Después de leer el artículo "
Google Neural Machine Translation ", recordé la última traducción automática de error épico de Google que se ejecuta en Internet últimamente. Quien no puede esperar mucho, inmediatamente llegamos al final del artículo.
Bueno, para empezar, una pequeña teoría:
GNMT es el sistema de traducción automática neuronal (
NMT ) de Google que utiliza una red neuronal (
ANN ) para aumentar la precisión y la velocidad de la traducción, y en particular para crear opciones de traducción de texto mejores y más naturales en Google Translate.
En el caso de GNMT, este es el llamado método de traducción basado en
ejemplos (
EBMT ), es decir
El ANN subyacente al método aprende de millones de ejemplos de traducción, y a diferencia de otros sistemas, este método permite la llamada
traducción de cero disparo , es decir, traducir de un idioma a otro sin ejemplos explícitos para este par de idiomas específicos. en el proceso de aprendizaje (en la muestra de entrenamiento).
 Fig. 1. Traducción Zero-Shot
Fig. 1. Traducción Zero-ShotAdemás, GNMT está diseñado principalmente para mejorar la traducción de frases y oraciones, porque solo en la traducción contextual, no puede usar la versión literal de la traducción y, a menudo, la oración se traduce de manera completamente diferente.
Además, volviendo a la traducción cero, Google está tratando de resaltar algún componente común que sea válido para varios idiomas a la vez (tanto al buscar dependencias como al construir relaciones para oraciones y frases).
Por ejemplo, en la Figura 2, esta "comunidad" interlingua se muestra entre todos los pares posibles para japonés, coreano e inglés.
 Fig. 2. Interlingua. Presentación tridimensional de datos de red para japonés, coreano e inglés
Fig. 2. Interlingua. Presentación tridimensional de datos de red para japonés, coreano e inglés .
La parte (a) muestra la "geometría" general de tales traducciones, donde los puntos están coloreados por significado (y el mismo color para el mismo significado en varios pares de idiomas).
La parte (b) muestra un aumento en uno de los grupos, parte © en los colores del idioma original.
GNMT utiliza el gran aprendizaje profundo
ANN (
DNN ), que, aprendido de millones de ejemplos, debería mejorar la calidad de la traducción, aplicando aproximaciones abstractas contextuales para la opción de traducción más adecuada. En términos generales, elige el mejor resultado, en el sentido de la gramática más apropiada del lenguaje humano, teniendo en cuenta la comunidad de construir enlaces, frases y oraciones para varios idiomas (es decir, resaltar y enseñar por separado el modelo o las capas interlingua).
Sin embargo, DNN, tanto en el proceso de aprendizaje como en el proceso de trabajo, generalmente se basa en inferencia estadística (probabilística) y rara vez está sujeto a algoritmos no probabilísticos adicionales. Es decir Para evaluar el mejor resultado posible que ha salido del variador, se seleccionará la mejor opción estadísticamente (probable).
Naturalmente, todo esto depende de la calidad de la muestra de entrenamiento (y / o la calidad de los algoritmos en el caso de un modelo de autoaprendizaje).
Dado el método de traducción de disparo cero y recordando algún componente común (interlingua), en presencia de una conexión profunda lógica positiva para un idioma, y la ausencia de componentes negativos para otros idiomas, surgió algún error abstracto en el proceso de aprendizaje y, como resultado, Lo más probable es que la traducción de una determinada frase para un idioma se repita para otros idiomas o incluso pares de idiomas.
Fracaso épico realmente nuevo
Se puede hacer clic en todas las imágenes (como prueba en la página correspondiente del Traductor de Google).Aleman: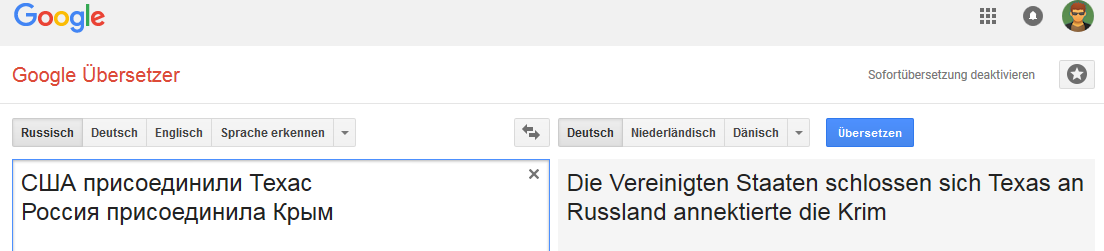 Inglés
Inglés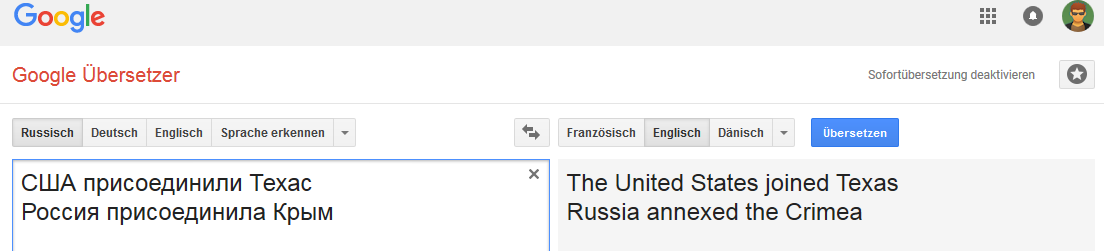 Holandés:
Holandés: Danés:
Danés: Francés:
Francés:
Etc.
En lugar de una conclusión
La conexión es estable para la palabra Rusia (en el sentido de que cuando Rusia es reemplazada, por ejemplo, por el Imperio ruso, la opción de "transferencia" cambia).
Y no es muy estable con ciertos cambios en las frases que no son típicas para la traducción al inglés, pero comunes, por ejemplo, para el ruso, el alemán y el holandés.
Desafortunadamente, esto está lejos de ser el único caso e Internet está repleto de todo tipo de errores de Google Translate.
Y me parece que una parte considerable de los errores existentes se manifiesta debido a una combinación de varios factores, que van desde la calidad de la muestra de entrenamiento hasta la calidad de los algoritmos de análisis semántico y morfológico para un idioma en particular (y el modelo de aprendizaje en particular).
Una vez, un colega sugirió participar en el Google Text Normalization Challenge (para ruso e inglés) en kaggle ...
Antes de aceptar, hice un pequeño análisis de la calidad de la muestra de prueba de entrenamiento para todas las clases de tokens para ambos idiomas ... y, como resultado, me negué a participar, porque cuanto más cavaba, más fuerte era la sensación de que la competencia sería como una lotería o el que gana ganaría con mayor precisión podrá repetir todos los errores cometidos durante la creación semi-manual del conjunto de entrenamiento de Google.
Incluso quería escribir un artículo sobre el tema "Cómo lanzar fácilmente 50K ...", pero el tiempo, que esté bien.
Si alguien está interesado de repente, intentaré esculpirme un poco.
[UPD] ¿Por qué es esto realmente un archivo? Sin distraerse con la letra, el subtexto "político" y todo tipo de intentos de justificar "una persona traduciría de esta manera", etc.
1. Esta es una traducción incorrecta. El punto
2. En este caso ilustrativo, GNMT muestra una ausencia total de cualquier modelo de clasificación (en el sentido de
CADM , en el que Google debe brillar, porque tienen muchos datos de todas partes). Solo en la medida en que los sujetos en ambos casos son países / estados, y los suplementos son entidades geográficas (territorio).
Incluso la regla de plausibilidad más tonta de alguna clasificación difusa de K-nn nunca habría cometido tal error. Ya no hablamos de algoritmos modernos para la clasificación y construcción de relaciones (semánticas).
Como dice el refrán nada personal, matemática simple ... Bueno, si Google decidió indiscriminadamente alimentar su red con recortes de la prensa sensacionalista, entonces tengo malas noticias para él.
PD Sin embargo, como un profesor que respeté me dijo una vez: "A veces es muy difícil demostrarle a un pájaro carpintero que es un pájaro carpintero, especialmente si está seguro de que es más inteligente que un profesor".