Este artículo se centrará en algunos algoritmos de búsqueda y descripciones de puntos de imagen específicos. Aquí este tema ya se ha
planteado , y más
de una vez . Consideraré que las definiciones básicas ya son familiares para el lector, examinaremos en detalle los algoritmos heurísticos FAST, FAST-9, FAST-ER, BRIEF, rBRIEF, ORB, y discutiremos las ideas brillantes subyacentes. En parte, esta será una traducción gratuita de la esencia de varios artículos [1, 2, 3, 4, 5], habrá algún código para "probar".

Algoritmo RÁPIDO
FAST, propuesto por primera vez en 2005 en [1], fue uno de los primeros métodos heurísticos para encontrar puntos singulares, que ganó gran popularidad debido a su eficiencia computacional. Para tomar una decisión sobre si considerar un punto C dado como especial o no, este método considera el brillo de los píxeles en un círculo centrado en el punto C y el radio 3:

Comparando el brillo de los píxeles del círculo con el brillo del centro C, para cada uno obtenemos tres resultados posibles (más claro, más oscuro, parece):
$ en línea $ \ begin {array} {l} {I_p}> {I_C} + t \\ {I_p} <{I_C} -t \\ {I_C} -t <{I_p} <{I_C} + t \ end {array} $ en línea $
Aquí I es el brillo de los píxeles, t es un umbral de brillo predeterminado.
Un punto se marca como especial si hay n = 12 píxeles en una fila más oscuros o 12 píxeles más claros que el centro.
Como la práctica ha demostrado, en promedio, tomar una decisión, fue necesario verificar alrededor de 9 puntos. Para acelerar el proceso, los autores sugirieron primero verificar solo cuatro píxeles con números: 1, 5, 9, 13. Si entre ellos hay 3 píxeles más claros o más oscuros, entonces se realiza una verificación completa en 16 puntos, de lo contrario, el punto se marca inmediatamente como " no especial ". Esto reduce en gran medida el tiempo de trabajo, para tomar una decisión en promedio es suficiente sondear solo alrededor de 4 puntos de un círculo.
Aquí hay un poco de código ingenuo
Parámetros variables (descritos en el código): radio del círculo (toma valores 1,2,3), parámetro n (en el original, n = 12), parámetro t. El código abre el archivo in.bmp, procesa la imagen, la guarda en out.bmp. Las imágenes son ordinarias de 24 bits.
Construyendo un árbol de decisión, Tree FAST, FAST-9
En 2006, en [2], fue posible desarrollar una idea original utilizando el aprendizaje automático y los árboles de decisión.
El FAST original tiene las siguientes desventajas:
- Varios píxeles adyacentes se pueden marcar como puntos especiales. Necesitamos alguna medida de la "fuerza" de una característica. Una de las primeras medidas propuestas es el valor máximo de t en el que el punto todavía se toma como uno especial.
- Una prueba rápida de 4 puntos no se generaliza para n menos de 12. Entonces, por ejemplo, visualmente los mejores resultados del método se logran con n = 9, no 12.
- ¡También me gustaría acelerar el algoritmo!
En lugar de utilizar una cascada de dos pruebas de 4 y 16 puntos, se propone hacer todo en una sola pasada a través del árbol de decisión. De manera similar al método original, compararemos el brillo del punto central con los puntos en el círculo, pero en este orden para tomar la decisión lo más rápido posible. Y resulta que puedes tomar una decisión para solo ~ 2 (!!!) comparaciones en promedio.
La sal es cómo encontrar el orden correcto para comparar puntos. Encuentra usando el aprendizaje automático. Supongamos que alguien señala para nosotros en la imagen muchos puntos especiales. Los utilizaremos como un conjunto de ejemplos de capacitación, y la idea es elegir con
entusiasmo el que proporcionará la mayor cantidad de información en este paso como el siguiente punto. Por ejemplo, suponga que inicialmente en nuestra muestra había 5 puntos singulares y 5 puntos no singulares. En forma de tableta como esta:
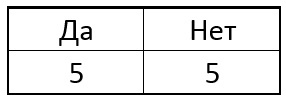
Ahora elegimos uno de los píxeles p del círculo y para todos los puntos singulares comparamos el píxel central con el seleccionado. Dependiendo del brillo del píxel seleccionado cerca de cada punto en particular, la tabla puede tener el siguiente resultado:
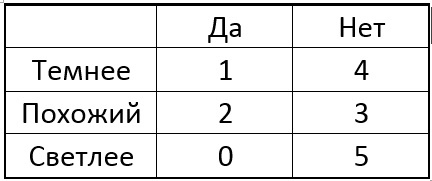
La idea es elegir un punto p para que los números en las columnas de la tabla sean lo más diferentes posible. Y si ahora para un nuevo punto desconocido obtenemos el resultado de comparación "Más ligero", entonces ya podemos decir de inmediato que el punto "no es especial" (ver tabla). El proceso continúa de manera recursiva hasta que los puntos de una sola de las clases caen en cada grupo después de dividirse en "más oscuro como el más claro". Resulta un árbol de la siguiente forma:
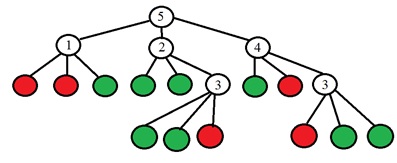
El valor binario está en las hojas del árbol (el rojo es especial, el verde no es especial), y en los otros vértices del árbol está el número del punto que debe analizarse. Más específicamente, en el artículo original, proponen elegir el número de punto cambiando la entropía. Se calcula la entropía del conjunto de puntos:
$$ display $$ H = \ left ({c + \ overline c} \ right) {\ log _2} \ left ({c + \ overline c} \ right) - c {\ log _2} c - \ overline c {\ log _2} \ overline c $$ display $$
c es el número de puntos singulares,
$ en línea $ {\ bar c} $ en línea $ Es el número de puntos no singulares del conjunto.
Cambio en la entropía después del punto de procesamiento p:
$$ display $$ \ Delta H = H - {H_ {dark}} - {H_ {equal}} - {H_ {bright}} $$ display $$
En consecuencia, se selecciona un punto para el cual el cambio en la entropía será máximo. El proceso de división se detiene cuando la entropía es cero, lo que significa que todos los puntos son singulares o viceversa, no todos son especiales. Con una implementación de software, después de todo esto, el árbol de decisión encontrado se convierte en un conjunto de construcciones del tipo "if-else".
El último paso del algoritmo es la operación de suprimir los no máximos para obtener uno de varios puntos adyacentes. Los desarrolladores sugieren usar la medida original basada en la suma de las diferencias absolutas entre el punto central y los puntos del círculo de esta forma:
$$ display $$ V = \ max \ left ({\ sum \ limits_ {x \ in {S_ {brillante}}} {\ left | {{I_x} - {I_p}} \ right | - t, \ sum \ límites_ {x \ in {S_ {dark}}} {\ left | {{I_p} - {I_x}} \ right | - t}}} \ right) $$ display $$
Aqui
$ en línea $ {S_ {brillante}} $ en línea $ y
$ en línea $ {S_ {dark}} $ en línea $ respectivamente, los grupos de píxeles son más claros y más oscuros, t es el valor de brillo del umbral,
$ en línea $ {I_p} $ en línea $ - brillo del píxel central,
$ en línea $ {{I_x}} $ en línea $ - brillo del píxel en el círculo. Puedes probar el algoritmo con el
siguiente código . El código se toma de OpenCV y se libera de todas las dependencias, solo ejecútelo.
Optimizando el árbol de decisiones - FAST-ER
FAST-ER [3] es un algoritmo de los mismos autores que el anterior, un detector rápido está construido de manera similar, la secuencia óptima de puntos también se busca para comparar, también se construye un árbol de decisión, pero usando un método diferente: el método de optimización.
Ya entendemos que un detector se puede representar como un árbol de decisión. Si tuviéramos algún criterio para comparar el rendimiento de diferentes árboles, entonces podemos maximizar este criterio clasificando diferentes variantes de árboles. Y como tal criterio, se propone utilizar "Repetibilidad".
La repetibilidad muestra qué tan bien se detectan los puntos singulares de una escena desde diferentes ángulos. Para un par de imágenes, un punto se llama "útil" si se encuentra en un cuadro y, en teoría, se puede encontrar en otro, es decir, No bloquee los elementos de la escena. Y el punto se llama "repetido" (repetido), si también se encuentra en el segundo cuadro. Dado que la óptica de la cámara no es ideal, el punto en el segundo cuadro puede no estar en el píxel calculado, sino en algún lugar cercano en su vecindad. Los desarrolladores tomaron un vecindario de 5 píxeles. Definimos la repetibilidad como la relación entre el número de puntos repetidos y el número de puntos útiles:
$$ display $$ R = \ frac {{{N_ {repetido}}}} {{{N_ {útil}}}} $$ display $$
Para encontrar el mejor detector, se utiliza un método de simulación de recocido. Ya hay un
excelente artículo sobre Habré sobre él. Brevemente, la esencia del método es la siguiente:
- Se selecciona alguna solución inicial al problema (en nuestro caso, este es algún tipo de árbol detector).
- Se considera la repetibilidad.
- El árbol se modifica al azar.
- Si la versión modificada es mejor por el criterio de repetibilidad, entonces se acepta la modificación, y si es peor, puede aceptarse o no, con cierta probabilidad, que depende de un número real llamado "temperatura". A medida que aumenta el número de iteraciones, la temperatura cae a cero.
Además, la construcción del detector ahora involucra no 16 puntos del círculo, como antes, sino 47, pero el significado no cambia en absoluto:

De acuerdo con el método de recocido simulado, definimos tres funciones:
• Función de costo k. En nuestro caso, usamos la repetibilidad como valor. Pero hay un problema. Imagine que todos los puntos en cada una de las dos imágenes se detectan como singulares. Entonces resulta que la repetibilidad es 100% - absurdo. Por otro lado, incluso si hemos encontrado un punto particular en dos imágenes, y estos puntos coinciden, la repetibilidad también es del 100%, pero esto tampoco nos interesa. Y por lo tanto, los autores propusieron usar esto como un criterio de calidad:
$$ display $$ k = \ left ({1 + {{\ left ({\ frac {{{w_r}}} {R}} \ right)} ^ 2}} \ right) \ left ({1 + \ frac {1} {N} \ sum \ limits_ {i = 1} {{{\ left ({\ frac {{{d_i}}} {{{w_n}}}} right)} ^ 2}}} \ right) \ left ({1 + {{\ left ({\ frac {s} {{{w_s}}}} right)} ^ 2}} \ right) $$ display $$
r es la repetibilidad
$ en línea $ {{d_i}} $ en línea $ Es el número de ángulos detectados en el cuadro i, N es el número de cuadros y s es el tamaño del árbol (número de vértices). W son parámetros de métodos personalizados.]
• Función de cambio de temperatura con el tiempo:
$$ display $$ T \ left (I \ right) = \ beta \ exp \ left ({- \ frac {{\ alpha I}} {{{I _ {\ max}}}} \ right) $$ display $$
donde
$ en línea $ \ alpha, \ beta $ en línea $ Son los coeficientes, Imax es el número de iteraciones.
• Una función que genera una nueva solución. El algoritmo realiza modificaciones aleatorias en el árbol. Primero, seleccione algún vértice. Si el vértice seleccionado es una hoja de un árbol, entonces con igual probabilidad hacemos lo siguiente:
- Reemplace el vértice con un subárbol aleatorio con profundidad 1
- Cambiar la clase de esta hoja (puntos singulares y no singulares)
Si esto NO es una hoja:
- Reemplace el número del punto probado con un número aleatorio de 0 a 47
- Reemplazar vértice con una hoja con una clase aleatoria
- Intercambia dos subárboles de este vértice
La probabilidad P de aceptar el cambio en la iteración I es:
$ en línea $ P = \ exp \ left ({\ frac {{k \ left ({i - 1} \ right) - k \ left (i \ right)}} {T}} \ right) $ en línea $
k es la función de costo, T es la temperatura, i es el número de iteración.
Estas modificaciones al árbol permiten tanto el crecimiento del árbol como su reducción. El método es aleatorio, no garantiza que se obtenga el mejor árbol. Ejecute el método muchas veces, eligiendo la mejor solución. En el artículo original, por ejemplo, se ejecutan 100 veces por cada 100,000 iteraciones cada una, lo que lleva 200 horas de tiempo de procesador. Como muestran los resultados, el resultado es mejor que Tree FAST, especialmente en imágenes ruidosas.
BREVE descriptor
Después de encontrar los puntos singulares, se calculan sus descriptores, es decir, conjuntos de características que caracterizan la vecindad de cada punto singular. BREVE [4] es un descriptor heurístico rápido, construido a partir de 256 comparaciones binarias entre el brillo de los píxeles en una imagen
borrosa . La prueba binaria entre los puntos x e y se define de la siguiente manera:
$$ display $$ \ tau \ left ({P, x, y} \ right): = \ left \ {{\ begin {array} {* {20} {c}} {1: p \ left (x \ right) <p \ left (y \ right)} \\ {0: p \ left (x \ right) \ ge p \ left (y \ right)} \ end {array}} \ right. $$ display $$

En el artículo original, se consideraron varios métodos para elegir puntos para comparaciones binarias. Al final resultó que, una de las mejores maneras es seleccionar puntos al azar utilizando una distribución gaussiana alrededor de un píxel central. Esta secuencia aleatoria de puntos se selecciona una vez y no cambia más. El tamaño del vecindario considerado del punto es de 31x31 píxeles, y la apertura de desenfoque es de 5.
El descriptor binario resultante es resistente a los cambios de iluminación, la distorsión de perspectiva, se calcula y compara rápidamente, pero es muy inestable a la rotación en el plano de la imagen.
ORB: rápido y eficiente
El desarrollo de todas estas ideas fue el algoritmo ORB (Oriented FAST and Rotated BRIEF) [5], en el que se intentó mejorar el rendimiento BRIEF durante la rotación de la imagen. Se propone calcular primero la orientación del punto singular y luego realizar comparaciones binarias de acuerdo con esta orientación. El algoritmo funciona así:
1) Los puntos de características se detectan mediante el uso del árbol FAST rápido en la imagen original y en varias imágenes de la pirámide en miniatura.
2) Para los puntos detectados, se calcula la medida de Harris, se descartan los candidatos con un valor bajo de la medida de Harris.
3) Se calcula el ángulo de orientación del punto singular. Para esto, primero se calculan los momentos de brillo para la vecindad del punto singular:
$ en línea $ {m_ {pq}} = \ sum \ limits_ {x, y} {{x ^ p} {y ^ q} I \ left ({x, y} \ right)} $ en línea $
x, y - coordenadas de píxeles, I - brillo. Y luego el ángulo de orientación del punto singular:
$ en línea $ \ theta = {\ rm {atan2}} \ left ({{m_ {01}}, {m_ {10}}} \ right) $ en línea $
Todo esto, los autores llamaron la "orientación centroide". Como resultado, obtenemos una cierta dirección para la vecindad del punto singular.
4) Teniendo el ángulo de orientación del punto singular, la secuencia de puntos para comparaciones binarias en el descriptor BREVE gira de acuerdo con este ángulo, por ejemplo:
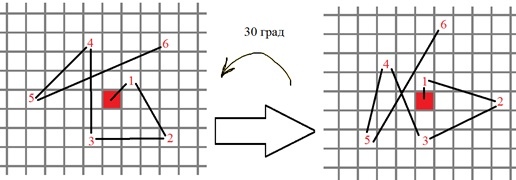
Más formalmente, las nuevas posiciones para los puntos de prueba binarios se calculan de la siguiente manera:
$$ display $$ \ left ({\ begin {array} {* {20} {c}} {{x_i} '} \\ {{y_i}'} \ end {array}} \ right) = R \ left (\ theta \ right) \ cdot \ left ({\ begin {array} {* {20} {c}} {{x_i}} \\ {{y_i}} \ end {array}} \ right) $$ display $$
5) En base a los puntos recibidos, se calcula el descriptor binario BREVE
Y eso es ... ¡no todo! Hay otro detalle interesante en ORB que requiere una explicación por separado. El hecho es que en el momento en que "convertimos" todos los puntos singulares en un ángulo cero, la elección aleatoria de las comparaciones binarias en el descriptor deja de ser aleatoria. Esto lleva al hecho de que, en primer lugar, algunas comparaciones binarias resultan dependientes entre sí, y en segundo lugar, su promedio ya no es igual a 0.5 (1 es más claro, 0 es más oscuro cuando la elección fue aleatoria, luego el promedio fue 0.5) y todo esto reduce significativamente la capacidad del descriptor para distinguir puntos singulares entre ellos.
Solución: debe seleccionar las pruebas binarias "correctas" en el proceso de aprendizaje, esta idea arroja el mismo sabor que el entrenamiento del árbol para el algoritmo FAST-9. Supongamos que tenemos un montón de puntos singulares ya encontrados. Considere todas las opciones posibles para las pruebas binarias. Si el vecindario es 31 x 31, y la prueba binaria es un par de 5 x 5 subconjuntos (debido al desenfoque), entonces hay muchas opciones para elegir N = (31-5) ^ 2. El algoritmo de búsqueda para pruebas "buenas" es el siguiente:
- Calculamos el resultado de todas las pruebas para todos los puntos singulares
- Organice todo el conjunto de pruebas de acuerdo con su distancia del promedio 0.5
- Cree una lista que contendrá las pruebas "buenas" seleccionadas, llamemos a la lista R.
- Agregue a R la primera prueba del conjunto ordenado
- Tomamos la siguiente prueba y la comparamos con todas las pruebas en R. Si la correlación es mayor que el umbral, descartamos la nueva prueba, de lo contrario la agregamos.
- Repita el paso 5 hasta que escribamos el número requerido de pruebas.
Resulta que las pruebas se seleccionan de modo que, por un lado, el valor promedio de estas pruebas sea lo más cercano posible a 0.5, por otro lado, de modo que la correlación entre las diferentes pruebas sea mínima. Y esto es lo que necesitamos. Compare cómo fue y cómo se convirtió:
Afortunadamente, el algoritmo ORB se implementa en la biblioteca OpenCV en la clase cv :: ORB. Estoy usando la versión 2.4.13. El constructor de la clase acepta los siguientes parámetros:
nfeatures - número máximo de puntos singulares
scaleFactor: multiplicador para la pirámide de imágenes, más de uno. Value 2 implementa la clásica pirámide.
Niveles: el número de niveles en la pirámide de imágenes.
edgeThreshold: el número de píxeles en el borde de la imagen donde no se detectan puntos singulares.
firstLevel: deja cero.
WTA_K: la cantidad de puntos necesarios para un elemento del descriptor. Si es igual a 2, se compara el brillo de dos píxeles seleccionados al azar. Esto es lo que se necesita.
scoreType: si es 0, entonces harris se utiliza como una medida característica, de lo contrario, la medida RÁPIDA (basada en la suma de los módulos de las diferencias de brillo en los puntos del círculo). La medida FAST es ligeramente menos estable, pero más rápida.
patchSize: el tamaño del vecindario desde el cual se seleccionan píxeles aleatorios para la comparación. El código busca y compara los puntos singulares en dos imágenes, "templ.bmp" e "img.bmp"
Códigocv::Mat img_object=cv::imread("templ.bmp", 0); std::vector<cv::KeyPoint> keypoints_object, keypoints_scene; cv::Mat descriptors_object, descriptors_scene; cv::ORB orb(500, 1.2, 4, 31, 0, 2, 0, 31);
Si alguien ayudó a comprender la esencia de los algoritmos, entonces no es en vano. A todos los Habr.
Referencias
1.
Puntos de fusión y líneas para el seguimiento de alto rendimiento2.
Aprendizaje automático para la detección de curvas de alta velocidad.3.
Más rápido y mejor: un enfoque de aprendizaje automático para la detección de esquinas4.
BREVE: Características elementales independientes binarias robustas5.
ORB: una alternativa eficiente a SIFT o SURF