(gracias por la idea del título gracias a Sergey G. Brester
sebres )
Colegas, el propósito de este artículo es el deseo de compartir la experiencia de una operación de prueba de un año de una nueva clase de soluciones IDS basadas en tecnologías de engaño.
Para preservar la coherencia lógica de la presentación del material, considero necesario comenzar con las premisas. Entonces, los problemas:
- Los ataques dirigidos son el tipo de ataque más peligroso, a pesar de que su participación en el número total de amenazas es pequeña.
- Todavía no se ha inventado algún tipo de medio efectivo garantizado para proteger el perímetro (o un complejo de tales medios).
- Como regla general, los ataques dirigidos tienen lugar en varias etapas. Superar el perímetro es solo una de las etapas iniciales, que (puede tirarme piedras) no causa mucho daño a la "víctima", a menos que sea, por supuesto, un ataque DEoS (Destrucción del servicio) (encriptadores, etc.). El verdadero "dolor" comienza más tarde, cuando los activos incautados comienzan a usarse para pivotar y desarrollar un ataque "en profundidad", pero no nos dimos cuenta de esto.
- Dado que comenzamos a sufrir pérdidas reales cuando los atacantes alcanzan los objetivos del ataque (servidor de aplicaciones, DBMS, almacenamiento de datos, repositorios, elementos críticos de infraestructura), es lógico que una de las tareas del servicio de IS sea interrumpir los ataques antes de este triste evento. Pero para interrumpir algo, primero debes averiguarlo. Y cuanto antes mejor.
- En consecuencia, para una gestión de riesgos exitosa (es decir, para reducir el daño de los ataques dirigidos), es fundamental contar con herramientas que proporcionen un TTD mínimo (tiempo de detección, el tiempo desde el momento de la invasión hasta el momento en que se detecta el ataque). Dependiendo de la industria y la región, este período promedia 99 días en los EE. UU., 106 días en la región EMEA, 172 días en la región APAC (M-Trends 2017, A View From the Front Lines, Mandiant).
- ¿Qué ofrece el mercado?
- Cajones de arena. Otro control preventivo que está lejos de ser ideal. Existen toneladas de técnicas efectivas para detectar y eludir los entornos limitados o las soluciones de listas blancas. Los chicos del "lado oscuro" todavía están un paso por delante.
- UEBA (perfiles de comportamiento y sistemas de detección de desviaciones): en teoría, puede ser muy efectivo. Pero, en mi opinión, esto es en algún momento en un futuro lejano. En la práctica, sigue siendo muy costoso, poco confiable y requiere una infraestructura de TI y seguridad de la información muy madura y estable, que ya tiene todas las herramientas que generarán datos para el análisis del comportamiento.
- SIEM es una buena herramienta para investigaciones, pero no puede ver y mostrar algo a tiempo, porque las reglas de correlación son las mismas firmas.
- Como resultado, la necesidad ha madurado para tal instrumento que:
- trabajado con éxito en condiciones de perímetro ya comprometido,
- detectó ataques exitosos en modo casi en tiempo real, independientemente de las herramientas y las vulnerabilidades que se utilizan,
- no depende de firmas / reglas / scripts / políticas / perfiles y otras cosas estáticas,
- no requirió la disponibilidad de grandes cantidades de datos y sus fuentes para el análisis,
- Nos permitiría definir ataques no como una especie de puntuación de riesgo como resultado del trabajo de "las mejores matemáticas del mundo, patentadas y por lo tanto cerradas", lo que requiere investigación adicional, pero prácticamente como un evento binario: "Sí, nos atacan" o "No, todo está bien",
- Era universal, efectivamente escalable y realmente implementado en cualquier entorno heterogéneo, independientemente de la topología de red física y lógica utilizada.
Las llamadas soluciones de engaño ahora reclaman el papel de dicha herramienta. Es decir, soluciones basadas en el viejo concepto de hanipot, pero con un nivel de implementación completamente diferente. Este tema ahora está claramente en aumento.
De acuerdo con los resultados de la
cumbre de gestión de Gartner Security & Risc 2017, las soluciones de engaño se incluyen en las estrategias y herramientas TOP 3 que se recomienda aplicar.
De acuerdo con el informe
anual de engaño
2017 de TAG sobre ciberseguridad , el engaño es una de las principales líneas de desarrollo de soluciones de sistemas de detección de intrusiones IDS.
La sección completa del último
Informe de estado de seguridad de TI de Cisco en SCADA se basa en los datos de uno de los líderes del mercado TrapX Security (Israel), cuya solución ha estado trabajando en nuestra zona de prueba durante un año.
TrapX Deception Grid le permite costear y operar un IDS distribuido masivo centralmente, sin aumentar la carga de licencias y los requisitos de hardware. De hecho, TrapX es un constructor que le permite crear a partir de los elementos de la infraestructura de TI existente un gran mecanismo para detectar ataques de toda la escala empresarial, una especie de "señalización" de red distribuida.
Estructura de la solución
En nuestro laboratorio, estudiamos y probamos constantemente diversas innovaciones en el campo de la seguridad de TI. Ahora se implementan aquí cerca de 50 servidores virtuales diferentes, incluidos los componentes TrapX Deception Grid.
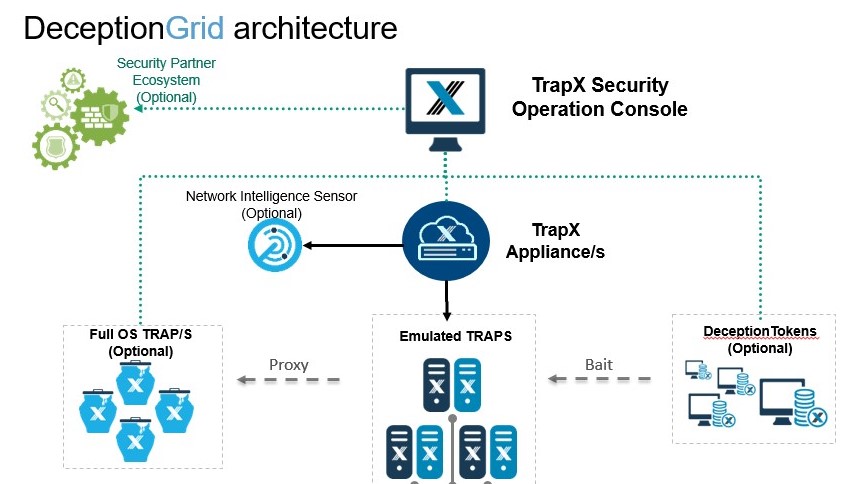
Entonces, de arriba a abajo:
- TSOC (TrapX Security Operation Console): el cerebro del sistema. Esta es la consola de administración central con la que puede configurar, implementar la solución y todo el trabajo diario. Como se trata de un servicio web, se puede implementar en cualquier lugar: en el perímetro, en la nube o en el proveedor de MSSP.
- TrapX Appliance (TSA) es un servidor virtual en el que utilizamos el puerto troncal para conectar las subredes que queremos monitorear. Además, todos nuestros sensores de red realmente "viven" aquí.
Hay un TSA (mwsapp1) implementado en nuestro laboratorio, pero en realidad puede haber muchos. Esto puede ser necesario en redes grandes donde no hay conectividad L2 entre segmentos (un ejemplo típico es "Holding y subsidiarias" o "Oficinas centrales y sucursales bancarias") o si hay segmentos aislados en la red, por ejemplo, sistemas de control de procesos. En cada sucursal / segmento, puede implementar su TSA y conectarlo a un único TSOC, donde toda la información se procesará centralmente. Esta arquitectura le permite construir sistemas de monitoreo distribuido sin la necesidad de una reestructuración fundamental de la red o romper la segmentación existente.
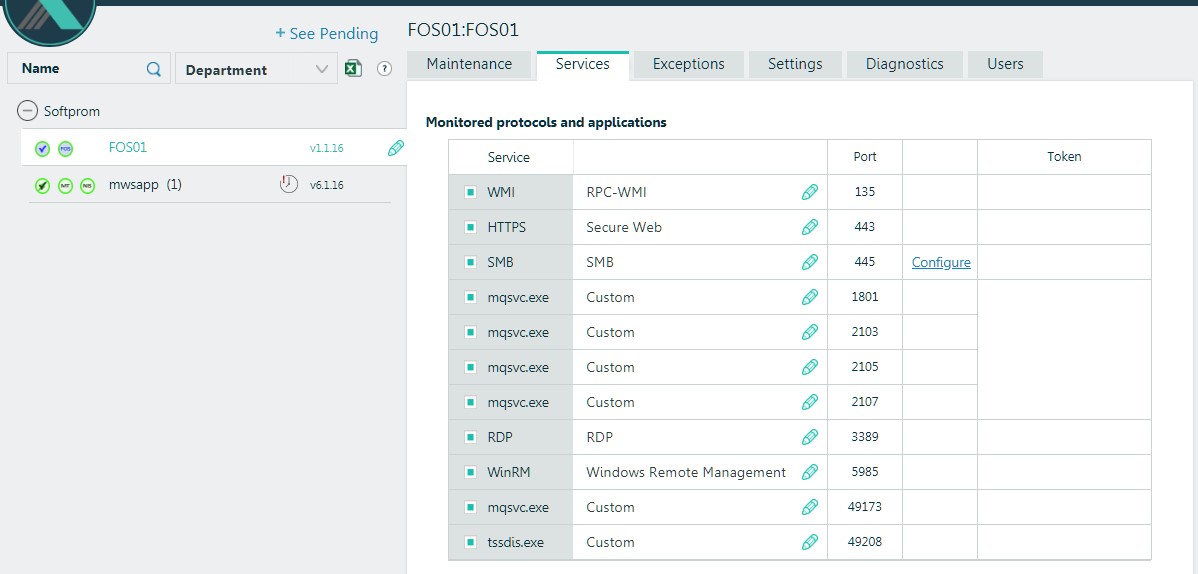
Además, en TSA podemos enviar una copia del tráfico saliente a través de TAP / SPAN. En caso de detección de conexiones con botnets conocidas, servidores de comando, sesiones TOR, también obtendremos el resultado en la consola. El sensor de inteligencia de red (NIS) es responsable de esto. En nuestro entorno, esta funcionalidad se implementa en el firewall, por lo que no la usamos aquí. - Trampas de aplicación (sistema operativo completo): identificadores de servidor tradicionales basados en Windows. No requieren mucho, ya que la tarea principal de estos servidores es proporcionar servicios de TI al siguiente nivel de sensores o identificar ataques a aplicaciones comerciales que se pueden implementar en un entorno Windows. Tenemos uno de esos servidores instalado en el laboratorio (FOS01)
- Trampas emuladas: el componente principal de la solución, que nos permite crear un campo "minero" muy denso para los atacantes con una sola máquina virtual y saturar la red empresarial, todas sus vlan-s, con nuestros sensores. El atacante ve dicho sensor, o un host fantasma, como una PC o servidor Windows real, un servidor Linux u otro dispositivo que decidamos mostrar.
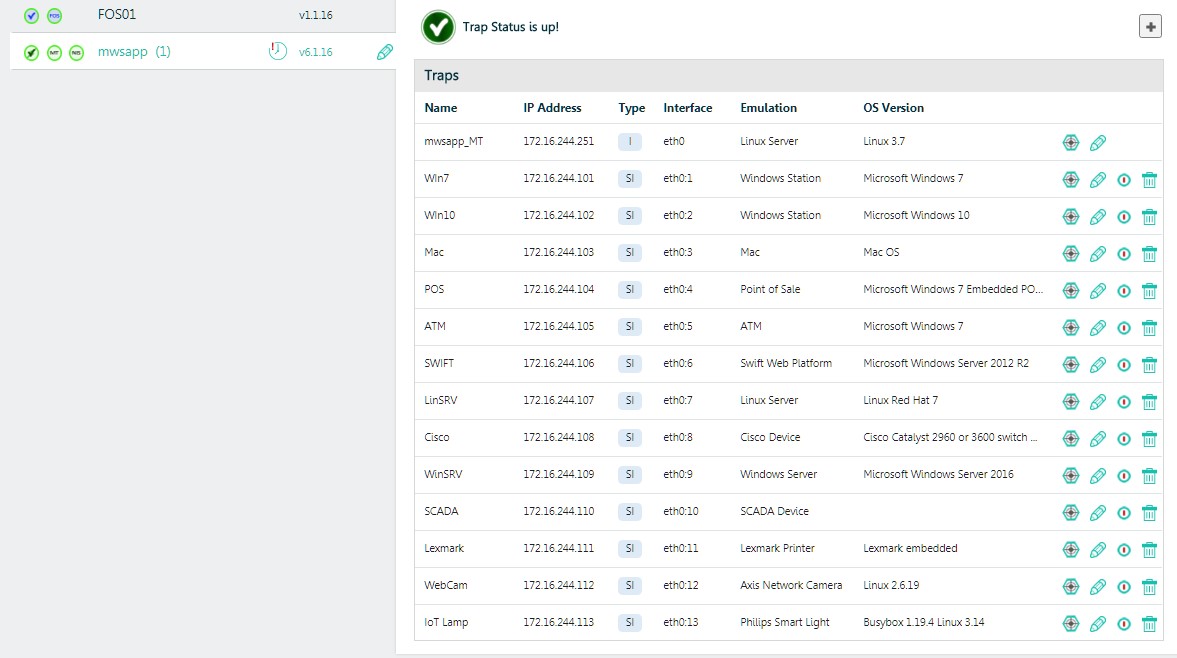
En aras de los negocios y la curiosidad, implementamos "todas las criaturas en pares": PC con Windows y servidores de varias versiones, servidores Linux, cajeros automáticos con Windows incorporado, SWIFT Web Access, impresora de red, conmutador Cisco, cámara IP Axis, MacBook, PLC -dispositivo e incluso una bombilla inteligente. En total - 13 anfitriones. En general, el proveedor recomienda implementar dichos sensores en una cantidad de al menos el 10% del número de hosts reales. La barra superior es el espacio de direcciones disponible.
Un punto muy importante es que cada host no es una máquina virtual completa que requiere recursos y licencias. Este es un inconveniente, emulación, un proceso en la TSA, que tiene un conjunto de parámetros y una dirección IP. Por lo tanto, con la ayuda de incluso un TSA, podemos saturar la red con cientos de hosts fantasmas que actuarán como sensores en el sistema de alarma. Es esta tecnología la que le permite escalar económicamente de manera efectiva el concepto de "Hanipot" en la escala de cualquier gran empresa distribuida.
Desde el punto de vista del lado atacante, estos hosts son atractivos porque contienen vulnerabilidades y parecen objetivos relativamente fáciles. El atacante ve los servicios en estos hosts y puede interactuar con ellos, atacarlos utilizando herramientas y protocolos estándar (smb / wmi / ssh / telnet / web / dnp / bonjour / Modbus, etc.). Pero usar estos hosts para desarrollar un ataque y lanzar su código es imposible.
- La combinación de estas dos tecnologías (FullOS y trampas emuladas) nos permite lograr una alta probabilidad estadística de que un atacante tarde o temprano encuentre algún elemento de nuestra red de señales. Pero, ¿cómo hacer que esta probabilidad sea cercana al 100%?
Las llamadas fichas (fichas de engaño) entran en la batalla. Gracias a ellos, podemos incluir en nuestros IDS distribuidos todas las PC y servidores empresariales disponibles. Los tokens se colocan en usuarios reales de PC. Es importante comprender que los tokens no son un agente que consume recursos y puede causar conflictos. Las fichas son elementos de información pasiva, una especie de "migas de pan" para el lado atacante, que lo llevan a una trampa. Por ejemplo, unidades de red mapeadas, marcadores para administradores web falsos en el navegador y contraseñas guardadas para ellos, sesiones ssh / rdp / winscp guardadas, nuestras trampas con comentarios en archivos de hosts, contraseñas almacenadas en la memoria, credenciales de usuarios inexistentes, archivos de oficina, apertura que activará el sistema y mucho más. Por lo tanto, colocamos al atacante en un entorno distorsionado saturado de esos vectores de ataque que en realidad no representan una amenaza para nosotros, sino todo lo contrario. Y no tiene forma de determinar dónde está la información verdadera y dónde es falsa. Por lo tanto, no solo proporcionamos una definición rápida de un ataque, sino que también disminuimos significativamente su progreso.
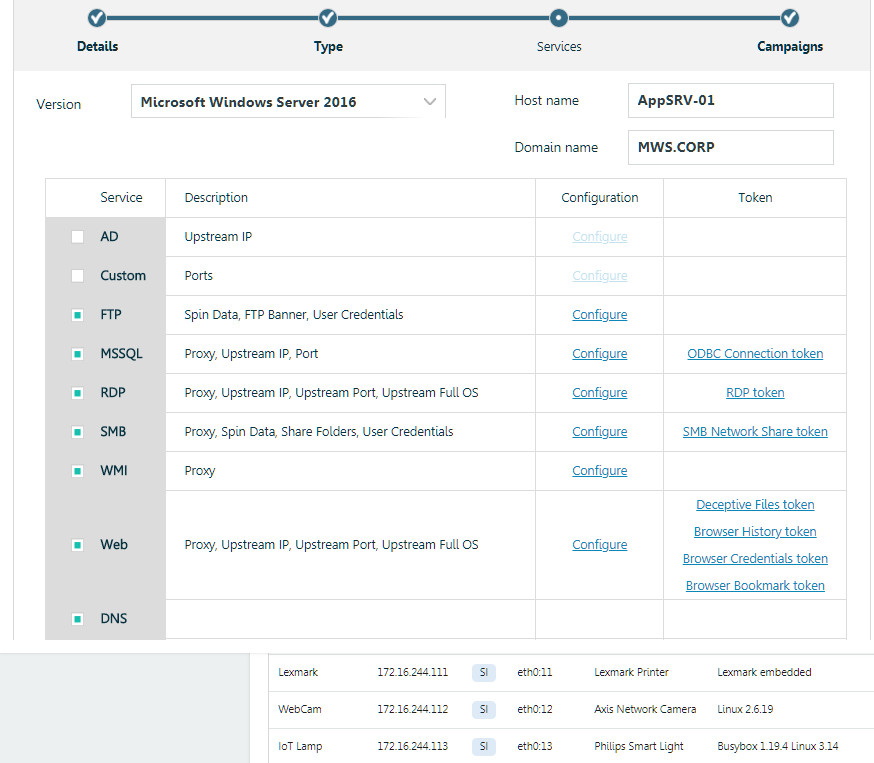 Un ejemplo de cómo crear una trampa de red y establecer tokens. Interfaz amigable y edición manual de configuraciones, scripts, etc.
Un ejemplo de cómo crear una trampa de red y establecer tokens. Interfaz amigable y edición manual de configuraciones, scripts, etc.En nuestro entorno, configuramos y colocamos una cantidad de tales tokens en FOS01 con Windows Server 2012R2 y una PC de prueba con Windows 7. Estas máquinas ejecutan RDP y las publicamos periódicamente en la DMZ, que también muestra una serie de sensores (trampas emuladas). Por lo tanto, obtenemos un flujo constante de incidentes, por así decirlo, de forma natural.
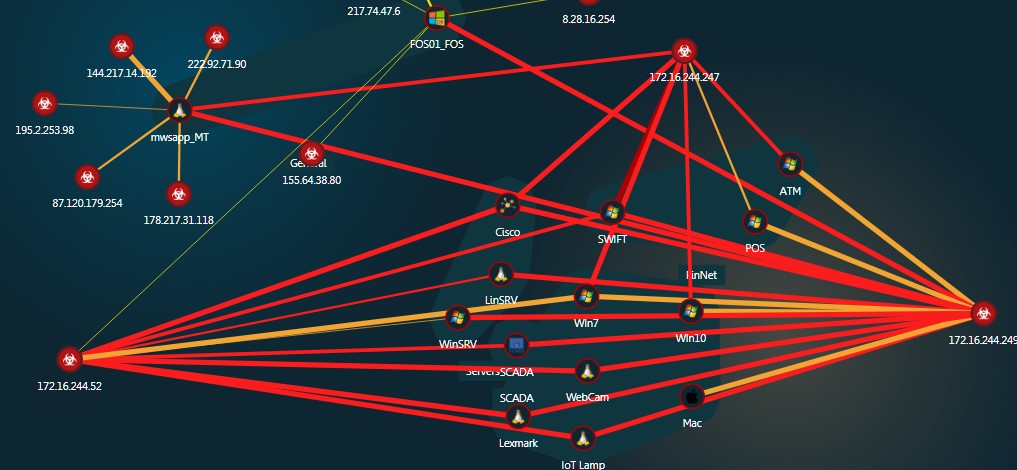
Entonces, una breve estadística para el año:
56208 - incidentes registrados
2 912 - hosts de origen de ataque detectados.
Mapa interactivo de ataque en el que se puede hacer clicAl mismo tiempo, la solución no genera ningún mega-registro o fuente de eventos, en los que lleva mucho tiempo entender. En cambio, la solución en sí clasifica los eventos por sus tipos y permite que el equipo de IS se centre principalmente en los más peligrosos, cuando la parte atacante intenta aumentar las sesiones de control (interacción) o cuando aparecen cargas binarias (infección) en nuestro tráfico.
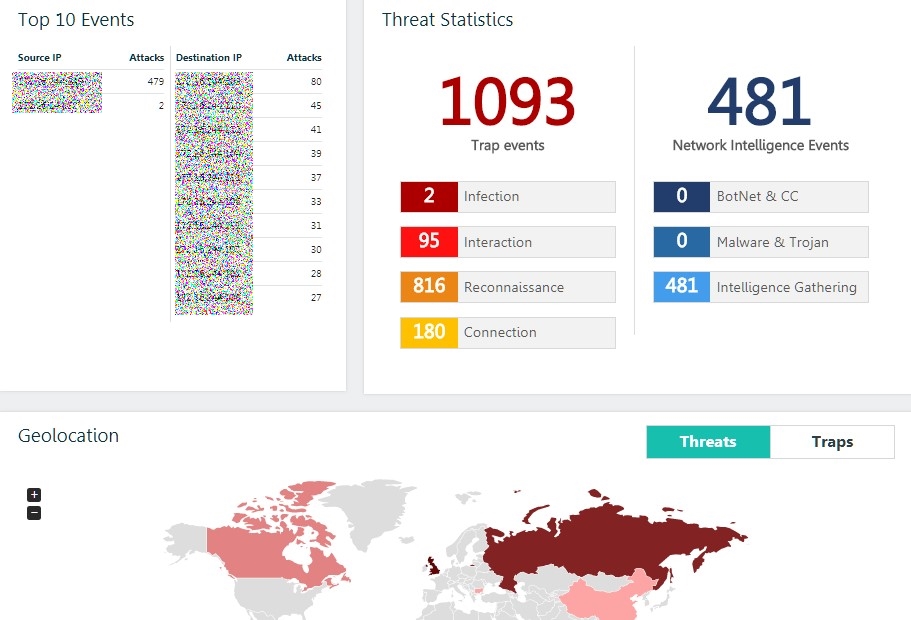
Toda la información sobre los eventos es legible y presentada, en mi opinión, en una forma fácil de entender incluso para un usuario con conocimientos básicos en el campo de la seguridad de la información.
La mayoría de los incidentes reportados son intentos de escanear nuestros hosts o conexiones individuales.
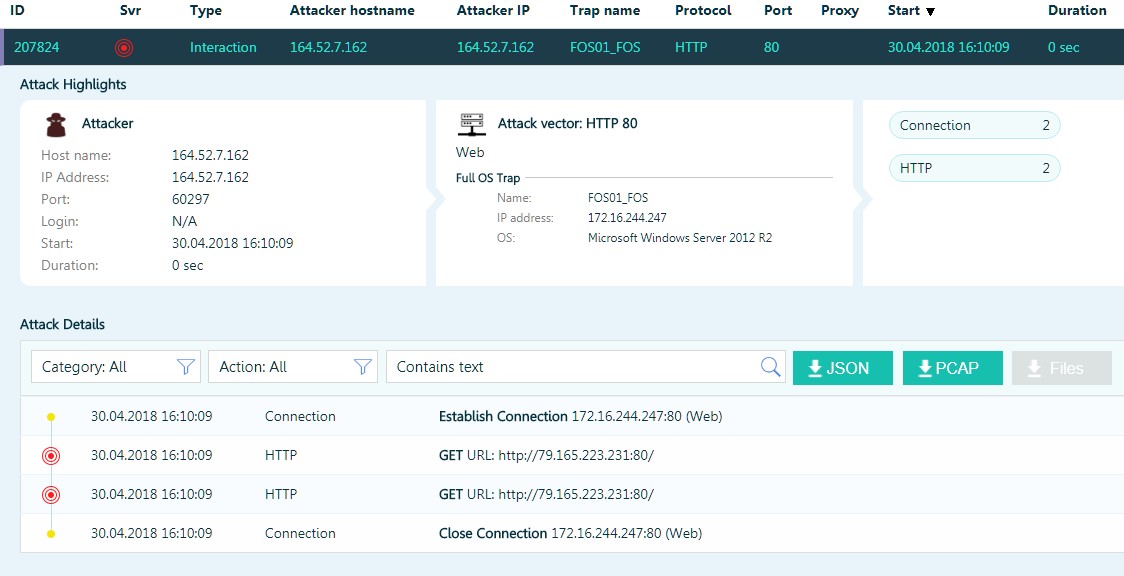
O intentos de adivinar contraseñas para RDP
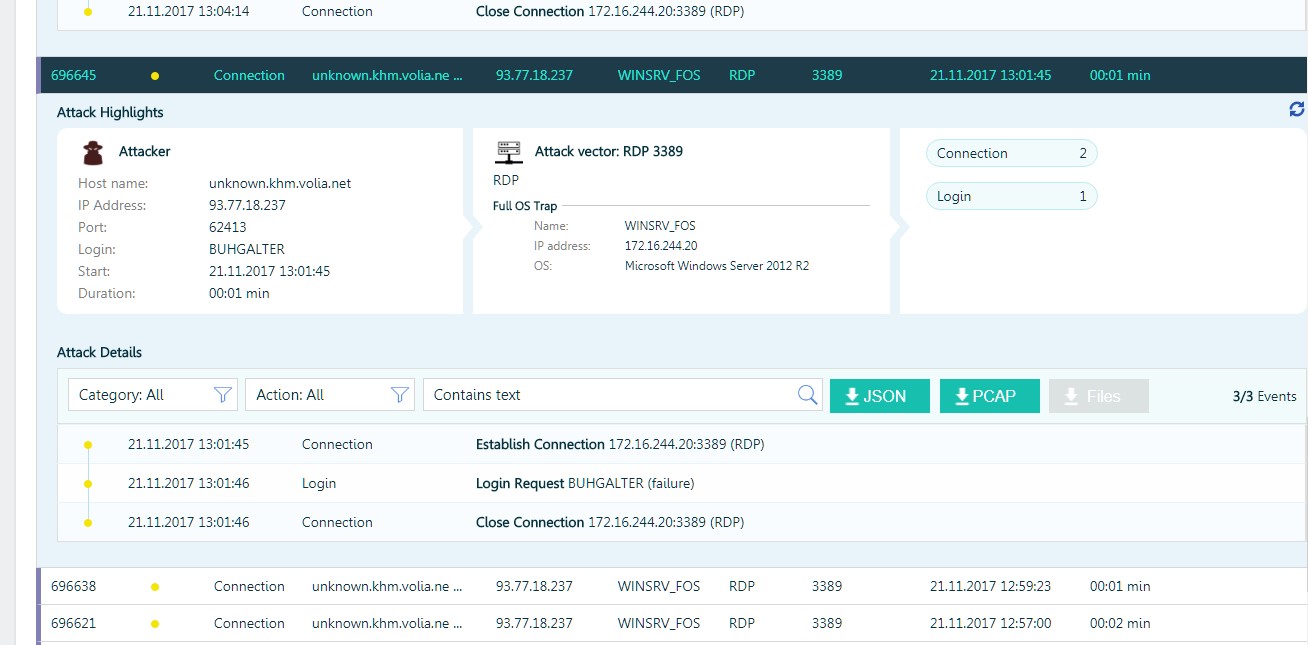
Pero hubo casos más interesantes, especialmente cuando los atacantes "lograron" obtener una contraseña para RDP y obtener acceso a la red local.
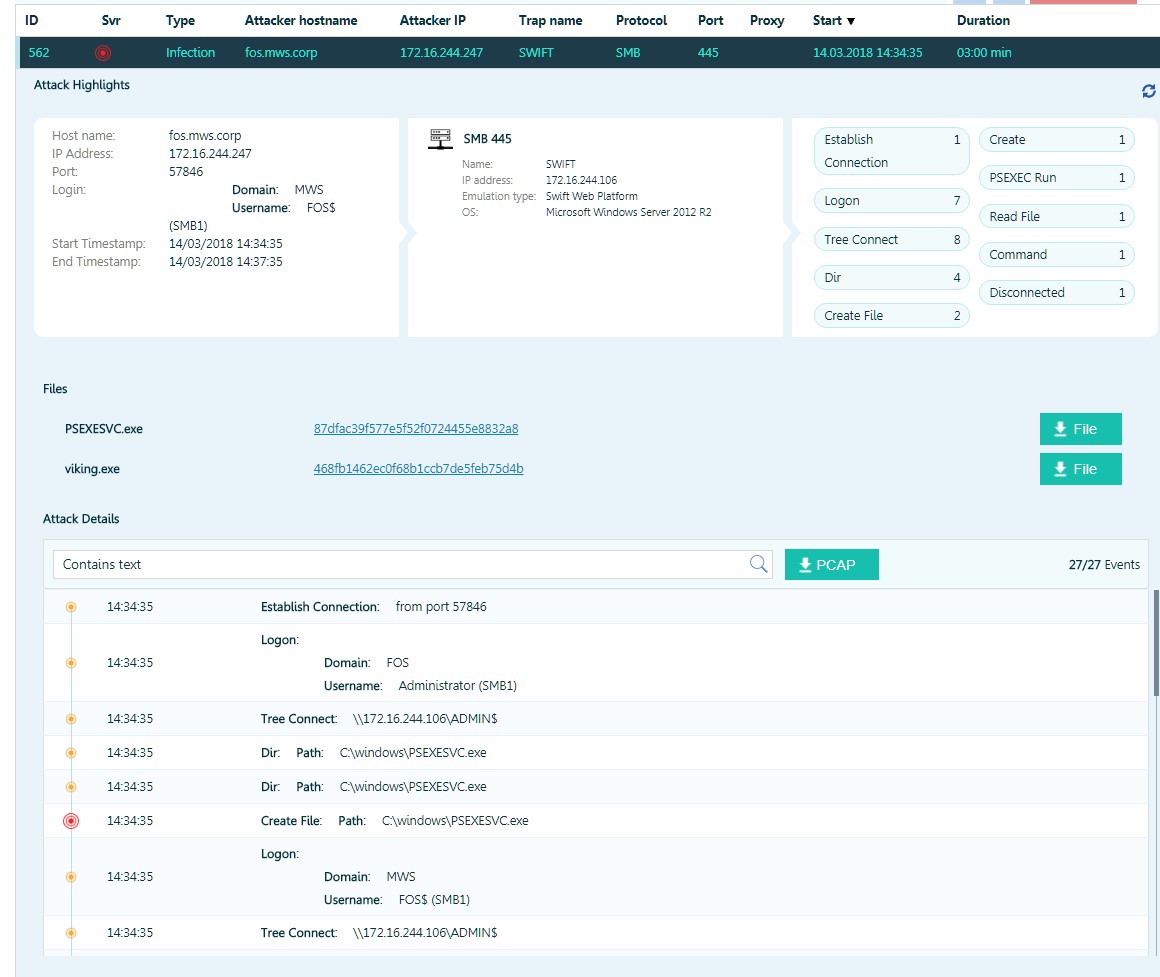
Un atacante está intentando ejecutar código usando psexec.
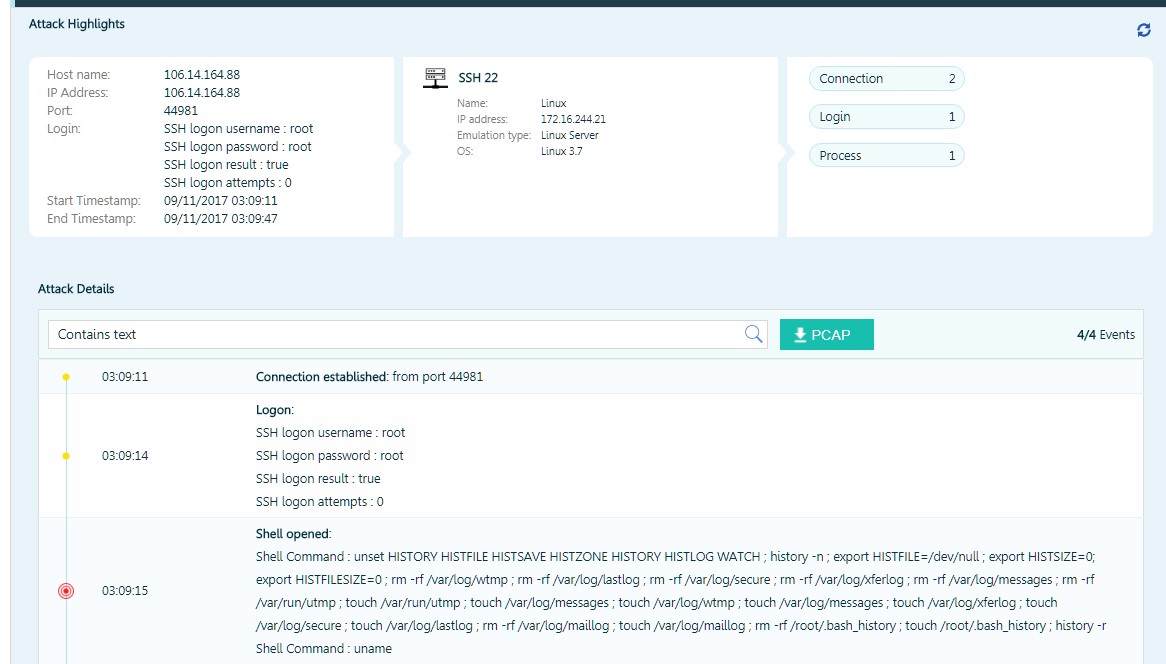
El atacante encontró una sesión guardada que lo atrapó como un servidor Linux. Inmediatamente después de conectarse con un conjunto predefinido de comandos, intentó destruir todos los archivos de registro y las correspondientes variables del sistema.
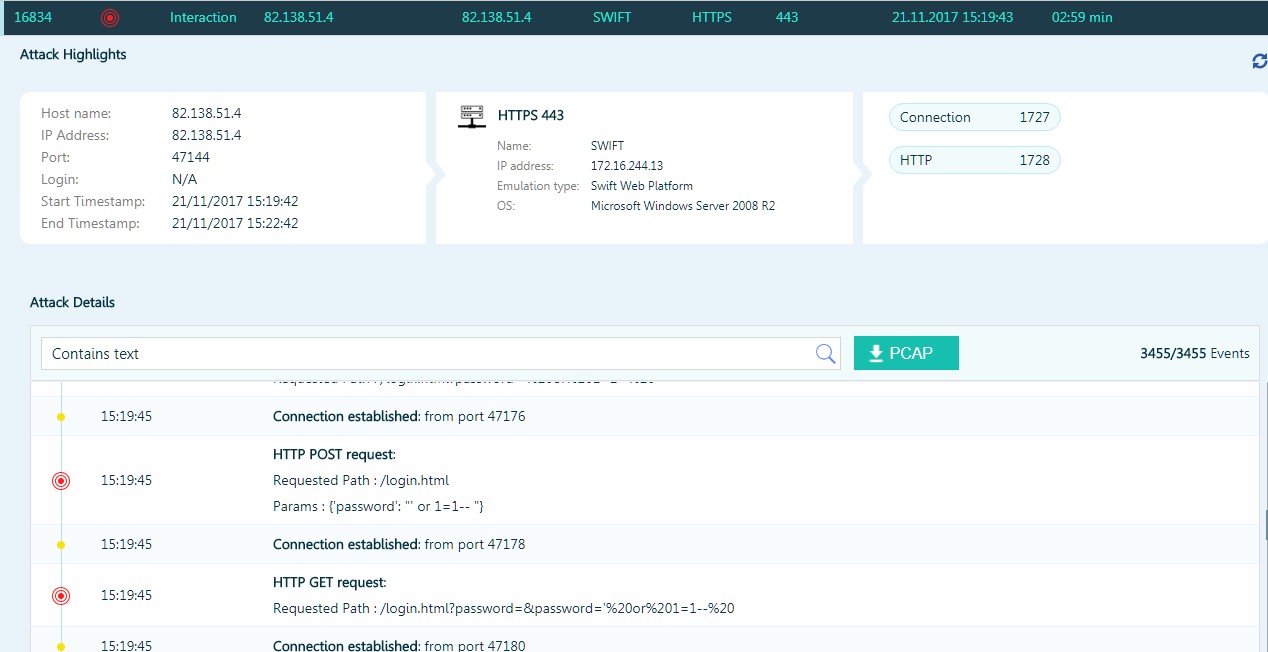
El atacante intenta inyectar SQL en una trampa que imita SWIFT Web Access.
Además de tales ataques "naturales", realizamos una serie de nuestras propias pruebas. Uno de los más indicativos es probar el tiempo de detección de un gusano de red en una red. Para hacer esto, utilizamos una herramienta de GuardiCore llamada
Infection Monkey . Este es un gusano de red que puede capturar Windows y Linux, pero sin algún tipo de "carga útil".
Implementamos un centro de comando local, lanzamos la primera instancia de gusano en una de las máquinas y recibimos la primera notificación en la consola TrapX en menos de un minuto y medio. TTD 90 segundos versus 106 días en promedio ...
Gracias a la capacidad de integrarse con otras clases de soluciones, solo podemos pasar de la detección rápida de amenazas a la respuesta automática a ellas.
Por ejemplo, la integración con los sistemas NAC (Control de acceso a la red) o con CarbonBlack desconectará automáticamente las PC comprometidas de la red.
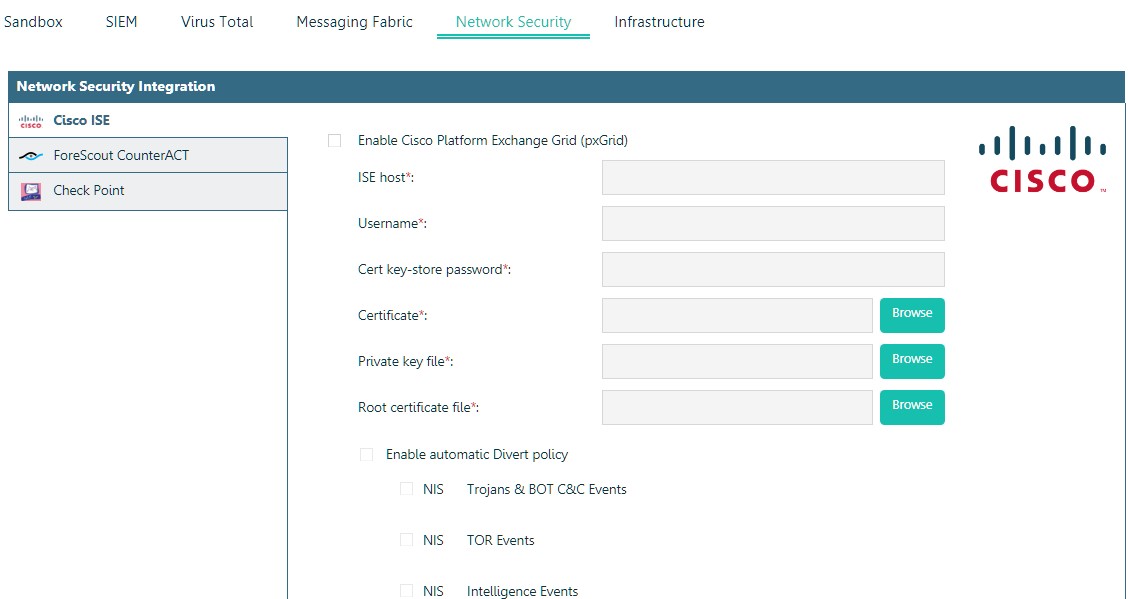
La integración con sandboxes le permite transferir automáticamente archivos involucrados en el ataque para su análisis.
Integración de McAfee
La solución también tiene su propio sistema de correlación de eventos incorporado.
Pero sus capacidades no nos convenían, así que lo integramos con HP ArcSight.
El sistema de tickets integrado ayuda a hacer frente a las amenazas detectadas "en todo el mundo".
Dado que la solución "desde el principio" se desarrolló para las necesidades de las agencias gubernamentales y un gran segmento corporativo, entonces, por supuesto, se implementa allí un modelo de acceso basado en roles, integración con AD, un sistema desarrollado de informes y disparadores (alertas de eventos), orquestación para grandes estructuras de retención o proveedores de MSSP.
En lugar de un curriculum vitae
Si hay un sistema de monitoreo similar que, en sentido figurado, cubre nuestra espalda, entonces, con el compromiso del perímetro, todo acaba de comenzar. Lo más importante es que existe una oportunidad real de lidiar con incidentes de seguridad de la información y no lidiar con sus consecuencias.