El preprocesamiento es un término general para todas las manipulaciones realizadas con datos antes de transferir su modelo, incluido el centrado, la normalización, el desplazamiento, la rotación, el recorte, etc. Como regla general, se requiere preprocesamiento en dos casos.
- Limpieza de datos . Suponga que algunos artefactos están presentes en las imágenes. Para facilitar el entrenamiento del modelo, los artefactos deben eliminarse en la etapa de preprocesamiento.
- Adición de datos . A veces, los conjuntos de datos pequeños no son suficientes para la formación de modelos profundos de alta calidad. Un enfoque de suplemento de datos es muy útil para resolver este problema. Este es el proceso de transformar cada muestra de datos de varias maneras y agregar tales muestras modificadas al conjunto de datos. De esta forma, se puede aumentar el tamaño efectivo del conjunto de datos.
Consideremos algunos posibles métodos de transformación durante el preprocesamiento y su implementación a través de Keras.

Datos
En este y en los artículos siguientes, se utilizará un conjunto de datos para analizar el color emocional de las imágenes. Contiene 1.500 ejemplos de imágenes, divididas en dos clases: positiva y negativa. Veamos algunos ejemplos.
 Ejemplos negativos
Ejemplos negativos Ejemplos positivos
Ejemplos positivosTransformaciones de limpieza
Ahora considere un conjunto de posibles transformaciones comúnmente utilizadas para limpiar datos, su implementación e impacto en las imágenes.
Todos los fragmentos de código se pueden encontrar en el libro
Preprocessing.ipynb .
Reescalado
Las imágenes generalmente se almacenan en formato RGB (Rojo Verde Azul). En este formato, la imagen está representada por una matriz tridimensional (o de tres canales).
 Descomposición RGB de la imagen. Gráfico tomado de Wikiwand
Descomposición RGB de la imagen. Gráfico tomado de WikiwandUna dimensión se usa para canales (rojo, verde y azul), las otras dos representan la ubicación. Por lo tanto, cada píxel se codifica con tres números. Cada número generalmente se almacena como un tipo entero sin signo de 8 bits (0 a 255).
El cambio de escala es una operación que cambia el rango numérico de datos simplemente dividiéndolo por una constante predeterminada. En redes neuronales profundas, puede ser necesario limitar los datos de entrada a un rango de 0 a 1 debido a un posible desbordamiento, problemas de optimización, estabilidad, etc.
Por ejemplo, volvemos a escalar nuestros datos del rango [0; 255] al rango [0; 1] En lo sucesivo, utilizaremos la clase Keras
ImageDataGenerator , que le permite realizar todas las transformaciones sobre la marcha.
Creemos dos instancias de esta clase: una para los datos transformados y la otra para la fuente:

(o para datos predeterminados). Solo es necesario especificar la constante de escala. Además, la clase
ImageDataGenerator le permite transmitir datos directamente desde una carpeta en su disco duro utilizando el método
flow_from_directory .
Todos los parámetros se pueden encontrar en la
documentación , pero los parámetros principales son: la ruta a la secuencia y el tamaño de la imagen objetivo (si la imagen no coincide con el tamaño objetivo, el generador simplemente la corta o la construye). Finalmente, obtenemos una muestra del generador y consideramos los resultados.
Visualmente, ambas imágenes son idénticas, pero la razón de esto es porque las herramientas Python * cambian el tamaño de las imágenes automáticamente
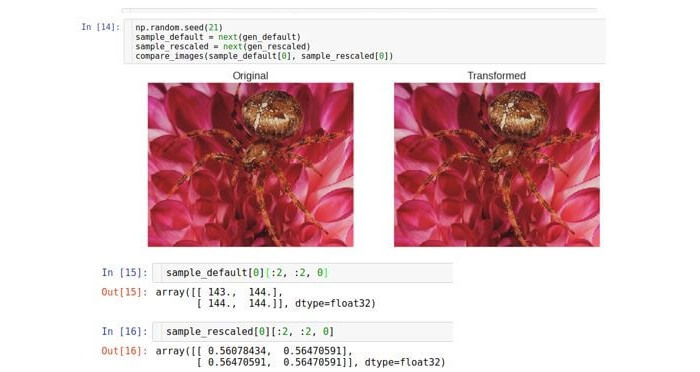
al rango predeterminado para que puedan mostrarse en la pantalla. Considere los datos sin procesar (matrices). Como puede ver, los macizos sin procesar difieren exactamente 255 veces.
Escala de grises
Otro tipo de transformación que puede ser útil es la
escala de grises , que convierte una imagen RGB de color en una imagen en la que todos los colores se representan en tonos de gris. El procesamiento de imágenes convencional puede usar la traducción en escala de grises en combinación con un umbral posterior. Este par de transformaciones puede rechazar píxeles ruidosos y definir formas en la imagen. Hoy, todas estas operaciones son realizadas por la red neuronal convolucional (CNN), pero la conversión en escala de grises como un paso de preprocesamiento puede ser útil. Ejecute este paso en Keras con la misma clase de generador.
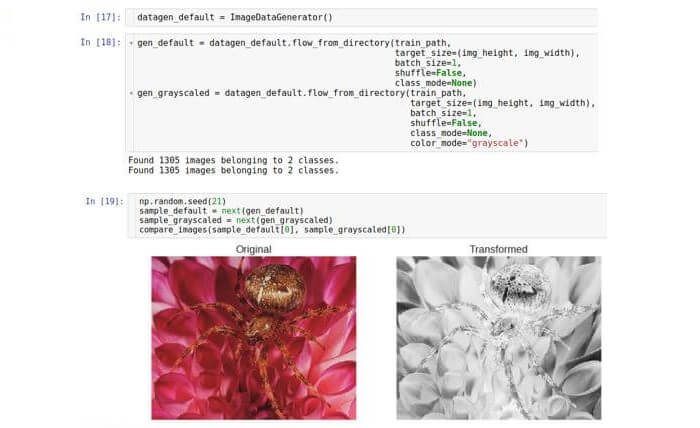
Aquí creamos solo una instancia de la clase y tomamos dos generadores diferentes. El segundo generador establece el parámetro
color_mode en "escala de grises" (el valor predeterminado es "RGB").
Muestras de centrado
Ya hemos visto que los valores de los datos sin procesar están en el rango de 0 a 255. Por lo tanto, una muestra es una matriz tridimensional de números de 0 a 255. A la luz de los principios de estabilidad de optimización (deshacerse del problema de la desaparición o saturación de valores),
puede ser necesario normalizar el conjunto de datos para que el promedio de cada muestra de datos sea 0 .
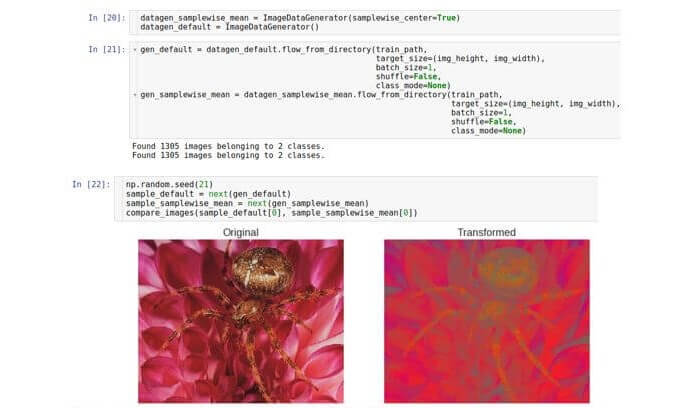
Para esto, es necesario calcular el valor promedio sobre toda la muestra y restarlo de cada número en la muestra dada.
En Keras, esto se hace usando el parámetro
samplewise_center .
Normalización de la desviación estándar de las muestras.
Esta etapa de preprocesamiento se basa en la misma idea que el centrado de las muestras, pero en lugar de establecer el promedio en 0 desde, establece la desviación estándar en 1.

La normalización de la desviación
estándar se controla mediante el parámetro
samplewise_std_normalization . Cabe señalar que estos dos métodos de normalización de muestras a menudo se usan juntos.
Esta transformación se puede utilizar en modelos de aprendizaje profundo para mejorar la estabilidad de la optimización al reducir el impacto de los gradientes explosivos.
Centrado de funciones
Las dos secciones anteriores utilizaron una técnica de normalización que analizó cada muestra individual de datos. Existe un enfoque alternativo para el procedimiento de normalización. Considere cada número en la matriz de imágenes como un signo. Entonces
cada imagen es un vector de características . Hay muchos de esos vectores en el conjunto de datos; por lo tanto, podemos considerarlos como una
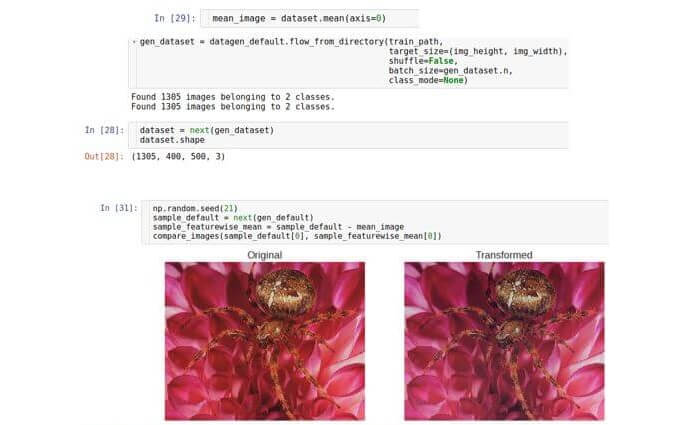
distribución desconocida. Esta distribución es multiparamétrica, y su dimensión será igual al número de características, es decir, ancho × alto × 3. Aunque se desconoce la distribución real de los datos, puede intentar normalizarla restando la distribución promedio. Cabe señalar que el valor promedio es un vector de la misma dimensión, es decir, también es una imagen. En otras palabras, promediamos sobre todo el conjunto de datos, y no sobre una muestra.
Hay un parámetro especial de Keras llamado
featurewise_centering , pero, desafortunadamente, a partir de agosto de 2017, hubo un error en su implementación; por lo tanto, lo implementamos nosotros mismos. Primero, consideramos todo el conjunto de datos en la memoria (podemos pagarlo, ya que estamos tratando con un pequeño conjunto de datos). Lo hicimos configurando el tamaño del paquete al tamaño del conjunto de datos. Luego calculamos la imagen promedio sobre todo el conjunto de datos y finalmente la restamos de la imagen de prueba.
Normalización de la desviación estándar de los síntomas.
La idea de normalizar la desviación estándar es exactamente la misma que la idea de centrar. La única diferencia es que en lugar de restar el promedio, dividimos por la desviación estándar. Visualmente, el resultado no es muy diferente. Sucedió lo mismo

durante el cambio de escala, dado que la normalización de la desviación estándar no es más que un cambio de escala con una constante calculada de cierta manera, y con un cambio de escala simple, la constante se especifica manualmente. Tenga en cuenta que una idea similar de normalizar los paquetes de datos es el núcleo de una técnica moderna de aprendizaje profundo llamada
BatchNormalization .
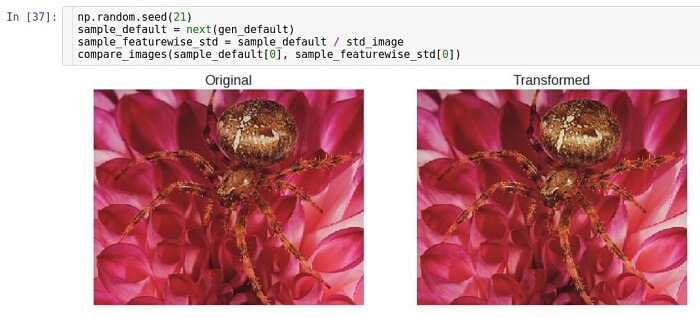
Transformación con la adición.
En esta sección, observamos varias transformaciones dependientes de datos que usan explícitamente la naturaleza gráfica de los datos. Estos tipos de transformaciones a menudo se usan en procedimientos de adición de datos.
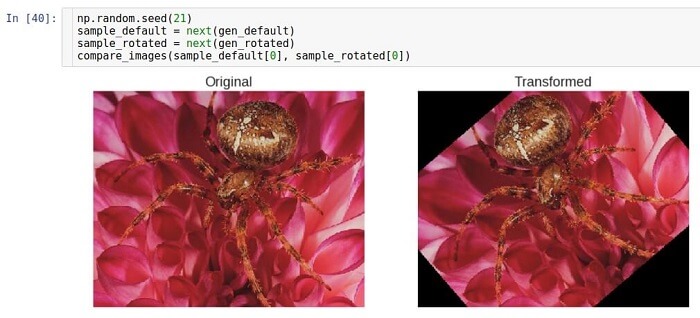
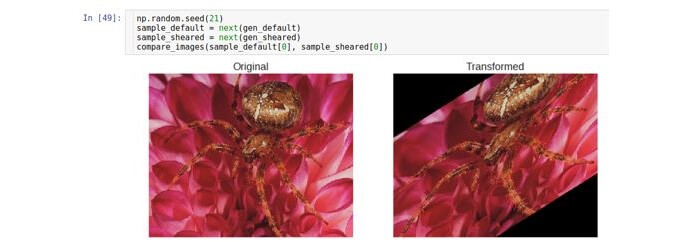
Rotación
Este tipo de transformación gira la imagen en cierta dirección (en sentido horario o antihorario).
El parámetro que permite la rotación se llama
rotación_rango . Indica el rango en grados desde el cual el ángulo de rotación se selecciona aleatoriamente con una distribución uniforme. Cabe señalar que durante la rotación, el tamaño de la imagen no cambia. Por lo tanto, algunas partes de la imagen pueden recortarse y otras llenarse.
El modo de relleno se establece utilizando el parámetro
fill_mode . Es compatible con varios métodos de relleno, pero aquí usamos el método
constante como ejemplo.
Desplazamiento horizontal
Este tipo de transformación desplaza la imagen en una determinada dirección a lo largo del eje horizontal (izquierda o derecha).

El tamaño del cambio se puede determinar utilizando el parámetro
width_shift_range y se puede medir como parte del ancho total de la imagen.
Desplazamiento vertical
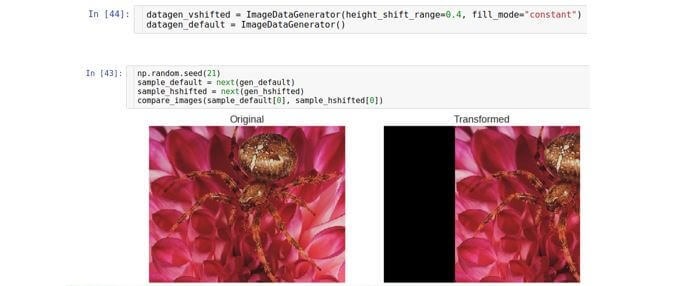
Desplaza la imagen a lo largo del eje vertical (arriba o abajo). El parámetro que controla el rango de desplazamiento se denomina generador de cambio de
altura y también se mide como parte de la altura total de la imagen.
Poda
Una conversión de recorte o recorte desplaza cada punto en la dirección vertical en una cantidad proporcional a la distancia desde ese punto hasta el borde de la imagen. Tenga en cuenta que en el caso general, la dirección no tiene que ser vertical y es arbitraria.
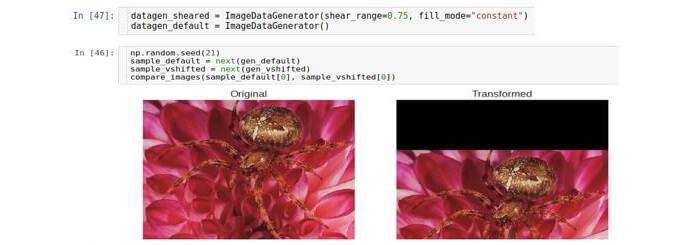
El parámetro que controla el desplazamiento se llama
shear_range y corresponde al ángulo de desviación (en radianes) entre la línea horizontal en la imagen original y la imagen (en el sentido matemático) de esta línea en la imagen transformada.
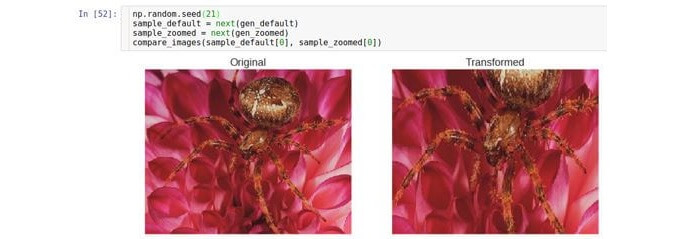
Acercar / Alejar

Este tipo de transformación se aproxima o elimina la imagen original. El parámetro
zoom_range controla el factor de zoom.
Por ejemplo, si
zoom_range es 0.5, entonces el factor de zoom se seleccionará del rango [0.5, 1.5].
Volteo horizontal

Voltea la imagen en relación con el eje vertical. Se puede activar o desactivar utilizando el parámetro
horizontal_flip .
Volteo vertical

Voltea la imagen alrededor del eje horizontal. El parámetro
vertical_flip (de tipo booleano) controla la presencia o ausencia de esta transformación.
Combinación
Aplicamos todos los tipos descritos de transformaciones del complemento al mismo tiempo y vemos qué sucede. Recuerde que los parámetros para todas las transformaciones se seleccionan aleatoriamente de un cierto rango; por lo tanto, debemos obtener un conjunto de muestras con un grado significativo de diversidad.
Iniciamos
ImageDataGenerator con todos los parámetros disponibles y verificamos el hidrante rojo en la imagen.

Tenga en cuenta que el modo de relleno
constante se usó solo para una mejor visualización. Ahora usaremos un modo de relleno más avanzado llamado
más cercano ; Este modo asigna el color del píxel existente más cercano al píxel vacío.
Conclusión
Este artículo proporciona una descripción general de las técnicas básicas para el preprocesamiento de imágenes, tales como: escala, normalización, rotación, desplazamiento y recorte. También demostraron la implementación de estas técnicas de transformación utilizando Keras y su introducción en el proceso de aprendizaje profundo tanto técnica (clase
ImageDataGenerator ) como ideológicamente (suplemento de datos).