En el festival de datos 2 en Minsk, Vladimir Iglovikov, ingeniero de visión artificial en Lyft, comentó
perfectamente que la mejor manera de aprender Data Science es participar en competiciones, ejecutar soluciones de otras personas, combinarlas, lograr resultados y mostrar su trabajo. En realidad, dentro del marco de este paradigma, decidí echar un vistazo más de cerca a la
competencia de evaluación de riesgo de crédito de Home Credit y explicar (a los principiantes, científicos y ante todo a mí mismo) cómo analizar adecuadamente dichos conjuntos de datos y construir modelos para ellos.
(foto
de aquí )

Home Credit Group es un grupo de organizaciones de crédito bancarias y no bancarias que realiza operaciones en 11 países (incluida Rusia como Home Credit and Finance Bank LLC). El propósito de la competencia es crear una metodología para evaluar la solvencia de los prestatarios que no tienen un historial crediticio. Lo que parece bastante noble: los prestatarios de esta categoría a menudo no pueden obtener ningún crédito del banco y se ven obligados a recurrir a estafadores y micropréstamos. Es interesante que el cliente no establezca requisitos de transparencia e interpretabilidad del modelo (como suele ser el caso con los bancos), puede usar cualquier cosa, incluso una red neuronal.
La muestra de capacitación consta de más de 300 mil registros, hay muchos signos: 122, entre ellos hay muchos categóricos (no numéricos). Las señales describen al prestatario con suficiente detalle, hasta el material del que están hechas las paredes de su casa. Parte de los datos están contenidos en 6 tablas adicionales (datos de la agencia de crédito, saldo de tarjetas de crédito y préstamos anteriores), estos datos también deben procesarse de alguna manera y cargarse en los principales.
La competencia parece una tarea de clasificación estándar (1 en el campo OBJETIVO significa cualquier dificultad con los pagos, 0 significa que no hay dificultades). Sin embargo, no se debe predecir 0/1, sino la probabilidad de problemas (que, por cierto, puede resolverse fácilmente mediante los métodos de predicción de probabilidad predic_proba que tienen todos los modelos complejos).
A primera vista, el conjunto de datos es bastante estándar para las tareas de aprendizaje automático, los organizadores ofrecieron un gran premio de $ 70k, como resultado, más de 2,600 equipos participan en la competencia hoy, y la batalla es en milésimas de un por ciento. Sin embargo, por otro lado, tal popularidad significa que el conjunto de datos se ha estudiado de arriba abajo y muchos núcleos se han creado con buena EDA (Análisis de datos exploratorios: investigación y análisis de datos en la red, incluidos gráficos), Ingeniería de características (trabajo con atributos) y con modelos interesantes. (Kernel es un ejemplo de trabajo con un conjunto de datos que cualquiera puede diseñar para mostrar su trabajo a otros kugglers).
Los granos merecen atención:
Para trabajar con datos, generalmente se recomienda el siguiente plan, que intentaremos seguir.
- Comprender el problema y familiarizarse con los datos
- Limpieza y formateo de datos
- EDA
- Modelo base
- Mejora modelo
- Interpretación del modelo
En este caso, debe tener en cuenta el hecho de que los datos son bastante extensos y no se pueden dominar de inmediato, tiene sentido actuar por etapas.
Comencemos importando las bibliotecas que necesitamos en el análisis para trabajar con datos en forma de tablas, construir gráficos y trabajar con matrices.
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline
Descargue los datos. Veamos que tenemos todos. Esta ubicación en el directorio "../input/", por cierto, está conectada con el requisito de colocar sus núcleos en Kaggle.
import os PATH="../input/" print(os.listdir(PATH))
['application_test.csv', 'application_train.csv', 'bureau.csv', 'bureau_balance.csv', 'credit_card_balance.csv', 'HomeCredit_columns_description.csv', 'installments_payments.csv', 'POS_CASH_balance.csv', 'previous_application.csv']Hay 8 tablas con datos (sin contar la tabla HomeCredit_columns_description.csv, que contiene una descripción de los campos), que se interconectan de la siguiente manera:
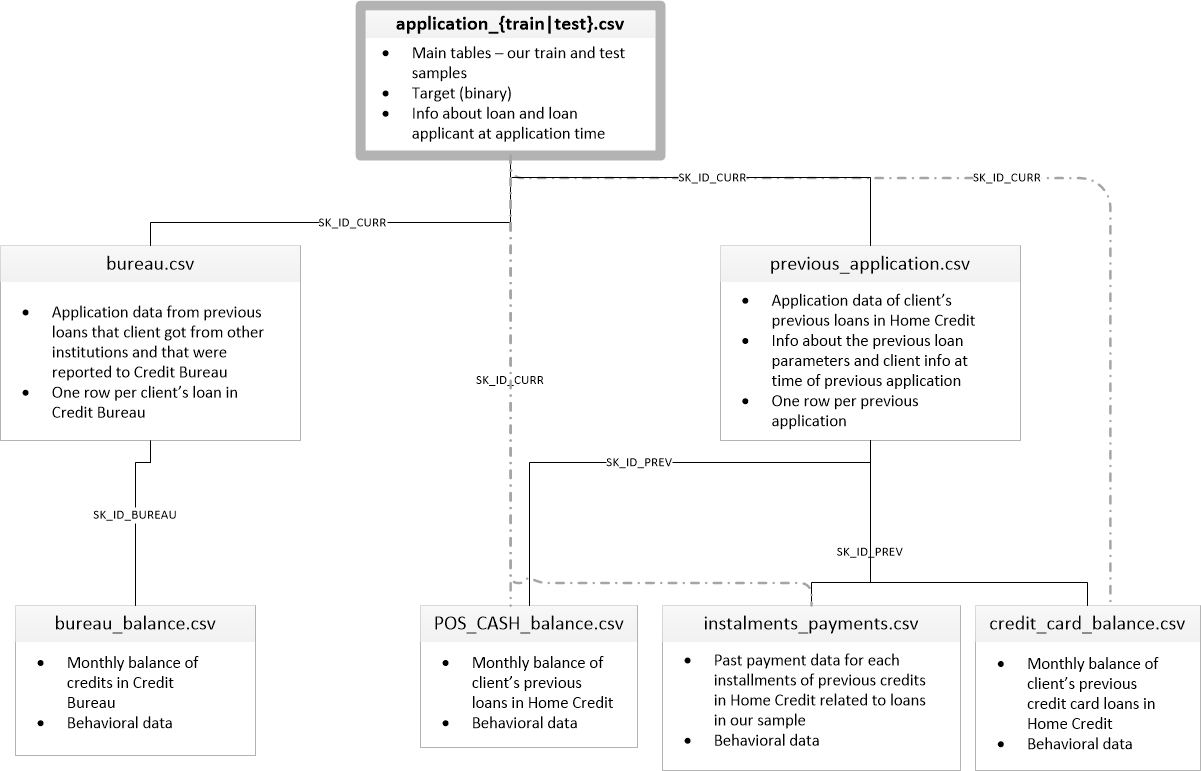
application_train / application_test: datos maestros, el prestatario se identifica por el campo SK_ID_CURR
buró: Datos sobre préstamos anteriores de otras instituciones de crédito de un buró de crédito
bureau_balance: datos mensuales sobre préstamos anteriores de la oficina. Cada línea es el mes de usar el préstamo
previous_application: Solicitudes anteriores para préstamos en Home Credit, cada una tiene un campo único SK_ID_PREV
POS_CASH_BALANCE: Datos mensuales sobre préstamos en Home Credit con la emisión de efectivo y préstamos para la compra de bienes.
credit_card_balance: datos mensuales del saldo de la tarjeta de crédito en Home Credit
cuotas_pago: Historial de pagos de préstamos anteriores en Home Credit.
Centrémonos primero en la fuente de datos principal y veamos qué información se puede extraer de ella y qué modelos construir. Descargue los datos básicos.
- app_train = pd.read_csv (PATH + 'application_train.csv',)
- app_test = pd.read_csv (PATH + 'application_test.csv',)
- print ("formato del conjunto de entrenamiento:", app_train.shape)
- print ("formato de muestra de prueba:", app_test.shape)
- formato de muestra de entrenamiento: (307511, 122)
- formato de muestra de prueba: (48744, 121)
En total, tenemos 307 mil registros y 122 signos en la muestra de capacitación y 49 mil registros y 121 signos en la prueba. La discrepancia se debe obviamente al hecho de que no hay un atributo objetivo TARGET en la muestra de prueba, y lo predeciremos.
Echemos un vistazo más de cerca a los datos.
pd.set_option('display.max_columns', None)
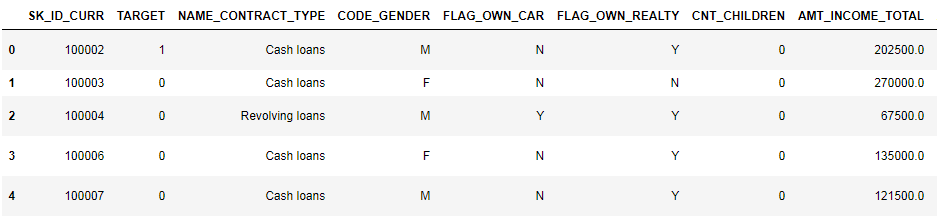
(se muestran las primeras 8 columnas)
Es bastante difícil ver datos en este formato. Veamos la lista de columnas:
app_train.info(max_cols=122)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MBRecupere anotaciones detalladas por campo en el archivo HomeCredit_columns_description. Como puede ver en la información, parte de los datos está incompleta y parte es categórica, se muestran como objeto. La mayoría de los modelos no funcionan con dichos datos, tendremos que hacer algo con ellos. Sobre esto, el análisis inicial puede considerarse completado, iremos directamente a EDA
Análisis exploratorio de datos o minería de datos primarios
En el proceso EDA, contamos las estadísticas básicas y dibujamos gráficos para encontrar tendencias, anomalías, patrones y relaciones dentro de los datos. El objetivo de EDA es averiguar qué pueden decir los datos. Por lo general, el análisis va de arriba a abajo, desde una visión general hasta el estudio de zonas individuales que llaman la atención y pueden ser de interés. Posteriormente, estos hallazgos pueden usarse en la construcción del modelo, la selección de características para él y en su interpretación.
Distribución Variable Objetivo
app_train.TARGET.value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64 plt.style.use('fivethirtyeight') plt.rcParams["figure.figsize"] = [8,5] plt.hist(app_train.TARGET) plt.show()
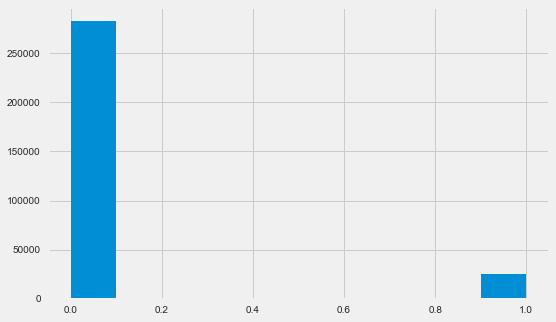
Permítame recordarle que 1 significa problemas de cualquier tipo con un retorno, 0 significa que no hay problemas. Como puede ver, principalmente los prestatarios no tienen problemas con el pago, la parte problemática es de aproximadamente el 8%. Esto significa que las clases no están equilibradas y esto debe tenerse en cuenta al construir el modelo.
Investigación de datos faltantes
Hemos visto que la falta de datos es bastante sustancial. Veamos con más detalle dónde y qué falta.
122 .
67 .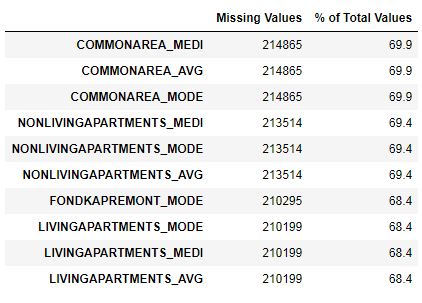
En formato gráfico:
plt.style.use('seaborn-talk') fig = plt.figure(figsize=(18,6)) miss_train = pd.DataFrame((app_train.isnull().sum())*100/app_train.shape[0]).reset_index() miss_test = pd.DataFrame((app_test.isnull().sum())*100/app_test.shape[0]).reset_index() miss_train["type"] = "" miss_test["type"] = "" missing = pd.concat([miss_train,miss_test],axis=0) ax = sns.pointplot("index",0,data=missing,hue="type") plt.xticks(rotation =90,fontsize =7) plt.title(" ") plt.ylabel(" %") plt.xlabel("")
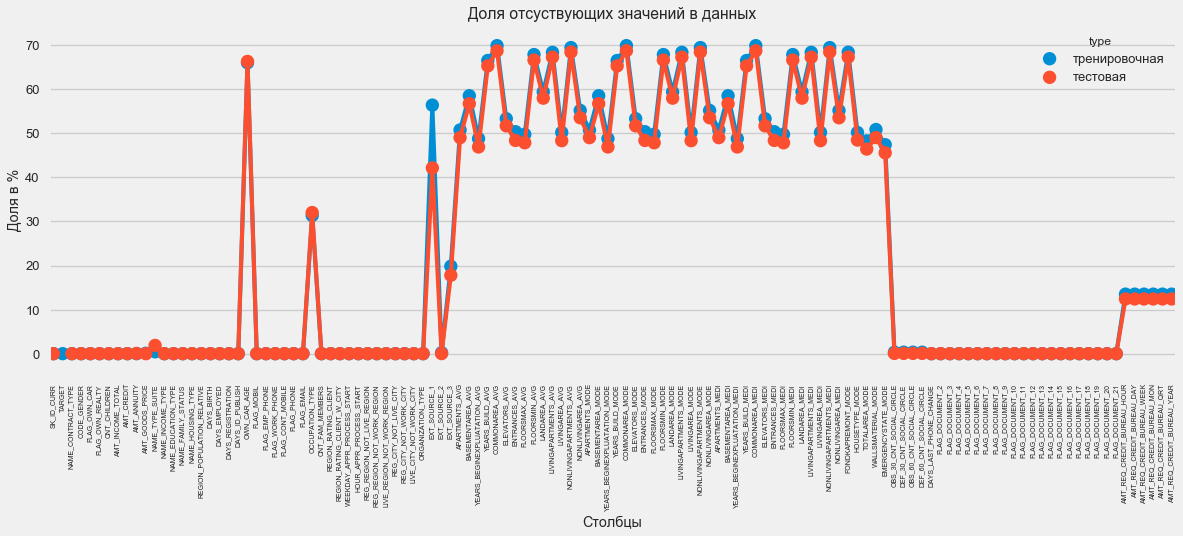
Hay muchas respuestas a la pregunta "qué hacer con todo esto". Puede llenarlo con ceros, puede usar valores medios, simplemente puede eliminar líneas sin la información necesaria. Todo depende del modelo que planeemos usar, ya que algunos de ellos hacen frente perfectamente a los valores perdidos. Mientras recordamos este hecho y dejamos todo como está.
Tipos de columna y codificación categórica
Como recordamos parte de las columnas es de tipo objeto, es decir, no tiene un valor numérico, pero refleja alguna categoría. Miremos estas columnas más de cerca.
app_train.dtypes.value_counts()
float64 65
int64 41
object 16
dtype: int64 app_train.select_dtypes(include=[object]).apply(pd.Series.nunique, axis = 0)
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64Tenemos 16 columnas, cada una con 2 a 58 opciones de valor diferentes. En general, los modelos de aprendizaje automático no pueden hacer nada con tales columnas (excepto algunas, como LightGBM o CatBoost). Como planeamos probar diferentes modelos en el conjunto de datos, es necesario hacer algo con esto. Básicamente hay dos enfoques:
- Codificación de etiquetas: a las categorías se les asignan dígitos 0, 1, 2, etc., y se escriben en la misma columna
- One-Hot-encoding: una columna se descompone en varias según el número de opciones y estas columnas indican qué opción tiene este registro.
Entre los más populares, vale la pena señalar
la codificación media del objetivo (gracias por aclarar los
rrangeorangepants ).
Hay un pequeño problema con la codificación de etiquetas: asigna valores numéricos que no tienen nada que ver con la realidad. Por ejemplo, si estamos tratando con un valor numérico, entonces el ingreso del prestatario de 100,000 es definitivamente mayor y mejor que el ingreso de 20,000. Pero podemos decir que, por ejemplo, una ciudad es mejor que otra porque a una se le asigna el valor 100 y la otra 200 ?
La codificación One-Hot, por otro lado, es más segura, pero puede producir columnas "adicionales". Por ejemplo, si codificamos el mismo género usando One-Hot, obtenemos dos columnas, "género masculino" y "género femenino", aunque una sería suficiente, "¿es masculino".
Para un buen conjunto de datos, sería necesario codificar signos con baja variabilidad utilizando Label Encoding y todo lo demás: One-Hot, pero por simplicidad codificamos todo de acuerdo con One-Hot. Prácticamente no afectará la velocidad de cálculo y el resultado. El proceso de codificación de pandas en sí mismo es muy simple.
app_train = pd.get_dummies(app_train) app_test = pd.get_dummies(app_test) print('Training Features shape: ', app_train.shape) print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 246)
Testing Features shape: (48744, 242)Como el número de opciones en las columnas de selección no es igual, el número de columnas ahora no coincide. Se requiere alineación: debe eliminar las columnas del conjunto de entrenamiento que no están en el conjunto de prueba. Esto hace que el método de alineación, necesite especificar axis = 1 (para columnas).
: (307511, 242)
: (48744, 242)Correlación de datos
Una buena manera de comprender los datos es calcular los coeficientes de correlación de Pearson para los datos relativos al atributo objetivo. Este no es el mejor método para mostrar la relevancia de las características, pero es simple y le permite tener una idea de los datos. Los coeficientes se pueden interpretar de la siguiente manera:
- 00-.19 "muy débil"
- 20-.39 "débil"
- 40-.59 "promedio"
- 60-.79 fuerte
- 80-1.0 "muy fuerte"
:
DAYS_REGISTRATION 0.041975
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
ORGANIZATION_TYPE_XNA -0.045987
DAYS_EMPLOYED -0.044932
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64Por lo tanto, todos los datos se correlacionan débilmente con el objetivo (excepto el objetivo en sí, que, por supuesto, es igual a sí mismo). Sin embargo, la edad y algunas "fuentes de datos externas" se distinguen de los datos. Estos son probablemente algunos datos adicionales de otras organizaciones de crédito. Es curioso que aunque el objetivo se declare independiente de dichos datos al tomar una decisión de crédito, de hecho nos basaremos principalmente en ellos.
Edad
Está claro que cuanto mayor es el cliente, mayor es la probabilidad de un retorno (hasta cierto límite, por supuesto). Pero por alguna razón, la edad se indica en días negativos antes de que se emita un préstamo, por lo tanto, se correlaciona positivamente con la falta de reembolso (lo que parece algo extraño). Lo llevamos a un valor positivo y observamos la correlación.
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH']) app_train['DAYS_BIRTH'].corr(app_train['TARGET'])
-0.078239308309827088Echemos un vistazo más de cerca a la variable. Comencemos con el histograma.
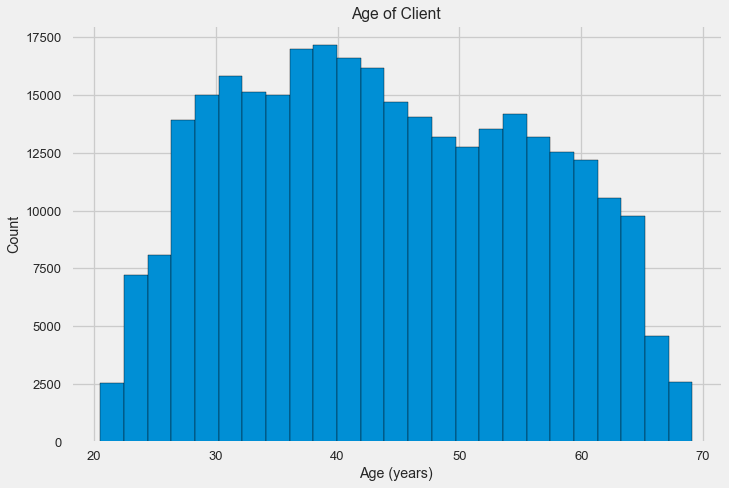
El histograma de distribución en sí puede ser un poco útil, excepto que no vemos valores atípicos especiales y todo parece más o menos creíble. Para mostrar el efecto de la influencia de la edad en el resultado, podemos construir un gráfico de estimación de la densidad del núcleo (KDE): la distribución de la densidad nuclear, pintada con los colores del atributo objetivo. Muestra la distribución de una variable y puede interpretarse como un histograma suavizado (calculado como un núcleo gaussiano para cada punto, que luego se promedia para suavizar).
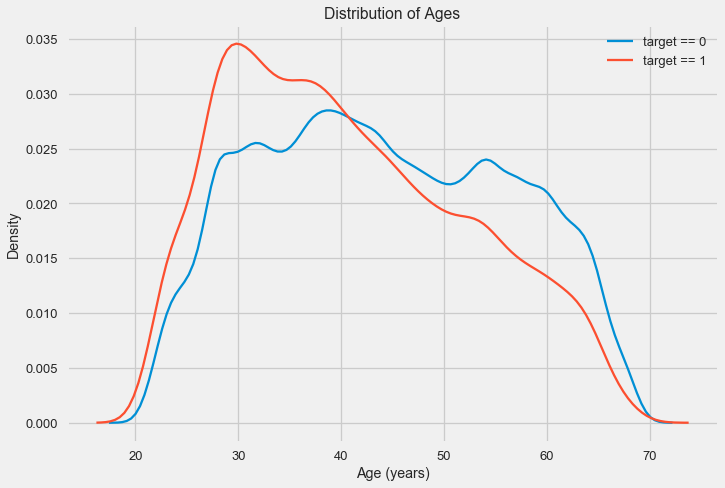
Como puede verse, la proporción de impagos es mayor para los jóvenes y disminuye a medida que aumenta la edad. Esta no es una razón para rechazar siempre el crédito a los jóvenes, tal "recomendación" solo conducirá a la pérdida de ingresos y al mercado para el banco. Esta es una ocasión para pensar en un monitoreo más exhaustivo de dichos préstamos, evaluaciones y, posiblemente, incluso algún tipo de educación financiera para jóvenes prestatarios.
Fuentes externas
Echemos un vistazo más de cerca a las "fuentes de datos externas" EXT_SOURCE y su correlación.
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']] ext_data_corrs = ext_data.corr() ext_data_corrs
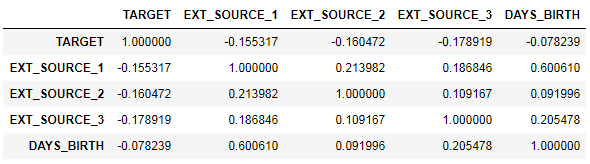
También es conveniente mostrar la correlación usando el mapa de calor
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6) plt.title('Correlation Heatmap');
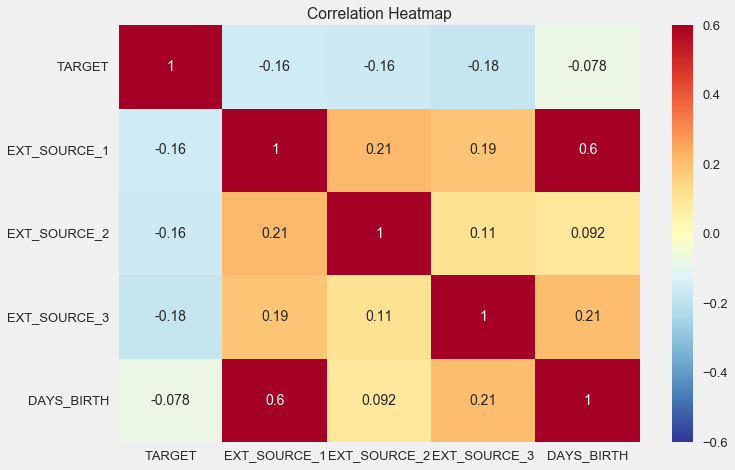
Como puede ver, todas las fuentes muestran una correlación negativa con el objetivo. Veamos la distribución de KDE para cada fuente.
plt.figure(figsize = (10, 12))
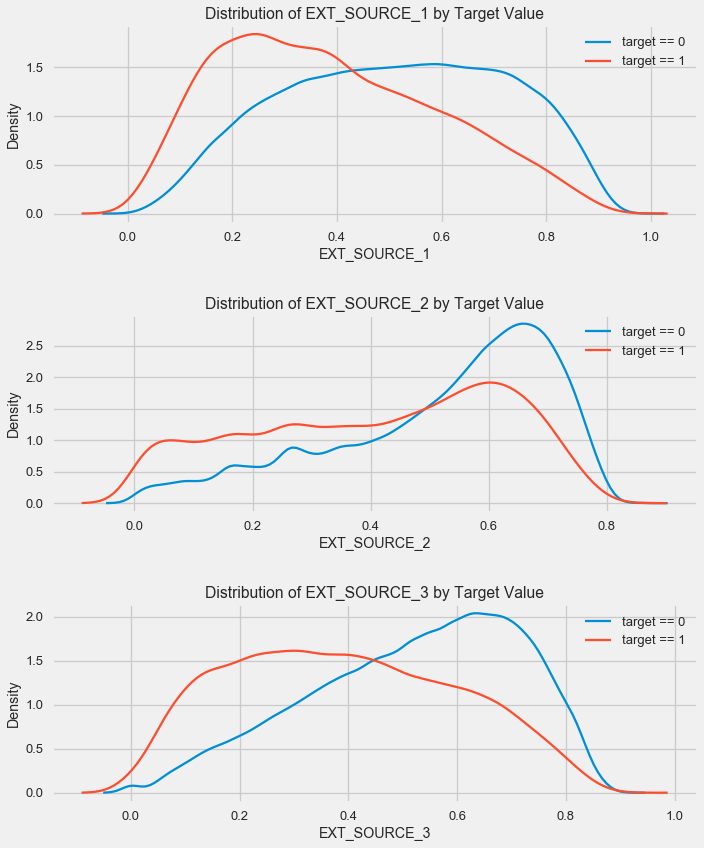
La imagen es similar a la distribución por edad: con un aumento en el indicador, aumenta la probabilidad de un préstamo. La tercera fuente es la más poderosa a este respecto. Aunque en términos absolutos la correlación con la variable objetivo todavía está en la categoría "muy baja", las fuentes de datos externas y la edad serán de la mayor importancia en la construcción del modelo.
Horario par
Para comprender mejor la relación de estas variables, puede construir un gráfico de pares, en él podemos ver la relación de cada par y un histograma de la distribución a lo largo de la diagonal. Por encima de la diagonal, puede mostrar el diagrama de dispersión, y debajo - 2d KDE.
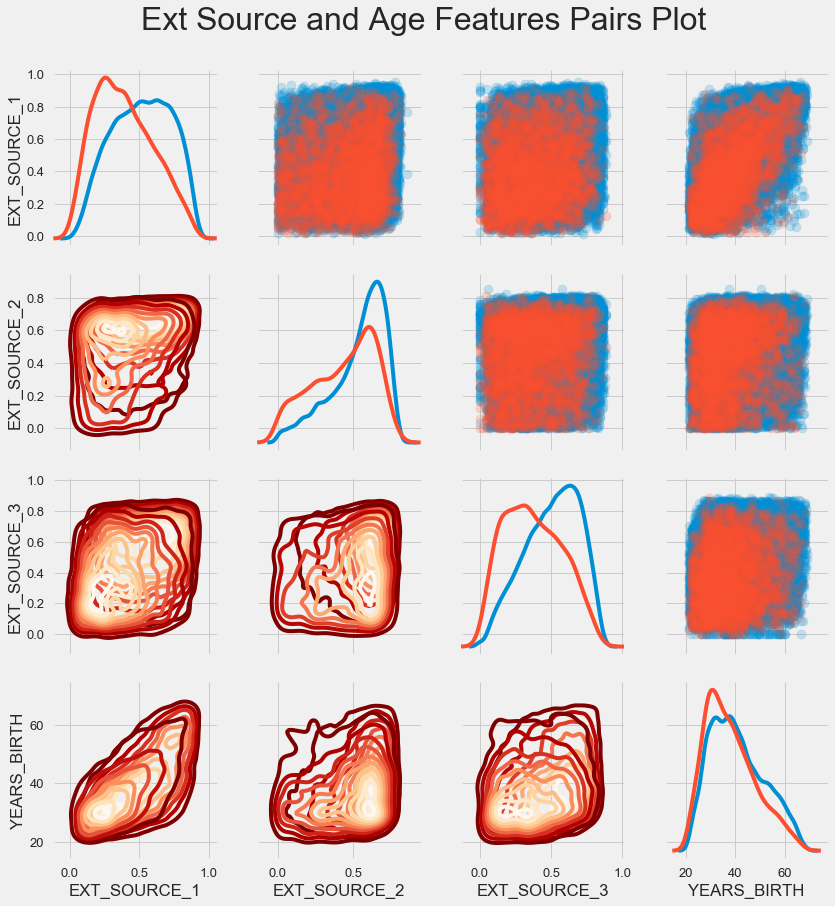
Los préstamos reembolsables se muestran en azul, no reembolsables en rojo. Interpretar todo esto es bastante difícil, pero una buena impresión en una camiseta o una imagen en un museo de arte moderno puede salir de esta imagen.
Examen de otros signos.
Consideremos con más detalle otras características y su dependencia de la variable objetivo. Como hay muchos categóricos (y ya logramos codificarlos), nuevamente necesitamos los datos iniciales. Llamemos un poco diferente para evitar confusiones
application_train = pd.read_csv(PATH+"application_train.csv") application_test = pd.read_csv(PATH+"application_test.csv")
También necesitaremos un par de funciones para mostrar bellamente las distribuciones y su influencia en la variable objetivo. Muchas gracias
a ellos por el
autor de este
núcleo. def plot_stats(feature,label_rotation=False,horizontal_layout=True): temp = application_train[feature].value_counts() df1 = pd.DataFrame({feature: temp.index,' ': temp.values})
Por lo tanto, consideraremos los principales signos de los clientes.
Tipo de préstamo
plot_stats('NAME_CONTRACT_TYPE')
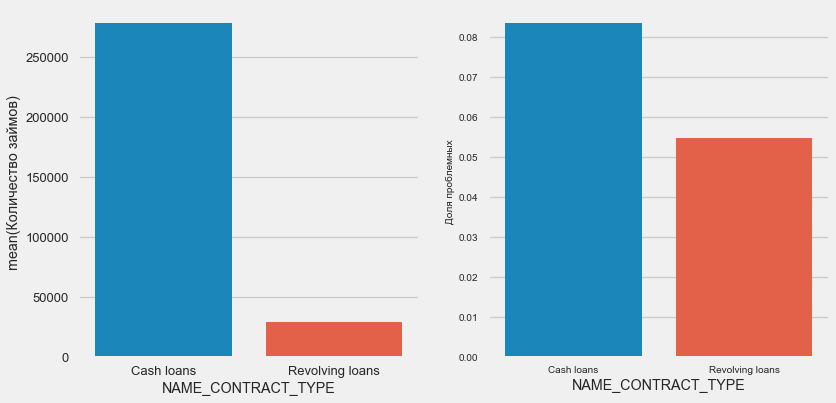
Curiosamente, los préstamos renovables (probablemente sobregiros o algo así) representan menos del 10% del número total de préstamos. Al mismo tiempo, el porcentaje de no retorno entre ellos es mucho mayor. Una buena razón para revisar la metodología de trabajo con estos préstamos, y tal vez incluso abandonarlos.
Sexo del cliente
plot_stats('CODE_GENDER')
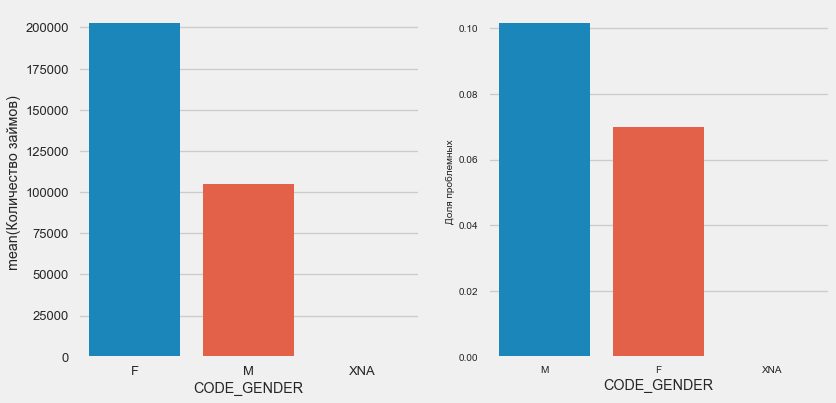
Hay casi el doble de clientes femeninas que hombres, y los hombres muestran un riesgo mucho mayor.
Propiedad de automóviles y propiedades
plot_stats('FLAG_OWN_CAR') plot_stats('FLAG_OWN_REALTY')
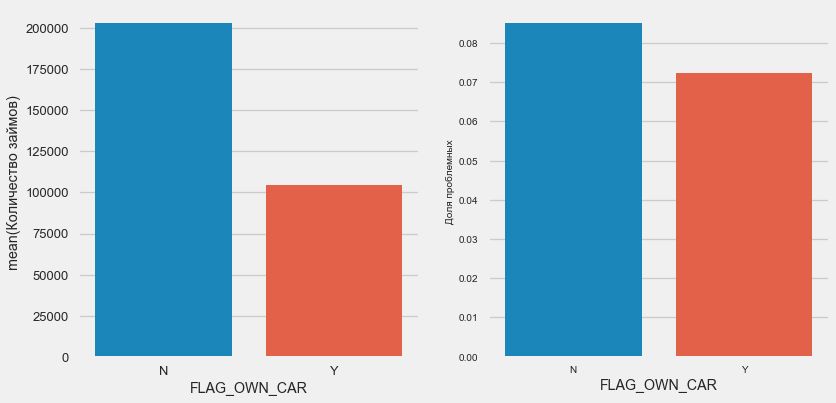
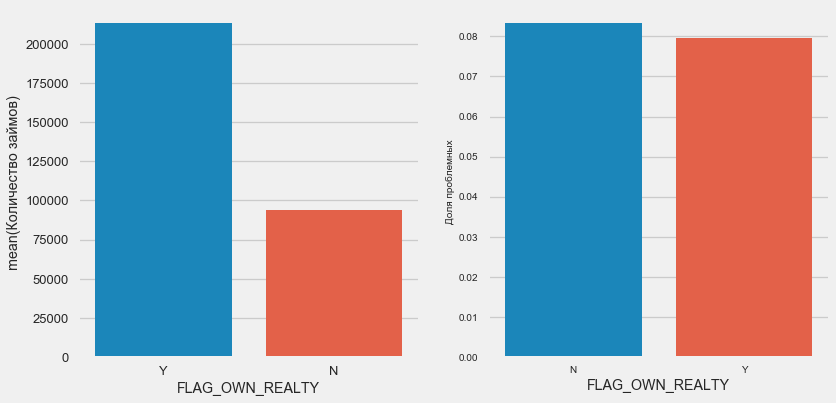
Los clientes con el automóvil son la mitad de "sin caballo". El riesgo es casi el mismo, los clientes con la máquina pagan un poco mejor.
Para el sector inmobiliario, lo contrario es cierto: hay la mitad de los clientes sin él. El riesgo para los propietarios también es ligeramente menor.
Estado civil
plot_stats('NAME_FAMILY_STATUS',True, True)
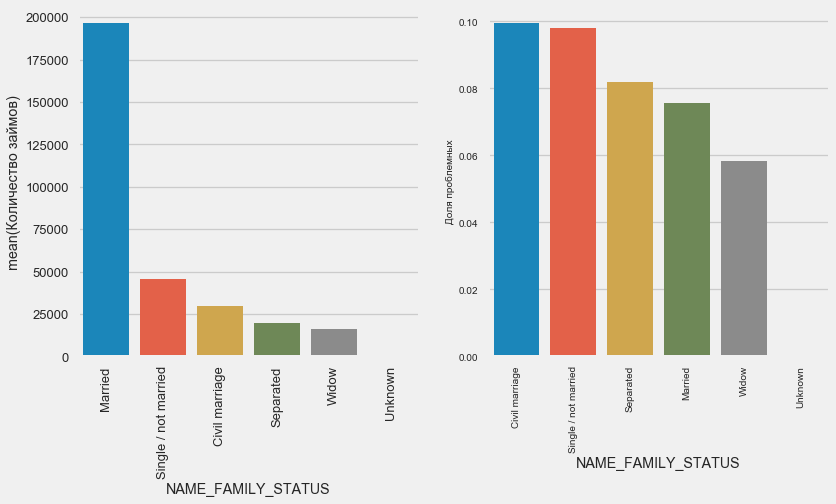
Si bien la mayoría de los clientes están casados, los más riesgosos son los clientes civiles y solteros. Los viudos muestran un riesgo mínimo.
Numero de niños
plot_stats('CNT_CHILDREN')
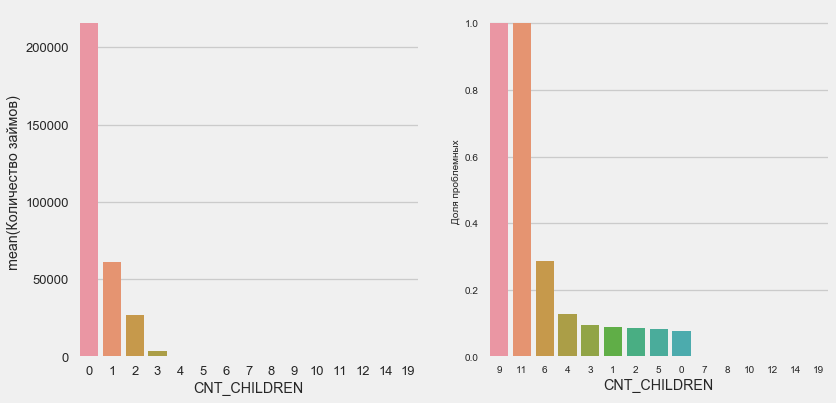
La mayoría de los clientes no tienen hijos. Al mismo tiempo, los clientes con 9 y 11 niños muestran un no reembolso completo
application_train.CNT_CHILDREN.value_counts()
0 215371
1 61119
2 26749
3 3717
4 429
5 84
6 21
7 7
14 3
19 2
12 2
10 2
9 2
8 2
11 1
Name: CNT_CHILDREN, dtype: int64Como muestra el cálculo de los valores, estos datos son estadísticamente insignificantes: solo 1-2 clientes de ambas categorías. Sin embargo, los tres entraron en incumplimiento, al igual que la mitad de los clientes con 6 hijos.
Numero de miembros de la familia
plot_stats('CNT_FAM_MEMBERS',True)
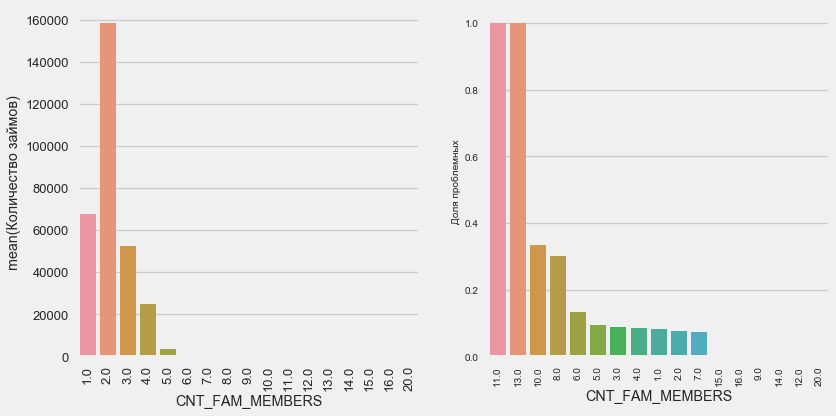
La situación es similar: cuantas menos bocas, mayor será el rendimiento.
Tipo de ingreso
plot_stats('NAME_INCOME_TYPE',False,False)
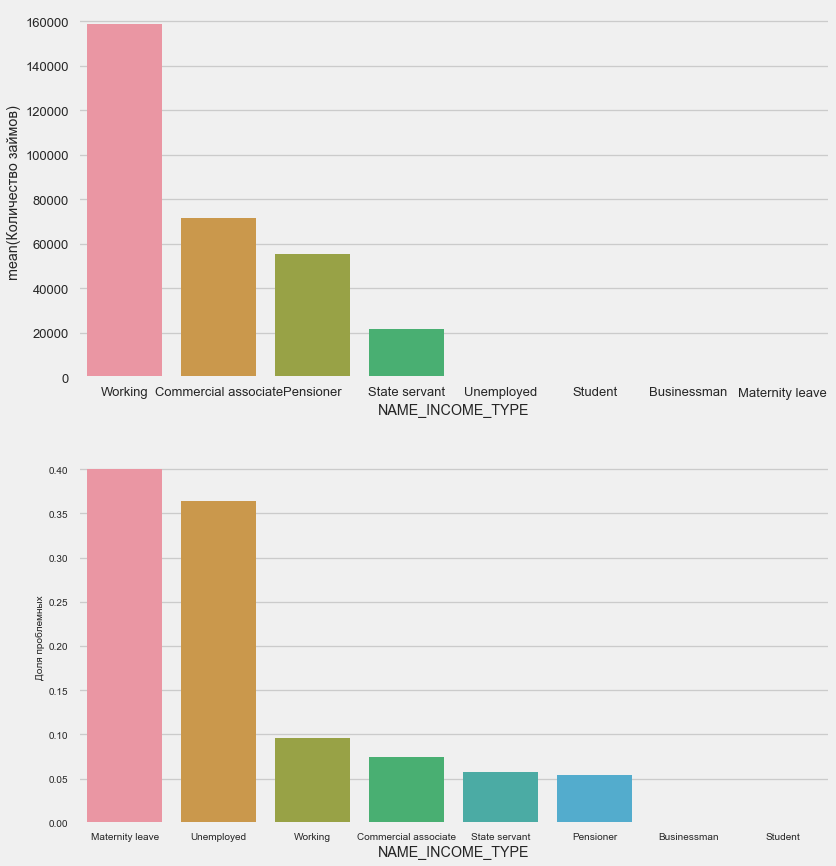
Es probable que las madres solteras y los desempleados sean interrumpidos en la etapa de solicitud; hay muy pocos de ellos en la muestra. Pero los problemas se muestran de manera estable.
Tipo de actividad
plot_stats('OCCUPATION_TYPE',True, False)
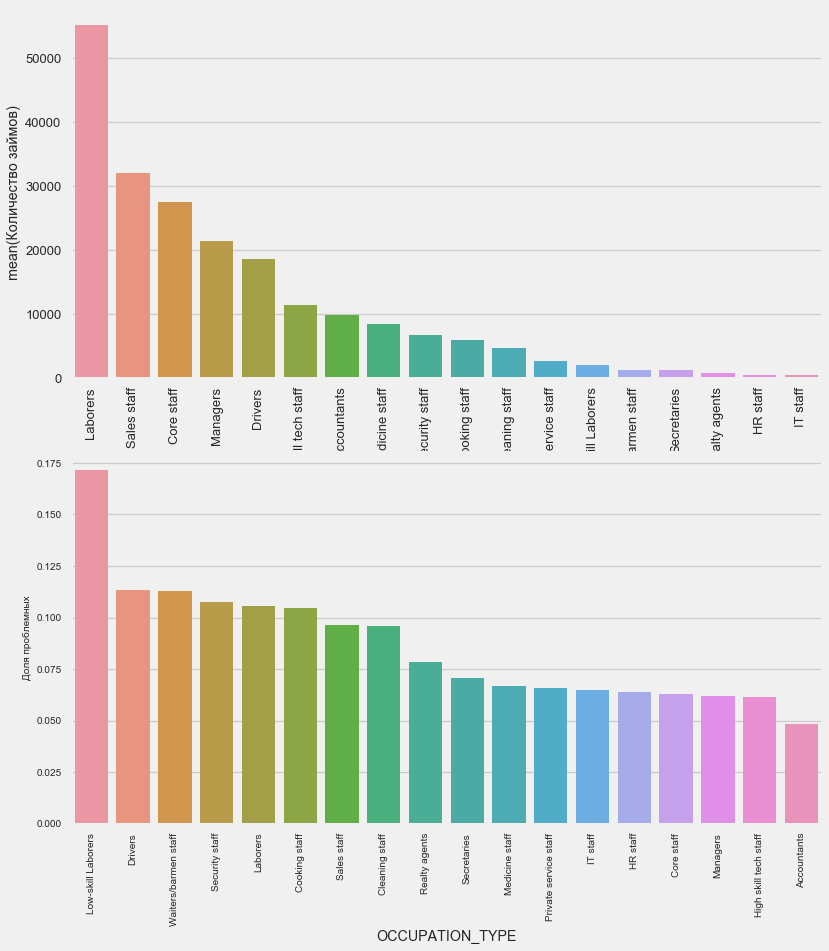
application_train.OCCUPATION_TYPE.value_counts()
Laborers 55186
Sales staff 32102
Core staff 27570
Managers 21371
Drivers 18603
High skill tech staff 11380
Accountants 9813
Medicine staff 8537
Security staff 6721
Cooking staff 5946
Cleaning staff 4653
Private service staff 2652
Low-skill Laborers 2093
Waiters/barmen staff 1348
Secretaries 1305
Realty agents 751
HR staff 563
IT staff 526
Name: OCCUPATION_TYPE, dtype: int64Es de interés para los conductores y los oficiales de seguridad que son bastante numerosos y enfrentan problemas con más frecuencia que otras categorías.
Educacion
plot_stats('NAME_EDUCATION_TYPE',True)
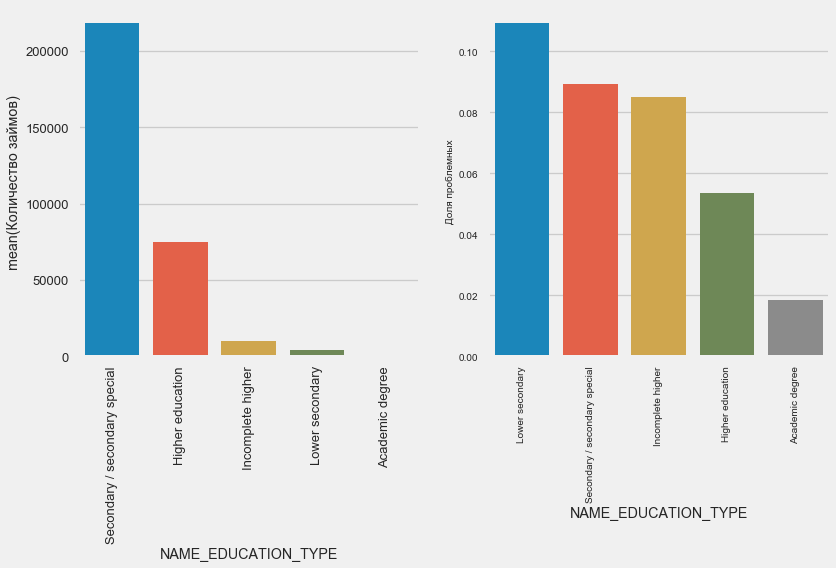
Cuanto mayor es la educación, mejor es la recurrencia, obviamente.
Tipo de organización: empleador
plot_stats('ORGANIZATION_TYPE',True, False)
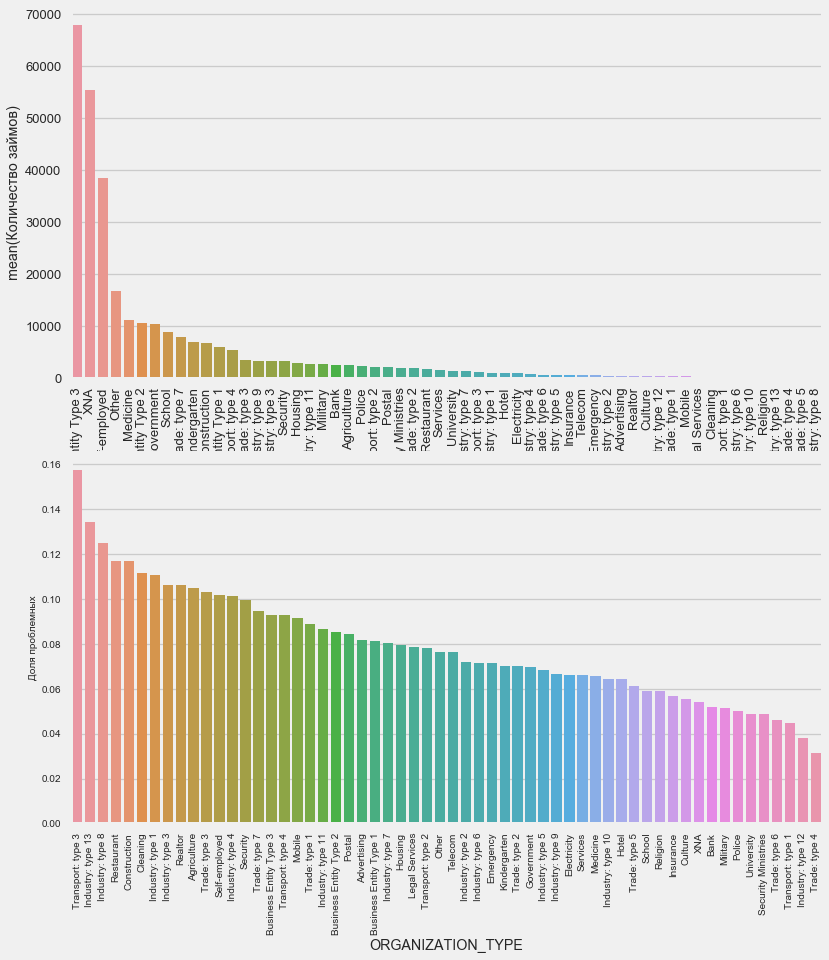
El mayor porcentaje de no retorno se observa en Transporte: tipo 3 (16%), Industria: tipo 13 (13.5%), Industria: tipo 8 (12.5%) y Restaurante (hasta 12%).
Asignación de préstamos
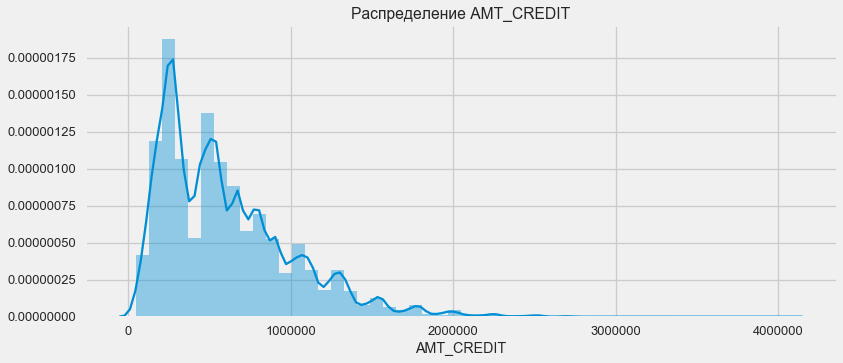
Considere la distribución de los montos de los préstamos y su impacto en el reembolso
plt.figure(figsize=(12,5)) plt.title(" AMT_CREDIT") ax = sns.distplot(app_train["AMT_CREDIT"])
plt.figure(figsize=(12,5))
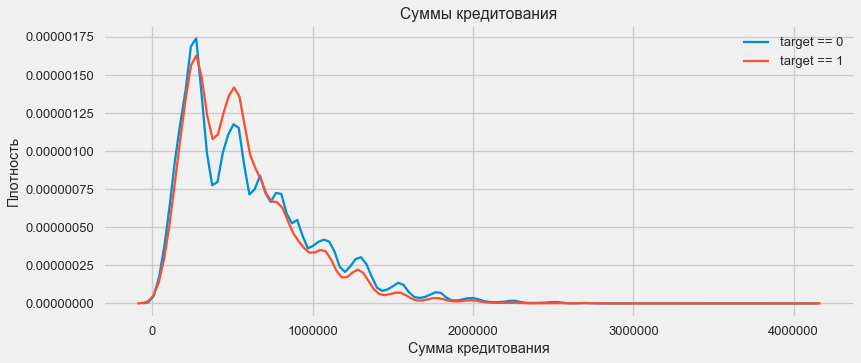
Como muestra el gráfico de densidad, las cantidades sólidas se devuelven con mayor frecuencia
Distribución de la densidad
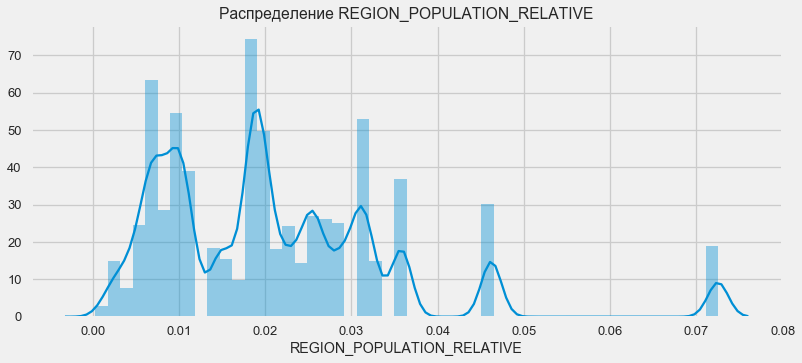
plt.figure(figsize=(12,5)) plt.title(" REGION_POPULATION_RELATIVE") ax = sns.distplot(app_train["REGION_POPULATION_RELATIVE"])
plt.figure(figsize=(12,5))
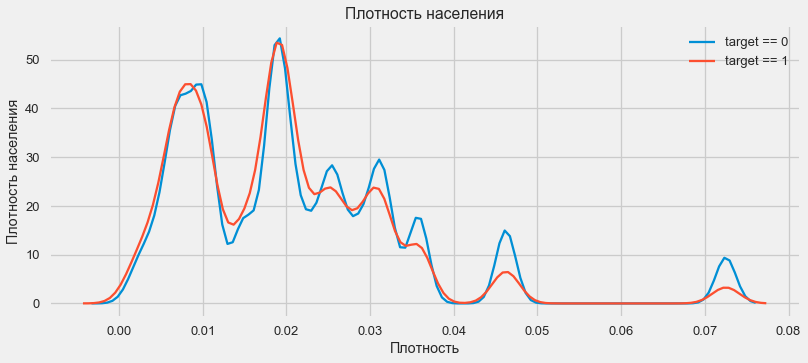
Los clientes de regiones más pobladas tienden a pagar mejor los préstamos.
Por lo tanto, tenemos una idea de las principales características del conjunto de datos y su influencia en el resultado. No haremos nada específicamente con los enumerados en este artículo, pero pueden resultar muy importantes en el trabajo futuro.
Ingeniería de características - Conversión de características
Las competiciones en Kaggle se ganan mediante la transformación de los signos: gana el que pueda crear los signos más útiles a partir de los datos. Al menos para los datos estructurados, los modelos ganadores ahora son básicamente diferentes opciones de aumento de gradiente. La mayoría de las veces, es más eficiente pasar tiempo convirtiendo atributos que configurando hiperparámetros o seleccionando modelos. Un modelo todavía puede aprender solo de los datos que se le han transferido. Asegurarse de que los datos sean relevantes para la tarea es la responsabilidad principal de la fecha del Científico.
El proceso de transformación de características puede incluir la creación de nuevos datos disponibles, la selección de los más importantes disponibles, etc. Esta vez intentaremos con signos polinómicos.
Signos polinomiales
El método polinómico de construcción de características es que simplemente creamos características que son el grado de características disponibles y sus productos. En algunos casos, tales características construidas pueden tener una correlación más fuerte con la variable objetivo que sus "padres". Aunque tales métodos se usan a menudo en modelos estadísticos, son mucho menos comunes en el aprendizaje automático. Sin embargo nada nos impide probarlos, especialmente dado que Scikit-Learn tiene una clase específicamente para estos fines, PolynomialFeatures, que crea características polinómicas y sus productos, solo necesita especificar las características originales en sí mismas y el grado máximo en el que deben elevarse. Utilizamos los efectos más potentes sobre el resultado de 4 atributos y el grado 3 para no complicar demasiado el modelo y evitar el sobreajuste (sobreentrenamiento del modelo, su ajuste excesivo a la muestra de entrenamiento).
: (307511, 35)
get_feature_names poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']Un total de 35 características polinómicas y derivadas. Verifique su correlación con el objetivo.
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64Entonces, algunos signos muestran una correlación más alta que la original. Tiene sentido intentar aprender con ellos y sin ellos (como mucho más en el aprendizaje automático, esto se puede determinar experimentalmente). Para hacer esto, cree una copia de los marcos de datos y agregue nuevas características allí.
: (307511, 277)
: (48744, 277)Entrenamiento modelo
Nivel básico
En los cálculos, debe comenzar desde un nivel básico del modelo, por debajo del cual ya no es posible caer. En nuestro caso, esto podría ser 0.5 para todos los clientes de prueba; esto muestra que no tenemos idea de si el cliente pagará el préstamo o no. En nuestro caso, ya se ha realizado un trabajo preliminar y se pueden utilizar modelos más complejos.Regresión logística
Para calcular la regresión logística, necesitamos tomar tablas con características categóricas codificadas, completar los datos faltantes y normalizarlos (llevarlos a valores de 0 a 1). Todo esto ejecuta el siguiente código: from sklearn.preprocessing import MinMaxScaler, Imputer
: (307511, 242)
: (48744, 242)Utilizamos la regresión logística de Scikit-Learn como primer modelo. Tomemos el modelo de deflación con una corrección: bajamos el parámetro de regularización C para evitar el sobreajuste. La sintaxis es normal: creamos un modelo, lo entrenamos y predecimos la probabilidad usando predict_proba (necesitamos probabilidad, no 0/1) from sklearn.linear_model import LogisticRegression
Ahora puede crear un archivo para cargar en Kaggle. Cree un marco de datos a partir de la identificación del cliente y la probabilidad de no devolución y cárguelo. submit = app_test[['SK_ID_CURR']] submit['TARGET'] = log_reg_pred submit.head()
SK_ID_CURR TARGET
0 100001 0.087954
1 100005 0.163151
2 100013 0.109923
3 100028 0.077124
4 100038 0.151694 submit.to_csv('log_reg_baseline.csv', index = False)
Entonces, el resultado de nuestro trabajo titánico: 0.673, con el mejor resultado para hoy es 0.802.Modelo mejorado - Bosque aleatorio
Logreg no se muestra muy bien, intentemos usar un modelo mejorado: un bosque aleatorio. Este es un modelo mucho más poderoso que puede construir cientos de árboles y producir un resultado mucho más preciso. Usamos 100 árboles. El esquema de trabajar con el modelo es el mismo, completamente estándar: cargar el clasificador, entrenamiento. predicción from sklearn.ensemble import RandomForestClassifier
El resultado aleatorio del bosque es ligeramente mejor - 0.683Modelo de entrenamiento con características polinómicas.
Ahora que tenemos un modelo. que hace al menos algo: es hora de probar nuestros signos polinómicos. Hagamos lo mismo con ellos y comparemos el resultado. poly_features_names = list(app_train_poly.columns)
El resultado de un bosque aleatorio con características polinómicas ha empeorado: 0.633. Lo que pone en tela de juicio la necesidad de su uso.Aumento de gradiente
El aumento de gradiente es un "modelo serio" para el aprendizaje automático. Casi todas las últimas competiciones son "arrastradas" exactamente. Vamos a construir un modelo simple y probar su rendimiento. from lightgbm import LGBMClassifier clf = LGBMClassifier() clf.fit(train, train_labels) predictions = clf.predict_proba(test)[:, 1]
El resultado de LightGBM es 0.735, lo que deja atrás a todos los demás modelos.Interpretación del modelo: importancia de los atributos
La forma más fácil de interpretar un modelo es observar la importancia de las características (que no todos los modelos pueden hacer). Como nuestro clasificador procesó la matriz, tomará algo de trabajo volver a configurar los nombres de las columnas de acuerdo con las columnas de esta matriz.
Como era de esperar, la más importante modelar todas las mismas características 4. La importancia de los atributos no es el mejor método de interpretación del modelo, pero le permite comprender los principales factores que utiliza el modelo para las predicciones.feature importance
28 EXT_SOURCE_1 310
30 EXT_SOURCE_3 282
29 EXT_SOURCE_2 271
7 DAYS_BIRTH 192
3 AMT_CREDIT 161
4 AMT_ANNUITY 142
5 AMT_GOODS_PRICE 129
8 DAYS_EMPLOYED 127
10 DAYS_ID_PUBLISH 102
9 DAYS_REGISTRATION 69
0.01 = 158
Agregar datos de otras tablas
Ahora consideraremos cuidadosamente tablas adicionales y qué se puede hacer con ellas. Inmediatamente comience a preparar mesas para más capacitación. Pero primero, elimine las tablas voluminosas pasadas de la memoria, borre la memoria utilizando el recolector de basura e importe las bibliotecas necesarias para un análisis posterior. import gc
Importar datos, eliminar inmediatamente la columna de destino en una columna separada data = pd.read_csv('../input/application_train.csv') test = pd.read_csv('../input/application_test.csv') prev = pd.read_csv('../input/previous_application.csv') buro = pd.read_csv('../input/bureau.csv') buro_balance = pd.read_csv('../input/bureau_balance.csv') credit_card = pd.read_csv('../input/credit_card_balance.csv') POS_CASH = pd.read_csv('../input/POS_CASH_balance.csv') payments = pd.read_csv('../input/installments_payments.csv')
Codifique inmediatamente características categóricas. Ya hicimos esto antes, codificamos las muestras de entrenamiento y prueba por separado, y luego alineamos los datos. Intentemos un enfoque ligeramente diferente: encontraremos todos estos signos categóricos, combinaremos los marcos de datos, codificaremos de la lista de los encontrados y luego dividiremos nuevamente las muestras en entrenamiento y pruebas. categorical_features = [col for col in data.columns if data[col].dtype == 'object'] one_hot_df = pd.concat([data,test]) one_hot_df = pd.get_dummies(one_hot_df, columns=categorical_features) data = one_hot_df.iloc[:data.shape[0],:] test = one_hot_df.iloc[data.shape[0]:,] print (' ', data.shape) print (' ', test.shape)
(307511, 245)
(48744, 245)Datos de la agencia de crédito sobre el saldo mensual del préstamo.
buro_balance.head()
 MONTHS_BALANCE: el número de meses antes de la fecha de solicitud de un préstamo. Eche un vistazo más de cerca a los "estados"
MONTHS_BALANCE: el número de meses antes de la fecha de solicitud de un préstamo. Eche un vistazo más de cerca a los "estados" buro_balance.STATUS.value_counts()
C 13646993
0 7499507
X 5810482
1 242347
5 62406
2 23419
3 8924
4 5847
Name: STATUS, dtype: int64Los estados significan lo siguiente:- cerrado, es decir, préstamo pagado. X es un estado desconocido. 0 - préstamo actual, sin morosidad. 1 - retraso de 1 a 30 días, 2 - retraso de 31 a 60 días, y así sucesivamente hasta el estado 5 - el préstamo se vende a un tercero o se cancela.Aquí, por ejemplo, se pueden distinguir los siguientes signos: buro_grouped_size - el número de entradas en la base de datos buro_grouped_max - el saldo máximo del préstamo buro_grouped_min - el saldo mínimo del préstamoY todos estos estados de préstamo pueden codificarse (utilizamos el método de desapilar, y luego adjuntamos los datos recibidos a la tabla buro, ya que SK_ID_BUREAU es lo mismo aquí y allá. buro_grouped_size = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].size() buro_grouped_max = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].max() buro_grouped_min = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].min() buro_counts = buro_balance.groupby('SK_ID_BUREAU')['STATUS'].value_counts(normalize = False) buro_counts_unstacked = buro_counts.unstack('STATUS') buro_counts_unstacked.columns = ['STATUS_0', 'STATUS_1','STATUS_2','STATUS_3','STATUS_4','STATUS_5','STATUS_C','STATUS_X',] buro_counts_unstacked['MONTHS_COUNT'] = buro_grouped_size buro_counts_unstacked['MONTHS_MIN'] = buro_grouped_min buro_counts_unstacked['MONTHS_MAX'] = buro_grouped_max buro = buro.join(buro_counts_unstacked, how='left', on='SK_ID_BUREAU') del buro_balance gc.collect()
Información general sobre oficinas de crédito.
buro.head()
 (se muestran las primeras 7 columnas) Haybastantes datos que, en general, puede intentar codificar simplemente con One-Hot-Encoding, agrupar por SK_ID_CURR, promedio y, de la misma manera, prepararse para unirse a la tabla principal
(se muestran las primeras 7 columnas) Haybastantes datos que, en general, puede intentar codificar simplemente con One-Hot-Encoding, agrupar por SK_ID_CURR, promedio y, de la misma manera, prepararse para unirse a la tabla principal buro_cat_features = [bcol for bcol in buro.columns if buro[bcol].dtype == 'object'] buro = pd.get_dummies(buro, columns=buro_cat_features) avg_buro = buro.groupby('SK_ID_CURR').mean() avg_buro['buro_count'] = buro[['SK_ID_BUREAU', 'SK_ID_CURR']].groupby('SK_ID_CURR').count()['SK_ID_BUREAU'] del avg_buro['SK_ID_BUREAU'] del buro gc.collect()
Datos sobre solicitudes anteriores
prev.head()
 Del mismo modo, codificamos características categóricas, promediamos y combinamos sobre la ID actual.
Del mismo modo, codificamos características categóricas, promediamos y combinamos sobre la ID actual. prev_cat_features = [pcol for pcol in prev.columns if prev[pcol].dtype == 'object'] prev = pd.get_dummies(prev, columns=prev_cat_features) avg_prev = prev.groupby('SK_ID_CURR').mean() cnt_prev = prev[['SK_ID_CURR', 'SK_ID_PREV']].groupby('SK_ID_CURR').count() avg_prev['nb_app'] = cnt_prev['SK_ID_PREV'] del avg_prev['SK_ID_PREV'] del prev gc.collect()
Saldo de tarjeta de crédito
POS_CASH.head()

POS_CASH.NAME_CONTRACT_STATUS.value_counts()
Active 9151119
Completed 744883
Signed 87260
Demand 7065
Returned to the store 5461
Approved 4917
Amortized debt 636
Canceled 15
XNA 2
Name: NAME_CONTRACT_STATUS, dtype: int64Codificamos características categóricas y preparamos una tabla para combinar le = LabelEncoder() POS_CASH['NAME_CONTRACT_STATUS'] = le.fit_transform(POS_CASH['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() POS_CASH['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] POS_CASH['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] POS_CASH.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Datos de la tarjeta
credit_card.head()
 (primeras 7 columnas)Trabajo similar
(primeras 7 columnas)Trabajo similar credit_card['NAME_CONTRACT_STATUS'] = le.fit_transform(credit_card['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() credit_card['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] credit_card['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] credit_card.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Datos de pago
payments.head()
 (se muestran las primeras 7 columnas)Creemos tres tablas, con valores promedio, mínimo y máximo de esta tabla.
(se muestran las primeras 7 columnas)Creemos tres tablas, con valores promedio, mínimo y máximo de esta tabla. avg_payments = payments.groupby('SK_ID_CURR').mean() avg_payments2 = payments.groupby('SK_ID_CURR').max() avg_payments3 = payments.groupby('SK_ID_CURR').min() del avg_payments['SK_ID_PREV'] del payments gc.collect()
Tabla de unión
data = data.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') del avg_prev, avg_buro, POS_CASH, credit_card, avg_payments, avg_payments2, avg_payments3 gc.collect() print (' ', data.shape) print (' ', test.shape) print (' ', y.shape)
(307511, 504)
(48744, 504)
(307511,)¡Y, en realidad, golpearemos esta tabla duplicada con un aumento de gradiente! from lightgbm import LGBMClassifier clf2 = LGBMClassifier() clf2.fit(data, y) predictions = clf2.predict_proba(test)[:, 1]
El resultado es 0.770.OK, finalmente, intentemos una técnica más compleja con plegado en pliegues, validación cruzada y elección de la mejor iteración. folds = KFold(n_splits=5, shuffle=True, random_state=546789) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) feature_importance_df = pd.DataFrame() feats = [f for f in data.columns if f not in ['SK_ID_CURR']] for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[feats].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[feats].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier( n_estimators=10000, learning_rate=0.03, num_leaves=34, colsample_bytree=0.9, subsample=0.8, max_depth=8, reg_alpha=.1, reg_lambda=.1, min_split_gain=.01, min_child_weight=375, silent=-1, verbose=-1, ) clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=100, early_stopping_rounds=100
Full AUC score 0.785845Scor final en kaggle 0.783A donde ir ahora
Definitivamente continuar trabajando con signos. Explore los datos, seleccione algunos de los signos, combínelos, adjunte tablas adicionales de una manera diferente. Puede experimentar con hiperparámetros Mogheli, muchas direcciones.Espero que esta pequeña compilación le haya mostrado métodos modernos de investigación de datos y preparación de modelos predictivos. ¡Aprenda datasaens, participe en concursos, sea genial!Y nuevamente enlaces a los núcleos que me ayudaron a preparar este artículo. El artículo también se publica en forma de computadora portátil en Github , puede descargarlo, conjunto de datos y ejecutar y experimentar.Will Koehrsen. Comience aquí: una introducción suavesban. HomeCreditRisk: Amplia línea de base EDA + [0.772]Gabriel Preda. Home Credit Default Risk Extensive EDAPavan Raj. Loan repayers v/s Loan defaulters — HOME CREDITLem Lordje Ko. 15 lines: Just EXT_SOURCE_xShanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERINGDmitriy Kisil. Good_fun_with_LigthGBM