Recientemente, la competencia iMaterialist Challenge (Muebles) terminó en Kaggle, en la que la tarea consistía en clasificar las imágenes en 128 tipos de muebles y artículos para el hogar (la llamada clasificación de grano fino, donde las clases están muy cerca una de la otra).
En este artículo describiré el enfoque que nos llevó al tercer lugar con
m0rtido , pero antes de pasar al punto, propongo usar la red neuronal natural en mi cabeza para resolver este problema y dividir las sillas en la foto a continuación en tres clases.

¿Has adivinado bien? Yo tampoco.
Pero detente, lo primero es lo primero.
Declaración del problema.
En la competencia, se nos dio un conjunto de datos en el que se presentaron 128 clases de objetos domésticos comunes, como sillas, televisores, sartenes y almohadas en forma de personajes de anime.
La parte de capacitación del conjunto de datos consistió en ~ 190 mil imágenes (es difícil decir el número exacto porque a los participantes se les proporcionó solo un conjunto de URL de descarga, algunas de las cuales, por supuesto, no funcionaron), y la distribución de las clases estuvo lejos de ser uniforme (ver la imagen en la que se puede hacer clic a continuación) .

El conjunto de datos de prueba estaba representado por 12800 imágenes, y estaba perfectamente equilibrado: había 100 imágenes para cada clase. También se emitió un conjunto de datos de validación, que también tenía una distribución equilibrada de clases y era exactamente la mitad del tamaño de la prueba.
La métrica de evaluación de la tarea fue
.
¿Cómo decidimos?
En primer lugar, descargamos los datos y miramos una pequeña parte con nuestros ojos. En lugar de muchas imágenes, se descargó una imagen 1x1 o un marcador de posición con un error. Inmediatamente borramos tales imágenes con un script.
Transferencia de aprendizaje
Era obvio que con la cantidad disponible de imágenes y límites de tiempo, no es una buena idea entrenar redes neuronales desde cero en este conjunto de datos. En cambio, utilizamos el enfoque de aprendizaje de transferencia, cuya idea es la siguiente: el peso de la red capacitada en una tarea se puede utilizar para un conjunto de datos completamente diferente y obtener una calidad decente, o incluso un aumento en la precisión en comparación con el aprendizaje desde cero.
Como funciona Las capas ocultas en las redes neuronales profundas actúan como extractores de características, extrayendo características que luego las capas superiores utilizan directamente para la clasificación.
Aprovechamos esto completando una serie de CNN profundos previamente capacitados en ImageNet. Para estos fines, utilizamos Keras y su zoológico de modelos, donde el siguiente código fue suficiente para cargar la arquitectura terminada:
base_model = densenet.DenseNet201(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg')
Después de eso, extrajimos los llamados signos de cuello de botella (características a la salida de la última capa convolucional) de la red y capacitamos a softmax con
deserción en la parte superior de ellos.
Luego, conectamos los pesos "superiores" entrenados a la parte convolucional de la red y capacitamos a toda la red a la vez.
Ver código for layer in base_model.layers: layer.trainable = True top_model = Sequential() top_model.add(Dropout(0.5, name='top_dropout', input_shape=base_model.output_shape[1:])) top_model.add(Dense(128, activation='softmax', name='top_softmax')) top_model.load_weights('top-weights-densenet.hdf5', by_name=True) model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) initial_lrate = 0.0005 model.compile(optimizer=Adam(lr=initial_lrate), loss='categorical_crossentropy', metrics=['accuracy'])
Con un ajuste tan fino de las redes, logramos probar los siguientes hacks:
- Aumento de datos . Para combatir el sobreajuste, utilizamos un aumento muy estricto: reflexión horizontal, zoom, cambios, rotaciones, inclinaciones, agregando ruido de color, cambios de canales de color, entrenamiento en cinco líneas de recorte (ángulos y centro de la imagen). También queríamos probar FancyPCA , pero fallamos debido a la falta de recursos informáticos.
- TTA Para predecir las clases de validación y prueba, utilizamos el aumento, ligeramente menos agresivo que durante el entrenamiento, y promediamos los resultados de las predicciones para aumentar la precisión.
- Ciclismo Tasa de aprendizaje . El aumento cíclico y la disminución del ritmo de entrenamiento ayudaron a los modelos a no quedarse atascados en los mínimos locales.
- Modelo de entrenamiento en un subconjunto de clases . Como puede ver en la imagen arriba del corte, el conjunto de datos contenía clases muy cercanas entre sí. Tan cerca que en ciertos grupos de objetos (por ejemplo, en sillas y sillones, que se representaron hasta 8 clases), nuestros modelos estaban mucho más equivocados que en otros tipos de objetos. Intentamos entrenar a una CNN separada para reconocer solo las sillas, con la esperanza de que dicha red aprenda a distinguir variedades de sillas mejor que una red de propósito general, pero este enfoque no aumentó la precisión.
Por qué Parte de la respuesta a esta pregunta se presenta en la imagen antes del corte: las clases eran tan similares que incluso con el marcado inicial de los datos, las personas que colocaban las etiquetas de clase no podían distinguirlos, por lo que aún sería imposible extraer los datos de estos datos. - Red de transformadores espaciales . A pesar de que entrenamos una de las redes con ella y obtuvimos una precisión bastante buena, desafortunadamente no se incluyó en la presentación final.
- Función de pérdida ponderada . Para compensar la distribución desequilibrada de las clases, utilizamos la pérdida ponderada. Esto ayudó tanto en el entrenamiento de softmax "tops" como en el entrenamiento adicional de toda la red. Los pesos se calcularon utilizando la función de scikit-learn y luego se pasaron al método de ajuste del modelo:
train_labels = utils.to_categorical(train_generator.classes) y_integers = np.argmax(train_labels, axis=1) class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
Las redes formadas de esta manera representaron el 90% de nuestro conjunto final.
Apilando etiquetas de cuello de botella
Descargo de responsabilidad: nunca repita la técnica descrita más adelante en la vida real.
Entonces, como determinamos en la sección anterior, las características de cuellos de botella de las redes capacitadas en ImageNet se pueden usar para la clasificación en otras tareas.
m0rtido decidió ir más allá y propuso la siguiente estrategia:
- Tomamos todas las arquitecturas pre-entrenadas disponibles (en particular, NasNet Large, InceptionV4, Vgg19, Vgg16, InceptionV3, InceptionResnetV2, Resnet-50, Resnet-101, Resnet-152, Xception, Densenet-169, Densenet-121, Densenet-201 fueron tomadas ) y extraer signos de cuello de botella de ellos. También contaremos los signos para las versiones reflejadas de las imágenes (como un aumento minimalista).
- Reduzca la dimensión de las características de cada uno de los modelos tres veces con la ayuda de SAR para que se ajusten normalmente a los 16 Gb de RAM disponibles.
- Concatena estas características en un gran vector de características.
- Enseñaremos un perceptrón multicapa además de todo esto y generaremos predicciones. También entrenaremos rompiendo en pliegues y promediando todas estas predicciones.
El apilamiento monstruoso resultante dio un gran aumento de precisión al conjunto general.
Conjunto de modelos
Después de todo lo anterior, teníamos alrededor de dos docenas de redes convolucionales oscurecidas, así como dos perceptrones en la parte superior de los signos de cuello de botella. La pregunta era: ¿cómo obtener una sola predicción de todo esto?
En el buen sentido, en la mejor tradición de Kaggle, tuvimos que apilarnos encima de todo esto, pero para hacer el apilamiento de OOF, no teníamos tiempo ni una GPU, y entrenar a un modelo de nivel superior en una reserva de validación resultó en un sobreajuste muy grande. Por lo tanto, decidimos implementar un algoritmo bastante simple para la creación de conjuntos codiciosos:
- Inicializa un conjunto vacío.
- Intentamos agregar cada modelo por turno y considerar la puntuación. Seleccionamos el modelo que aumenta más la métrica y lo agregamos al conjunto. Los resultados de la predicción de modelos en el conjunto simplemente se promedian.
- Si ninguno de los modelos mejora el rendimiento, revisamos el conjunto e intentamos eliminar los modelos. Si resulta que eliminas algún modelo para que la puntuación mejore, hacemos esto y volvemos al paso 2.
Como se seleccionó una métrica
. Esta fórmula fue elegida empíricamente de tal manera que
y
resultó ser aproximadamente de la misma escala. Tal métrica integral se correlaciona bien con
tanto en validación como en una tabla de clasificación pública.
Además, el hecho de que en cada iteración agregamos o eliminamos un modelo (es decir, los pesos del modelo siempre se mantuvieron enteros) desempeñó el papel de una especie de regularización, no permitiendo que el conjunto se sobreajuste bajo el conjunto de datos de validación.
Como resultado, el conjunto incluyó los siguientes modelos:
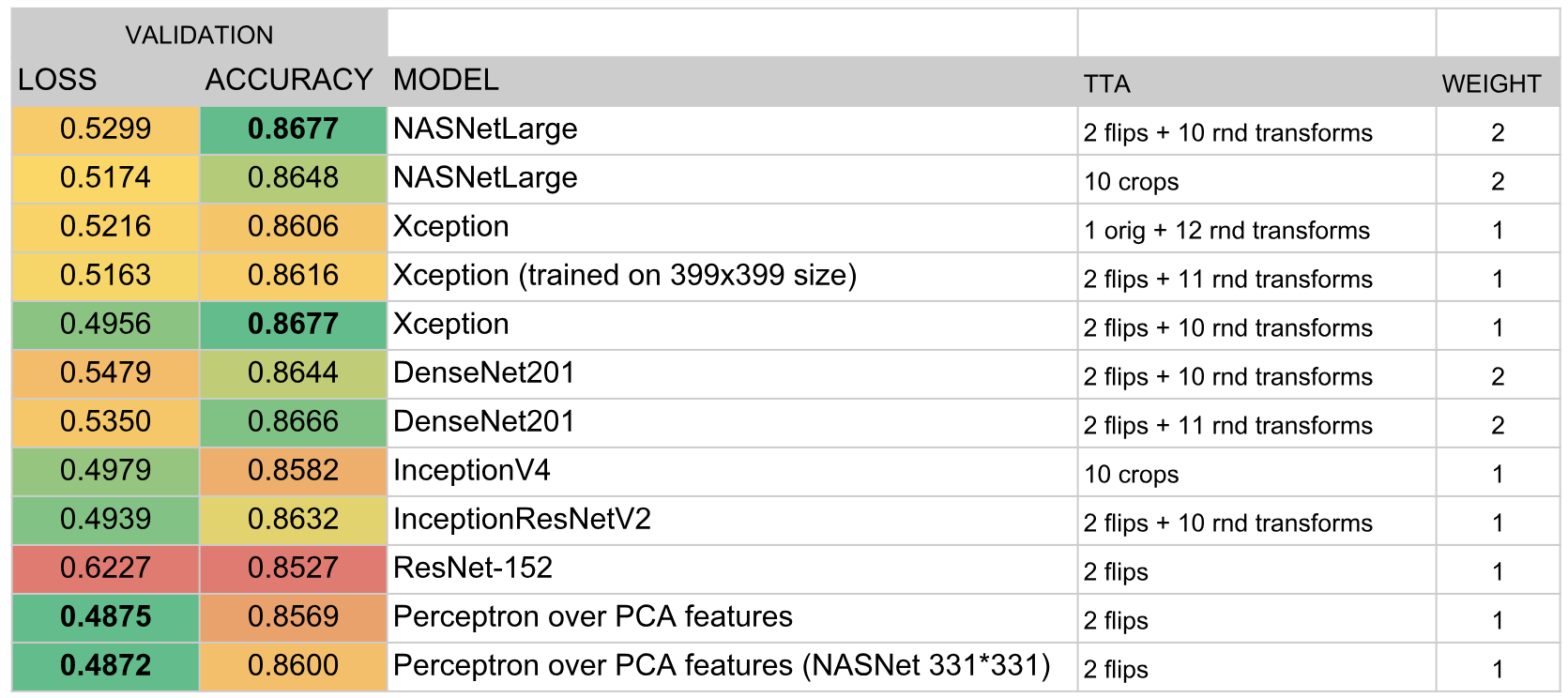
Resultados
Según los resultados de la competencia, tomamos el tercer lugar. Me parece que la clave del éxito fue la elección exitosa del algoritmo de conjunto y la gran cantidad de tiempo que
m0rtido y yo invertimos en entrenar a una gran cantidad de modelos.
