La tendencia NoSQL tiene casi 10 años y puede sacar conclusiones y generalizaciones de forma segura. Haremos esto y hablaremos sobre el desarrollo de NoSQL.
Recordemos cómo nació NoSQL. Veamos qué es bueno y qué es malo, y qué ha resistido la prueba del tiempo. Analicemos las características que ya están en SQL y que ahora aparecen en NoSQL DBMS. Destacamos los valores únicos de NoSQL y miramos un poco más adelante lo que sucederá en el mercado mañana.
Y Konstantin Osipov (
@kostja ), el desarrollador y arquitecto del DBMS Tarantool, que habló sobre las tendencias de NewSQL en su informe en RIT ++ 2017, nos ayudará con esto, porque se supone que el arquitecto debe entender lo que está sucediendo en el mundo de la base de datos para que al menos reinventar la rueda.
Sobre el orador : Ahora Konstantin Osipov está trabajando en Tarantool, pero anteriormente participó en el desarrollo de MySQL, y cuando Konstantin comenzó a trabajar en una nueva base de datos, estaba muy confundido sobre por qué esto debería hacerse, por qué se necesitaba la siguiente base de datos. En particular, la actitud hacia NoSQL era muy escéptica, en cuanto a "under-SQL".
Sin embargo, el desarrollo continúa, algunos de los principios originales se extinguen y, al mismo tiempo, las bases de datos NoSQL toman las capacidades del SQL clásico. En base a los resultados de estos varios años de rápida transformación, es muy posible extraer resultados intermedios y permitirse hacer varias predicciones para el futuro.
Plan
Principios NoSQL
Muchas personas están tratando de apegarse al término NoSQL ahora, pero fue ampliamente adoptado en 2009 cuando apareció el hashtag
#nosql . El desarrollador de Last.FM inventó esta etiqueta para las bases de datos distribuidas mitap.
Después de eso, la etiqueta comenzó a ganar popularidad en Twitter, y NoSQL se convirtió en un tanque de drenaje o embudo para la frustración, como lo llamo, frustración que se ha acumulado durante muchos años de trabajo con bases de datos tradicionales.
NoSQL es una salida a la frustración, una etiqueta que todos los que no han tenido suficientes características SQL se han apropiado para sí mismos.
Esta frustración necesita ser estructurada y determinada de alguna manera que a la mayoría de las personas no les gusta en los DBMS tradicionales. Podemos distinguir 3 grandes bloques de tareas para cuya solución se creó NoSQL:
- escala horizontal;
- nuevos modelos de datos;
- Nuevos modelos de consistencia.
Veamos qué son estos bloques. Tomemos, por ejemplo, bases de datos de valores clave. La idea principal del modelo de datos de valor clave es que la base de datos es simple, pero es escalable. El desarrollador tiene una gran cantidad de problemas, pero tiene una garantía estricta de que su base de datos será
infinitamente escalable . Pero la escalabilidad infinita no es mágica. Las garantías de escalabilidad se logran debido a la
semántica extremadamente simple de las operaciones admitidas: en una base de datos de valores clave, cualquier operación afecta estrictamente a un nodo del clúster.
Inicialmente, fue muy difícil para la comunidad separar los modelos de datos de los modelos a escala. Si nos fijamos en el mismo Cassandra, en las primeras versiones su modelo de datos se llamaba Wide Column Store, una base de datos de columnas anchas. Si hay un índice en el valor clave del DBMS, por clave, en el almacén de columnas anchas siempre se crean automáticamente dos índices: por clave y por familia de columnas.
Además, el índice por clave es compartible y el índice por Column Family es local para un nodo de datos específico. Debido a esto, logramos una escala horizontal, pero al mismo tiempo tuvimos la oportunidad de realizar consultas locales en la familia de columnas. Los veteranos recuerdan que se implementó una característica similar en Oracle, mientras se mantenía el modelo relacional, y se llamaba tabla unida. Esta característica hizo posible especificar la ubicación física de las dos tablas en el formulario unido. Amplia tienda de columnas en Cassandra: implementa una tabla unida con distribución automática en todo el clúster.
La fusión del modelo de datos y el modelo a escala es exactamente el problema que se resolvió utilizando el modelo relacional. Bienvenido a los años 70.
Además de los nuevos modelos de datos, NoSQL ha implementado nuevos modelos de consistencia. Sí, sí, de nuevo este famoso
teorema CAP . Hablar sobre el teorema de CAP me divierte todo el tiempo, ¿quién lo necesita? Como no hay esturión de la segunda frescura, tampoco hay otras respuestas a la pregunta sobre la consistencia de los datos, excepto una:
la base de datos debe garantizar esta consistencia . Por lo tanto, los nuevos modelos de consistencia también son, en mi opinión, una tendencia a la muerte.
NoSQL hoy
La tesis que quiero expresar en primer lugar es la de todo el movimiento NoSQL sobrevivido:
- escala horizontal;
nuevos modelos de datos modelos de documentos y gráficos de datos;Nuevos modelos de consistencia.
De las tesis sobre nuevos modelos de datos, casi uno y medio sobrevivieron y la tesis sobre modelos de consistencia murió por completo.
Gorro de muerte
¿Por qué no sobrevivieron algunos modelos de consistencia?
●
Consistencia eventual: inflación a plazo¿Quién usa una base de datos que tiene un reloj vectorial en funcionamiento y la lógica de negocios de la aplicación está orientada a esto? - nadie ¿Quién usa las bases de datos que tienen CRDT (tipos de datos replicados sin conflicto)? ¿Quién está usando Riak? - nadie ¿Qué usa la gente? Más a menudo PostgreSQL, menos a menudo otras bases, por ejemplo, MongoDB.
●
MongoDB: atomic se reemplaza por aislado, las transacciones se agregan en 3.xxEsta base de datos tiene replicación asincrónica. Esto es algo muy fácil de entender, aunque, de hecho,
hay 4 tipos de replicación asincrónica . La replicación de los datos de la transacción puede ocurrir después de que una transacción se confirma localmente; antes de que la transacción se confirme localmente.
Es decir, el punto de confirmación de la base de datos principal también se puede correlacionar con el punto de confirmación de la réplica de diferentes maneras.
Ya se ha realizado una entrada en el registro local, pero aún no ha volado a la réplica. Suponga que quiere esperar a que al menos se vaya volando a una réplica. Volado - no significa volado. Llegado: esto no significa que se haya escrito en el diario local en la réplica.
Inicialmente, MongoDB tenía un modo: la solicitud llega al servidor, la base de datos respondió OK, ni siquiera ha llegado al disco, ni al libro de registro, no fue a ningún lado. Debido a esto, todo funciona muy rápido, pero luego comenzaron a criticar a MongoDB por esto y, por defecto, en versiones posteriores 3+, después de todo, primero comenzó a escribir la transacción en el registro, y solo después de eso envió una confirmación al cliente.
Es decir, incluso la replicación asincrónica es un abismo de modelos semánticos. Por lo tanto, los
modelos de consistencia son demasiado complicados para que un amplio círculo de desarrolladores los entiendan, y las transacciones y la replicación sincrónica están reemplazando la variedad de modelos exóticos .
En el contexto de la muerte del modelo de consistencia, todavía hay una tendencia interesante en el desarrollo de una consistencia realmente más estricta. Hay transacciones en Redis, aunque no las llamaría transacciones, pero a expensas de lo que es una transacción real, existe controversia sin ella.
Veamos el historial de transacciones en NoSQL. Inicialmente, MongoDB implementó la atomicidad a nivel de documento. Luego, se agregó un modo de ejecución aislado para permitir a los desarrolladores, si realmente lo desean, actualizar varios documentos atómicamente.
●
transacciones RedisEn los albores de NoSQL, se le ofreció al desarrollador poner todo el caso de negocios en un documento de canasta. Aparece un flujo completo llamado diseño impulsado por dominio, que eleva esta perversión al rango de patrón de diseño. De hecho, si todo se almacena en un documento, la atomicidad se logra simplemente: realizó una transacción, un proceso de negocio y tiene un cambio atómico en un documento.
Pero resulta que esto no funciona. Los datos deben normalizarse para evitar la redundancia de almacenamiento. Deben normalizarse para consultas analíticas. Al final, el modelo de datos está evolucionando, y el documento que ayer podría guardar toda la información necesaria para un escenario empresarial de hoy necesita ser ampliado y complementado.
¿Se demuestran los problemas de atomicidad? cuán estrechamente relacionados están los modelos de datos con los modelos de consistencia: el advenimiento de las transacciones y la replicación sincrónica hace que la mayoría de los modelos en NoSQL sean innecesarios.
Modelos de datos
Ahora hablemos de la próxima historia: la historia con modelos de datos.
Grupos de modelos de datos inventados después de SQL:
- Valor clave
- Documental
- Amplia tienda de columnas;
- Servidor de estructura de datos (para Redis);
- Graficar bases de datos.
Genial! ¡Tenemos tantos modelos de datos! ¿Y qué tan bien escalan?
Esta es una tesis, relacionada principalmente con la llamada hiperconvergencia, cuando todos los proyectos modernos usan servidores de un solo servidor y las empresas dejan de comprar máquinas escalables verticalmente.
La hiperconvergencia ha llegado a nuestras vidas tan a fondo que hoy en día, incluso dentro de las máquinas con escala vertical, si hay alguna, ya existe un software escalable horizontalmente: observe cómo funciona PureStorage o, si lo recuerda, de noche, Nutanix. Por supuesto, venden gabinetes a personas, pero estos gabinetes están dispuestos en el interior como bastidores ordinarios en un proveedor de alojamiento.
Es decir, la escala horizontal es una tendencia que ejerce presión sobre todos, incluidos los inventores de nuevos modelos de datos. Entonces, ¿qué modelos de datos son buenos para el escalado horizontal y cuáles son malos?
¿Es bueno o malo para el escalado horizontal? La respuesta, de hecho, es bastante controvertida, volveremos a ella más tarde.
Redis
Cuando Redis agregó el clúster de Redis, resultó que no todas las operaciones del modelo de datos se escalan normalmente horizontalmente.

Esta es una cita de la documentación donde escriben que algo funciona para ellos en un fragmento en particular, y algo realmente funciona como en un clúster real.
El problema fundamental de este enfoque es el mismo que en MySQL, que recogimos y nos dimos la mano. Es decir, el desarrollador tiene dos modelos de datos:
- En uno, piensa en el marco del álgebra relacional.
- Luego, cuando piensa en el fragmentación independiente, piensa en el modelo de datos del álgebra relacional de fragmentos.
Un buen modelo de datos debe ser universal . Lo hermoso del álgebra relacional: el resultado de una proyección es una relación, el resultado de cualquier operador es una relación. Y tan pronto como comenzamos a fragmentar MySQL manualmente en el clúster, perdemos eso.
Sin embargo, Redis agrega un clúster de Redis porque
todos quieren escalar horizontalmente .
Graficar bases de datos
Las bases de datos de gráficos son un buen ejemplo que ayuda a
separar los conceptos de escala horizontal de la informática y el almacenamiento . La información siempre se puede dividir por cualquier número de nodos. Pero si la base de datos está diseñada por su naturaleza para procesar los datos que almacena, y estos cálculos no se escalan horizontalmente, entonces surge el problema del almacenamiento horizontal efectivo que permite que los cálculos funcionen.
Veamos el problema de los DBMS de gráficos de escala: los DBMS de SQL enfrentan barreras de escala muy similares.
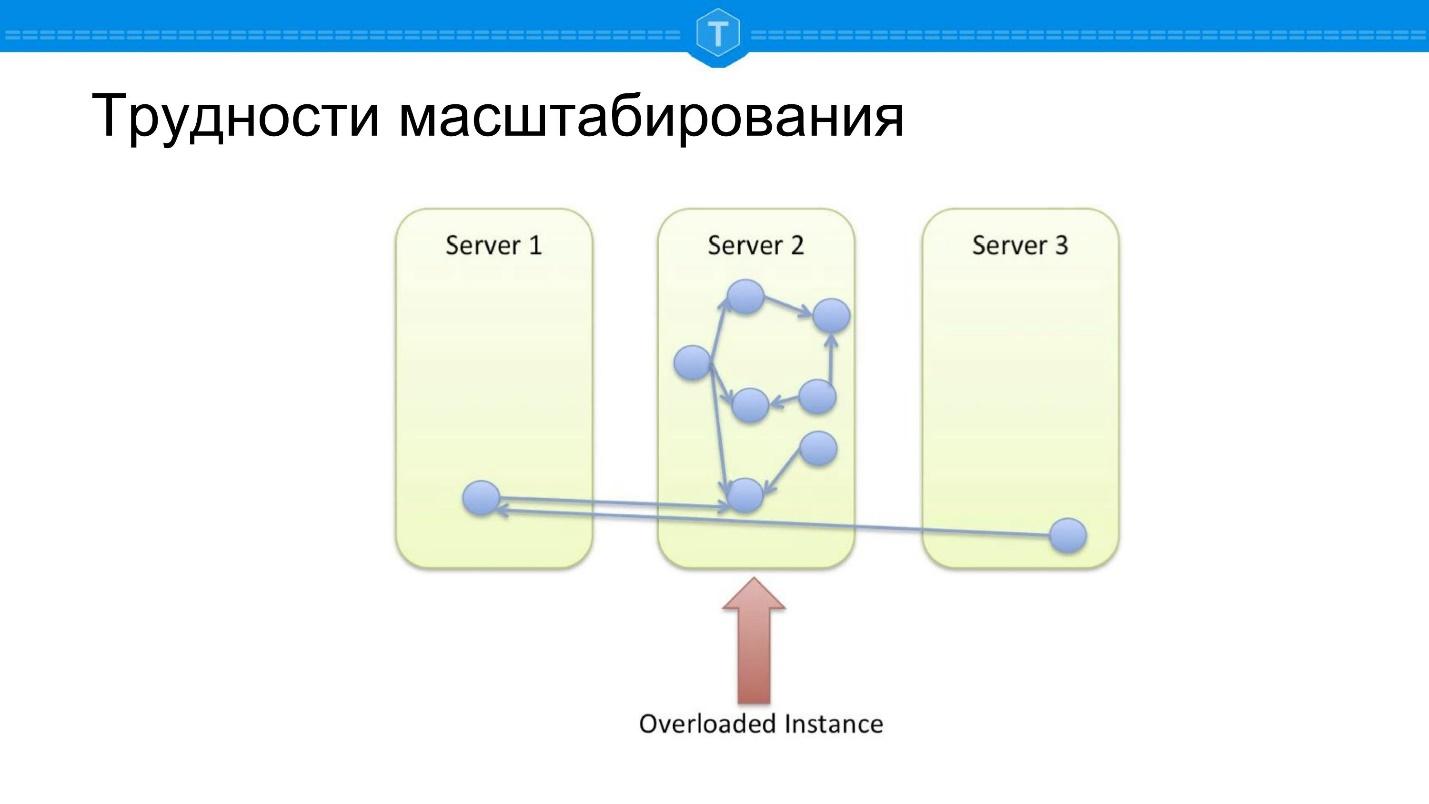
Tome la base de datos local en la que se almacena el gráfico. Tarde o temprano, un nodo se llena y comenzamos a usar otros nodos. Tan pronto como usamos más de un nodo, el nodo central se sobrecarga, ya que se pierde la localidad de las solicitudes. Algunas consultas en el gráfico se ven obligadas a ir a lo largo de varios nodos físicos, es decir, aparecen retrasos en la red.
Supongamos que hicimos algo diferente: tomaron y rompieron todo con una buena función de fragmentación. Calculamos un cierto hash, distribuyendo aleatoriamente todos los datos en nuestro clúster de manera bastante aleatoria, y tenemos otro problema.

Si en el esquema anterior al menos algunas consultas funcionaron bien, entonces el
100% de las consultas son estúpidas aquí , porque la mayoría de las consultas de la base de datos están conectadas con el
recorrido del gráfico. Cualquier desvío desde el nodo debe ir a algún lado, y la mayoría de las veces, para calcular la solicitud, debe ir a otro nodo.

La idea surge como un fragmento aproximadamente, como se muestra en el diagrama anterior: encuentre grupos y colóquelos en sus nodos: los subconjuntos estrechamente conectados se colocan juntos, los subconjuntos débilmente conectados están espaciados.
Esta es una opción ideal, pero la
opción ideal solo existe en teoría . Los datos en vivo no se prestan a particiones estáticas. Para implementar este enfoque, debemos detectar automáticamente los clústeres en un conjunto que cambia dinámicamente, mover nodos constantemente dependiendo de los enlaces emergentes y desaparecidos.
Por lo tanto, Neo4j en general ahora se escala como bases de datos SQL clásicas. Han estado trabajando en fragmentar durante bastante tiempo, tratando de resolver los problemas descritos.
La tesis que expuse es que el
escalado horizontal ejerce
presión sobre todos , y que tarde o temprano todos los modelos de datos se verán obligados a implementarlo. Pero algunos modelos permanecerán con nosotros, mientras que otros no.
Entonces, por ejemplo, si consideramos las bases de datos Key-Value y Document en forma pura, entonces mi afirmación es que no lo serán. Si observa las bases de datos de gráficos, ya ocupan un segmento significativo, pero están bajo la presión de la escala horizontal.
¿Desaparecerán las bases de datos de gráficos? Es más probable que las
columnas, como los documentos, se incluyan en todos los productos . Esta tendencia se denomina bases de datos multimodelos, y más adelante en el informe daré un ejemplo de cómo esto puede funcionar en la práctica. Pero por ahora, como otra ilustración de la tendencia de las bases de datos multimodelos, veamos JSON.
Json
A continuación se muestra un ejemplo de cómo funciona una tendencia que se está volviendo global.
Sostengo que cualquier base de datos que sea capaz de admitir JSON de alguna manera admitirá JSON.
Quizás algunas bases de datos para la computación matricial no admitan JSON. Pero lo más probable allí será útil. Y todo lo demás definitivamente lo será.
| MySQL
| PostgreSQL
| Redis
| Couchbase
| Cassandra
| Neo4j
|
Almacenamiento JSON
| Si
| Si
| Si
| Si
| Si
| Si!
|
Operaciones de campo JSON
| Si
| Si
| Si
| Si
| No
| No
|
Consulta Json
| Si
| Si
| No
| Si
| Si
| No
|
Índice secundario JSON
| Si
| Si
| No
| Si
| No
| No
|
Esta tabla le permite ver visualmente lo que sucede con los modelos de datos. Las bases de datos relacionales en su soporte para JSON están incluso por delante de las no relacionales de la misma Cassandra. No tiene claves secundarias para los campos JSON. E incluso las bases de datos de gráficos también están comenzando a incluir JSON, porque
todos necesitan JSON .
Por lo tanto, las bases de datos multimodelos, y en particular JSON como el tipo de datos que se encuentra en casi todos los productos, es lo que quedará de NoSQL de manera seria y permanente.
Pero si todas las bases de datos admiten JSON, ¿por qué necesita bases de datos NoSQL?Solo queda una historia: escala horizontal. Queremos escalar horizontalmente, y es por eso que usamos algo diferente a MySQL o PostgreSQL.

Esta es la nota clave de Thomas Ulin, vicepresidente de ingeniería de MySQL en Oracle, que habla sobre el futuro de MySQL. Lo mismo sucede en la comunidad de Postgres y otros productos relacionales. La presión del escalado horizontal afecta al 100% de los productos debido a la transición a la hiperconvergencia y la computación en la nube.
Thomas dice que su visión es un producto con alta disponibilidad y escalabilidad fuera de la caja. Estamos hablando de alta disponibilidad principalmente InnoDB Cluster, esto es replicación grupal + InnoDB. Tal base de datos nunca muere, incluso si es golpeada con un martillo.
Luego, Thomas escribe "
características de escala integradas " - "hemos preparado todas estas características". El punto es que a través de las versiones x (creo que x = 2, 3) recibirán MySQL Cluster en su forma pura, que admitirá SQL en el clúster, almacenamiento JSON en el clúster.
Hoy,
MySQL tiene un protocolo X que es muy similar a MongoDB y está diseñado para funcionar con JSON.
SQL en NoSQL
Ahora veamos el movimiento desde el otro lado. Para declarar la muerte, debe observar no solo cómo SQL adopta los principios de NoSQL, sino también viceversa.
| Mongodb
| Couchbase
| Cassandra
| Redis
|
Esquema de datos
| Sí *
| No
| Si
| No
|
NULL / valores ausentes
| Sí *
| Si
| Si
| No
|
Se une
| Si
| Si
| No
| No
|
Llaves secundarias
| Sí *
| Si
| Si pero ...
| No
|
GRUPO POR
| Sí *
| Si
| No
| No
|
JDBC / ODBC
| No
| Si
| No
| No
|
Aquí, de hecho, también hay ideas interesantes. Tomé, en mi opinión, los líderes. Estoy de acuerdo en que no todo está aquí, por ejemplo, Elastic también es un líder NoSQL. Pero Elastic sigue siendo principalmente una solución para la búsqueda de texto completo, por lo que no lo incluí en la tabla.
Bases de datos de series de tiempo como una tendencia que no toco. Existe una tesis entre las series de movimientos de tiempos que dice que este es un nicho separado, similar a las bases de datos de gráficos, pero si profundiza, Postgres se sienta debajo del capó.
Couchbase
En mi opinión, Couchbase tiene la gama más amplia de posibilidades del mundo SQL. Todos saben que
Couchbase es Memcached . Dormando (
Alan Kasindorf ), uno de los desarrolladores de Memcached, tenía una visión del producto completamente diferente, que no implicaba escala horizontal. Por lo tanto, Memcache se bifurcó para escalar horizontalmente. Todo salió bien y comenzó a hacer negocios a su alrededor, luego se fusionó con CouchDB y así sucesivamente.
Couchbase inicialmente se dice a sí mismo que son una
base de datos sin esquema . Memcache es originalmente un valor clave muy simple. Ahora veamos cómo esta autoidentificación cambia con el tiempo.
Por ejemplo, Couchbase tiene claves secundarias, y las
claves secundarias son en realidad el comienzo del esquema . Si dice que tiene algunos campos por los cuales construye el índice, significa que ya está hablando sobre el esquema de estos documentos que almacena.
Además, a medida que Couchbase recorta gradualmente toda la historia sobre el pasado de Memcache de la documentación de hoy, también recortará la historia sobre la consistencia eventual mañana, aunque hoy todavía hay muchas historias sobre la falta de consistencia de lectura: las claves secundarias finalmente son consistentes.
Pero el problema es que Couchbase tiene JDBC / ODBC. , Tableau ClickView — , CQL SQL.
— SQL., .

, - , , , - — , SQL.
, IS MISSING — , IS NULL?
JDBC, ODBC SQL ? 30-40 , SQL- SQL , , : look-in, , ..
, .
, , ., Couchbase JDBC/ODBC — . , — .
Secondary keys
, NoSQL — , — , . OrientDB, , , .
SQL- , ( , ), NoSQL, .
NoSQL- secondary keys. secondary keys?
( — ):
- , , . , range-, SQL . range- map/reduce .
- . index notes, . range- .., .
, , , , , . , .
. , NoSQL- SQL, , , .
: CockroachDB? :
, . , MySQL — legacy. , , ..
, NoSQL- legacy 10 . , , . SQL- , PostgreSQL, , MySQL Couchbase , True NewSQL.
, secondary keys. MongoDB SQL, . , JOINs, , .
Redis No, . Redis , — . , , , .
, Redis — , - . , Redis-, SQL. , Redis SQLite, — storage — Redis', in memory.
NoSQL , , ?
, NoSQL . , , , SQL . SQL .
schemaless , , , waterfall : agile, - . , , CREATE TABLE, .
, online alter table. Oracle , .
SQL , .
MongoDB — , .
MongoDB , schemaless. . , , strict. validation level validation action. Validation level , .
, , - . , , . validation action reject, warn: warning, validation action.
. , MongoDB ( Tarantool), .
Cassandra JSON, . — , . , , NoSQL, .
-, NoSQL SQL .

eventually consistent , , ,
. , — . .
?
, , . BigQuery , , Vertica, .
NoSQL . , SELECT LTP, LTP - Key-value.
, NoSQL- .
SELECT JOIN , , ,
— ..
NoSQL:
,
, , .
domain-specific languages .
NoSQL DSL. —
RethinkDB ReQL . , — domen specific language. Python, JavaScript .. — . SQL , .
ReQL, . ReQL , , — . RethinkDB, , , , , .
:
- Elasticsearch Query Language:
- MIN/MAX/AVG;
- derivative/percentiles/histogram/cumulative sum/serial diff;
- JSONIQ;
- GraphQL;
- SparQL;
- Pregel.
, , SQL, .
- SQL!SQL — OLTP , GROUP BY, Window Functions, (recursive). SQL , . ! , , .
, , . , , , , .
, , Pregel — . : , / . - , . , , .
- SQL, , , .
, ,
, , . .
-
, , . .

ArangoDB, - : , , ( ), , .

, , . . : , .
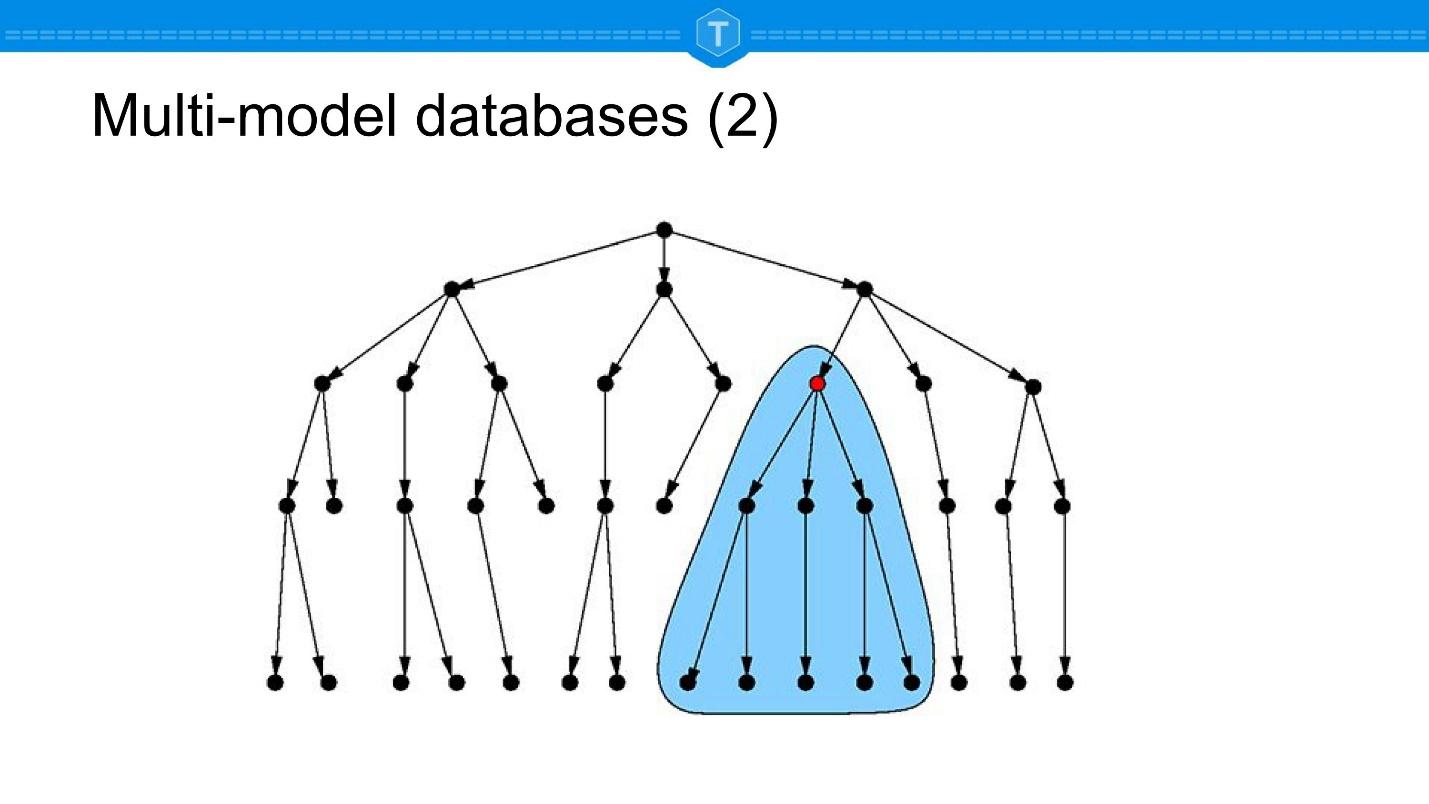
, , . , , , , . .
. , , relations. , relation , , relations ..
UPSERT:
No se trata completamente de NoSQL, pero esta es una tendencia que me parece muy importante: se trata de
almacenamiento optimizado para escritura , que, en mi opinión, permanecerá con nosotros seriamente y durante mucho tiempo.
Ni SQL ni NoSQL tienen declaraciones que se escriben solo por naturaleza. Incluso absert, que está en MongoDB, en varios casos también lee datos. Insertar también es una operación de lectura, porque si una ID ya está definida en el documento, entonces debe verificar que no existe dicha ID.
Usted dice: si hay índices, entonces debemos leer. Pero
incluso si hay índices, la lectura no siempre es necesaria . La idea es esta: no desea leer en ningún caso, no necesita hacerlo, no le importa el resultado de la lectura. Desea agregar datos a la base de datos si aún no existe. Si existen, supongamos que reemplaza su versión anterior por una nueva o ejecuta algún tipo de comando de combinación. Es decir, debe inventar una
nueva semántica para no leer.
En mi opinión, ni una sola base de datos proporciona esto ahora, pero el atractivo de los algoritmos de escritura optimizados es tan grande que realmente quiero esta posibilidad. Debido a que gracias al almacenamiento optimizado de escritura, los árboles de LSM (RocksDB, LevelDB y otros)
rendimiento de escritura sin lectura es 2 órdenes de magnitud mayor que el rendimiento de escritura con lectura . En lugar de 10 mil solicitudes por segundo, puede haber un millón en un nodo.
Es por eso que la base de datos de series temporales ahora está ganando porque carecen de esta brecha semántica. El flujo de datos que llega en ellos se define claramente como una serie temporal y se escribe de manera muy rápida y compacta en la base de datos, en particular. porque no necesitas verificar la unicidad. Este es un orden de magnitud más rápido simplemente porque en las bases de datos tradicionales no existe tal operación semántica que solo se escribiría.
Creo que aparecerá

¿A dónde va todo esto después? Si miras muy lejos, la innovación no se detiene en NoSQL y NewSQL. Nuestra comprensión de la información está en constante evolución.
Una de las tendencias más importantes del futuro, en mi opinión, es que eliminaremos cada vez menos información.
Para esto, nace toda una serie de productos, que se denominan bases de datos temporales.
Después de NewSQL: base de datos temporal
A continuación se muestran capturas de pantalla de Microsoft SQL Server. Esta es una base de datos que le permite hacer preguntas en un momento dado: hay SELECT para el estado actual, pero aún es posible hacer SELECT para alguna fecha en el pasado.

Esto genera una serie de nuevas aplicaciones de bases de datos. En primer lugar, puede rastrear el historial de un objeto. En segundo lugar, puede calcular automáticamente grupos, informes por período. No necesita crear tablas separadas para esto: tiene una representación natural en una tabla: una entidad, una tabla.
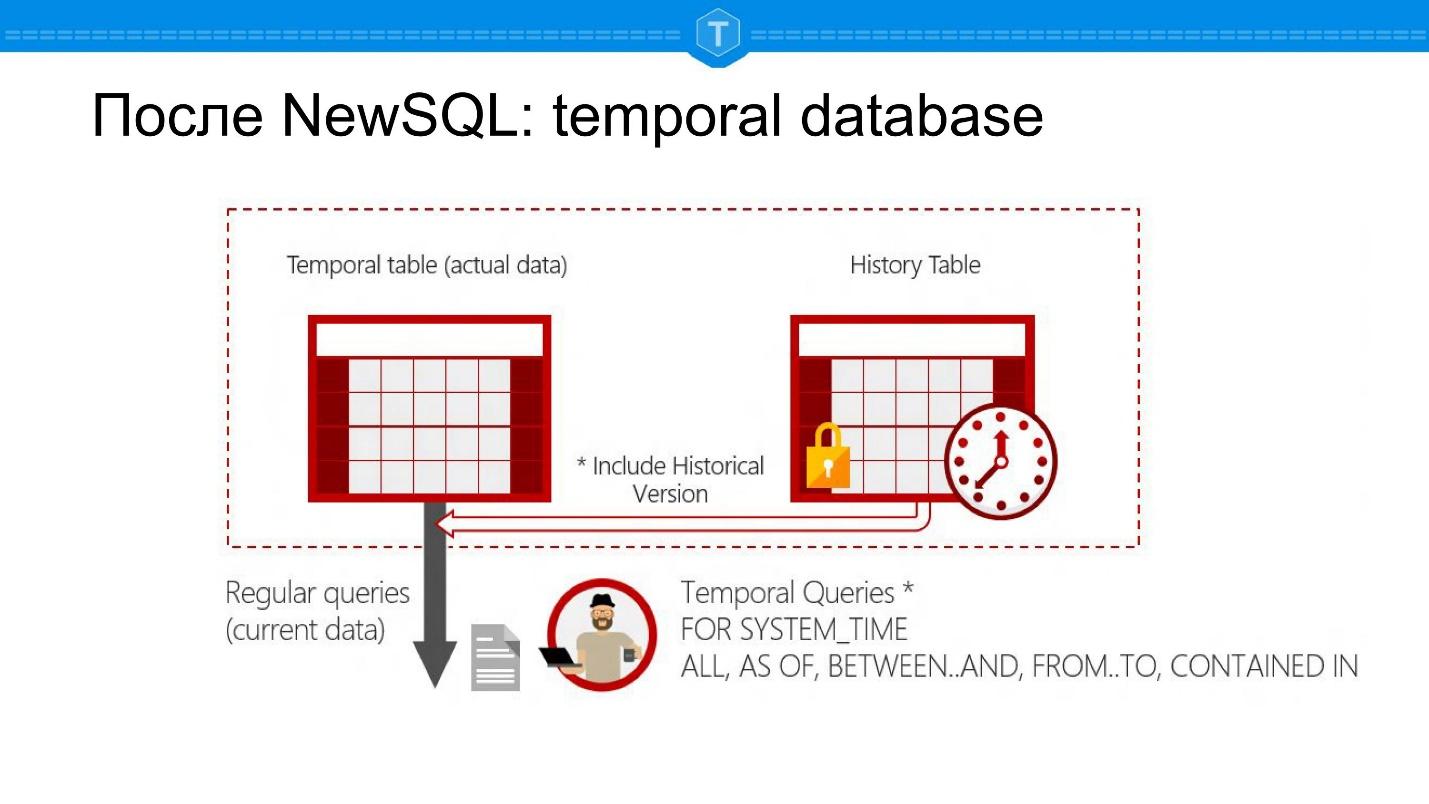
Desde el punto de vista de la estructura interna, esta es en realidad la tabla principal y la tabla con el historial. Cada línea está asociada con dos veces conocidas por el sistema. Estas no son solo dos columnas que agregó, sino datos que el sistema admite automáticamente:
- la hora en que se agregó el registro a la base de datos,
- hora del evento
Estos son tiempos diferentes, no importa cuán divertido.
Supongamos que Ivan Ivanovich murió el 17 de noviembre, y este registro se ingresó en la base de datos el 20 de noviembre; ambos tiempos se almacenan en dichas bases de datos.
En mi opinión, esta es también una de las tendencias fundamentales. ¿Por qué pienso eso? Si volvemos a las claves secundarias y la coherencia eventual, almacenar absolutamente todo solo le permite resolver este problema con elegancia.
Si nunca necesitamos eliminar nada de la base de datos, nuestra base de datos siempre es coherente, ¡una historia tan interesante!
Enlaces utiles
FAQ- ¿Hay algún desarrollo en la creación de una nueva base de datos que no se aplique a MySQL, PostgreSQL, MongoDB, etc.?
En el buen sentido, la pregunta es: ¿habrá nuevas bases de datos, nuevas empresas? Creo que aparecerán cada vez menos. La tormenta ha disminuido, y ahora veremos la salida antes que la llegada, CockroachDB fue uno de los últimos en llegar.
Vayamos al grano. Mi profesor en la universidad dijo que DBMS es un área eternamente verde. Por lo tanto, siempre veremos algún tipo de movimiento. Pero creo que en el futuro cercano no aparecerán productos fundamentalmente diferentes, habrá convergencia, no un auge.
- No es una pregunta, sino más bien una adición: SQL a menudo intenta hacer índices de cobertura para que el resultado de la consulta SQL no afecte al nivel de almacenamiento, sino que se obtiene inmediatamente del índice. El índice en sí mismo es en realidad un caso especial del gráfico. Entonces, ¿tal vez la tendencia es que toda la base de datos fluya gradualmente en un índice de gráfico empinado?
Esta es una historia maravillosa que a todos los representantes de las bases de datos de gráficos les encanta contar a sus clientes: ¡no funciona! Porque hay muchas maneras de actualizar los índices, y hay muchas opciones de indexación, ¡pero no todos tienen un gráfico! Vamos a calmarnos, así como no todo es relacional, tampoco todos son un gráfico.
- En tu opinión, ¿a dónde irán Elastic y similares? Me refiero al hecho de que está empezando a resolver problemas muy extraños: está tratando de simular series de tiempo y una base analítica para trabajar con registros. Parece que nadie lo usa para la búsqueda de texto.
Elastic no tiene que moverse a ninguna parte porque Elastic se siente genial. Resuelve un problema comercial específico: es una búsqueda efectiva y todo lo relacionado con este ecosistema.
Creo que todo proviene principalmente del hecho de que Elastic está tratando de ser todo. Pero aquí la pregunta es de la tarea, la tarea Elastic es muy similar a las tareas de series de tiempo, por lo tanto, está justificada. Elastic es bueno para buscar en grandes matrices de los mismos registros, etc.
Hay un caso más estrecho: es solo una búsqueda de texto completo, pero no hará mucho de eso. Se necesita hacer más para diferenciarse de los competidores en primer lugar. Por lo tanto, todo esto está sucediendo.
Pero no creo que Elastic haga transacciones bancarias mañana. Todo llega al punto en que Couchbase, por ejemplo, será, si no transacciones bancarias, sino algo tan rápido.
Noticias
Muy pronto, el 21 de junio, la Conferencia de Tarantool tendrá lugar en Moscú , o brevemente T + Conf , una conferencia no solo sobre Tarantool en sí, sino sobre el uso de la computación en memoria en general .
- Konstantin Osipov planea hacer un informe en el que examinará la arquitectura de Vinyl, sus capacidades y, lo más importante, los mecanismos de ajuste y monitoreo de rendimiento específicos de este motor de la manera más consistente y detallada posible.
- Vladimir Perepelitsa, en formato tutorial, quiere mostrar que Tarantool es una base de datos que tiene un gran potencial para su uso como servidor de aplicaciones.
- Vladislav Zaitsev va a abordar este tema desde su lado, desde el lado de Internet de las cosas y contar , en particular, por qué el sistema de control de IoT.