Hola Habr! Continuamos nuestra serie experimental de artículos, observando que puedes influir en tiempo real en el proceso de creación de un juego en UWP. Hoy hablaremos sobre la pregunta "¿Dónde almacenar los datos?" Que surge constantemente en las filas de los desarrolladores. ¡Únete a nosotros y comparte tus pensamientos en los comentarios!
 Doy la palabra al autor, Alexei Plotnikov .
Doy la palabra al autor, Alexei Plotnikov .En un artículo anterior, planteé la cuestión de la sincronización conveniente de los datos del usuario entre dispositivos y, en primer lugar, resolví el problema con su identificación, sin embargo, esta es la fracción más pequeña de lo que queda por hacer para lograr los objetivos.
Un problema mucho más complejo es la forma, y lo más importante, la ubicación de los datos del usuario y, a través de los esfuerzos de Microsoft, al plantear una pregunta de este tipo, lo primero que se me ocurre es
Microsoft Azure . La plataforma en la nube de Azure incluye una gama tan amplia de servicios que parece que no hay tareas que no puedan resolverse con su ayuda. Si es cierto o no, no puedo juzgar, pero mi tarea está definitivamente dentro del poder de esta plataforma. Sin embargo, lo primero es lo primero.
Comenzamos con algo pequeño: ¿qué es una nube? Por primera vez escuché sobre la nube en 2012 y luego la frase "computación en la nube" se usaba con mayor frecuencia. La idea inicial de tales cálculos era distribuir el trabajo informático entre diferentes dispositivos que están alejados entre sí. Particularmente impresionante habló sobre el futuro, en el que incluso las tareas más difíciles se procesarán en un par de momentos debido al hecho de que los cálculos se distribuirán entre todas las computadoras del mundo.
En la práctica, todo se redujo a centros de datos repartidos por todo el mundo y que proporcionaban su potencia informática a los consumidores, y el concepto inicial era solo la distribución entre las máquinas dentro del centro de datos y entre los propios centros de datos (con mayor frecuencia dentro de la misma región).
Con base en lo anterior, podemos suponer que cuando escuche la palabra "nube", puede percibirla como un "alojamiento" más familiar, con la única diferencia de que el poder de la nube puede expandirse sin ningún esfuerzo adicional de su parte.
La segunda pregunta que puede tener es ¿por qué Azure? "Dado que este es un artículo en el blog de Microsoft, entonces el autor solo hablará sobre sus productos" - usted dice, y se equivocará. Los motivos para usar Azure son mucho más comunes: dado que este es un producto de Microsoft, tiene el mayor grado posible de integración con sus otros productos, con la ayuda de la cual se está desarrollando mi aplicación.
Sin embargo, observo que la compañía hace todo lo posible para que el uso de Azure sea atractivo para los desarrolladores de Android o iOS. Bueno, el último problema mencionado, pero no menos importante, es el costo de usar la nube. Como soy titular de una suscripción a BizSpark, me han otorgado un préstamo mensual para una bolsa con intereses más que para cubrir mis necesidades en la nube, aunque las condiciones que se brindan de forma gratuita también pueden cubrir la mayoría de las necesidades de un desarrollador privado.
Ahora pasemos a la selección directa de un mecanismo de sincronización y almacenamiento de datos. No voy a ser astuto, como persona autodidacta a menudo tengo que lidiar con tecnologías de las que no tengo idea antes de conocer UWP, resolví problemas similares usando bases de datos SQL.
Sin embargo, UWP no tiene los medios para trabajar con los DBMS clásicos de SQL, y SQLite se ofrece como una alternativa, y, después de comenzar su estudio, descubrí que dicha base de datos está integrada, lo que es adecuado para el almacenamiento conveniente y el uso de datos locales, pero no es absolutamente adecuado para la colocación de datos en almacenamiento remoto Ya en el proceso de escribir este artículo, cuando se eligió la tecnología adecuada, me encontré con una de las soluciones de Azure en el campo del desarrollo de aplicaciones móviles, que le permite sincronizar datos de la tabla SQLite entre dispositivos, pero después de pensarlo detenidamente, seguí con la elección inicial.
Por cierto, hacer la elección inicial no fue difícil, ya que Microsoft solicitó cortésmente una lista de tecnologías que el desarrollador de UWP probablemente tendría que enfrentar. En las últimas versiones de Visual Studio, al crear un nuevo proyecto para UWP, verá una página con recomendaciones para comenzar, donde uno de los enlaces dice "Agregar un servicio recomendado". Al hacer clic en este enlace, se abre la pestaña "Conectar el servicio" y ya en él vemos la opción "Almacenamiento en la nube con el servicio de almacenamiento de Azure".
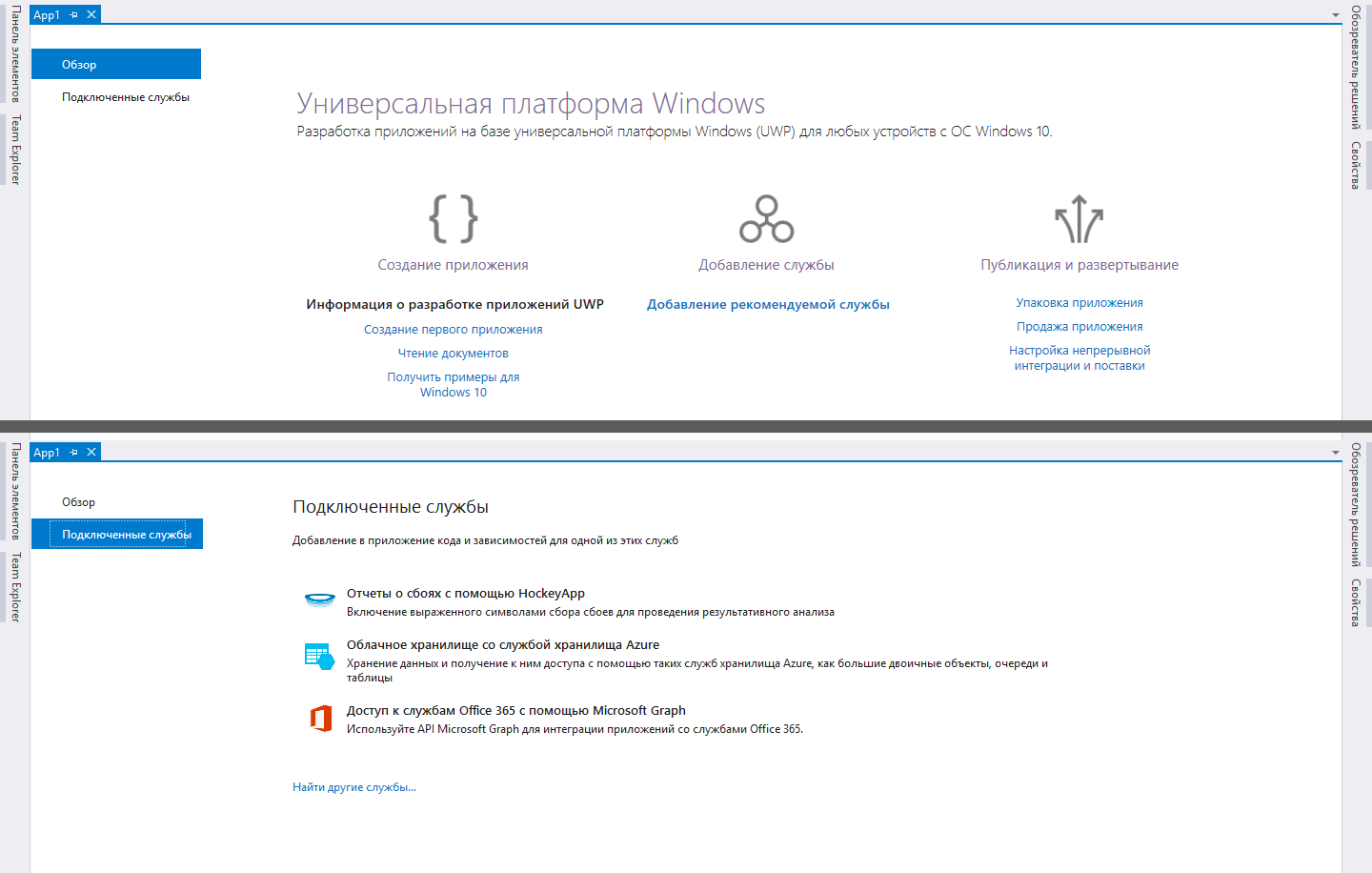
La intuición sugiere que esto es exactamente lo que necesita, por lo que decidí centrarme en un estudio en profundidad de este problema con miras a un mayor uso en el proyecto.
El almacenamiento en la nube es un conjunto de varios productos para diferentes tareas, que se pueden leer más
aquí , pero estaba principalmente interesado en el almacenamiento de tablas, que resultó ser la base de datos NoSQL.
NoSQL es una base de datos sin esquema, es decir, una en la que la tabla no necesita ser estructurada de antemano. De hecho, la tabla en este caso es solo parte de la ruta a lo que se llama la sección, lo que significa que una sola tabla puede contener filas, por ejemplo, con tres y cinco columnas a la vez. Para comprender completamente las características del almacenamiento de la tabla, le aconsejo que lea detenidamente el
manual , pero consideraré este tema desde mi punto de vista mundano, porque al final el material está dirigido a principiantes, quienes soy yo en este tema.
Para comenzar, descubramos cómo crear una tabla NoSQL:1. Registre una cuenta de Azure
gratuita . Si tiene una suscripción a MSDN o BizSpark y ya está activada en Azure, puede omitir este paso. Una cuenta gratuita le otorga un préstamo de $ 200 durante el primer mes y luego acceso gratuito a una cierta cantidad de recursos de la mayoría de los servicios de Azure. Traducido a un lenguaje comprensible, todo se hace de tal manera que no tendrá que pagar hasta que su producto gane lo suficiente para cubrir los gastos, sin mencionar el uso de Azure para la autoeducación.
Pero incluso si cruza el umbral libre, los precios para el almacenamiento de una tabla son mucho más leales que para una cantidad similar de bases de datos SQL. Por ejemplo, al momento de escribir este artículo, he creado dos tablas, hasta ahora con solo una entrada. Durante 18 días del período de informe, recurrí a ella en promedio 20-30 veces al día y se cancelaron 2 kopeks de la cuenta de crédito para este período. Al aumentar dichos costos para el volumen planificado, me di cuenta de que están más que cubiertos por los ingresos potenciales de la aplicación.
2. Ahora que tiene una cuenta en Azure, procedemos a crear una cuenta de almacenamiento.
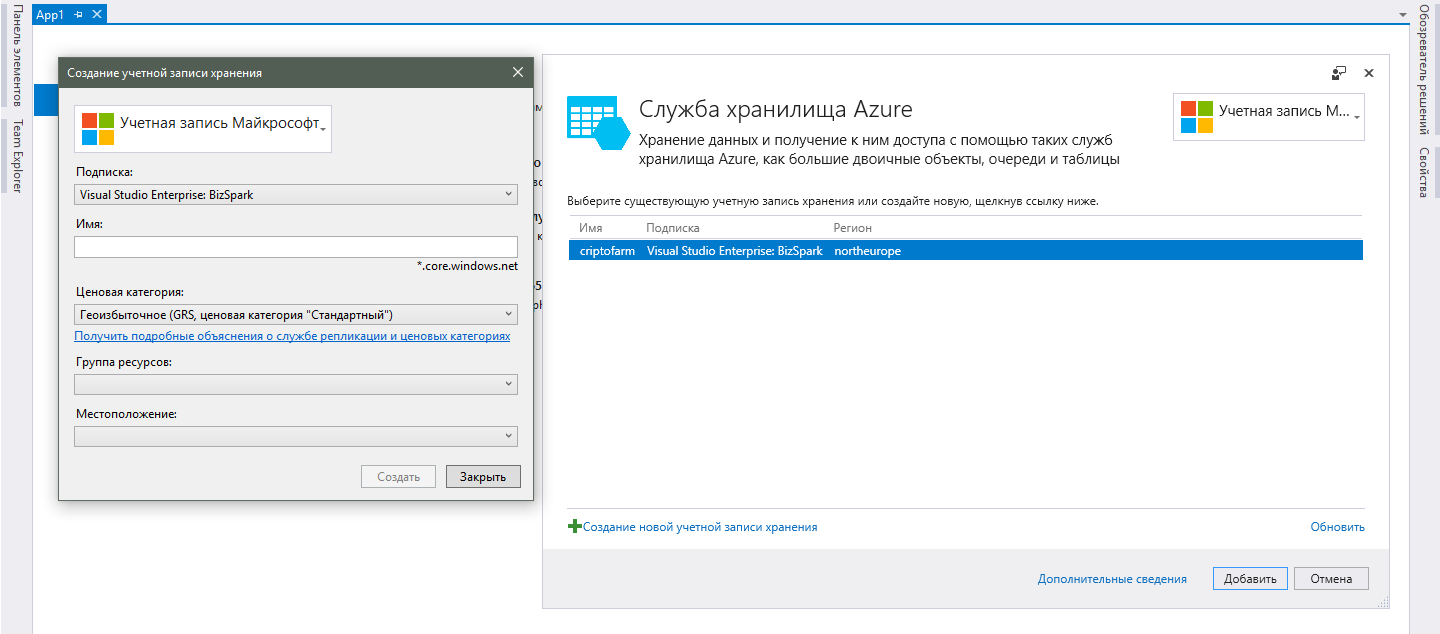
Puede hacer todo esto desde la misma página de conexión de Visual Studio Services, que describí anteriormente. Si de repente cerró esta página, puede abrirla haciendo doble clic en "Servicios conectados" en el Explorador de soluciones. Después de seleccionar el servicio requerido, se abrirá una ventana con las cuentas de almacenamiento disponibles y, para agregar una nueva, haga clic en el botón correspondiente.
En la nueva ventana, deberá realizar los siguientes pasos:- Para comenzar, deberá iniciar sesión con su cuenta de Microsoft. Debe usar la cuenta a la que están vinculadas sus suscripciones o una cuenta de Azure gratuita.
- Después de iniciar sesión en su cuenta, su suscripción (a) aparecerá en el campo "Suscripción". Todo es simple con la elección, por lo que los comentarios son superfluos.
- En el campo "Nombre", especifique el nombre deseado del servicio de almacenamiento. Dado que este también es el nombre de dominio del servicio, debe ser único en todas las cuentas disponibles en Azure, y no solo en el suyo.
- El campo "Categoría de precios" requerirá que comprenda las diferencias entre una plataforma en la nube y el alojamiento convencional, ya que al hacer clic en el enlace debajo del campo puede ver una lista de precios, pero no una explicación inteligible, que le brinda cada opción. Por supuesto, en la naturaleza de los enlaces de sitio puede encontrar información completa sobre todas estas abreviaturas como GRS y LRS, pero esto es superfluo para el desarrollador promedio. Es suficiente entender que cuanto más cara sea la tarifa, más centros de datos estarán involucrados en el procesamiento y almacenamiento de sus datos y mayor será la probabilidad de su seguridad. Para un proyecto pequeño, la tasa LRS más baja está bien.
- Un "grupo de recursos" es una combinación de varios servicios de Azure para una sola administración. En nuestro caso, cree uno nuevo, asigne cualquier nombre descriptivo y continúe.
- Lo último que debe elegir es la "Ubicación" de su servicio. Por ubicación se entiende la ubicación real de los centros de datos que serán responsables de trabajar con nuestros datos. Tenga en cuenta que hablo en plural, ya que en una región puede haber varios centros de datos y el trabajo se puede distribuir entre ellos (en caso de que elija una categoría de precios de asesoramiento). Elija el que esté más cerca de su base de usuarios principal. Sin embargo, si planea crecer a la escala de todo el mundo y necesita una respuesta máxima en cualquier parte del mundo, nadie lo molestará por cada versión regional de la aplicación para crear una cuenta de almacenamiento separada e implementar la sincronización de datos entre ellos. Es un alto nivel de extensibilidad que es la principal ventaja de la nube.
3. Después de crear la cuenta de almacenamiento, se agregará a la lista y puede continuar haciendo clic en el botón "Agregar". El resultado de esta acción será agregar un paquete NuGet para trabajar con Azure en el proyecto y guardar la cadena de conexión en el archivo app.config del proyecto.
Desafortunadamente, es imposible trabajar con valores de este archivo en UWP (o posiblemente con muletas terribles), así que simplemente copie la cadena de conexión al servicio de almacenamiento desde allí a un lugar conveniente en el proyecto y continúe con el siguiente paso.
4. Ahora queda crear una tabla y comenzar a trabajar con ella. Y aquí comienza el trabajo individual, dependiendo directamente de las tareas.
El hecho es que antes de comenzar a crear tablas, debe pensar cuidadosamente sobre la arquitectura para almacenar sus datos. Trabajar con el almacenamiento de la tabla es tan conveniente que crear una nueva tabla directamente desde el código es solo cuestión de unas pocas líneas, y con esa conveniencia existe un deseo natural de asignar una tabla separada para cada usuario, porque la tarea final es sincronizar los datos entre sus dispositivos. Sin embargo, cuando trabaje con una tecnología desconocida, no debe tomar decisiones apresuradas y debe sopesar cuidadosamente los pros y los contras. Un
artículo especial
en el manual puede ayudar a tomar la decisión correcta, pero prepárese para tener que volver a leerlo varias veces, ya que es muy difícil aprender todos los datos de inmediato, especialmente teniendo en cuenta la gran cantidad de términos nuevos.
Continuaré la historia teniendo en cuenta el hecho de que aún leyó el manual y comprendió algunas de las características de trabajar con el almacenamiento de tablas. Por ejemplo, me di cuenta de que conceptualmente una tabla no es una especie de unidad aislada y es más bien un lugar para una agrupación lógica de registros. Esto es fácil de entender si presenta la tabla como una carpeta en la que almacena archivos de datos. Una carpeta por sí sola no ocupa espacio y no es una parte integral de los archivos, sino que simplemente define una parte de la ruta a los archivos que son lógicos, pero no necesarios, para guardarse en esta carpeta.
La conclusión de esto es bastante simple: nadie se molesta en almacenar la configuración de todos los usuarios en una tabla, lo principal es que el par de valores en las columnas PartitionKey y RowKey son únicos dentro de la tabla. Esto se implementa nuevamente en mi proyecto, ya que la ID de usuario actuará como PartitionKey y, por ejemplo, la cadena "UserName" como RowKey, lo que nos permitirá determinar el registro único en el que se almacena el nombre de usuario. Pero como dije anteriormente, debemos sopesar todos los pros y los contras, así que sopesemos:
- "Para" una tabla separada para los datos de cada usuario es la conveniencia de percibir la estructura de datos. Si tomamos la tabla como una carpeta con archivos, entonces es lógico que todos los archivos de un usuario estén en la misma carpeta y es más común trabajar con dicha arquitectura.
- Todos los demás factores están "en contra" de una tabla separada. Datos del usuario dentro de una tabla separada: esto es convenientemente preciso hasta que el número de tales tablas sea de miles. Dado que la cuenta de almacenamiento está en un nivel superior a la tabla, no se les proporciona ninguna otra agrupación.
Dada la base de usuarios potenciales, corremos el riesgo de ahogarnos en miles de tablas individuales, perdiendo aquellas que tienen algún valor de prioridad. Al mismo tiempo, almacenar la configuración de todos los usuarios en una tabla simplifica la administración y trabaja con datos para recopilar información estadística o implementar funciones sociales.
Además, el bajo costo de usar el almacenamiento de tablas le permite duplicar cualquier dato en tablas separadas, de acuerdo con la lógica requerida. En particular, planeo crear una tabla adicional con el nombre de usuario, un enlace al avatar y una indicación de pertenencia al país, que se utilizará para clasificar tablas u otras funciones sociales que se pueden agregar a la aplicación.
Entonces, cuando descubrió la estructura de almacenamiento de datos, finalmente agreguemos una nueva tabla. Como nos negamos a crearlo a nivel de código, quedan dos opciones: a través del portal web de Azure o usando la herramienta especial Microsoft Azure Storage Explorer, que se puede descargar desde storageexplorer.com. En ambos casos, es necesario seleccionar la cuenta de almacenamiento deseada y en la sección "Servicio de tablas / tablas", seleccione "+ Tabla / Crear tabla". En el cuadro de diálogo que aparece, ingrese el nombre deseado y confirme los cambios.
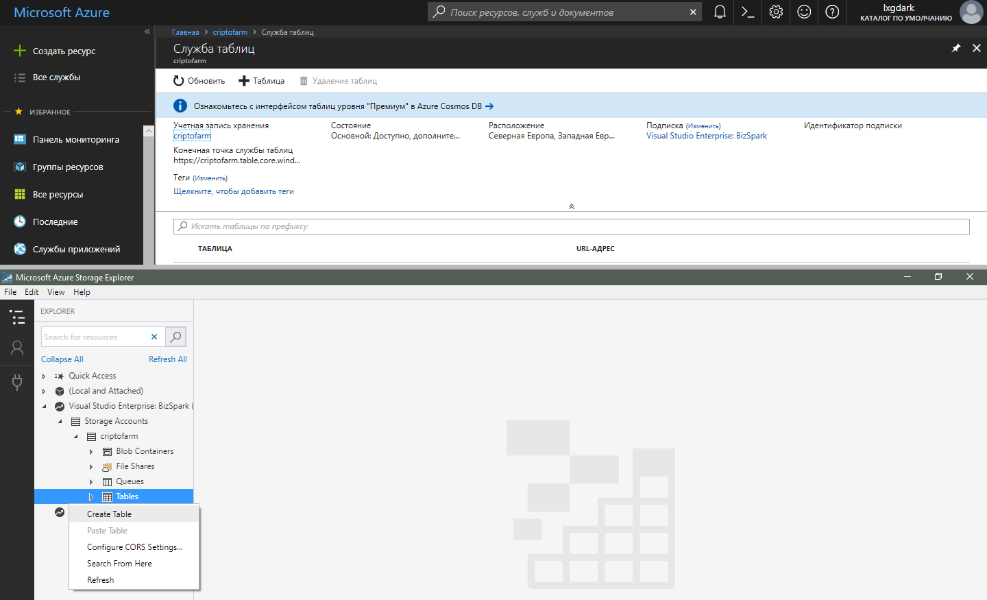
Después de eso, puede trabajar con la nueva tabla del código sin ningún problema.
Las operaciones principales que realizaré con la tabla son la inserción y extracción de filas, que se denominan "entidades" en la terminología de almacenamiento de la tabla. Tal término es más fácil de entender cuando se da cuenta de que para insertar y recuperar una entidad, deberá asignarla a una clase heredada de TableEntity de Microsoft.WindowsAzure.Storage.Table. La clase sucesora ya contendrá algunos campos obligatorios, como, por ejemplo, PartitionKey (nombre de sección) y RowKey (nombre de línea), y aquellos campos que implementemos independientemente serán columnas en la línea (propiedades de la entidad).
Considere un ejemplo de una tabla en la que se almacenará una lista de todos los jugadores con su nombre, avatar y afiliación de país.
: Imports Microsoft.WindowsAzure.Storage Imports Microsoft.WindowsAzure.Storage.Table
Decidí poner los métodos para trabajar con la tabla en una clase separada para la conveniencia de trabajar desde diferentes puntos de la aplicación. Créelo e inmediatamente agregue las constantes previamente conocidas:
Public Class AzureWorker Private Const AzureStorageConnectionString As String = " , app.config" Private Const GamerListTableNameString As String = "GamerList" ' … End Class
Ahora necesitamos crear una clase que asignaremos a la entidad (fila) dentro de la tabla:
Private Class GamerListClodTableDataClass Inherits TableEntity Public Const RowKeyValue As String = "UserID" Public Sub New () RowKey = RowKeyValue End Sub Public Property UserName As String = "" Public Property UserountryID As String = "" Public Property UserAvatar As String = "" End Class
La clase a mapear debe ser heredada de TableEntity y tener campos para los datos que planeamos colocar en la tabla. Tenga en cuenta que no es necesario establecer valores para RowKey o PartitionKey en el nivel de clase, pero en mi caso, RowKey se establece porque es inmutable independientemente de otra entrada.
Pero, dado que en esta etapa probablemente no entendiste completamente la esencia de trabajar con el almacenamiento de la tabla, explicaré la lógica establecida en esta etapa. La forma más rápida de trabajar con una tabla es consultar a la entidad por el nombre de la cadena y el nombre de la sección, por lo que debe conocer estos datos de antemano. Además, la combinación de PartitionKey y RowKey debe ser única dentro de la tabla, lo que significa que es lógico escribir una ID de usuario única en una de estas teclas y asignar a la segunda clave cualquier nombre que siempre sabremos. Esto es exactamente lo que se hace en la clase GamerListClodTableDataClass.
La última etapa preparatoria antes de las consultas directas a la tabla es la creación de su objeto en una función separada:
Private Shared Function GetCloudTable(tableName As String) As CloudTable Dim storageAccount As CloudStorageAccount = CloudStorageAccount.Parse(AzureStorageConnectionString) Dim tableClient As CloudTableClient = storageAccount.CreateCloudTableClient() Dim table As CloudTable = tableClient.GetTableReference(tableName) Return table End Function
Esto se hace para no duplicar el código cada vez que queremos leer o escribir datos en la tabla. Tenga en cuenta que este código no realiza solicitudes directas a la nube y se ejecutará sin problemas cuando no haya conexión. Todo lo que hace es crear paso a paso un objeto de tabla a partir de datos existentes, como la cadena de conexión de almacenamiento y el nombre de la tabla.
Finalmente, pasemos a trabajar directamente con la tabla y comencemos guardando los datos de usuario actuales:
Public Shared Async Function SavedOrUpdateUserData(u As UserManager) As Task(Of Boolean) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim UserDataClodTableData As New GamerListClodTableDataClass With {.PartitionKey = u.UserId, .UserName = u.UserName.Trim, .UserountryID = u.UserountryID, .UserAvatar = "https://apis.live.net/v5.0/" & u.UserId & "/picture"} Dim insertOperation As TableOperation = TableOperation.InsertOrReplace(UserDataClodTableData) Await table.ExecuteAsync(insertOperation) Return True End If Catch ex As Exception End Try Return False End Function
La solicitud se realiza como una función asincrónica para que el código de llamada pueda obtener el resultado de la ejecución (True en caso de éxito y False en caso de error). Además, un parámetro del tipo UserManager se pasa a la función, que es una referencia a la clase con datos del usuario. Creamos tal clase en un artículo anterior, con la única diferencia de que en esta versión hay un campo UserountryID que almacena datos sobre el país del usuario.
Para consultas a la tabla, primero debe crear su objeto usando la cadena de conexión al repositorio y el nombre de la tabla (anteriormente hemos puesto este proceso en una función separada). A continuación, debe verificar la existencia de la tabla y, aunque estamos seguros de que tenemos una tabla con ese nombre, puede producirse un error, por ejemplo, debido a la falta de conectividad de red o debido a una falla en la nube (por lo que este código se coloca en Try / Captura). Luego, antes de escribir en la tabla, debe crear una instancia de la clase UserDataClodTableData y asignar el valor requerido a sus campos y solo luego crear la operación InsertOrReplace. Como puede adivinar por el nombre de la operación, insertará una nueva fila en la tabla si las filas con el mismo par de PartitionKey y RowKey no existen en la tabla y reemplazará los datos si dicha fila ya existe. Bueno, el equipo final de ExecuteAsync, de hecho, realizará la acción planificada en el lado del almacenamiento de la tabla.
Leer datos de una tabla es tan fácil como escribirlo. Por ejemplo, solicitemos un nombre de usuario:
Public Shared Async Function GetUserName(id As String) As Task(Of String) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim retrieveOperation As TableOperation = TableOperation.Retrieve(Of GamerListClodTableDataClass)(id, GamerListClodTableDataClass.RowKeyValue) Dim retrievedResult As TableResult = Await table.ExecuteAsync(retrieveOperation) If retrievedResult.Result IsNot Nothing Then Return CType(retrievedResult.Result, GamerListClodTableDataClass).UserName End If End If Catch ex As Exception End Try Return "" End Function
Este código casi no difiere del anterior y también comienza creando un objeto de tabla y verificando su existencia. Además, como en la grabación, creamos una operación, pero esta vez una operación de extracción, que requiere la indicación de PartitionKey y RowKey. Después de eso, extraemos el resultado usando ExecuteAsync y trabajamos con el objeto resultante del tipo TableResult, que en realidad se reduce a convertir la propiedad Result al tipo de la clase que se está asignando y extraer el nombre de usuario.
Trabajar con una tabla no se limita a las operaciones de lectura y escritura y admite muchos scripts diferentes. Por ejemplo, puede crear una consulta que extraiga todas las entidades con la PartitionKey especificada o todas las entidades que tengan el campo especificado, pero es importante recordar la velocidad de tales operaciones, así como la cantidad de datos que se transmitirán a través de la red.
El ejemplo anterior es el más óptimo desde el punto de vista de la velocidad de consulta, ya que el sistema de direccionamiento probablemente encontrará una entidad a lo largo de la ruta "nombre de almacenamiento \ nombre de tabla \ PartitionKey + RowKey", sin embargo, para obtener solo un nombre, cargamos toda la entidad como un todo, lo que no es beneficioso sobre la cantidad de datos transferidos.
El siguiente es un código de función modificado que tiene en cuenta la optimización máxima de la consulta:
Public Shared Async Function GetUserName(id As String) As Task(Of String) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim projectionQuery As TableQuery(Of DynamicTableEntity) = New TableQuery(Of DynamicTableEntity)().Where(TableQuery.CombineFilters(TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, id), "and", TableQuery.GenerateFilterCondition("RowKey", QueryComparisons.Equal, GamerListClodTableDataClass.RowKeyValue))).Select({"UserName"}) Dim resolver As EntityResolver(Of String) = Function(pk, rk, ts, props, etag) Return props("UserName").StringValue End Function Dim result As TableQuerySegment(Of String) = Await table.ExecuteQuerySegmentedAsync(projectionQuery, resolver, Nothing) If result.Count > 0 Then Return result(0) End If End If Catch ex As Exception End Try Return "" End Function
En lugar de crear un objeto de operación, en este código creamos un objeto de solicitud que contiene varios métodos para determinar qué debe obtenerse como resultado. El método Where crea un filtro que indica la necesidad de devolver solo aquellas filas para las cuales PartitionKey y RowKey son iguales a los valores especificados, y la siguiente selección indica que solo se necesita seleccionar la columna UserName.
Con tal consulta, no tiene sentido comparar el resultado con ninguna clase, por lo tanto, IDictionary se usa como valor de retorno, donde la clave es el nombre de la columna y el valor es su contenido. Dado que la función ExecuteQuerySegmentedAsync no sabe qué resultado de su ejecución se obtendrá, es posible (y en este caso necesario) pasar un delegado EntityResolver, que se refiere a una función que toma el valor deseado del diccionario. El resultado de todo esto se convierte en TableQuerySegment en el primer índice del cual se almacena el nombre del usuario solicitado.
En general, el uso de consultas en lugar de la operación de extracción básica le permite ampliar significativamente las posibilidades de trabajar con una tabla, pero tenga cuidado, porque a diferencia del SQL clásico, aquí la velocidad de procesamiento de consultas depende directamente de sus parámetros. Nadie se molesta en ejecutar una consulta para recuperar todos los registros de usuario cuyos nombres son iguales al dado, pero dicha consulta será más larga que su contraparte en SQL. Para aprender esto, una vez más lo dirijo a la guía de diseño de tablas que mencioné anteriormente, y también le recomiendo que estudie el
artículo , que proporciona ejemplos sobre cómo trabajar con el almacenamiento de tablas.
Importante! Los artículos de enlace usan código para aplicaciones .NET clásicas y son diferentes de la implementación de UWP. Afortunadamente, esta diferencia no es significativa y los análogos son intuitivos (la mayoría de las veces están en el prefijo Async).En conclusión, compartiré los resultados del uso del almacenamiento de Azure en mi proyecto en este momento. En el primer inicio, después de recibir la identificación de usuario y descargar datos de Live ID, le sugiero que elija un alias (apodo) en caso de que el nombre almacenado en el perfil no sea adecuado para él. Luego, el apodo ingresado se guarda en la clase UserManager en lugar del estándar, y todos estos datos se guardan en la tabla GamerList. En el siguiente inicio, la identificación de usuario se recibe en segundo plano y se solicita un alias de la tienda. Como resultado, el usuario ve su apodo en el juego, y no el nombre del perfil estándar.
También en el futuro, una tabla con una lista de usuarios será útil para ingresar funciones sociales en el juego y, ahora, he creado al menos una aplicación para estos datos. En la implementación de esta tarea, las herramientas de Azure, como el Almacenamiento en cola y las Funciones de Azure, me ayudarán nuevamente, pero hablaré sobre esto en uno de los siguientes artículos.