
El verano pasado, terminó la
competencia en el sitio de kaggle, que se dedicó a la clasificación de imágenes satelitales de los bosques amazónicos. Nuestro equipo ocupó el séptimo lugar de más de 900 participantes. A pesar de que la competencia terminó hace mucho tiempo, casi todos los métodos de nuestra solución siguen siendo aplicables, y no solo para competencias, sino también para la formación de redes neuronales en venta. Para detalles bajo cat.
tldr.pyimport kaggle from ods import albu, alno, kostia, n01z3, nizhib, romul, ternaus from dataset import x_train, y_train, x_test oof_train, oof_test = [], [] for member in [albu, alno, kostia, n01z3, nizhib, romul, ternaus]: for model in member.models: model.fit_10folds(x_train, y_train, config=member.fit_config) oof_train.append(model.predict_oof_tta(x_train, config=member.tta_config)) oof_test.append(model.predict_oof_tta(x_test, config=member.tta_config)) for model in albu.second_level: model.fit(oof_train) y_test = model.predict_proba(oof_test) y_test = kostia.bayes_f2_opt(y_test) kaggle.submit(y_test)
Descripción de la tarea
Planet preparó un conjunto de imágenes satelitales en dos formatos:
- TIF - 16 bits RGB + N, donde N - Cerca del infrarrojo
- JPG - RGB de 8 bits, que se derivan de TIF y que se proporcionaron para reducir el umbral para ingresar a la tarea, así como para simplificar la visualización. En la competencia anterior en Kaggle, era necesario trabajar con imágenes multiespectrales. no visuales, es decir, infrarrojos, así como canales con una longitud de onda más larga, mejoraron en gran medida la calidad de la predicción, tanto de red como de métodos no supervisados.
Geográficamente, los datos se tomaron del territorio de la cuenca del Amazonas y de los territorios de los países de Brasil, Perú, Uruguay, Colombia, Venezuela, Guyana, Bolivia y Ecuador, en los que se seleccionaron áreas de superficie interesantes, cuyas fotografías se ofrecieron a los participantes.
Después de crear jpg desde tif, todas las escenas se cortaron en pequeñas piezas de 256x256. Y de acuerdo con el jpg recibido por los empleados de Planet de las oficinas de Berlín y San Francisco, así como a través de la plataforma Crowd Flower, se realizó el marcado.
Los participantes tenían la tarea de predecir para cada mosaico de 256x256 una de las marcas climáticas mutuamente excluyentes:
Nublado, parcialmente nublado, neblina, claro
Y también 0 o más mal tiempo: agricultura, primaria, tala selectiva, habitación, agua, caminos, cultivo itinerante, floración, minería convencional
Un total de 4 condiciones climáticas y 13 no climáticas, clima mutuamente excluyente, pero sin clima, pero si la imagen está nublada, entonces no debería haber otras etiquetas.

La precisión del modelo se estimó mediante la métrica F2:
Además, todas las etiquetas tenían el mismo peso y primero se calculó F2 para cada imagen, y luego hubo un promedio general. Por lo general, lo hacen de manera un poco diferente, es decir, se calcula una determinada métrica para cada clase y luego se promedia. La lógica es que la última opción es más interpretable, ya que le permite responder a la pregunta de cómo se comporta el modelo en cada clase en particular. En este caso, los organizadores fueron de acuerdo con la primera opción, que, aparentemente, está relacionada con los detalles de su negocio.
Hay 40k muestras en el tren. En la prueba 40k. Debido al pequeño tamaño del conjunto de datos, pero al gran tamaño de las imágenes, podemos decir que esto es "MNIST con esteroides"
Digresión líricaComo puede ver en la descripción, la tarea es bastante comprensible y la solución no tiene sentido: solo necesita archivar la cuadrícula. Y teniendo en cuenta los detalles de la abrazadera, también puede apilar un montón de modelos en la parte superior. Sin embargo, para obtener una medalla de oro, no solo debes entrenar de alguna manera a un montón de modelos. Es imperativo tener muchos modelos diversos básicos, cada uno de los cuales en sí mismo muestra un resultado sobresaliente. Y ya encima de estos modelos puedes terminar apilando y otros hacks.
| miembro | neto | 1 cultivo | Tta | diff,% |
|---|
| alno | densenet121 | 0.9278 | 0.9294 | 0.1736 |
| nizhib | densenet169 | 0.9243 | 0.9277 | 0.3733 |
| romul | vgg16 | 0,9266 | 0.9267 | 0,0186 |
| ternaus | densenet121 | 0,9232 | 0.9241 | 0,0921 |
| albu | densenet121 | 0.9294 | 0,9312 | 0,1933 |
| kostia | resnet50 | 0.9262 | 0.9271 | 0,0907 |
| n01z3 | resnext50 | 0.9281 | 0.9298 | 0.1896 |
La tabla muestra los modelos de puntaje F2 de todos los participantes para un solo cultivo y TTA. Como puede ver, la diferencia es pequeña para el uso real, pero es importante para el modo de competencia.
Interacción del equipoAlexander Buslaev
albuEn el momento de la participación en la competencia, dirigió toda la dirección ml en Geoscan. Pero desde entonces arrastró un montón de competiciones, se convirtió en el padre de todas las SAO en la segmentación semántica y se fue a Minsk, remando en Mapbox, sobre el cual se
publicó el
artículo.Alexey Noskov
alnoCombatiente universal ml. Trabajó en Evil Martians. Ahora rodó hacia Yandex.
Konstantin Lopukhin
kostialopuhinTrabajó y continúa trabajando en Scrapinghub. Desde entonces, Kostya logró obtener algunas medallas más y sin 5 minutos Kaggle Grandmaster
Arthur Cousin
n01z3Al momento de participar en esta competencia, trabajaba en Avito. Pero alrededor del año nuevo,
el científico principal de datos de
Dbrain se trasladó a la cadena de bloques. Espero que pronto deleitemos a la comunidad con nuestras competencias con estibadores y marcas de lámparas.
Evgeny Nizhibitsky
@nizhibCientífico principal de datos en Rambler & Co. A partir de esta competencia, Eugene descubrió la habilidad secreta de encontrar caras en las competiciones de imágenes. Lo que lo ayudó a arrastrar un par de competiciones en la plataforma Topcoder.
Hablé sobre uno de ellos.
Ruslan
Baykulov romulComprometido en el seguimiento de eventos deportivos en Constanta.
Vladimir Iglovikov
ternausPodría ser recordado por un
artículo lleno de acción sobre el acoso por parte de la inteligencia británica. Trabajó en TrueAccord, pero luego se convirtió en el joven y moderno Lyft. ¿Dónde funciona Computer Vision para el auto sin conductor? Continúa arrastrando competencias y recientemente recibió el Gran Maestro Kaggle.
Nuestra asociación y formato de participación pueden llamarse típicos. La decisión de unirnos se debió al hecho de que todos tuvimos resultados cercanos en la clasificación. Y cada uno de nosotros vio nuestra propia tubería independiente, que era una solución completamente autónoma de principio a fin. Además, después de la fusión, varios participantes se dedicaron al apilamiento.
Lo primero que hicimos fue compartir pliegues. Nos aseguramos de que la distribución de clases en cada pliegue fuera la misma que en todo el conjunto de datos. Para esto, primero se seleccionó la clase más rara, estratificada por ella, porque las imágenes restantes fueron estratificadas por la segunda clase más popular, y así sucesivamente hasta que no quedaron imágenes.
Histograma de clases de pliegue:
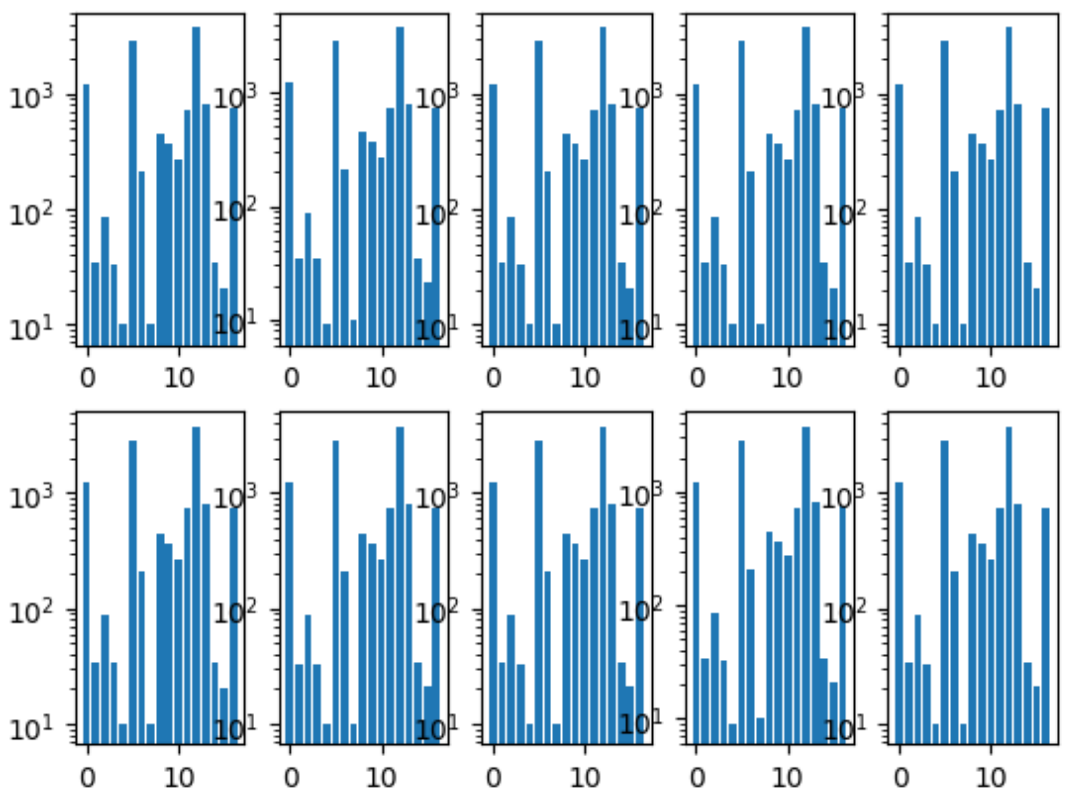
También teníamos un repositorio común, donde cada miembro del equipo tenía su propia carpeta, dentro de la cual organizaba el código como quería.
Y también acordamos el formato de predicciones, porque este era el único punto de interacción para combinar nuestros modelos.
Entrenamiento de redes neuronalesComo cada uno de nosotros tenía una tubería independiente, éramos una muestra de la red del proceso de aprendizaje óptimo paralelo a la gente.
Enfoque general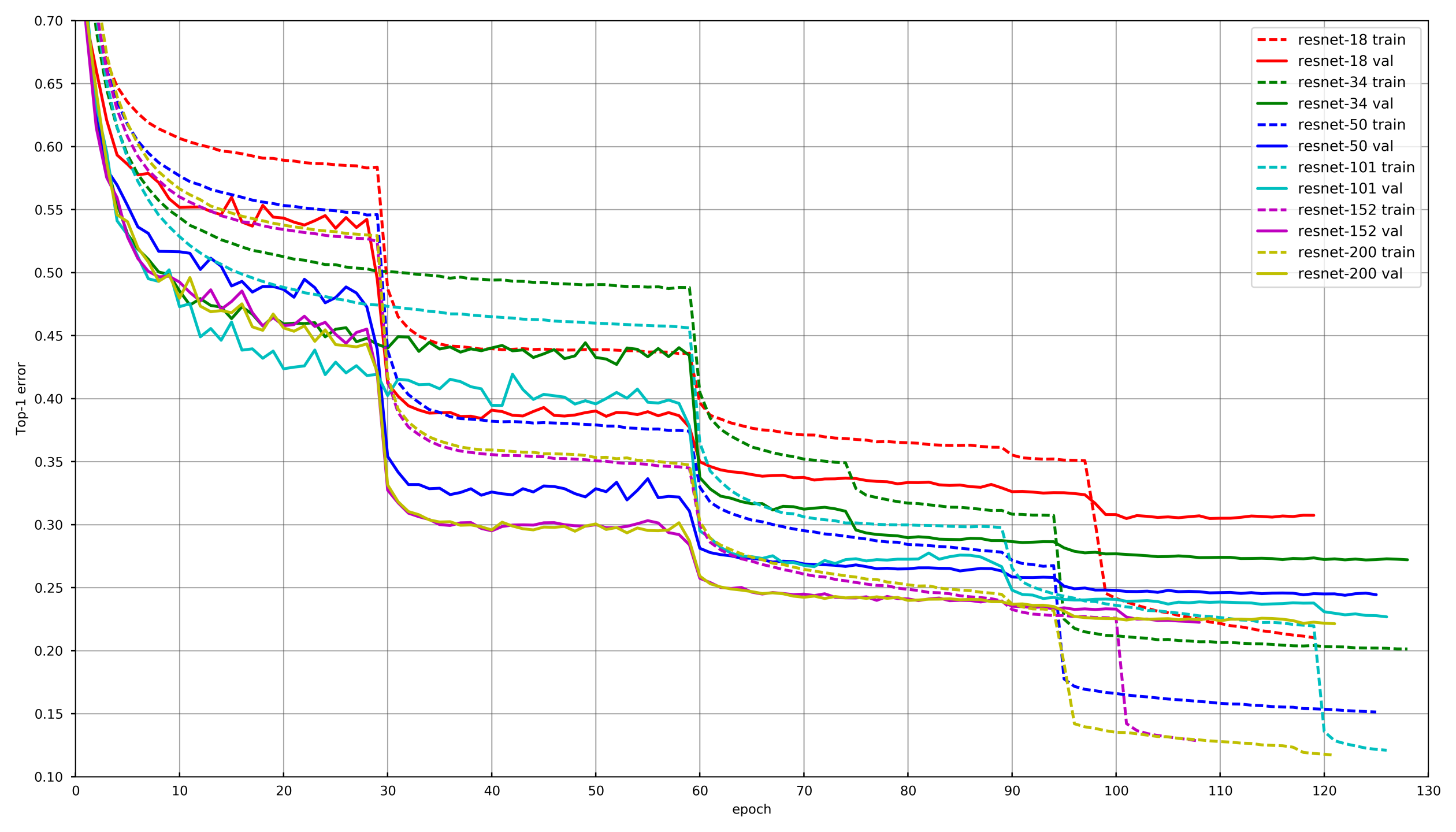
Imagen de
github.com/tornadomeet/ResNetSe presenta un proceso de aprendizaje típico en el programa de capacitación de las redes neuronales Resnet en imagenet. Comienzan a partir de pesos inicializados aleatoriamente con SGD (lr 0.1 Nesterov Momentum 0.0001 WD 0.9) y luego, después de 30 borrados, reducen la tasa de aprendizaje en 10 veces.
Conceptualmente, cada uno de nosotros usó el mismo enfoque, sin embargo, para no envejecer mientras se entrena cada red, se produjo una disminución en LR si la validación no redujo la pérdida durante 3-5 eras seguidas. O, algunos participantes simplemente redujeron el número de eras en cada daño LR y lo redujeron de acuerdo con el cronograma.
AumentoElegir los aumentos correctos es muy importante al entrenar redes neuronales. Los aumentos deben reflejar la variabilidad de la naturaleza de los datos. Convencionalmente, los aumentos se pueden dividir en dos tipos: los que introducen sesgos en los datos y los que no. Por sesgo, uno puede entender varias estadísticas de bajo nivel, como histogramas de color o tamaño característico. A este respecto, digamos, los aumentos y escalas de HSV introducen un desplazamiento, pero un recorte aleatorio no.
En las primeras etapas de entrenamiento de la red, puede ir demasiado lejos con los aumentos y usar un conjunto muy difícil. Sin embargo, hacia el final del entrenamiento, debes desactivar los aumentos o dejar solo aquellos que no introducen sesgos. Esto permite que la red neuronal se sobreajuste un poco debajo del tren y muestre un resultado ligeramente mejor en la validación.
Capa de congelaciónEn la gran mayoría de las tareas, no tiene sentido entrenar una red neuronal desde cero, es mucho más eficiente jugar con redes pre-entrenadas, digamos con Imagenet. Sin embargo, puede ir más allá y no solo cambiar la capa completamente conectada debajo de la capa con el número deseado de clases, sino primero entrenarla con la congelación de todas las circunvoluciones. Si no congela las circunvoluciones e inmediatamente entrena a toda la red con pesos inicializados aleatoriamente de una capa totalmente conectada, entonces los pesos de las circunvoluciones se corromperán y el rendimiento final de la red neuronal será menor. En esta tarea, esto fue especialmente notable debido al pequeño tamaño de la muestra de entrenamiento. En otras competiciones con una gran cantidad de datos, como cdiscount, era posible no congelar toda la red neuronal, sino grupos de convoluciones desde el final. De esta manera, el entrenamiento podría acelerarse enormemente, ya que no se consideraron los gradientes para las capas congeladas.
Recocido cíclicoEste proceso se ve así. Después de completar el proceso de entrenamiento básico de la red neuronal, se toman los mejores pesos y se repite el proceso de entrenamiento. Pero comienza con una tasa de aprendizaje más baja y ocurre en poco tiempo, digamos 3-5 eras. Esto permite que la red neuronal baje a un mínimo local más bajo y muestre un mejor rendimiento. Esta campaña estable mejora el resultado en un número bastante amplio de concursos.
En más detalle sobre dos recepciones
aquíAumentos de tiempo de pruebaComo se trata de una competencia y no tenemos una restricción formal sobre el tiempo de inferencia, puede usar aumentos durante la prueba. Parece que la imagen está distorsionada de la misma manera que sucedió durante el entrenamiento. Digamos, se refleja verticalmente, horizontalmente, girado por un ángulo, etc. Cada aumento da una nueva imagen de la que obtenemos predicciones. Luego se promedian las predicciones de tales distorsiones de una imagen (como regla por medios geométricos). También da una ganancia. En otras competiciones, también experimenté con aumentos aleatorios. Digamos que puede aplicar no uno a la vez, sino simplemente reducir la amplitud para giros aleatorios, contrastes y aumentos de color a la mitad, arreglar la semilla y hacer varias imágenes distorsionadas al azar. Esto también dio un aumento.
Conjunto de instantáneas (TTA de puntos múltiples)La idea del recocido se puede desarrollar más. En cada etapa del recocido, la red neuronal vuela a mínimos locales ligeramente diferentes. Y esto significa que estos son modelos esencialmente ligeramente diferentes que se pueden promediar. Por lo tanto, durante las predicciones de la prueba, puede tomar los tres mejores puntos de control y promediar sus predicciones. También traté de tomar no los tres mejores, sino los tres más diversos de los 10 puntos de control principales: fue peor. Bueno, para la producción, tal truco no es aplicable e intenté promediar el peso de los modelos. Esto dio un aumento muy insignificante pero constante.
 Enfoques de cada miembro del equipo
Enfoques de cada miembro del equipoEn consecuencia, en un grado u otro, cada miembro de nuestro equipo utilizó una combinación diferente de las técnicas anteriores.
| nick | Conv congelar,
época | Optimizador | Estrategia | Ago | Tta |
|---|
| albu | 3 | SGD | 15 decadencia LR de época,
Círculo 13 épocas | D4
Escala
Offset
Distorsión
Contraste
Desenfoque | D4 |
|---|
| alno | 3 | SGD | Lr decaimiento | D4
Escala
Offset
Distorsión
Contraste
Desenfoque
Corte
Multiplicador de canales | D4 |
|---|
| n01z3 | 2 | SGD | Drop LR, paciente 10 | D4
Escala
Distorsión
Contraste
Desenfoque | D4, 3 puntos de control |
|---|
| ternaus | - | Adam | LR cíclico (1e-3: 1e-6) | D4
Escala
Agregar canal
Contraste | D4
cultivo aleatorio |
|---|
| nizhib | - | Adam | StepLR, 60 épocas, 20 por descomposición | D4
RandomSizedCrop | D4
4 esquinas
centro
escala |
|---|
| kostia | 1 | Adam | | D4
Escala
Distorsión
Contraste
Desenfoque | D4 |
|---|
| romul | - | SGD | base_lr: 0.01 - 0.02
lr = base_lr * (0.33 ** (época / 30))
Época: 50 | D4, escala | D4, cultivo central,
Cultivos de esquina |
|---|
Apilamiento y hacksEntrenamos cada modelo con cada conjunto de parámetros en 10 pliegues. Y luego, en las predicciones fuera de pliegue (OOF), enseñamos modelos de segundo nivel: Árboles adicionales, Regresión lineal, Red neuronal y simplemente modelos de promedios.
Y ya en OOF, las predicciones de los modelos de segundo nivel recogieron pesos para mezclar. Puedes leer más sobre apilar
aquí y
aquí .
En la producción real, por extraño que parezca, este enfoque también tiene lugar. Por ejemplo, cuando hay datos multimodales (imágenes, texto, categorías, etc.) y desea combinar las predicciones de los modelos. Simplemente puede promediar las probabilidades, pero el entrenamiento de un modelo de segundo nivel da el mejor resultado.
Baes Optimization F2Además, las predicciones finales se ajustaron un poco usando la optimización bayesiana. Supongamos que tenemos probabilidades ideales, entonces F2 con el mejor tapete de expectativa (es decir, de tipo óptimo) se obtiene mediante la siguiente fórmula:
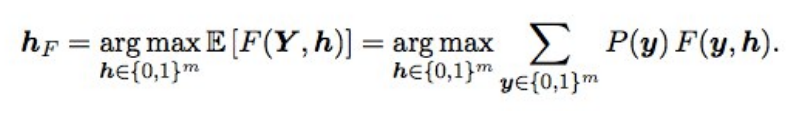
¿Qué significa esto? Necesitamos clasificar todas las combinaciones (es decir, para cada etiqueta 0 y 1), calcular la probabilidad de cada combinación y multiplicar por F2; obtenemos el F2 esperado. Para qué combinación es mejor, y dará el F2 óptimo. Las probabilidades se consideraron simplemente una multiplicación de las probabilidades de las etiquetas individuales (si la etiqueta es 0, tomamos 1 - p), y para no clasificar de 2 a 17 opciones, solo se escalonaron las etiquetas con una probabilidad de 0.05 a 0.5; había 3-7 de ellas en una fila, por lo que las opciones un poco (la presentación se realizó en un par de minutos). En teoría, sería genial obtener la probabilidad de una combinación de etiquetas, no solo multiplicando las probabilidades individuales (porque las etiquetas no son independientes), sino que no funcionó.
que dio Cuando los modelos se volvieron buenos, la selección de umbrales después de que el conjunto dejó de funcionar, y esto dio un aumento pequeño pero estable tanto en la validación como en lo público / privado.
EpílogoComo resultado, entrenamos 48 modelos diferentes, cada uno con 10 pliegues, es decir 480 modelos del primer nivel. Dicha red de redes humanas me permitió probar diferentes técnicas al entrenar redes neuronales convolucionales profundas, que todavía uso en el trabajo y las competiciones.
¿Fue posible entrenar menos modelos y obtener el mismo o mejor resultado? Si bastante. Nuestros compatriotas del tercer lugar, Stanislav
stasg7 Semenov y Roman
ZFTurbo Soloviev, cuestan un número menor de modelos de primer nivel y compensan más de 250 modelos de segundo nivel. Sobre la solución, puede
ver el análisis y
leer la publicación.
El primer lugar fue para el misterioso bestfitting. En general, este tipo es muy bueno, y ahora se ha convertido en el mejor de Keggle, después de haber realizado muchas competiciones de imágenes. Permaneció en el anonimato durante mucho tiempo, hasta que Nvidia rompió la tapa al
entrevistarlo . En el cual admitió que 200 subordinados le reportarían ... También hay una
publicación sobre la decisión.
Otro de los interesantes: ampliamente conocido en círculos estrechos
Jeremy Howard , padre
fastai terminó 22m. Y si pensabas que acababa de enviar un par de presentaciones para su fan, entonces no lo adivinaste. Participó en el equipo y envió 111 paquetes.
Además, los estudiantes graduados de Stanford que estaban tomando el legendario curso CS231n en ese momento y a quienes se les permitió usar esta tarea como un proyecto del curso, terminaron todo el equipo en el medio de la tabla de clasificación.
Como beneficio adicional,
hablé en Mail.ru con el material de esta publicación y aquí hay otra
presentación de Vladimir Iglovikov de una reunión en el Valle.