
Anotación
El procesamiento de datos en tiempo real exactamente una vez ( exactamente una vez ) es una tarea extremadamente trivial y requiere un enfoque serio y reflexivo en toda la cadena de cálculos. Algunos incluso creen que tal tarea es imposible . En realidad, quiero tener un enfoque que proporcione un procesamiento tolerante a fallas sin demora y el uso de varios almacenamientos de datos, que presente nuevos requisitos aún más estrictos para el sistema: concurrente exactamente una vez y heterogeneidad de la capa persistente. Hasta la fecha, dicho requisito no es compatible con ninguno de los sistemas existentes.
El enfoque propuesto revelará consistentemente los ingredientes secretos y los conceptos necesarios que hacen que sea relativamente fácil implementar un procesamiento heterogéneo concurrente exactamente una vez literalmente a partir de dos componentes.
Introduccion
El desarrollador de sistemas distribuidos pasa por varias etapas:
Etapa 1: Algoritmos . Aquí está el estudio de algoritmos básicos, estructuras de datos, enfoques de programación como OOP, etc. El código es exclusivamente de un solo subproceso. La fase inicial de ingreso a la profesión. Sin embargo, es bastante complicado y puede durar años.
Etapa 2: Multithreading . Luego, surgen preguntas sobre la extracción de la máxima eficiencia del hierro, hay múltiples subprocesos, asincronía, carreras, depuración, strace, noches sin dormir ... Muchos se quedan atrapados en esta etapa e incluso comienzan a sentir una emoción inexplicable en algún momento. Pero solo unos pocos llegan a comprender la arquitectura de la memoria virtual y los modelos de memoria, los algoritmos sin bloqueo / sin espera y varios modelos asincrónicos. Y casi nadie: verificación de código de subprocesos múltiples.
Etapa 3: Distribución . Aquí está sucediendo tal basura que ni en un cuento de hadas ni en un bolígrafo para describir.
Parecería que algo complicado. Hacemos la transformación: muchos hilos -> muchos procesos -> muchos servidores. Pero cada paso de la transformación produce cambios cualitativos, y todos caen en el sistema, lo aplastan y lo convierten en polvo.
Y el punto aquí es cambiar el dominio de manejo de errores y la disponibilidad de memoria compartida. Si antes siempre había un trozo de memoria disponible en cada subproceso, y si se deseaba, en cada proceso, ahora no existe ese trozo y no puede existir. Cada uno para sí mismo, independiente y orgulloso.
Si antes una falla en la corriente enterraba la corriente y el proceso al mismo tiempo, y esto era bueno, porque no condujo a fallas parciales, ahora las fallas parciales se convierten en la norma y cada vez que piensa cada acción: "¿y si?". Esto es tan molesto y distrae de la escritura, de hecho, las acciones en sí mismas que el código debido a esto no crece a veces, sino por órdenes de magnitud. Todo se convierte en los fideos de manejo de errores, cambio de estado y preservación del contexto, restauración debido a fallas de un componente, otro componente, inaccesibilidad de algunos servicios, etc. etc. Después de haber estropeado el monitoreo de todo esto, puede tener una buena noche de sueño en su computadora portátil favorita.
Si se trata de subprocesos múltiples: tomé el mutex y fui a triturar la memoria compartida por placer. Belleza!
Como resultado, tenemos que se quitaron las claves y los patrones probados en la batalla, y los nuevos, para reemplazarlos, por alguna razón no se entregaron, y resultó como en una broma sobre cómo la hada agitó su varita y la torre se cayó del tanque.
Sin embargo, los sistemas distribuidos tienen un conjunto de prácticas y algoritmos probados. Sin embargo, cada programador que se respete a sí mismo considera que es su deber rechazar los logros conocidos y andar en bicicleta por su propio bien, a pesar de la experiencia adquirida, un número considerable de artículos científicos e investigaciones académicas. Después de todo, si puede usar algoritmos y subprocesos múltiples, ¿cómo puede meterse en un lío con la distribución? ¡No puede haber dos opiniones aquí!
Como resultado, los sistemas tienen errores, los datos divergen y se deterioran, los servicios periódicamente no están disponibles para la escritura, o incluso no están completamente disponibles, porque de repente un nodo se bloqueó, la red se cayó, Java consumió mucha memoria y GC se aburrió, y hay muchas otras razones que podrían retrasar su finalización. a las autoridades.
Sin embargo, incluso con enfoques conocidos y probados, la vida no se vuelve más fácil, porque Las primitivas confiables distribuidas son pesadas con requisitos serios para la lógica del código ejecutable. Por lo tanto, las esquinas se cortan siempre que sea posible. Y, como suele suceder, con esquinas cortadas apresuradamente, aparece la simplicidad y la escalabilidad relativa, pero la confiabilidad, disponibilidad y consistencia de un sistema distribuido desaparece.
Idealmente, me gustaría no pensar en absoluto que nuestro sistema está distribuido y multiproceso, es decir trabajar en la primera etapa (algoritmos), sin pensar en la segunda (subprocesamiento múltiple + asincronía) y la tercera (distribución). Esta forma de aislar abstracciones aumentaría significativamente la simplicidad, confiabilidad y velocidad de escribir código. Desafortunadamente, por el momento esto solo es posible en los sueños.
Sin embargo, las abstracciones individuales permiten un relativo aislamiento. Uno de los ejemplos típicos es el uso de corutinas , donde en lugar de código asincrónico nos hacemos sincrónicos, es decir. pasamos de la segunda etapa a la primera etapa, lo que nos permite simplificar significativamente la escritura y el mantenimiento del código.
El artículo revela sucesivamente el uso de algoritmos sin bloqueo para construir un sistema confiable en tiempo real, escalable, distribuido y consistente, es decir cómo los logros sin bloqueo de la segunda etapa ayudan en la implementación de la tercera, reduciendo la tarea a algoritmos de subproceso único de la primera etapa.
Declaración del problema.
Esta tarea solo ilustra algunos enfoques importantes y se presenta como un ejemplo para introducir problemas en el contexto. Se puede generalizar fácilmente a casos más complejos, lo que se hará en el futuro.
Tarea: procesamiento de datos en tiempo real .
Hay dos corrientes de números. El controlador lee los datos de estos flujos de entrada y selecciona los últimos números para un período determinado. Estos números se promedian durante este intervalo de tiempo, es decir en una ventana de datos deslizante durante un tiempo determinado. El valor promedio obtenido debe escribirse en la cola de salida para el procesamiento posterior. Además, si el número de números en la ventana excede un cierto umbral, aumente en uno el contador en la base de datos transaccional externa.
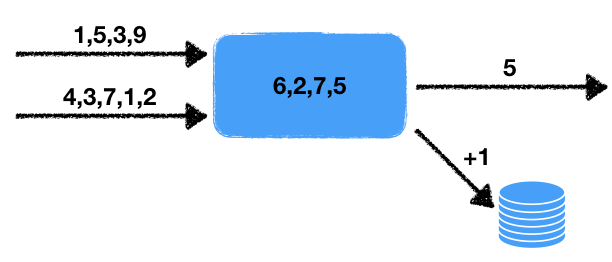
Observamos algunas características de este problema.
- No determinismo . Hay dos fuentes de comportamiento no determinista: esta es una lectura de dos flujos, así como una ventana de tiempo. Está claro que la lectura puede llevarse a cabo de diferentes maneras, y el resultado final dependerá de en qué secuencia se extraerán los datos. La ventana de tiempo también cambia el resultado de inicio a inicio, ya que La cantidad de datos en la ventana dependerá de la velocidad del trabajo.
- El estado del manejador . Hay un estado del controlador en forma de un conjunto de números en la ventana, del que dependen los resultados actuales y posteriores del trabajo. Es decir Tenemos un controlador con estado.
- Interacción con almacenamiento externo . Es necesario actualizar el valor del contador en la base de datos externa. El punto crucial es que el tipo de almacenamiento externo es diferente del almacenamiento del estado del procesador y los subprocesos.
Todo esto, como se mostrará a continuación, afecta seriamente las herramientas utilizadas y los posibles métodos de implementación.
Queda por agregar un pequeño toque a la tarea, que inmediatamente transfiere la tarea de un área más allá de la complejidad a lo imposible: se necesita una garantía concurrente de una sola vez .
Exactamente una vez
Exactamente una vez a menudo se interpreta de manera demasiado amplia, lo que emascula el término en sí mismo, y deja de cumplir con los requisitos originales de la tarea. Si estamos hablando de un sistema que se ejecuta localmente en una computadora, entonces todo es simple: toma más, tira más. Pero en este caso estamos hablando de un sistema distribuido en el que:
- El número de manejadores puede ser grande: cada manejador trabaja con sus propios datos. Además, los resultados se pueden agregar a varios lugares, por ejemplo, una base de datos externa, posiblemente incluso barajada.
- Cada controlador puede detener repentinamente el procesamiento. Un sistema tolerante a fallas implica una operación continua incluso en caso de falla de partes individuales del sistema.
Por lo tanto, debemos estar preparados para el hecho de que el controlador puede caer, y otro controlador debe recoger el trabajo ya realizado y continuar con el procesamiento.
La pregunta surge de inmediato: ¿qué significará exactamente una vez si funciona el controlador no determinista? Después de todo, cada vez que reiniciamos, recibiremos, en términos generales, diferentes estados resultantes. La respuesta aquí es simple: con exactamente una vez, existe tal ejecución del sistema en la que cada valor de entrada se procesa exactamente una vez, dando el resultado de salida correspondiente. Además, esta ejecución no tiene que estar físicamente en el mismo nodo. Pero el resultado debería ser como si todo se procesara en un solo nodo lógico sin bloqueos .
Concurrente exactamente una vez
Para agravar los requisitos, presentamos un nuevo concepto: concurrente exactamente una vez . La diferencia fundamental de simple exactamente una vez es la ausencia de pausas durante el procesamiento, como si todo se procesara en el mismo nodo sin caídas y sin pausas . En nuestra tarea, requeriremos exactamente concurrente exactamente una vez , por simplicidad de presentación, para no considerar una comparación con los sistemas existentes que no están disponibles hoy en día.
Las consecuencias de tener tal requisito se discutirán a continuación.
Transaccional
Para que el lector esté aún más profundamente imbuido de la complejidad que ha surgido, veamos varios escenarios negativos que deben tenerse en cuenta al desarrollar un sistema de este tipo. También intentaremos utilizar un enfoque general que nos permita resolver el problema anterior teniendo en cuenta nuestros requisitos.
Lo primero que viene a la mente es la necesidad de registrar el estado del controlador y los flujos de entrada y salida. El estado de los flujos de salida se describe mediante una simple cola de números, y el estado de los flujos de entrada por la posición en ellos. En esencia, una secuencia es una cola infinita, y una posición en la cola establece de forma única una ubicación.

La siguiente implementación ingenua de un controlador surge utilizando algún tipo de almacén de datos. En esta etapa, las propiedades específicas del repositorio no serán importantes para nosotros. Usaremos el lenguaje Pseco para ilustrar la idea (Pseco: = pseudocódigo):
handle(input_queues, output_queues, state): # input_indexes = storage.get_input_indexes() # while true: # items, new_input_indexes = input_queues.get_from(input_indexes) # state.queue.push(items) # duration state.queue.trim_time_window(duration) avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary # (A) output_queues[0].push(avg) if need_update_counter: # (B) db.increment_counter() # (C) storage.save_state(state) # (D) storage.save_queue_indexes(new_input_indexes) # (E) input_indexes = new_input_indexes
Aquí hay un algoritmo simple de subproceso único que lee datos de flujos de entrada y escribe los valores deseados de acuerdo con la tarea descrita anteriormente.
Veamos qué sucede en caso de que un nodo caiga en puntos arbitrarios en el tiempo, así como después de reanudar el trabajo. Está claro que en caso de una caída en los puntos (A) y (E) todo estará bien: o los datos aún no se han registrado en ningún lugar y simplemente restauramos el estado y continuamos en otro nodo, o todos los datos necesarios ya se han registrado y simplemente continúan con el siguiente paso.
Sin embargo, en caso de una caída en todos los demás puntos, nos esperan problemas inesperados. Si se produce una caída en el punto (B) , cuando se reinicie el controlador, restauraremos el estado y volveremos a registrar el valor promedio en aproximadamente el mismo rango de números. En el caso de una caída en el punto (C) además del duplicado promedio, se producirá un duplicado en el incremento del valor. Y en caso de una caída en (D) obtendremos un estado inconsistente del controlador: el estado corresponde a un nuevo momento en el tiempo, y leeremos los valores de los flujos de entrada antiguos.

Al mismo tiempo, nada cambiará fundamentalmente al reorganizar las operaciones de grabación: la inconsistencia y los duplicados seguirán siéndolo. Por lo tanto, llegamos a la conclusión de que todas las acciones para cambiar el estado del controlador en el repositorio, la cola de salida y la base de datos deben realizarse transaccionalmente, es decir. todo es atómico al mismo tiempo.
Por consiguiente, es necesario desarrollar un mecanismo para que diferentes almacenamientos puedan cambiar transaccionalmente su estado, y no dentro de cada uno de forma independiente, sino transaccionalmente entre todos los almacenamientos simultáneamente. Por supuesto, puede colocar nuestro almacenamiento dentro de una base de datos externa, sin embargo, la tarea asumió que el motor de la base de datos y el motor para el marco de procesamiento de datos de transmisión están separados y funcionan de forma independiente el uno del otro. Aquí quiero considerar el caso más difícil, porque No es interesante considerar casos simples.
Capacidad de respuesta competitiva
Considere la ejecución competitiva exactamente una vez con más detalle. En el caso de un sistema tolerante a fallas, requerimos la continuación del trabajo desde algún punto. Está claro que este punto será un punto en el pasado, porque Para mantener el rendimiento, es imposible almacenar todos los momentos de cambios de estado en el presente y en el futuro: se guarda el último resultado de las operaciones o un grupo de valores para aumentar el rendimiento. Este comportamiento nos lleva inmediatamente al hecho de que después de la restauración del estado del procesador, habrá algún retraso en los resultados, aumentará con el aumento del tamaño del grupo de valores y el tamaño del estado.
Además de este retraso, también hay retrasos en el sistema asociados con la carga del estado en otro nodo. Además de esto, la detección de un nodo problemático también lleva algún tiempo, y a menudo mucho. Esto se debe, en primer lugar, al hecho de que si establecemos un tiempo de detección corto, entonces son posibles los falsos positivos frecuentes, lo que conducirá a todo tipo de efectos especiales desagradables.
Además, con el aumento en el número de procesadores paralelos, de repente resulta que no todos funcionan igual de bien incluso en ausencia de fallas. A veces se producen embotamientos, que también conducen a retrasos en el procesamiento. La razón de tales embotamientos puede variar:
- Software : pausas del GC, fragmentación de la memoria, pausas del asignador, interrupción del kernel y programación de tareas, problemas con los controladores de dispositivos que causan ralentizaciones.
- Hardware : disco alto o carga de red, aceleración de la CPU debido a problemas de enfriamiento, sobrecarga, etc., desaceleración del disco debido a problemas técnicos.
Y esta no es una lista exhaustiva de problemas que pueden ralentizar a los manejadores.
En consecuencia, la desaceleración es un hecho con el que uno tiene que vivir. A veces esto no es un problema grave, y a veces es extremadamente importante mantener una alta velocidad de procesamiento a pesar de fallas o ralentizaciones.
Inmediatamente surge la idea de la duplicación de sistemas: corramos por el mismo flujo de datos, no uno sino dos procesadores a la vez, o incluso tres. El problema aquí es que, en este caso, pueden producirse fácilmente comportamientos duplicados e inconsistentes del sistema. Normalmente, los marcos no están diseñados para este comportamiento y sugieren que el número de controladores en un momento dado no excede uno. Los sistemas que permiten la duplicación de ejecución descrita se llaman concurrentes exactamente una vez .
Esta arquitectura le permite resolver varios problemas a la vez:
- Comportamiento a prueba de fallos: si uno de los nodos cae, el otro simplemente continúa funcionando como si nada hubiera pasado. No hay necesidad de coordinación adicional, ya que el segundo manejador se ejecuta independientemente del estado del primero.
- Eliminando las contundentes: el primero que proporcionó el resultado es bueno para él. El otro solo tendrá que recoger un nuevo estado y continuar desde este momento.
Este enfoque, en particular, le permite completar un cálculo largo y difícil por un tiempo más predecible, porque la probabilidad de que ambos sean estúpidos y caigan significativamente menos.
Evaluación de probabilidad
Intentemos evaluar los beneficios de la duplicación del rendimiento. Supongamos que algo sucede en promedio todos los días con el controlador: o el GC se ha embotado, o el nodo está mintiendo, o los contenedores se han vuelto cancerosos. Supongamos también que preparamos paquetes de datos en 10 segundos.
Entonces la probabilidad de que algo suceda durante la creación del paquete es 10 / (24 · 3600) ≃ 1e-4 .
Si ejecuta dos controladores en paralelo, entonces la probabilidad de que ambos ≃ 1e-8 es ≃ 1e-8 . ¡Entonces este evento llegará en 23 años! Sí, los sistemas no viven tanto, lo que significa que esto nunca sucederá.
Además, si el tiempo de preparación del paquete será aún más corto y / o se producirán embotamientos incluso con menos frecuencia, esta cifra solo aumentará.
Por lo tanto, concluimos que el enfoque considerado aumenta significativamente la confiabilidad de todo nuestro sistema. Solo queda resolver una pequeña pregunta como esta: dónde leer sobre cómo hacer un sistema concurrente de una sola vez . Y la respuesta es simple: tienes que leer aquí.
Media transacción
Para mayor discusión, necesitamos el concepto de media transacción . La forma más fácil de explicarlo es con un ejemplo.
Considere transferir fondos de una cuenta bancaria a otra. El enfoque tradicional que utiliza transacciones en el lenguaje Pseco se puede describir de la siguiente manera:
transfer(from, to, amount): tx = db.begin_transaction() amount_from = tx.get(from) if amount_from < amount: return error.insufficient_funds tx.set(from, amount_from - amount) tx.set(to, tx.get(to) + amount) tx.commit() return ok
Sin embargo, ¿qué pasa si estas transacciones no están disponibles para nosotros? Usando bloqueos, esto se puede hacer de la siguiente manera:
transfer(from, to, amount): # lock_from = db.lock(from) lock_to = db.lock(to) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) db.set(to, db.get(to) + amount) return ok
Este enfoque puede conducir a puntos muertos, ya que Los bloqueos se pueden tomar en diferentes secuencias en paralelo. Para corregir este comportamiento, es suficiente introducir una función que tome simultáneamente varios bloqueos en una secuencia determinista (por ejemplo, ordenada por teclas), lo que elimina por completo los posibles puntos muertos.
Sin embargo, la implementación puede simplificarse un tanto:
transfer(from, to, amount): lock_from = db.lock(from) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) lock_from.release() # , # .. db.set(db.get...) lock_to = db.lock(to) db.set(to, db.get(to) + amount) return ok
Este enfoque también hace que el estado final sea consistente, preservando a los invariantes por el tipo de prevención de gastos excesivos de fondos. La principal diferencia con el enfoque anterior es que en tal implementación tenemos un cierto período de tiempo en el que las cuentas están en un estado inconsistente. Es decir, tal operación implica que el estado total de los fondos en las cuentas no cambia. En este caso, hay un intervalo de tiempo entre lock_from.release() y db.lock(to) , durante el cual la base de datos puede devolver un valor inconsistente: la cantidad total puede diferir del correcto hacia abajo.
De hecho, dividimos una transacción para transferir dinero en dos medias transacciones:
- La primera mitad de la transacción hace un cheque y deduce la cantidad necesaria de la cuenta.
- La segunda mitad de la transacción escribe el monto retirado en otra cuenta.
Está claro que dividir una transacción en otras más pequeñas, en general, viola el comportamiento transaccional. Y el ejemplo anterior no es una excepción. Sin embargo, si todas las medias transacciones en la cadena se cumplen por completo, entonces el resultado será consistente con todos los invariantes preservados. Esto es precisamente lo que es una propiedad importante de una cadena de media transacción.
Sin embargo, al perder temporalmente cierta coherencia, adquirimos otra característica útil: la independencia de las operaciones y, como resultado, una mejor escalabilidad. La independencia se manifiesta en el hecho de que una media transacción cada vez funciona con una sola línea, leyendo, verificando y cambiando sus datos, sin comunicarse con otros datos. Por lo tanto, puede barajar una base de datos cuyas transacciones funcionan con un solo fragmento. Además, este enfoque se puede utilizar en el caso de repositorios heterogéneos, es decir las medias transacciones pueden comenzar en un tipo de almacenamiento y terminar en otro. Son propiedades útiles que se utilizarán en el futuro.
Surge una pregunta legítima: ¿cómo implementar half-trance en sistemas distribuidos y no rake? Para resolver este problema, debe considerar el enfoque sin bloqueo.
Sin bloqueo
Como sabe, los enfoques sin bloqueo a veces mejoran el rendimiento de los sistemas de subprocesos múltiples, especialmente en el caso del acceso competitivo al recurso. Sin embargo, es completamente obvio que este enfoque puede usarse en sistemas distribuidos. Profundicemos y consideremos qué es sin bloqueo y por qué esta propiedad será útil para resolver nuestro problema.
Algunos desarrolladores a veces no entienden qué es sin bloqueo. La mirada de mente estrecha sugiere que esto es algo relacionado con las instrucciones del procesador atómico. Es importante entender aquí que sin bloqueo significa el uso de "átomos", lo contrario no es cierto, es decir, no todas las "atómicas" dan un comportamiento sin bloqueo.
Una propiedad importante del algoritmo sin bloqueo es que al menos un subproceso avanza en el sistema. Pero por alguna razón, muchos atribuyen esta propiedad como una definición (es una definición tan contundente que se puede encontrar, por ejemplo, en Wikipedia ). Aquí es necesario agregar un matiz importante: el progreso se logra incluso en el caso de romos de uno o más hilos. Este es un punto muy crítico que a menudo se pasa por alto y tiene serias implicaciones para un sistema distribuido.
¿Por qué la ausencia de una condición de progreso de al menos un hilo niega el concepto de un algoritmo sin bloqueo? El hecho es que, en este caso, el spinlock habitual también estará libre de bloqueos. De hecho, el que tomó la cerradura hará progresos. ¿Hay un hilo con progreso => sin bloqueo?
Obviamente, sin bloqueo significa sin bloqueos, mientras que el spinlock por su nombre indica que se trata de un bloqueo real. Por eso es importante agregar una condición al progreso, incluso en el caso de embotamientos. Después de todo, estos retrasos pueden durar indefinidamente, porque la definición no dice nada sobre la línea de tiempo superior. Y si es así, dichos retrasos serán equivalentes en cierto sentido a la desconexión de los flujos. En este caso, los algoritmos sin bloqueo producirán progreso en este caso.
Pero, ¿quién dijo que los enfoques sin bloqueo se aplican exclusivamente a sistemas de subprocesos múltiples? Al reemplazar los subprocesos en el mismo proceso en el mismo nodo con procesos en diferentes nodos, y la memoria compartida de los subprocesos con almacenamiento distribuido compartido, obtenemos un algoritmo distribuido sin bloqueo.
Una caída de nodo en dicho sistema es equivalente a un retraso en la ejecución de un hilo durante algún tiempo, porque Es hora de restaurar el trabajo. Al mismo tiempo, el enfoque sin bloqueo permite que otros participantes en el sistema distribuido continúen trabajando. Además, se pueden ejecutar algoritmos especiales sin bloqueo en paralelo entre sí, detectando un cambio competitivo y eliminando duplicados.
El enfoque Exactamente una vez implica la presencia de un almacenamiento distribuido consistente. Tales almacenamientos, como regla, representan una enorme tabla persistente de clave-valor. Posibles operaciones: set , get , del . Sin embargo, se requiere una operación más complicada para el enfoque sin bloqueo: CAS o compare-and-swap. Consideremos con más detalle esta operación, las posibilidades de su uso, así como los resultados que ofrece.
Cas
CAS o compare-and-swap es la primitiva de sincronización principal e importante para algoritmos sin bloqueo y sin espera. Su esencia puede ilustrarse con el siguiente Pseco:
CAS(var, expected, new): # , atomic, atomic: if var.get() != expected: return false var.set(new) return true
A veces, para la optimización, devuelven no true o false , sino el valor anterior, porque muy a menudo, tales operaciones se realizan en un bucle, y para obtener el valor expected , primero debe leerlo:
CAS_optimized(var, expected, new): # , atomic, atomic: current = var.get() if current == expected: var.set(new) return current # CAS CAS_optimized CAS(var, expected, new): return var.CAS_optimized(expected, new) == expected
Este enfoque puede ahorrar una lectura. Como parte de nuestra revisión, utilizaremos una forma simple de CAS , porque si se desea, dicha optimización se puede hacer de forma independiente.
En el caso de los sistemas distribuidos, cada cambio se versiona. Es decir Primero leemos el valor de la tienda, obteniendo la versión actual de los datos. Y luego tratamos de escribir, esperando que la versión de los datos no haya cambiado. En este caso, la versión se incrementa cada vez que se actualizan los datos:
CAS_versioned(var, expected_version, new): atomic: if var.get_version() != expected_version: return false var.set(new, expected_version + 1) return true
Este enfoque le permite controlar con mayor precisión la actualización de valores, evitando el problema ABA . En particular, las versiones son compatibles con Etcd y Zookeeper.
Tenga en cuenta la importante propiedad que otorga el uso de operaciones CAS_versioned . El hecho es que tal operación puede repetirse sin perjuicio de la lógica superior. En la programación multiproceso, esta propiedad no tiene un valor especial, porque allí, si la operación falló, entonces sabemos con certeza que no se aplicó. En el caso de los sistemas distribuidos, esta invariante se viola, porque la solicitud puede llegar al destinatario, pero la respuesta exitosa ya no está allí. Por lo tanto, es importante poder reenviar solicitudes sin temor a romper invariantes de la lógica de alto nivel.
Es esta propiedad la que CAS_versioned operación CAS_versioned . De hecho, esta operación se puede repetir sin cesar hasta que se devuelva la respuesta real del destinatario. Lo que, a su vez, arroja toda una clase de errores relacionados con la interacción de la red.
Ejemplo
Veamos cómo, en base a CAS_versioned y medias transacciones, transferir de una cuenta a otra, que pertenecen, por ejemplo, a diferentes copias de Etcd. Aquí, supongo que la función CAS_versioned ya CAS_versioned implementada de acuerdo con la API proporcionada.
withdraw(from, amount): # CAS- while true: # version_from, amount_from = from.get_versioned() if amount_from < amount: return error.insufficient_funds if from.CAS_versioned(version_from, amount_from - amount): break return ok deposit(to, amount): # CAS- while true: version_to, amount_to = to.get_versioned() if to.CAS_versioned(version_to, amount_to + amount): break return ok transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
Aquí dividimos nuestra operación en medias transacciones, y realizamos cada media transacción a través de la operación CAS_versioned . Este enfoque le permite trabajar de forma independiente con cada cuenta, lo que permite el uso de almacenamiento heterogéneo que no está conectado entre sí. El único problema que nos espera aquí es la pérdida de dinero en caso de una caída en el proceso actual en el intervalo entre las medias transacciones.
Cola
Para continuar, debe implementar una cola de eventos. La idea es que para que los manejadores se comuniquen entre sí, debe tener una cola de mensajes ordenada en la que los datos no se pierdan ni se dupliquen. En consecuencia, toda interacción en la cadena de controladores se construirá sobre esta primitiva. También es una herramienta útil para analizar y auditar flujos de datos entrantes y salientes. Además de esto, las mutaciones del estado de los manejadores también se pueden hacer a través de la cola.
La cola consistirá en un par de operaciones:
- Agregue un mensaje al final de la cola.
- Recibir un mensaje de la cola en el índice especificado.
En este contexto, no considero eliminar mensajes de la cola por varias razones:
- Varios procesadores pueden leer desde la misma cola. Eliminar la sincronización será una tarea no trivial, aunque no imposible.
- Es útil mantener una cola durante un intervalo relativamente largo (día o semana) para la depuración y la auditoría. La utilidad de esta propiedad es difícil de sobreestimar.
- Puede eliminar elementos antiguos según lo programado o configurando TTL en los elementos de la cola. Es importante asegurarse de que los procesadores logren procesar los datos antes de que llegue la escoba y limpien todo. Si el tiempo de procesamiento es del orden de segundos y el TTL del orden de días, entonces nada de esto debería suceder.
Para almacenar los elementos e implementar efectivamente la adición, necesitamos:
- El valor con el índice actual. Este índice apunta al final de la cola para agregar elementos.
- , .
lock-free
: . :
- CAS .
- .
, , .
- lock-free . , , . Lock-free? ! , 2 : . lock-free, — ! , , , . . , .. , .
- . , . .
, lock-free .
Lock-free
, , : , .. , :
push(queue, value): # index = queue.get_current_index() while true: # , # var = queue.at(index) # = 0 , .. # , if var.CAS_versioned(0, value): # , queue.update_index(index + 1) break # , . index = max(queue.get_current_index(), index + 1) update_index(queue, index): while true: # cur_index, version = queue.get_current_index_versioned() # , # , . if cur_index >= index: # - , # break if queue.current_index_var().CAS_versioned(version, index): # , break # - . # , ,
. , ( — , , ). lock-free . ?
, push , ! , , .
. : . , - , - . , , .. . . ? , .. , , .
, , . Es decir . , , . , .
, . , . , , . , .
, , , .
. .
, :
- , .. stateless.
- , — .
, , concurrent exactly-once .
:
handle(input, output): index = 0 while true: value = input.get(index) output.push(value) index += 1
. :
handle(input, output, state): # index = state.get() while true: value = input.get(index) output.push(value) index += 1 # state.set(index)
exactly-once . , , , .
exactly-once , , . .., , , , , — :
# get_next_index(queue): index = queue.get_index() # while queue.has(index): # queue.push index = max(index + 1, queue.get_index()) return index # . # true push_at(queue, value, index): var = queue.at(index) if var.CAS_versioned(0, value): # queue.update_index(index + 1) return true return false handle(input, output, state): # # {PREPARING, 0} fsm_state = state.get() while true: switch fsm_state: case {PREPARING, input_index}: # : , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) if output.push_at(value, output_index): # , input_index += 1 # , push_at false, # fsm_state = {PREPARING, input_index} state.set(fsm_state)
push_at ? , . , , , . , . . - , lock-free .
, :
- : .
- , : .
: concurrent exactly-once .
? :
- , ,
push_at false. . - , . , , .
concurrent exactly-once ? , , . , . .
:
# , , # .. true, # true. # false push_at_idempotent(queue, value, index): return queue.push_at(value, index) or queue.get(index) == value handle(input, output, state): version, fsm_state = state.get_versioned() while true: switch fsm_state: case {PREPARING, input_index}: # , , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) # , # if output.push_at_idempotent(value, output_index): input_index += 1 fsm_state = {PREPARING, input_index} # if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

, . , .
kernel panic, , .. . . : , . , .
, , .
: .
: , , , , :
# : # - input_queues - # - output_queues - # - state - # - handler - : state, inputs -> state, outputs handle(input_queues, output_queues, state, handler): # version, fsm_state = state.get_versioned() while true: switch fsm_state: # input_indexes case {HANDLING, user_state, input_indexes}: # inputs = [queue.get(index) for queue, index in zip(input_queues, input_indexes)] # , next_indexes = next(inputs, input_indexes) # # user_state, outputs = handler(user_state, inputs) # , # fsm_state = {PREPARING, user_state, next_indexes, outputs, 0} case {PREPARING, user_state, input_indexes, outputs, output_pos}: # , # output_index = output_queues[output_pos].get_next_index() # fsm_state = { WRITING, user_state, input_indexes, outputs, output_pos, output_index } case { WRITING, user_state, input_indexes, outputs, output_pos, output_index }: value = outputs[output_pos] # if output_queues[output_pos].push_at_idempotent( value, output_index ): # , output_pos += 1 # , PREPARING. # # fsm_state = if output_pos == len(outputs): # , # {HANDLING, user_state, input_indexes} else: # # , # {PREPARING, user_state, input_indexes, outputs, output_pos} if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

: HANDLING . , .., , . , . , PREPARING WRITING , . , HANDLING .
, , , . , . , .
. . .

:
my_handler(state, inputs): # state.queue.push(inputs) # duration state.queue.trim_time_window(duration) # avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary return state, [ avg, if need_update_counter: true else: # none none ]
, , concurrent exactly-once handle .
:
handle_db(input_queue, db): while true: # tx = db.begin_transaction() # . # , # index = tx.get_current_index() # tx.write_current_index(index + 1) # value = intput_queue.get(index) if value: # tx.increment_counter() tx.commit() # , , #
. .. , , , , concurrent exactly-once . .
— . , , .
, , . , , .
. , . .. , . . .
— . , , . , - , , . , .. , , .
. , , . , , .
. , . : , . , .
, , :
- , . .
- . , .
- . , . , , . Es decir . : .
, , -, , -, .
, . :
transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
withdraw , , deposit : ? deposit - (, , ), . , , , , ? , , - , .
, , , . , , , . , . , , . .. , , . , : , — .
, .
: , , , , . , - :
, , .
, , .. , , . , .
: lock-free , . , .. , .
CAS . , :
# , handle(input, output, state): # ... while true: switch fsm_state: case {HANDLING, ...}: # fsm_state = {PREPARING, ...} case {PREPARING, input_index}: # ... output_index = ...get_next_index() fsm_state = {WRITING, output_index, ...} case {WRITING, output_index, ...}: # , output_index
, . . :
- PREPARING . , .
- WRITING . . , PREPARING .
, . , , — . :
- . , , .. , .
- , .. . , .
, lock-free , , .
, . , Stale Read , . — CAS: . :
- Distributed single register — (, etcd Zookeeper):
- Linearizability
- Sequential consistency
- Transactional — (, MySQL, PostgreSQL ..):
- Serializability
- Snapshot Isolation
- Repeatable Read
- Read Committed
- Distributed Transactional — NewSQL :
- Strict Consistency
: ? , , . , , CAS . , , Read My Writes .
Conclusión
exactly-once . , .. , , , . , , , , .. , .
lock-free .
:
- : .
- : .
- : : exactly-once .
- Concurrent : .
- Real-time : .
- Lock-free : , .
- Deadlock free : , .
- Race condition free : .
- Hot-hot : .
- Hard stop : .
- No failover : .
- No downtime : .
- : , .
- : .
- : .
- : .
, . Pero esa es otra historia.

:
- Concurrent exactly-once.
- Semi-transactions .
- Lock-free two-phase commit, .
- .
- lock-free .
- .
Literatura
[1] : ABA.
[2] Blog: You Cannot Have Exactly-Once Delivery
[3] : .
[4] : 3: .
[5] : .