Continuamos compartiendo nuestra experiencia en la organización del almacén de datos, del que comenzamos a hablar en una publicación anterior . Esta vez queremos hablar sobre cómo resolvimos las tareas de instalación de CDH.

Instalación de CDH
Iniciamos el servidor de Cloudera Manager, lo agregamos a la carga automática y verificamos que haya cambiado al estado activo:
systemctl start cloudera-scm-server systemctl enable cloudera-scm-server systemctl status cloudera-scm-server
Una vez que ha aumentado, seguimos el enlace "nombre de host: 7180 /", iniciamos sesión (admin / admin) y continuamos la instalación desde la GUI. Después de la autorización, la instalación comenzará automáticamente y se realizará una transición a la página para agregar hosts al clúster:

Se recomienda agregar todos los hosts que de alguna manera estarán conectados con el entorno implementado (incluso si no alojarán los servicios de Cloudera). Pueden ser máquinas con herramientas de integración continua, herramientas de BI o ETL o herramientas de descubrimiento de datos. La inclusión de estas máquinas en el clúster le permitirá instalar las puertas de enlace de los servicios del clúster (Gateways) que contienen archivos con la configuración y ubicación de los servicios del clúster, lo que simplificará la integración con programas de terceros. Cloudera Manager también proporciona herramientas de monitoreo convenientes y la creación de monitores de métricas clave para todas las máquinas de clúster en una sola ventana, lo que simplificará la localización de problemas durante la operación. Los hosts se agregan mediante el botón "Nueva búsqueda": se realiza una transición a la página para agregar máquinas al clúster, donde se propone proporcionarles datos para conectarse a través de SSH:

Después de agregar los hosts, pasamos a la etapa de elegir el método de instalación. Desde que descargamos los perejiles, seleccionamos el método "Usar paquetes (recomendado)", y ahora necesitamos agregar nuestro repositorio. Hacemos clic en el botón "Más opciones", eliminamos todos los repositorios predeterminados instalados allí y agregamos la dirección del repositorio con el parámetro CDH - "nombre de host / parcels / cdh /". Después de la confirmación, a la derecha de la inscripción "Seleccione la versión de CDH", se debe mostrar la versión de CDH presentada en el documento descargado. Para este método de instalación, no se puede configurar nada en esta pestaña:

La siguiente pestaña le pedirá que instale el JDK. Como ya hicimos esto en preparación para la instalación, omitimos este paso:

Cuando vaya a la siguiente pestaña, comienza la instalación de los componentes del clúster en los hosts especificados. Una vez completada la instalación, la transición al siguiente paso estará disponible. Si durante la instalación se encuentran errores (me encontré con esta situación al instalar entornos de desarrollo locales), puede ver sus detalles con el comando "tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log" y haciendo clic en el botón Detalles en el lado derecho de la tabla:

En el siguiente paso de instalación, se le pedirá que seleccione uno de los conjuntos de servicios preparados para la instalación. En el futuro, los servicios y sus roles se pueden configurar manualmente, por lo que no es muy importante qué elegir en esta pestaña. En nuestro caso, usualmente se instaló "Core with Impala". También aquí puede indicar la necesidad de instalar Cloudera Navigator. Si está instalando la versión Enterprise, debe instalar esta útil herramienta:

En la siguiente pestaña para servicios del conjunto seleccionado, se propone seleccionar los roles y hosts en los que se instalarán. A continuación se presentan algunas pautas para instalar roles en los hosts.
Roles HDFS
NameNode : se coloca en una sola copia en uno de los nodos maestros, preferiblemente el más descargado, ya que es muy importante para el funcionamiento del clúster y contribuye significativamente a la utilización de los recursos.
SecondaryNameNode : se coloca en una única copia en uno de los nodos maestros, preferiblemente no en el mismo nodo que NameNode (para garantizar la tolerancia a fallos).
Equilibrador : se coloca en una sola copia en uno de los nodos maestros.
HttpFS : una API adicional para HDFS, no puede instalarla.
NFS Gateway : una función muy útil que le permite montar HDFS como una unidad de red. Se coloca en una sola copia en uno de los nodos maestros.
DataNode : poner en todos los nodos de datos.
Roles de la colmena
Gateway : archivos de configuración de Hive. Se coloca en todos los hosts del clúster.
Hive Metastore Server : un servidor de metadatos, se instala en una sola copia en uno de los Nodos Maestros (por ejemplo, en el que está instalado PostgreSQL, almacena sus datos allí).
WebHCat : no es necesario instalarlo.
HiveServer2 : se
instala en una única copia en el mismo nodo maestro que el servidor Hive Metastore (un requisito para su trabajo conjunto).
Roles de Hue
Hue Server : la GUI para HDFS se instala en una sola copia en uno de los nodos maestros.
Load Balancer : un equilibrador de carga en la GUI para HDFS se instala en una sola copia en uno de los nodos maestros.
Roles de Impala
Impala StateStore : se coloca en una sola copia en uno de los nodos maestros.
Impala Catalog Server : se coloca en una única copia en uno de los nodos maestros.
Impala Daemon : pon todos los nodos de datos (puedes dejar el valor predeterminado).
Roles de servicios de Cloudera Manager
Service Monitor, Activity Monitor, Host Monitor, Reports Manager, Event Server, Alert Publisher se instalan en una sola copia en uno de los nodos maestros.
Oozie roles
Servidor Oozie: se coloca en una sola copia en uno de los nodos maestros.
Hilo de Roles
ResourceManager : se coloca en una sola copia en uno de los nodos maestros.
Servidor JobHistory : se
instala en una única copia en uno de los nodos maestros.
NodeManager :
active todos los nodos de datos (puede dejar el valor predeterminado).
Roles de ZooKeeper
Servidor ZooKeeper: para garantizar la tolerancia a fallos, se instala por triplicado en los nodos maestros.
Roles de Cloudera Navigator
Navigator Audit Server : se instala en una sola copia en uno de los nodos maestros.
Navigator Metadata Server : se coloca en una sola copia en uno de los nodos maestros.

Después de la distribución de roles, hay una pestaña con una breve lista de configuraciones para los servicios instalados. Su cambio estará disponible después de la instalación y en esta etapa se pueden dejar sin cambios:

Después de la configuración del servicio, hay una configuración de base de datos para los servicios que los necesitan. Ingresamos el nombre completo del host en el que está instalado PostgreSQL, en los cuadros de lista "Tipo de base de datos", seleccionamos el elemento apropiado y en los campos restantes especificamos los datos para conectarnos a las bases de datos correspondientes. Después de ingresar todos los datos, haga clic en el botón "Probar conexión" y verifique que las bases de datos estén disponibles. Si este es el caso, en el lado derecho de la tabla opuesta a cada una de las bases de datos aparecerá la inscripción "Exitosa":

Todo está listo para el despliegue de servicios. Vaya a la siguiente pestaña y observe este proceso. Si hicimos todo bien, todos los pasos se completarán con éxito. De lo contrario, el proceso se interrumpirá en uno de los pasos y el registro de errores estará disponible presionando la flecha:

¡Felicitaciones, CDH está funcionando!

Puede proceder con la instalación de perejiles adicionales.
Establecer perejiles adicionales
En los casos en que el conjunto básico de servicios de CHD no es suficiente o si se requiere una versión más reciente, puede instalar programas adicionales que amplíen la lista de servicios disponibles que se pueden implementar en el clúster. Durante nuestro proyecto, necesitábamos el servicio Spark versión 2.2 para lanzar las tareas desarrolladas y el funcionamiento de las herramientas de descubrimiento de datos. No es parte de CDH, así que instálelo por separado. Para hacer esto, haga clic en el botón "Hosts" y seleccione el elemento de la lista desplegable "Parcelas":

Se abre una pestaña con perejiles, que muestra una lista de clústeres administrados por este Administrador de Cloudera y los perejiles instalados en ellos. Para agregar un perejil con Spark 2.2, seleccione el clúster deseado y haga clic en el botón "Configuración" en la esquina superior derecha.

Hacemos clic en el botón "+", en la línea que aparece indicamos la dirección del repositorio con el símbolo Spark 2.2 ("nombre de host / parcelas / chispa /") y hacemos clic en el botón "Guardar cambios":

Después de estas manipulaciones, debería aparecer uno nuevo con el nombre SPARK2 en la lista de perejiles en la pestaña anterior. Inicialmente, aparece como disponible para descargar, por lo que el siguiente paso es descargarlo haciendo clic en el botón "Descargar":

El parsel descargado debe estar disperso en los nodos del clúster para que los servicios se puedan instalar desde él. Para hacer esto, haga clic en el botón "Distribuir" que aparece en el lado derecho de la línea con el perejil SPARK2:

El último paso para trabajar con el paquete es activarlo. Lo activamos haciendo clic en el botón "Activar", que aparece en el lado derecho de la línea con el perejil:

Después de la confirmación, el servicio que necesitamos estará disponible para la instalación. Pero hay matices. Para instalar algunos servicios en el clúster, debe realizar cualquier acción adicional además de instalar el perejil. Por lo general, esto está escrito en el sitio web oficial en la sección sobre instalación y actualización de este servicio (aquí está su ejemplo para Spark 2: www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html ). En este caso, debe descargar el archivo CSD de Spark 2 (disponible en la página de Información de versión y empaquetado: www.cloudera.com/documentation/spark2/latest/topics/spark2_packaging.html ), instalarlo en el host con Cloudera Manager y reiniciar el último. Hagámoslo: descargue este archivo, transfiéralo al host deseado y ejecute los comandos de las instrucciones:
mv SPARK2_ON_YARN-2.1.0.cloudera1.jar /opt/cloudera/csd/ chown cloudera-scm:cloudera-scm /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar chmod 644 /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar systemctl restart cloudera-scm-server
Cuando se levante Cloudera Manager, todo estará listo para instalar Spark 2. En la pantalla principal, haga clic en la flecha a la derecha del nombre del clúster y seleccione el elemento "Agregar servicio" en el menú desplegable:

En la lista de servicios disponibles para la instalación, seleccione el que necesitamos:

En la siguiente pestaña, seleccione el conjunto de dependencias para el nuevo servicio. Por ejemplo, aquel donde la lista es más amplia:

Luego viene la pestaña con la elección de roles y hosts en los que se instalarán, similar a la que se realizó durante la instalación de CDH. Se recomienda que coloque la función del servidor de historial en una sola copia en uno de los nodos maestros y la puerta de enlace en todos los servidores del clúster:

Después de seleccionar los roles, se propone verificar y confirmar los cambios realizados en el clúster durante la instalación del servicio. Aquí puedes dejar todo por defecto:

La confirmación de los cambios inicia la instalación del servicio en el clúster. Si todo se hace correctamente, la instalación se completará con éxito:
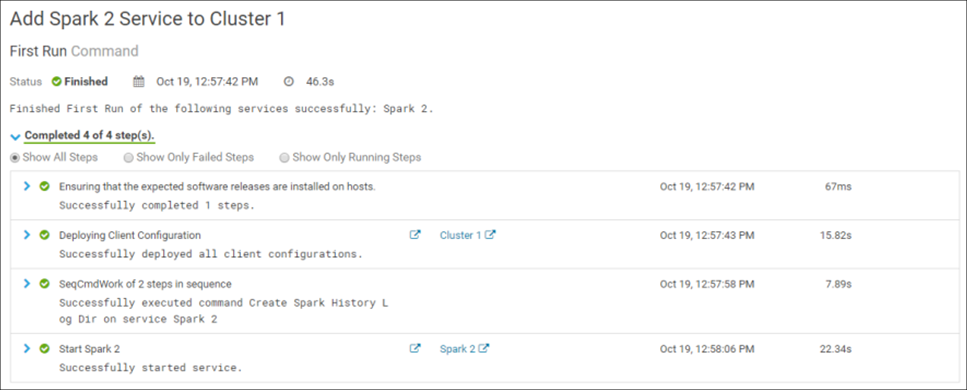
Felicidades Spark 2 se ha instalado correctamente en el clúster:

Debe reiniciar el clúster para completar el proceso de instalación. Después de eso, todo está listo para funcionar.
Pueden producirse errores durante la fase de instalación del servicio. Por ejemplo, al instalar en uno de los entornos, no fue posible implementar el rol de Spark 2 Gateway. La solución a este problema se ayudó copiando el contenido del archivo / var / lib / Alternatives / spark2-conf del host en el que este rol se instaló con éxito en un archivo similar en la máquina con problemas. Para diagnosticar errores de instalación, es conveniente utilizar los archivos de registro de los procesos correspondientes, que se almacenan en la carpeta / var / run / cloudera-scm-agent / process /.
Eso es todo por hoy. La próxima publicación de la serie cubrirá el tema de la administración de clústeres de CDH.