Para saber qué son los cachés, qué es el Caché de resultados, cómo se hace en Oracle y en otras bases de datos no es muy interesante y bastante repetitivo. Pero todo adquiere colores completamente diferentes cuando se trata de ejemplos específicos.
Alexander Tokarev (
shtock ) construyó su informe sobre Highload ++ 2017 basado en casos. Y fue precisamente sobre la base de los casos que dijo cuándo podría ser conveniente un caché hecho en casa, cuál es el dolor del caché de resultados del lado del servidor y cómo reemplazarlo por uno del lado del cliente, y en general presentó una serie de consejos útiles para configurar el caché de resultados en Oracle.
Sobre el orador: Alexander Tokarev trabaja en DataArt y se ocupa de cuestiones relacionadas con las bases de datos, tanto en términos de construir sistemas desde cero como de optimizar los existentes.
Comencemos con algunas preguntas retóricas. ¿Has trabajado con Oracle Result Cache? ¿Cree que Oracle es una base de datos adecuada para todas las ocasiones? Según la experiencia de Alexander, la mayoría de las personas responden negativamente a la última pregunta:
cien soñadores tienen un soñador . Pero gracias a su fe, el progreso se está moviendo.
Por cierto, Oracle ya tiene 14 bases de datos, hasta ahora 14, lo que sucederá en el futuro es desconocido.
Como ya se mencionó, todos los problemas y soluciones se ilustrarán con casos específicos. Estos serán dos casos de proyectos de DataArt y un ejemplo de un tercero.
Cachés de bases de datos
Para empezar, qué cachés están en las bases de datos. Todo está claro aquí:
- Buffer cache - data cache - cache para páginas de datos / bloques de datos;
- Caché de declaraciones: caché de declaraciones y sus planes: caché de plan de consultas;
- Caché de resultados - caché de resultados de filas - filas de consultas;
- Caché del sistema operativo: caché del sistema operativo.
Además, la caché de resultados, en general, se usa solo en Oracle. Una vez estuvo en MySQL, pero luego fue heroicamente cortado. En PostgreSQL tampoco está allí, está presente de una forma u otra solo en el producto pgpool de terceros.
Caso 1. Bóveda del minorista
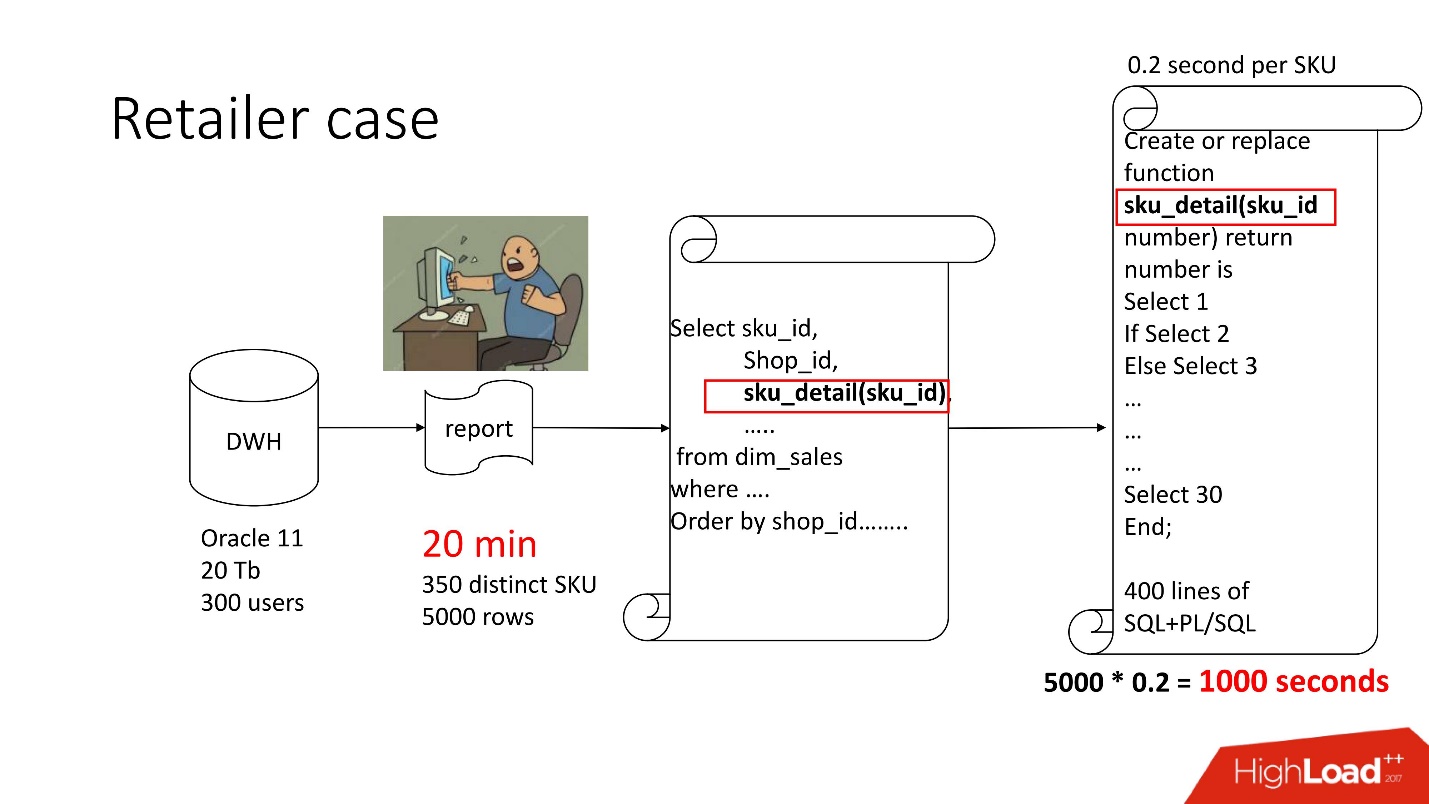
Arriba está el diagrama del producto que acompañamos: el repositorio (Oracle 11, 20 Tb, 300 usuarios), y contiene algún tipo de informe triste, en el que había 350 productos únicos por 5000 líneas de datos. Conseguirlo tardó unos 20 minutos, y los usuarios estaban tristes.
La presentación de este informe, como todos los demás, está disponible en el sitio de la conferencia Highload ++.
Este informe tiene SELECCIONAR, UNIRSE y una función. Una función como función, todo estaría bien, solo que calcula un parámetro misterioso llamado "valor de precio de transferencia", funciona durante 0.2 s, parece que no es nada, pero se llama tantas veces como haya filas en la tabla. Esta función tiene 400 filas de SQL + PL / SQL, ya que el producto está en soporte, da miedo cambiarlo.
Por la misma razón, no se pudo utilizar result_cache.
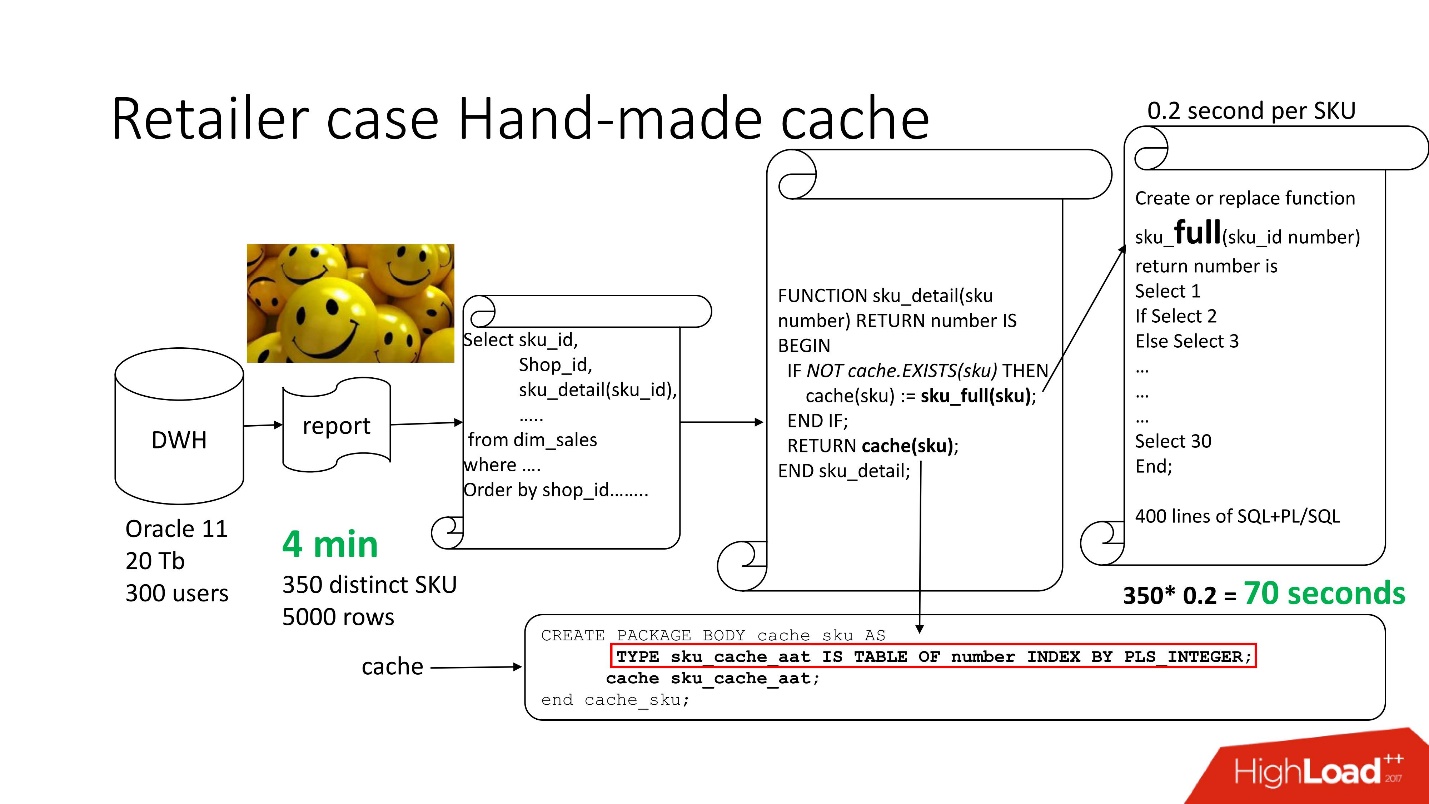
Para resolver el problema, utilizamos el
enfoque estándar
con el almacenamiento en caché hecho a mano : dejamos los primeros 3 bloques del circuito, tal como estaban, simplemente cambie el nombre de nuestra función sku_detail () a sku_full () y declaremos una matriz asociativa, donde respectivamente:
- las claves son nuestros SKU (artículos básicos),
- Los valores son el precio de conversión de transferencia calculado.
Hacemos que la función de caché (sku) sea obvia: si no hay tal identificación en nuestra matriz asociativa, nuestra función se inicia, el resultado se almacena en caché, se guarda y se devuelve. En consecuencia, si tal identificación es, entonces todo esto no sucede. De hecho, tenemos
caché bajo demanda .
Por lo tanto, hemos reducido el número de llamadas a funciones a la cantidad que realmente se necesita.
El tiempo de procesamiento de informes disminuyó a 4 minutos , todos los usuarios se sintieron bien.
Memoria de caché hecha a mano
Las desventajas y ventajas de este sistema son claras a partir de esta gran imagen inteligente, que abordaremos mucho: esta es la arquitectura de memoria.
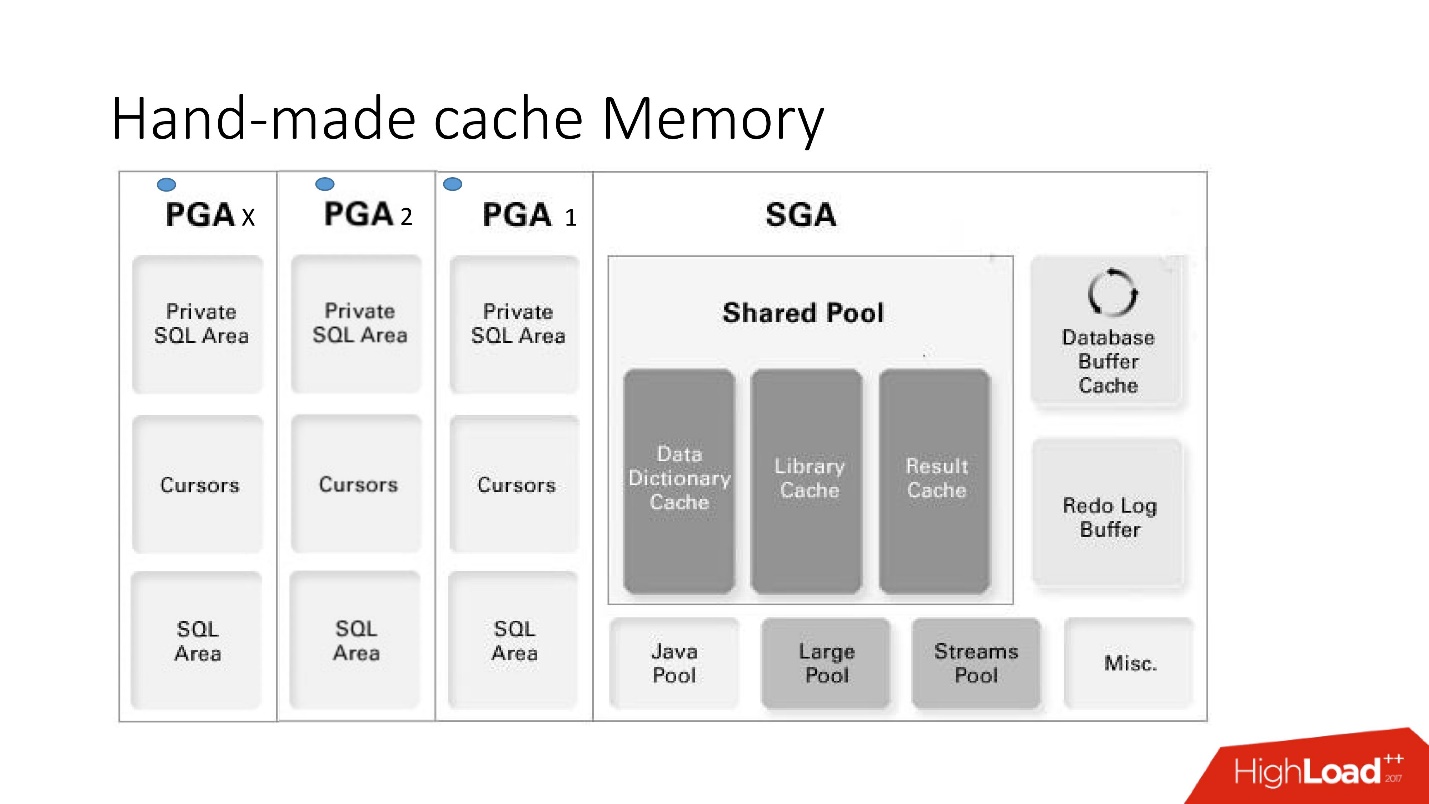
Es importante comprender en qué área de memoria se encuentran las colecciones. Se colocan en un área de memoria llamada PGA.
El área global del programa se instancia en cada conexión a la base de datos. Esto es lo que determina las ventajas y desventajas, ya que más conexiones: más memoria y
memoria costosa, servidor , administradores son tiernos.

- Pros: todo funciona muy rápido, muy fácil de hacer, no se necesita configuración, no hay problemas con la participación entre procesos.
- Las desventajas son comprensibles: si la lógica almacenada está prohibida en el proyecto, no se pueden usar, no existe un mecanismo para la invalidación automática, y dado que la memoria en el caché se asigna dentro de una sesión de la base de datos, no una instancia, su consumo se exagera . Además, en el caso del uso del grupo de conexiones, debe recordar vaciar los cachés si debe haber un almacenamiento en caché diferente para cada sesión.
Hay otras opciones para cachés hechos a mano basados en vistas materializadas, tablas temporales, pero de ellos hay una gran carga en el sistema de entrada-salida, por lo que aquí no los consideramos. Son más aplicables a otras bases de datos en las que estos problemas generalmente se resuelven almacenando el procedimiento almacenado en alguna tabla intermedia y tomando los datos de esta antes de acceder a una solicitud pesada. Y solo si no se encontró lo que se necesita, se llama a la solicitud inicial.

Lo anterior es una ilustración de este enfoque del problema de almacenamiento en caché para obtener una lista de productos relacionados en MsSQL. En general, el enfoque es relativamente similar, pero no funciona en la memoria de la base de datos tanto en términos de obtención de datos como de llenado primario, debido a esto
puede ser más lento .
En general, result_cache casero se utiliza activamente, pero result_cache en la base de datos es un enfoque diferente para la implementación de esta tarea. Lo y cómo no funcionó la victoria rápida lo consideraremos más a fondo.
Caso 2. Tramitación de documentación financiera.
Entonces, nuestro segundo caso.
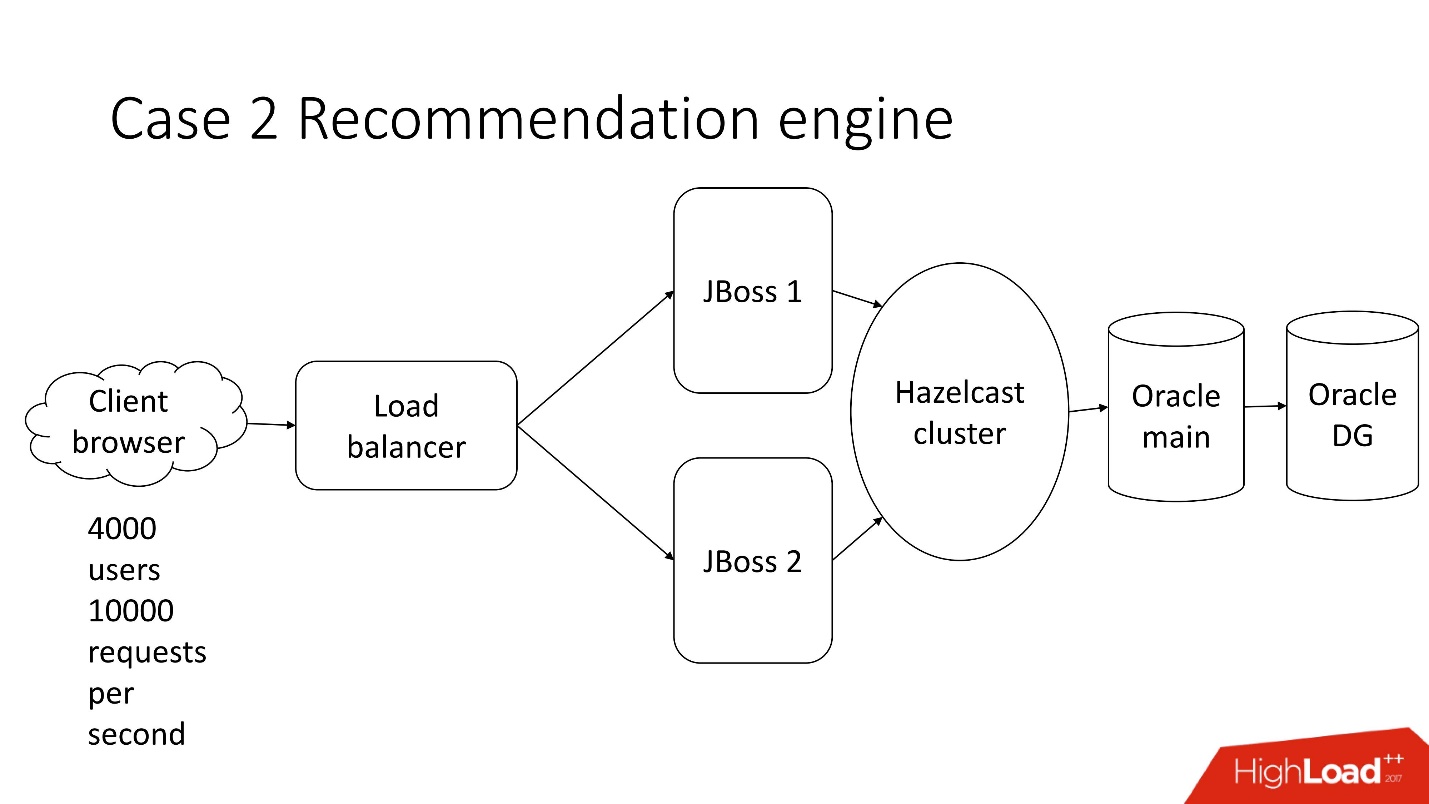
Este es un sistema de procesamiento de documentación financiera semiautomatizado, una empresa triste con una arquitectura clásica, que incluye:
- cliente ligero
- 4.000 usuarios que viven en diferentes partes del mundo;
- equilibrador
- 2 JBoss para calcular la lógica de negocios;
- clúster en memoria;
- núcleo de Oracle;
- Copia de seguridad de Oracle
Una de las muchas tareas de este sistema es el
cálculo de recomendaciones .

Hay documentos, para cada indicador que el sistema no reconoce automáticamente, se ofrece un conjunto de indicadores de documentos de clientes anteriores, de una industria similar o de una rentabilidad similar, mientras que el indicador se compara con el valor reconocido para no ofrecer demasiado. Lo que es importante, los
documentos son multilingües .
El usuario selecciona el valor deseado y repite la operación para cada línea vacía.
Simplificada, esta tarea consiste en lo siguiente: los documentos llegan en forma de pares clave-valor de diferentes sistemas de reconocimiento, y los parámetros se reconocen en algún lugar, pero no en algún lugar. Es necesario asegurarse de que al final los usuarios procesen los documentos y se reconozcan todos los valores. La recomendación está dirigida precisamente a simplificar esta tarea y tiene en cuenta:
- Multilingüismo: unos 30 idiomas. Cada idioma tiene sus propias características, sinónimos y otras características.
- Los datos previos de este cliente, o, en ausencia de los mismos, los datos de un cliente de la misma industria o un cliente similar en ganancias.
De hecho, se trata de 12 reglas muy complejas.
Suposiciones iniciales:- No más de 100 usuarios a la vez;
- 2-3 columnas para reconocimiento;
- 100 lineas.
No hay mucha carga , todo es aburrido.
Entonces, es hora de su lanzamiento. Se produjo la congelación de código, Java tiene miedo de tocar y se tarda al menos 5 minutos en procesar un documento.
Acuden al equipo de desarrollo de la base de datos pidiendo ayuda. Por supuesto, porque
si algo se ralentiza en la JVM, entonces, por sí solo, debe cambiar o reparar la base de datos .

Estudiamos los documentos y nos dimos cuenta de que en pares clave-valor los valores a menudo se repiten, 5-10 veces. En consecuencia, decidimos usar la base de datos para almacenar en caché, porque ya se ha probado.
Decidimos usar la caché de resultados del lado del servidor de Oracle porque:
- Se han agotado las oportunidades para optimizar SQL, porque utiliza el motor de búsqueda de texto completo de Oracle;
- el caché se usará para parámetros duplicados;
- La mayoría de los datos para las recomendaciones se recalculan una vez por hora, ya que utilizan un índice de texto completo;
- PL / SQL está prohibido .
Caché de resultados de Oracle
Caché de resultados (almacenamiento en caché de resultados de Oracle) tiene las siguientes propiedades:
- Esta es el área de memoria en la que se examinan todos los resultados de la consulta;
- lee de forma coherente y se produce su invalidación automática;
- Se requieren cambios mínimos en la aplicación. Puede hacer que la aplicación no necesite ser cambiada;
- bono: puede almacenar en caché la lógica PL / SQL, pero está prohibido aquí.
¿Cómo habilitarlo?Método número 1
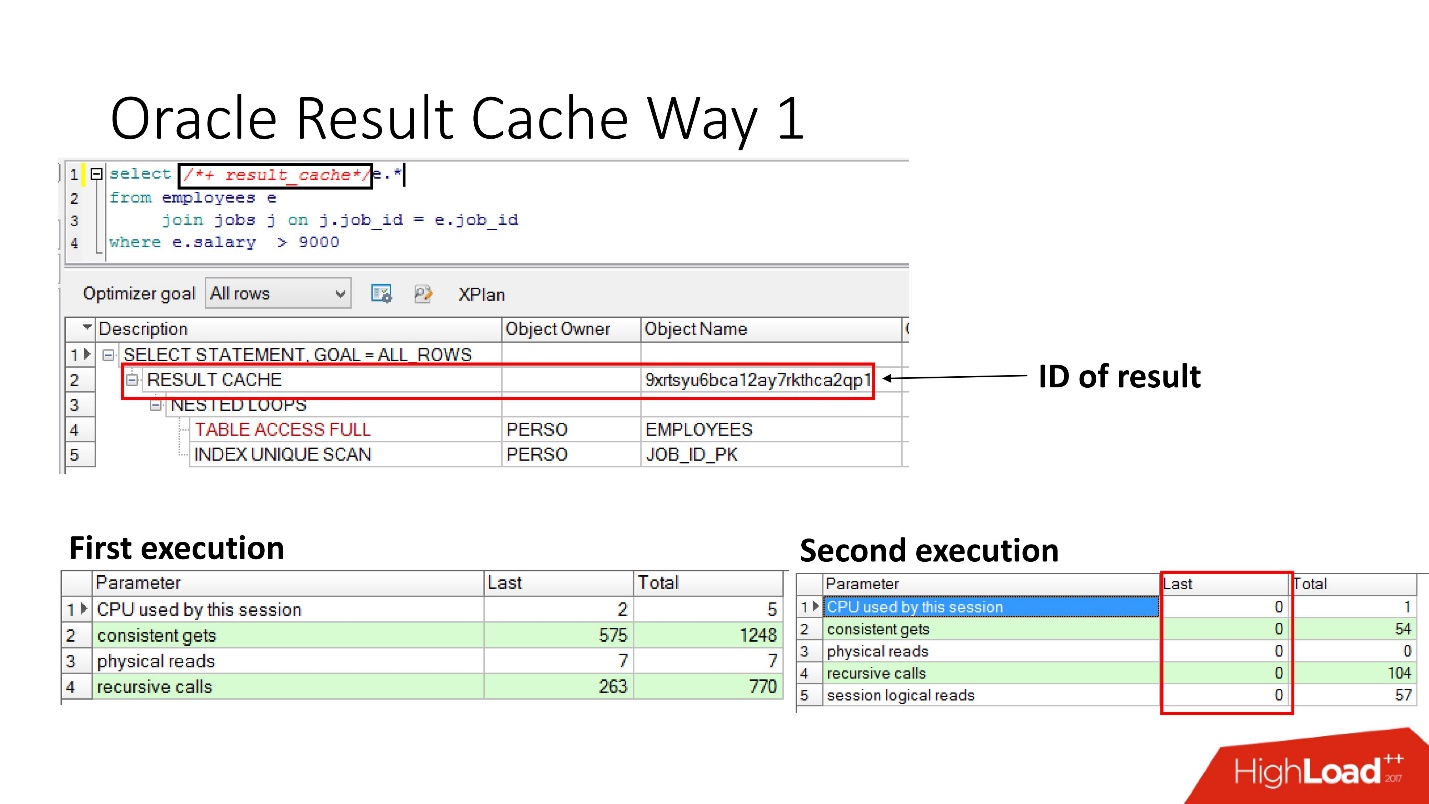
Es muy simple
especificar la instrucción result_cache . La diapositiva muestra que ha aparecido el identificador del resultado. En consecuencia, la primera vez que se ejecuta la consulta, la base de datos hará algún trabajo; durante la ejecución posterior, en este caso no se necesita trabajo. Todo esta bien.
Método número 2
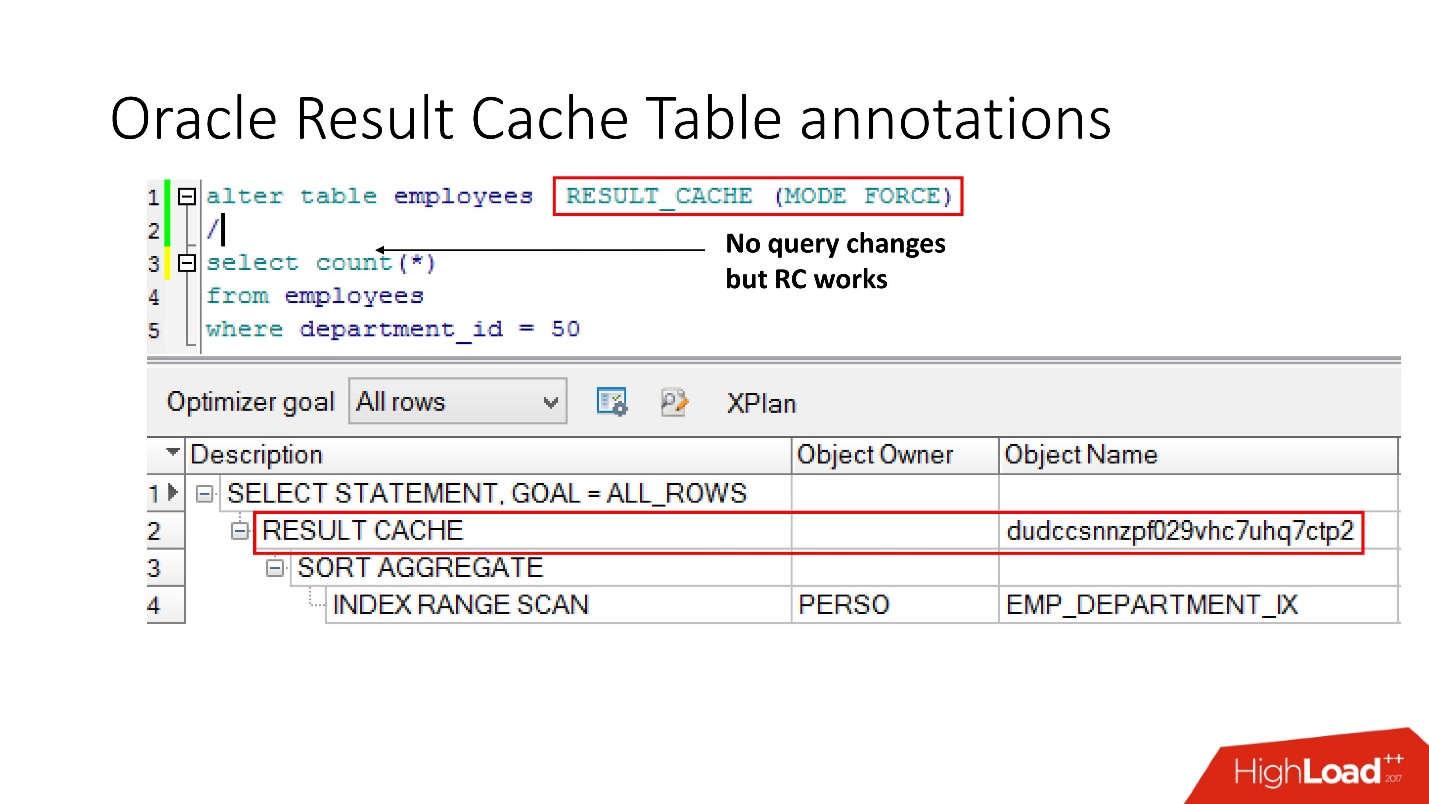
La segunda forma permite a los desarrolladores de aplicaciones no hacer nada: estas son las llamadas anotaciones. Indicamos una marca de verificación para la tabla en la que la solicitud debe colocarse en result_cache. En consecuencia, no hay ninguna pista, no tocamos la aplicación, y todo ya está en result_cache.
Por cierto, ¿qué crees que si una consulta se refiere a dos tablas, una de las cuales está marcada como result_cache y la segunda no, es el resultado de dicha consulta en caché?
La respuesta es no, en absoluto.
Para que se almacene en caché, todas las tablas que participan en la consulta deben tener una anotación result_cache.
Seguimiento de dependencias
Hay vistas relevantes en las que puede ver qué dependencias son.
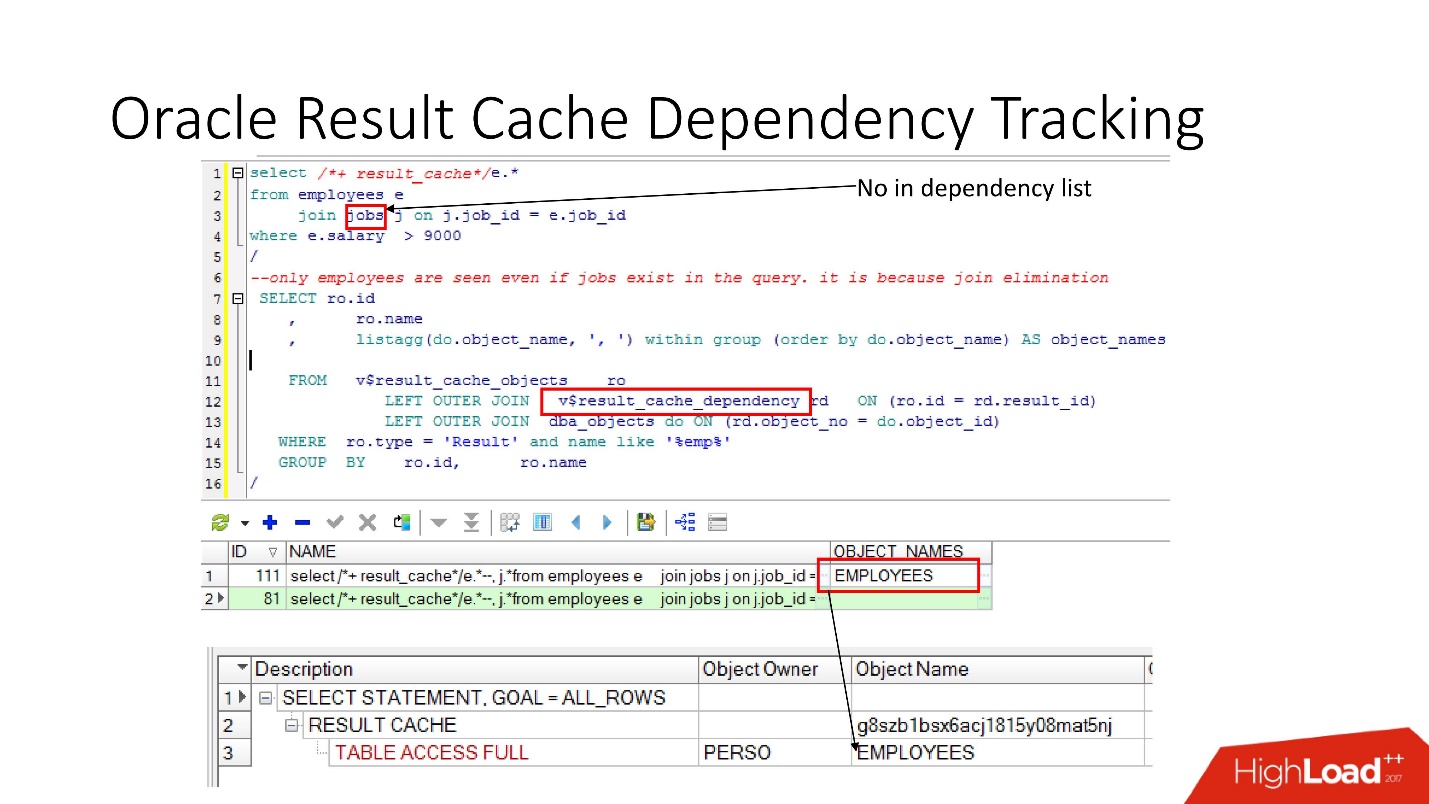
En el ejemplo anterior, la consulta JOIN es una tabla en la que hay una dependencia. Por qué Debido a que Oracle determina la dependencia no solo analizando, sino que la implementa de
acuerdo con los resultados del plan de trabajo .
En este caso, se eligió dicho plan porque solo se usa una tabla y, de hecho, la tabla de trabajos está vinculada a la tabla de empleados a través de restricciones de clave externa. Si eliminamos la restricción de clave externa que permite esta transformación de eliminación de unión, entonces veremos dos dependencias, porque el plan cambiará de esta manera.
Oracle no rastrea lo que no necesita ser rastreado .
En PL / SQL, la dependencia se ejecuta en tiempo de ejecución para que pueda usar SQL dinámico y hacer otras cosas.
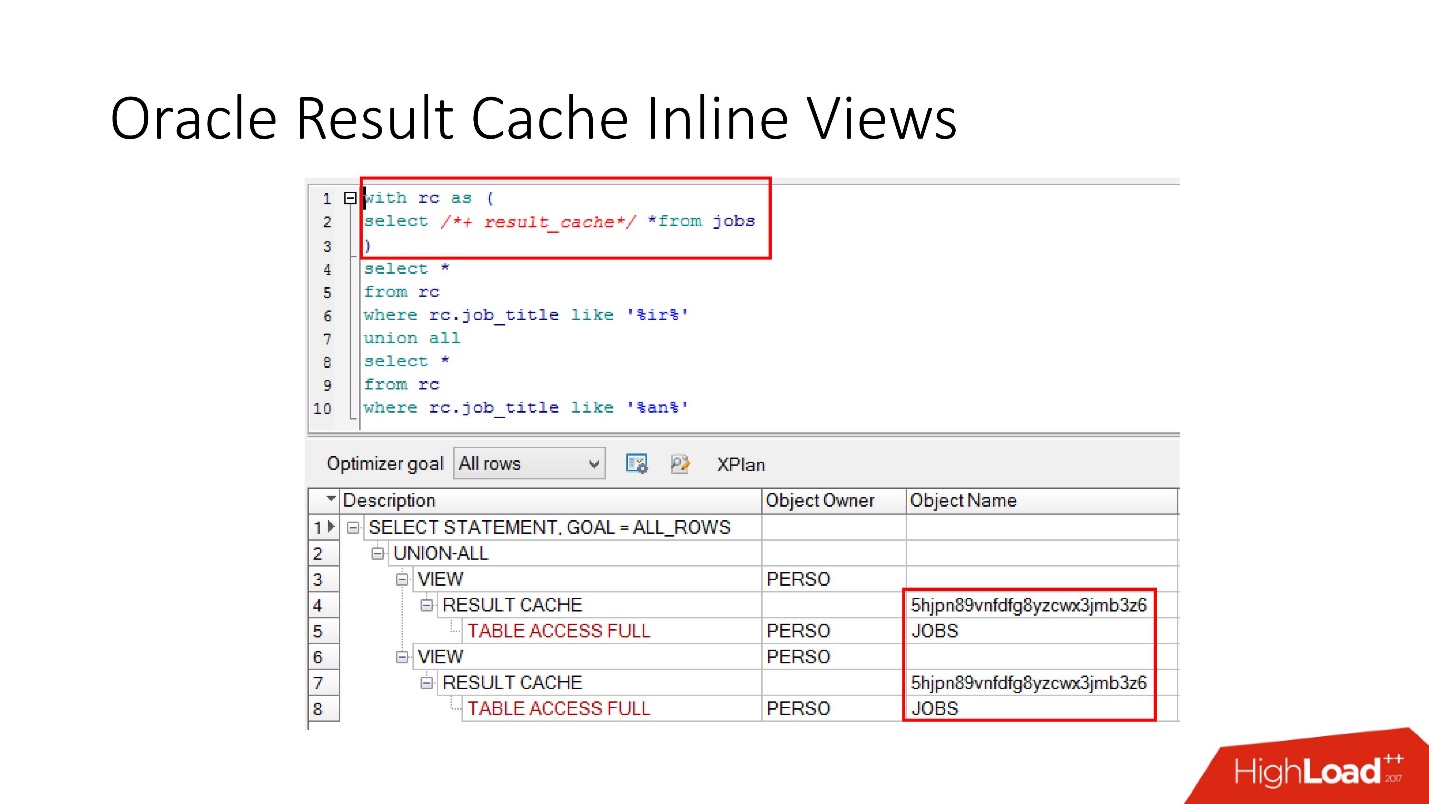
Tenga en cuenta que puede almacenar en caché no solo la solicitud completa, sino
que también puede almacenar en caché la vista en línea con y desde . Supongamos, por un lado, que necesitamos un caché, y el otro sería mejor leer de la base de datos para no forzarlo. Tomamos una vista en línea, nuevamente la declaramos como result_cache y vemos que solo una parte está en caché, y por la segunda accedemos a la base de datos cada vez.
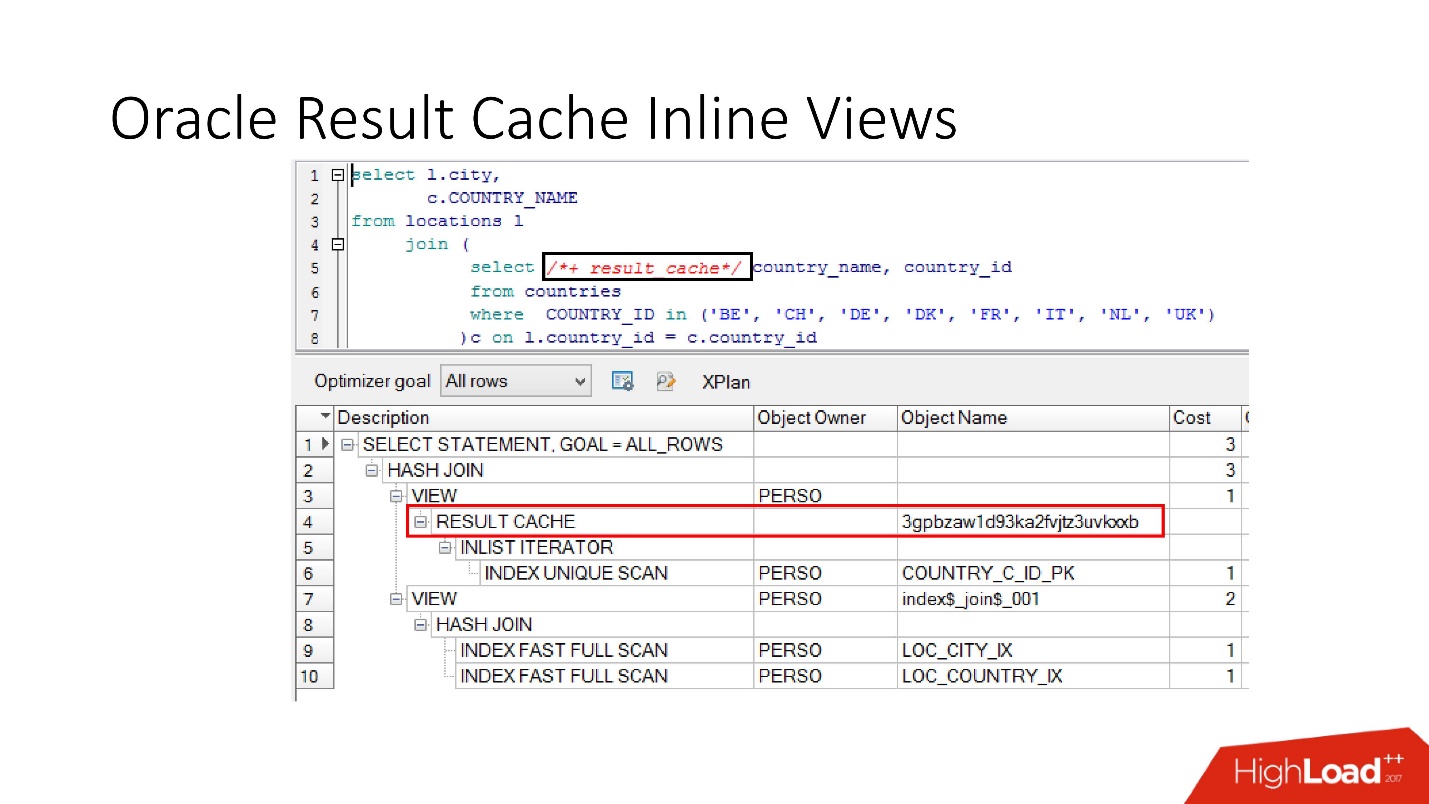
Y finalmente, las
bases de datos también tienen encapsulación , aunque nadie cree en ella. Tomamos una vista, ponemos result_cache en ella, y nuestros programadores ni siquiera se dan cuenta de que está en caché. A continuación vemos que, de hecho, solo una parte funciona.
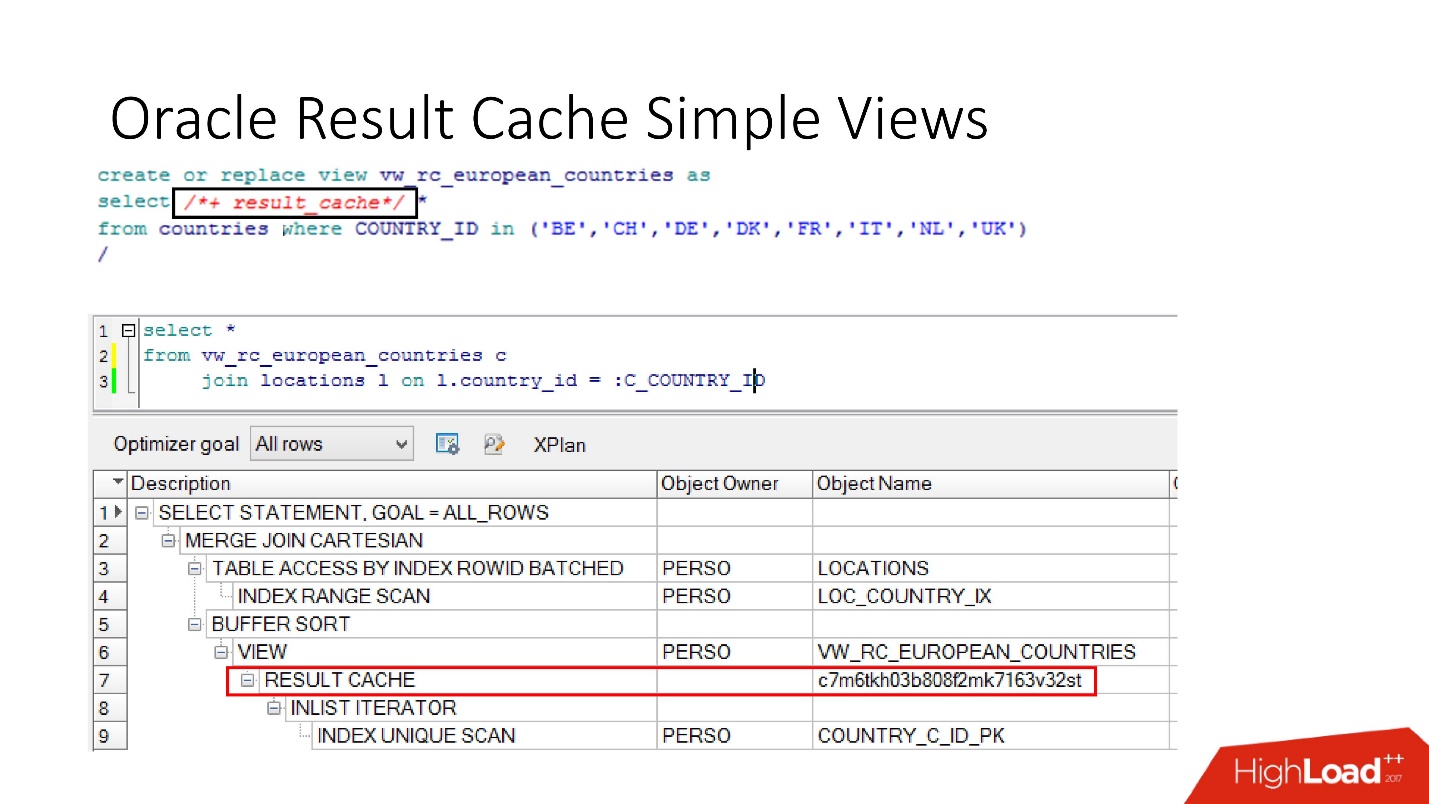
Discapacidad
Entonces, veamos cuando Oracle invalida result_cache. El estado Publicado muestra el estado actual de validez de caché. Cuando la solicitud de result_cache, como dije, no hay trabajos en la base de datos
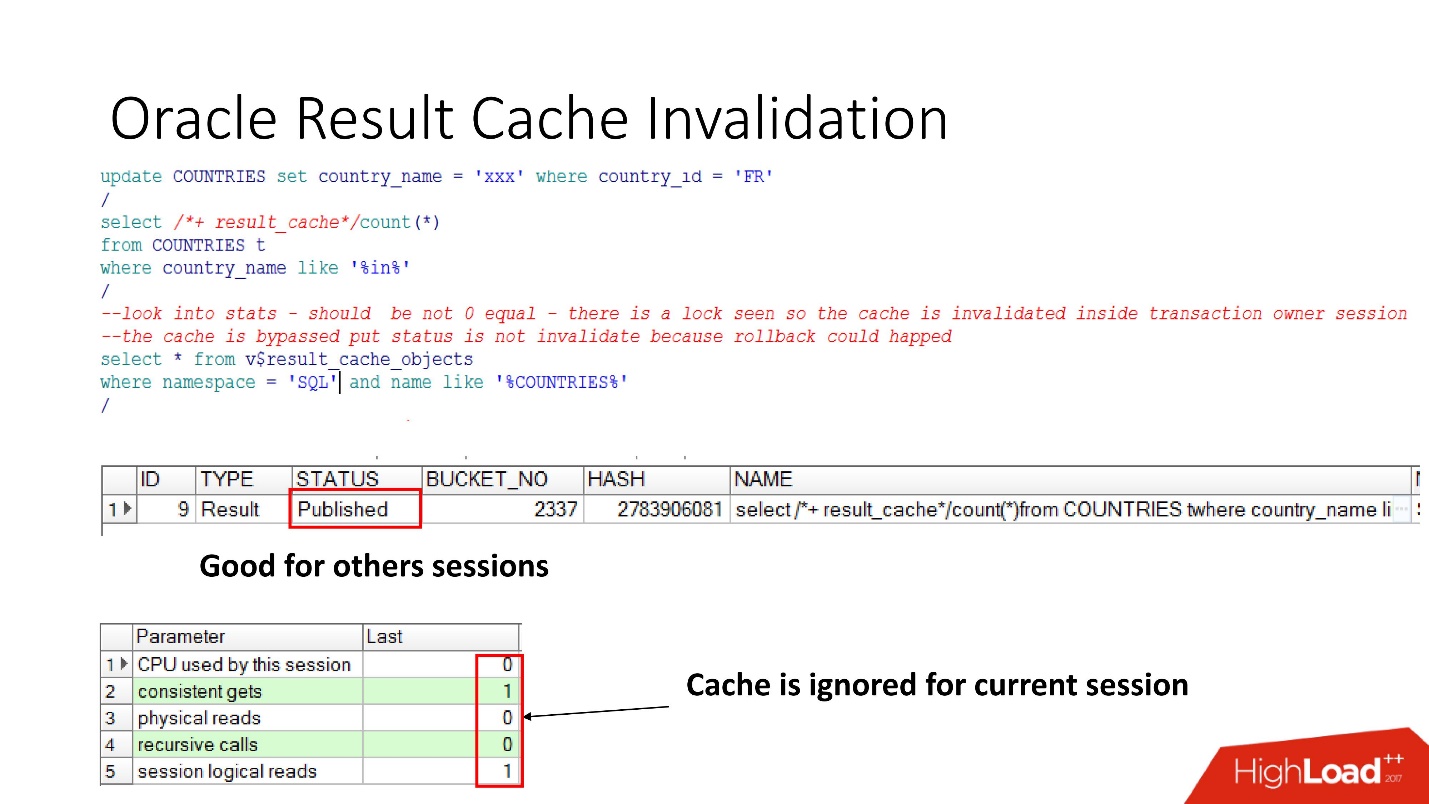
Cuando realizamos la actualización, el estado sigue siendo Publicado, porque la actualización no se ha confirmado y otras sesiones deberían ver el antiguo resultado_caché. Esta es la consistencia de lectura notoria.
Pero en la sesión actual veremos que la carga se ha ido, ya que es en esta sesión que se ignora el caché. Esto es bastante razonable, hagamos commit: el resultado será inválido, todo funciona por sí solo.

Parecería, ¡un sueño! La dependencia se considera correcta, solo según la solicitud. Pero no, se revelaron varios matices.
Oracle produce discapacidades y en varios casos no obvios :
- Con cualquier llamada SELECCIONAR PARA ACTUALIZAR, las dependencias desaparecen.
- Si la tabla tiene claves foráneas no indexadas, y se produce una actualización en la tabla marcada como resultado_caché, que no afectó nada en absoluto, pero algo ha cambiado en la tabla primaria, la caché también se invalidará.
- Esto es lo más interesante que arruina la vida tanto como sea posible: si hay alguna actualización fallida en la tabla marcada como result_cache, nada funcionó, pero luego en la misma transacción se aplicaron otros cambios que de alguna manera afectaron la primera tabla, de todos modos result_cache se restablecerá.
Todavía hay un antipattern sobre result_cache, cuando los desarrolladores, habiendo escuchado que hay algo tan genial, piensan: “¡Oh, hay almacenamiento! Ahora tomaremos alguna solicitud que funcione en 2-3 particiones: en la fecha actual y en la anterior, márquela como result_cache, ¡y siempre se tomará de la memoria! "
Pero cuando cambia a Patricia en retrospectiva, todo el caché vuela, porque de hecho la unidad de seguimiento de dependencias en result_cache siempre es una tabla, y no sé si alguna vez habrá particiones o no.
Pensamos y decidimos que iríamos a la producción de un sistema de recomendación con tales cosas:
- No almacenaremos en caché todas nuestras tablas, tomaremos solo las necesarias.
- Establezca result_cache para la consulta de larga duración.
Verificamos todo, realizamos pruebas de rendimiento,
tiempo de procesamiento: 30 s . ¡Todo está genial, ve a producción!
Arruinado - se fue a dormir. Llegamos por la mañana Vemos una carta: "El reconocimiento lleva al menos 20 minutos, las sesiones se congelan". ¿Por qué se están congelando? ¿Cómo se
convirtieron 30 segundos en 20 minutos ?
Comenzaron a entender, mira la base de datos:
- sesiones activas - 400;
- en promedio líneas en un documento para reconocimiento - 500;
- columnas mínimas: 5-8;
- ¡el número de sesiones en la base de datos siempre es igual al número de aplicaciones de usuario multiplicado por 3! Y result_cache no le gusta el acceso frecuente a él.
Después de realizar una investigación interna, descubrimos que los desarrolladores de Java reconocen en 3 hilos.
Estábamos molestos: una carga de 5 veces, caída, degradación e incluso con tales parámetros, tal hundimiento no debería haber sucedido.
Obviamente, necesitas entender.
Monitoreo

Para el monitoreo, tenemos dos cosas clave:
- V $ RESULT_CACHE_OBJECTS: una lista de todos los objetos;
- V $ RESULT_CACHE_STATISTICS - estadísticas agregadas de result_cache en su conjunto.
MEMORY_REPORT son variaciones sobre un tema, no las necesitaremos.
¡Oracle es mágico! Hay una gran documentación, pero está diseñada para aquellos que cambian de otras bases de datos para que lean y piensen que Oracle es muy bueno. Pero
toda la información sobre result_cache se encuentra solo con soporte .

¡Hay un matiz que consiste en el hecho de que tan pronto como recurrimos a estos objetos para resolver el problema, lo exacerbamos enterrándonos finalmente! Hasta Oracle12.2, antes del parche que se lanzó en octubre del año pasado, estas solicitudes hacen que result_cache sea inaccesible para el estado y la escritura hasta que se cuenten por completo.
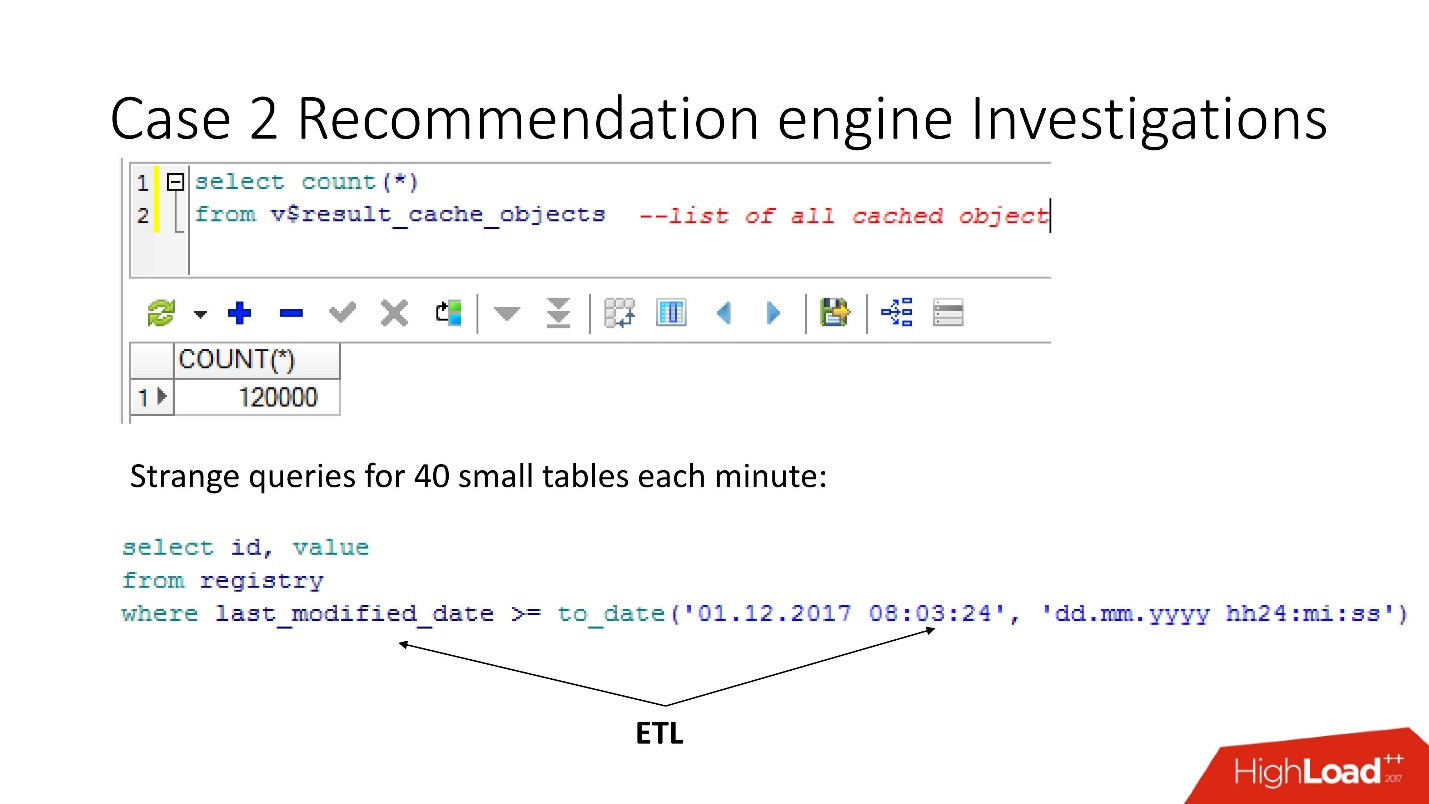
Entonces, usando la vista v $ result_cache_objects, descubrimos que hay miles de entradas en la lista de objetos en caché, mucho más de lo que esperábamos. Además, estos fueron objetos de algunas de nuestras consultas en tablas extrañas: tabletas pequeñas y consultas last_modified_date. Obviamente,
alguien estableció ETL en nuestra base .
Antes de insultar a los desarrolladores de ETL, verificamos que la opción result_cache force estuviera habilitada para estas tablas, y recordamos que la activamos nosotros mismos, ya que algunos de estos datos a menudo eran requeridos por la aplicación y el almacenamiento en caché era apropiado.
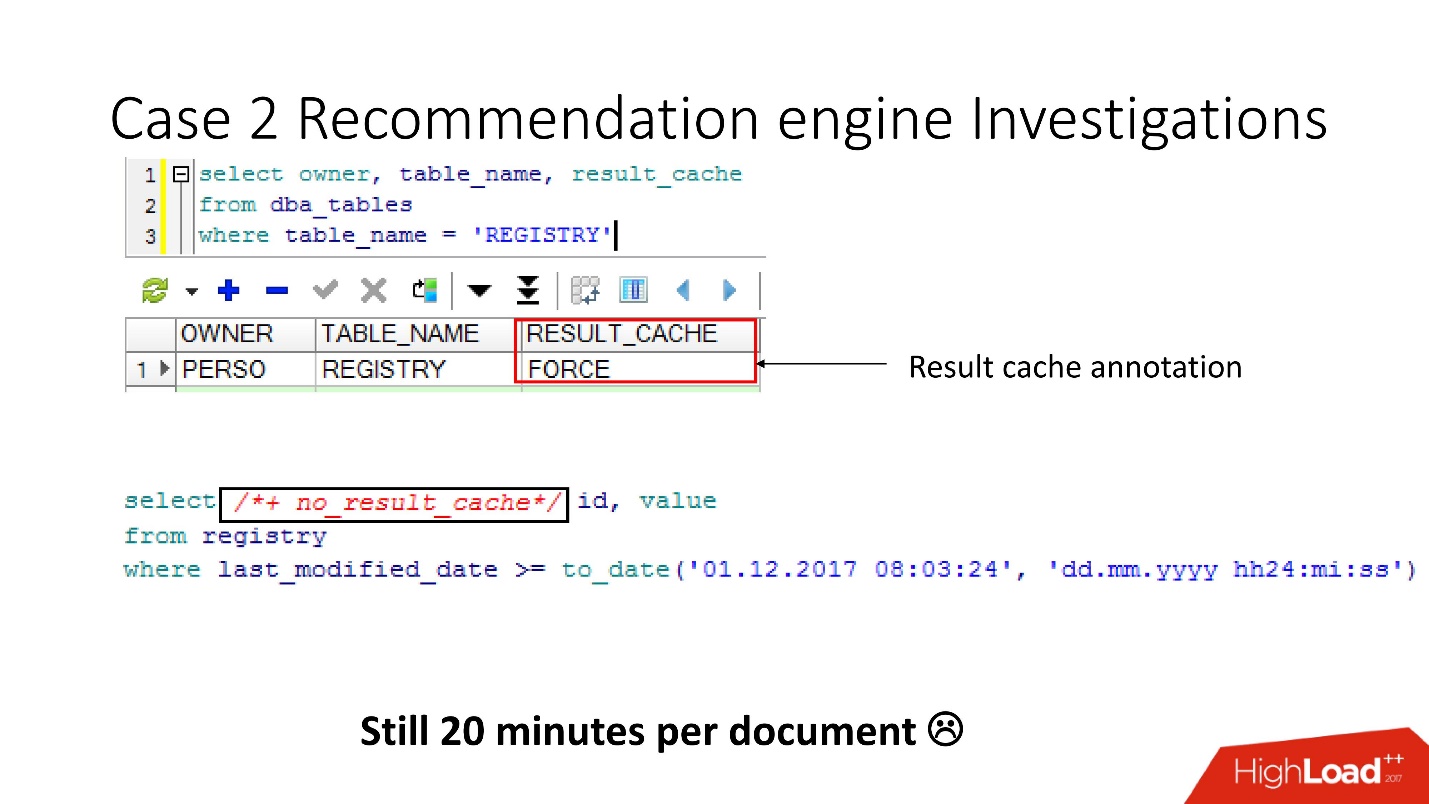
Pero resultó que
todas estas solicitudes solo toman y lavan nuestro caché . Afortunadamente, los desarrolladores tuvieron la oportunidad de influir en el ETL en la producción, por lo que pudimos cambiar result_cache para excluir estas minuciosas solicitudes.
¿Crees que es más fácil? - No te sientas mejor! El número de objetos almacenados en caché disminuyó, y luego volvió a aumentar a 12,000. Continuamos estudiando qué más se almacenaba en caché, ya que la velocidad no cambió.

Miramos: un montón de solicitudes, y muy inteligentes, pero todas incomprensibles. Aunque cualquiera que haya trabajado con Oracle 12 sabe que DS SVC son estadísticas adaptativas. Es necesario para mejorar el rendimiento, pero cuando hay result_cache, resulta que lo mata porque la competencia está sucediendo. Esto, por supuesto, está escrito
solo en soporte .
Sabíamos cómo se organiza la carga de trabajo y entendimos que en nuestro caso, las estadísticas adaptativas no mejorarían radicalmente nuestros planes. Por lo tanto, lo apagamos heroicamente: el resultado, como está escrito en el manual secreto, es de 10 minutos por documento. No está mal, pero no lo suficiente.
Cierres
La competencia entre result_cache y DS SVC se debe al hecho de que Oracle tiene pestillos, pequeños bloqueos livianos.

Sin entrar en detalles sobre cómo funcionan, intentamos poner un pestillo con nombre varias veces, no funcionó, Oracle se levanta y se duerme
Cualquiera que esté en el tema puede decir que en result_cache, se colocan dos pestillos en cada bloque con fetch. Estos son los detalles. Hay dos tipos de pestillos en result_cache:
1. Bloquee el período mientras escribimos datos en result_cache.

Es decir, si su solicitud ha estado funcionando durante 8 s, durante el período de estos 8 s, otras mismas solicitudes (la palabra clave "same") no podrán hacer nada, porque esperan hasta que los datos se escriban en result_cache. Se registrarán otras solicitudes, pero esperarán el bloqueo solo en la primera línea. Se desconoce cuánto tendrán que esperar; este es el parámetro no documentado result_cache_timeout. Después de eso, comienzan a ignorar result_cache, por así decirlo, y trabajan lentamente. Sin embargo, tan pronto como se libera el bloqueo de la última línea en la puerta, comienzan a funcionar automáticamente con result_cache nuevamente.
2. El segundo tipo de bloqueos: para recibir desde result_cache también desde la primera línea hasta la última.
Pero como la recuperación proviene de la memoria instantánea, se eliminan muy rápidamente.

Asegúrese de tener en cuenta que cuando el DBA ve bloqueos en la base de datos, comienza a decir: “¡Cierres! ¡Espera, todo se fue! »Y aquí comienza el juego más interesante:
convencer a DBA de que el tiempo de espera de los pestillos es en realidad incomparablemente más corto que el tiempo de reintento de consulta .

Como muestra nuestra experiencia, nuestras medidas, los
pestillos en result_cache ocupan el 10% de las solicitudes mismas .
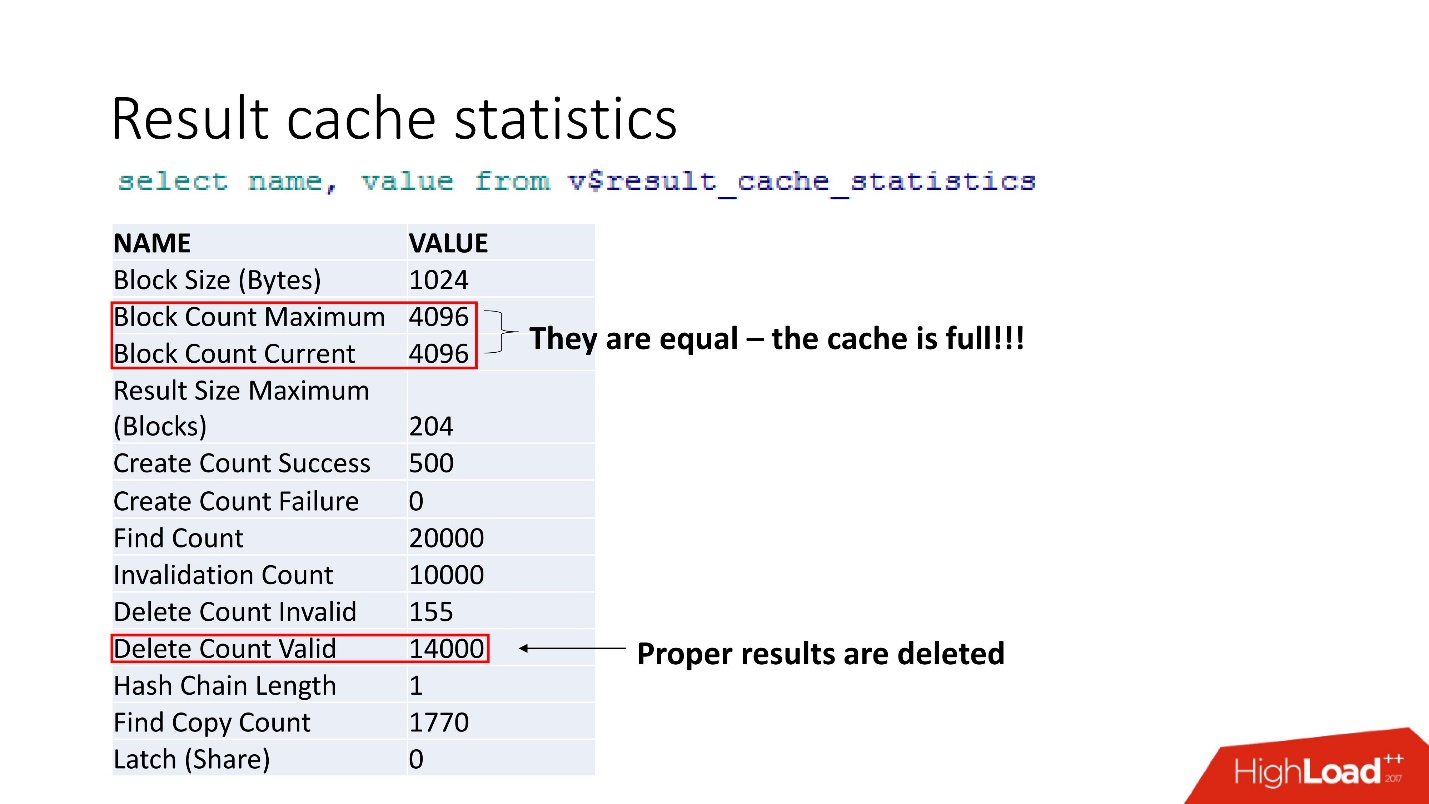
Estas son estadísticas agregadas. El hecho de que todo está mal puede entenderse por el hecho de que el caché está obstruido. Otra confirmación es que se eliminan los resultados adecuados. Es decir, el
caché se sobrescribe . Parece que somos inteligentes y siempre consideramos el tamaño de la memoria: tomamos el tamaño de la línea de nuestro resultado en caché para nuestra recomendación, lo multiplicamos por el número de líneas y algo salió mal.

support 2 , ,
result_cache . .
, . , , , workload 5 . , , .
?: . , .
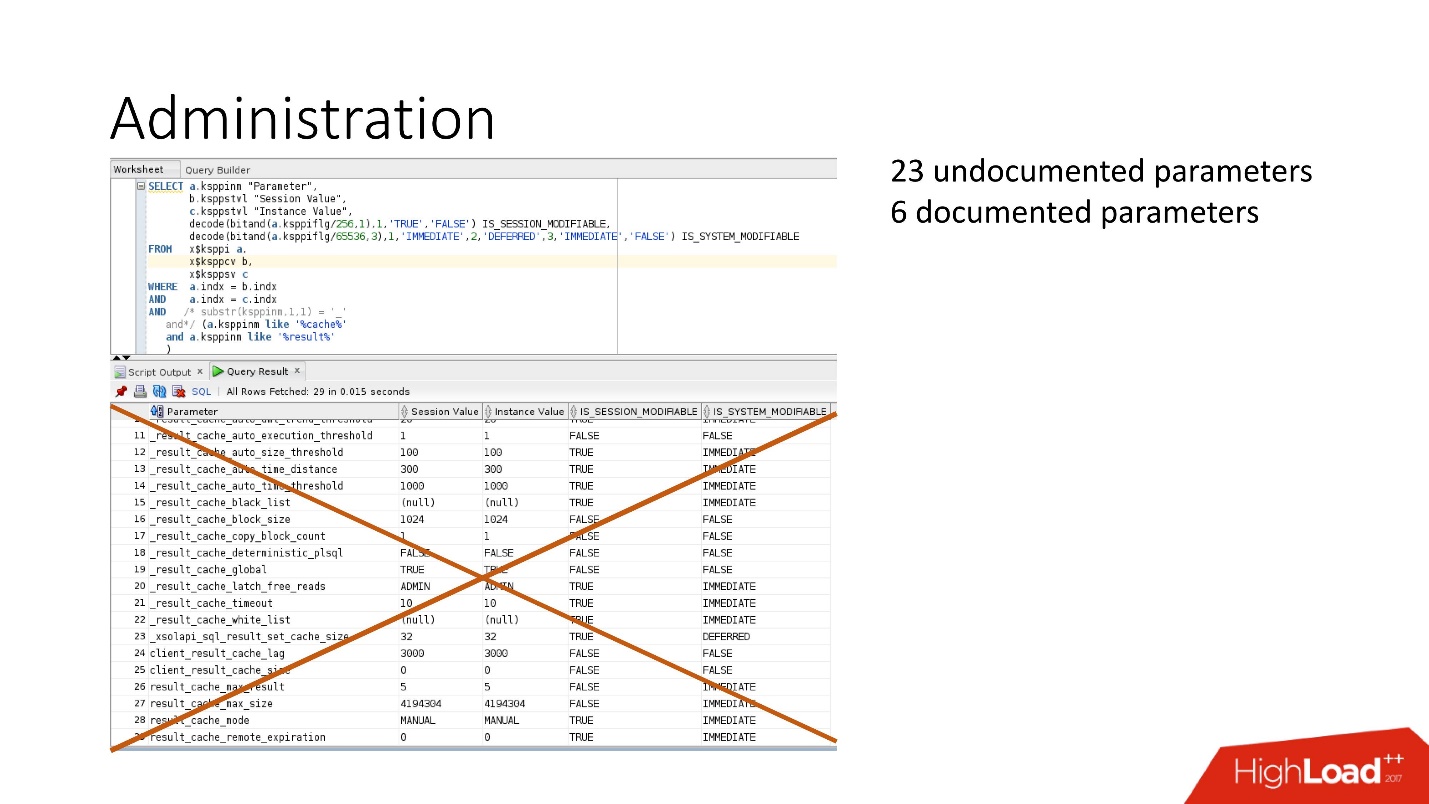
4 :
- RESULT_CACHE_MAX_SIZE;
- RESULT_CACHE_MAX_RESULT;
- RESULT_CACHE_MODE;
- _RESULT_CACHE_MAX_TIMEOUT.
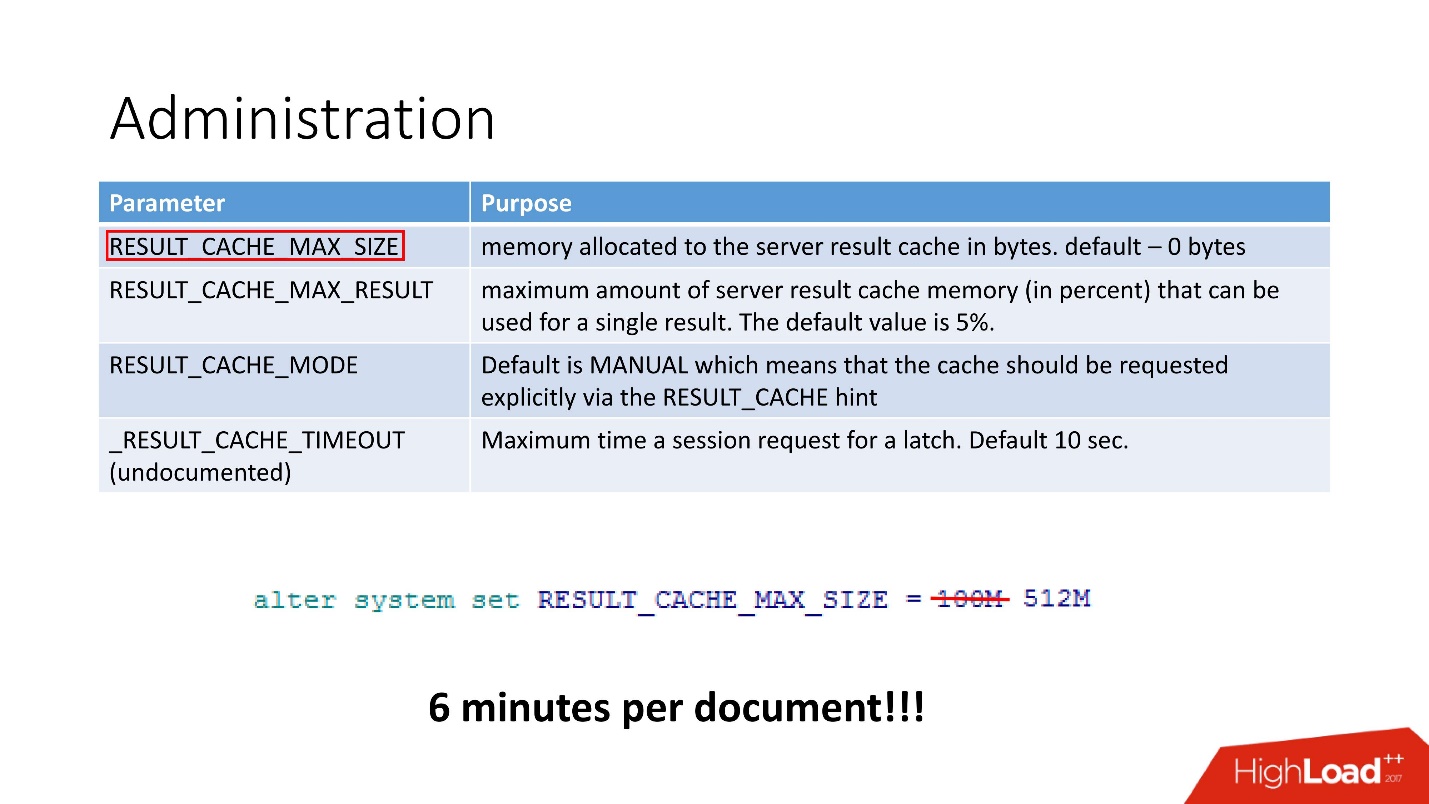
— . , 100 512, 6 .
, - . , Invalidation Count = 10000.
, . , job , . , . job , , .
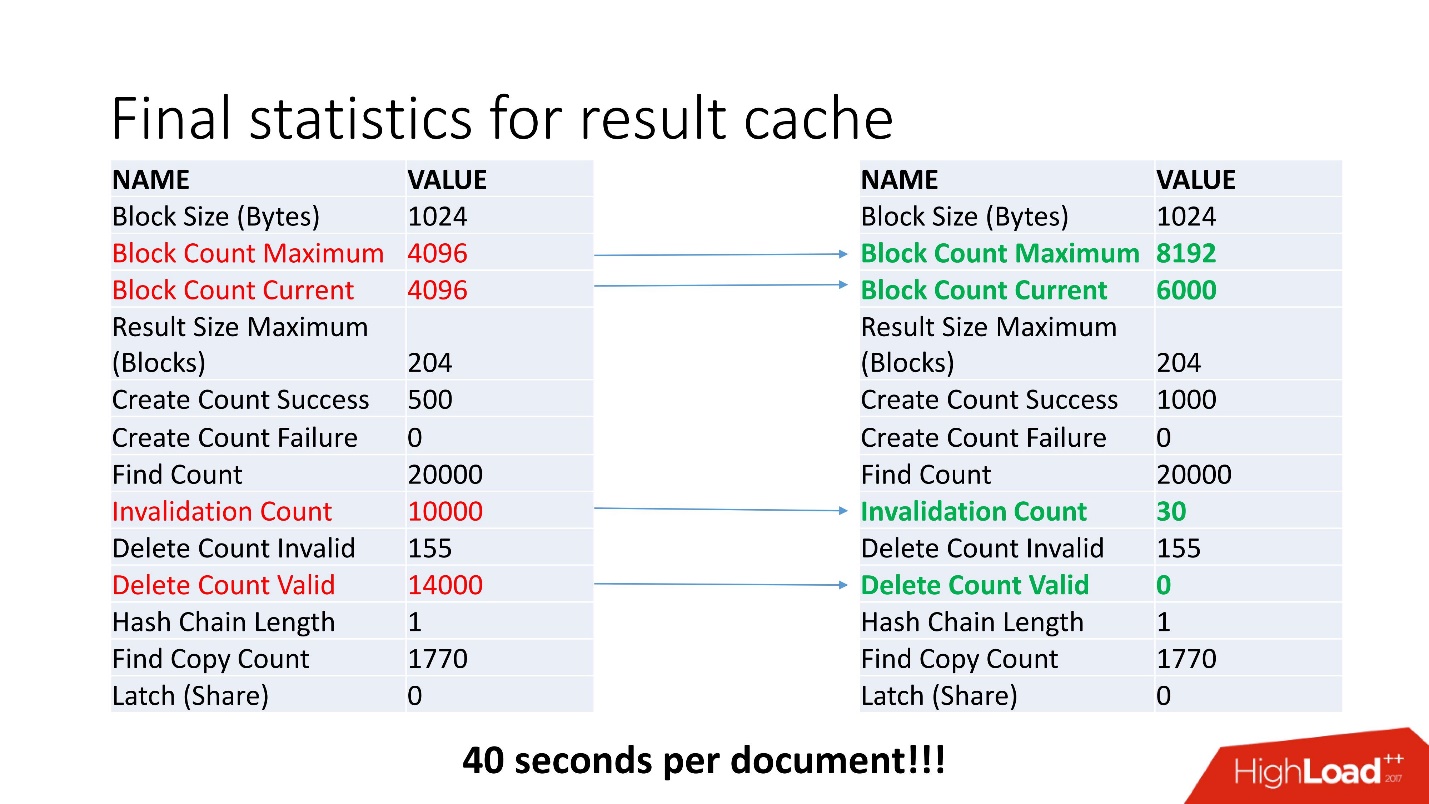
, invalid , .
40 .
, . , , Oracle. !
 SHELFLIVE
SHELFLIVE — , read-consistent , 10 , . . , , .
—
SNAPSHOT . , , read-consistent — .
:

- — SYS.
- . , , Oracle , , . , Oracle , , 12.2 . , external - support, .
- sql pl/sql : current_date, current_time . , current_time, .
- .
- , CLOB, BLOB .
Result cache inside Oracle
Result_cache — Oracle Core. , , job result_cache (, hint, ) , APEX.

, Dynamic sampling , , , result_cache.

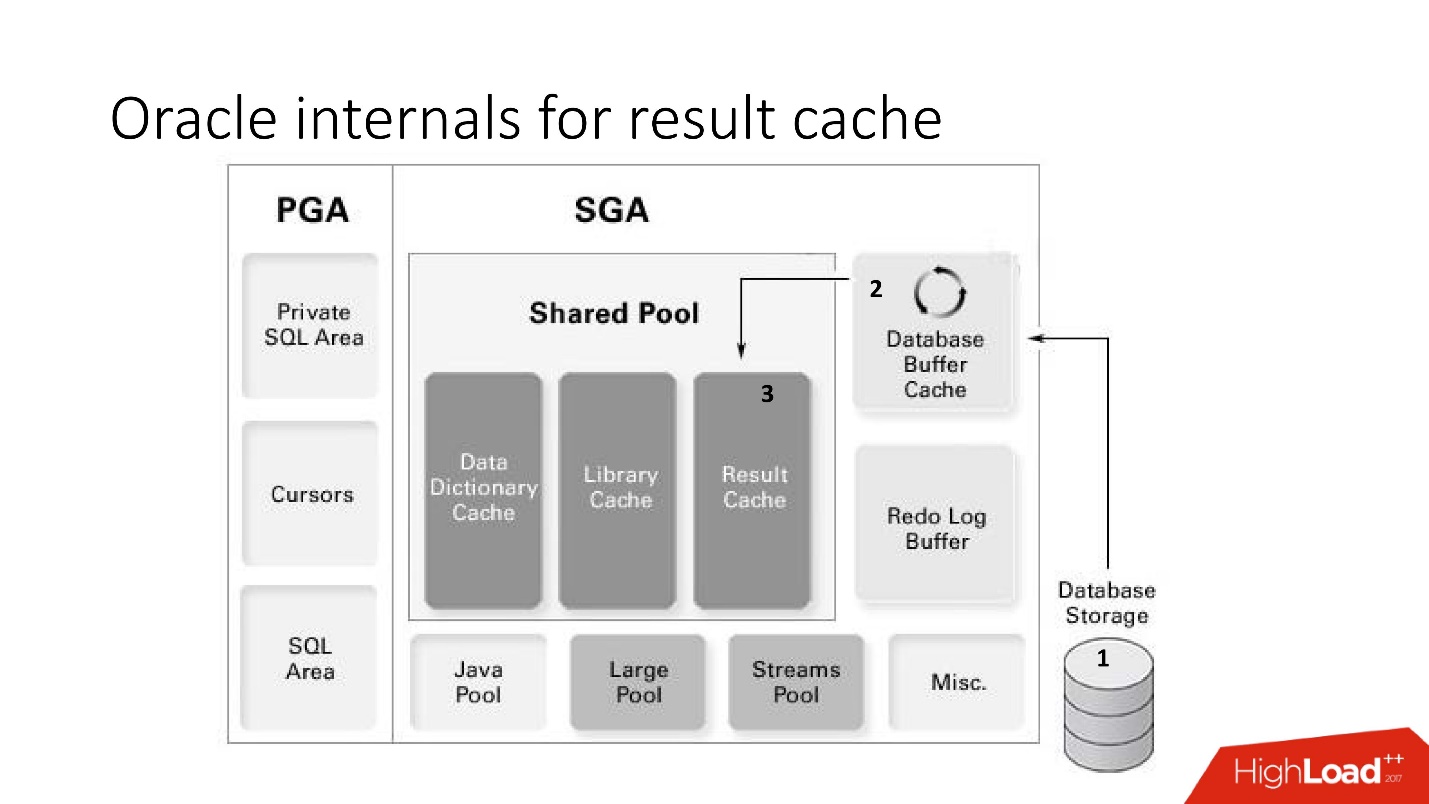
Oracle internals for result cache
result_cache:
- (storage) ;
- result_cache;
- result_cache shared pool.
 :
:- .
- read-consistent.
- Result_cache, , .
:!
, . support Oracle, , 29 2017 .: Oracle E-Business suite result_cache, .

, , . support , , .

:
- - ;
- , , , , v$result_cache_memory dbms_result_cache.memory_report, .
, , , v_result_cache_objects .
, support note — support , .

, , : - . , , :
- hint result_cache;
- hint no result_cache;
- black_list, , , -.
?- , - , , ;
- Inhabilite el caché durante el período de arranque, es decir, se desconecta, vierte y enciende rápidamente. Es mejor que el sistema se desacelere un poco, pero funciona, luego se cae.
Como notamos, el principal problema con los cachés en el servidor es el costo de la costosa memoria del servidor . Oracle tiene una tercera solución final.Caché de resultados del lado del cliente

El diagrama de su dispositivo se muestra en lo anterior, estos son los componentes principales de la base de datos y el controlador.
La primera vez que se accede al lado del cliente, el Caché de resultados va a la base de datos, que está preconfigurada, recibe el tamaño del caché del cliente de la base de datos e instala este caché en el cliente una vez en la primera conexión. La consulta en caché primero accede a la base de datos y escribe datos en la caché. Los subprocesos restantes solicitan un caché de controlador compartido, ahorrando así memoria y recursos del servidor. Por cierto, a veces dependiendo de la carga, el controlador envía estadísticas sobre el uso de la memoria caché a la base de datos, que luego se puede ver.
Una pregunta interesante es, ¿cómo ocurre la discapacidad?Hay dos modos de invalidación, que se agudizan con el parámetro Retardo de invalidación. Esta es la cantidad de Oracle que permite que el caché del controlador no sea coherente.
El primer modo se utiliza cuando las solicitudes van con frecuencia y no se produce el retraso de invalidación. En este caso, la transmisión irá a la base de datos, actualizará los cachés y leerá los datos de ella.
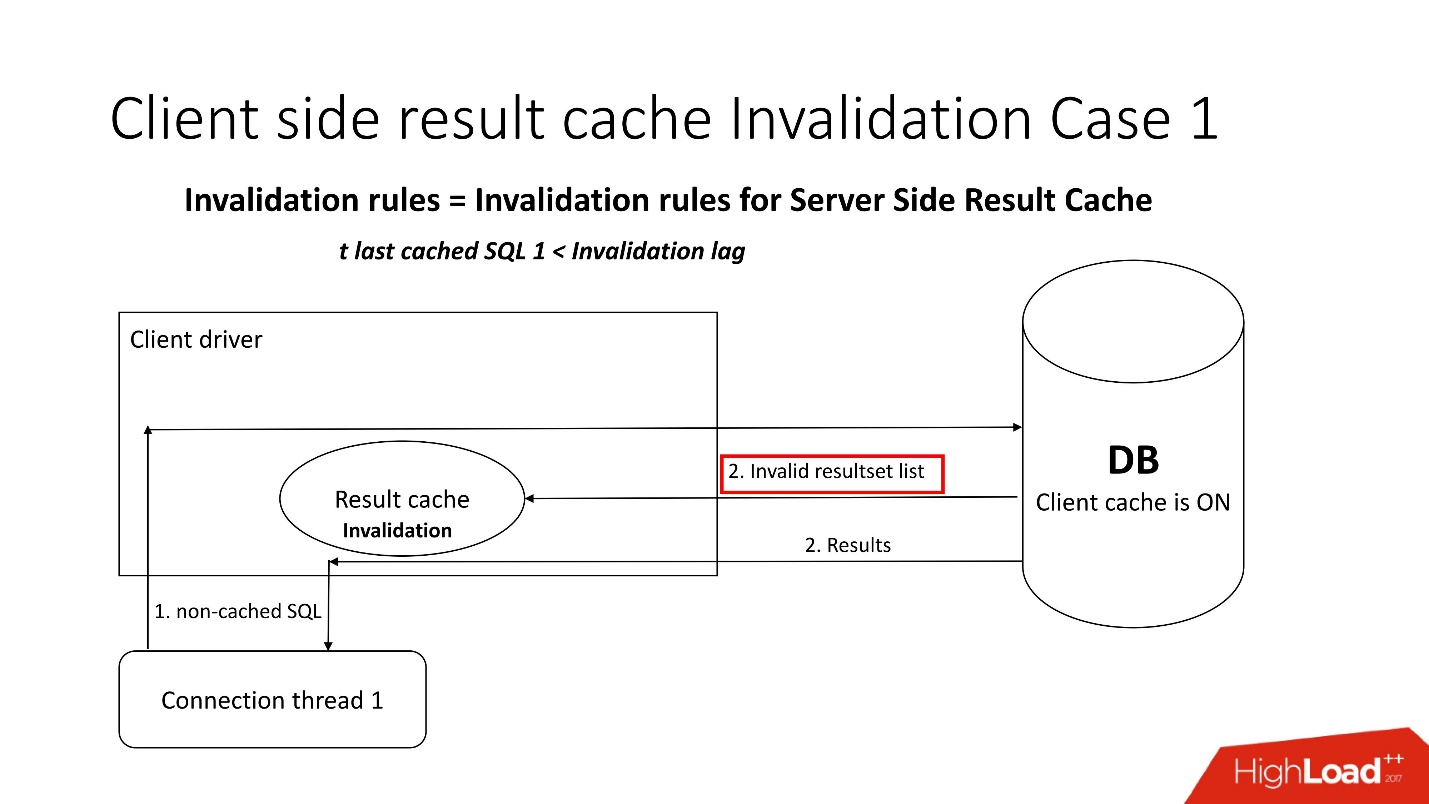
Si falla el retraso de invalidación, cualquier solicitud no almacenada en caché, que se refiera a la base de datos, además de los resultados de la consulta, trae una lista de objetos no válidos. En consecuencia, están marcados como no válidos en la memoria caché, y todo funciona como en la imagen del primer escenario.
En el segundo caso, si ha pasado más tiempo que el retraso de invalidación, entonces el resultado result_cache del cliente mismo va a la base de datos y dice: "¡Dame una lista de cambios!" Es decir, él mismo mantiene su estado adecuado.
Configurar el caché de resultados del lado del cliente es muy simple . Hay 2 opciones:
- CLIENT_RESULT_CACHE_LAG - valor de retraso de caché;
- CLIENT_RESULT_CACHE_SIZE - tamaño (mínimo 32 Kb, máximo - 2 GB).

Desde el punto de vista del desarrollador de la aplicación, la caché del cliente no es muy diferente de la caché del servidor, también ingresaron la pista result_cache. Si lo fuera, entonces simplemente comenzará a ser utilizado por el cliente, tanto en .Net como en Java.

Habiendo hecho 10 iteraciones de la consulta, obtuve lo siguiente.

El primer atractivo es la creación, luego 9 accesos a caché. La tabla indica que la memoria también se asigna en bloques. También preste atención a SELECCIONAR: no es muy intuitivo. Para ser honesto, antes de comenzar a lidiar con esto, ni siquiera sabía que había una representación de
GV$SESSION_CONNECT_INFO . Por qué Oracle no lo llevó directamente a esta tabla (y esta es una tabla, no una vista), no podía entenderlo. Pero por eso creo que esta funcionalidad no es muy popular, aunque, como me parece, es muy útil.
Ventajas del almacenamiento en caché del cliente:- memoria de cliente barata;
- cualquier controlador disponible: JDBC, .NET, etc.
- Impacto mínimo en el código de la aplicación.
- Reducir la carga en la CPU, E / S y, en general, la base de datos;
- no es necesario aprender y usar todo tipo de capas de caché inteligente y API;
- Sin pestillos.
Desventajas- consistencia en la lectura con retraso - en principio, ahora esta es una tendencia;
- necesita cliente Oracle OCI;
- limitación de 2 GB por cliente, pero en general 2 GB es mucho;
- Para mí personalmente, la limitación clave es una pequeña información sobre la producción.
En el soporte, que siempre usamos cuando trabajamos con result_cache, encontré solo 5 errores. Esto sugiere que, muy probablemente, pocas personas lo necesitan.
Entonces, reunimos todo lo que se dijo anteriormente.
Caché hecho a mano
Malos escenarios:- Cambio instantáneo: si después de cambiar los datos, el caché debería volverse irrelevante de inmediato. Para las memorias caché hechas a sí mismas, es difícil crear la invalidación correcta en caso de cambios en los objetos sobre los que están construidas.
- Si el uso de la lógica almacenada en la base de datos está prohibido por las políticas de desarrollo.
Buenos escenarios:- Hay un fuerte equipo de desarrollo de bases de datos.
- Lógica PL / SQL implementada.
- Existen limitaciones que impiden el uso de otras técnicas de almacenamiento en caché.
Caché de resultados del lado del servidor
Malos escenarios:- Muchos resultados diferentes que simplemente lavan todo el caché;
- Las solicitudes tardan más de _RESULT_CACHE_TIMEOUT o este parámetro está configurado incorrectamente.
- Los resultados de sesiones muy grandes se cargan en la memoria caché en subprocesos paralelos.
Buenos escenarios:- Cantidad razonable de resultados en caché.
- Conjuntos de datos relativamente pequeños (200–300 filas).
- SQL bastante costoso, de lo contrario todo el tiempo irá a pestillos.
- Más o menos tablas estáticas.
- Hay un DBA, que en caso de que algo venga y salve a todos.
Caché de resultados del lado del cliente
Malos escenarios:- Cuando surge el problema mismo de la discapacidad instantánea.
- Se requieren controladores delgados.
Buenos escenarios:- Hay un equipo normal de desarrollo de capa media.
- Ya se está utilizando una gran cantidad de SQL sin utilizar una capa de almacenamiento en caché externa que se pueda conectar fácilmente.
- Hay restricciones en las glándulas.
Conclusiones
Creo que mi historia es sobre el dolor de caché de resultados del lado del servidor, por lo que las conclusiones son las siguientes:
- Siempre evalúe el tamaño de la memoria correctamente teniendo en cuenta la cantidad de consultas y no la cantidad de resultados, es decir: bloques, APEX, trabajo, estadísticas adaptativas, etc.
- No tenga miedo de usar las opciones de descarga automática de caché (instantánea + vida útil).
- No sobrecargue el caché con solicitudes mientras carga grandes cantidades de datos; deshabilite result_cache antes de esto. Calienta el caché.
- Asegúrese de que _result_cache_timeout cumpla con sus expectativas.
- NUNCA use FORCE para toda la base de datos. Necesita una base de datos en memoria: use una solución especializada en memoria.
- Verifique si la opción FORCE se usa apropiadamente para tablas individuales para que no funcione como lo hacemos con un ETL de terceros.
- Decida si las estadísticas adaptativas son tan buenas como las descritas por Oracle (_optimizer_ads_use_result_cache = false).
Highload ++ Siberia el próximo lunes, el calendario está listo y publicado en el sitio. Hay varios informes en el tema de este artículo:
- Alexander Makarov (CFT GC) demostrará un método para identificar cuellos de botella en el lado del servidor del software utilizando la base de datos Oracle como ejemplo.
- Ivan Sharov y Konstantin Poluektov le dirán qué problemas surgen al migrar el producto a nuevas versiones de la base de datos Oracle, y también prometen dar recomendaciones sobre la organización y realización de dicho trabajo.
- Nikolay Golov le dirá cómo garantizar la integridad de los datos en una arquitectura de microservicio sin transacciones distribuidas y conectividad estrecha.
Nos vemos en Novosibirsk!