La primera y
segunda parte, "Evaluación de Cavium ThunderX2: El sueño del servidor Arm se ha hecho realidad".
Rendimiento de Java
SPECjbb 2015 es un punto de referencia de Java Business Benchmark que se utiliza para evaluar el rendimiento de los servidores que ejecutan aplicaciones Java típicas. Utiliza las últimas funciones de Java 7 y XML, lo que hace que la seguridad se vea afectada.

Tenga en cuenta que hemos actualizado la versión de SPECjbb 1.0 a la versión 1.01.

Probamos SPECjbb con cuatro grupos de inyectores de transacciones y backends. La razón por la que usamos la prueba Multi JVM es que está más cerca de las condiciones reales: varias máquinas virtuales en un servidor son una práctica común, especialmente en servidores con más de 100 subprocesos. La versión de Java es OpenJDK 1.8.0_161.
Cada vez que publicamos los resultados de SPECjbb, recibimos comentarios de que nuestro rendimiento es demasiado bajo. Por lo tanto, decidimos pasar un poco más de tiempo y prestar atención a varias configuraciones.
- La configuración del kernel, como los tiempos del planificador de tareas, borra la memoria caché de la página
- Desactivar las funciones de ahorro de energía, configurar manualmente el comportamiento del estado c.
- Configurar los ventiladores a la velocidad máxima (gastamos mucha energía en favor de un par de puntos de rendimiento adicionales)
- Deshabilitar funciones RAS (por ejemplo, borrado de memoria)
- Numerosas configuraciones para varios parámetros de Java ... No es realista, porque cada vez que ejecuta la aplicación en diferentes máquinas (lo que a menudo ocurre en la nube), especialistas caros deben configurar las configuraciones para una máquina específica, lo que, además, puede hacer que la aplicación se detenga en otras máquinas
- Configure ajustes NUMA muy específicos de SKU y asignaciones de CPU. La migración entre dos SKU diferentes en el mismo clúster puede generar serios problemas de rendimiento.
En un entorno de producción, la configuración debe ser simple y, preferiblemente, no demasiado específica para la máquina. Para este propósito, aplicamos dos tipos de configuraciones. La primera es una configuración muy simple para medir el rendimiento de fábrica para colocar todo en un servidor con 128 GB de RAM:
"-server -Xmx24G -Xms24G -Xmn16G"Para la segunda configuración, en busca del indicador de mejor rendimiento, jugamos con "-XX: + AlwaysPreTouch", "-XX: -UseBiasedLocking" y "specjbb.forkjoin.workers". "+ AlwaysPretouch" antes de comenzar restablece todas las páginas de memoria, lo que reduce el impacto del rendimiento en las páginas nuevas. "-UseBiasedLockin" deshabilita el bloqueo baised, que está habilitado de forma predeterminada. El bloqueo sesgado da prioridad a un subproceso que ya ha cargado datos contendidos en la memoria caché. El reverso del bloqueo sesgado son procesos adicionales bastante complejos (Rebias) que pueden reducir el rendimiento en el caso de una estrategia elegida incorrectamente.
El siguiente gráfico muestra el rendimiento máximo para nuestro punto de referencia MultiJVM SPECJbb.

ThunderX2 logra un rendimiento del 80 al 85% del Xeon 8176. Esta cifra es suficiente para superar el Xeon 6148. Curiosamente, los sistemas Intel y Cavium logran sus mejores resultados de diferentes maneras. En el caso de Dual ThunderX2, utilizamos:
'-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:-UseBiasedLockingMientras que el sistema Intel logró el mejor rendimiento, dejando un bloqueo de compensación (predeterminado). Notamos que el sistema Intel, probablemente debido al número relativamente "extraño" de subprocesos, tiene una carga de procesador promedio ligeramente menor (un pequeño porcentaje) y un caché L3 más grande, lo que hace que el bloqueo parcial sea una buena estrategia para esta arquitectura.
Finalmente, tenemos Critical-jOPS, que mide el rendimiento por límites de tiempo de respuesta.

Con el uso activo de una gran cantidad de subprocesos, puede obtener significativamente más Critical-jOPS al aumentar la distribución de RAM en la JVM. Sorprendentemente, el sistema Dual ThunderX2, con su mayor número de transmisiones y menor velocidad de reloj, muestra el mejor momento, proporciona un gran ancho de banda y mantiene un tiempo de respuesta del 99 por ciento hasta cierto límite.
El aumento del tamaño del almacenamiento dinámico ayuda a Intel a cerrar ligeramente la brecha (hasta x2), pero a expensas del ancho de banda (de -20% a -25%). Parece que el chip Intel necesita más personalización que ARM. Para explorar esto más a fondo, recurrimos a Transparant Huge Pages (THP).
Rendimiento de Java: páginas grandes
Por lo general, para la CPU, alguien rara vez reproduce otro en el factor 3, pero decidimos investigar el asunto más a fondo. El candidato más obvio era Huge Pages, o como todos, excepto la comunidad de Linux, lo llaman "páginas grandes".
Cada procesador moderno almacena en caché las asignaciones de memoria física y virtual en sus TLB. El tamaño de página "normal" es de 4 KB, por lo que con 1536 elementos, el núcleo de Skylake puede almacenar aproximadamente 6 MB por núcleo. En los últimos 15 años, la capacidad de DRAM ha crecido de unos pocos GB a cientos de GB y, por lo tanto, las fallas de TLB se han convertido en una preocupación. Un error de TLB es bastante costoso: necesita algunos accesos a la memoria para leer algunas tablas y finalmente encontrar una dirección física.
Todos los procesadores modernos admiten páginas grandes. En x86-64 (Intel y AMD), una opción popular es 2 MB, también está disponible una página de 1 GB. Mientras tanto, una página grande en ThunderX2 tiene al menos 0,5 GB. El uso de páginas grandes reduce la cantidad de errores de TLB (aunque la cantidad de entradas en TLB es generalmente mucho menor para páginas grandes), reduce la cantidad de accesos de memoria necesarios cuando falta una TLB.
Sin embargo, era tiempo antes de que Linux admitiera esta característica de manera conveniente. La fragmentación de la memoria, las configuraciones conflictivas y difíciles de configurar, las incompatibilidades y especialmente los nombres muy confusos causaron muchos problemas. De hecho, muchos proveedores de software todavía aconsejan a los administradores del servidor que apaguen las páginas grandes.
Con este fin, veamos qué sucede si activamos las páginas transparentes enormes y guardamos la mejor configuración que se discutió anteriormente.
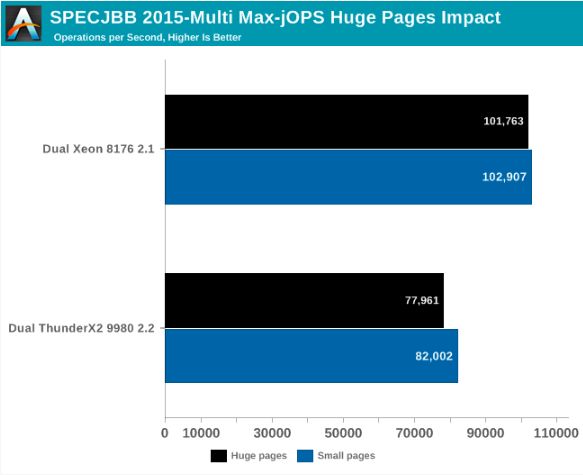
En general, para Max-jOP, el impacto en el rendimiento no es espectacular; Esto es en realidad una pequeña regresión. Xeon pierde aproximadamente el 1% de su ancho de banda, ThunderX2, aproximadamente el 5%.
Pasemos a la métrica Critical-jOPS, donde el rendimiento se mide como el percentil 99 del límite de tiempo de respuesta.

Enorme diferencia! En lugar de la derrota, Intel va más allá de ThunderX2. Sin embargo, debe decirse que el rendimiento con páginas de 4 KB es aparentemente una debilidad grave en la arquitectura Intel.
Apache Spark 2.x Benchmarking
Por último, pero no menos importante, nuestro arsenal tiene la prueba Apache Spark. Apache Spark es una creación del procesamiento de Big Data. Acelerar las aplicaciones de Big Data sigue siendo un proyecto prioritario en el laboratorio universitario donde trabajo (Sizing Servers Lab University of West-Flanders), por lo que hemos preparado un punto de referencia que utiliza muchas funciones de Spark y se basa en el uso en el mundo real.

La prueba se describe en el diagrama anterior. Comenzamos con 300 GB de datos comprimidos recopilados de CommonCrawl. Estos archivos comprimidos son una gran cantidad de archivos web. Descomprimimos los datos sobre la marcha para evitar una larga espera, que está relacionada principalmente con el dispositivo de almacenamiento. Luego extraemos los datos de texto significativos de los archivos usando la biblioteca Java BoilerPipe. Usando la herramienta de procesamiento del lenguaje natural Stanford CoreNLP, extraemos entidades ("palabras que significan algo") del texto y luego calculamos qué URL tienen la mayor ocurrencia de estos objetos. El algoritmo Cuadrado menor alterno se utiliza para recomendar qué URL son más interesantes para un tema en particular.
Para lograr una mejor escala, lanzamos 4 artistas. La investigadora Esley Havenert reconfiguró la prueba de Spark para que pudiera ejecutarse en Apache Spark 2.1.1.
Aquí están los resultados:

(*) EPYC y Xeon E5 V4 son anteriores, funcionan en Kernel 4.8 y Java un poco más antiguo 1.8.0_131 en lugar de 1.8.0_161. Aunque esperamos que los resultados sean muy similares en el kernel 4.13 y Java 1.8.0_161, ya que no vimos mucha diferencia en Skylake Xeon entre estas dos configuraciones.
El procesamiento de datos es muy paralelo y carga muy intensamente el procesador, pero para las fases de "barajado" requiere mucha interacción con la memoria. El tiempo dedicado a comunicarse con el dispositivo de almacenamiento es insignificante. La fase ALS no escala en muchos subprocesos, pero es menos del 4% del tiempo total de prueba.
ThunderX2 proporciona el 87% del rendimiento del EPYC 7601. El doble de caro que EPYC 7601. Como este indicador escala bien con el número de núcleos, podemos estimar que el Xeon 6148 tendrá un puntaje de aproximadamente 4.8. en Apache Spark Por lo tanto, aunque ThunderX2 realmente no puede amenazar al Xeon Platinum 8176, ofrece lo mismo que el Gold 6148 y su hermano por mucho menos dinero.
Y que al final
Para resumir todo, nuestras pruebas ESPECÍFICAS muestran que los núcleos ThunderX2 todavía tienen algunos defectos. Nuestra primera impresión negativa es que el código de ramificación intensivo, especialmente en combinación con los errores habituales de caché L3 (alto retraso de DRAM), funciona bastante lento. Por lo tanto, habrá casos especiales cuando ThunderX2 no sea la mejor opción.
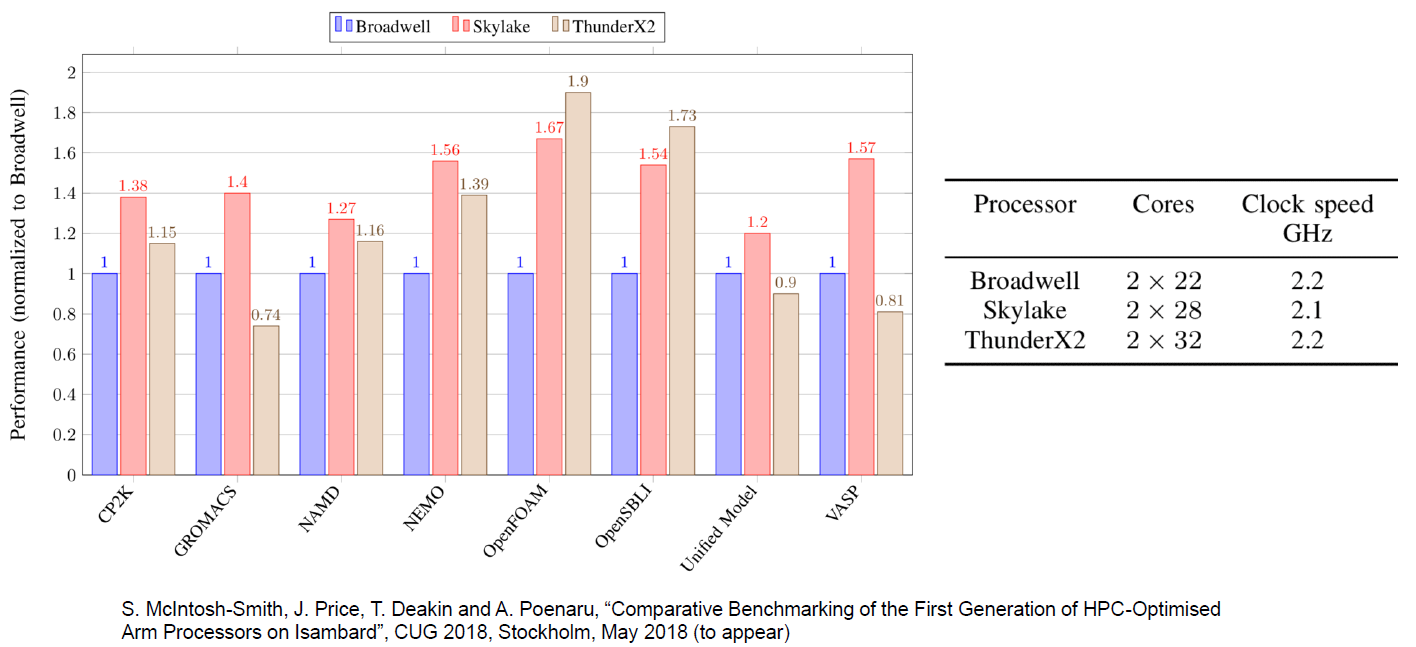
Sin embargo, además de algunos nichos de mercado, estamos bastante seguros de que ThunderX2 tendrá un desempeño sólido. Por ejemplo, las mediciones de rendimiento realizadas por nuestros colegas de la Universidad de Bristol confirman nuestra suposición de que las intensas cargas de trabajo de HPC como OpenFoam (CFD) y NAMD.run funcionan bien en ThunderX2
Según los resultados de las primeras pruebas del software del servidor que logramos hacer, podemos estar gratamente sorprendidos. Rendimiento de ThunderX2 por un dólar tanto en Java Server (SPECJbb) como en procesamiento de big data, ahora, con mucho, el mejor en el mercado de servidores. Tenemos que volver a probar el procesador AMD EPYC y la versión dorada de la generación actual (Skylake) de Xeon, pero al mismo tiempo, será muy difícil superar el 80-90% del rendimiento del procesador 8176 por una cuarta parte de su costo.
Como un beneficio adicional para Cavium y ThunderX2, debe mencionarse que el ecosistema Arm Linux ya está maduro en 2018; Ya no se necesitan núcleos especializados de Linux y otras herramientas. Simplemente instale el servidor Ubuntu, Red Hat o Suse, y puede automatizar la implementación e instalación de software desde repositorios estándar. Esta es una mejora significativa sobre lo que experimentamos cuando se lanzó ThunderX. En 2016, una instalación simple desde los repositorios habituales de Ubuntu podría causar problemas.
Entonces, en general, ThunderX2 es un rival muy poderoso. Esto puede ser aún más peligroso para EPYC AMD que para Skylake Xeon de Intel debido al hecho de que tanto Cavium como AMD están compitiendo por el mismo grupo de clientes, dada la posibilidad de abandonar Intel. Esto se debe al hecho de que los clientes que invirtieron en software corporativo costoso (Oracle, SAP) son menos sensibles a los costos en el lado del hardware, por lo que es mucho menos probable que cambien a una nueva plataforma de hardware. Y estas personas han invertido en Intel en los últimos 5 años, ya que esa era la única opción.
Esto, a su vez, significa que aquellos que son más flexibles y sensibles al precio, como los proveedores de alojamiento y la nube, ahora podrán elegir un servidor Arm alternativo con una excelente relación rendimiento / dólar. Y con HP, Cray, Pengiun, Gigabyte, Foxconn e Inventec que ofrecen sistemas basados en ThunderX2, no faltan proveedores de calidad.
En resumen, ThunderX2 es el primer SoC que compite con Intel y AMD en el mercado de servidores de CPU. Y esto es una sorpresa agradable: finalmente, ¡apareció una solución para los servidores Arm!
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?