
Netflix está obsesionado con la disponibilidad del servicio. Ya lo hemos revisado en nuestro blog más de una vez y contamos cómo logramos alcanzar nuestros objetivos. Utilizamos disyuntores, límites de concurrencia, pruebas de caos y más. Hoy le presentamos otro enfoque innovador que aumenta significativamente la estabilidad de la aplicación bajo cargas extremas y evita fallas en el servicio en cascada: límites adaptativos para conexiones paralelas. No se necesita más esfuerzo para determinar los límites de las conexiones paralelas, lo que permite que el sistema mantenga un tiempo de respuesta corto. Como parte de este anuncio, también publicaremos en el dominio público una biblioteca Java simple con capacidades de integración para servlets, programas de control y gRPC.
Comencemos con lo básico
El límite de conexiones paralelas es el número máximo de solicitudes que el sistema puede procesar en un determinado momento. Por lo general, esta cantidad depende de un recurso limitado, como la potencia de procesamiento del procesador central. Por lo general, el límite de conexiones paralelas del sistema se calcula de acuerdo con la ley de Little, que suena así: para un sistema estable, el número máximo de conexiones paralelas es igual al producto del tiempo promedio dedicado a procesar la solicitud y la intensidad promedio de las solicitudes entrantes (L = λW). Cualquier solicitud que exceda el límite de conexión paralela no puede ser procesada inmediatamente por el sistema, por lo que será puesta en cola o rechazada. La puesta en cola es una función importante que le permite utilizar completamente el sistema en los casos en que las solicitudes se reciben de manera desigual y requieren un tiempo diferente para procesar.
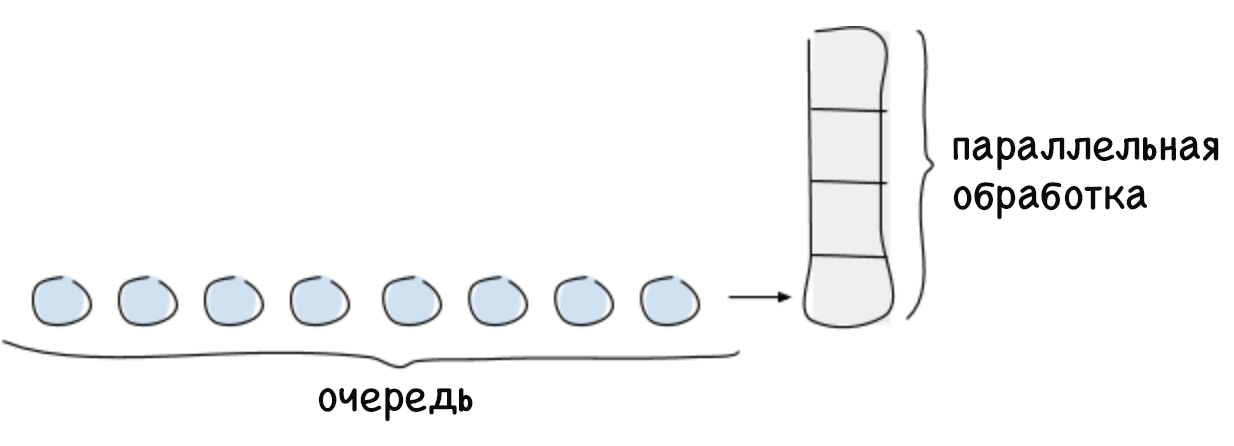
Si no hay límite para la cola, se puede producir un bloqueo del sistema, por ejemplo, si durante mucho tiempo la intensidad de las solicitudes es mayor que la velocidad de su procesamiento. A medida que crece la cola, también lo hace el retraso, lo que lleva a exceder el tiempo de espera para las solicitudes. Esto continúa hasta que se agote la memoria libre, después de lo cual el sistema se bloquea. Si no realiza un seguimiento del creciente tiempo de retraso, comenzará a afectar negativamente a los servicios de llamadas y provocará fallas en el sistema en cascada.

El uso de límites de conexión en paralelo es una práctica estándar, pero la dificultad radica en determinarlos para grandes sistemas dinámicos distribuidos, donde parámetros tales como el tiempo de retardo y la posible cantidad de conexiones en paralelo cambian constantemente. La esencia de nuestra solución es la capacidad de determinar dinámicamente el límite de las conexiones paralelas. Este límite puede representarse como el número de solicitudes entrantes (ejecutadas en paralelo y en cola) que el sistema puede procesar hasta que su rendimiento comience a disminuir (y aumente el tiempo de retraso).
Solución
Anteriormente, los empleados de Netflix determinaron los límites de conexión simultánea manual a través de pruebas de rendimiento y perfiles que requieren mucho tiempo. El número resultante fue correcto para un período de tiempo específico, pero pronto la topología del sistema comenzó a cambiar debido a fallas parciales, escalado automático o la introducción de código adicional que afectó el tiempo de retraso. Como resultado, el límite está desactualizado. Sabíamos que éramos capaces de más, que ya no nos bastaba con determinar los límites de conexión de forma estática. Necesitábamos una forma de determinar automáticamente los límites inherentes al sistema mismo. Al mismo tiempo, queríamos este método:
- no requirió trabajo manual;
- no requirió coordinación central;
- podría determinar el límite sin ninguna información sobre el hardware o la topología del sistema;
- Adaptado a los cambios en la topología del sistema;
- fue simple en términos de implementación y los cálculos necesarios.
Para resolver este problema, recurrimos al probado algoritmo de seguimiento de congestión TCP. Este algoritmo determina la cantidad de paquetes de datos que se pueden transmitir en paralelo (es decir, el tamaño de la ventana de desbordamiento) sin aumentar el tiempo de retraso o exceder el tiempo de espera. Estos algoritmos utilizan varios indicadores para determinar el límite de paquetes transmitidos simultáneamente y para cambiar el tamaño de la ventana de desbordamiento en consecuencia.

El color azul en la imagen muestra el límite desconocido para conexiones paralelas al sistema. Primero, el cliente envía una pequeña cantidad de solicitudes concurrentes, y luego comienza a verificar periódicamente el sistema para ver si puede manejar más solicitudes aumentando la ventana de desbordamiento hasta que esto provoque un aumento en el retraso. Cuando el retraso aún aumenta, el remitente decide que ha alcanzado el límite y nuevamente reduce el tamaño de la ventana de desbordamiento. Dicha prueba continua del límite se refleja en el gráfico que ve arriba.
Nuestro algoritmo se basa en el algoritmo de seguimiento de congestión en el protocolo TCP, que considera la relación entre el tiempo de retraso mínimo (el mejor escenario posible en el que no se utiliza la cola) y el tiempo de retraso, que se mide periódicamente a medida que se ejecutan las solicitudes. Esta relación permite determinar que se ha formado una cola que provoca un aumento en el retraso. Esta relación nos da el gradiente o la magnitud del cambio de tiempo de retraso:
gradiente = (RTTnoload / RTTactual) . Si el valor es igual a uno, entendemos que no hay cola y el límite puede aumentarse. Un valor menor que uno indica que la cola está llena y que el límite debe reducirse. Con cada nueva medición del tiempo de retraso, el límite se ajusta en función de la relación anterior, y con ello el tamaño de cola permitido cambia de acuerdo con esta fórmula simple:
_ = _ × + _
Para varias iteraciones, el algoritmo calcula un límite que permite no solo mantener el tiempo de retraso en un nivel bajo, sino también formar la cola de solicitudes necesaria en caso de brotes de actividad. El tamaño de cola válido se puede configurar. Se utiliza para determinar qué tan rápido puede aumentar el límite de concurrencia. Como tamaño predeterminado, elegimos la raíz cuadrada del valor límite actual. Esta elección se debe a la propiedad útil de la raíz cuadrada: a valores pequeños, será lo suficientemente grande en comparación con el límite para garantizar un crecimiento rápido, pero a valores grandes, por el contrario, su valor relativo será menor, lo que aumentará la estabilidad del sistema.
Límites adaptativos en acción
Los límites adaptativos en el lado del servidor rechazan las solicitudes excesivas y mantienen una latencia baja, lo que permite que la instancia del sistema se proteja a sí misma y a los servicios de los que depende. Anteriormente, cuando no era posible rechazar solicitudes excesivas, cualquier aumento constante en el número de solicitudes por segundo o el tiempo de retraso conducía a un aumento aún mayor en este tiempo y, en última instancia, a la caída de todo el sistema. Hoy en día, los servicios pueden eliminar cargas de trabajo innecesarias y mantener una baja latencia mientras trabajan con otras herramientas de estabilización, como el escalado automático.
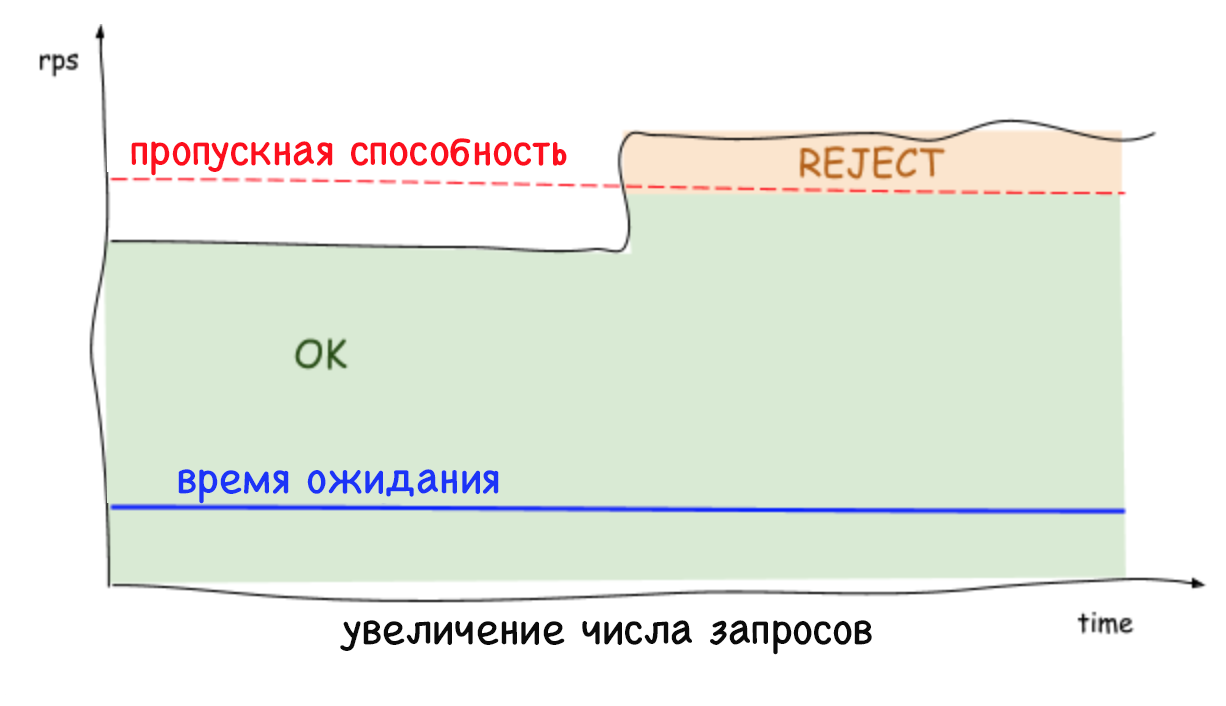
Es importante recordar que los límites se establecen a nivel del servidor (y sin ninguna coordinación), que el tráfico a cada servidor puede caer y aumentar considerablemente. Por lo tanto, no es sorprendente que el límite detectado y el número de conexiones concurrentes puedan ser diferentes según el servidor. Esto es especialmente cierto en un entorno de nube multicliente. Como resultado, puede surgir una situación cuando un servidor está sobrecargado, aunque el resto será gratuito. Al mismo tiempo, al equilibrar la carga en el lado del cliente, solo una solicitud repetida llegará al servidor con recursos gratuitos en casi el 100% de los casos. Y eso no es todo: no hay más motivos para preocuparse de que las solicitudes repetidas provoquen un ataque DDOS, ya que los servicios pueden rechazar rápidamente (en menos de un milisegundo) el tráfico con un impacto mínimo en el rendimiento.
Conclusión
El uso de límites adaptativos para conexiones paralelas elimina la necesidad de determinar manualmente cómo y en qué casos nuestros servicios deberían rechazar el tráfico. Además, también aumenta la fiabilidad general y la disponibilidad de todo nuestro ecosistema de microservicios.
Nos complace compartir con usted nuestros métodos de implementación y la integración general de esta solución, que puede encontrar en la biblioteca pública en
github.com/Netflix/concurrency-limits . Esperamos que nuestro código ayude a los usuarios a proteger sus servicios de fallas en cascada y problemas con el aumento de la latencia, así como a aumentar su disponibilidad.