Cada uno de nosotros hace una tarea. Todos escriben código repetitivo. Por qué ¿No es mejor automatizar este proceso y trabajar solo en tareas interesantes? Lea este artículo si desea que la computadora haga ese trabajo por usted.
 Este artículo se basa en una transcripción de un informe de Zack Sweers, un desarrollador de aplicaciones móviles de Uber, que habló en la conferencia MBLT DEV en 2017.
Este artículo se basa en una transcripción de un informe de Zack Sweers, un desarrollador de aplicaciones móviles de Uber, que habló en la conferencia MBLT DEV en 2017.
Uber tiene alrededor de 300 desarrolladores de aplicaciones móviles. Trabajo en un equipo llamado "plataforma móvil". El trabajo de mi equipo es simplificar y mejorar el proceso de desarrollo de aplicaciones móviles tanto como sea posible. Principalmente trabajamos en marcos internos, bibliotecas, arquitecturas, etc. Debido al gran personal, tenemos que hacer proyectos a gran escala que nuestros ingenieros necesitarán en el futuro. Puede ser mañana, o tal vez el próximo mes o incluso un año.
Generación de código para automatización
Me gustaría demostrar el valor del proceso de generación de código, así como considerar algunos ejemplos prácticos. El proceso en sí se parece a esto:
FileSpec.builder("", "Presentation") .addComment("Code generating your way to happiness.") .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", "Zac Sweers") .useSiteTarget(FILE) .build()) .build()
Este es un ejemplo del uso de Kotlin Poeta. Kotlin Poet es una biblioteca con una buena API que genera código Kotlin. Entonces, ¿qué vemos aquí?
- FileSpec.builder crea un archivo llamado " Presentación ".
- .addComment () - Agrega un comentario al código generado.
- .addAnnotation () - Agrega una anotación de tipo Autor .
- .addMember () - agrega una variable " nombre " con un parámetro, en nuestro caso es " Zac Sweers ". % S - tipo de parámetro.
- .useSiteTarget () - Instala SiteTarget.
- .build () : completa la descripción del código que se generará.
Después de la generación del código, se obtiene lo siguiente:
Presentation.kt // Code generating your way to happiness. @file:Author(name = "Zac Sweers")
El resultado de la generación de código es un archivo con el nombre, comentario, anotación y nombre del autor. La pregunta surge de inmediato: "¿Por qué necesito generar este código si puedo hacerlo en un par de pasos simples?" Sí, tienes razón, pero ¿qué pasa si necesito miles de estos archivos con diferentes opciones de configuración? ¿Qué sucede si comenzamos a cambiar los valores en este código? ¿Qué pasa si tenemos muchas presentaciones? ¿Qué pasa si tenemos muchas conferencias?
conferences .flatMap { it.presentations } .onEach { (presentationName, comment, author) -> FileSpec.builder("", presentationName) .addComment(comment) .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", author) .useSiteTarget(FILE) .build()) .build() }
Como resultado, llegaremos a la conclusión de que es simplemente imposible mantener tal cantidad de archivos manualmente, es necesario automatizar. Por lo tanto, la primera ventaja de la generación de código es deshacerse del trabajo de rutina.
Generación de código sin errores
La segunda ventaja importante de la automatización es la operación sin errores. Todas las personas cometen errores. Esto sucede especialmente a menudo cuando hacemos lo mismo. Las computadoras, por el contrario, hacen un trabajo a la perfección.
Considere un ejemplo simple. Hay una clase de persona:
class Person(val firstName: String, val lastName: String)
Supongamos que queremos agregarle serialización en JSON. Haremos esto usando la biblioteca
Moshi , ya que es bastante simple y genial para la demostración. Cree un PersonJsonAdapter y herede de JsonAdapter con un parámetro de tipo Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { }
A continuación, implementamos el método fromJson. Proporciona un lector para leer información que finalmente se devolverá a Persona. Luego completamos los campos con el nombre y apellido y obtenemos el nuevo valor Persona:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String return Person(firstName, lastName) } }
A continuación, observamos los datos en formato JSON, los verificamos y los ingresamos en los campos necesarios:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() } } return Person(firstName, lastName) } }
¿Funcionará esto? Sí, pero hay un matiz: los objetos que leemos deben estar contenidos dentro de JSON. Para filtrar el exceso de datos que pueden provenir del servidor, agregue otra línea de código:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() else -> reader.skipValue() } } return Person(firstName, lastName) } }
En este punto, eludimos con éxito el área del código de rutina. En este ejemplo, solo dos campos de valor. Sin embargo, este código tiene un montón de secciones diferentes donde podría bloquearse repentinamente. ¿De repente cometimos un error en el código?
Considere otro ejemplo:
class Person(val firstName: String, val lastName: String) class City(val name: String, val country: String) class Vehicle(val licensePlate: String) class Restaurant(val type: String, val address: Address) class Payment(val cardNumber: String, val type: String) class TipAmount(val value: Double) class Rating(val numStars: Int) class Correctness(val confidence: Double)
Si tiene al menos un problema cada 10 modelos más o menos, esto significa que definitivamente tendrá dificultades en esta área. Y este es el caso cuando la generación de código realmente puede ayudarlo. Si hay muchas clases, no podrá trabajar sin automatización, porque todas las personas permiten errores tipográficos. Con la ayuda de la generación de código, todas las tareas se realizarán automáticamente y sin errores.
Hay otros beneficios para la generación de código. Por ejemplo, proporciona información sobre el código o le dice si algo sale mal. La generación de código será útil durante la fase de prueba. Si usa el código generado, puede ver cómo se verá realmente el código de trabajo. Incluso puede ejecutar la generación de código durante las pruebas para simplificar su trabajo.
Conclusión: vale la pena considerar la generación de código como una posible solución para deshacerse de los errores.
Ahora echemos un vistazo a las herramientas de software que ayudan con la generación de código.
Las herramientas
- Las bibliotecas JavaPoet y KotlinPoet para Java y Kotlin, respectivamente. Estos son los estándares de generación de código.
- Patronación Un ejemplo popular de plantillas para Java es Apache Velocity , y para iOS Handlebars .
- SPI - Interfaz de procesador de servicio. Está integrado en Java y le permite crear y aplicar una interfaz y luego declararla en un JAR. Cuando se ejecuta el programa, puede obtener todas las implementaciones listas para usar de la interfaz.
- Compile Testing es una biblioteca de Google que ayuda con las pruebas de compilación. En términos de generación de código, esto significa: "Esto es lo que esperaba, pero esto es lo que finalmente obtuve". La compilación comenzará en la memoria, y luego el sistema le dirá si este proceso se completó o qué errores ocurrieron. Si la compilación se ha completado, se le pedirá que compare el resultado con sus expectativas. La comparación se basa en el código compilado, así que no se preocupe por cosas como el formato del código o cualquier otra cosa.
Herramientas de compilación de código
Hay dos herramientas principales para construir código:
- Procesamiento de anotaciones : puede escribir anotaciones en el código y solicitar al programa información adicional sobre ellas. El compilador proporcionará información incluso antes de que termine de trabajar con el código fuente.
- Gradle es un sistema de ensamblaje de aplicaciones con muchos ganchos (gancho - intercepción de llamadas a funciones) en su ciclo de vida de ensamblaje de código. Es ampliamente utilizado en el desarrollo de Android. También le permite aplicar la generación de código al código fuente, que es independiente de la fuente actual.
Ahora considere algunos ejemplos.
Cuchillo de mantequilla
Butter Knife es una biblioteca desarrollada por Jake Wharton. Es una figura bien conocida en la comunidad de desarrolladores. La biblioteca es muy popular entre los desarrolladores de Android porque ayuda a evitar la gran cantidad de trabajo de rutina que casi todos enfrentan.
Por lo general, inicializamos la vista de esta manera:
TextView title; ImageView icon; void onCreate(Bundle savedInstanceState) { title = findViewById(R.id.title); icon = findViewById(R.id.icon); }
Con Butterknife, se verá así:
@BindView(R.id.title) TextView title; @BindView(R.id.icon) ImageView icon; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
Y podemos agregar fácilmente cualquier cantidad de vistas, mientras que el método onCreate no aumentará el código repetitivo:
@BindView(R.id.title) TextView title; @BindView(R.id.text) TextView text; @BindView(R.id.icon) ImageView icon; @BindView(R.id.button) Button button; @BindView(R.id.next) Button next; @BindView(R.id.back) Button back; @BindView(R.id.open) Button open; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
En lugar de hacer este enlace manualmente cada vez, simplemente agregue anotaciones @BindView a estos campos, así como los identificadores (ID) a los que están asignados.
Lo bueno de Butter Knife es que analizará el código y generará todas sus secciones similares para usted. También tiene una excelente escalabilidad para nuevos datos. Por lo tanto, si aparecen nuevos datos, no hay necesidad de aplicar onCreate nuevamente o rastrear algo manualmente. Esta biblioteca también es excelente para eliminar datos.
Entonces, ¿cómo se ve este sistema desde adentro? La vista se busca por reconocimiento de código, y este proceso se realiza en la etapa de procesamiento de anotaciones.
Tenemos este campo:
@BindView(R.id.title) TextView title;
A juzgar por estos datos, se utilizan en una determinada actividad de FooActivity:
Ella tiene su propio significado (R.id.title), que actúa como el objetivo. Tenga en cuenta que durante el procesamiento de datos este objeto se convierte en un valor constante dentro del sistema:
Esto es normal Esto es a lo que Butter Knife debería tener acceso de todos modos. Hay un componente TextView como tipo. El campo en sí se llama título. Si, por ejemplo, hacemos una clase contenedor a partir de estos datos, obtenemos algo como esto:
ViewBinding( target = "FooActivity", id = 2131361859, name = "title", type = "field", viewType = TextView.class )
Por lo tanto, todos estos datos se pueden obtener fácilmente durante su procesamiento. También es muy similar a lo que hace Butter Knife dentro del sistema.
Como resultado, esta clase se genera aquí:
public final class FooActivity_ViewBinding implements Unbinder { private FooActivity target; @UiThread public FooActivity_ViewBinding(FooActivity target, View source) { this.target = target; target.title = Utils.findRequiredViewAsType(source, 2131361859,
Aquí vemos que todos estos datos se reúnen. Como resultado, tenemos la clase de destino ViewBinding de la biblioteca Java de Underscore. En el interior, este sistema está organizado de tal manera que cada vez que crea una instancia de la clase, realiza inmediatamente todo este enlace a la información (código) que generó. Y todo esto se genera previamente de forma estática durante el procesamiento de anotaciones, lo que significa que es técnicamente correcto.
Volvamos a nuestra tubería de software:
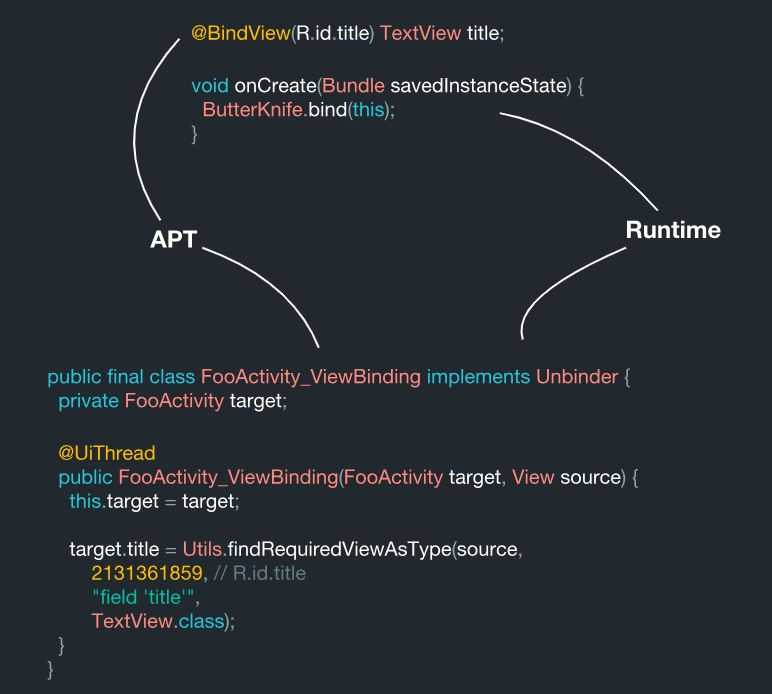
Durante el procesamiento de anotaciones, el sistema lee estas anotaciones y genera la clase ViewBinding. Y luego, durante el método de enlace, realizamos una búsqueda idéntica para la misma clase de una manera simple: tomamos su nombre y agregamos el enlace de vista al final. Por sí misma, una sección con ViewBinding durante el procesamiento se sobrescribe en el área especificada utilizando JavaPoet.
Rxbindings
RxBindings solo no es responsable de la generación de código. No maneja anotaciones y no es un complemento de Gradle. Esta es una biblioteca ordinaria. Proporciona fábricas estáticas basadas en el principio de programación reactiva para la API de Android. Esto significa que, por ejemplo, si ha configurado SetOnClickListener, aparecerá un método de clic que devolverá una secuencia de eventos (Observables). Actúa como un puente (patrón de diseño).
Pero en realidad hay generación de código en RxBinding:
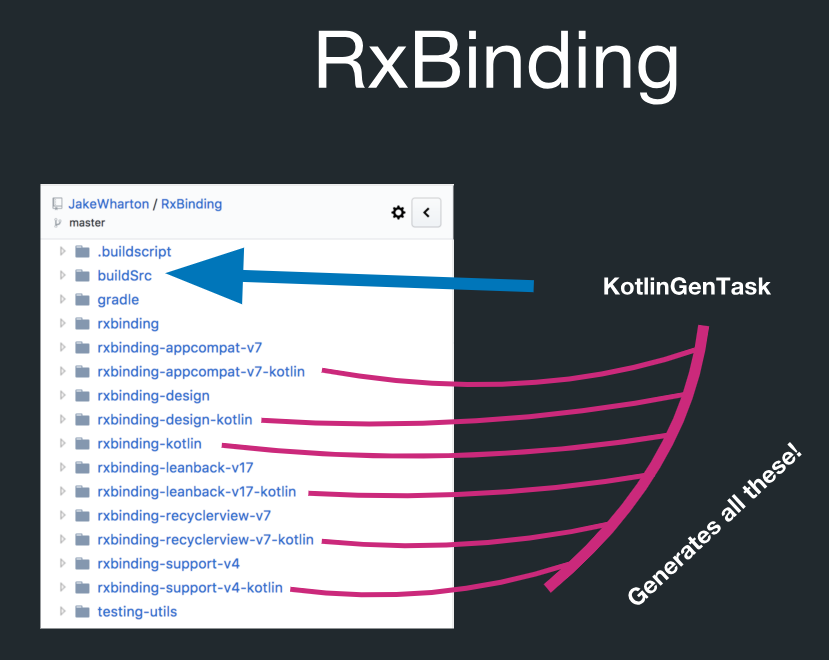
En este directorio llamado buildSrc hay una tarea de Gradle llamada KotlinGenTask. Esto significa que todo esto es realmente creado por la generación de código. RxBinding tiene implementaciones de Java. Ella también tiene artefactos de Kotlin que contienen funciones de extensión para todos los tipos de objetivos. Y todo esto está estrictamente sujeto a las reglas. Por ejemplo, puede generar todas las funciones de extensión de Kotlin y no tiene que controlarlas individualmente.
¿Cómo se ve realmente?
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Aquí hay un método RxBinding completamente clásico. Los objetos observables se devuelven aquí. El método se llama clics. Trabajar con eventos de clic se lleva a cabo "bajo el capó". Omitimos los fragmentos de código adicionales para mantener la legibilidad del ejemplo. En Kotlin, se ve así:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
Esta función de extensión devuelve objetos observables. En la estructura interna del programa, llama directamente a la interfaz Java habitual para nosotros. En Kotlin, debe cambiar esto a Tipo de unidad:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Es decir, en Java, se ve así:
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Y también lo es el código de Kotlin:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Tenemos una clase RxView que contiene este método. Podemos sustituir los datos correspondientes en el atributo de destino, en el atributo de nombre con el nombre del método y en el tipo que estamos expandiendo, así como en el tipo del valor de retorno. Toda esta información será suficiente para comenzar a escribir estos métodos:
BindingMethod( target = "RxView", name = "clicks", type = View.class, returnType = "Observable<Unit>" )
Ahora podemos sustituir directamente estos fragmentos en el código Kotlin generado dentro del programa. Aquí está el resultado:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Servicio gen
Estamos trabajando en Service Gen en Uber. Si trabaja en una empresa y maneja características generales y una interfaz de software común tanto para el lado del cliente como para el servidor, independientemente de si está desarrollando aplicaciones Android, iOS o web, no tiene sentido crear modelos y servicios manualmente para el trabajo en equipo
Utilizamos la biblioteca
AutoValue de Google para modelos de objetos. Procesa anotaciones, analiza datos y genera un código hash de dos líneas, el método equals () y otras implementaciones. Ella también es responsable de soportar extensiones.
Tenemos un objeto de tipo Rider:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Tenemos líneas con ID, nombre, apellido y dirección. Para trabajar con la red, utilizamos las bibliotecas Retrofit y OkHttp, y JSON como formato de datos. También usamos RxJava para la programación reactiva. Así es como se ve nuestro servicio API generado:
interface UberService { @GET("/rider") Rider getRider() }
Podemos escribir todo esto manualmente, si así lo deseamos. Y durante un largo período de tiempo, lo hicimos. Pero lleva mucho tiempo. Al final, cuesta mucho en términos de tiempo y dinero.
¿Qué y cómo hace Uber hoy?
La última tarea de mi equipo es crear un editor de texto desde cero. Decidimos dejar de escribir manualmente el código que posteriormente llega a la red, por lo que usamos
Thrift . Es algo así como un lenguaje de programación y un protocolo al mismo tiempo. Uber usa Thrift como lenguaje para especificaciones técnicas.
struct Rider { 1: required string uuid; 2: required string firstName; 3: required string lastName; 4: optional Address address; }
En Thrift, definimos contratos de API entre el backend y el lado del cliente, y luego simplemente generamos el código apropiado. Usamos la biblioteca
Thrifty para analizar datos y JavaPoet para la generación de código. Al final, generamos implementaciones usando AutoValue:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Hacemos todo el trabajo en JSON. Existe una extensión llamada
AutoValue Moshi , que se puede agregar a las clases de AutoValue utilizando el método estático jsonAdapter:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); static JsonAdapter<Rider> jsonAdapter(Moshi moshi) { return new AutoValue_Rider.JsonAdapter(moshi); } }
Thrift también ayuda en el desarrollo de servicios:
service UberService { Rider getRider() }
También tenemos que agregar algunos metadatos aquí para hacernos saber qué resultado final queremos lograr:
service UberService { Rider getRider() (path="/rider") }
Después de la generación del código, recibiremos nuestro servicio:
interface UberService { @GET("/rider") Single<Rider> getRider(); }
Pero este es solo uno de los posibles resultados. Un modelo Como sabemos por experiencia, nadie ha usado solo un modelo. Tenemos muchos modelos que generan código para nuestros servicios:
struct Rider struct City struct Vehicle struct Restaurant struct Payment struct TipAmount struct Rating
Por el momento tenemos alrededor de 5-6 aplicaciones. Y tienen muchos servicios. Y todos pasan por la misma tubería de software. Escribir todo esto a mano sería una locura.
En la serialización en JSON, el "adaptador" no necesita estar registrado en Moshi, y si usa JSON, entonces no necesita registrarse en JSON. También es dudoso sugerir a los empleados que realicen la deserialización reescribiendo el código a través de un gráfico DI.
Pero trabajamos con Java, por lo que podemos usar el patrón Factory, que generamos a través de la biblioteca
Fractory . Podemos generar esto porque conocemos estos tipos antes de que ocurriera la compilación. Fractory genera un adaptador como este:
class ModelsAdapterFactory implements JsonAdapter.Factory { @Override public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) { Class<?> rawType = Types.getRawType(type); if (rawType.isAssignableFrom(Rider.class)) { return Rider.adapter(moshi); } else if (rawType.isAssignableFrom(City.class)) { return City.adapter(moshi); } else if (rawType.isAssignableFrom(Vehicle.class)) { return Vehicle.adapter(moshi); }
El código generado no se ve muy bien. Si le duele el ojo, puede reescribirse manualmente.
Aquí puede ver los tipos mencionados anteriormente con los nombres de los servicios. El sistema determinará automáticamente qué adaptadores seleccionará y los llamará. Pero aquí nos enfrentamos a otro problema. Tenemos 6000 de estos adaptadores. Incluso si los divide entre ellos dentro de la misma plantilla, el modelo "Come" o "Conductor" caerá en el modelo "Jinete" o estará en su aplicación. El código se extenderá. Después de cierto punto, ni siquiera puede caber en un archivo .dex. Por lo tanto, debe separar de alguna manera los adaptadores:

Finalmente, analizaremos el código de antemano y crearemos un subproyecto de trabajo para él, como en Gradle:

En la estructura interna, estas dependencias se convierten en dependencias de Gradle. Los elementos que usan la aplicación Rider ahora dependen de ella. Con él, formarán los modelos que necesitan. Como resultado, nuestra tarea se resolverá y todo esto estará regulado por el sistema de ensamblaje de código dentro del programa.
Pero aquí nos enfrentamos a otro problema: ahora tenemos un número n de modelos de fábrica. Todos ellos se compilan en varios objetos:
class RiderModelFactory class GiftCardModelFactory class PricingModelFactory class DriverModelFactory class EATSModelFactory class PaymentsModelFactory
En el proceso de procesamiento de anotaciones, no será posible leer solo anotaciones a dependencias externas y generar código adicional solo en ellas.
Solución: tenemos un poco de soporte en la biblioteca Fractory, que nos ayuda de una manera complicada. Está contenido en el proceso de enlace de datos. Introducimos metadatos usando el parámetro classpath en el archivo Java para su almacenamiento adicional:
class RiderModelFactory // -> json // -> ridermodelfactory-fractory.bin class MyAppGlobalFactory // Delegates to all discovered fractories
Ahora, cada vez que necesite usarlos en la aplicación, vaya al filtro del directorio classpath con estos archivos y luego extráigalos desde allí en formato JSON para averiguar cuáles de las dependencias están disponibles.
Cómo todo encaja
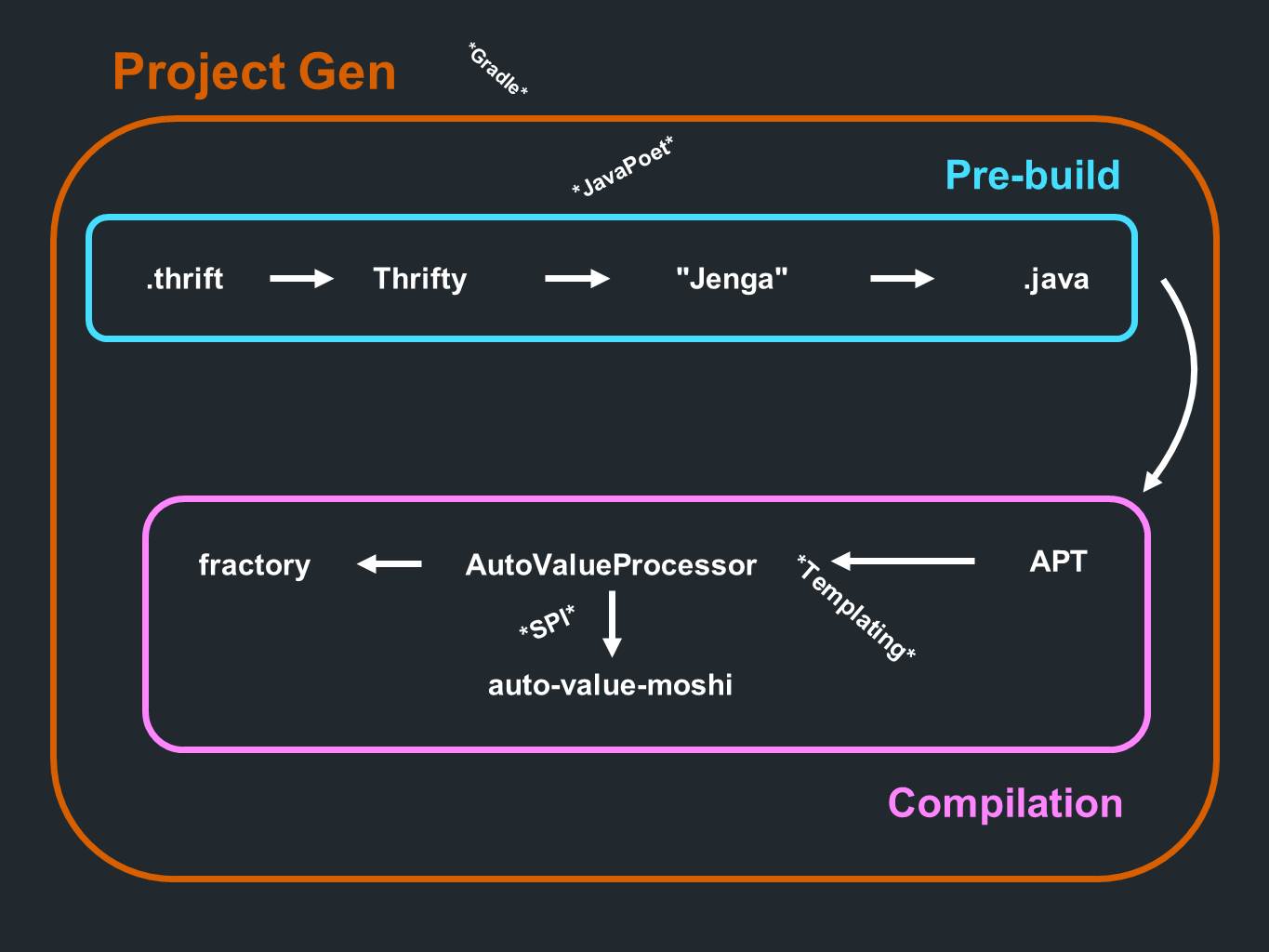
Tenemos un
ahorro . Los datos de allí van a
Thrifty y pasan por el análisis. Luego pasan por un programa de generación de código que llamamos
Jenga . Produce archivos en formato Java. Todo esto sucede incluso antes de la etapa preliminar de procesamiento o antes de la compilación. Y durante el proceso de compilación, se procesan las anotaciones. Es
el turno
de AutoValue para generar una implementación. También llama a
AutoValue Moshi para proporcionar soporte JSON.
Fractory también
está involucrado . Todo sucede durante el proceso de compilación. El proceso está precedido por un componente para crear el proyecto en sí, que genera principalmente subproyectos de
Gradle .
Ahora que ve la imagen completa, comienza a notar las herramientas que se mencionaron anteriormente. Entonces, por ejemplo, está Gradle, creando plantillas, AutoValue, JavaPoet para la generación de código. Todas las herramientas no solo son útiles por sí mismas, sino también en combinación entre sí.Contras de la generación de código
Es necesario contar sobre las trampas. El inconveniente más obvio es hinchar el código y perder el control del mismo. Por ejemplo, Dagger ocupa aproximadamente el 10% de todo el código en la aplicación. Los modelos ocupan una parte significativamente mayor, alrededor del 25%.En Uber, intentamos resolver el problema desechando código innecesario. Tenemos que realizar un análisis estadístico del código y comprender qué áreas están realmente involucradas en el trabajo. Cuando lo descubramos, podemos hacer algunas transformaciones y ver qué sucede.Esperamos reducir la cantidad de modelos generados en aproximadamente un 40%. Esto ayudará a acelerar la instalación y el funcionamiento de las aplicaciones, además de ahorrarnos dinero.Cómo la generación de código afecta los plazos de desarrollo del proyecto
La generación de código, por supuesto, acelera el desarrollo, pero el tiempo depende de las herramientas que utilice el equipo. Por ejemplo, si está trabajando en Gradle, lo más probable es que lo esté haciendo a un ritmo medido. El hecho es que Gradle genera modelos una vez al día, y no cuando el desarrollador lo desea.Obtenga más información sobre el desarrollo en Uber y otras compañías importantes.
El 28 de septiembre, la 5ta Conferencia Internacional de Desarrolladores Móviles MBLT DEV comienza en Moscú . 800 participantes, oradores principales, concursos y rompecabezas para aquellos que estén interesados en el desarrollo de Android e iOS. Los organizadores de la conferencia son e-Legion y RAEC. Puede convertirse en un participante o socio de MBLT DEV 2018 en el sitio web de la conferencia .
Informar video