La replicación de secuencias, que apareció en 2010, se ha convertido en una de las características innovadoras de PostgreSQL y, en la actualidad, casi ninguna instalación puede funcionar sin el uso de la replicación de secuencias. Es confiable, fácil de configurar, poco exigente con los recursos. Sin embargo, a pesar de todas sus cualidades positivas, durante su funcionamiento pueden surgir varios problemas y situaciones desagradables.
Alexey Lesovsky (
@lesovsky ) en Highload ++ 2017 dijo cómo
diagnosticar varios tipos de problemas utilizando herramientas integradas y de terceros
y cómo solucionarlos . Según los recortes, la decodificación de este informe, construida sobre la base de un principio espiral: primero, enumeramos todas las herramientas de diagnóstico posibles, luego pasamos a enumerar problemas comunes y diagnosticarlos, luego vemos qué medidas de emergencia se pueden tomar y finalmente cómo abordar el problema radicalmente.
Sobre el orador : Alexei Lesovsky, administrador de la base de datos en Data Egret. Uno de los temas favoritos de Alexey en PostgreSQL es la replicación de transmisión y el trabajo con estadísticas, por lo que el informe en Highload ++ 2017 se dedicó a cómo encontrar problemas usando estadísticas y qué métodos usar para resolverlos.
Plan
- Un poco de teoría, o cómo funciona la replicación en PostgreSQL
- Herramientas de solución de problemas o lo que PostgreSQL y la comunidad tienen
- Solución de problemas de casos:
- problemas: sus síntomas y diagnóstico
- decisiones
- medidas a tomar para que no surjan estos problemas.
¿Por qué todo esto? Este artículo lo ayudará a comprender mejor la replicación de transmisión, aprenderá a encontrar y solucionar problemas rápidamente para reducir el tiempo de reacción ante incidentes desagradables.
Poco de teoría
PostgreSQL tiene una entidad como Write-Ahead Log (XLOG), un registro de transacciones.
Casi todos
los cambios que se producen con los datos y metadatos en la base de datos se registran en el registro. Si ocurre un accidente repentinamente, PostgreSQL se inicia, lee el registro de transacciones y restaura los cambios registrados en los datos. Esto garantiza la fiabilidad, una de las propiedades más importantes de cualquier DBMS y PostgreSQL también.
El registro de transacciones se puede completar de dos maneras:
- Por defecto, cuando los backends hacen algunos cambios en la base de datos (INSERT, UPDATE, DELETE, etc.), todos los cambios se registran en el registro de transacciones de forma síncrona :
- El cliente envió un comando COMMIT para confirmar los datos.
- Los datos se registran en el registro de transacciones.
- Una vez que se ha producido la fijación, se le da control al backend y puede continuar recibiendo comandos del cliente.
- La segunda opción es la escritura asíncrona en el registro de transacciones, cuando un proceso de escritor WAL dedicado separado escribe los cambios en el registro de transacciones con un cierto intervalo de tiempo. Debido a esto, se logra un aumento en el rendimiento del backend, ya que no es necesario esperar hasta que se complete el comando COMMIT.
Lo más importante, la replicación de transmisión se basa en este registro de transacciones. Tenemos varios miembros de replicación de transmisión:
- maestro donde tienen lugar todos los cambios;
- varias réplicas que aceptan el registro de transacciones del maestro y reproducen todos estos cambios en sus datos locales. Esta es la replicación de transmisión.
Vale la pena recordar que todos estos registros de transacciones se almacenan en el directorio pg_xlog en $ DATADIR, el directorio con los principales archivos de datos DBMS. En la décima versión de PostgreSQL, este directorio se renombró a pg_wal /, porque no es raro que pg_xlog / ocupe mucho espacio, y los desarrolladores o administradores que sin saberlo lo confunden con los registros, lo eliminan descuidadamente y todo se vuelve malo.
PostgreSQL tiene varios servicios en segundo plano que participan en la replicación de transmisión. Echemos un vistazo desde el punto de vista del sistema operativo.
- Del lado del maestro - Proceso WAL Sender. Este es un proceso que envía registros de transacciones a las réplicas, cada réplica tendrá su propio WAL Sender.
- La réplica, a su vez, ejecuta el proceso del receptor WAL, que recibe registros de transacciones a través de la conexión de red del remitente WAL y los pasa al proceso de inicio.
- El proceso de inicio lee los registros y reproduce en el directorio de datos todos los cambios que se registran en el registro de transacciones.
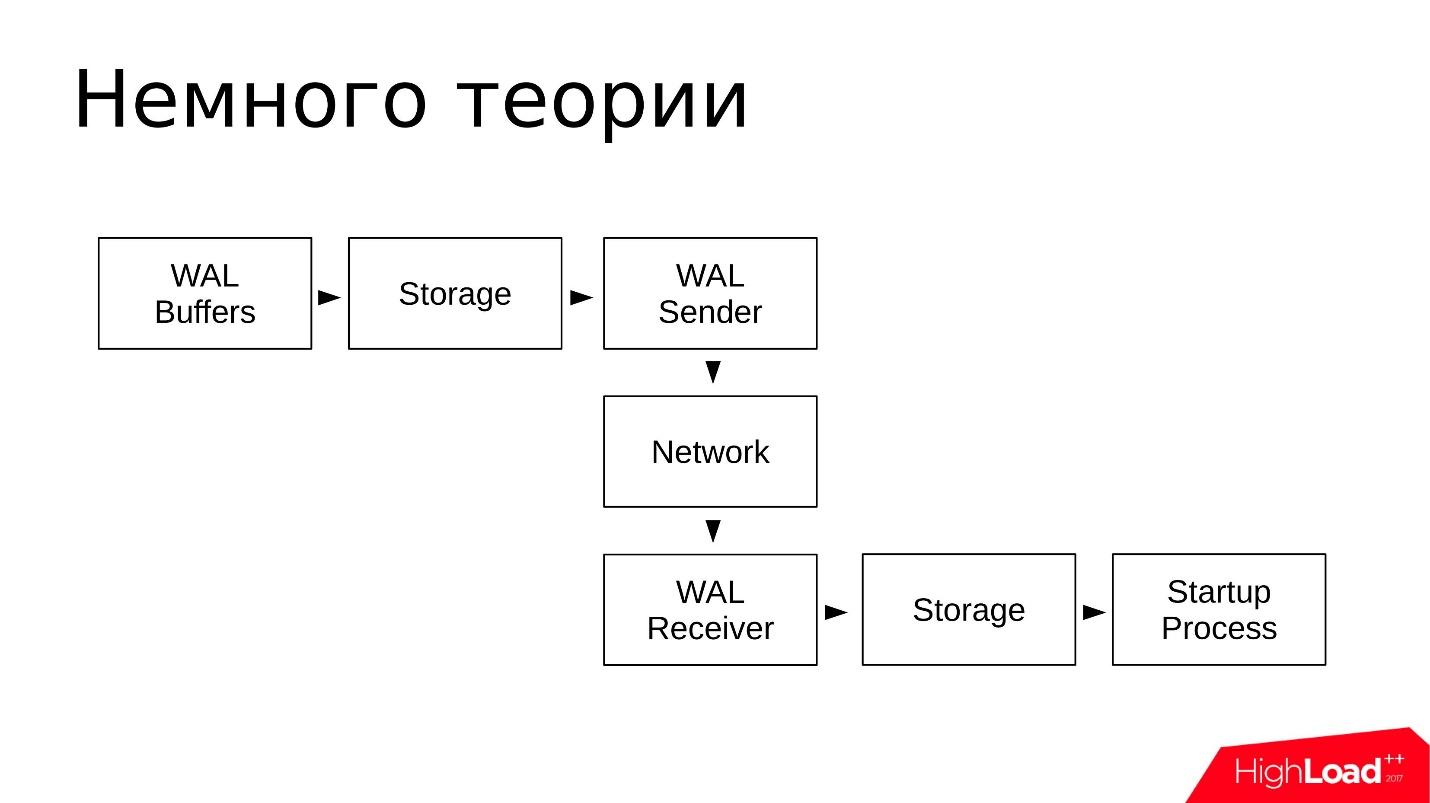
Esquemáticamente, se parece a esto:
- Los cambios se escriben en WAL Buffers, que luego se escribirán en el registro de transacciones;
- Los registros están almacenados en el directorio pg_wal /;
- WAL Sender lee el registro de transacciones del repositorio y los transmite a través de la red;
- WAL Receiver recibe y almacena en su Almacenamiento - en el local pg_wal /;
- El proceso de inicio lee todo lo que se acepta y reproduce.
El esquema es simple. La replicación de flujo funciona de manera bastante confiable y ha sido excelentemente explotada por muchos años.
Herramientas de solución de problemas
Veamos qué herramientas y utilidades ofrece la comunidad y PostgreSQL para investigar los problemas encontrados con la replicación de transmisión.
Herramientas de terceros
Comencemos con herramientas de terceros. Estas utilidades son de un
plan bastante
universal ; pueden usarse no solo para investigar incidentes relacionados con la replicación de transmisión. Generalmente son
utilidades de cualquier administrador del sistema .
- parte superior del paquete procps. Como reemplazo de la parte superior, puede utilizar cualquier utilidad, como arriba, htop y similares. Ofrecen una funcionalidad similar.
Con la ayuda de top buscamos: utilización de procesadores (CPU), carga promedio (carga promedio) y uso de memoria y espacio de intercambio.
- iostat de sysstat e iotop. Estas utilidades muestran la utilización de dispositivos de disco y qué E / S se crea mediante procesos en el sistema operativo.
Con la ayuda de iostat buscamos: utilización del almacenamiento, cuántas iops en este momento, qué rendimiento en los dispositivos, qué demoras al procesar solicitudes de E / S (latencia). Esta información bastante detallada se toma del sistema de archivos procfs y se proporciona al usuario en forma visual.
- nicstat es un análogo de iostat, solo para interfaces de red. En esta utilidad puede ver la utilización de interfaces.
Usando nicstat, buscamos: de manera similar, la utilización de la interfaz, algunos errores que ocurren en las interfaces, el rendimiento también es una utilidad muy útil.
- pgCenter es una utilidad para trabajar solo con PostgreSQL. Muestra estadísticas de PostgreSQL en una interfaz similar a la superior, y también puede ver estadísticas relacionadas con la replicación de transmisión en ella.
Con la ayuda de pgCenter buscamos: estadísticas sobre replicación. Puede ver el retraso de la replicación, evaluarlo de alguna manera y predecir el trabajo futuro.
- perf es una utilidad para una investigación más profunda de las causas del "golpeteo subterráneo", cuando en funcionamiento hay problemas extraños en el nivel de código PostgreSQL.
Con la ayuda de perf buscamos: golpes subterráneos. Para que perf funcione completamente con PostgreSQL, este último debe compilarse con caracteres de depuración, para que pueda ver la pila de funciones en los procesos y qué funciones ocupan más tiempo de CPU.
Todas estas utilidades son necesarias para
probar las hipótesis que surgen al resolver problemas: dónde y qué se ralentiza, dónde y qué necesita corregir, verifique. Estas utilidades ayudan a asegurarnos de que estamos en el camino correcto.
Herramientas integradas
¿Qué ofrece el propio PostgreSQL?
Vistas del sistema
En general, hay muchas herramientas para trabajar con PostgreSQL. Cada compañía proveedora que brinda soporte PostgreSQL ofrece sus propias herramientas. Pero, por regla general, estas herramientas se basan en estadísticas internas de PostgreSQL. A este respecto, PostgreSQL proporciona vistas del sistema en las que puede realizar varias selecciones y obtener la información que necesita. Es decir, utilizando un cliente normal, generalmente psql, podemos hacer consultas y ver qué sucede en las estadísticas.
Hay bastantes vistas del sistema. Para trabajar con la replicación de transmisión e investigar problemas, solo necesitamos: pg_stat_replication, pg_stat_wal_receiver, pg_stat_databases, pg_stat_databases_conflicts y auxiliares pg_stat_activity y pg_stat_archiver.
Hay pocos de ellos, pero este conjunto es suficiente para verificar si hay algún problema.
Funciones de ayuda
Usando funciones auxiliares, puede tomar datos de representaciones de sistemas estadísticos y transformarlos en una forma más conveniente para usted. Las funciones auxiliares también son solo unas pocas piezas.
- pg_current_wal_lsn () (el antiguo análogo de pg_current_xlog_location ()) es la función más necesaria que le permite ver la posición actual en el registro de transacciones. Un registro de transacciones es una secuencia continua de datos. Usando esta función, puede ver el último punto, obtener la posición donde el registro de transacciones se ha detenido ahora.
- pg_last_wal_receive_lsn (), pg_last_xlog_receive_location () es una función similar a la anterior, solo para réplicas. La réplica recibe el registro de transacciones y puede ver la última posición del registro de transacciones recibido;
- pg_wal_lsn_diff (), pg_xlog_location_diff () es otra función útil. Le damos dos posiciones del registro de transacciones, y ella muestra diff: la distancia entre estos dos puntos en bytes. Esta función siempre es útil para determinar el retraso entre el maestro y las réplicas en bytes.
Se puede obtener una lista completa de funciones con el metacomando psql: \ df * (wal | xlog | lsn | location) *.
Puede escribirlo en psql y ver todas las funciones que contiene wal, xlog, Isn, location. Habrá alrededor de 20-30 funciones de este tipo, y también proporcionan información variada en el registro de transacciones. Te recomiendo que te familiarices.
Utilidad Pg_waldump
Antes de la versión 10.0, se llamaba pg_xlogdump. La utilidad pg_waldump es necesaria cuando queremos examinar los segmentos del registro de transacciones, averiguar qué registros de recursos llegaron allí y qué escribió PostgreSQL allí, es decir, para un estudio más detallado.
En la versión 10.0, todas las vistas, funciones y utilidades del sistema que incluían la palabra xlog fueron renombradas. Todas las apariciones de las palabras xlog y location fueron reemplazadas por las palabras wal e lsn, respectivamente. Lo mismo se hizo con el directorio pg_xlog que se convirtió en el directorio pg_wal.
La utilidad pg_waldump simplemente decodifica el contenido de los segmentos XLOG en un formato legible para humanos. Puede ver qué denominados registros de recursos caen en los registros de segmento durante el trabajo de PostgreSQL, qué índices y archivos de almacenamiento dinámico se modificaron, qué información destinada para stand-by llegó allí. Por lo tanto, se puede ver mucha información usando pg_waldump.
Pero hay un descargo de responsabilidad que está escrito en la documentación oficial : pg_waldump puede mostrar datos ligeramente incorrectos cuando PostgreSQL se está ejecutando (puede dar resultados incorrectos cuando el servidor se está ejecutando, lo que sea que eso signifique)
Puedes usar el comando:
pg_waldump -f - /wal_10 \ $(psql -qAtX - "select pg_walfile_name(pg_current_wal_lsn())")
Este es un análogo del comando tail -f solo para registros de transacciones. Este comando muestra la cola del registro de transacciones que está sucediendo en este momento. Puede ejecutar este comando, encontrará el último segmento con la entrada de registro de transacciones más reciente, se conectará a él y comenzará a mostrar el contenido del registro de transacciones. Un equipo un poco complicado, pero, sin embargo, funciona. A menudo lo uso.
Solución de problemas de casos
Aquí observamos los problemas más comunes que surgen en la práctica de los consultores, qué síntomas pueden ser y cómo diagnosticarlos:
Los retrasos de replicación son el problema más común . Más recientemente, tuvimos correspondencia con el cliente:
- Hemos roto la replicación maestro-esclavo entre los dos servidores.
- Detectado retraso 2 horas, pg_dump comenzó.
- OK, veo. ¿Cuál es nuestro retraso permisible?
- 16 horas en max_standby_streaming_delay.
- ¿Qué pasará cuando se exceda este retraso? Sirena aullando?
- No, las transacciones serán superadas y se reanudará el rollo de WAL.
Tenemos problemas con los retrasos de replicación todo el tiempo, y casi todas las semanas los resolvemos.
La expansión del directorio pg_wal / donde se almacenan los segmentos del registro de transacciones es un problema que ocurre con menos frecuencia. Pero en este caso es necesario tomar medidas inmediatas para que el problema no se convierta en una situación de emergencia cuando las réplicas se caigan.
Las consultas largas que se ejecutan en la réplica generan
conflictos durante la recuperación . Esta es una situación en la que iniciamos algún tipo de carga en la réplica, puede ejecutar consultas de lectura en las réplicas, y en este momento estas consultas interfieren con la reproducción del registro de transacciones. Hay un conflicto, y PostgreSQL necesita decidir si esperar a que se complete la consulta o completarla y continuar reproduciendo el registro de transacciones. Este es un conflicto de replicación o un conflicto de recuperación.
Proceso de recuperación: 100% de uso de la CPU: el proceso de recuperación de un registro de transacciones en las réplicas toma el 100% del tiempo del procesador. Esta también es una situación rara, pero es bastante desagradable, porque conduce a un aumento en el retraso de la replicación y generalmente es difícil de investigar.
Retrasos de replicación
Los retrasos de replicación se producen cuando la misma solicitud, ejecutada en el maestro y en la réplica, devuelve datos diferentes. Esto significa que los datos son inconsistentes entre el maestro y las réplicas, y hay algún retraso. La réplica necesita reproducir parte de los registros de transacciones para ponerse al día con el asistente. El síntoma principal se ve exactamente así: hay una consulta y devuelven resultados diferentes.
¿Cómo buscar tales problemas?- Hay una vista básica sobre el asistente y las réplicas: pg_stat_replication . Muestra información sobre todos los remitentes de WAL, es decir, sobre procesos que envían registros de transacciones. Cada réplica tendrá una línea separada que muestra estadísticas para esta réplica en particular.
- La función auxiliar pg_wal_lsn_diff () le permite comparar diferentes posiciones en el registro de transacciones y calcular el mismo retraso. Con su ayuda, podemos obtener números específicos y determinar dónde tenemos un gran retraso, dónde es pequeño y de alguna manera ya responder al problema.
- La función pg_last_xact_replay_timestamp () funciona solo en la réplica y le permite ver la hora en que se realizó la última transacción perdida. Hay una conocida función now () que muestra la hora actual, restamos el tiempo que nos muestra la función pg_last_xact_replay_timestamp () de la función now () y obtenemos el retraso de tiempo.
En la décima versión de pg_stat_replication, aparecieron campos adicionales que muestran el retraso de tiempo ya en el asistente, por lo tanto, este método ya está desactualizado, pero, sin embargo, puede usarse.
Hay una pequeña trampa. Si no hay transacciones en el asistente durante mucho tiempo y no genera registros de transacciones, la última función mostrará un retraso creciente. De hecho, el sistema simplemente está inactivo, no hay actividad en él, pero al monitorear podemos ver que el retraso está creciendo. Vale la pena recordar esta trampa.
La vista es la siguiente.

Contiene información sobre cada remitente de WAL y varios campos que son importantes para nosotros. Esto es principalmente
client_addr : la dirección de red de la réplica conectada (generalmente una dirección IP) y un conjunto de campos
lsn (en versiones anteriores se llama ubicación), hablaré un poco más sobre ellos.
En la décima versión, aparecieron los campos de
retraso : este es un retraso expresado en el tiempo, es decir, un formato más legible para los humanos. El retraso puede expresarse en bytes o en tiempo: puede elegir lo que más le guste.
Como regla, uso esta solicitud.

Esta no es la consulta más compleja que pg_stat_replication imprime en un formato más conveniente y comprensible. Aquí uso las siguientes funciones:
- pg_wal_lsn_diff () para leer diffs. Pero entre lo que creo que son las diferencias? Tenemos varios campos: sent_lsn, write_lsn, flush_lsn, replay_lsn. Al calcular la diferencia entre el campo actual y el anterior, podemos comprender con precisión dónde nos retrasamos, dónde ocurre exactamente el retraso.
- pg_current_wal_lsn (), que muestra la posición actual de las transacciones de diario. Aquí observamos la distancia entre la posición actual en el registro y la enviada: cuántos registros de transacciones se generaron pero no se enviaron.
- sent_lsn , write_lsn : esto es cuánto se envía a la réplica, pero no se registra. Es decir, ahora se encuentra en algún lugar de la red, o fue recibido por una réplica, pero aún no se ha escrito desde los búferes de red al almacenamiento en disco.
- write_lsn, flush_lsn : esto está escrito, pero no fue emitido por el comando fsync, como si estuviera escrito, pero puede ubicarse en algún lugar de la RAM, en el caché de páginas del sistema operativo. Tan pronto como hacemos fsync, los datos se sincronizan con el disco, llegan al almacenamiento persistente y todo parece ser confiable.
- replay_lsn, flush_lsn : datos volcados, fsync ejecutado, pero no replicado.
- current_wal_lsn y replay_lsn es una especie de retraso total que incluye todas las posiciones anteriores.
Algunos ejemplos

La réplica 10.6.6.8 se destaca arriba. Tiene un
retraso pendiente , generó algunos registros de transacciones, pero aún no se envían y yacen en el maestro. Lo más probable es que haya algún tipo de problema con el rendimiento de la red. Verificaremos esto usando la utilidad nicstat.
Lanzaremos nicstat, veremos la utilización de la interfaz, si hay algún problema y error allí. Entonces podemos probar esta hipótesis.

El
retraso de escritura está marcado arriba. De hecho, este retraso es bastante raro, casi no veo que sea grande. El problema puede estar en los discos, y usamos la utilidad iostat o iotop: observamos la utilización de los almacenes de discos, que es la E / S creada por los procesos, y luego descubrimos por qué.
 Vaciar y reproducir retrasos
Vaciar y reproducir retrasos : la mayoría de las veces el retraso ocurre allí cuando el dispositivo de disco en la réplica no tiene tiempo para simplemente perder todos los cambios que llegan del maestro.
También con las utilidades iostat e iotop observamos qué sucede con la utilización del disco y por qué los frenos.
Y el último
total_lag es una métrica útil para monitorear sistemas. Si se supera nuestro umbral total_lag, se activa una casilla de verificación en la supervisión y comenzamos a investigar lo que está sucediendo allí.
Prueba de hipótesis
Ahora necesita descubrir cómo investigar más a fondo un problema particular. Ya dije que si esto es un retraso de la red, entonces debemos verificar si todo está en orden con la red.
Ahora, casi todos los servidores proporcionan 1 Gb / so incluso 10 Gb / s, por lo que un
ancho de banda obstruido es el escenario más improbable . Como regla general, debe mirar los errores. nicstat contiene información sobre errores en las interfaces, puede darse cuenta de que hay problemas con los controladores, ya sea con la tarjeta de red o con los cables.
En el problema de almacenamiento, se investiga con el iostat y iotop. iostat es necesario para ver la imagen general del almacenamiento en disco: reciclaje del dispositivo, ancho de banda del dispositivo, latencia. iotop: para una investigación más precisa, cuando necesitamos identificar qué proceso está cargando el subsistema de disco. Si se trata de algún tipo de proceso de terceros, simplemente se puede detectar, completar y quizás el problema desaparecerá.
En primer lugar, observamos
los retrasos de recuperación y los conflictos de replicación a través de top o pg_stat_activity: qué procesos se están ejecutando, qué solicitudes se están ejecutando, su tiempo de ejecución, cuánto tiempo se están ejecutando. Si se trata de consultas largas, analizamos por qué funcionan durante mucho tiempo, les disparamos, las entendemos y las
optimizamos : examinaremos las consultas por sí mismas.
Si se trata de una
gran cantidad de registros de transacciones generados por el asistente, podemos detectar esto mediante
pg_stat_activity . Tal vez algunos procesos de respaldo se inicien allí, se haya iniciado algún tipo de vacío (pg_stat_progress_vacuum) o se esté ejecutando el punto de control. Es decir, si se generan demasiados registros de transacciones y la réplica simplemente no tiene tiempo para procesarla, en algún momento puede caerse y esto será un problema para nosotros.
Y, por supuesto,
pg_wal_lsn_diff () para determinar el retraso y determinar dónde tenemos el retraso específicamente: en la red, en los discos o en los procesadores.
Opciones de solucion
Problemas de red / almacenamientoAquí todo es bastante simple, pero desde el punto de vista de la configuración, esto generalmente no se resuelve. Puede apretar algunas tuercas, pero en general hay 2 opciones:
- Verificar carga de trabajo
Verifique qué solicitudes se están ejecutando. Tal vez se inicie algún tipo de migración que genere muchos registros de transacciones, o puede ser transferencia de datos, eliminación o inserción.
Cualquier proceso que genere registros de transacciones puede conducir al retraso de la transacción . Todos los datos en el asistente se generan lo más rápido posible, realizamos un cambio en los datos, los enviamos a la réplica y la réplica puede hacer frente o fallar; esto no afecta al asistente. Aquí puede aparecer un retraso y debe hacer algo con él.
- Actualización de hardware
La opción más estúpida: tal vez nos hemos encontrado con el rendimiento del hierro y solo necesita cambiarlo. Pueden ser discos viejos o SSD de baja calidad, o un complemento en el rendimiento de un controlador RAID. Aquí ya no estamos explorando la base en sí, sino comprobando el rendimiento de nuestras glándulas.
Retrasos de recuperaciónSi tenemos algún tipo de conflicto de replicación debido a solicitudes largas, lo que resulta en un aumento en el retraso de reproducción, lo
primero que hacemos es
disparar solicitudes largas que se ejecutan en la réplica, ya que retrasan la reproducción de los registros de transacciones.
Si las consultas largas están relacionadas con la falta de optimización de la consulta SQL en sí misma (lo descubrimos utilizando EXPLAIN ANALYZE), solo necesita abordar esta consulta de manera diferente y reescribirla. O hay una opción para configurar una
réplica separada para informar consultas . Si hacemos informes que funcionen durante mucho tiempo, deben enviarse a una réplica separada.
Todavía existe la opción de
solo esperar . Si tenemos algún tipo de retraso al nivel de unos pocos kilobytes o incluso decenas de megabytes, pero creemos que esto es aceptable, solo esperamos a que se complete la solicitud y el retraso se resolverá por sí solo. Esta también es una opción, y a menudo sucede que es aceptable.
WAL de alto volumenSi generamos un gran volumen de registro de transacciones, necesitamos reducir este
volumen por unidad de tiempo , para que la réplica necesite masticar menos registros de transacciones.
Típicamente, esto se hace
con la configuración. Solución parcial en la configuración del parámetro full_page_writes = off. Esta opción activa / desactiva la grabación de imágenes completas de páginas cambiantes en el registro de transacciones. Esto significa que cuando tuvimos la operación de servicio de escribir un punto de control (CHECKPOINT), la próxima vez que cambiemos algún bloque de datos en el área de buffers compartidos, la imagen completa de esta página irá al registro de transacciones, y no solo el cambio en sí. Con todos los cambios posteriores en la misma página, solo los cambios se registrarán en el registro de transacciones. Y así sucesivamente al siguiente punto de control.
Después del punto de control, registramos la imagen completa de la página, y esto afecta el volumen del registro de transacciones registrado. Si hay muchos puntos de control por unidad de tiempo, digamos que se realizan 4 puntos de control por hora, y habrá muchas imágenes de página completa, esto será un problema. Puede deshabilitar la grabación de imágenes completas y esto afectará el volumen del WAL. Pero de nuevo, esta es una media medida.
Nota: La recomendación de deshabilitar full_page_writes debe considerarse cuidadosamente, ya que el autor olvidó aclarar durante el informe que deshabilitar un parámetro puede, en algunas circunstancias, ocurrir en situaciones de emergencia (daño al sistema de archivos o su registro, escritura parcial en bloques, etc.) archivos de base de datos potencialmente corruptos. Por lo tanto, tenga cuidado, deshabilitar el parámetro puede aumentar el riesgo de corrupción de datos en situaciones de emergencia.Otra media medida es
aumentar el intervalo entre puntos de control . Por defecto, el punto de control se realiza cada 5 minutos, y esto es bastante común. Como regla general, este intervalo se incrementa a 30-60 minutos; este es un tiempo bastante aceptable para que todas las páginas sucias se sincronicen con el disco.
Pero la solución principal es, por supuesto,
observar nuestra carga de trabajo : qué tipo de operaciones pesadas están ocurriendo allí, asociadas con el cambio de datos y, tal vez, intentar hacer estos cambios en lotes.
Supongamos que tenemos una tabla, queremos eliminar varios millones de registros. La mejor opción es no eliminar estos millones de una vez con una sola solicitud, sino dividirlos en paquetes de 100-200 mil para que, en primer lugar, se generen pequeñas cantidades de WAL, en segundo lugar, el vacío tenga tiempo de pasar por los datos eliminados, y por lo tanto el retraso no fue tan Grande y crítico.
Hinchazón pg_wal /
Ahora, hablemos sobre cómo puede encontrar que el directorio pg_wal / está hinchado.
En teoría, PostgreSQL siempre lo mantiene en un estado óptimo para sí mismo al nivel de ciertos archivos de configuración y, por regla general, no debería crecer por encima de ciertos límites.
Hay un parámetro max_wal_size, que determina el valor máximo. Además, está el parámetro wal_keep_segments, un número adicional de segmentos que el maestro almacena para la réplica si la réplica no está disponible de repente durante mucho tiempo.
Habiendo calculado la suma de max_wal_size y wal_keep_segments, podemos estimar aproximadamente cuánto espacio ocupará el directorio pg_wal /. Si crece rápidamente y ocupa mucho más espacio que el valor calculado, esto significa que hay algún problema y debe hacer algo al respecto.
¿Cómo detectar tales problemas?
En el sistema operativo Linux, existe el
comando du -csh . Simplemente podemos controlar el valor y controlar cuántos registros de transacciones tenemos allí; mantenga una etiqueta calculada, cuánto debe y cuánto toma realmente, y de alguna manera responde a los cambios en los números.
Otro lugar que vemos son las
vistas pg_replication_slots y
pg_stat_archiver . Las razones más comunes por las que pg_wal / ocupa mucho espacio son las ranuras de replicación olvidadas o el archivado roto. Otras razones también tienen un lugar para estar, pero en mi práctica eran muy raras.
Y, por supuesto, siempre hay errores en los registros de PostgreSQL que están asociados con el comando de archivo. Desafortunadamente, no habrá otras razones relacionadas con pg_wal / overflow. Solo podemos detectar errores de archivo allí.
Opciones para problemas:
CRUD pesado: operaciones de actualización de datos pesados: INSERT, BORRADO, ACTUALIZACIÓN pesados, asociados con el cambio de varios millones de filas. Si PostgreSQL necesita hacer tal operación, está claro que se generará una gran cantidad de registro de transacciones. Se almacenará en pg_wal /, y esto aumentará el espacio ocupado. Es decir, nuevamente, como dije antes, es una buena práctica simplemente dividirlos en paquetes y actualizar no toda la matriz, sino 100, 200, 300 mil cada uno.
Una ranura de replicación olvidada o no utilizada es otro problema común. Las personas a menudo usan la replicación lógica para algunas de sus tareas: configuran buses que envían datos a Kafka, envían datos a una aplicación de terceros que decodifica la replicación lógica a otro formato y de alguna manera los procesa.
La replicación lógica generalmente funciona a través de ranuras . Sucede que configuramos una ranura de replicación, jugamos con la aplicación, nos dimos cuenta de que esta aplicación no nos conviene, la apagamos, la eliminamos
y las ranuras de replicación continúan activas .
PostgreSQL para cada ranura de replicación guarda segmentos del registro de transacciones en caso de que una aplicación remota o réplica se conecte a esta ranura nuevamente, y luego el asistente puede enviarles estos registros de transacciones.
Pero el tiempo pasa, nadie se conecta a la ranura, los registros de transacciones se acumulan y, en algún momento, ocupan el 90% del espacio. Necesitamos descubrir qué es, por qué se ocupa tanto espacio. Como regla general, esta ranura olvidada y no utilizada solo debe eliminarse, y el problema se resolverá. Pero más sobre eso más tarde.
Otra opción podría ser un
archivo_comando roto . Cuando tenemos algún tipo de repositorio de registro de transacciones externo que mantenemos para las tareas de recuperación ante desastres, generalmente se configura un comando de archivo, con menos frecuencia se configura pg_receivexlog. El comando registrado en archive_command es a menudo un comando separado o algún script que toma segmentos del registro de transacciones de pg_wal / y lo copia en el almacenamiento de archivos.
Sucede que realizamos algún tipo de actualización de los paquetes del sistema, por ejemplo, en rsync la versión cambió, los indicadores se actualizaron o cambiaron, o en algún otro comando que se utilizó en el comando de archivo, el formato también cambió, y el script o el programa en sí que se especifica en archivado_comando se rompe. En consecuencia, los archivos dejan de copiarse.
Si el comando de archivado funcionó con una salida que no es 0, se escribirá un mensaje sobre esto en el registro y el segmento permanecerá en el directorio pg_wal /.
Hasta que descubramos que nuestro equipo de archivo se ha roto, los segmentos se acumularán y el lugar también finalizará en algún momento.
Conjunto de medidas de emergencia (espacio 100% utilizado):1. Dispare todas las solicitudes CRUD largas que se ejecutan actualmente en el asistente: pg_terminate_backend ().Puede ser algún tipo de copias de solicitudes, copias de seguridad, actualizaciones que actualizan un millón de líneas, etc. En primer lugar, tenemos que disparar estas solicitudes para evitar que el directorio pg_wal / siga creciendo, de modo que no se generen nuevos segmentos.2. Reduzca el llamado espacio reservado para los archivos de usuario raíz: relación de espacio reservado (sistemas de archivos ext).ext ext 5%. , , 5% — . , , 1% , tune2fs -m 1. PostgreSQL , . 100% .
3.
(LVM, ZFS,...).
LVM ZFS, LVM ZFS, , , . , .
4. —
, , HE pg_wal/ .
, , , . ! PostgreSQL , . , , , .
, pg_xlog/ pg_wal/ — log , , , , - — !
, 100% CPU, .
workload . , ? , - , -. : , tablespace, tablespace.
. , , , , , , .
— .checkpoints_segments/max_wal_size, wal_keep_segments . , , — 10-20 wal_keep_segments, max_wal_size. , . PostgreSQL pg_wal/ .
pg_replication_slots — . ,
, — . , , . .
WAL, ,
pg_stat_archiver , . ,
, , , .
checkpoint . , , . , PostgreSQL .
, checkpoint .
, , — . - , . , .
— PostgreSQL :
- User was holding shared bufer pin for too long.
- User query might have needed to see row versions that must be removed.
- User was holding a relation lock for too long.
- User was or might have been using table space that must be dropped.
- User transaction caused bufer deadlock with recovery.
- User was connected to a database that must be dropped.
2 — , , . : , , . ( 30 ),
PostgreSQL — .
. , , . - , timeout . — ALTER, , .
. , tablespace , tablespace. , , - — .
?
pg_stat_databases, pg_stat_databases_conflicts . , . , .
,
. , . , . , , , .
?
, — :
- max_standby_streaming_delay ( ). , . .
- hot_stadby_feedback ( /). , vacuum - , . bloat . , , , hot_stadby_feedback .
- DBA — . , . , , , - , .
- , , , , DBA — , , . max_standby_streaming_delay . , . , , , . — , .
Recovery process: 100% CPU usage
, , ,
100% . , , 100%. , pg_stat_replication, , replay, , .
:
- top — — 100% CPU usage recovery process;
- pg_stat_replication — , , .
, . , :
- perf top/record/report ( debug—);
- GDB;
- pg_waldump.
, , . workload,
. , , PostgreSQL shared buffers ( ). .
Solución
,
. - workload, - , - : « , - ».
pgsql-hackers ,
pgsql-bugs , , . , .
—
- , , .
. , , , .
. , , , , , — .
,
, — . , , , .
, ,
— , , .
Enlaces utiles
, Highload++ Siberia , 25 26 . , , .
- MySQL ClickHouse.
- , Oracle.
- Nikolay Golov le dirá cómo implementar transacciones si el dinero está en un servicio, los servicios en otro y cada servicio tiene su propia base aislada.
- Yuri Nasretdinov explicará en detalle por qué VK necesita ClickHouse, cuántos datos se almacenan y mucho más.