
Hola Habr! Mi nombre es Alexey Pristavko, soy el director de proyectos web en DataLine. Mi artículo de hoy trata sobre cómo solucionar o prevenir problemas de rendimiento del backend de la aplicación web.
Esto se centrará en cómo optimizar las aplicaciones web que sufren problemas crónicos de escalabilidad, rendimiento o confiabilidad.
Cualquier persona interesada: ¡bienvenido bajo el corte!
Terminología
Comencemos con un vistazo a la terminología. Hablando sobre el rendimiento de proyectos web o sistemas web, me refiero principalmente al back-end y al componente del servidor. Lo que sucede al cargar páginas en un navegador es una historia completamente diferente, que, muy probablemente, se dedicará a un artículo separado.
- La medida del rendimiento de la aplicación será el número de solicitudes procesadas por segundo (RPS) y su velocidad de ejecución (TTFB - Tiempo hasta el primer byte).
- En consecuencia, por escalabilidad del sistema nos referimos a un conjunto de oportunidades para aumentar el RPS.
Ahora sobre la fiabilidad. Aquí es necesario separar dos conceptos: tolerancia a fallas y tolerancia a desastres.
- Resiliencia ante fallas : la capacidad de un sistema de fallar si uno o más servidores no pueden continuar trabajando dentro de los parámetros requeridos.
- Los sistemas con redundancia de copia de seguridad completa (el llamado segundo hombro) y capaces de funcionar sin una fuerte reducción con la falla completa de uno de los centros de datos se consideran resistentes a los desastres .
Al mismo tiempo, un sistema tolerante a desastres es un sistema a prueba de fallas. Una situación en la que un sistema tolerante a desastres, pero no tolerante a fallas continúa trabajando en un solo "hombro" es bastante normal. Pero si uno de los servidores falla, el sistema también fallará.
Ahora que hemos descubierto los conceptos clave y actualizado la terminología actual, es hora de pasar directamente a los conceptos básicos de optimización y trucos de la vida.
Donde comenzar la optimización

¿Cómo entender dónde comenzar la optimización? Antes de apresurarse a optimizar, respire profundamente y pase tiempo investigando la aplicación.
Asegúrese de dibujar un diagrama detallado. Muestre en él todos los componentes de la aplicación y sus relaciones. Después de examinar este esquema, puede descubrir vulnerabilidades previamente discretas y puntos potenciales de falla.
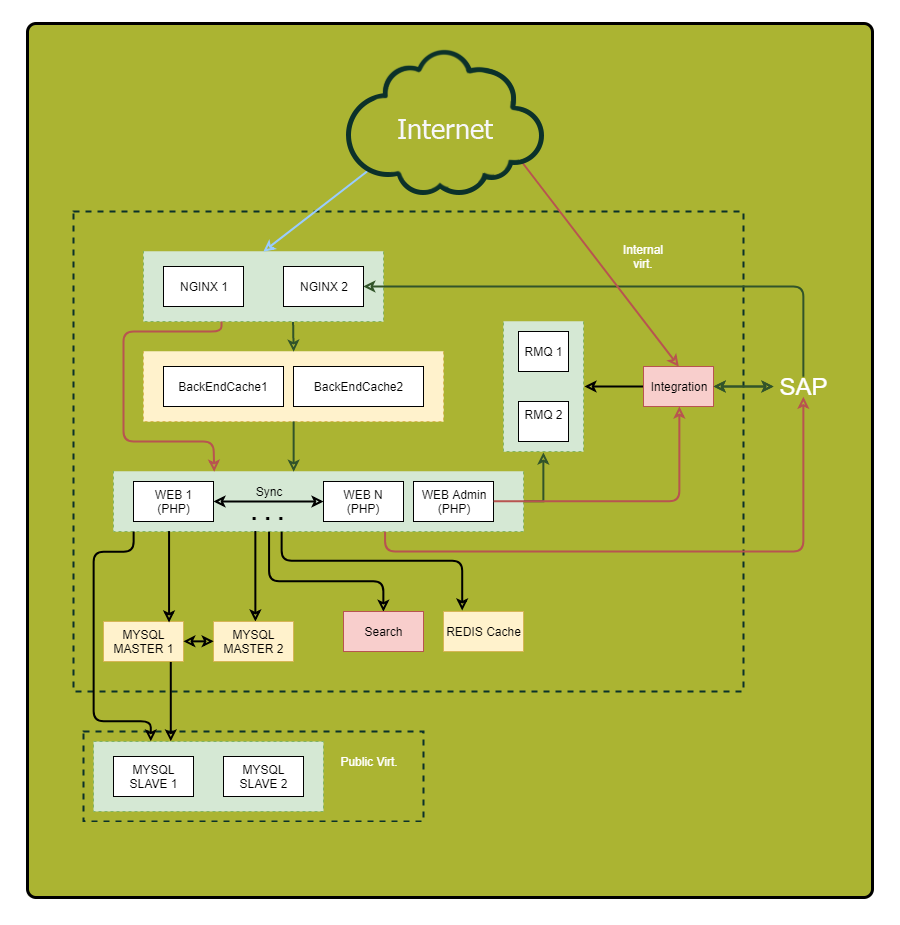
"¿Qué? Donde ¿Cuándo? - optimizar consultas
Presta especial atención a las solicitudes sincrónicas. Permítame recordarle, estas son solicitudes cuando enviamos una solicitud en el mismo hilo y esperamos una respuesta. Aquí es donde se encuentran las razones de los frenos graves cuando algo sale mal del otro lado. Por lo tanto, si puede reducir el número de solicitudes sincrónicas o reemplazarlas por otras asíncronas, hágalo.
Aquí hay algunos trucos para ayudarlo a rastrear sus solicitudes:
- Asigne un identificador único a cada solicitud entrante. Nginx tiene una variable incorporada $ request_id para esto. Pase el identificador en los encabezados del back-end y escriba en todos los registros. Para que pueda rastrear convenientemente las solicitudes.
- Registre no solo el final de la solicitud en el componente externo, sino también su comienzo. Entonces, mide la duración real de la llamada externa. Puede diferir significativamente de lo que ve en el sistema remoto, por ejemplo, debido a problemas de red o frenos DNS.
Entonces, los datos se recopilan. Ahora analicemos los puntos problemáticos. Definir:
- ¿Dónde pasa más tiempo?
- ¿De dónde provienen la mayoría de las solicitudes?
- ¿De dónde vienen las solicitudes más largas?
Como resultado, obtendrá una lista de las secciones más interesantes del sistema para la optimización.
Consejo: Si algún punto "recopila" muchas consultas pequeñas, intente combinarlas en una consulta grande para reducir la sobrecarga. Los resultados de consultas largas a menudo tienen sentido en la memoria caché.
Nos almacenamos sabiamente
Existen reglas generales de almacenamiento en caché en las que debe confiar al optimizar:
- Cuanto más cerca esté el caché del consumidor, más rápido será el trabajo. Para la aplicación, el lugar "más cercano" será RAM. Para el usuario, su navegador.
- El almacenamiento en caché acelera la adquisición de datos y reduce la carga en la fuente.
Si diez servidores web realizan las mismas consultas a la base de datos, un caché intermedio centralizado, por ejemplo en Redis, dará un mayor porcentaje de visitas (en comparación con el caché local) y reducirá la carga general en la base de datos, lo que mejorará significativamente la imagen general.
Consejo 1: Realice el almacenamiento en caché de componentes de la página terminada en el lado de Nginx con Edge Side incluye. Se adapta bien a la arquitectura de microservicios / SOA y descarga el sistema en su conjunto, mejorando en gran medida la velocidad de respuesta.
Consejo 2: realice un seguimiento del tamaño de los objetos en la memoria caché, la proporción de aciertos y los volúmenes de escritura / lectura. Cuanto más grande sea el objeto, más tardará en procesarse. Si escribe en el caché con más frecuencia o más de lo que lee, ese caché no es su amigo. Vale la pena eliminarlo o pensar en aumentar su efectividad.
Consejo 3: use sus propias cachés de bases de datos cuando sea posible. La configuración adecuada puede acelerar el trabajo.
Cargar perfiles
Pasamos a cargar perfiles. Como sabes, hay dos tipos principales: OLAP y OLTP.
- Para OLAP (procesamiento analítico en línea), la cantidad de tráfico gastado por segundo es importante.
- Para OLTP (procesamiento de transacciones en línea), el indicador clave es la velocidad de respuesta, tiempos de milisegundos.
Muy a menudo, es efectivo separar estos dos tipos de carga. Como mínimo, necesitará un ajuste separado de la base de datos y, posiblemente, de otros componentes del sistema.
Consejo: las solicitudes de lectura desde el panel de administración generalmente se procesan con el tipo OLAP. Cree una copia separada de la base de datos y un servidor web para que esta tarea descargue el sistema principal.
Bases de datos

Entonces, naturalmente, nos acercamos a una de las etapas más difíciles de optimización, a saber, la optimización de la base de datos.
Permítame recordarle la regla general: cuanto más pequeña es la base de datos, más rápido funciona. La organización misma de la base de datos es crucial cuando se trata de velocidad.
Si es posible, almacene
datos históricos , registros de aplicaciones y datos
utilizados con frecuencia en diferentes bases de datos. Mejor aún, publíquelos en diferentes servidores. Esto no solo facilitará la vida de la base de datos principal, sino que también dará más espacio para una mayor optimización, por ejemplo, en algunos casos permitirá el uso de diferentes índices para diferentes cargas. Además, la "uniformidad" de la carga simplifica la vida del planificador y el optimizador de consultas del servidor de bases de datos.
Y nuevamente sobre la importancia de planificar
Para no confundir la optimización donde realmente no es necesaria, elija el hardware en función de las tareas.
- Para solicitudes pequeñas, pero frecuentes, es mejor tomar más núcleos de procesador.
- Para solicitudes pesadas: menos núcleos con una mayor velocidad de reloj.
Intente poner el volumen de trabajo de la base de datos en la RAM. Si esto no es posible o hay una gran cantidad de solicitudes de escritura, es hora de buscar transferir las bases de datos a SSD. Darán un aumento significativo en la velocidad de trabajo con el disco.
Escalamiento

Arriba, describí la mecánica clave para mejorar el rendimiento de la aplicación sin aumentar sus recursos físicos.
Ahora hablaremos sobre cómo elegir una estrategia de escala y aumentar la resistencia.
Hay dos tipos de escalado del sistema:
- vertical : el crecimiento de los recursos mientras se mantiene el número de entidades;
- horizontal : un aumento en el número de entidades.
Crecer alto
Comencemos eligiendo una estrategia de escala vertical.
Primero, considere el
aumento de la potencia del sistema . Si su sistema funciona dentro de un servidor, tendrá que elegir entre aumentar la capacidad del servidor actual o comprar otro.
Puede parecer que la primera opción es más fácil y segura. Pero será más previsible comprar un servidor más y recibir una gran tolerancia a fallas como un bono a la productividad. Hablé sobre esto al comienzo del artículo.
Si su sistema tiene varios servidores y la opción es aumentar la capacidad de los existentes o comprar algunos más, preste atención a la parte financiera. Por ejemplo, un servidor potente puede ser más costoso que dos 50% "más débiles". Por lo tanto, será razonable detenerse en la segunda opción de compromiso. Al mismo tiempo, con una gran cantidad de servidores, la relación de rendimiento, consumo de energía y el costo de un rack completo es crucial.
Crecer de ancho
La escala horizontal es una historia sobre tolerancia a fallas y agrupamiento. En el caso general, mientras más instancias tengamos de una entidad, mayor será la tolerancia a fallas de toda la solución.
Probablemente lo primero que desea escalar son
los servidores de aplicaciones . El primer obstáculo para esto es la organización del trabajo con fuentes de datos centralizadas. Además de las bases de datos, también son datos de sesión y contenido estático. Esto es lo que te recomiendo que hagas:
- Para almacenar sesiones, use Couchbase, no el Memcached habitual, ya que funciona con el mismo protocolo, pero, a diferencia de memcached, admite la agrupación en clúster.
- Todas las estadísticas , especialmente los grandes volúmenes de imágenes y documentos, se almacenan por separado y se sirven con Nginx, y no desde el código de la aplicación. Esto le ahorrará dinero en flujos y simplificará la administración de la infraestructura.
"Levantando" la base de datos
Difícil de escalar bases de datos. Hay dos técnicas principales para esto: fragmentación y replicación. Considéralos.
Durante la
replicación, agregamos copias completamente idénticas de la base de datos al sistema, mientras
fragmentamos , partes separadas lógicamente, fragmentos. Al mismo tiempo, es altamente deseable llevar a cabo el fragmentación en paralelo con la replicación (replicación) de cada fragmento para no perder la tolerancia a fallas.
Recuerde: a menudo, un clúster de base de datos consta de un nodo maestro que se hace cargo de la secuencia de escritura y varios nodos esclavos utilizados para la lectura. Desde el punto de vista de la tolerancia a fallas, esto es ligeramente mejor que un solo servidor, ya que la tolerancia a fallas general está determinada por el elemento menos estable del sistema.
Los esquemas con más de dos asistentes de base de datos (topología en anillo) sin confirmar el registro en cada servidor, a menudo sufren inconsistencias. En caso de falla de uno de los servidores, será extremadamente difícil restaurar la integridad lógica de los datos en el clúster.
Consejo: Si en su caso no es racional tener varios servidores maestros, considere la posibilidad arquitectónica de que el sistema funcione sin un maestro durante al menos una hora. En caso de accidente, esto le dará tiempo para reemplazar el servidor sin tiempo de inactividad de todo el sistema.
Consejo: Si necesita mantener más de 2 maestros de bases de datos, le recomiendo que considere las soluciones NoSQL, ya que muchas de ellas tienen mecanismos incorporados para llevar los datos a un estado consistente.
En la búsqueda de la tolerancia a fallas, en ningún caso no olvide que la replicación le asegura
solo contra fallas físicas del servidor . No se guardará de la corrupción de datos lógicos debido a un error del usuario.
Recuerde: todos los datos importantes deben ser respaldados y almacenados como una copia independiente no editable.
En lugar de una conclusión
Por último, un par de consejos de rendimiento para realizar copias de seguridad:
Consejo 1: Extraiga datos de una réplica de base de datos separada para no sobrecargar el servidor activo.
Consejo 2: Tenga a mano una réplica adicional, ligeramente "retrasada" en el tiempo de la base de datos. En caso de accidente, esto ayudará a reducir la cantidad de datos perdidos.
Los métodos y técnicas presentados en este artículo nunca deben usarse a ciegas, sin analizar la situación actual y comprender lo que le gustaría lograr. Puede encontrar "sobre-optimización", y el sistema resultante será solo un 10% más rápido, pero un 50% más vulnerable a los accidentes.
Eso es todo Si tiene alguna pregunta, me complacerá responderla en los comentarios.