
Hola habr
Mi nombre es Alexey Solodky, soy desarrollador de PHP en Badoo. Y hoy compartiré una versión de texto de mi charla para el primer Badoo PHP Meetup. Un video de este y otros informes del mitap se puede encontrar
aquí .
Cualquier sistema que consta de al menos dos componentes (y si tiene PHP y una base de datos, entonces estos son dos componentes), enfrenta clases enteras de riesgos en la interacción entre estos componentes.
El departamento de plataformas en el que trabajo integra nuevos servicios internos con nuestra aplicación. Y para resolver estos problemas, hemos acumulado experiencia, que quiero compartir.
Nuestro backend es un monolito PHP que interactúa con muchos servicios (actualmente hay alrededor de 50 de ellos). Los servicios rara vez interactúan entre sí. Pero los problemas de los que hablo en el artículo también son relevantes para la arquitectura de microservicios. De hecho, en este caso, los servicios interactúan muy activamente entre sí, y cuanta más interacción tenga, más problemas tendrá.
Considere qué hacer cuando el servicio se bloquea o no, cómo organizar la recopilación de métricas y qué hacer cuando todo lo anterior no lo salva.
Servicio fallido
Tarde o temprano, el servidor en el que está instalado su servicio caerá. Sucederá con seguridad, y no puedes defenderte contra eso, solo reduce la probabilidad. Puede decepcionarse por hardware, red, código, implementación fallida, cualquier cosa. Y cuantos más servidores tenga, más a menudo sucederá esto.
¿Cómo hacer que sus servicios sobrevivan en un mundo en el que los servidores se bloquean constantemente? Un enfoque general para resolver esta clase de problemas es la redundancia.
La redundancia se usa en todas partes en diferentes niveles: desde el hierro hasta centros de datos completos. Por ejemplo, RAID1 para proteger contra fallas del disco duro o una fuente de alimentación de respaldo para su servidor en caso de falla de la primera. Además, este esquema se aplica ampliamente a las bases de datos. Por ejemplo, puede usar master-slave para esto.
Consideremos problemas típicos de redundancia usando el esquema más simple como ejemplo:
La aplicación se comunica exclusivamente con el maestro, mientras que en segundo plano, de forma asíncrona, los datos se transfieren al esclavo. Cuando el maestro falla, cambiaremos al esclavo y continuaremos trabajando.
Después de restaurar al maestro, solo hacemos un nuevo esclavo, y el viejo se convierte en un maestro.
El esquema es simple, pero incluso tiene muchos matices característicos de cualquier esquema redundante.
Carga
Digamos que un servidor del ejemplo anterior puede soportar aproximadamente 100k RPS. Ahora la carga es de 60k RPS, y todo funciona como un reloj.
Pero con el tiempo, la carga en la aplicación, y por lo tanto la carga en el maestro, aumenta. Es posible que desee equilibrarlo moviendo parte de la lectura a un esclavo.
Se ve bastante bien. Mantiene la carga, el servidor ya no está inactivo. Pero esta es una mala idea. Es importante recordar por qué inicialmente criaste al esclavo, para cambiarlo en caso de problemas con el principal. Si comenzó a cargar ambos servidores, cuando su maestro se bloquee, y tarde o temprano se bloquee, tendrá que cambiar el tráfico principal del servidor maestro al servidor de respaldo, y ya está cargado. Tal sobrecarga hará que su sistema sea terriblemente lento o lo deshabilitará por completo.
Datos
El principal problema al agregar tolerancia a fallas a un servicio es el estado local. Si su servicio no tiene estado, es decir, no almacena ningún dato mutable, entonces escalarlo no presenta un problema. Simplemente planteamos todas las instancias que necesitamos y equilibramos las solicitudes entre ellas.
En el caso de que el servicio tenga estado, ya no podemos hacerlo. Debe pensar en cómo almacenar los mismos datos en todas las instancias de nuestro servicio para que sean coherentes.
Para resolver este problema, se utiliza uno de dos enfoques: replicación sincrónica o asincrónica. En el caso general, le aconsejo que use la opción asincrónica, ya que generalmente es más simple y rápido de escribir y, según las circunstancias, vea si necesita cambiar a síncrono.
Un matiz importante a considerar cuando se trabaja con replicación asíncrona es la
consistencia eventual . Esto significa que en un punto particular en el tiempo en diferentes esclavos, los datos pueden quedar rezagados con respecto al maestro en intervalos de tiempo impredecibles y diferentes.
En consecuencia, no puede leer datos cada vez desde un servidor aleatorio, porque entonces pueden surgir diferentes respuestas a las mismas solicitudes de los usuarios. Para evitar este problema,
se utiliza el mecanismo de
sesiones fijas , lo que garantiza que todas las solicitudes de un usuario vayan a una instancia.
Las ventajas de un enfoque sincrónico son que los datos siempre están en un estado consistente y el riesgo de perder datos es menor (porque se considera que se registra solo después de que todos los servidores lo hayan hecho). Sin embargo, debe pagar por esto con la velocidad de escritura y la complejidad del sistema en sí (por ejemplo, varios algoritmos de quórum para protección contra
cerebro dividido ).
Conclusiones
- Reserva Si los datos en sí y la disponibilidad de un servicio en particular son importantes, asegúrese de que su servicio sobrevivirá a la caída de una máquina en particular.
- Al calcular la carga, tenga en cuenta la caída de algunos servidores. Si su clúster tiene cuatro servidores, asegúrese de que cuando uno se caiga, los tres restantes tirarán de la carga.
- Elija el tipo de replicación según las tareas.
- No ponga todos sus huevos en una canasta. Asegúrese de estar lo suficientemente lejos de los servidores. Dependiendo de la importancia de la disponibilidad del servicio, sus servidores pueden estar en diferentes racks en un centro de datos, o en diferentes centros de datos en diferentes países. Todo depende de la cantidad de desastre global que desee y esté listo para sobrevivir.
Servicio de silencio
En algún momento, su servicio puede comenzar a funcionar muy lentamente. Este problema puede ocurrir por muchas razones: carga excesiva, retrasos en la red, problemas de hardware o errores de código. Parece un problema no tan terrible, pero de hecho es más insidioso de lo que parece.
Imagínese: un usuario solicita una página. Simultáneamente y secuencialmente accedemos a los cuatro demonios para dibujarlo. Responden rápidamente, todo funciona bien.
Supongamos que este caso se maneja usando nginx con un número fijo de trabajadores PHP FPM (con diez, por ejemplo). Si cada solicitud se procesa durante aproximadamente 20 ms, con la ayuda de cálculos simples se puede entender que nuestro sistema es capaz de procesar aproximadamente quinientas solicitudes por segundo.
¿Qué sucede cuando uno de estos cuatro servicios comienza a disminuir y el procesamiento de solicitudes aumenta de 20 ms a un tiempo de espera de 1000 ms? Es importante recordar que cuando trabajamos con la red, el retraso puede ser infinitamente grande. Por lo tanto, siempre debe establecer un tiempo de espera (en este caso, es igual a un segundo).
Resulta que el back-end se ve obligado a esperar a que expire el tiempo de espera y recibir y procesar el error del demonio. Esto significa que el usuario recibe la página en un segundo en lugar de diez milisegundos. Lento, pero no fatal.
Pero, ¿cuál es el verdadero problema aquí? El hecho es que cuando tenemos cada solicitud procesada por segundo, el rendimiento cae trágicamente a diez solicitudes por segundo. Y el undécimo usuario ya no podrá obtener una respuesta, incluso si solicitó una página que de ninguna manera está asociada con un servicio aburrido. Solo porque los diez trabajadores están esperando un tiempo de espera y no pueden procesar nuevas solicitudes.
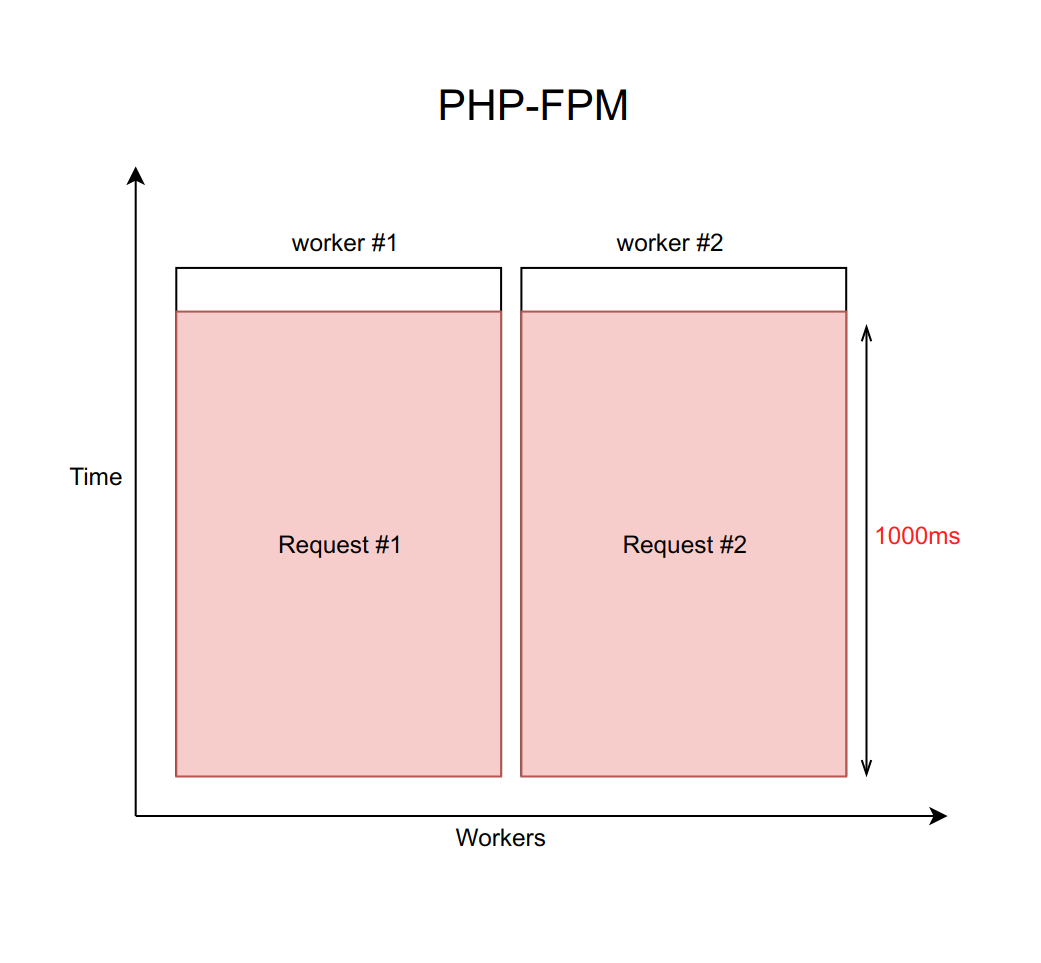
Es importante comprender que este problema no se puede resolver aumentando el número de trabajadores. Después de todo, cada trabajador requiere una cierta cantidad de RAM para su trabajo, incluso si no realiza un trabajo real, sino que simplemente se cuelga en anticipación de un tiempo de espera. Por lo tanto, si no limita el número de trabajadores de acuerdo con las capacidades de su servidor, entonces aumentar cada vez más trabajadores nuevos colocará todo el servidor. Este caso es un ejemplo de una falla en cascada, cuando la caída de cualquier servicio, incluso si no es crítico para el usuario, causa una falla en todo el sistema.
Solución
Hay un patrón llamado
disyuntor . Su tarea es bastante simple: en algún momento debe reducir un servicio aburrido. Para esto, se coloca un proxy entre el servicio y los trabajadores. Puede ser código PHP con almacenamiento o un demonio en el host local. Es importante tener en cuenta que si tiene varias instancias (su servicio se replica), este proxy debe realizar un seguimiento por separado de cada una de ellas.
Hemos escrito nuestra implementación de este patrón. Pero no porque nos encanta escribir código, sino porque cuando resolvimos este problema hace muchos años, no había soluciones preparadas.
Ahora describiré en términos generales nuestra implementación y cómo ayuda a evitar este problema. Y se puede escuchar más sobre ella y sus diferencias con respecto a otras soluciones
en un informe de Mikhail Kurmaev sobre Highload Siberia a fines de junio. La transcripción de su informe también estará en este blog.
Se parece a esto:
Hay un servicio abstracto de Sphinx, que se enfrenta a un interruptor automático. El disyuntor almacena el número de conexiones activas a un demonio específico. Tan pronto como este valor alcanza el umbral, que establecemos como un porcentaje de los trabajadores de FPM disponibles en la máquina, creemos que el servicio comenzó a disminuir. Al llegar al primer umbral, enviamos una notificación a la persona responsable del servicio. Tal situación es una señal de que los límites deben ser revisados, o un presagio de problemas de aburrimiento.
Si la situación empeora y el número de trabajadores inhibidores alcanza el segundo valor umbral, en nuestra producción es de aproximadamente el 10%, reducimos este host por completo. Más precisamente, el servicio en realidad continúa funcionando, pero dejamos de enviarle solicitudes. El navegador del circuito los rechaza e inmediatamente les da a los trabajadores un error, como si el servicio estuviera mintiendo.
De vez en cuando, omitimos automáticamente una solicitud de un trabajador para ver si el servicio ha cobrado vida. Si responde adecuadamente, lo incluimos nuevamente en el trabajo.
Todo esto se hace para reducir la situación al esquema de replicación anterior. En lugar de esperar un segundo antes de darnos cuenta de que el host no está disponible, inmediatamente recibimos un error y vamos al host de respaldo.
Implementaciones
Afortunadamente, Open Source no se detiene, y hoy puede tomar una solución llave en mano en Github.
Existen dos enfoques principales para implementar el interruptor automático: una biblioteca de nivel de código y un demonio independiente que representa las solicitudes por sí mismo.
La opción con la biblioteca es más adecuada si tiene un monolito principal en PHP, que interactúa con varios servicios, y los servicios casi no se comunican entre sí. Aquí hay algunas implementaciones disponibles:
Si tiene muchos servicios en diferentes idiomas y todos interactúan entre sí, entonces la opción a nivel de código deberá duplicarse en todos estos idiomas. Esto es inconveniente en el soporte y, en última instancia, conduce a diferencias en las implementaciones.
Poner un demonio en este caso es mucho más fácil. En este caso, no tiene que editar especialmente el código. El demonio está tratando de hacer que la interacción sea transparente. Sin embargo, esta opción es
mucho más complicada arquitectónicamente .
Aquí hay algunas opciones (la funcionalidad es más rica allí, pero también hay un interruptor automático):
Conclusiones
- No confíes en la red.
- Todas las solicitudes de red deben tener un tiempo de espera, porque la red puede dar un tiempo infinitamente largo.
- Use un disyuntor si desea evitar bloqueos de aplicaciones en cascada debido al hecho de que un pequeño servicio se ralentiza.
Monitoreo y telemetria
Que da
- Previsibilidad Es importante predecir cuál es la carga y lo que será en un mes para aumentar oportunamente el número de instancias de servicio. Esto es especialmente cierto si se trata de una infraestructura de hierro, ya que ordenar nuevos servidores lleva tiempo.
- Investigación de incidentes. Tarde o temprano, algo saldrá mal de todos modos, y tendrá que investigarlo. Y es importante tener suficientes datos para comprender el problema y poder prevenir tales situaciones en el futuro.
- Prevención de accidentes. Idealmente, debe comprender qué patrones conducen a bloqueos. Es importante realizar un seguimiento de estos patrones y notificar al equipo sobre ellos de manera oportuna.
Que medir
Métricas de integraciónComo estamos hablando de la interacción entre servicios, monitoreamos todo lo que es posible en relación con la comunicación del servicio con la aplicación. Por ejemplo:
- cantidad de solicitudes;
- solicitar tiempo de procesamiento (incluidos los percentiles);
- número de errores lógicos;
- Número de errores del sistema.
Es importante distinguir los errores lógicos de los errores del sistema. Si el servicio cae, esta es una situación regular: simplemente cambiamos a la segunda. Pero no da tanto miedo. Si inicia algún tipo de error lógico, por ejemplo, datos extraños ingresan al servicio o lo dejan, entonces esto ya debe investigarse. Lo más probable es que el error esté relacionado con un error en el código. Ella misma no pasará.
Métricas internasPor defecto, el servicio es un cuadro negro que hace su trabajo de manera incomprensible. Todavía es deseable comprender y recopilar los datos máximos que el servicio puede proporcionar. Si el servicio es una base de datos especializada que almacena algunos datos de su lógica comercial, realice un seguimiento de la cantidad exacta de datos, de qué tipo es y otras métricas de contenido. Si tiene una interacción asincrónica, también es importante controlar las colas a través de las cuales se comunica su servicio: su velocidad de llegada y salida, el tiempo en diferentes etapas (si tiene varios puntos intermedios), el número de eventos en la cola.
Veamos qué métricas se pueden recopilar usando memcached como ejemplo:
- proporción de aciertos / fallas;
- tiempo de respuesta para varias operaciones;
- RPS de varias operaciones;
- desglose de los mismos datos en diferentes claves;
- teclas cargadas en la parte superior;
- todas las métricas internas dadas por el comando de estadísticas.
Como hacerlo
Si tiene una empresa pequeña, un proyecto pequeño y pocos servidores, entonces es una buena solución para conectar algún tipo de SaaS para recopilar y ver: es más fácil y más barato. En este caso, generalmente SaaS tiene una amplia funcionalidad y no tiene que preocuparse por muchas cosas. Ejemplos de tales servicios:
Alternativamente, siempre puede instalar Zabbix, Grafana o cualquier otra solución autohospedada en su propia máquina.
Conclusiones
- Recoge todas las métricas que puedas. Los datos no son superfluos. Cuando tenga que investigar algo, dirá gracias por su previsión.
- No te olvides de la interacción asincrónica. Si tiene líneas que llegan gradualmente, es importante comprender qué tan rápido llegan, qué sucede con sus eventos en el cruce entre los servicios.
- Si escribe su servicio, enséñele a dar estadísticas sobre el trabajo. Parte de los datos se pueden medir en la capa de integración cuando nos comunicamos con este servicio. El resto del servicio debería poder proporcionar estadísticas de acuerdo con el comando condicional. Por ejemplo, en todos nuestros servicios en Go, esta funcionalidad es estándar.
- Personaliza los disparadores. Los gráficos son buenos, pero solo mientras los miras. Es importante que tenga un sistema personalizado que le permita saber si algo sale mal.
Memento mori
Y ahora un poco sobre cosas tristes. Puede tener la sensación de que lo anterior es una panacea, y ahora nada caerá nunca. Pero incluso si aplica todo lo descrito anteriormente, de todos modos, algo caerá. Es importante considerar esto.
Las razones de la caída son muchas. Por ejemplo, puede elegir un esquema de replicación insuficientemente paranoico. Un meteorito cayó en su centro de datos, y luego en el segundo. O simplemente desplegó el código con un error complicado que apareció inesperadamente.
Por ejemplo, en Badoo hay una página "Personas cercanas". Allí, los usuarios buscan a otras personas cercanas para chatear con ellos.

Ahora, para representar la página, el backend realiza llamadas sincrónicas a unos siete servicios. Para mayor claridad, reduzca este número a dos. Un servicio es responsable de representar el bloque central con fotos. El segundo es para el bloque publicitario en la parte inferior izquierda. Aquellos que quieran hacerse más visibles pueden llegar allí. Si tenemos un servicio que muestra este anuncio, el bloqueo simplemente desaparece.

La mayoría de los usuarios ni siquiera saben sobre este hecho: nuestro equipo responde rápidamente y pronto el bloqueo simplemente vuelve a aparecer.
Pero no todas las funcionalidades podemos eliminar silenciosamente. Si perdemos el servicio responsable de la parte central de la página, esto no funcionará para ocultarlo. Por lo tanto, es importante decirle al usuario en su idioma lo que está sucediendo.

También es deseable que la falla de un servicio no conduzca a una falla en cascada. Para cada servicio, se debe escribir un código que maneje su caída; de lo contrario, la aplicación puede bloquearse en su conjunto.
Pero eso no es todo. A veces algo cae, sin el cual no puedes vivir de ninguna manera. Por ejemplo, una base de datos central o servicio de sesión. Es importante resolverlo correctamente y mostrarle al usuario algo adecuado, de alguna manera entretenerlo, para decirle que todo está bajo control. Al mismo tiempo, es importante que todo esté realmente bajo control, y los monitores son notificados del problema.
Morir tan bien
- Prepárate para el otoño. No hay una bala de plata, así que siempre coloque pajitas en caso de que el servicio caiga por completo, incluso si usa redundancia.
- Evite fallas en cascada cuando los problemas con uno de los servicios maten a toda la aplicación.
- Deshabilitar la funcionalidad de usuario no crítica. Esto es normal Muchos servicios se usan solo para necesidades internas y no afectan la funcionalidad proporcionada. Por ejemplo, un servicio de estadísticas. Al usuario no le importa si las estadísticas se recopilan de usted o no. Es importante para él que el sitio funcione.
Resumen
Para integrar de manera confiable el nuevo servicio en el sistema, escribimos una API de envoltura especial alrededor de él en Badoo, que asume las siguientes tareas:
- balanceo de carga;
- tiempos de espera;
- conmutación por error lógica;
- disyuntor
- monitoreo y telemetría;
- lógica de autorización;
- serialización y deserialización de datos.
Es mejor asegurarse de que todos estos elementos también estén cubiertos en su capa de integración. Especialmente si está utilizando un cliente API de código abierto listo para usar. Es importante recordar que la capa de integración es una fuente de mayor riesgo de falla en cascada de su aplicación.
Gracias por su atencion!
Literatura