Hola Mi nombre es Sergey, trabajo como ingeniero jefe en Sbertekh. He estado en el campo de TI durante aproximadamente 10 años, de los cuales 6 están involucrados en bases de datos, procesos ETL, DWH y todo lo relacionado con datos. En este artículo hablaré sobre Vertica, un DBMS analítico y verdaderamente columnar que comprime, almacena, entrega datos de manera eficiente y es excelente como una solución de big data.

Información general
Big data comenzó a desarrollarse en la década de 2000, y se necesitaban motores que pudieran digerirlo todo. En respuesta a esto, aparecieron varios DBMS en columna destinados a este propósito, incluido Vertica.
Vertica no solo almacena sus datos en columnas, lo hace racionalmente, con un alto grado de compresión, sino que también programa eficientemente las consultas y entrega datos rápidamente. La información, que en un DBMS clásico en minúsculas ocupa aproximadamente 1 TB de espacio en disco, en Vertica tomará aproximadamente 200-300 GB, con lo que obtendremos buenos ahorros en discos.
Vertica fue originalmente diseñado como una columna DBMS. Básicamente, otras bases simplemente intentan imitar varios mecanismos de columna, pero no siempre tienen éxito porque el motor todavía está diseñado para procesar cadenas. Como regla, los imitadores simplemente transponen la tabla y luego la procesan con el mecanismo de línea habitual.
Vertica es tolerante a fallas, no tiene un nodo de control, todos los nodos son iguales. Si hay problemas con uno de los servidores del clúster, seguiremos recibiendo los datos. Muy a menudo, recibir datos a tiempo es fundamental para los clientes comerciales, especialmente en un momento en que los informes están cerrados y es necesario proporcionar información a las autoridades financieras.
Áreas de aplicación
Vertica es principalmente un almacén de datos analíticos. No debe escribirle en pequeñas transacciones, no debe atornillarlo a ningún sitio, etc. Vertica debe considerarse como un tipo de capa de lote, donde vale la pena sumergir los datos en paquetes grandes. Si es necesario, Vertica está lista para proporcionar estos datos muy rápidamente: las consultas para millones de líneas se completan en segundos.
¿Dónde puede ser útil? Tomemos, por ejemplo, una compañía de telecomunicaciones. Vertica se puede utilizar para geoanálisis, desarrollo de redes, gestión de calidad, marketing dirigido, estudio de información de centros de contacto, gestión de salidas de clientes y soluciones antifraude / antispam.

En otros sectores empresariales, todo es casi lo mismo: los análisis oportunos y confiables son importantes para obtener ganancias. En el comercio, por ejemplo, todos intentan personalizar de alguna manera a los clientes, distribuir tarjetas de descuento para esto, recopilar datos sobre dónde, qué y cuándo compró una persona, etc. Al analizar los conjuntos de información de todos estos canales, podemos compararlo, construir modelos y tomar decisiones que conduzcan al crecimiento de las ganancias.
Umbral de entrada
Hoy, cualquier empleador requiere un analista para comprender qué es SQL. Si conoce ANSI SQL, entonces puede ser llamado un usuario seguro de Vertica. Si puede construir modelos en Python y R, entonces usted es simplemente un "masajista" de datos. Si ha dominado Linux y tiene conocimientos básicos de administración de Vertica, puede trabajar como administrador. En general, el umbral de entrada en Vertica es bajo, pero, por supuesto, todos los matices solo se pueden encontrar rellenando una mano durante la operación.
Arquitectura de hardware
Considere el nivel de clúster Vertica. Este DBMS proporciona un procesamiento masivo de datos paralelos (MPP) en una arquitectura de computación distribuida, "nada compartido", donde, en principio, cualquier nodo está listo para recoger las funciones de cualquier otro nodo. Propiedades principales:
- No hay un solo punto de falla
- cada nodo es independiente e independiente,
- No hay un único punto de conexión para todo el sistema,
- los nodos de infraestructura están duplicados,
- los datos en los nodos del clúster se copian automáticamente.
El clúster se escala linealmente sin ningún problema. Simplemente colocamos los servidores en un estante y los conectamos a través de una interfaz gráfica. Además de los servidores en serie, es posible la implementación en máquinas virtuales. ¿Qué se puede lograr con la extensión?
- Aumentos de volumen para nuevos datos.
- Aumenta la carga de trabajo máxima
- Mejora de la resiliencia. Cuantos más nodos haya en el clúster, es menos probable que el clúster falle debido a un fallo y, por lo tanto, más cerca estamos de garantizar la disponibilidad 24/7.
Pero hay algunas cosas a considerar. Periódicamente, los nodos deben eliminarse del clúster para el mantenimiento. Otro caso bastante común en las grandes organizaciones es que los servidores quedan fuera de garantía y pasan de ser productivos a algún tipo de entorno de prueba. En su lugar, hay nuevos que están bajo la garantía del fabricante. Según los resultados de todas estas operaciones, es necesario reequilibrar. Este es un proceso en el que los datos se redistribuyen entre nodos; en consecuencia, la carga de trabajo se redistribuye. Este es un proceso que requiere muchos recursos y, en clústeres con una gran cantidad de datos, puede reducir en gran medida el rendimiento. Para evitar esto, debe seleccionar la ventana de servicio: el momento en que la carga es mínima, en cuyo caso los usuarios no lo notarán.
Proyecciones
Para comprender cómo se almacenan los datos en Vertica, debe lidiar con uno de los conceptos básicos: la proyección.
Las unidades lógicas de almacenamiento de información son diagramas, tablas y vistas. Las unidades físicas son proyecciones. Las proyecciones vienen en varios tipos:
- Superproyección
- Proyecciones específicas de consultas
- Proyecciones Agregadas
Al crear cualquier tabla, se crea automáticamente una
súper proyección que contiene todas las columnas de nuestra tabla. Si necesita acelerar cualquiera de los procesos regulares, podemos crear una
proyección especial
orientada a consultas que contendrá, por ejemplo, 3 de cada 10 columnas.
El tercer tipo también está destinado a la aceleración:
proyecciones agregadas . No entraré en sus subclases, esto no es muy interesante. Quiero advertirle de inmediato que no vale la pena resolver constantemente sus problemas con la ejecución de consultas mediante la creación de nuevas proyecciones. Finalmente, el clúster comenzará a disminuir.
Al crear proyecciones, debemos evaluar si nuestras consultas tienen suficientes superproyecciones. Si aún queremos experimentar, agregamos estrictamente una nueva proyección. Si surgen problemas, será más fácil encontrar la causa raíz. Para tablas grandes, cree una proyección segmentada. Se divide en segmentos que se distribuyen entre varios nodos, lo que aumenta la tolerancia a fallas y minimiza la carga en un nodo. Si las tabletas son pequeñas, entonces es mejor hacer proyecciones no segmentadas. Se copian completamente a cada nodo y, por lo tanto, aumenta el rendimiento. Haré una reserva: en términos de Vertica, una tabla "pequeña" es de aproximadamente 1 millón de filas.
Tolerancia a fallos
La tolerancia a fallos en Vertica se implementa utilizando el mecanismo K-Safety. Es bastante simple en términos de descripción, pero complejo en términos de trabajo a nivel de motor. Se puede controlar con el parámetro K-Safety: puede tener un valor de 0, 1 o 2. Este parámetro establece el número de copias de los datos de proyección segmentados.
Las copias de las proyecciones se llaman proyecciones de amigos. Traté de traducir esta frase a través del traductor Yandex y resultó algo así como una "proyección de compinche". Google ofreció opciones y más interesantes. Por lo general, estas proyecciones se denominan socio o vecino, de acuerdo con su propósito funcional. Estas son proyecciones que simplemente se almacenan en nodos vecinos y, por lo tanto, se reservan. Las proyecciones no segmentadas no tienen proyecciones de amigos, se copian por completo.
Como funciona Considere un grupo de cinco máquinas. Deje que la seguridad K sea igual a 1.

Los nodos están numerados y debajo de ellos hay proyecciones de socios escritas que se almacenan en ellos. Supongamos que tenemos un nodo desconectado. Que va a pasar

El nodo 1 contiene una proyección amigable del nodo 2. Por lo tanto, la carga en el nodo 1 crecerá, pero el clúster no dejará de funcionar. Y ahora esta situación:
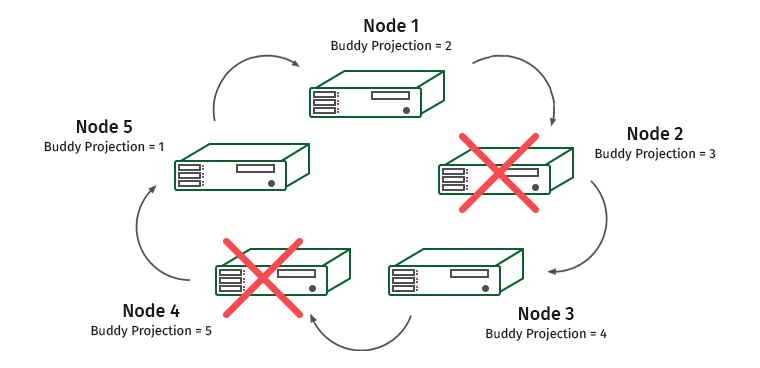
El nodo 3 contiene la proyección del nodo 4, y los nodos 1 y 3 se sobrecargarán.
Complicamos la tarea. K-Safety = 2, deshabilita dos nodos adyacentes.
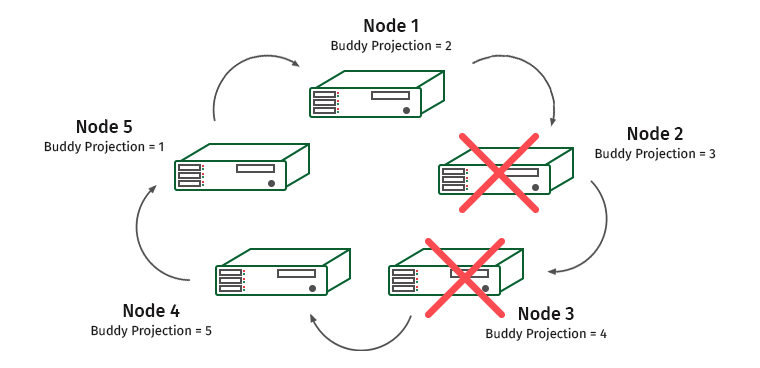
Aquí los nodos 1 y 4 se sobrecargarán (el nodo 2 contiene la proyección del nodo 1 y el nodo 3 contiene la proyección del nodo 4).
En tales situaciones, el motor del sistema reconoce que uno de los nodos no responde y la carga se transfiere al nodo vecino. Se usará hasta que el nodo se restablezca nuevamente. Una vez que esto sucede, la carga y los datos se redistribuyen de nuevo. Tan pronto como perdemos más de la mitad del clúster o los nodos que contienen todas las copias de algunos datos, el clúster se levanta.
Almacenamiento lógico de datos
Vertica tiene áreas de almacenamiento optimizadas para escritura, áreas optimizadas para lectura y un mecanismo Tuple Mover que permite que los datos fluyan de la primera a la segunda.
Cuando usamos las operaciones COPY, INSERT, UPDATE, automáticamente terminamos en WOS (Write Optimized Store), un área donde los datos no están optimizados para leer y ordenados solo cuando se solicitan, almacenados sin compresión o indexación. Si los volúmenes de datos son demasiado grandes para el área WOS, utilizando la instrucción DIRECT adicional, deben escribirse inmediatamente en ROS. De lo contrario, el WOS estará lleno y nos estrellaremos.
Después de que expira el tiempo especificado en la configuración, los datos de WOS fluyen hacia ROS (Read Optimized Store), una estructura optimizada y orientada a la lectura del almacenamiento en disco. ROS almacena la mayor parte de los datos, aquí se clasifica y comprime. Los datos de ROS se dividen en contenedores de almacenamiento. Un contenedor es un conjunto de líneas creadas por operadores de traducción (COPY DIRECT) y se almacena en un grupo específico de archivos.
Independientemente de dónde se escriban los datos, en WOS o en ROS, están disponibles de inmediato. Pero leer desde WOS es más lento porque los datos no están agrupados allí.

Tuple Mover es una herramienta de limpieza que realiza dos operaciones:
- Desplazamiento: comprime y ordena los datos en WOS, los mueve a ROS y crea nuevos contenedores para ellos en ROS.
- Fusión: barriendo detrás de nosotros cuando usamos DIRECT. No siempre podemos cargar tanta información para obtener contenedores ROS grandes. Por lo tanto, combina periódicamente pequeños contenedores ROS en grandes, limpia los datos marcados para su eliminación, mientras trabaja en segundo plano (según el tiempo especificado en la configuración).
¿Cuáles son los beneficios del almacenamiento en columna?
Si leemos líneas, entonces, por ejemplo, para ejecutar un comando
SELECT 1,11,15 from table1
tendremos que leer toda la tabla. Esta es una gran cantidad de información. En este caso, el enfoque de columna es más rentable. Le permite contar solo las tres columnas que necesitamos, ahorrando memoria y tiempo.

Asignación de recursos
Para evitar problemas, el usuario debe estar limitado un poco. Siempre existe la posibilidad de que el usuario escriba una gran solicitud que engullirá todos los recursos. De forma predeterminada, Vertica ocupa una parte importante del área General y, además, se resaltan áreas separadas para Tuple Mover, WOS y procesos del sistema (recuperación, etc.).
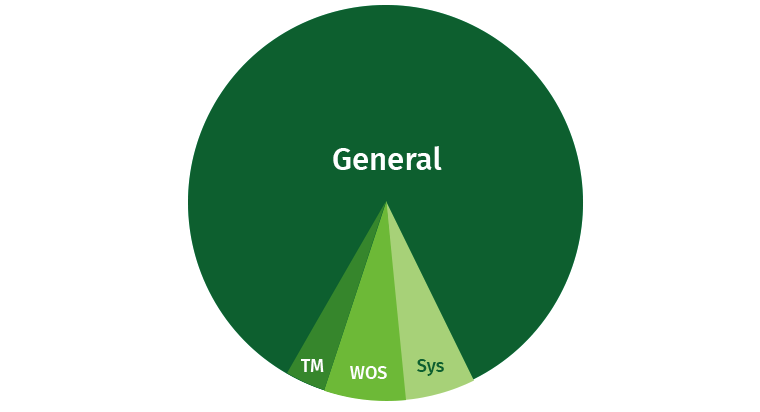
Intentemos compartir estos recursos. Creamos áreas para escritores, lectores y consultas lentas de baja prioridad.

Si observamos las tablas del sistema en las que se almacenan nuestros recursos (agrupaciones de recursos), veremos muchos parámetros con los que puede ajustar todo con mayor precisión. Al principio, no debe entrar en esto, es mejor limitarse simplemente a cortar la memoria para ciertas tareas. Cuando ganes experiencia y estés 100% seguro de que estás haciendo todo correctamente, será posible experimentar.
Las configuraciones finas incluyen prioridad de ejecución, sesiones competitivas y la cantidad de memoria asignada. E incluso con procesadores podemos arreglar algo. Para trabajar con esta configuración, necesita plena confianza en la corrección de sus acciones, por lo que es mejor contar con el apoyo de la empresa y tener el derecho de cometer un error.
A continuación se muestra un ejemplo de una solicitud mediante la cual puede ver la configuración del grupo General:
dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |ANSI SQL y otras características
- Vertica le permite escribir en SQL-99: toda la funcionalidad es compatible.
- Verica tiene excelentes capacidades analíticas: incluso se incluyen herramientas de aprendizaje automático
- Vertica puede indexar textos
- Vertica procesa datos semiestructurados
Integración
Vertica, como todas las herramientas actuales, está seriamente integrado con otros sistemas. Capaz de funcionar bien con HDFS (Hadoop). En versiones anteriores, Vertica solo podía descargar datos de HDFS de ciertos formatos, pero ahora puede hacer todo, funciona con todos los formatos, por ejemplo, ORC y Parquet. Incluso puede adjuntar archivos como tablas externas y almacenar sus datos en contenedores ROS directamente en HDFS. En la octava versión de Vertica, se realizó una optimización significativa de la velocidad de trabajo con HDFS, un catálogo de metadatos y análisis de estos formatos. Puede construir un clúster Vertica directamente en un clúster Hadoop.
A partir de la versión 7.2, Vertica puede funcionar con Apache Kafka, si alguien necesita un agente de mensajes.
Vertica 8 tiene soporte completo para Spark. Es posible copiar datos de Spark a Vertica y viceversa.
Conclusión
Vertica es una buena opción para trabajar con big data que no requiere mucho conocimiento de entrada. Este DBMS tiene amplias capacidades analíticas. De los inconvenientes, esta solución no es de código abierto, pero puede intentar implementarla de forma gratuita con un límite de 1 TB y tres nodos; esto es suficiente para comprender si necesita Vertica o no.