La expresividad es una propiedad interesante de los lenguajes de programación. Simplemente combinando expresiones, puede lograr resultados impresionantes. Algunos idiomas rechazan deliberadamente la idea de expresividad, pero Kotlin definitivamente no es tal lenguaje.
Usando construcciones de lenguaje básico y un poco de azúcar, intentaremos recrear el SQL en la sintaxis de Kotlin lo más cerca posible.

Enlace de GitHub para los impacientes
Nuestro objetivo es ayudar al programador a detectar un subconjunto específico de errores en la etapa de compilación. Kotlin, siendo un lenguaje fuertemente tipado, nos ayudará a deshacernos de expresiones inválidas en la estructura de la consulta SQL. Como beneficio adicional, obtendremos más protección contra errores tipográficos y ayuda del IDE en las solicitudes por escrito. No es posible reparar fallas de SQL por completo, pero es bastante posible arreglar algunas áreas problemáticas.
Este artículo le informará sobre la biblioteca de Kotlin, que le permite escribir consultas SQL en la sintaxis de Kotlin. Además, echamos un vistazo al interior de la biblioteca para comprender cómo funciona esto.
Poco de teoría
SQL significa lenguaje de consulta estructurado, es decir La estructura de las consultas está presente, aunque la sintaxis es deficiente: el lenguaje se creó para que pueda ser utilizado por cualquier usuario que ni siquiera tenga habilidades de programación.
Sin embargo, bajo SQL se encuentra una base bastante poderosa en la forma de la teoría de las bases de datos relacionales: todo es muy lógico allí. Para comprender la estructura de las consultas, pasamos a una selección simple:
SELECT id, name
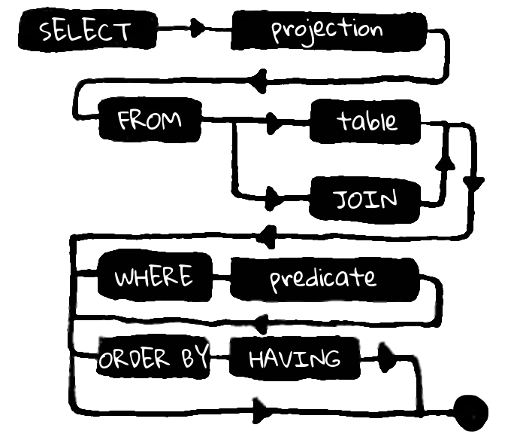
Lo que es importante entender: la solicitud consta de tres partes consecutivas. Cada una de estas partes, en primer lugar, depende de la anterior y, en segundo lugar, implica un conjunto limitado de expresiones para continuar con la solicitud. De hecho, ni siquiera es así: la expresión FROM aquí es claramente primaria en relación con SELECT, porque qué conjunto de campos podemos elegir depende de la tabla desde la que se realiza la selección, pero no al revés.
Portar a Kotlin
Entonces, FROM es primario con respecto a cualquier otra construcción de lenguaje de consulta. De esta expresión surgen todas las opciones posibles para continuar la consulta. En Kotlin, reflejamos esto a través de la función from (T), que tomará un objeto de entrada, que es una tabla que tiene un conjunto de columnas.
object Employees : Table("employees") { val id = Column("id") val name = Column("name") val organizationId = Column("organization_id") }
La función devolverá un objeto que contiene métodos que reflejan la posible continuación de la solicitud. La construcción from siempre viene primero, antes que cualquier otra expresión, por lo que involucra una gran cantidad de extensiones, incluida la SELECT final (a diferencia de SQL, donde SELECT siempre viene antes de FROM). El código equivalente a la consulta SQL anterior se verá así:
from(Employees) .where { e -> e.organizationId eq 1 } .select { e -> e.id .. e.name }
Curiosamente, de esta manera podemos evitar SQL inválido incluso en tiempo de compilación. Cada expresión, cada llamada al método en la cadena implica un número limitado de extensiones. Podemos controlar la validez de la solicitud utilizando el lenguaje Kotlin. Como ejemplo, la expresión where no implica una continuación en forma de otro where y, además, de, pero las construcciones groupBy, having, orderBy, limit, offset y la selección final son todas válidas.
Lambdas pasó como argumentos a las declaraciones where y select están diseñadas para construir el predicado y la proyección, respectivamente (los mencionamos anteriormente). Se pasa una tabla a la entrada lambda para que pueda acceder a las columnas. Es importante que la seguridad de tipo se mantenga también a este nivel: con la ayuda de la sobrecarga del operador, podemos asegurarnos de que el predicado sea una expresión pseudobooleana que no se pueda compilar si hay un error de sintaxis o un error relacionado con el tipo. Lo mismo vale para la proyección.
fun where(predicate: (T) -> Predicate): WhereClause<T> fun select(projection: (T) -> Iterable<Projection>): SelectStatement<T>
Unirse
Las bases de datos relacionales le permiten trabajar con muchas tablas y las relaciones entre ellas. Sería bueno darle al desarrollador la oportunidad de trabajar con JOIN en nuestra biblioteca. Afortunadamente, el modelo relacional encaja bien con todo lo que se describió anteriormente: solo necesita agregar el método de unión, que agregará una segunda tabla a nuestra expresión.
fun <T2: Table> join(table2: T2): JoinClause<T, T2>
JOIN, en este caso, tendrá métodos similares a los proporcionados por la expresión FROM, con la única diferencia de que la proyección y el predicado lambdas tomarán dos parámetros cada uno para poder acceder a las columnas de ambas tablas.
from(Employees) .join(Organizations).on { e, o -> o.id eq e.organizationId } .where { e, o -> e.organizationId eq 1 } .select { e, o -> e.id .. e.name .. o.name }
Gestión de datos
El lenguaje de manipulación de datos es una herramienta de lenguaje SQL que, además de consultar tablas, le permite insertar, modificar y eliminar datos. Estos diseños encajan bien con nuestro modelo. Para admitir la actualización y eliminación, solo necesitamos complementar las expresiones from y where con una variante con la llamada de los métodos correspondientes. Para apoyar la inserción, introducimos una función adicional.
from(Employees) .where { e -> e.id eq 1 } .update { e -> e.name("John Doe") } from(Employees) .where { e -> e.id eq 0 } .delete() into(Employees) .insert { e -> e.name("John Doe") .. e.organizationId(1) }
Descripción de datos
SQL funciona con datos estructurados en forma de tablas. Las tablas requieren una descripción antes de trabajar con ellas. Esta parte del lenguaje se llama lenguaje de definición de datos.
Las instrucciones CREATE TABLE y DROP TABLE se implementan de manera similar: la función over servirá como punto de partida.
over(Employees) .create { integer(it.id).primaryKey(autoIncrement = true).. text(it.name).unique().notNull().. integer(it.organizationId).foreignKey(references = Organizations.id) }
over(Employees).drop()