Publicado mayo 17, 2018Inmediatamente después de instalar la colmena, pensé: "Me pregunto cómo calcular la cantidad de abejas que llegan y salen".
Un pequeño estudio mostró: hasta ahora nadie parece haber encontrado un buen sistema no invasivo para resolver este problema. Pero probablemente sería útil tener esa información para verificar el estado de la colmena.
Primero, necesita recolectar muestras de datos. Raspberry Pi, cámara Pi estándar y panel solar: este equipo simple es suficiente para grabar un cuadro cada 10 segundos y guardar más de 5000 imágenes por día (de 6 a.m. a 9 p.m.).

Debajo hay una imagen de ejemplo ... ¿Cuántas abejas puedes contar?

¿Cuál es exactamente la pregunta?
En segundo lugar, es necesario formular el problema de lo que debe hacer exactamente la red neuronal. Si la tarea es "contar abejas en la imagen", puede intentar obtener números específicos, pero esta no parece ser la opción más fácil, y el seguimiento de las abejas individuales entre cuadros no es un placer. En cambio, decidí centrarme en localizar cada abeja en la imagen.
Una verificación rápida de un detector estándar cuadro por cuadro no produjo ningún resultado en particular. Esto no es sorprendente, especialmente teniendo en cuenta la densidad de las abejas alrededor de la entrada a la colmena (pista: transferir el entrenamiento no siempre funciona), pero esto es normal. Entonces, tengo una imagen muy pequeña, solo una clase para reconocer objetos y no hay problemas especiales con el cuadro delimitador como tal. Simplemente decida si hay una abeja o no. ¿Qué solución será más simple?
v1: red completamente convolucional "bee eat / not" en un fragmento
El primer experimento rápido fue el detector "la abeja en la imagen es / no es". Es decir, cuál es la probabilidad de que haya al menos una abeja en este fragmento de la imagen. Hacer esto en forma de una
red completamente convolucional en fragmentos muy pequeños de la imagen significa que puede procesar fácilmente los datos en resolución completa. El enfoque pareció funcionar, pero falló en el área de entrada de la colmena con una densidad muy alta de abejas.
v2: imagen RGB → mapa de bits en blanco y negro
Rápidamente me di cuenta de que el problema puede reducirse al problema de la transformación de la imagen. En la entrada, la señal de la cámara es RGB, y en la salida hay una imagen de un solo canal donde el píxel "blanco" indica el centro de la abeja.
 Entrada RGB (fragmento) y salida de un solo canal (fragmento)
Entrada RGB (fragmento) y salida de un solo canal (fragmento)Marcado
El tercer paso es el etiquetado, es decir, la asignación de designaciones. No es demasiado difícil implementar una pequeña aplicación
TkInter para seleccionar /
deseleccionar abejas en la imagen y guardar los resultados en la base de datos SQLite. Pasé mucho tiempo para configurar correctamente esta herramienta: cualquiera que haya realizado manualmente una cantidad significativa de marcado me entenderá: /
Más adelante veremos, afortunadamente, que con una gran cantidad de muestras puede obtener un resultado bastante bueno con métodos semiautomáticos.
Modelo
La arquitectura de red es bastante estándar u-net.
- red totalmente convolucional entrenada en fragmentos con media resolución, pero funciona en imágenes con resolución completa;
- la codificación es una secuencia de cuatro convoluciones 3 × 3 en incrementos de 2
- decodificación: una secuencia de cambios de tamaño en los vecinos más cercanos + plegado 3 × 3 en incrementos de 1 + omitiendo la conexión de los codificadores;
- la capa de convolución final 1 × 1 con el paso 1 con la activación de la función sigmoidea (es decir, la opción binaria "abeja es / no es" para cada píxel).
Después de algunos experimentos empíricos, decidí volver a decodificar con media resolución. Fue suficiente.
Decodifiqué cambiando el tamaño a los vecinos más cercanos en lugar de desconvolver más por costumbre.
La red fue entrenada por el método
Adam y era demasiado pequeña para aplicar la
normalización por lotes . El diseño resultó ser sorprendentemente simple, una pequeña cantidad de filtros fue suficiente.

Apliqué el método estándar de aumento de datos, rotación aleatoria y distorsión de color. El entrenamiento en fragmentos significa que esencialmente obtenemos una variante de cortar aleatoriamente la imagen. No roté la imagen porque la cámara siempre se encuentra a un lado de la colmena.
Hay algunos matices en las predicciones de salida de posprocesamiento. Con resultados probabilísticos, obtenemos una nube borrosa donde puede haber abejas. Para convertirlo en una imagen clara de un píxel por abeja, agregué un valor umbral, teniendo en cuenta los componentes relacionados y detectando los centroides utilizando
el módulo de medición de skimage . Todo esto tenía que instalarse manualmente y configurarse únicamente a simple vista, aunque en teoría se puede agregar al final de la pila como un elemento de aprendizaje. Tal vez tenga sentido hacerlo en el futuro ... :)
 Entrada, salida sin procesar y centroides de clúster
Entrada, salida sin procesar y centroides de clústerUnos dias generalizacion
En un dia
Inicialmente, los experimentos se realizaron con imágenes en un corto período de un día. Resultó ser fácil obtener un buen modelo a partir de estos datos con un pequeño número de imágenes marcadas (aproximadamente 30).
 Tres muestras recibidas el primer día.
Tres muestras recibidas el primer día.Por muchos dias
Las cosas se pusieron más complicadas cuando comencé a considerar períodos más largos de varios días. Una de las diferencias clave es la diferencia en la iluminación (hora del día y clima diferente). Otra razón es que instalo la cámara manualmente todos los días, simplemente pegándola con Velcro. La tercera y más inesperada diferencia fue que con el crecimiento de la hierba, los brotes de diente de león parecen abejas (es decir, en la primera ronda el modelo entrenado no vio los brotes, y luego aparecieron y proporcionaron una corriente continua de falsos positivos).
La mayoría de los problemas se resolvieron mediante el aumento de datos, y ningún problema se volvió crítico. En general, los datos no varían demasiado. Esto es genial, porque te permite limitarte a una red neuronal simple y un esquema de entrenamiento.
 Muestras obtenidas en tres días.
Muestras obtenidas en tres días.Ejemplo de pronóstico
La imagen muestra un ejemplo de pronóstico. Es interesante notar que hay muchas más abejas que en cualquier imagen que etiquete manualmente. Esta es una gran confirmación de que un enfoque totalmente convolucional con el aprendizaje en pequeños fragmentos realmente funciona.

La red funciona bien en una amplia gama de opciones. Supongo que un fondo uniforme ayuda aquí, y comenzar la red en una colmena arbitraria no dará un resultado tan bueno.
 De izquierda a derecha: alta densidad alrededor de la entrada; abejas de diferentes tamaños; abejas a alta velocidad!
De izquierda a derecha: alta densidad alrededor de la entrada; abejas de diferentes tamaños; abejas a alta velocidad!Trucos de etiquetado
Entrenamiento semi-controlado
La posibilidad de obtener una gran cantidad de imágenes sugiere de inmediato la idea de utilizar un entrenamiento semi-controlado.
Un enfoque muy simple:
- Tomando 10,000 imágenes.
- Etiquetado de 100 imágenes y
model_1 entrenamiento_1. - Usando
model_1 para marcar las 9900 imágenes restantes. model_2 entrenamiento_2 sobre las 10.000 imágenes "etiquetadas".
Como resultado,
model_2 muestra un mejor resultado que
model_1 .
Aquí hay un ejemplo. Tenga en cuenta que
model_1 muestra algunos falsos positivos (centro izquierdo y brizna de hierba) y falsas respuestas negativas (abejas alrededor de la entrada a la colmena).
 Izquierda model_1, derecha model_2
Izquierda model_1, derecha model_2Marcado arreglando un mal modelo
Tales datos también son un gran ejemplo de cómo arreglar un modelo malo es más rápido que marcar desde cero ...
- Marcamos 10 imágenes y entrenamos al modelo.
- Usamos el modelo para marcar las siguientes 100 imágenes.
- Utilizamos la herramienta de marcado para corregir las marcas en estas 100 imágenes.
- Vuelva a educar al modelo en 110 imágenes.
- Repetimos ...
Este es un patrón de aprendizaje muy común, y a veces te obliga a revisar un poco tu herramienta de etiquetado.
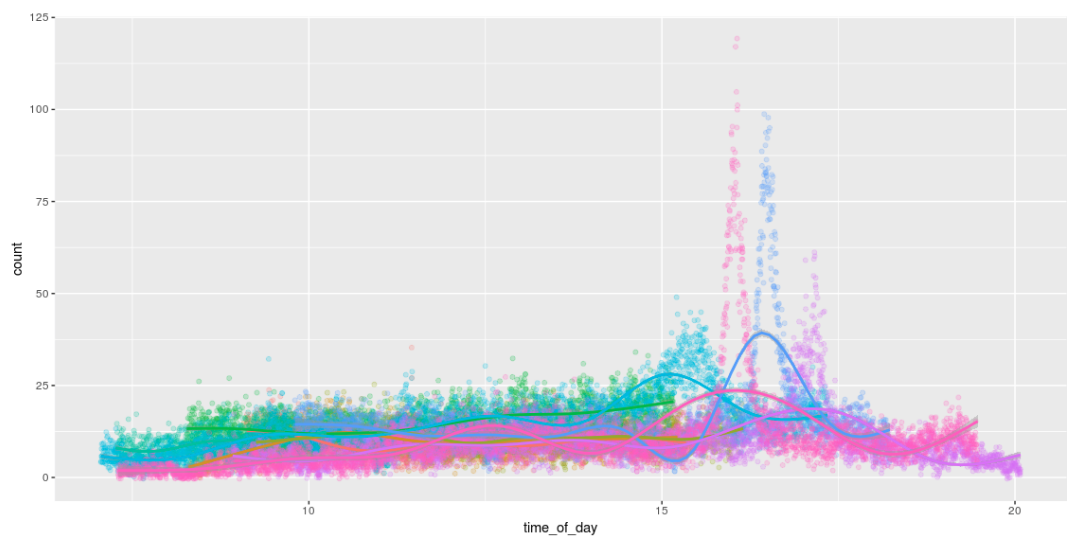
Contando
¡La posibilidad de detectar abejas significa que podemos contarlas! Y para divertirse, dibuje gráficos divertidos que muestren la cantidad de abejas durante el día. Me encanta la forma en que trabajan todo el día y llegan a casa alrededor de las 4 p.m. :)
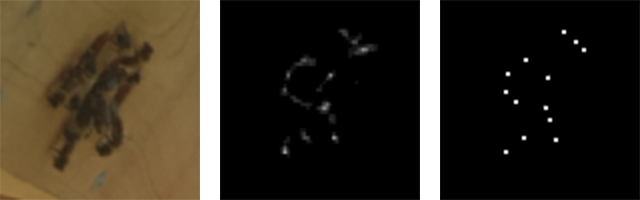
Raspberry Pi de salida
Lanzar el modelo en el Pi fue una parte importante de este proyecto.
Directamente en el hierro Pi
Originalmente se planeó congelar el gráfico TensorFlow y simplemente ejecutarlo directamente en el Pi. Esto funciona sin problemas, pero solo Pi toma solo 1 imagen por segundo. : /
Ejecutando en el Módulo de Computación Movidius
Estaba muy interesado en la oportunidad de lanzar un modelo en un Pi usando el
Movidus Neural Compute Stick . Este es un gadget increíble.
Lamentablemente, no pasó nada: /. La API para convertir un gráfico TensorFlow a su formato de modelo interno no es compatible con mi método de decodificación. Por lo tanto, era necesario aumentar el tamaño (aumento de tamaño), utilizando la deconvolución en lugar de cambiar el tamaño de los vecinos más cercanos. No hay problemas además del hecho de que no pasó nada. Hay muchas dificultades pequeñas, debido a que los
errores se multiplicaron . Cuando se arreglen, puede volver a este tema ...
Modelo v3: imagen RGB → recuento de abejasEsto me llevó a la tercera versión del modelo: ¿podemos pasar directamente de la entrada RGB al recuento de abejas? De esta forma, evitaremos problemas con operaciones no compatibles en el Movidus Neural Compute Stick, aunque es poco probable que el resultado sea tan bueno como en el modelo centroide v2.
Al principio tenía miedo de probar este método: pensé que requeriría mucho más etiquetado (ya no es un sistema basado en fragmentos). Pero! Con un modelo que funciona bastante bien con la búsqueda de abejas y una gran cantidad de datos sin marcar, puede generar un buen conjunto de datos sintéticos aplicando el modelo v2 y simplemente contando el número de detecciones.
Tal modelo es bastante fácil de aprender y da resultados significativos ... (aunque todavía no es tan bueno como un simple cálculo de los centroides detectados por el modelo v2).
| Número real y previsto de abejas en algunas muestras de prueba. |
| Lo real | 40 | 19 | 16 | 15 | 13 | 12 | 11 | 10 | 8 | 7 7 | 6 6 | 4 4 |
| v2 (centroide) predictivo | 39 | 19 | 16 | 13 | 13 | 14 | 11 | 8 | 8 | 7 7 | 6 6 | 4 4 |
| Pronóstico v3 (cálculo simple) | 33,1 | 15,3 | 12,3 | 12,5 | 13,3 | 10,4 | 9.3 | 8.7 | 6.3 | 7.1 | 5.9 | 4.2 4.2 |
... desafortunadamente, el modelo
todavía no funciona en el Neural Compute Stick (es decir, funciona, pero solo da resultados aleatorios). Hice
algunos informes de errores más y dejé de nuevo el dispositivo para volver más tarde ... algún día ...
Que sigue
Como siempre, quedaban un montón de pequeñas cosas ...
- Lanzamiento en Neural Compute Stick (NCS); Ahora estamos esperando un poco de trabajo por su parte ...
- Transfiera todo a la cámara incorporada JeVois . Me metí un poco con ella, pero antes que nada quería lanzar un modelo en NCS. ¡Quiero rastrear abejas a 120 FPS!
- Rastree las abejas entre múltiples cuadros / cámaras para visualizar el flujo óptico.
- Explore con más detalle los beneficios de un enfoque semi-controlado y entrene un modelo más grande para etiquetar datos para un modelo más pequeño.
- Explore las características de NCS; ¿Qué hacer con la configuración de hiperparámetros?
- Continúe desarrollando una versión pequeña de FarmBot para realizar algunos experimentos genéticos con plántulas CNC (es decir, algo completamente diferente).
Código
Todo el código se publica
en Github .