Breve reseña: mi última nota describió un enfoque para almacenar y recuperar datos sobre los cuales puede construir un diseñador de aplicaciones, una alternativa a las plataformas de desarrollo modernas, pero sin la necesidad de programación. Este invento puede potencialmente transformar todo el mundo de TI, tal como lo conocemos.
Realicé una búsqueda de patentes y publiqué el resultado para asegurarme de que no hubiera contrapartes arquitectónicas. Luego recibió una patente y publicó un artículo con explicaciones, que contenía varios comentarios audaces sobre volúmenes, escalabilidad, velocidad y otras cosas.
Por supuesto, el artículo planteó una gran cantidad de preguntas que deben abordarse por separado: la diferencia con las soluciones existentes y un análisis comparativo del rendimiento y los planes para crear consultas en la base de datos. Y también responda la pregunta: ¿de qué se trata y por qué?
Dado que el tema es doloroso para muchos, y los beneficios reclamados son muy ambiciosos, los comentarios fueron bastante duros. La razón es comprensible: en el artículo, todos ven de inmediato "EAV", sobre el cual las personas serias aún escriben investigaciones, mientras que el problema de rendimiento generalmente no se puede resolver. Como se me informó amablemente en los comentarios, EAV tiene un montón de deficiencias, esto es bien conocido, y cualquiera que reclame una solución final a los problemas de EAV debe obtener patadas generosas en el karma para volver a sus sentidos.
Solo hay una sutileza: el artículo no presenta EAV como tal
La pregunta más popular fue: "¿cómo es esto diferente de EAV, KV, Magento ...".
Parece que las diferencias radican en todo lo que no encaja en las propiedades enumeradas:
- La estructura: en la tabla hay 5 columnas y 3 índices
- Método de muestreo: una tabla describe los tipos de datos y sus relaciones (metadatos) y los datos en sí
Pero tal respuesta no fue adecuada para muchos lectores, por lo que intentaré explicarlo con más detalle.
La estructura descrita usa el directorio EAV, complementado por el atributo ID, ya que cualquier atributo también es una entidad independiente que puede tener sus propios atributos, así como también puede usarse como un valor de referencia. Es decir, la estructura está pensada no solo como una referencia EAV, por lo que, de hecho, no puedo llamarla EAV.
Lo más importante, EAV no puede ser una solución autosuficiente, es solo una guía, uno de los elementos del sistema. Estoy hablando de una solución completa y autosuficiente, que no requiere nada extra para crear una estructura, datos y administrarla.
Para explicar cómo la solución difiere de Datomic, Magento y decenas de miles de otras soluciones y productos, deberá compararlos decenas de miles de veces. Por lo tanto, me aventuraré a proponer una técnica simple mediante la cual en un par de minutos puede hacer una comparación con cualquier sistema e identificar la diferencia, si la hay.
Es necesario verificar el cumplimiento de las siguientes condiciones para el sistema comparado:
1. Todos los datos se almacenan en una tabla (véase también la cláusula 3.) que contiene al menos los siguientes campos: ID, ID principal, ID de tipo, Valor
2. Para la tabla, se construyen al menos los siguientes índices: ID; ID de tipo + valor; ID principal + ID de tipo.
3. Puede haber varias tablas, pero todas contienen la estructura mínima del elemento 1 y los índices, que difieren según el tipo del campo Valor
4. La tabla contiene una descripción de los tipos de datos.
5. La tabla contiene una descripción de los detalles de los tipos de datos (del conjunto de tipos descritos en ella)
6. La tabla contiene objetos de datos con una referencia a su tipo (del conjunto de tipos descritos en ella)
7. La tabla contiene detalles de objetos con un enlace al padre y tipo
8. La selección de objetos se realiza con la indicación obligatoria del tipo de objeto.
9. La selección de los detalles del objeto se realiza con la indicación obligatoria del padre y tipo
10. La selección del objeto por sus detalles se realiza con la indicación obligatoria del tipo de detalles.
11. (opcional) Los objetos se conectan a través de los detalles que contienen como el tipo de ID del objeto vinculado
Si se cumplen todos los requisitos previos, entonces tiene un sistema que se incluye en la descripción de las notas discutidas aquí.
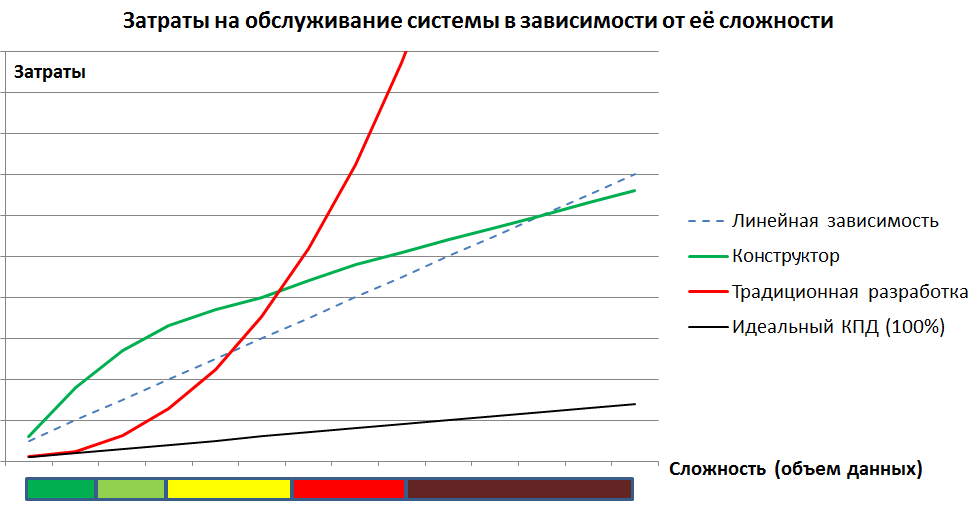
Problemas más importantes ponen en duda la declaración del rendimiento del sistema a medida que crece el volumen.
Para las pruebas comparativas, se hicieron dos bases de datos idénticas, una de las cuales se construyó en las tablas habituales de la base de datos relacional, y la otra utilizando la metodología declarada. A continuación se muestran los resultados de las pruebas de dos bases de datos con textos de consulta, mediciones de tiempo y análisis de planes de ejecución.
En los comentarios de la última publicación, se propuso una estructura simple de datos relacionados, adecuada para la prueba. Lo tomé como base: esta es una lista de 1,048,552 libros de 142,654 autores generados a partir de datos aleatorios.
La estructura se ve así (haga clic para ver)CREATE TABLE `author` (
`id` int(11) NOT NULL,
`author` varchar(128) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `books` (
`id` int(8) NOT NULL,
`name` varchar(256) NOT NULL,
`author` int(8) NOT NULL,
`pages` int(4) NOT NULL,
`year` int(4) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE `author`
ADD PRIMARY KEY (`id`),
ADD KEY `author` (`author`);
ALTER TABLE `books`
ADD PRIMARY KEY (`id`),
ADD KEY `name` (`name`(255)),
ADD KEY `author` (`author`);
ALTER TABLE `books`
ADD CONSTRAINT `books_ibfk_1` FOREIGN KEY (`author`) REFERENCES `author` (`id`);
:

: 1 @2.4GHz, 1GB RAM, SSD.
207 289 .
, , .
: , . .
:
SELECT author.author, books.name, books.pages, books.year
FROM books, author
WHERE author.author LIKE '%aro%' AND books.author=author.id
LIMIT 1000
( ):

«aro», 465 .
193 :

:

266 :

, 266 6 ( , - , ). 264 .
:
SELECT a225.val v1_225,a217.val v2_217,a223.val v3_217,a219.val v4_217
FROM test a225
LEFT JOIN (test r217 JOIN test a217 USE INDEX (PRIMARY)) ON r217.up=a217.id AND a225.id=r217.t AND a217.t=217
LEFT JOIN test a223 ON a223.up=a217.id AND a223.t=223
LEFT JOIN test a219 ON a219.up=a217.id AND a219.t=219
WHERE a225.up!=0 AND a225.t=225 AND a225.val LIKE '%aro%'
LIMIT 1000
:

, , «», , , .
, , ( ).
, , . .
, :
, . . Magento, , .
,
, , .
:
SELECT author.author, books.name, books.pages, books.year
FROM books, author
WHERE author.author LIKE 'lac%' AND books.author=author.id
LIMIT 1000
3.1 :

8.4 , 6 :

, , .
:

:

, ( ):
, , . , .
—
: . :
SELECT author.author, books.name, books.pages, books.year
FROM books, author
WHERE books.name LIKE '% %' AND books.author=author.id
LIMIT 50
:

: 148 2490 . 17 !
, , , , . :

: 181 25 . , , 7 .
:
SELECT author.author, books.name, books.pages, books.year
FROM books INNER JOIN author ON books.author=author.id
WHERE books.name LIKE '% %'
LIMIT 50
: 62 47 . . , , . , .
, , , .
, , , . , .
: () . :
SELECT author.author, books.name, books.pages, books.year
FROM books, author
WHERE books.pages=150 AND books.year=1972 AND books.author=author.id
LIMIT 50
:

, 30 :


, , . .
, : , .
: DDL DML .