O cómo terminé en el equipo ganador de la competencia adversaria Machines Can See 2018.
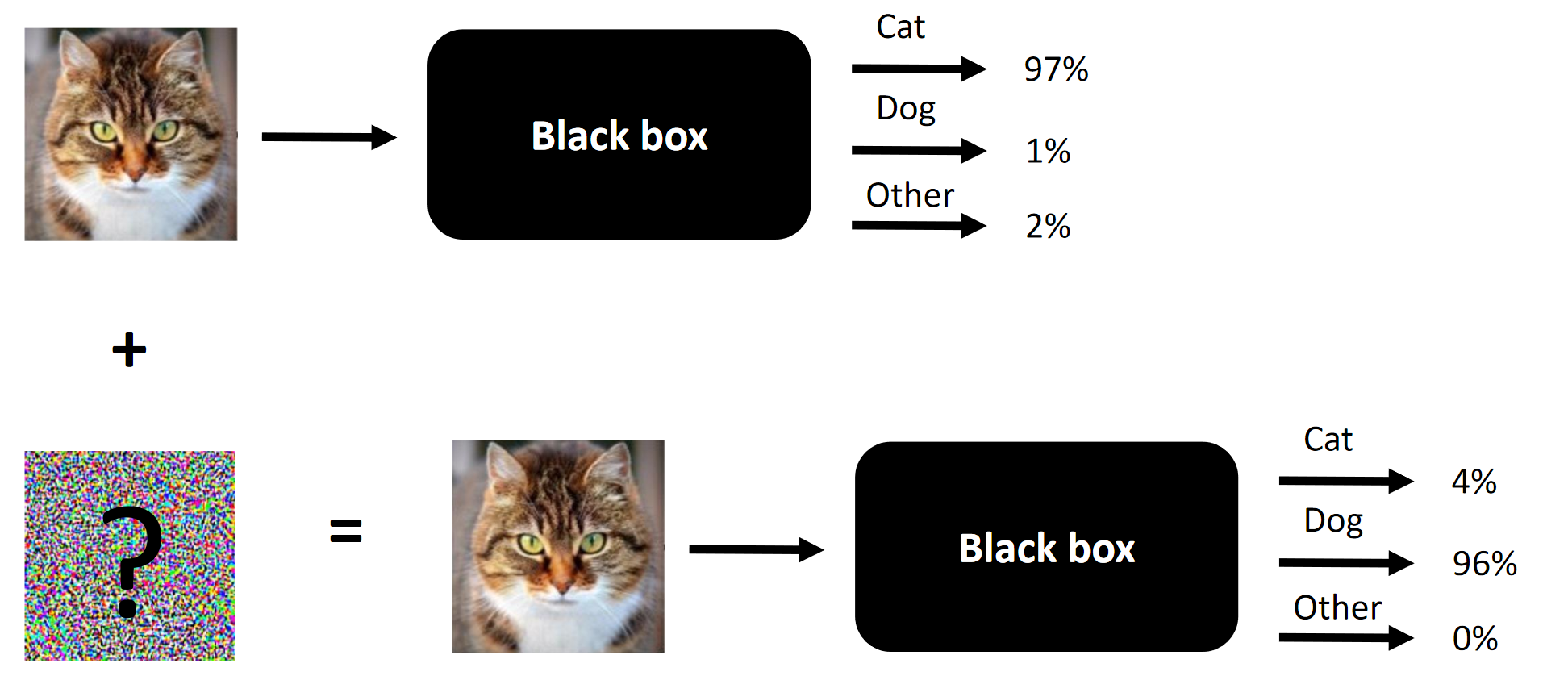 La esencia de cualquier ataque competitivo es un ejemplo.
La esencia de cualquier ataque competitivo es un ejemplo.Dio la casualidad de que participé en la competencia Machines Can See 2018. Me uní a la competencia llegué un poco tarde (aproximadamente una semana antes del final), pero finalmente terminé en un equipo de 4 personas, donde la contribución de los tres (incluyéndome a mí) fue necesario para la victoria (elimine un componente, y seríamos extraños).
El propósito de la competencia es cambiar las caras de las personas para que la red neuronal convolucional, presentada por los organizadores como una caja negra, no pueda distinguir la cara fuente de la cara objetivo. El número de cambios permitidos estaba limitado por
SSIM .
Artículo original publicado
aquí .
Nota La torpe traducción de la terminología o su ausencia está dictada por la falta de una terminología establecida en el idioma ruso. Puedes sugerir tus opciones en los comentarios. La esencia de la competencia es cambiar la cara en la entrada para que la caja negra no pueda distinguir entre dos caras (al menos desde el punto de vista de L2 / distancia euclidiana)
La esencia de la competencia es cambiar la cara en la entrada para que la caja negra no pueda distinguir entre dos caras (al menos desde el punto de vista de L2 / distancia euclidiana)Lo que funciona en ataques competitivos y lo que funcionó en nuestro caso:
- Método de signo de gradiente rápido (FGSM). Agregar heurísticas lo hizo un poco mejor;
- Método de valor de gradiente rápido (FGVM). Agregar heurísticas lo hizo FUERTEMENTE mejor;
- Evolución diferencial genética (gran artículo sobre este método) + ataques píxel por píxel;
- Conjuntos de modelos (solución de gama alta ... 6 ResNet "apilados");
- Bypass inteligente de combinaciones de imágenes de destino;
- Esencialmente, detenerse temprano durante un ataque de FGVM;
Lo que no funcionó en nuestro caso:
- Agregar un "momento de inercia" al FGVM (aunque funcionó para el equipo que clasificó más bajo, entonces, ¿es posible que los conjuntos + heurística funcionen mejor que agregar un momento?);
- Ataque C&W (esencialmente un ataque de extremo a extremo dirigido a los registros del modelo de caja blanca): funciona para la caja blanca (BY), no funciona para la caja negra (CN);
- Un enfoque basado en el LinkNet siamés de extremo a extremo (arquitectura similar a UNet, pero basada en ResNet). También trabajó solo para BY;
Lo que no probamos (no tenía tiempo, no tenía suficiente esfuerzo o era demasiado vago):
- Pruebas de aumento sensatas para el aprendizaje de los estudiantes (también tendría que contar los descriptores, es fácil, pero una idea tan simple no surgió de inmediato);
- Aumento durante el ataque, por ejemplo, "reflejar" la imagen de izquierda a derecha;
Sobre la competencia en general:
- El conjunto de datos era "demasiado pequeño" (1000 combinaciones de 5 + 5);
- El conjunto de datos de formación neta de los estudiantes fue relativamente grande (más de 1 millón de imágenes);
- CE se presentó como un conjunto de modelos precompilados en Caffe (naturalmente, en nuestros entornos, primero emitieron errores). Esto también introdujo cierta complejidad, ya que QW no aceptaba imágenes con lotes;
- La competencia tenía una excelente línea base (solución básica), sin la cual, en mi opinión, pocos se involucrarían directamente;
Recursos:
1. Descripción general de las máquinas puede ver la competencia 2018 y cómo me metí en ella
Competencia y enfoques
Honestamente, me atrajo una nueva área interesante, la GTX 1080Ti Founders 'Edition en premios, y una competencia relativamente baja (que no sería posible comparar con 4000 personas en ninguna competencia en Kaggle contra todo el ODS con 20 GPU por equipo).
Como se mencionó anteriormente, el propósito de la competencia era engañar al modelo CE, de modo que este último no pudiera distinguir entre dos personas diferentes (en el sentido de la norma L2 / distancia euclidiana). Bueno, dado que era una caja negra, tuvimos que destilar las redes de los Estudiantes con los datos proporcionados y esperar que los gradientes de QW y BYW fueran lo suficientemente similares como para llevar a cabo el ataque.
Si lee reseñas de artículos (por ejemplo,
aquí y
allá , aunque dichos artículos realmente no dicen lo que funciona en la práctica) y compila lo que han logrado los mejores equipos, puede describir brevemente tales mejores prácticas:
- Los ataques más simples en la implementación involucran BY o conocimiento de la estructura interna de la red neuronal convolucional (o simplemente arquitectura) en la que se lleva a cabo el ataque;
- Alguien en el chat sugirió rastrear el tiempo de inferencia en el CE e intentar adivinar su arquitectura;
- Al tener acceso a una cantidad suficiente de datos, puede emular QW con QW bien entrenado
- Presumiblemente, los métodos más avanzados son:
- Ataque C&W de extremo a extremo (no funcionó en este caso);
- Extensiones de FGSM inteligentes (es decir, momento de inercia + conjuntos complicados);
Honestamente, todavía estábamos confundidos por el hecho de que dos enfoques de principio a fin completamente diferentes, implementados independientemente por dos personas diferentes del equipo, estúpidamente no funcionaban para CH. En esencia, esto podría significar que en nuestra interpretación de la declaración del problema en algún lugar hubo una fuga de datos que no notamos (o que las manos estaban torcidas). En muchas tareas modernas de visión por computadora, las soluciones de extremo a extremo (por ejemplo, transferencia de estilo, cuenca profunda, generación de imágenes, limpieza de ruido y artefactos, etc.) son mucho mejores que todo lo que era antes o no funcionan en absoluto. Meh
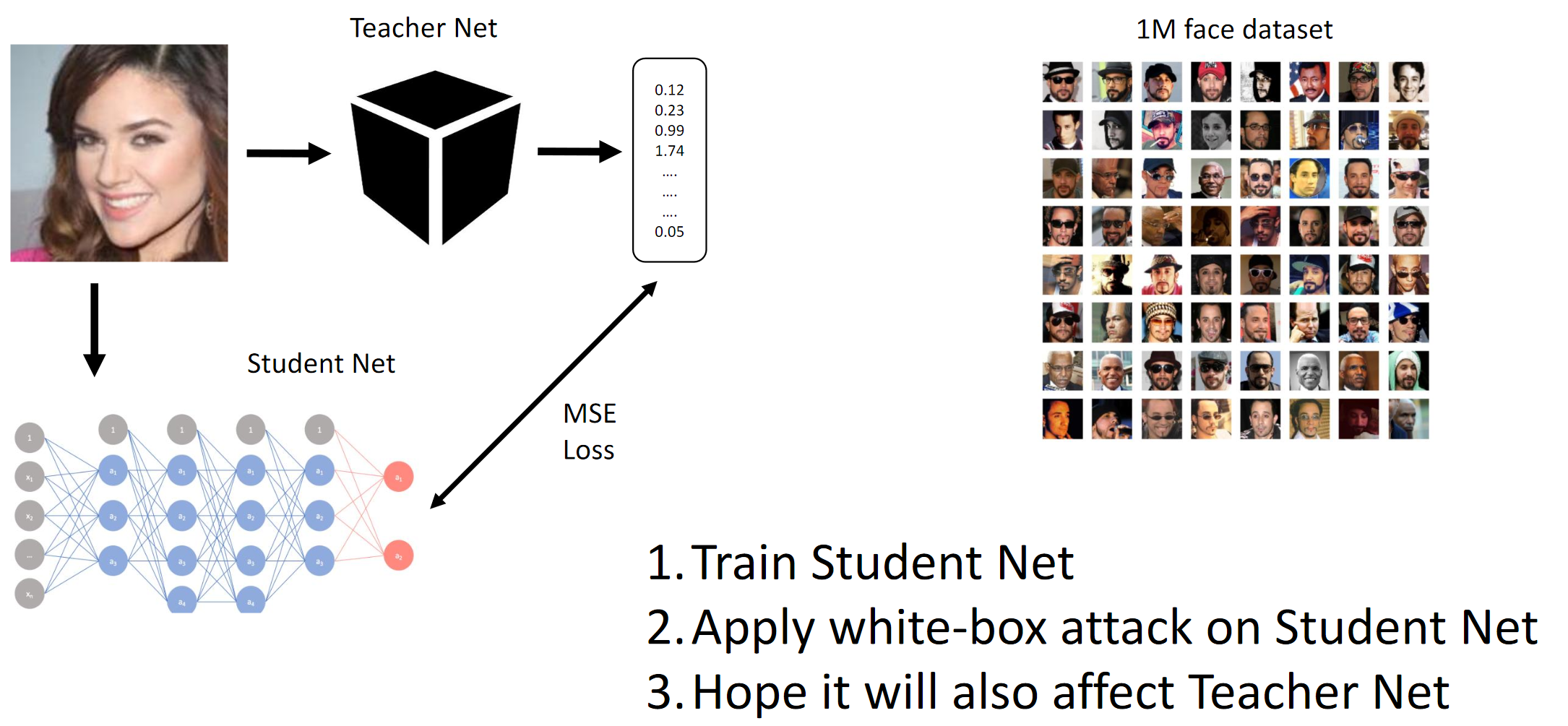 1. Entrenar a la red de estudiantes. 2. Aplicar el ataque BY en la red de estudiantes. 3. Los ataques Hope Teacher Net también se extendieronCómo funciona el método de gradiente
1. Entrenar a la red de estudiantes. 2. Aplicar el ataque BY en la red de estudiantes. 3. Los ataques Hope Teacher Net también se extendieronCómo funciona el método de gradiente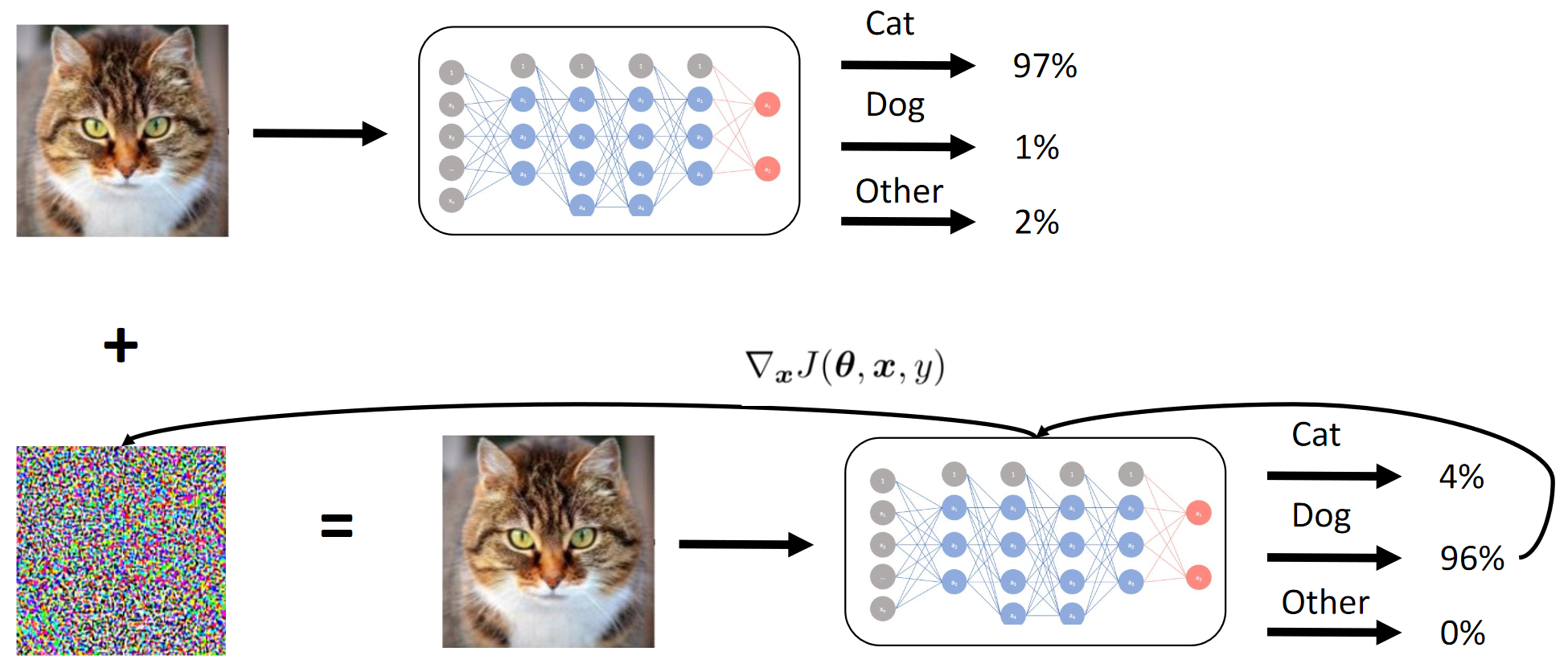
Esencialmente logramos por destilación que el BY emula al BY. Luego se consideran los gradientes de las imágenes de entrada en relación con la salida del modelo. El secreto, como siempre, radica en la heurística.
Métrica objetivo
La métrica objetivo era la norma L2 promedio (distancia euclidiana) entre las 25 combinaciones de imágenes fuente y objetivo (5 * 5 = 25).
Debido a las limitaciones de la plataforma (CodaLab), era probable que los puntajes privados (y la fusión de los equipos) se calcularan manualmente, lo que sería una gran historia.

El equipo
Me uní al equipo después de entrenar cuadrículas de estudiantes, mejor que todos los demás en la tabla de clasificación (hasta donde yo sé), y después de una pequeña discusión con
Atmyre (ella ayudó con el QW correctamente compilado, ya que ella misma se enfrentó a lo mismo). Luego compartimos nuestros puntajes locales sin compartir enfoques y códigos, y en realidad, 2-3 días antes de la línea de meta sucedió lo siguiente:
- Mis modelos continuos fracasaron (sí, en este caso también);
- Tenía los mejores modelos de estudiante;
- Ellos (los equipos) tuvieron las mejores variaciones heurísticas para FGVM (su código se basó en la línea base);
- Acabo de probar modelos con gradientes y alcancé una velocidad local de aproximadamente 1.1; inicialmente no quería usar la línea de base de mis preferencias personales (me desafié a mí mismo);
- No tenían suficiente poder de cómputo en ese momento;
- Al final, probamos suerte y unimos fuerzas: invertí mi poder de cómputo / redes neuronales convolucionales / conjunto de pruebas de ablación. El equipo puso su código base, que pulieron durante un par de semanas;
Una vez más, me gustaría agradecerle por sus valiosos consejos y habilidades organizativas.
Composición del equipo:
github.com/atmyre - basado en las acciones, fue el capitán del equipo inicialmente. Se agregó un ataque de evolución diferencial genética en la presentación final;
github.com/mortido : la mejor implementación de ataques FGVM con excelentes heurísticas + 2 modelos entrenados utilizando el código de línea de base;
github.com/snakers4 : además de cualquier prueba para reducir el número de opciones para encontrar una solución, entrené a 3 modelos de estudiantes con las mejores métricas + proporcioné potencia informática + ayudé en la fase de presentación final y presentación de los resultados;
github.com/stalkermustang;Como resultado, todos aprendimos mucho unos de otros, y me alegro de haber probado suerte en esta competencia. La ausencia de al menos una de cada tres contribuciones llevaría a la derrota.
2. Destilación Estudiante CNN
Logré obtener la mejor velocidad al entrenar modelos de estudiantes, ya que usé mi propio código en lugar del código de referencia.
Puntos clave / lo que funcionó:- Selección de un régimen de entrenamiento para cada arquitectura individualmente;
- Primer entrenamiento con Adam + LR decaimiento;
- Monitoreo cuidadoso de la capacidad de modelar y sobreajustar;
- Ajuste manual de modos de entrenamiento. No confíes completamente en los esquemas automáticos: pueden funcionar, pero si configuras bien la configuración, el tiempo de entrenamiento se puede reducir en 2-3 veces. Esto es especialmente importante con modelos pesados como DenseNet;
- Las arquitecturas pesadas funcionaron mejor que las arquitecturas ligeras, sin contar VGG;
- El entrenamiento con pérdida de L2 en lugar de MSE también funciona, pero un poco peor;
Lo que no funcionó:- Arquitecturas basadas en el inicio (no adecuadas debido al alto muestreo descendente y la mayor resolución de entrada). Aunque el equipo en tercer lugar pudo usar de alguna manera Inception-v1 e imágenes de corte completo (~ 250x250);
- Arquitecturas basadas en VGG (sobreajuste);
- Arquitecturas ligeras (SqueezeNet / MobileNet - equipamiento insuficiente);
- Aumento de imágenes (sin modificar los descriptores, aunque el equipo de alguna manera lo sacó del tercer lugar);
- Trabajar con imágenes a tamaño completo;
- También al final de las redes neuronales proporcionadas por los organizadores de la competencia había una capa de normas por lotes. Esto no ayudó a mis colegas, y usé mi código, ya que no entendía por qué esta capa estaba allí;
- Uso de mapas destacados con ataques basados en píxeles. Supongo que esto es más aplicable a imágenes de tamaño completo (solo compare 112x112x search_space y 299x299x search_space);
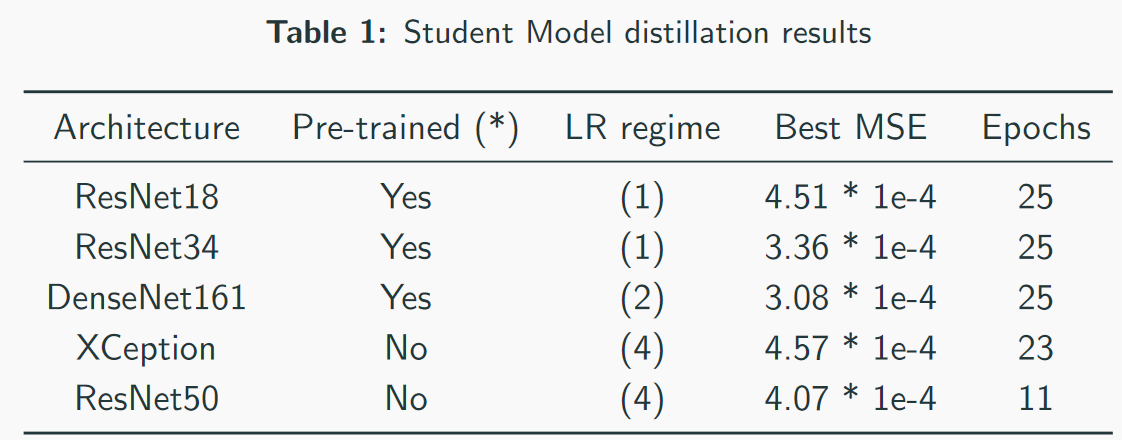 Nuestros mejores modelos: tenga en cuenta que la mejor velocidad es 3 * 1e-4. A juzgar por la complejidad de los modelos, uno puede imaginar aproximadamente que QW es ResNet34. En mis pruebas, ResNet50 + funcionó peor que ResNet34.
Nuestros mejores modelos: tenga en cuenta que la mejor velocidad es 3 * 1e-4. A juzgar por la complejidad de los modelos, uno puede imaginar aproximadamente que QW es ResNet34. En mis pruebas, ResNet50 + funcionó peor que ResNet34.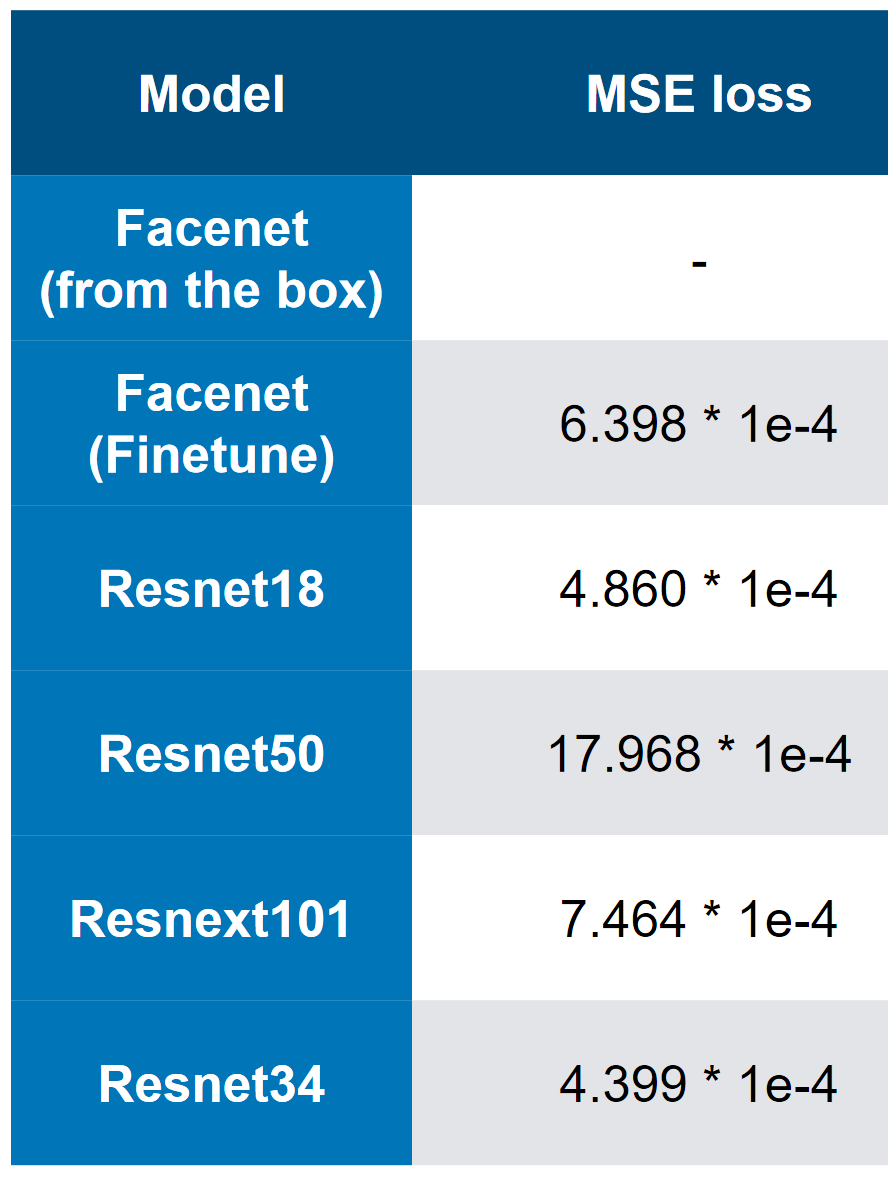 MSE primer lugar pérdida
MSE primer lugar pérdida3. La velocidad final y el análisis de "ablación"
Recolectamos nuestra velocidad así:
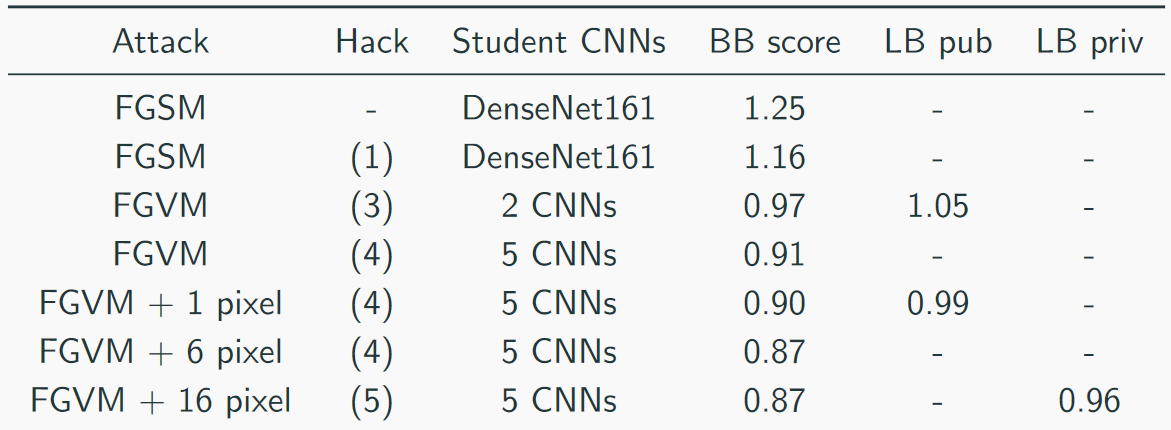
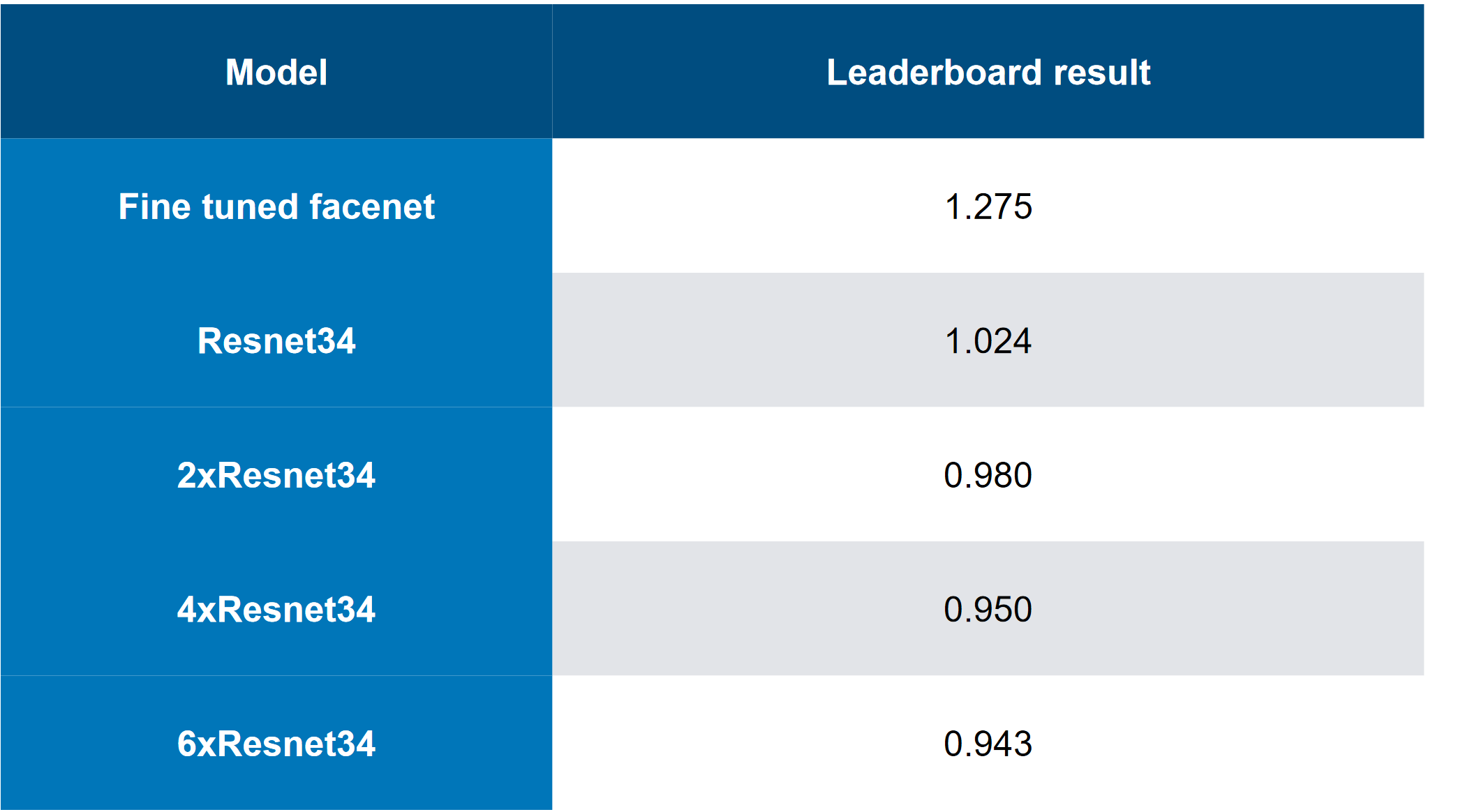
La solución principal se veía así (sí, hubo bromas sobre el hecho de que solo apilando la matanza, puedes adivinar que CH es una matanza):
Otros enfoques útiles de otros equipos:
- Parámetros adaptativos épsilon;
- Aumento de datos
- Momento de inercia;
- El momento de Nesterov ;
- Imágenes especulares;
- "Hackea" un poco los datos: solo había 1000 imágenes únicas y 5000 combinaciones de imágenes => era posible generar más datos (no 5 objetivos, sino 10, porque las imágenes se repitieron);
Heurística útil para FGVM:
- Generación de ruido por la regla: ruido = eps * pinza (grad / grad.std (), -2, 2);
- Un conjunto de varias CNN ponderando sus gradientes;
- Guardar cambios solo si reducen la pérdida promedio;
- Use combinaciones de objetivos para una orientación más consistente
- Utilice solo gradientes que sean más altos que la media + estándar (para FGSM);
Sammari corto:
- En primer lugar, fue una decisión más "torpe"
- Teníamos la solución más "diversificada";
- En tercer lugar fue la solución más "elegante";
Soluciones de punta a punta
Incluso si fallaron, valen la pena intentarlo en el futuro en nuevas tareas. Vea los detalles en el repositorio, pero de hecho probamos lo siguiente:
- Ataque C&W;
- LinkNet siamés;
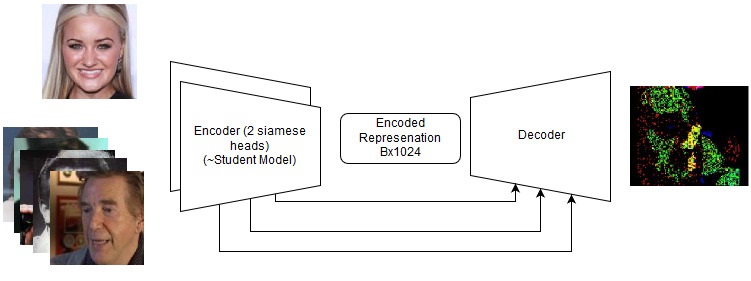 Modelo de extremo a extremo
Modelo de extremo a extremo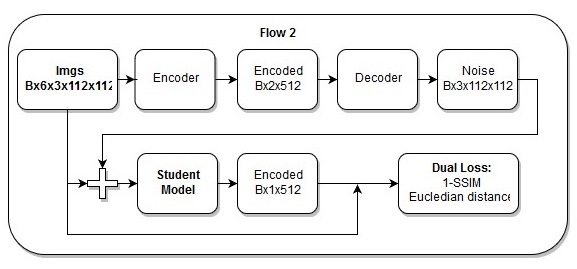 La secuencia de acciones en el modelo de extremo a extremo.
La secuencia de acciones en el modelo de extremo a extremo.También creo que mi
pérdida es simplemente hermosa.
5. Referencias y materiales de lectura adicionales.
- Página de competencia ;
- Nuestro repositorio ;
- Una serie de artículos sobre VAE es un tema similar;
- Recursos de SSIM
- Recursos para la evolución diferencial.
- Presentaciones
- 2 artículos más útiles:
- 2 artículos de revisión "en la parte superior":