de indexación y consulta. Esta es la unidad que se almacenará en el diccionario índice. Puede ser una palabra reducida a su forma normal de palabra o base, número, correo electrónico, letra n-gramas u otra cosa. Normalmente, un término incluye un campo en el que se indexa o en el que se realiza una búsqueda.
Primero, debe convertir los documentos de entrada en un conjunto de términos y filtrar palabras de detención. Pueden ser como palabras frecuentes: preposiciones, conjunciones, interjecciones y otras cosas, por ejemplo, caracteres especiales que no queremos buscar. Para que la búsqueda funcione con diferentes formas de palabras, durante el proceso de indexación usualmente traemos todas las palabras a un estado básico. Por lo general, se utiliza uno de los dos procedimientos: derivación: el proceso de aislar la base de una palabra (desarrollo-> desarrollo) o lematización: el proceso de llevar una palabra a su forma normal (habilidades-> habilidad).
1.2 Estructuras de índice
La forma más popular de representar un índice es un índice invertido. De hecho, este es un tipo de tabla hash, donde la clave es un término, y el valor es una lista de documentos (generalmente una lista de identificación de documento llamada lista de publicaciones) en la que este término está presente. Por lo general, un índice invertido consta de dos partes: un diccionario (diccionario de términos) y listas de documentos para cada término (lista de publicaciones):

Además, el índice puede contener información sobre las posiciones de los términos en el documento (índice de posición), que será útil al buscar términos a una cierta distancia, en particular con consultas de frases, sobre la frecuencia de los términos, lo que ayudará a clasificar y construir un plan de consulta. Pero más sobre eso a continuación.
1.2.1 Diccionario de términos
El diccionario almacena todos los términos que existen en el índice y está diseñado para encontrar rápidamente enlaces a una lista de documentos. Hay varias opciones para almacenar un diccionario:
- Una tabla hash, donde el término es la clave, y el valor es un enlace a una lista de documentos de este término.
- Una lista ordenada por la cual puede buscar por búsqueda binaria.
- Árbol de prefijo (trie).
La forma más óptima es la última opción, porque Tiene varias ventajas. En primer lugar, en una gran cantidad de términos, el árbol de prefijos ocupará mucha menos memoria, porque las partes repetidas de los prefijos se almacenarán solo una vez. En segundo lugar, inmediatamente tenemos la oportunidad de hacer solicitudes de prefijo. Y en tercer lugar, dicho árbol puede comprimirse combinando partes no ramificadas.
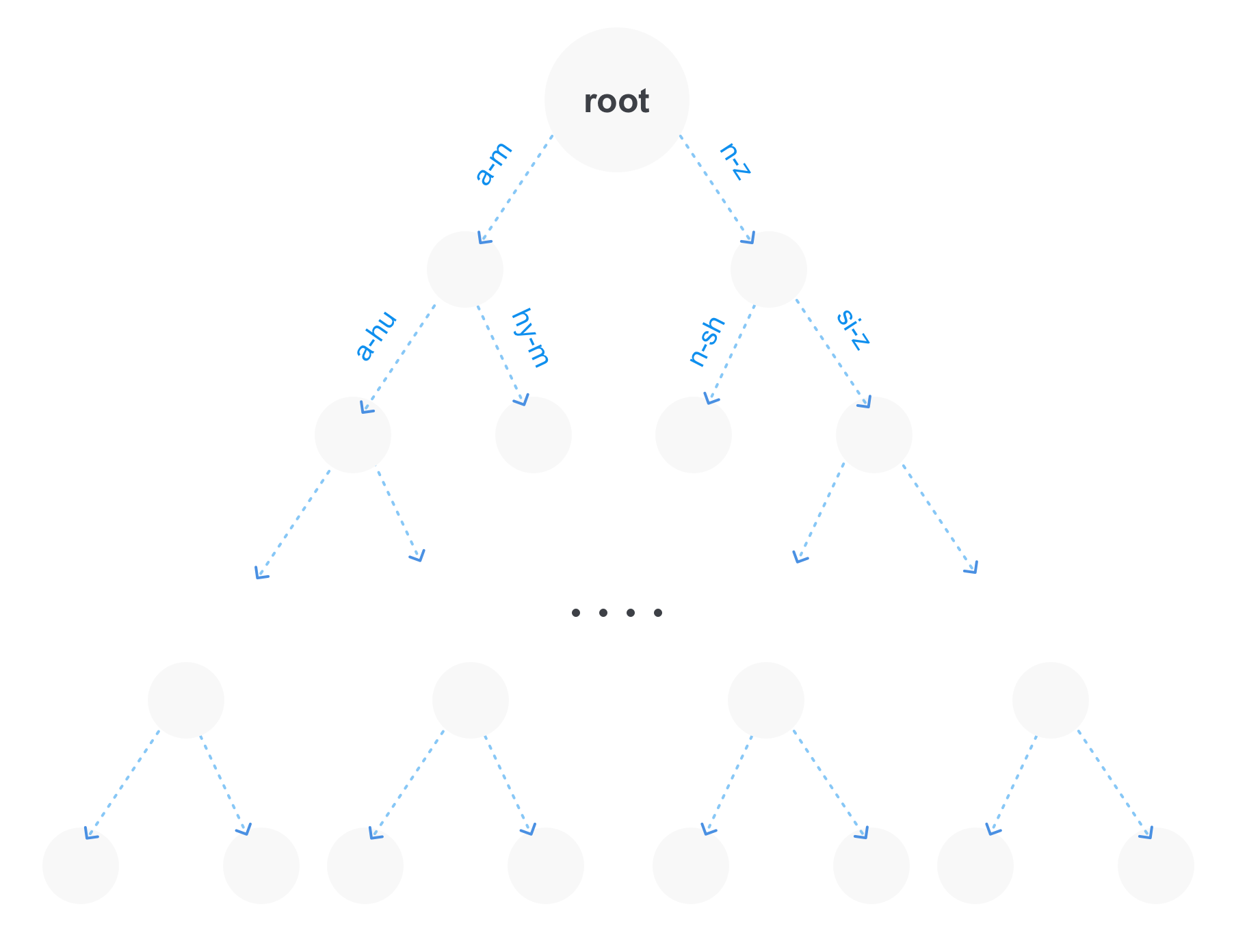
Por supuesto, un árbol de prefijos puede no ser la única estructura para almacenar términos en un índice. Por ejemplo, un árbol de sufijos también puede estar cerca, lo que a su vez será más óptimo para consultas con comodines (consultas de la forma po * sql).
1.2.2 Lista de publicaciones
La lista de documentos es una lista ordenada de identificadores de documentos, que permite realizar algunas optimizaciones con ella. Por lo general, almacena en sí mismo no solo una lista de documentos en los que aparece el término, sino también las posiciones (publicaciones) en las que aparece. Esto resuelve varios problemas a la vez: sabemos de inmediato cuántas veces aparece una palabra en un documento, podemos hacer frases y consultas con una cierta distancia entre los términos, cruzando varias listas de documentos a la vez y observando las posiciones de los términos.

Por ejemplo, en esta lista por el término
scala en el sexto documento del
título, la palabra aparece 4 veces, en las posiciones 2, 15, 18 y 25.
1.2.3 Documentos con múltiples campos
La mayor parte del documento consta de varios campos, al menos desde el nombre del documento y su cuerpo. Esto ayuda cuando se buscan partes individuales del documento y cuando el término es significativo al clasificar (por ejemplo, el término que aparece en el título puede considerarse más significativo).
Además, en el índice, generalmente no solo se almacenan los campos de texto, sino que también se pueden almacenar signos de documentos, algunos valores numéricos, etc. El almacenamiento en el índice generalmente toma la forma de {field-term}.

Por ejemplo, si toma una vacante, tendrá varios campos a la vez: nombre, descripción, empresa, nómina, ciudad y la experiencia necesaria. Esto es necesario para que el usuario pueda buscar convenientemente no solo por el nombre y el texto de la empresa, sino que también pueda filtrar por salario y experiencia, ver cuántas vacantes hay en su ciudad y ciudades vecinas, o incluso buscar vacantes para una empresa en particular.
1.3 Compresión y optimización de índices
La velocidad del trabajo es importante para la búsqueda, por lo tanto, la mayoría de las operaciones de búsqueda de índice generalmente se realizan en RAM. Para hacer esto, es muy importante aplicar una serie de optimizaciones al índice, que lo ajustará a un tamaño de memoria limitado. Además de esto, generalmente se aplican varias optimizaciones, que le permiten moverse por el índice a una velocidad más alta cuando busca, omitiendo partes innecesarias de él.
1.3.1 Compresión Delta
Como recordamos que la lista de documentos por término (también conocida como lista de publicaciones) está ordenada, la primera idea de cómo comprimirla es hacer una lista con los desplazamientos de identificación de los documentos en lugar de la lista con documentos de identificación. En una lista específica de 6 identificadores, se verá así:

Por lo tanto, avanzando por la lista, siempre calcularemos el identificador actual a partir del valor anterior obtenido. Por ejemplo, al segundo desplazamiento 3, agregamos el primer valor 2 y obtenemos id 5, al tercer 4 agregamos 5 y obtenemos 9 y así sucesivamente. Con una gran cantidad de documentos, esto funciona muy bien, especialmente en combinación con otro método de compresión: registrar números de formato variable.
1.3.2 VarByte y VarInt
Esta es una forma de almacenar cada elemento de la lista individual en la memoria para que ocupe la cantidad mínima de espacio. Por ejemplo, si las primeras tres compensaciones caben en solo 1 byte, entonces no hay necesidad de tomar más. Teniendo en cuenta que nuestra lista no contiene documentos de identificación, sino deltas, la compresión será muy efectiva. En esta representación de números, el primer bit de cada byte es el indicador de si la representación del número actual termina en este byte.

Si el primer bit del byte 0 es el último byte del número, si 1 no lo es.
1.3.3 Saltar lista / Saltar tabla
Una lista de omisión es una de las estructuras para moverse rápidamente por una lista de documentos de un determinado término, omitiendo una parte innecesaria de la lista. La idea es almacenar enlaces a elementos distantes de la lista en el disco frente a la lista misma, porque después de la compresión no podemos decir dónde se ubicarán exactamente los documentos 100 o 200. Por ejemplo, esto es conveniente cuando hay una consulta de dos términos, donde un término se encontrará con frecuencia, y el segundo, por el contrario, será raro, y la lista de documentos comenzará solo con la identificación número 200 del documento. Luego, si hay una lista con pases para la primera lista, podemos ahorrar tiempo al movernos y omitir inmediatamente el bloque innecesario de identificadores.

1.4 Solicitudes
1.4.0 Consulta de plazo
El tipo de solicitud más simple en el que solo necesitamos encontrar la lista apropiada de documentos y emitir documentos ordenados después de la clasificación.
Por ejemplo, de esta manera encontramos una lista de posiciones para
Java :

1.4.1 Consultas booleanas (y, o, no)
La búsqueda booleana es una de las partes más importantes en la recuperación de información que encontramos en todas partes. Toda la búsqueda booleana se basa en una combinación de AND, OR y NOT. Por ejemplo, cuando buscamos una consulta en dos palabras:
java android , de hecho, en una búsqueda simple, se convertirá en
java AND android . Y esto significa que queremos encontrar todos los documentos que contienen ambas palabras.
Vale la pena mencionar de inmediato cómo se mueve por la lista de documentos. Dado que las listas de documentos para cada término están ordenadas, generalmente hay dos formas de desplazarse por las listas: desplazarse secuencialmente por los documentos, pasarlos uno por uno o pasar directamente a un documento específico, omitiendo los que no son necesarios (por ejemplo, cuando la primera lista es mucho más pequeña) , y no necesitamos pasar por un gran bloque de documentos en la segunda lista). En este caso, primero usamos el puntero de los punteros de salto para que la segunda lista se mueva lo más cerca posible de la identificación del documento deseado, y luego nos movemos a él linealmente.
En el momento de la búsqueda, sucede lo siguiente: en el índice de los términos java y android hay listas de documentos, luego se hace una intersección en ellos, es decir, encontramos documentos que contienen ambos términos. Con esta búsqueda, ambos métodos para moverse por las listas se utilizan para cruzar más rápido.

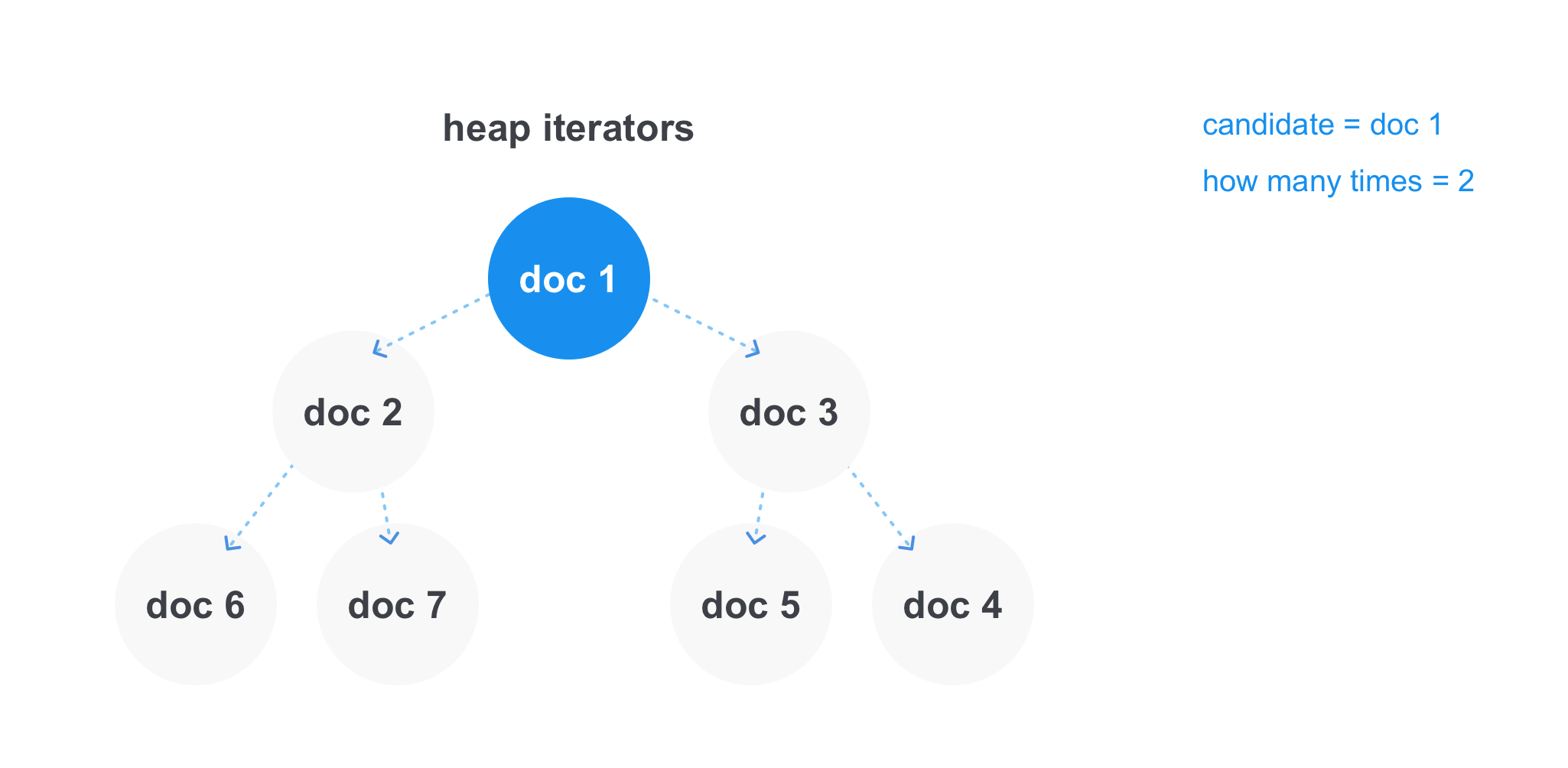
Con las consultas OR del formulario java OR scala, donde necesitamos encontrar todos los documentos que contienen al menos uno de los términos, la situación es diferente: aquí no necesitamos que el término esté en todas las listas de documentos a la vez. Pero hay consultas con varios operadores OR, y luego puede ocurrir la condición para un número mínimo de coincidencias, por ejemplo, puede haber una consulta java OR scala O cotlin O clojure con al menos dos coincidencias, y luego deberíamos mostrar todos los documentos que contienen al menos dos palabras de la consulta .
En este caso, el montón funciona de manera más eficiente. Podemos almacenar enlaces a iteradores de cada una de las listas y obtener el elemento mínimo para el tiempo constante. Después de tomar el elemento mínimo, eliminamos el iterador del montón, damos un paso adelante y lo agregamos nuevamente al montón. Puede almacenar por separado el candidato actual que se agregará al resultado y al contador, cuántas veces se reunió y en el momento en que el candidato diferirá del elemento mínimo en el montón, vea si pasamos por el número mínimo de coincidencias en la operación. Y agregue a la lista final de resultados o descarte el documento.
1.4.2 Prefijo / comodines
A veces queremos encontrar todos los documentos que contienen una palabra que comienza con un prefijo específico. En tales casos, la solicitud de prefijo nos ayudará, que se verá como
jav * . Una solicitud de prefijo funciona muy bien cuando el diccionario se implementa en un árbol de prefijos, y luego llegamos al anidamiento del prefijo y tomamos todos los términos que se encuentran a continuación.
1.4.3 Consultas sobre frases y consultas cercanas
Hay momentos en los que necesita encontrar la frase completa, por ejemplo, "desarrollador de Java", o encontrar palabras entre las cuales no habrá más que unas pocas palabras, por ejemplo, "Java" y "desarrollador", entre las cuales no hay más de 2 palabras, para que pueda encontrar documentos que contengan java android kotlin developer. Para esto, se utilizan adicionalmente listas de posiciones de palabras en cada documento.

En el momento de cruzar las listas de documentos, todo es igual que con la operación AND. Pero después de que el documento se encuentra en ambas listas, se realiza una verificación adicional: que los términos están a la distancia correcta entre sí, por la diferencia en la posición (posición).
1.4.4 Plan de solicitud
Por lo general, antes de la ejecución de la solicitud en sí, se construye su plan. Esto sucede para optimizar la ejecución de la solicitud y hacer optimizaciones tales como una lista con omisiones para la lista de documentos.
La forma más fácil de optimizar su consulta es cruzar las listas de documentos en orden creciente. Por lo tanto, no desperdiciaremos el desperdicio de documentos de listas grandes que no están en listas pequeñas.
Por ejemplo, analicemos la consulta
android AND java AND sql . Digamos que hay 10 documentos en la lista de Android, en sql - 20 y en java - 100. En este caso, es mejor cruzar primero las listas más pequeñas, y la consulta optimizada se verá como
(android AND sql) AND java .
En el caso de OR, lo más simple es contar el número de documentos en la intersección como la suma de dos listas potencialmente intersectadas.
1.4.5 Extensión de consulta - Sinónimos
Además de lo que el usuario ingresa en la barra de búsqueda, generalmente la búsqueda intenta expandir la consulta para encontrar documentos más relevantes. Se puede usar mucho para expandir la búsqueda: el historial de consultas del usuario, algunos datos personalizados sobre él y más. Pero además de todo esto, también hay una forma universal de expandir la solicitud: sinónimos.
En este caso, al escribir documentos en el índice, el término se reemplaza con un "enlace" en el diccionario de sinónimos:
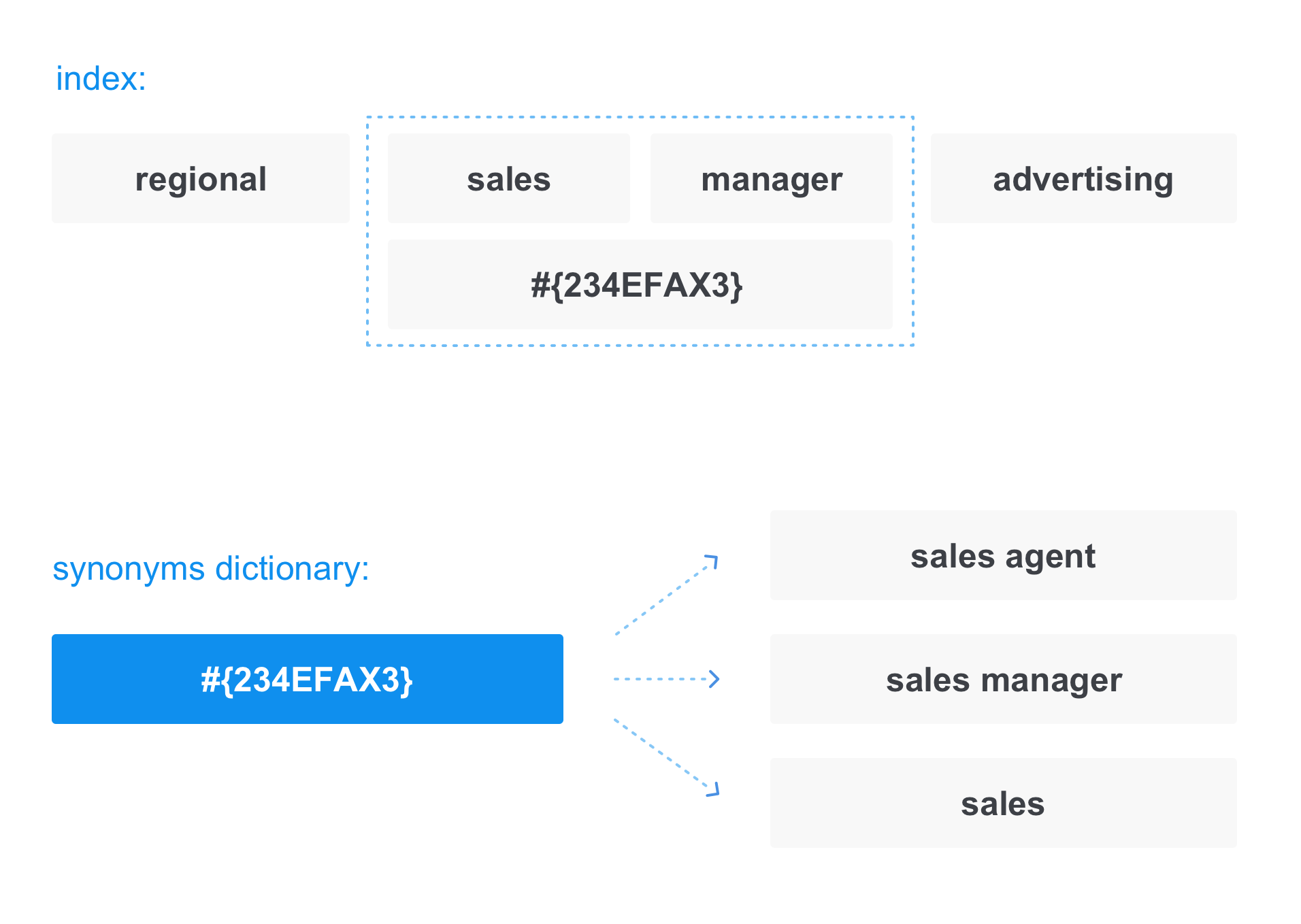
Lo mismo sucede al convertir una solicitud. Por ejemplo, cuando solicitamos un
gerente de ventas , la solicitud en realidad se ve así:

Por lo tanto, en la respuesta recibiremos no solo los documentos que contienen el gerente de ventas, sino también aquellos que contienen el agente de ventas y las ventas.
1.5 Filtrado
1.5.1 Filtro de rango rápido
A veces queremos filtrar algo por un rango de valores, por ejemplo, por experiencia en años. Supongamos que queremos encontrar todas las vacantes con la experiencia requerida de 3 a 11 años. La primera decisión es hacer una solicitud con todas las opciones del rango, combinándolas a través de OR. Pero el problema es que puede haber demasiados valores. Una forma de resolver este problema es registrar el valor con varias precisión a la vez:

En este caso, almacenaremos 5 valores de precisión: un año (lo consideraremos como el valor inicial), dos, cuatro, ocho y dieciséis.
Luego, al grabar, sucederá lo siguiente: por ejemplo, al grabar un documento con un requisito de experiencia de 6 años, registramos el valor inmediatamente con toda precisión:

Al filtrar "de 3 a 11 años", sucede lo siguiente: seleccionamos solo los valores que necesitamos en la precisión requerida, y obtenemos solo 3 valores en lugar de 8 y obtenemos la consulta
(valor real == 3) OR (precisión 4 == 4) OR (precisión 4 == 8)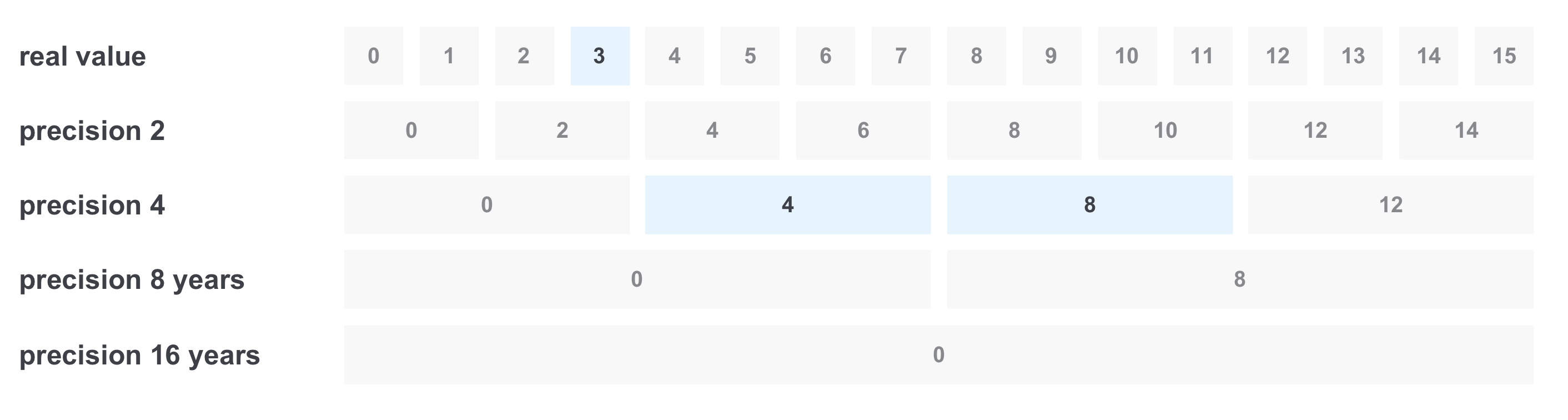
1.5.2 Máscaras de bits
Las máscaras de bits son una parte integral de un índice. El uso más importante es el filtrado de documentos eliminados. Cuando elimina un documento del índice, la eliminación física no ocurre de inmediato. Se escribe una estructura especial al lado del índice, donde cada bit significa la identificación del documento en el índice, y cuando se elimina, se eleva un bit, y al buscar, estos documentos se filtran y no caen en la salida.
También puede usar máscaras de bits para establecer permisos para cada usuario para ciertos documentos y almacenar en caché filtros populares individuales. Entonces, por lo general, las máscaras de bits se almacenan por separado del índice.
Por ejemplo, tenemos filtros populares: la ciudad de Moscú, solo a tiempo parcial, sin experiencia laboral. Luego, antes de la solicitud, podemos obtener las máscaras de bits ya guardadas para estos documentos, agregarlas y obtener la máscara de bits final, que documentos pasan por estos tres filtros, ahorrando así tiempo en el filtrado.

2. Ranking
Como recordamos, la tarea principal de la búsqueda es obtener la información más relevante en el tiempo mínimo. Y en esto seremos ayudados por la clasificación de documentos después de filtrar los documentos por consulta de texto y aplicar los filtros y derechos necesarios.
La forma más fácil y económica de clasificar es simplemente ordenar los documentos por fecha. En algunos sistemas, esto se hizo anteriormente, por ejemplo, en las noticias o en anuncios de bienes raíces, por lo que al usuario se le mostraron primero los últimos documentos.
A veces, se puede usar un modelo de clasificación por la cantidad de palabras encontradas en un documento, por ejemplo, cuando no hay tantos documentos y queremos encontrar todos los documentos en los que se encuentra al menos una de las palabras de consulta. En este caso, aquellos documentos en los que se encuentran todas las palabras de la consulta o más de ellas serán más relevantes.
Por supuesto, en la actualidad, estos métodos ya se han vuelto irrelevantes, y es más probable que se puedan atribuir a la historia del problema.
2.1 TF-IDF
TF-IDF (término frecuencia - frecuencia de documento inversa) es una de las fórmulas de clasificación más básicas y más utilizadas. La esencia de la fórmula es reducir los términos utilizados en todas partes, por ejemplo, preposiciones e interjecciones, y hacer términos más significativos que sean raros, mostrando así los primeros documentos con términos más raros y más significativos de la consulta. Ahora separemos la fórmula en partes:
TF (frecuencia de término) es la frecuencia del término que aparece en el documento. Se calcula simplemente:
TF term `java` = número de término` java` en el documento / número de todos los términos en el documento
IDF (frecuencia de documento inversa) : la inversa de la frecuencia con la que aparece la palabra en la colección de documentos. Ayuda a reducir el peso de las palabras de uso común.
IDF (`java`) = log (número de documentos en la colección / número de documentos en los que aparece el término` java`)Además, para obtener el TF-IDF del término java, solo necesitamos multiplicar los valores de TF e IDF obtenidos. , , . , , developer , , java developer .
2.2
, , . , , , .
2.3 BM25 BM*
BM25 (Okapi best match 25) TF-IDF . BM25F, ( ).
2.4
, :
- DFR (divergence from randomness),
- IBS (information-based models),
- LM Dirichlet,
- Jelinek-Mercer.
2.5
, , . ,
.
2.6 Top k
, . , , .
, .
top k .
— . k, k
* . heap. n*log(n) k.
. , , , 10 12, score 10 score . , n — (n*page size) .
3.
3.1
— . , .
, : , , . , . . ( , ). (merge).
, , :

. , , , - .
3.2 (megre)
— . «» — . , , ( ).

, , , . :
4.
, , . , - (, . .). , , , .

4.1
(, hh , ), . .
, , . -, , . -, , , .
4.2
, . , .
, hh,
, , - :
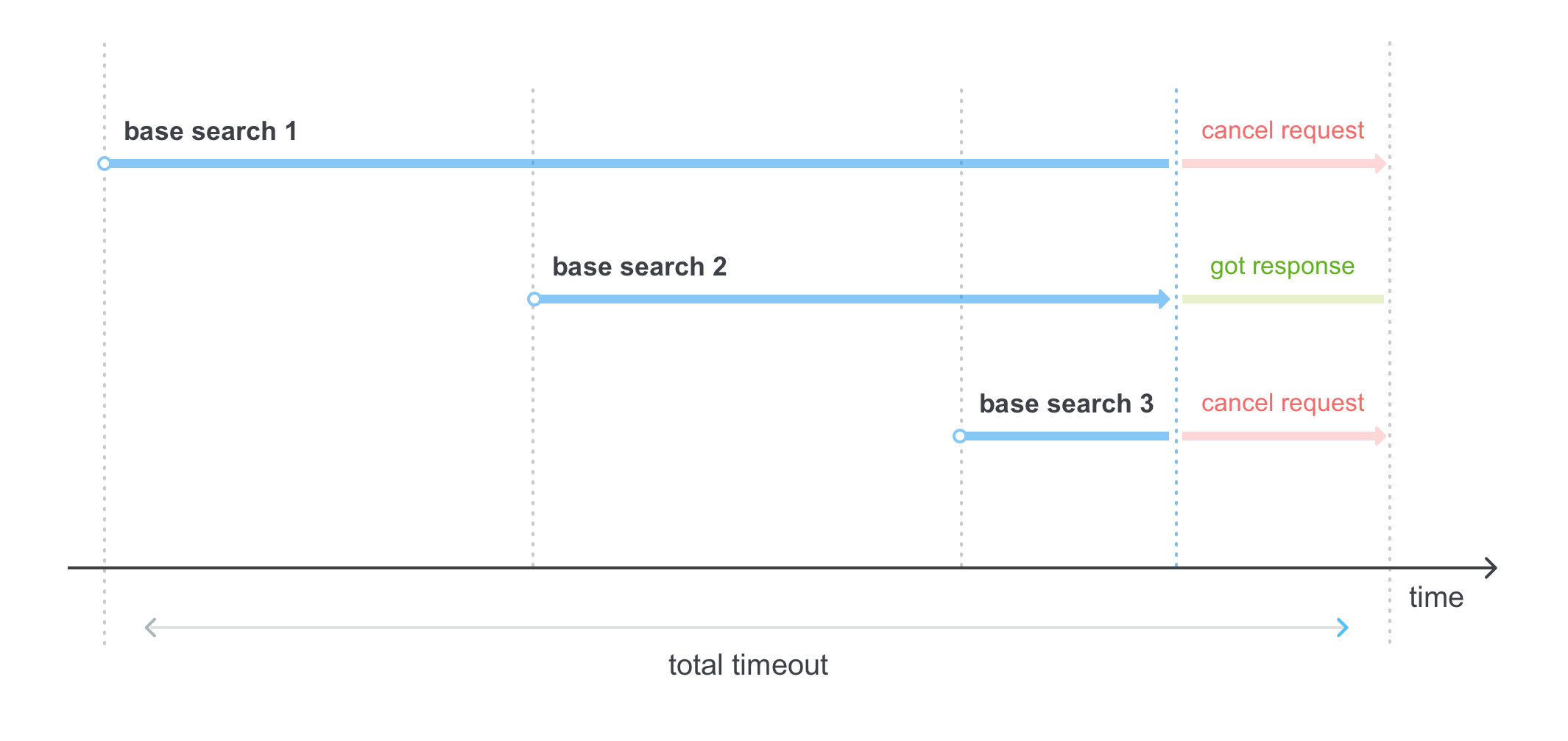
5. …
, , , . , : , , , , , (highlight), . , , , top k .
:
Eso es todo, gracias a todos por su atención, es interesante escuchar sus comentarios y preguntas.PS
Me gustaría expresar mi agradecimiento a gdanschin por ayudarme a escribir este artículo.