El
sistema antiplagio es un motor de búsqueda especializado. Como corresponde a un motor de búsqueda, con su propio motor e índices de búsqueda. Nuestro mayor índice en términos de cantidad de fuentes se encuentra, por supuesto, en Internet en ruso. Hace mucho tiempo decidimos que pondríamos en este índice todo lo que es texto (y no una imagen, música o video), está escrito en ruso, tiene un tamaño superior a 1 kb y no es un "casi duplicado" de algo que Ya en el índice.
Este enfoque es bueno porque no requiere pretratamientos complejos y minimiza los riesgos de "salpicar al bebé con agua", omitiendo un documento del que el texto puede ser prestado. Por otro lado, como resultado, sabemos poco qué documentos están finalmente en el índice.
A medida que el índice de Internet crece, y ahora, por un segundo, ya son más de 300 millones de documentos
solo en ruso , surge una pregunta completamente natural: ¿hay muchos documentos realmente útiles en este basurero?
Y como nosotros (
yury_chekhovich y
Andrey_Khazov ) tomamos esta reflexión, entonces ¿por qué no respondemos al mismo tiempo algunas preguntas más? ¿Cuántos documentos científicos están indexados y cuántos no científicos? ¿Cuál es la proporción de artículos científicos entre diplomas, artículos, resúmenes? ¿Cuál es la distribución de documentos por tema?

Como estamos hablando de cientos de millones de documentos, es necesario utilizar medios de análisis automático de datos, en particular, tecnología de aprendizaje automático. Por supuesto, en la mayoría de los casos, la calidad de la evaluación experta es superior a los métodos de máquina, pero sería demasiado costoso atraer recursos humanos para resolver una tarea tan extensa.
Entonces, necesitamos resolver dos problemas:
- Cree un filtro "científico", que, por un lado, le permite descartar automáticamente documentos que no están en estructura y contenido, y por otro lado determina el tipo de documento científico. Inmediatamente haga una reserva que bajo el término "científico" de ninguna manera se refiere al significado científico o la confiabilidad de los resultados. La tarea del filtro es separar los documentos que tienen la forma de un artículo científico, disertación, diploma, etc. de otros tipos de textos, a saber, ficción, artículos periodísticos, artículos de noticias, etc.
- Implemente una herramienta para rubricar documentos científicos que relacione el documento con una de las especialidades científicas (por ejemplo, Física y Matemáticas , Economía , Arquitectura , Estudios Culturales , etc.).
Al mismo tiempo, necesitamos resolver estos problemas trabajando exclusivamente con el respaldo textual de los documentos, sin usar sus metadatos, información sobre la ubicación de los bloques de texto e imágenes dentro de los documentos.
Vamos a ilustrar con un ejemplo. Incluso una mirada superficial es suficiente para distinguir un
artículo científico.
de, por ejemplo, un
cuento de hadas para niños .

Pero si solo hay una capa de texto (para los mismos ejemplos), debe leer el contenido.
Filtro científico y clasificación por tipo
Resolvemos las tareas secuencialmente:
- En la primera etapa, filtramos los documentos no científicos;
- En la segunda etapa, todos los documentos que se han identificado como científicos, se clasifican por tipo: artículo, disertación de candidatos, resumen de doctorado, diploma, etc.
Se parece a esto:
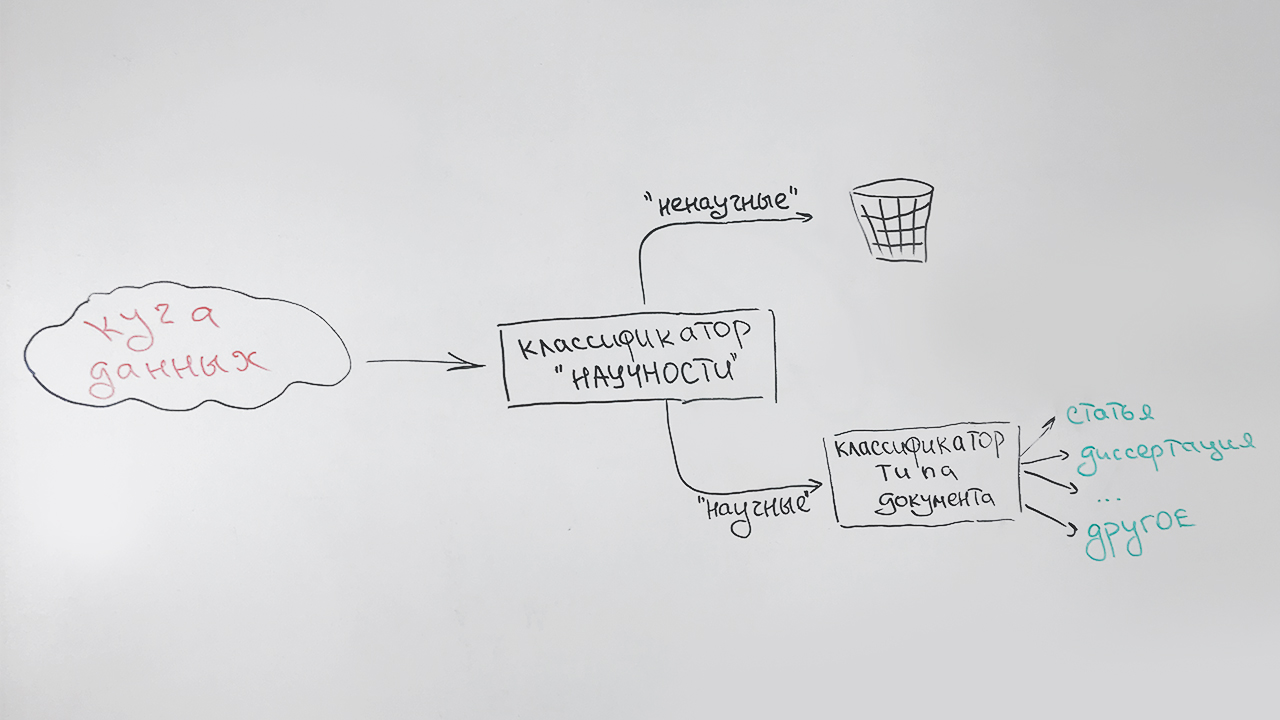
Se asigna un tipo especial (indefinido) a los documentos que no se pueden atribuir de manera confiable a ningún tipo (principalmente estos son documentos cortos: páginas de sitios científicos, resúmenes de resúmenes). Por ejemplo, esta publicación se atribuirá a este tipo, que tiene algunos signos de carácter científico, pero no es similar a ninguno de los anteriores.
Hay otra circunstancia que debe tenerse en cuenta. Esta es una alta velocidad del algoritmo y bajos requisitos de recursos; sin embargo, nuestra tarea es auxiliar. Por lo tanto, utilizamos una descripción indicativa muy pequeña de los documentos:
- longitud promedio de una oración en un texto;
- cuota de palabras vacías en relación con todas las palabras del texto;
- índice de legibilidad ;
- porcentaje de signos de puntuación en relación con todos los caracteres del texto;
- el número de palabras de la lista ("resumen", "disertación", "diploma", "certificación", "especialidad", "monografía", etc.) en la parte inicial del texto (el atributo es responsable de la página de título);
- el número de palabras de la lista ("lista", "literatura", "bibliográfica", etc.) en la última parte del texto (el atributo es responsable de la lista de literatura);
- la proporción de letras en el texto;
- longitud de palabra promedio;
- El número de palabras únicas en el texto.
Todos estos signos son buenos porque se calculan rápidamente. Como clasificador, utilizamos el algoritmo de bosque aleatorio (
bosque aleatorio ), un método de clasificación popular en el aprendizaje automático.
Con evaluaciones de calidad en ausencia de una muestra marcada por expertos, es difícil, por lo tanto, dejamos que el clasificador entre en la colección de artículos de la biblioteca electrónica científica
Elibrary.ru . Asumimos que todos los artículos serán identificados como científicos.
100% de resultado? Nada de eso, solo el 70%. ¿Quizás creamos un algoritmo malo? Revisamos los artículos filtrados. Resulta que muchos textos no científicos se publican en revistas científicas: editoriales, felicitaciones por aniversarios, obituarios, recetas e incluso horóscopos. La visualización selectiva de artículos que el clasificador considera científicos no revela errores, por lo tanto, reconocemos que el clasificador es adecuado.
Ahora asumimos la segunda tarea. Aquí no puede prescindir de material de calidad para la formación. Pedimos a los evaluadores que preparen una muestra. Obtenemos un poco más de 3.5 mil documentos con la siguiente distribución:
| Tipo de documento | El número de documentos en la muestra. |
|---|
| Artículos | 679 |
| Tesis doctorales | 250 |
| Resúmenes de tesis doctorales | 714 |
| Colecciones de conferencias científicas. | 75 |
| Tesis doctorales | 159 |
| Resúmenes de disertaciones doctorales | 189 |
| Monografías | 107 |
| Guías de estudio | 403 |
| Tesis | 664 |
| Tipo indefinido | 514 |
Para resolver el problema de clasificación multiclase, utilizamos el mismo bosque aleatorio y las mismas características para no calcular algo especial.
Obtenemos la siguiente calidad de clasificación:
| Precisión | Integridad | Medida F |
|---|
| 81% | 76% | 79% |
Los resultados de aplicar el algoritmo entrenado a los datos indexados son visibles en los diagramas a continuación. La Figura 1 muestra que más de la mitad de la colección consta de documentos científicos, y entre ellos, a su vez, más de la mitad de los documentos son artículos.
 Fig. 1. Distribución de documentos por "científico"
Fig. 1. Distribución de documentos por "científico"La Figura 2 muestra la distribución de documentos científicos por tipo, con la excepción del tipo de "artículo". Se puede ver que el segundo tipo de documento científico más popular es un libro de texto, y el tipo más raro es una disertación doctoral.
 Fig. 2. La distribución de otros documentos científicos por tipo.
Fig. 2. La distribución de otros documentos científicos por tipo.En general, los resultados están en línea con las expectativas. Desde el clasificador rápido "aproximado" ya no necesitamos.
Definición del tema del documento.
Dio la casualidad de que todavía no se ha creado un clasificador de trabajos científicos unificado y universalmente reconocido. Los más populares hoy son los títulos de
VAK ,
GRNTI ,
UDC . Por si acaso, decidimos clasificar los documentos temáticamente en cada una de estas categorías.
Para construir un clasificador temático, utilizamos un enfoque basado en el
modelado de temas , una forma estadística de construir un modelo para una colección de documentos de texto, en el que para cada documento se determina su probabilidad de pertenecer a ciertos temas. Como herramienta para construir un modelo temático, utilizamos la biblioteca abierta
BigARTM . Ya hemos usado esta biblioteca anteriormente y sabemos que es excelente para el modelado temático de grandes colecciones de documentos de texto.
Sin embargo, hay una dificultad. En el modelado temático, determinar la composición y estructura de los temas es el resultado de resolver un problema de optimización en relación con una colección específica de documentos. No podemos influir en ellos directamente. Naturalmente, los temas resultantes del ajuste a nuestra colección no se corresponderán con ninguno de los clasificadores de destino.
Por lo tanto, para obtener el valor final desconocido del rubricador de un documento de solicitud específico, debemos realizar una conversión más. Para hacer esto, en el espacio temático BigARTM, utilizando el algoritmo vecino más cercano (
k-NN ), buscamos varios documentos que sean más similares a la consulta con rubricadores conocidos y, en función de esto, asignamos la clase más relevante al documento de consulta.
De forma simplificada, el algoritmo se muestra en la figura:

Para entrenar el modelo, utilizamos documentos de fuentes abiertas, así como datos proporcionados por Elibrary.ru con especialidades bien conocidas de la Comisión de Certificación Superior, SRSTI, UDC. Eliminamos de la colección documentos que están vinculados a posiciones muy generales de los rubricadores, por ejemplo,
problemas generales y complejos de las ciencias naturales y exactas , ya que dichos documentos harán mucho ruido en la clasificación final.
La colección final contenía alrededor de 280 mil documentos para capacitación y 6 mil documentos para pruebas para cada una de las rúbricas.
Para nuestros propósitos, es suficiente para nosotros predecir los valores de los encabezados del primer nivel. Por ejemplo, para un texto con un valor GRNTI de
27.27.24: Funciones armónicas y sus generalizaciones, la predicción de la sección
27: Matemáticas es correcta.
Para mejorar la calidad del algoritmo desarrollado, agregamos un par de enfoques basados en el viejo clasificador
Naive Bayes . Como signos, utiliza la frecuencia de las palabras que son más características para cada uno de los documentos con un valor específico del encabezado HAC.
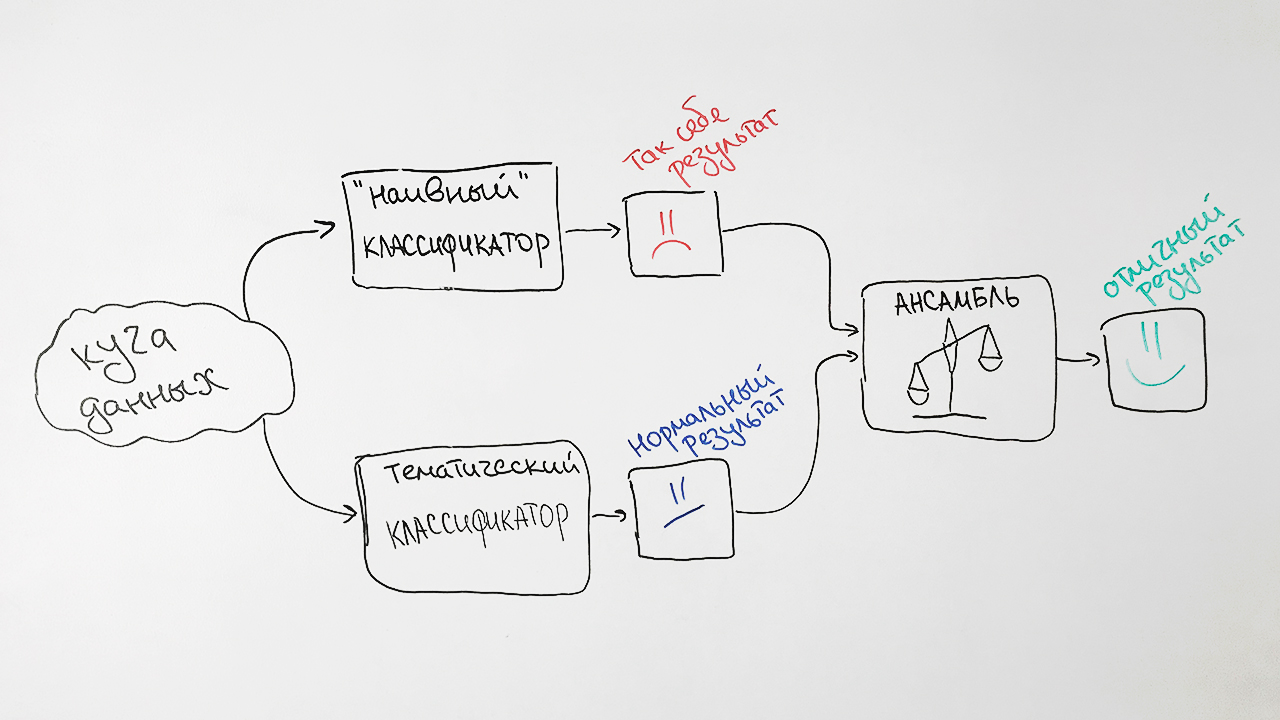
¿Por qué tan difícil? Como resultado, tomamos las predicciones de ambos algoritmos, los ponderamos y producimos una predicción promedio para cada solicitud. Esta técnica en aprendizaje automático se llama
ensamblaje . Tal enfoque nos da un aumento notable en la calidad. Por ejemplo, para la especificación SRSTI, la precisión del algoritmo original fue del 73%, la precisión del clasificador ingenuo de Bayes fue del 65% y sus asociaciones fueron del 77%.
Como resultado, obtenemos un esquema de nuestro clasificador:
Observamos dos factores que influyen en los resultados del clasificador. Primero, a cualquier documento se le puede asignar más de un valor de rubricator a la vez. Por ejemplo, los valores del encabezado de la Comisión Superior de Certificación 25.00.24 y 08.00.14 (Geografía
económica ,
social y política y
economía mundial ). Y eso no será un error.
En segundo lugar, en la práctica, los valores de las rúbricas se colocan de manera experta, es decir, subjetivamente. Un ejemplo sorprendente son temas aparentemente diferentes como
Ingeniería mecánica y
Agricultura y silvicultura . Nuestro algoritmo clasificó los artículos con el título
"Máquinas para adelgazar el bosque" y
"Requisitos previos para el desarrollo de una serie estándar de tractores para las condiciones de la zona noroeste" para ingeniería mecánica, y de acuerdo con el diseño original, se referían a la agricultura.
Por lo tanto, decidimos mostrar los 3 valores más probables de cada una de las categorías. Por ejemplo, para el artículo
"Tolerancia de docentes profesionales (en el ejemplo de la actividad de un maestro ruso de una escuela multiétnica)", las probabilidades de los valores del encabezado de la Comisión de Certificación Superior se distribuyeron de la siguiente manera:
| Valor de rubricator | Probabilidad |
|---|
| Ciencias pedagógicas | 47% |
| Ciencias psicologicas | 33% |
| Estudios culturales | 20% |
La precisión de los algoritmos resultantes fue:
| Rubricator | Top 3 de precisión |
|---|
| SRSTI | 93% |
| VAK | 92% |
| UDC | 94% |
Los diagramas muestran los resultados de un estudio sobre la distribución de temas de documentos en el índice de Internet en ruso para todos (Figura 3) y solo para documentos científicos (Figura 4). Se puede ver que la mayoría de los documentos se relacionan con las humanidades: las especificaciones más frecuentes son economía, derecho y pedagogía. Además, entre solo los documentos científicos, su participación es aún mayor.
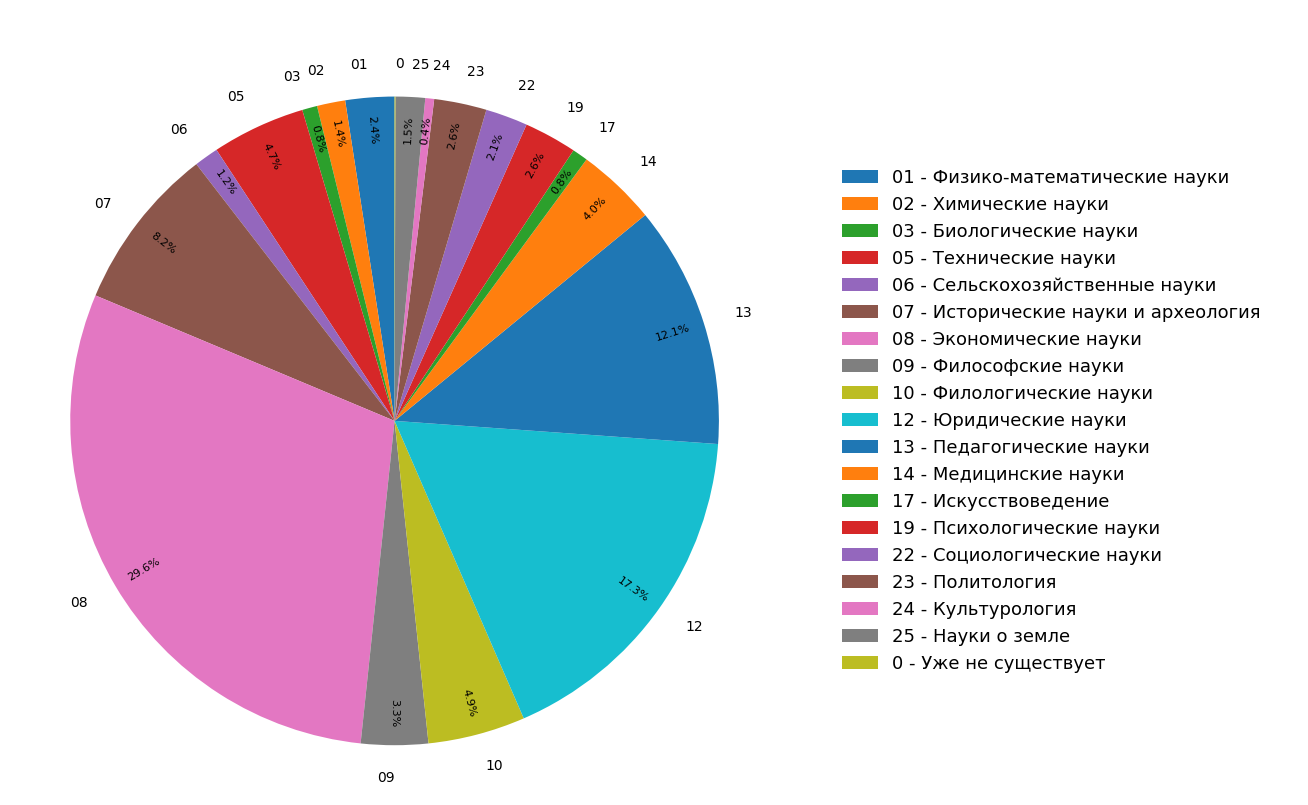 Fig. 3. Distribución de temas en todo el módulo de búsqueda.
Fig. 3. Distribución de temas en todo el módulo de búsqueda.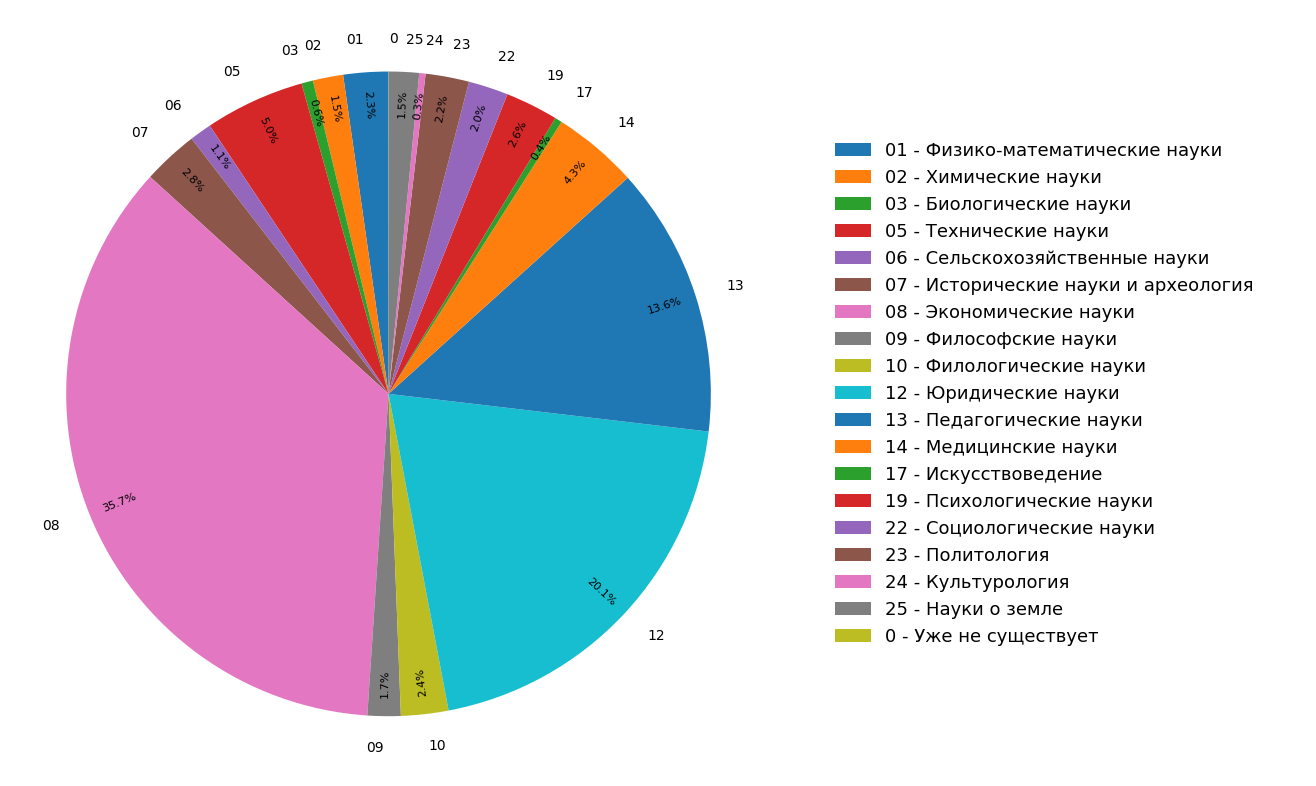 Fig. 4. La distribución de temas de documentos científicos.
Fig. 4. La distribución de temas de documentos científicos.Como resultado, literalmente, a partir de los materiales disponibles, no solo aprendimos la estructura temática de Internet indexada, sino que también hicimos una funcionalidad adicional con la que puede "clasificar" un artículo u otro documento científico en tres categorías temáticas a la vez.

La funcionalidad descrita anteriormente se está implementando activamente en el sistema antiplagio y pronto estará disponible para los usuarios.