"Investigar el mercado de vacantes de analistas" era la tarea muy real de un analista líder muy real de una empresa grande o pequeña. El analizador reparte docenas de descripciones de trabajo con hh manualmente, dispersándolas de acuerdo con las habilidades solicitadas y aumentando el contador en la columna de la hoja de cálculo correspondiente.
Vi en esta tarea un buen campo para la automatización y decidí tratar de manejarlo con menos sangre, fácil y simplemente.
Me interesaron las siguientes cuestiones planteadas en este estudio:
- salario promedio para analistas de negocios y sistemas,
- las habilidades y cualidades personales más demandadas en este puesto,
- dependencias (si las hay) entre ciertas habilidades y el nivel de salario.
Spoiler: no funcionó fácil y simplemente.
Preparación de datos
Si queremos recopilar muchos datos sobre vacantes, entonces es lógico que no esté limitado. Sin embargo, para experimentar pureza simplicidad, comenzamos con este recurso.
Coleccion
Para recopilar datos, utilizaremos la búsqueda de empleo a través de la API hh.
Buscaré utilizando la consulta de texto simple "analista de sistemas", "analista de negocios" y "propietario del producto", porque las actividades y áreas de responsabilidad en estos puestos, por regla general, se superponen.
Para hacer esto, cree una solicitud del formulario https://api.hh.ru/vacancies?text="systems+analyst" y analice el JSON recibido.
Para obtener las vacantes más relevantes en la muestra, buscaremos solo en los encabezados de vacantes agregando el parámetro search_field=name a la consulta.
Aquí puede ver qué campos de vacantes se devuelven para esta solicitud. Elegí lo siguiente:
- título del trabajo
- la ciudad
- fecha de publicación
- salario - límites superior e inferior
- moneda en la que se indica el salario
- bruto - T / F
- la compañia
- responsabilidades
- requisitos para el candidato
Además, quiero analizar más a fondo las habilidades que se indican en la sección Habilidades clave, pero esta sección solo está disponible en la descripción completa del trabajo. Por lo tanto, también mantendré enlaces a las vacantes encontradas, para obtener posteriormente una lista de habilidades para cada una de ellas.
Ver código # :) library(jsonlite) library(curl) library(dplyr) library(ggplot2) library(RColorBrewer) library(plotly) hh.getjobs <- function(query, paid = FALSE) { # Makes a call to hh API and gets the list of vacancies based on the given search queries df <- data.frame( query = character() # , URL = character() # , id = numeric() # id , Name = character() # , City = character() , Published = character() , Currency = character() , From = numeric() # . , To = numeric() # . , Gross = character() , Company = character() , Responsibility = character() , Requerement = character() , stringsAsFactors = FALSE ) for (q in query) { for (pageNum in 0:99) { try( { data <- fromJSON(paste0("https://api.hh.ru/vacancies?search_field=name&text=\"" , q , "\"&search_field=name" , "&only_with_salary=", paid ,"&page=" , pageNum)) df <- rbind(df, data.frame( q, data$items$url, as.numeric(data$items$id), data$items$name, data$items$area$name, data$items$published_at, data$items$salary$currency, data$items$salary$from, data$items$salary$to, data$items$salary$gross, data$items$employer$name, data$items$snippet$responsibility, data$items$snippet$requirement, stringsAsFactors = FALSE)) }) print(paste0("Downloading page:", pageNum + 1, "; query = \"", q, "\"")) } } names <- c("query", "URL", "id", "Name", "City", "Published", "Currency", "From", "To", "Gross", "Company", "Responsibility", "Requirement") colnames(df) <- names return(df) }
En la función hh.getjobs() , la entrada acepta el vector de consultas de búsqueda de interés y refinamiento, solo nos interesan las vacantes con el salario especificado o todo en una fila (por defecto tomamos la segunda opción). Se crea un marco de dafa vacío, y luego se fromJSON() función fromJSON() del paquete fromJSON() , que toma la URL de entrada y devuelve una lista estructurada. A continuación, de los nodos en esta lista, obtenemos los datos que nos interesan y completamos los campos del marco de datos correspondientes.
Por defecto, los datos se proporcionan página por página, con 20 elementos en cada página. Para un máximo de 2,000 vacantes laborales. Todos los datos que recibimos se registran en df .
Life hack 1: no es un hecho que, a pedido nuestro, haya 2.000 vacantes y, en algún momento, recibiremos páginas en blanco. En este caso, R jura y salta del bucle. Por lo tanto, envolvemos cuidadosamente el contenido del bucle interno en try() .
Life hack 2: también tiene sentido agregar la salida del estado actual de recopilación de datos a la consola en el bucle interno, porque este no es un negocio rápido. Hice esto:
print(paste0("Downloading page:", pageNum + 1, "; query = \"", query, "\""))
Después de completar los datos, las columnas se renombran para que sea conveniente trabajar con ellas y se devuelve el marco de datos resultante.
Almacenaré esta y otras funciones auxiliares en un archivo de functions.R separado para no saturar el script principal, que hasta ahora se ve así:
source("functions.R") # Step 1 - get data # 1.1 get vacancies (short info) jobdf <- hh.getjobs(query = c("business+analyst" , "systems+analyst" , "product+owner"), paid = FALSE)
Ahora obtendremos experience y key_skills de la descripción completa del trabajo .
hh.getxp el marco de datos a la función hh.getxp , seguimos los enlaces guardados a las vacantes, y de la descripción completa obtenemos el valor de la experiencia laboral requerida. El valor resultante se almacena en una nueva columna.
Ver código hh.getxp <- function(df) { df$experience <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) df[df$URL == myURL, "experience"] <- data$experience$name } ) print(paste0("Filling in ", which(df$URL == myURL, arr.ind = TRUE), "from ", nrow(df))) } return(df) }
La descripción de la nueva función auxiliar se envía a functions.R , y el script principal ahora accede a ella:
# s.1.2 get experience (from full info) jobdf <- hh.getxp(jobdf) # 1.3 get skills (from full info) all.skills <- hh.getskills(jobdf$URL)
En el fragmento anterior, también formamos un nuevo marco de datos all.skills formulario "job id - skill":
Ver código hh.getskills <- function(allurls) { analyst.skills <- data.frame( id = character(), # id skill = character() # ) for (myURL in allurls) { data <- fromJSON(myURL) if (length(data$key_skills) > 0) analyst.skills <- rbind(analyst.skills, cbind(data$id, data$key_skills)) print(paste0("Filling in " , which(allurls == myURL, arr.ind = TRUE) , " out of " , length(allurls))) } names(analyst.skills) <- c("id", "skill") analyst.skills$skill <- tolower(analyst.skills$skill) return(analyst.skills) }
Preprocesamiento
Veamos cuántos datos hemos logrado recopilar:
> length(unique(jobdf$id)) [1] 1478 > length(jobdf$id) [1] 1498
¡Casi mil quinientos empleos! Se ve bien Y aparentemente, varias vacantes entraron en los resultados de búsqueda dos veces, para diferentes solicitudes. Por lo tanto, el primer paso es dejar solo entradas únicas: jobdf <- jobdf[unique(jobdf$id),] .
Para comparar los salarios de los analistas del mercado laboral, necesito
1) asegúrese de que todos los datos disponibles sobre salarios se presenten en una moneda única,
2) seleccione en un marco de datos separado aquellas vacantes para las cuales se indica el salario.
Consideramos cada una de las subtareas con más detalle. Anteriormente, puede averiguar qué monedas se encuentran, en principio, en nuestros datos utilizando la table(jobdf$Currency) . En mi caso, además de rublos, aparecieron dólares, euros, hryvnias, tenge kazajo e incluso sumas uzbecas.
Para convertir los valores salariales en rublos, debe averiguar el tipo de cambio actual. Descubriremos desde el Banco Central :
Ver código quotations.update <- function(currencies) { # Parses the most up-to-date qutations data provided by the Central Bank of Russia # and returns a table with currency rate against RUR doc <- XML::xmlParse("http://www.cbr.ru/scripts/XML_daily.asp") quotationsdf <- XML::xmlToDataFrame(doc, stringsAsFactors = FALSE) quotationsdf <- select(quotationsdf, -Name) quotationsdf$NumCode <- as.numeric(quotationsdf$NumCode) quotationsdf$Nominal <- as.numeric(quotationsdf$Nominal) quotationsdf$Value <- as.numeric(sub(",", ".", quotationsdf$Value)) quotationsdf$Value <- quotationsdf$Value / quotationsdf$Nominal quotationsdf <- quotationsdf %>% select(CharCode, Value) return(quotationsdf) }
Para asegurarse de que los cursos se procesen correctamente en R, debe asegurarse de que la parte decimal esté separada por un punto. Además, debe prestar atención a la columna Nominal: en algún lugar es 1, en algún lugar 10 o 100. Esto significa que una libra esterlina cuesta ~ 85 rublos y, por ejemplo, por cien drams armenios puede comprar ~ 13 rublos. Para la conveniencia de un procesamiento adicional, reduje los valores a un valor nominal de 1 en relación con el rublo.
Ahora puedes traducir. Nuestro script hace esto usando la función convert.currency() . El tipo de cambio actual se toma de la tabla de quotations , donde guardamos los datos del XML proporcionado por el Banco Central. Además, la función de entrada acepta la moneda objetivo para la conversión (por defecto RUR) y una tabla con vacantes, los valores de los tenedores de salarios en los que es necesario conducir a una moneda única. La función devuelve una tabla con dígitos de salario actualizados (ya sin la columna Moneda, como innecesaria).
Tuve que jugar con los rublos bielorrusos: después de recibir datos muy extraños en varios enfoques, realicé una pequeña investigación y descubrí que desde 2016 se ha utilizado una nueva moneda en Bielorrusia, que difiere no solo en el tipo de cambio, sino también en la abreviatura (ahora no BYR, sino BYN) . En los directorios hh, todavía se usa la abreviatura BYR, sobre la cual XML del Banco Central no sabe nada. Por lo tanto, en la función convert.currency() I no de la manera más elegante Primero, reemplazo la abreviatura con la actual, y solo luego voy directamente a la conversión.
Se ve así:
Ver código convert.currency <- function(targetCurrency = "RUR", df, quotationsdf) { cond <- (!is.na(df$Currency) & df$Currency == "BYR") df[cond, "Currency"] <- "BYN" currencies <- unique(na.omit(df$Currency[df$Currency != targetCurrency])) # ( ) if (!is.null(df$From)) { for (currency in currencies) { condition <- (!is.na(df$From) & df$Currency == currency) try( df$From[condition] <- df$From[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } # ( ) if (!is.null(df$To)) { for (currency in currencies) { condition <- !is.na(df$To) & df$Currency == currency try( df$To[condition] <- df$To[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } return(df %>% select(-Currency)) }
También puede tener en cuenta que algunos datos sobre salarios se presentan en valores brutos, es decir, el empleado recibirá un poco menos en la mano. Para calcular el salario neto de los residentes de la Federación de Rusia, el 13% debe deducirse de estas cifras (el 30% se deduce para los no residentes).
Ver código gross.to.net <- function(df, resident = TRUE) { if (resident == TRUE) coef <- 0.87 else coef <- 0.7 if (!is.null(df$Gross)) { if (!is.null(df$From)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$From) & df$Gross == TRUE,]))) df$From[index] <- df$From[index] * coef } if (!is.null(df$To)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$To) & df$Gross == TRUE,]))) df$To[index] <- df$To[index] * coef } df <- df %>% select(-Gross) } return(df) }
Por supuesto, no haré esto, porque en este caso vale la pena considerar los impuestos en diferentes países, y no solo en Rusia, o agregar un filtro por país en la consulta de búsqueda inicial.
El último paso antes del análisis es dividir las vacantes encontradas en tres categorías: junio, medio y superior, y escribir las posiciones recibidas en una nueva columna. Los cargos superiores incluirán aquellos en los nombres de los cuales la palabra "senior" y sus sinónimos están presentes. Del mismo modo, encontraremos las posiciones iniciales para las palabras clave "junior" y sinónimos, y entre los medios incluimos todos aquellos entre:
get.positions <- function(df) { df$lvl <- NA df[grep(pattern = "lead|senior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "senior" df[grep(pattern = "junior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "junior" df[is.na(df$lvl), "lvl"] <- "middle" return(df) }
Agregue el bloque de preparación de datos al script principal.
Agregado # Step 2 - prepare data # 2.1. Convert all currencies to target currency # 2.1.1 get up-to-date currency rates quotations <- quotations.update() # 2.1.2 convert to RUR jobdf <- convert.currency(df = jobdf, quotationsdf = quotations) # 2.2 convert Gross to Net # jobdf <- gross.to.net(df = jobdf) # 2.3 define segments jobdf <- get.positions(jobdf)
Análisis
Como se mencionó anteriormente, voy a analizar los siguientes aspectos de los datos obtenidos:
- salario promedio BA / SA,
- las habilidades y cualidades personales más demandadas en este puesto,
- dependencias (si las hay) entre ciertas habilidades y el nivel de salario.
Ingresos promedio de BA / SA
Al final resultó que, las empresas son reacias a indicar límites salariales superiores o inferiores.
En nuestro marco de datos jobdf estos valores están en las columnas Para y Desde, respectivamente. Quiero encontrar los promedios y escribirlos en una nueva columna Salario.
Para los casos en que el salario se indica en su totalidad, esto se puede hacer fácilmente utilizando la función mean() , filtrando todos los demás registros donde faltan los datos en el enchufe en su totalidad o en parte. Pero en este caso, quedaría menos del 10% de nuestra muestra original, que ya es pequeña. Por lo tanto, calculo el coeficiente Podgoniana , que le indica cuánto difieren en promedio los valores To y From en las vacantes en las que se indica la bifurcación completa, y con su ayuda completé los datos faltantes en los casos en que solo falta un valor.
Ver código select.paid <- function(df, suggest = TRUE) { # Returns a data frame with average salaries between To and From # optionally, can suggest To or From value in case only one is specified if (suggest == TRUE) { df <- df %>% filter(!is.na(From) | !is.na(To)) magic.coefficient <- # shows the average difference between max and min salary round(mean(df$To/df$From, na.rm = TRUE), 1) df[is.na(df$To),]$To <- df[is.na(df$To),]$From * magic.coefficient df[is.na(df$From),]$From <- df[is.na(df$From),]$To / magic.coefficient } else { df <- na.omit(df) } df$salary <- rowMeans(x = df %>% select(From, To)) df$salary <- ceiling(df$salary / 10000) * 10000 return(df %>% select(-From, -To)) }
Este es un filtrado de datos "suave", que se establece en la función select.paid() con el parámetro suggest = TRUE . Alternativamente, podemos especificar suggest = FALSE al llamar a la función y simplemente cortar todas las líneas donde los datos salariales están al menos parcialmente ausentes. Sin embargo, utilizando un filtrado suave y un coeficiente mágico, logré guardar casi una cuarta parte del conjunto de datos original en la muestra.
Pasamos a la parte visual:

En este gráfico puede evaluar visualmente la densidad de distribución de los salarios de BA / SA en dos capitales y en regiones. Pero, ¿qué sucede si especificamos la solicitud y comparamos cuánto obtienen los hombres intermedios y superiores en las capitales?
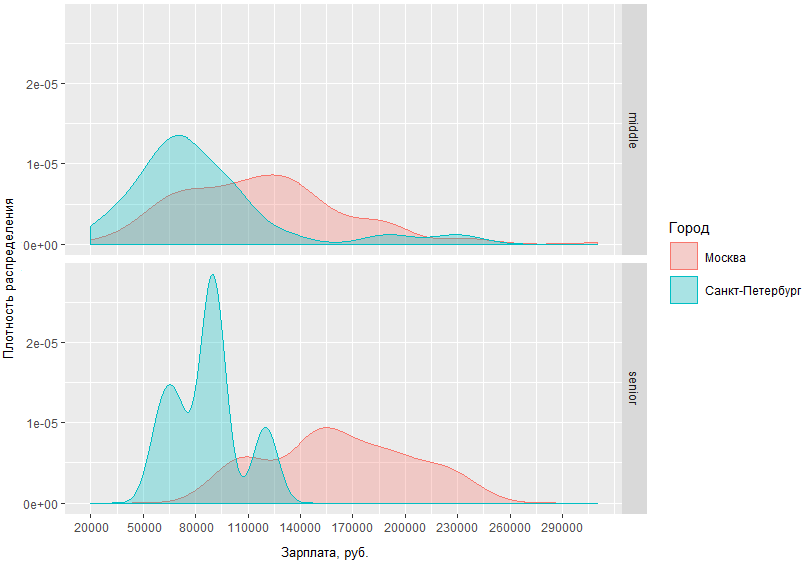
A partir del gráfico obtenido, está claro que la diferencia en las situaciones salariales entre hombres de mediana edad y superiores en Moscú y San Petersburgo no es muy diferente. Entonces, en San Petersburgo, los medios alcanzan, por regla general, en la región de 70 tr, mientras que en Moscú el pico de densidad cae en ~ 120 tr, y la diferencia en el ingreso de especialistas de alto nivel en Moscú y San Petersburgo difiere en un promedio de 60 mil.
También podemos ver, por ejemplo, los salarios de los analistas de Moscú por puesto:

Se puede concluir que a) hoy en Moscú hay una demanda mucho mayor de analistas de nivel de entrada, yb) al mismo tiempo, el umbral salarial superior para tales especialistas es mucho más limitado que el de los medios y los adultos mayores.
Otra observación: el sn promedio de los especialistas de Moscú de nivel medio y alto tiene un área de intersección bastante grande. Esto puede indicar que el mercado tiene una frontera bastante borrosa entre estos dos pasos.
Código completo para gráficos debajo del corte.
Vista # Step 3 - analyze salaries # 3.1 get paid jobs (with salaries specified) jobs.paid <- select.paid(jobdf) # 3.2 plot salaries density by region ggplotly(ggplot(jobs.paid, aes(salary, fill = region, colour = region)) + geom_density(alpha=.3) + scale_fill_discrete(guide = guide_legend(reverse=FALSE)) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10))) # 3.3 compare salaries for middle / senior in capitals ggplot(jobs.paid %>% filter(region %in% c("", "-"), lvl %in% c("senior", "middle")), aes(salary, fill = region, colour = region)) + facet_grid(lvl ~ .) + geom_density(alpha = .3) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + scale_fill_discrete(name = "") + scale_color_discrete(name = "") + guides(fill=guide_legend( keywidth=0.1, keyheight=0.1, default.unit="inch") ) + theme(legend.spacing = unit(1,"inch"), axis.title = element_text(size=10)) # 3.4 plot salaries in Moscow by position ggplotly(ggplot(jobs.paid %>% filter(region == ""), aes(salary, fill = lvl, color = lvl)) + geom_density(alpha=.4) + scale_fill_brewer(palette = "Set2") + scale_color_brewer(palette = "Set2") + theme_light() + scale_y_continuous(name = " ") + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10)))
Análisis de habilidades clave
Pasamos al objetivo clave del estudio: identificar las habilidades más buscadas para BA / SA. Para hacer esto, analizaremos los datos que se indican explícitamente en el campo especial de la vacante: habilidades clave.
Habilidades más populares
Anteriormente, recibimos un marco de datos separado all.skills , donde registramos los pares "id de trabajo - habilidad". Encontrar las habilidades más comunes es fácil con la función table() :
tmp <- as.data.frame(table(all.skills$skill), col.names = c("Skill", "Freq")) htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),]), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
Obtienes algo como lo siguiente:

Aquí Freq es el número de vacantes en el campo "key_skills" del cual se indica la habilidad correspondiente de la columna Skill.
"¡Pero eso no es todo!" (C) Es bastante obvio que las mismas habilidades se pueden encontrar fácilmente en diferentes vacantes en términos sinónimos.
Recopilé un pequeño diccionario de sinónimos para los nombres de las habilidades y las dividí en categorías.
El diccionario es un archivo csv con columnas de categoría, una de las siguientes: Actividades, Herramientas, Conocimiento, Estándares y Personal; skill: el nombre principal de la skill, que usaré en lugar de todos los sinónimos encontrados; syn1, syn2, ... syn13: posibles variaciones para cada habilidad. Algunas filas pueden contener columnas vacías de sinónimos.
category;skill;syn1;syn2;syn3;syn4;syn5;syn6;syn7;syn8;syn9;syn10;syn11;syn12;syn13 tools;axure;;;;;;;;;;;;; tools;lucidchart;;;;;;;;;;;;; standards;archimate;;;;;;;;;;;;; standards;uml;activity diagram;use case diagram;ucd;class diagram;;;;;;;;; personal;teamwork;team player; ;;;;;;;;;;; activities;wireframing;mockup;mock-up;;-;wireframe;;ui;ux/;/ux;;;;
Primero, importe el diccionario y luego redistribuya las habilidades nuevamente en función de las equivalencias existentes:
# Analyze skills # 4.1 import dictionary dict <- read.csv(file = "competencies.csv", header = TRUE, stringsAsFactors = FALSE, sep = ";", na.strings = "", encoding = "UTF-8") # 4.2 match skills with dictionary all.skills <- categorize.skills(all.skills, dict)
Debajo del corte, puede ver el relleno de la función categorize.skills() .
esas mismas agallas! categorize.skills <- function(analyst_skills, dictionary) { analyst_skills$skill.group <- NA analyst_skills$category <- NA for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) mypattern <- paste0(c(myskill, mypattern), collapse = "|") else mypattern <- myskill try( { analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"skill.group"] <- myskill analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"category"] <- category } ) } return(analyst_skills) }
Agrego la columna de categoría y habilidad al marco de datos de habilidades original. grupo: para la categoría y el nombre generalizado de la habilidad, respectivamente. Luego reviso el diccionario importado y compongo un patrón para la función grep() de cada línea de sinónimos. Al agregar cada valor de columna no vacío a la fila, los separo con un guión para obtener una condición "o". Entonces, para todas las habilidades de la tabla fuente, que incluye el uml|activity diagram|use case diagram|ucd|class diagram , escribiré el valor "uml" en la columna skill.group. ¡Y así será con todos! .. habilidad del marco de datos original.
Al volver a solicitar la parte superior de las habilidades más populares, puede ver que la alineación de las fuerzas ha cambiado algo:
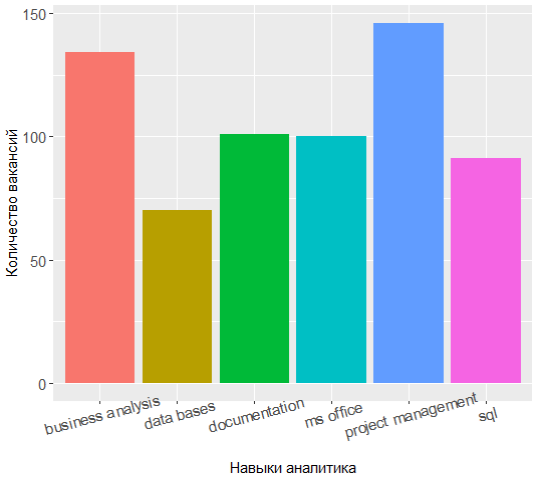
Los tres líderes ahora tienen gestión de proyectos, análisis de negocios y documentación, y el conocimiento de UML ha cambiado de los 7 mejores.
Es bastante interesante revisar las categorías y descubrir qué habilidades tienen más demanda en cada una de ellas.
Por ejemplo, para la categoría Conocimiento, la situación es la siguiente:
Ver código tmp <- merge(x = all.skills, y = jobdf %>% select(id, lvl), by = "id", sort = FALSE) tmp <- na.omit(tmp) ggplot(as.data.frame(table(tmp %>% filter(category == "knowledge") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = reorder(Var1, -Freq))) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

El gráfico muestra que la mayor demanda es de conocimiento en el campo de bases de datos, metodologías de desarrollo de software y 1C. Luego viene el conocimiento en el campo de CRM, sistemas ERP y los conceptos básicos de programación.
En lo que respecta a los estándares, el conocimiento de SQL y UML tiene una gran demanda, la notación ARIS llega a sus talones, pero los GOST ocupan solo el sexto lugar.
Aqui esta el codigo ggplot(as.data.frame(table(tmp %>% filter(category == "standards") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = Var1)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

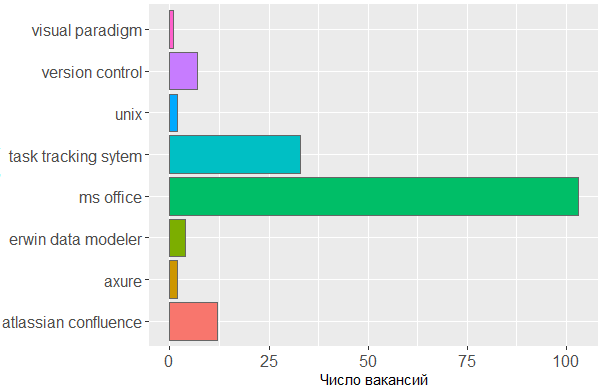
En cuanto a las herramientas utilizadas, una vez más vemos confirmación de que la cabeza es la herramienta principal del analista. No se puede prescindir de la línea de MS Office y los sistemas de seguimiento de tareas, pero el resto es de poca preocupación para el editor en el que el analista crea sus propios esquemas o bosqueja modelos de interfaz.
Aqui esta el codigo ggplot(tmp %>% filter(category == "tools")) + geom_histogram(colour = "#666666", stat = "count", aes(skill.group, fill = skill.group)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()
El impacto de las habilidades en los ingresos
, , . , , , .
jobs.paid all.skills , data frame.
# 4.4 vizualize paid skills tmp <- na.omit(merge(x = all.skills, y = jobs.paid %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
:
> head(tmp) id skill skill.group category salary lvl City 2 25781585 android mobile os knowledge 90000 middle 3 25781585 project management activities 90000 middle 5 25781585 project management activities 90000 middle 6 25781585 ios mobile os knowledge 90000 middle 7 25750025 aris aris standards 70000 middle 8 25750025 - business analysis activities 70000 middle
, .. . :
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, salary)) + coord_flip() + geom_count(aes(size = ..n.., color = City)) + scale_fill_discrete(name = "") + scale_y_continuous(name = ", .") + scale_size_area(max_size = 11) + theme(legend.position = "bottom", axis.title = element_blank(), axis.text.y = element_text(size=10, angle=10)))

, BA/SA .
:
ggplot(tmp %>% filter(category == "personal", City %in% c("", "-")), aes(tools::toTitleCase(skill), salary)) + coord_flip() + geom_count(aes(size = ..n.., color = skill.group)) + scale_y_continuous(breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 20000),1), name = ", .") + scale_size_area(max_size = 10) + theme(legend.position = "none", axis.title = element_text(size = 11), axis.text.y = element_text(size=10, angle=0))
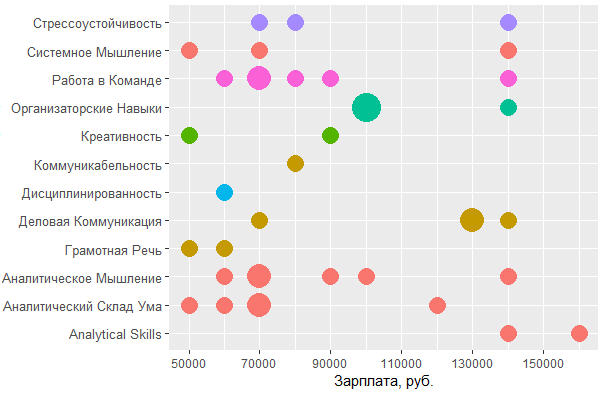
, MS Office , — , - . , , , .
, , : UML ARIS, SQL ( ) , IDEF — , "".
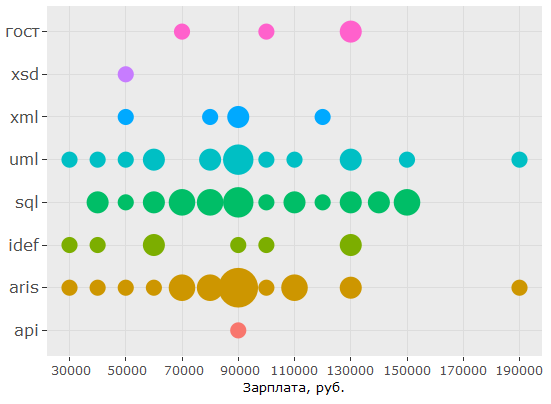
, , , . , 1478 - key_skills. , - .
, data frame:
> jobdf$Responsibility[[1]] [1] "Training course in business analysis. ● Define needs of the user/client, understand the problem which needs to be solved. ● " > jobdf$Requirement[[1]] [1] "At least 6 months' experience in business analysis. ● Knowledge of qualitative methods such as usability testing, interviewing, focus groups. ● "
, , . URL' , .
hh.get.full.desrtion <- function(df) { df$full.description <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) if (length(data$description) > 0) { df$full.description[which(df$URL == myURL, arr.ind = TRUE)] <- data$description } print(paste0("Filling in " , which(df$URL == myURL, arr.ind = TRUE) , " out of " , length(df$URL))) } ) } df$full.description <- tolower(df$full.description) return(df) }
- , html- ., gsub :
remove.Html <- function(htmlString) { #remove html tags return(gsub("<.*?>", "", htmlString)) }
, , , , . data frame ( df), , df "id, skill.group, category".
skills.from.desc <- function(df, dictionary) { sk <- data.frame( id = numeric() , skill.group = character() , category = character() ) for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) { mypattern <- paste0(c(myskill, mypattern), collapse = "|") } else { mypattern <- myskill } cond = grep(x = df$full.description, pattern = mypattern) tmp <- data.frame( id = df[cond, "id"], skill.group = rep(myskill, length(cond)), category = rep(category, length(cond)) ) sk <- rbind(sk, tmp) } return(sk) }
# 5 text analysis # 5.1 get full descriptions jobdf <- hh.get.full.description(jobdf) jobdf$full.description <- remove.Html(tolower(jobdf$full.description)) sk.from.desc <- skills.from.desc(jobdf, dict)
, ?
> head(sk.from.desc) id skill.group category 1 25638419 axure tools 2 24761526 axure tools 3 25634145 axure tools 4 24451152 axure tools 5 25630612 axure tools 6 24985548 axure tools > tmp <- as.data.frame(table(sk.from.desc$skill.group), col.names = c("Skill", "Freq")) > htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),], 20), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
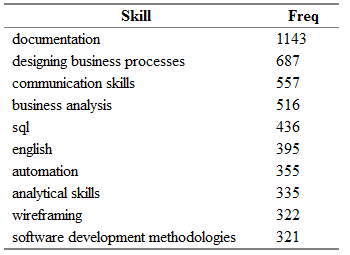
, ! Project management, key_skills, ( ).
, , key_skills -5.
, . 1478 , , key_skills, , .
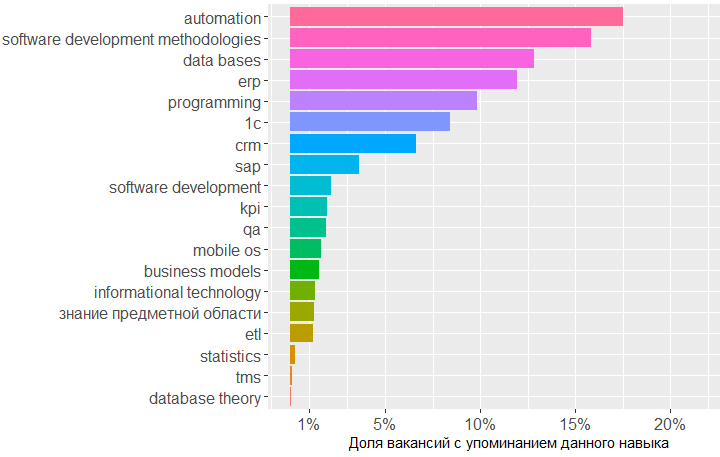
, , BA , - .
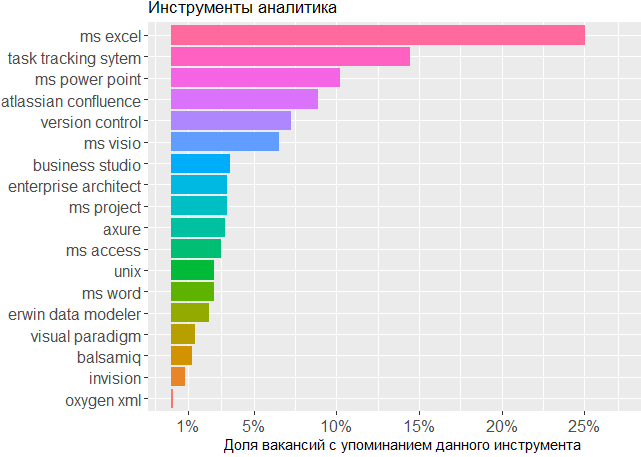
, .
data frame , , . , -.
tmp <- na.omit(merge(x = sk.from.desc, y = jobs.paid %>% filter(City %in% c("", "-")) %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
> head(tmp) id skill.group category salary lvl City 1 25243346 uml standards 160000 middle 2 25243346 requirements management activities 160000 middle 3 25243346 designing business processes activities 160000 middle 4 25243346 communication skills personal 160000 middle 5 25243346 mobile os knowledge 160000 middle 6 25243346 ms visio tools 160000 middle
, , , .
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, lvl)) + geom_count(aes(color = salary, size = ..n..)) + scale_size_area(max_size = 13) + theme(legend.position = "right", legend.title = element_text(size = 10), axis.title = element_blank(), axis.text.y = element_text(size=10)) + coord_flip() + scale_color_continuous(labels = function(x) format(x, scientific = FALSE), breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 70000),1), low = "blue", high = "red", name = ", ."))
?
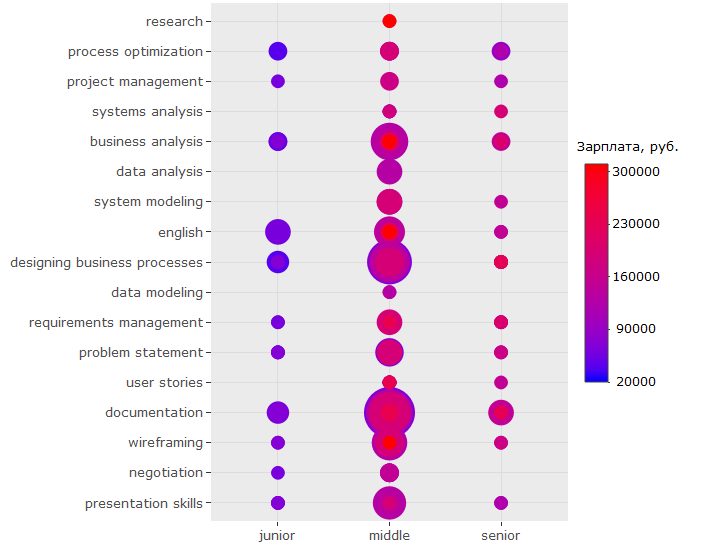
-, , - . ( , , , .)
-, , "" -, .
, key_skills.
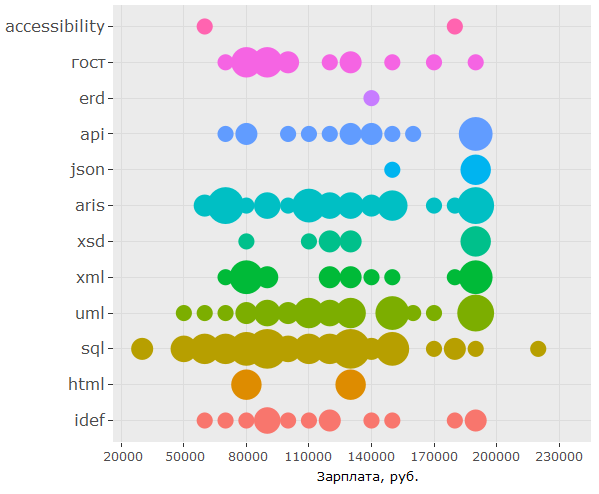
, , 150 .. UML ARIS, IDEF, , — .
:

, - , , key_skills , . , 150 .. , .
?
, - :

, , , ? , . , , . , ó ( )
, - :

-
BA/SA ,
- . , ;
- ( ) 200 .. , , ;
- ;
- — - ( , , )
key_skills hh , ;- , , , (!) ;
- , -, UX ;
- . , - 150 ..;
- , , SQL, UML & ARIS. , .. . , , ,
wordcloud2::wordcloud2(data = table(sk.from.desc$skill.group), rotateRatio = 0.3, color = 'random-dark')
