La primera parte, "Evaluación de Cavium ThunderX2: El sueño de un servidor Arm hecho realidad" está
aquíConfiguración de prueba y metodología
Para la revisión de ThunderX2, todas nuestras pruebas se llevaron a cabo en Ubuntu Server 17.10, Linux 4.13 kernel de 64 bits. Usualmente usamos la versión LTS, pero como Cavium viene con esta versión particular de Ubuntu, no nos arriesgamos a cambiar el sistema operativo. La distribución de Ubuntu incluye el compilador GCC 7.2.

Notará que la cantidad de DRAM varía en las configuraciones de nuestro servidor. La razón es simple: Intel tiene 6 canales de memoria y el ThunderX2 de Cavium tiene 8 canales de memoria.
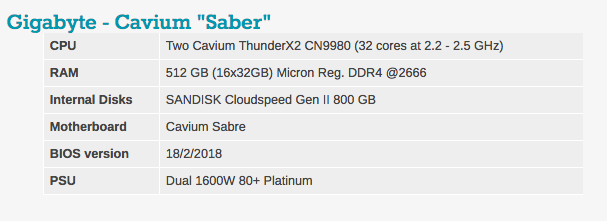
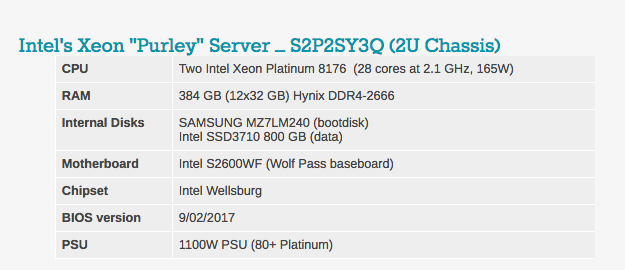
La configuración típica del BIOS se puede ver a continuación. Vale la pena señalar que se incluyen hyperthreading y la tecnología de virtualización Intel.
Otras notasAmbos servidores funcionan de acuerdo con el estándar europeo: 230 V (máximo 16 amperios). La temperatura del aire interior es controlada y mantenida a 23 ° C por nuestros instrumentos Airwell CRAC.
Consumo de energia
Vale la pena mencionar que el sistema Gigabyte "Sabre" consumía 500 vatios si solo estaba ejecutando Linux (es decir, estaba inactivo). Sin embargo, bajo carga, el sistema consume aproximadamente 800 W, lo que en principio cumplió con nuestras expectativas, ya que tenemos dos chips TDP de 180 W en el interior. Como suele ser el caso con los primeros sistemas de prueba, no podemos hacer comparaciones de potencia precisas.
De hecho, Cavium afirma que los sistemas actuales de HP, Gigabyte y otros serán mucho más eficientes. El sistema de prueba Sabre que se utilizó tenía varios problemas con la administración de energía: control incorrecto del firmware del ventilador, error de BMC y unidad de fuente de alimentación con demasiada potencia (1600 W).
Subsistema de memoria: ancho de banda
El uso del benchmark de ancho de banda Stream de John McCalpin en los últimos procesadores se está volviendo cada vez más difícil de medir todo el potencial del ancho de banda del sistema a medida que crece el número de canales centrales y de memoria. Como puede ver en los resultados a continuación, estimar el rendimiento no es fácil. El resultado depende en gran medida de la configuración seleccionada.

Teóricamente, ThunderX2 tiene un 33% más de ancho de banda que Intel Xeon, ya que el SoC tiene 8 canales de memoria en comparación con seis canales de Intel. Estos números de alto rendimiento solo se logran en condiciones muy específicas y requieren algunos ajustes para evitar el uso de memoria remota. En particular, debemos asegurarnos de que los flujos no se transporten de un zócalo a otro.
Para empezar, tratamos de lograr los mejores resultados en ambas arquitecturas. En el caso de Intel, el compilador ICC siempre ha arrojado mejores resultados con algunas optimizaciones de bajo nivel dentro de los bucles de transmisión. En el caso del Cavium, seguimos las instrucciones del Cavium. En términos generales, la imagen resultante es una idea del ancho de banda que estos procesadores pueden alcanzar en sus picos. Para ser honesto con Intel, con la configuración ideal (AVX-512) puede alcanzar 200 GB / s.
Sin embargo, es obvio que el sistema ThunderX2 puede proporcionar de 15 a 28% más de ancho de banda a sus núcleos de procesador. El resultado es 235 GB / s, o aproximadamente 120 GB / s por ranura. Esto, a su vez, es aproximadamente 3 veces más grande que el ThunderX original.
Subsistema de memoria: retraso
Aunque las mediciones de ancho de banda se aplican solo a una pequeña parte del mercado de servidores, casi todas las aplicaciones dependen en gran medida de la latencia del subsistema de memoria. En los intentos de medir la latencia de caché y memoria, utilizamos LMBench. Los datos que queremos ver como resultado son "Retraso en carga aleatoria, paso = 16 bytes". Tenga en cuenta que expresamos la latencia L3 y el retraso del tiempo DRAM en nanosegundos, ya que no tenemos valores exactos de reloj de caché L3.
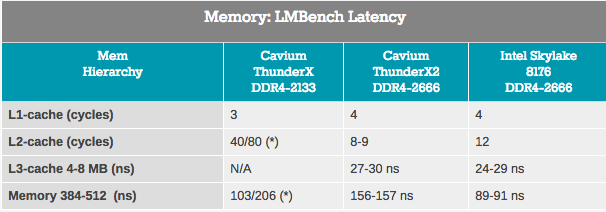
Se accede a la caché ThunderX2 L2 con una latencia muy baja, y cuando se usa una sola transmisión, la caché L3 se parece a un competidor de la caché L3 integrada de Intel. Sin embargo, cuando llegamos a DRAM, Intel mostró una latencia significativamente menor.
Subsistema de memoria: TinyMemBench
Para obtener una comprensión más profunda de las arquitecturas respectivas, se utilizó la prueba de código abierto TinyMemBench. El código fuente se compiló con GCC 7.2 y el nivel de optimización se estableció en -O3. La estrategia de prueba está bien descrita en el manual de referencia:
El tiempo promedio se mide para accesos aleatorios de memoria en buffers de varios tamaños. Cuanto más grande es el búfer, mayor es la contribución relativa de los errores de caché TLB, L1 / L2 y accesos DRAM. Todos los números representan el tiempo extra que debe agregarse a la latencia del caché L1 (4 ciclos).
Probamos con una y dos lecturas aleatorias (sin grandes páginas), porque queríamos ver cómo el sistema de memoria manejaba varias solicitudes de lectura.
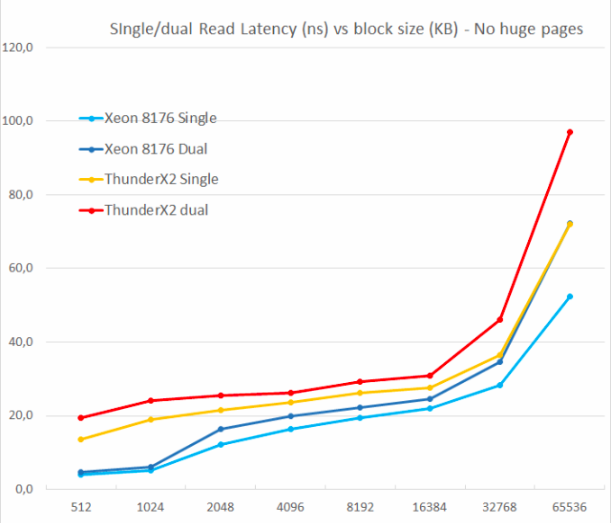
Uno de los principales inconvenientes del ThunderX original fue la incapacidad de soportar múltiples errores pendientes. La concurrencia de nivel de memoria es una característica importante para cualquier núcleo de procesador moderno de alto rendimiento: con su ayuda, evita errores de caché que pueden causar "hambre" de back-end. Por lo tanto, un caché sin bloqueo es una característica clave para núcleos grandes.
ThunderX2 no sufre este problema en absoluto, gracias a su caché sin bloqueo. Al igual que el núcleo de Skylake en Xeon 8176, la segunda lectura aumenta la latencia total solo en un 15-30%, no en un 100%. Según TinyMemBench, el núcleo de Skylake tiene una latencia significativamente mejor. El punto de referencia de 512 KB es fácil de explicar: el núcleo Skylake todavía se está recuperando de su rápido L2, y el núcleo ThunderX2 debe acceder a L3. Pero los números de 1 y 2 MB muestran que los prefetchers de Intel ofrecen una gran ventaja, ya que la latencia es el promedio de caché L2 y L3. Las tasas de latencia son similares en el rango de 8 a 16 MB, pero tan pronto como vamos más allá de L3 (64 MB), Intel's Skylake ofrece memoria de menor latencia.
Rendimiento de un solo subproceso: SPEC CPU2006
Comenzando a medir el rendimiento informático real, comenzamos con el paquete SPEC CPU2006. Los lectores expertos señalarán que SPEC CPU2006 quedó en desuso cuando apareció SPEC CPU2017. Pero debido al tiempo de prueba limitado y al hecho de que no pudimos volver a probar ThunderX, decidimos seguir con CPU2006.
Dado que SPEC es casi tan buen punto de referencia del compilador como el hardware, creemos que será apropiado formular nuestra filosofía de prueba. Debe evaluar los indicadores reales y no inflar los resultados de la prueba. Por lo tanto, es importante crear, en la medida de lo posible, condiciones "como en el mundo real" con las siguientes configuraciones (las críticas constructivas sobre este tema son bienvenidas):
- Gcc de 64 bits: el compilador más utilizado en Linux, un buen compilador que no intenta "interrumpir" las pruebas (libquantum ...)
- -Ofast: optimización del compilador que muchos desarrolladores pueden usar
- -fno-estricto-alias: requerido para compilar algunas subpruebas
- ejecución base: cada subprueba se compila de la misma manera
Primero, debe medir el rendimiento en aplicaciones en las que, por alguna razón, se produce un retraso debido a un "entorno hostil multiproceso". En segundo lugar, debe comprender qué tan bien funciona la arquitectura ThunderX LLC con un solo subproceso en comparación con la arquitectura Skylake de Intel. Tenga en cuenta que en ese modelo Skylake en particular, puede overclockear la frecuencia a 3.8 GHz. El chip funcionará a una frecuencia de 2.8 GHz en casi todas las situaciones (28 subprocesos están activos) y admitirá 3.4 GHz con 14 subprocesos activos.
En general, Cavium posiciona al ThunderX2 CN9980 ($ 1795) como "mejor que 6148" ($ 3072), un procesador que funciona a 2.6 GHz (20 hilos) y alcanza 3.3 GHz sin ningún problema (hasta 16 hilos activos ) Por otro lado, Intel-SKU tendrá una ventaja significativa del 30 por ciento en la velocidad del reloj en muchas situaciones (3.3 GHz versus 2.5 GHz).
Cavium decidió compensar el déficit de frecuencia por el número de núcleos, ofreciendo 32 núcleos, que es un 60% más que el Xeon 6148 (20 núcleos). Vale la pena señalar que una mayor cantidad de núcleos conducirá a una disminución en el rendimiento en muchas aplicaciones (por ejemplo, Amdahl). Por lo tanto, si Cavium quiere sacudir la posición dominante de Intel con ThunderX2, cada núcleo debería ofrecer al menos un rendimiento competitivo en el mundo real. O en este caso, ThunderX2 debería proporcionar al menos un 66% (2.5 frente a 3.8) de rendimiento de Skylake de subproceso único.
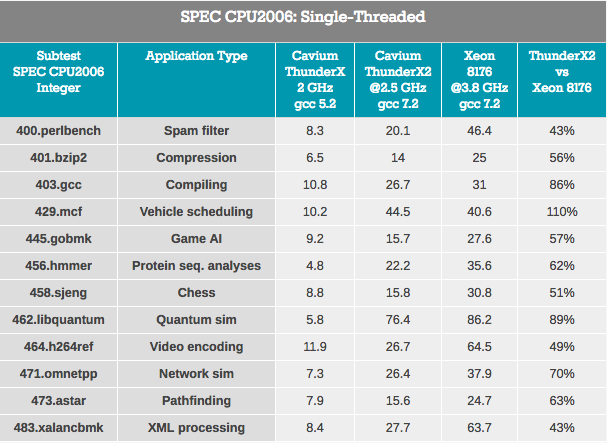
Los resultados son borrosos porque ThunderX2 funciona con el código ARMv8 (AArch64) y Xeon usa el código x86-64.
Pruebas de seguimiento de punteros: el procesamiento XML (también grandes buffers OoO) y la búsqueda de rutas que generalmente dependen de una gran caché L3 para reducir el impacto de la latencia de acceso son los peores para ThunderX2. Se puede suponer que una mayor latencia del sistema DRAM degrada el rendimiento.
Las cargas de trabajo en las que la influencia de la predicción de bifurcación es mayor (al menos en x86-64: un mayor porcentaje de elección de la bifurcación incorrecta) - gobmk, sjeng, hmmer - no son las mejores cargas en ThunderX2.
También vale la pena señalar que se sabe que las instrucciones perlbench, gobmk, hmmer y h264ref se benefician del caché L2 más grande de Skylake (512 KB). Le mostramos algunas piezas del rompecabezas, pero juntas pueden ayudar a armar la imagen.
En el lado positivo, ThunderX2 funcionó bien para gcc, que funciona principalmente dentro del caché L1 y L2 (por lo tanto, depende de una baja latencia L2), y el impacto del rendimiento del predictor de ramificación es mínimo. En general, la mejor prueba para TunderX2 es mcf (distribución de vehículos en transporte público), que, como usted sabe, omite casi por completo el caché de datos L1, confiando en el caché L2, y este es el punto fuerte de ThunderX2. Mcf también exige ancho de banda de memoria. Libquantum es una prueba que tiene la mayor necesidad de ancho de banda de memoria. El hecho de que Skylake ofrezca un ancho de banda bastante simple mediocre es probablemente también la razón por la que ThunderX2 funcionó tan bien en libquantum y mcf.
SPEC CPU2006 Cont: rendimiento basado en el núcleo con SMT
Más allá del rendimiento de un solo subproceso, también debe considerarse el rendimiento de varios subprocesos dentro de un solo núcleo. La arquitectura del procesador Vulcan fue diseñada originalmente para usar SMT4 para mantener sus núcleos cargados y aumentar el rendimiento general, y hablaremos de eso ahora.
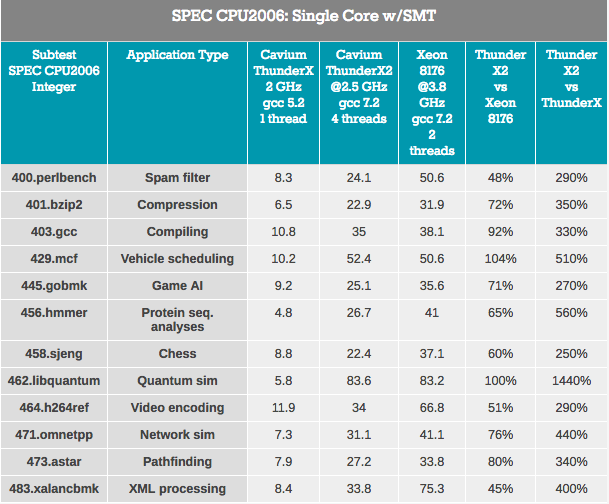
En primer lugar, el núcleo ThunderX2 ha "experimentado" muchas mejoras significativas sobre el primer núcleo ThunderX. Incluso con libquantum en mente, esta prueba puede ejecutarse fácilmente 3 veces más rápido en el núcleo ThunderX anterior después de algunas mejoras y optimizaciones para el compilador. Bueno, el nuevo ThunderX2 es no menos de 3,7 veces más rápido que su hermano mayor. Esta superioridad de IPC elimina cualquier ventaja del ThunderX anterior.
Al observar el impacto de SMT, en promedio vemos que SMT de 4 vías mejora el rendimiento de ThunderX2 en un 32%. Esto varía de 8% para codificación de video a 74% para Pathfinding. Mientras tanto, Intel está ganando un 18% de su SMT de 2 vías, del 4% al 37% en los mismos escenarios.
En general, el aumento de rendimiento de ThunderX2 es del 32%, lo cual es bastante bueno. Pero aquí surge la pregunta obvia: ¿en qué se diferencia de otras arquitecturas SMT4? Por ejemplo, IBM POWER8, que también admite SMT4, muestra un aumento del 76% en el mismo escenario.
Sin embargo, esto no es una comparación de lo similar con lo similar, ya que el chip de IBM tiene un back-end mucho más amplio: puede procesar 10 instrucciones, mientras que el núcleo ThunderX2 está limitado a 6 instrucciones por ciclo. El núcleo POWER8 es más glotón: el procesador podría acomodar solo 10 de estos núcleos "ultraanchos" en un presupuesto de potencia de 190 W a un proceso de 22 nm. Lo más probable es que un aumento adicional en el rendimiento del uso de SMT4 requerirá núcleos aún más grandes y, a su vez, afectará seriamente la cantidad de núcleos disponibles dentro de ThunderX2. Sin embargo, es interesante observar este aumento del 32% en el futuro.
En la siguiente (3) parte:
- Rendimiento de Java
- Rendimiento de Java: páginas enormes
- Apache Spark 2.x Benchmarking
- Resumen
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?