Todos los sistemas modernos de moderación utilizan
crowdsourcing o aprendizaje automático que ya se ha convertido en un clásico. En el próximo entrenamiento de ML en Yandex, Konstantin Kotik, Igor Galitsky y Alexey Noskov hablaron sobre su participación en el concurso para la identificación masiva de comentarios ofensivos. La competencia se llevó a cabo en la plataforma Kaggle.
- Hola a todos! Mi nombre es Konstantin Kotik, soy científico de datos en la compañía Button of Life, estudiante del departamento de física y de la Escuela de Graduados de Negocios de la Universidad Estatal de Moscú.
Hoy, nuestros colegas, Igor Galitsky y Alexei Noskov, le informarán sobre la competencia del Desafío de clasificación de comentarios tóxicos, en la que nuestro equipo DecisionGuys ocupó el décimo lugar entre 4551 equipos.
Una discusión en línea de temas que nos importan puede ser difícil. Los insultos, la agresión y el acoso que ocurren en línea a menudo obligan a muchas personas a abandonar la búsqueda de varias opiniones apropiadas sobre temas que les interesan, a negarse a expresarse.
Muchas plataformas luchan por comunicarse efectivamente en línea, pero esto a menudo lleva a muchas comunidades a simplemente cerrar los comentarios de los usuarios.
Un equipo de investigación de Google y otra compañía están trabajando en herramientas para ayudar a mejorar la discusión en línea.
Uno de los trucos en los que se centran es explorar comportamientos negativos en línea, como comentarios tóxicos. Estos son comentarios que pueden ser ofensivos, irrespetuosos o simplemente obligar al usuario a abandonar la discusión.

Hasta la fecha, este grupo ha desarrollado una API pública que puede determinar el grado de toxicidad de un comentario, pero sus modelos actuales aún cometen errores. Y en esta competencia, nosotros, los Kegglers, fuimos desafiados a construir un modelo que fuera capaz de identificar comentarios que contengan amenazas, odio, insultos y similares. E idealmente, este modelo debía ser mejor que el modelo actual para su API.
Tenemos la tarea del procesamiento de texto: identificar y luego clasificar los comentarios. Como ejemplos de entrenamiento y prueba, se proporcionaron comentarios de las páginas de discusión de Wikipedia. Hubo alrededor de 160 mil comentarios en el tren, 154 mil en la prueba.

La muestra de entrenamiento se marcó de la siguiente manera. Cada comentario tiene seis etiquetas. Las etiquetas toman el valor 1 si el comentario contiene este tipo de toxicidad, 0 de lo contrario. Y puede ser que todas las etiquetas sean cero, un caso de comentario adecuado. O puede ser que un comentario contenga varios tipos de toxicidad, inmediatamente una amenaza y obscenidad.
Debido al hecho de que estamos en el aire, no puedo demostrar ejemplos específicos de estas clases. Con respecto a la muestra de prueba, para cada comentario fue necesario predecir la probabilidad de cada tipo de toxicidad.
La métrica de calidad es el AUC ROC promediado sobre los tipos de toxicidad, es decir, la media aritmética del AUC ROC para cada clase por separado.
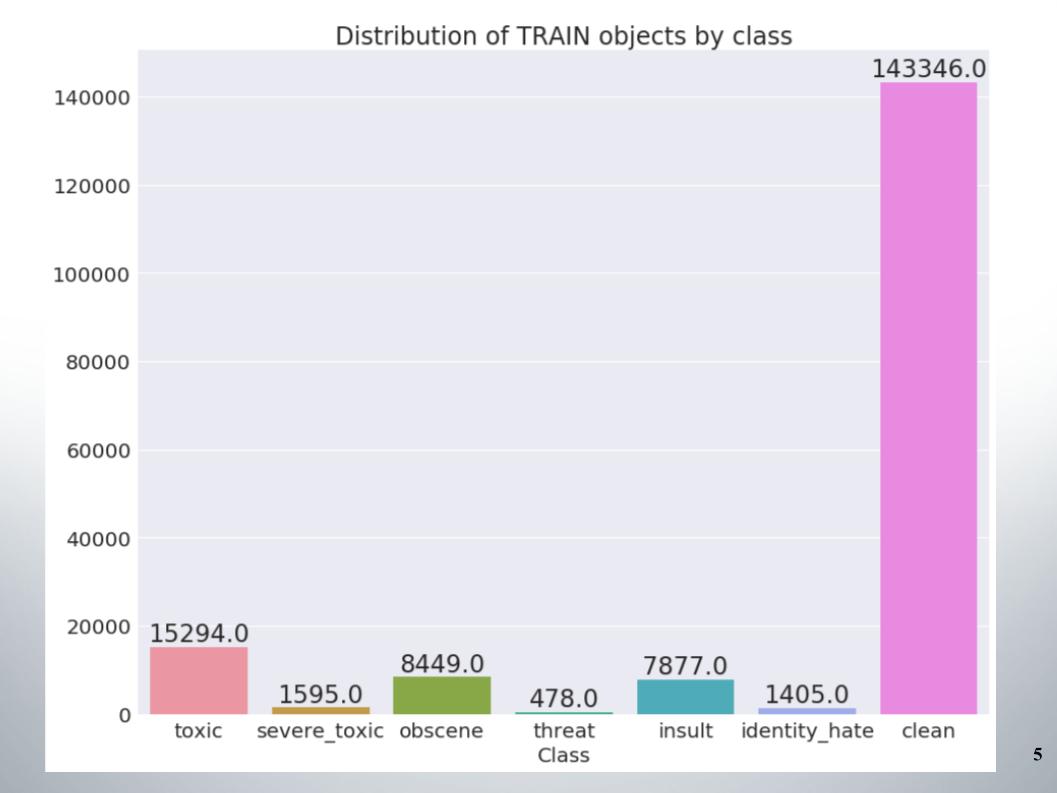
Aquí está la distribución de objetos por clases en el conjunto de entrenamiento. Se puede ver que los datos están muy desequilibrados. Debo decir de inmediato que nuestro equipo calificó en una muestra de métodos para trabajar con datos desequilibrados, por ejemplo, sobremuestreo o submuestreo.

Cuando construí el modelo, utilicé un preprocesamiento de datos en dos etapas. La primera etapa es el preprocesamiento básico de los datos, estas son las transformaciones de la vista en la diapositiva, esto está llevando el texto a minúsculas, eliminando enlaces, direcciones IP, números y signos de puntuación.

Para todos los modelos, se utilizó este preprocesamiento de datos básico. En la segunda etapa, se llevó a cabo un preprocesamiento parcial de los datos, reemplazando los emoticones con las palabras correspondientes, descifrando abreviaturas, corrigiendo errores tipográficos, llevando los diferentes tipos de tapetes a la misma forma y también eliminando imágenes. En algunos comentarios, se indicaron enlaces a imágenes, simplemente los eliminamos.
Para cada uno de los modelos, se utilizó el preprocesamiento parcial de datos y sus diversos elementos. Todo esto se hizo para que los modelos base redujeran la correlación cruzada entre los modelos base al construir una composición adicional.
Pasemos a la parte más interesante: construir un modelo.
Inmediatamente abandoné el enfoque clásico de la bolsa de palabras. Debido al hecho de que en este enfoque cada palabra es un atributo separado. Este enfoque no tiene en cuenta el orden general de las palabras; se supone que las palabras son independientes. En este enfoque, la generación del texto ocurre de modo que haya cierta distribución en las palabras, una palabra se selecciona aleatoriamente de esta distribución y se inserta en el texto.
Por supuesto, hay procesos generativos más complejos, pero la esencia no cambia: este enfoque no tiene en cuenta el orden general de las palabras. Puede ir a engramas, pero solo se tendrá en cuenta el orden de las palabras en la ventana, y no en general. Por lo tanto, también entendí a mis compañeros de equipo que necesitaban usar algo más inteligente.
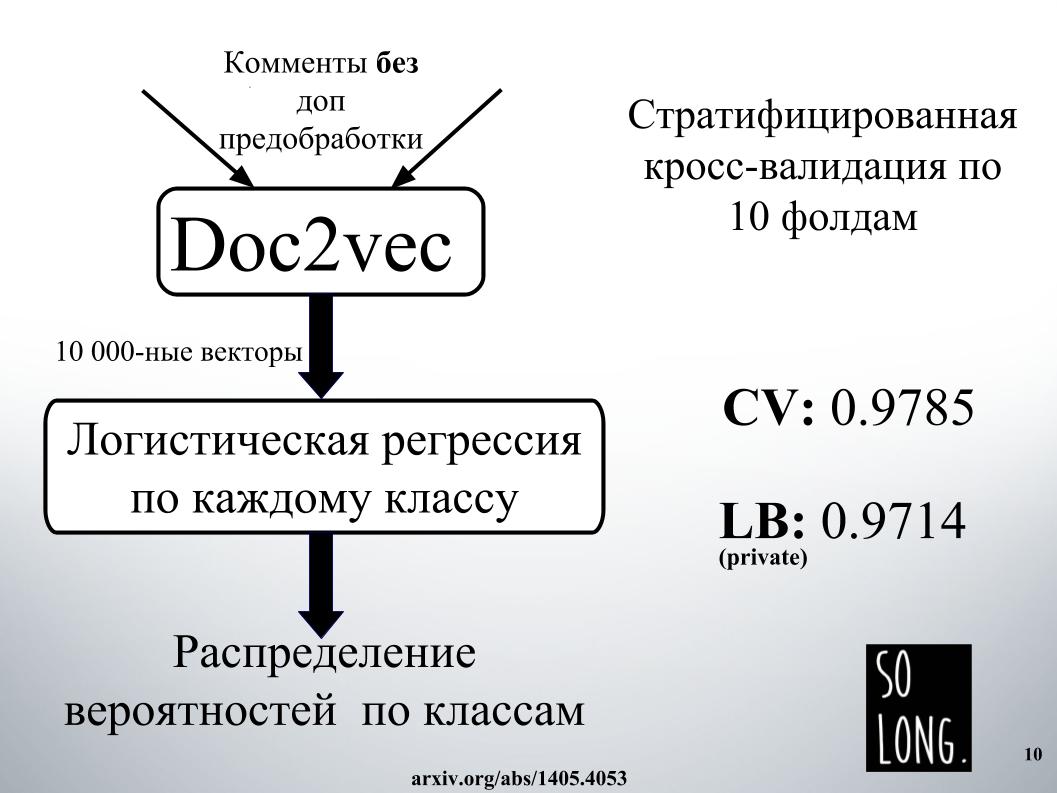
Lo primero que se me ocurrió fue usar una representación vectorial con Doc2vec. Este es Word2vec más un vector que tiene en cuenta la unicidad de un documento en particular. En el artículo original, este vector se llama como el párrafo id.
Luego, de acuerdo con dicha representación vectorial, se estudió la regresión logística, donde cada documento estaba representado por un vector de 10.000 dimensiones. La evaluación de calidad se realizó en una validación cruzada de diez pliegues, se estratificó y es importante tener en cuenta que la regresión logística se estudió para cada clase, seis problemas de clasificación se resolvieron por separado. Y al final, el resultado fue una distribución de probabilidad por clase.
La regresión logística ha sido entrenada durante mucho tiempo. Generalmente no encajaba en la RAM. En las instalaciones de Igor, pasaron un día en algún lugar para obtener el resultado, como en una diapositiva. Por esta razón, de inmediato nos negamos a usar Doc2vec debido a las altas expectativas, aunque podría mejorarse en 1000 si se hiciera un comentario con preprocesamiento de datos adicional.

Los más inteligentes que nosotros y los otros competidores usamos fueron redes neuronales recurrentes. Reciben secuencialmente palabras en la entrada, actualizando su estado oculto después de cada palabra. Igor y yo usamos la red recurrente GRU para la incorporación de palabras en fastText, que es especial porque resuelve muchos problemas de clasificación binaria independientes. Predecir la presencia o ausencia de la palabra de contexto de forma independiente.
También realizamos una evaluación de calidad en la validación cruzada de diez pliegues, no se estratificó aquí, y aquí la distribución de probabilidad se obtuvo inmediatamente por clase. Cada problema de clasificación binaria no se resolvió por separado, pero se generó inmediatamente un vector de seis dimensiones. Fue nuestro uno de los mejores modelos individuales.
Usted pregunta, ¿cuál fue el secreto del éxito?
Consistía en mezclar, había mucho, con apilamiento y redes en el enfoque. El enfoque de redes debe representarse como un gráfico dirigido.
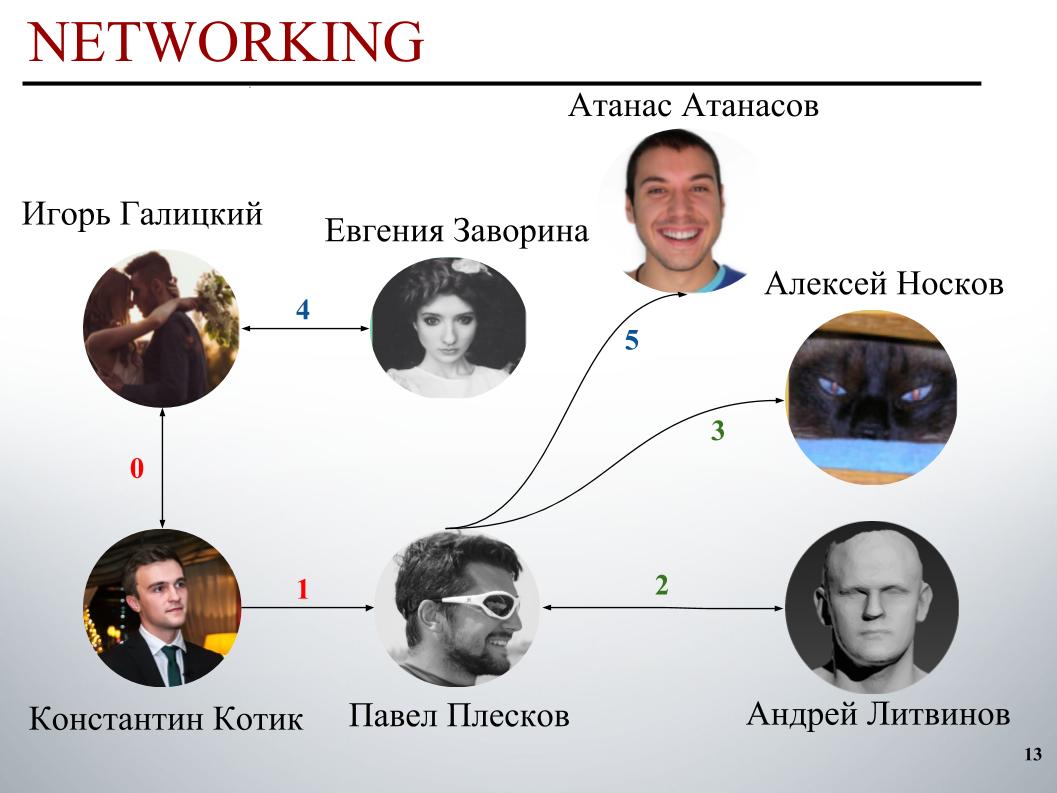
Al comienzo de la competencia, el equipo de DecisionGuys estaba formado por dos personas. Luego, Pavel Pleskov, en el canal ODS Slack, expresó el deseo de querer formar un equipo con alguien del top 200. En ese momento estábamos en algún lugar en el lugar 157, y Pavel Pleskov en el lugar 154, en algún lugar del vecindario. Igor notó su deseo de unirse, y lo invité al equipo. Entonces Andrey Litvinov se unió a nosotros, luego Pavel invitó al Gran Maestro Alexei Noskov a nuestro equipo. Igor - Eugene. Y el último socio de nuestro equipo fue el búlgaro Atanas Atanasov, y este fue el resultado de un conjunto internacional humano.
Ahora Igor Galitsky contará cómo enseñó gru, con más detalle hablará sobre las ideas y enfoques de Pavel Pleskov, Andrei Litvinov y Atanas Atanasov.
Igor Galitsky:
- Soy científico de datos en Epoch8, y hablaré sobre la mayoría de las arquitecturas que utilizamos.
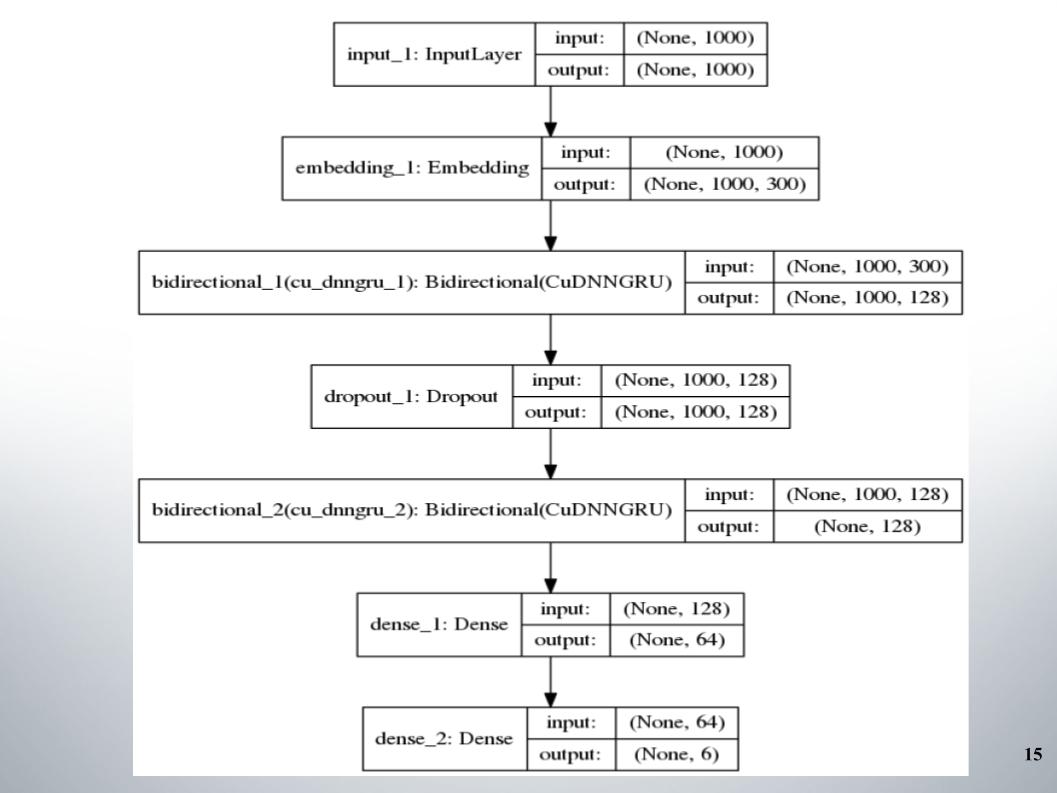
Todo comenzó con el gruñido didireccional estándar con dos capas, casi todos los equipos lo usaron, y fastText, la función de activación EL, se usó como incrustación.
No hay nada especial que decir, arquitectura simple, sin lujos. ¿Por qué nos dio tan buenos resultados con los que nos mantuvimos en el top 150 durante bastante tiempo? Tuvimos un buen preprocesamiento del texto. Era necesario seguir adelante.
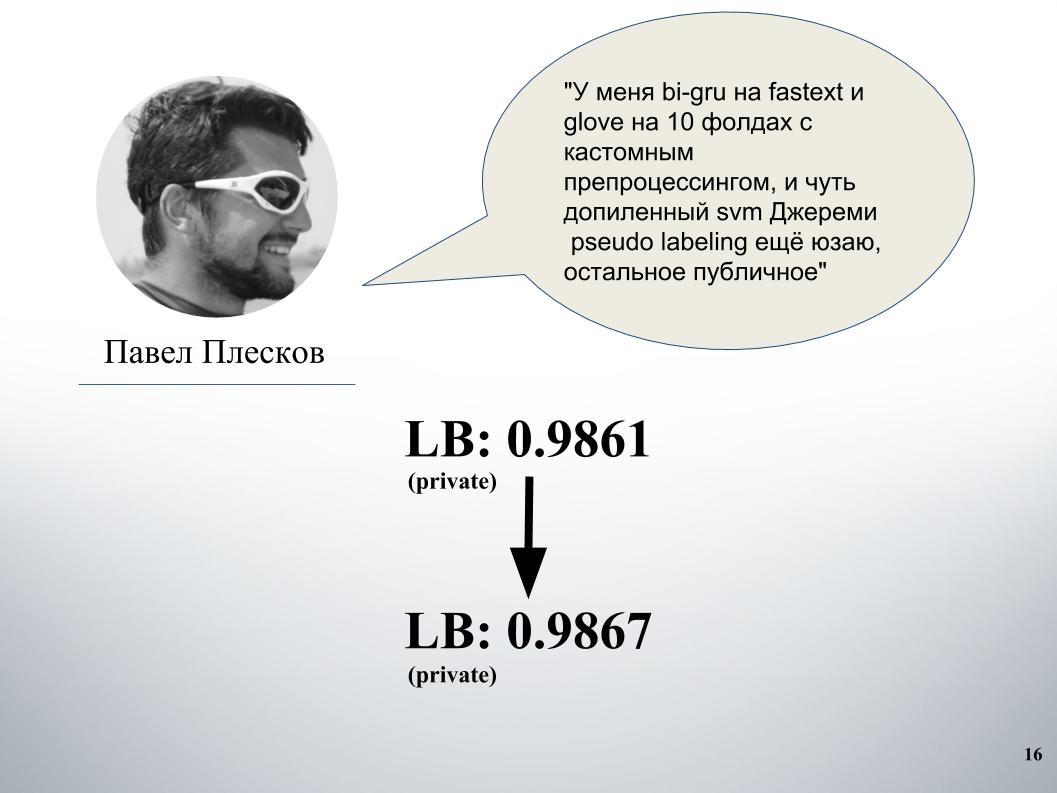
Paul tuvo su propio enfoque. Después de mezclarse con la nuestra, esto dio un aumento significativo. Antes de eso, teníamos una mezcla de gru y modelo en Doc2vec, dio 61 LB.
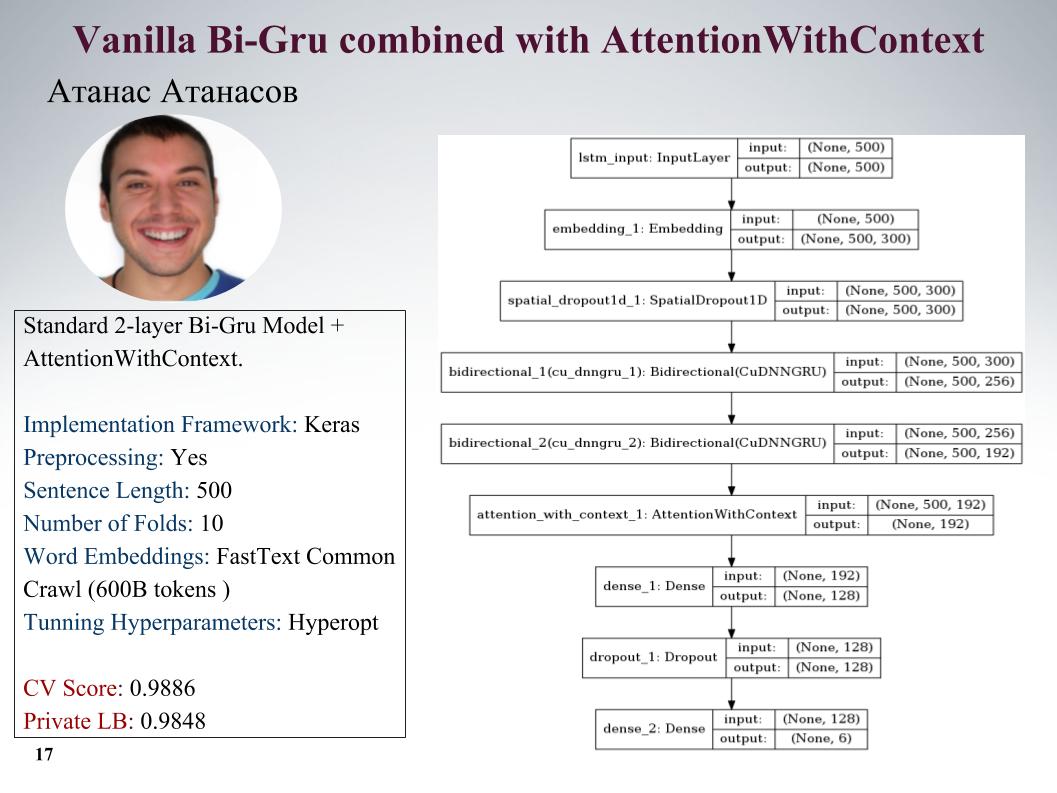
Te contaré sobre los enfoques de Atanas Atanasov, él es directamente un entusiasta de cualquier artículo nuevo. Aquí está gru con atención, todos los parámetros en la diapositiva. Tenía muchos enfoques realmente geniales, pero hasta el último momento usó su preprocesamiento y todas las ganancias se nivelaron. Velocidad en el tobogán.
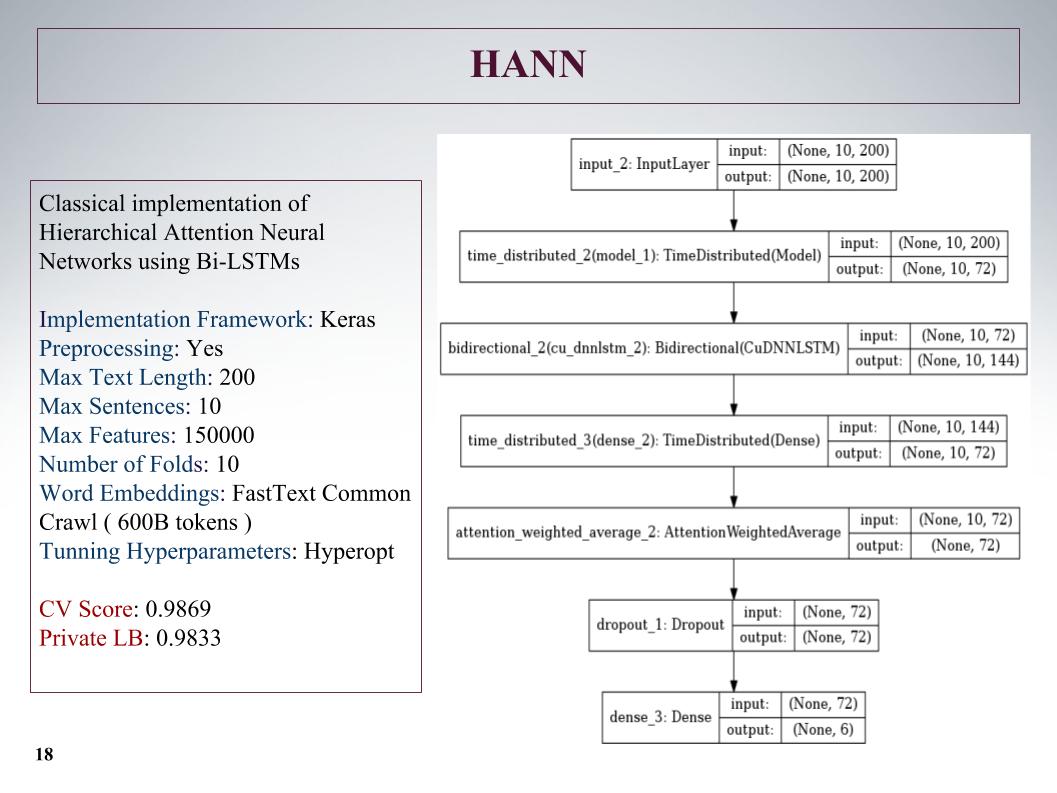
Luego hubo una atención jerárquica, mostró resultados aún peores, ya que inicialmente era una red para clasificar documentos que constaban de oraciones. Lo jodió, pero el enfoque no es muy.
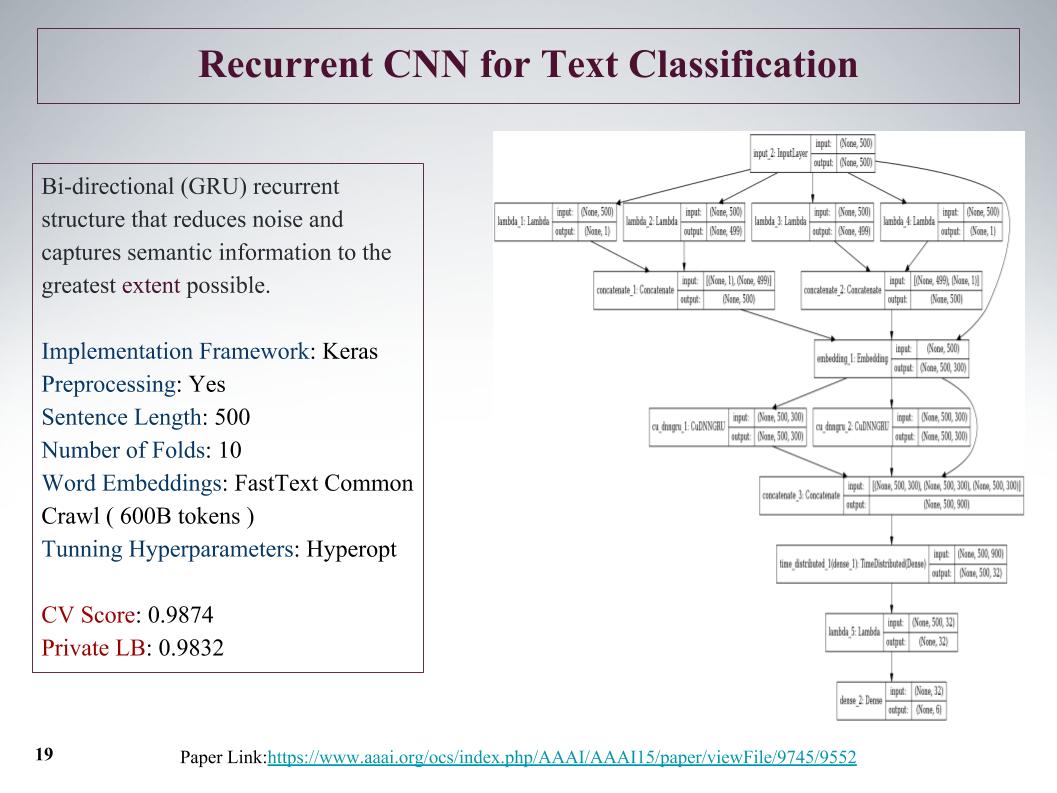
Hubo un enfoque interesante, inicialmente podemos obtener características de la oferta desde el principio y desde el final. Con la ayuda de convolución, capas convolucionales, obtenemos entidades por separado a la izquierda y a la derecha del árbol. Esto es desde el principio y el final de la oración, luego se fusionan y nuevamente pasan por gru.

También Bi-GRU con bloque de atención. Este es uno de los mejores en privado fue una red bastante profunda, mostró buenos resultados.

El siguiente enfoque es resaltar las características tanto como sea posible. Después de la capa de la red recurrente, hacemos tres capas paralelas más de convolución. Y aquí tomamos oraciones no tan largas, las redujimos a 250, pero debido a tres convoluciones esto dio un buen resultado.

Fue la red más profunda. Como dijo Atanas, solo quería enseñar algo grande e interesante. Una cuadrícula convolucional ordinaria que aprendió de las características del texto, los resultados no son nada especial.

Este es un enfoque nuevo bastante interesante, en 2017 hubo un artículo sobre este tema, se usó para ImageNet y allí nos permitió mejorar el resultado anterior en un 25%. Su característica principal es que se lanza una pequeña capa paralela al bloque convolucional, que enseña los pesos para cada convolución en este bloque. Ella dio un enfoque muy bueno, a pesar de cortar las oraciones.
El problema es que la longitud máxima de las oraciones en estas tareas alcanzó las 1.500 palabras, hubo comentarios muy grandes. Otros equipos también pensaron en cómo aprovechar esta gran oferta, cómo encontrarla, porque no todo está muy presionado. Y muchos dijeron que al final de la oración había un infante muy importante. Desafortunadamente, en todos estos enfoques, esto no se tuvo en cuenta, porque se tomó el comienzo. Quizás esto daría un aumento adicional.

Aquí está la arquitectura AC-BLSTM. La conclusión es que si la división inferior en dos partes, además de la atención, es un tirón inteligente, pero en paralelo todavía es normal, y todo esto se concreta. También buenos resultados.

Y Atanas su zoológico completo de modelos, entonces fue una mezcla genial. Además de los modelos en sí, agregué algunas características de texto, generalmente la longitud, la cantidad de letras mayúsculas, la cantidad de palabras malas, la cantidad de caracteres, todo lo demás. Validación cruzada de cinco pliegues, y obtuve excelentes resultados en LB privado 0.9867.
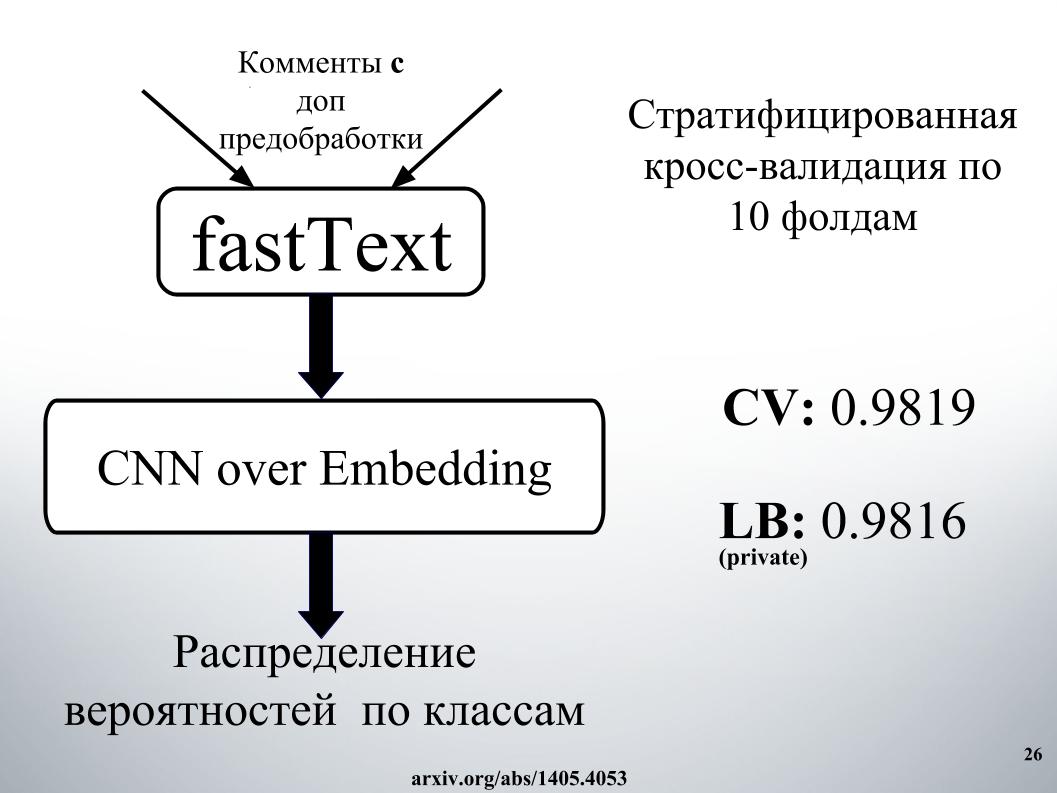
Y el segundo enfoque, enseñó con una inserción diferente, pero los resultados fueron peores. Casi todos usaban fastText.
Quería hablar sobre el enfoque de nuestro otro colega, Andrei, con el sobrenombre de Laol en ODS. Enseñó muchos granos públicos, los bebió como si estuviera fuera de sí mismo, y esto realmente arrojó resultados muy buenos. No podría hacer todo esto, pero solo tome un montón de núcleos públicos diferentes, incluso en tf-idf, hay todo tipo de convolucionistas gru.
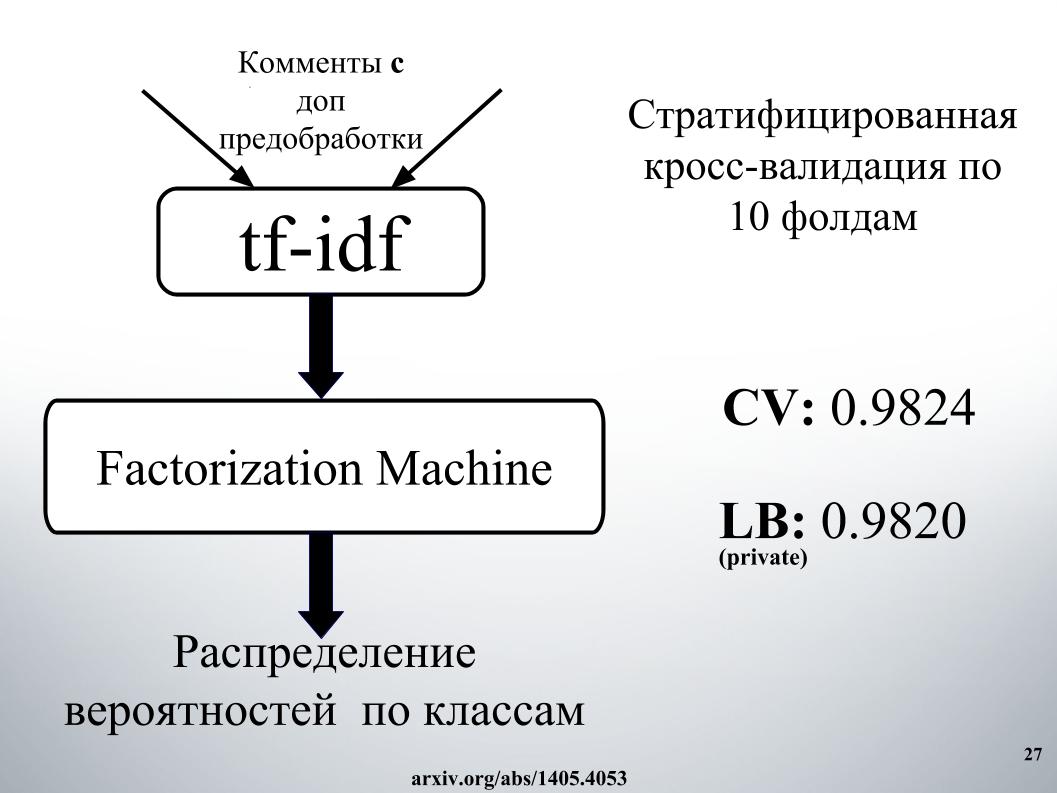
Tuvo uno de los mejores enfoques, con los que nos quedamos durante mucho tiempo en el top 15, hasta que Alexey y Atanas se unieron a nosotros, combinó la combinación y el apilamiento de todo esto. Y también un momento genial, que, según tengo entendido, que ninguno de los equipos utilizó, también hicimos funciones a partir de los resultados de la API de los organizadores. Sobre esto, dile a Alex.
Alexey Noskov:
hola Te contaré sobre el enfoque que utilicé y cómo lo completamos.

Todo fue lo suficientemente simple para mí: 10 pliegues de validación cruzada, modelos pre-entrenados en diferentes vectores con diferentes preprocesamientos, para que tuvieran más diversidad en el conjunto, un pequeño aumento y dos ciclos de desarrollo. El primero, que básicamente funcionó al principio, entrenó a un cierto número de modelos, analizó los errores de validación cruzada, en qué ejemplos comete errores obvios y corrigió el preprocesamiento basado en esto, porque es más claro cómo solucionarlos.
Y el segundo enfoque, que se usó más al final, enseñó algunos conjuntos de modelos, examinó las correlaciones, encontró bloques de modelos que están débilmente correlacionados entre sí, fortaleció la parte que consiste en ellos. Esta es la matriz de correlación de validación cruzada entre mis modelos.
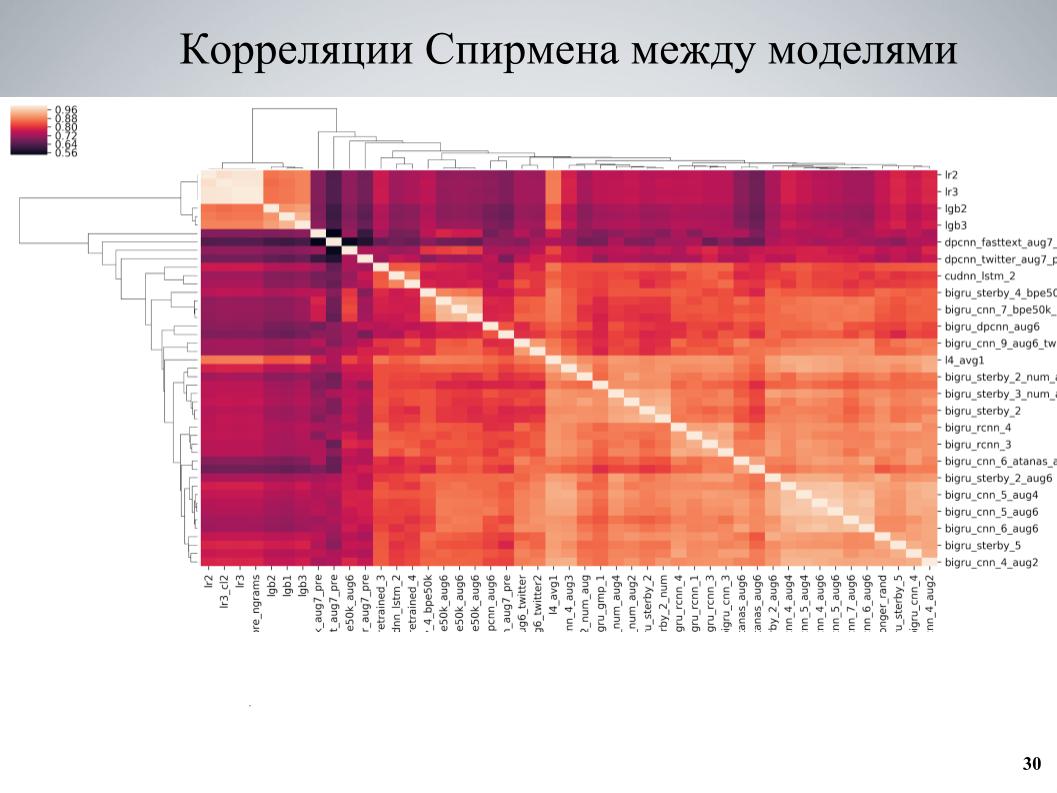
Se puede ver que tiene una estructura de bloques en algunos lugares, mientras que algunos modelos eran de buena calidad, estaban débilmente correlacionados con los demás, y se obtuvieron muy buenos resultados cuando tomé estos modelos como base, les enseñé varias variaciones diferentes que difieren en diferentes hiperparámetros o preprocesamiento, y luego se agregan al conjunto.

Para aumentar, la idea que fue publicada en el foro por Pavel Ostyakov fue la que más despertó. Consistió en el hecho de que podemos tomar un comentario, traducirlo a otro idioma y luego volver. Como resultado de la doble traducción, se obtiene una reformulación, algo se pierde un poco, pero en general se obtiene un texto similar ligeramente diferente, que también se puede clasificar y, por lo tanto, ampliar el conjunto de datos.
Y el segundo enfoque, que no ayudó tanto, pero también ayudó, es que puede intentar tomar dos comentarios arbitrarios, generalmente no muy largos, pegarlos y tomar como una etiqueta en el objetivo una combinación de etiquetas o un poco de entusiasmo donde solo hay uno de contenían una etiqueta.
Ambos enfoques funcionaron bien si no se aplicaron de antemano a todo el conjunto de conjuntos, sino para cambiar el conjunto de ejemplos a los que se debe aplicar el aumento en cada era. Cada era en el proceso de formar un lote, elegimos, digamos, el 30% de los ejemplos que se ejecutan a través de traducciones. Más bien, de antemano, en algún lugar paralelo yace en la memoria, simplemente seleccionamos la versión para la traducción basada en ella y la agregamos al lote durante su entrenamiento.

Una diferencia interesante fueron los modelos entrenados en BPE. Hay una SentencePiece, un tokenizador de Google que le permite dividirse en tokens en los que no habrá UNK en absoluto. Un diccionario limitado en el que cualquier cadena se divide en algunos tokens. Si el número de palabras en el texto real es mayor que el tamaño objetivo del diccionario, comienzan a dividirse en pedazos más pequeños, y se obtiene un enfoque intermedio entre el nivel de caracteres y los modelos de nivel de palabra.
Allí se utilizan dos algoritmos de construcción principales: BPE y Unigram. Para el algoritmo BPE, fue bastante fácil encontrar incrustaciones premarcadas en la red, y con un vocabulario fijo, solo tenía un buen vocabulario de 50k, también podía entrenar modelos que dieron bastante bien (inaudible, aprox. Ed.), Un poco peor, de lo habitual en fastText, pero se correlacionaron muy débilmente con todos los demás y dieron un buen impulso.
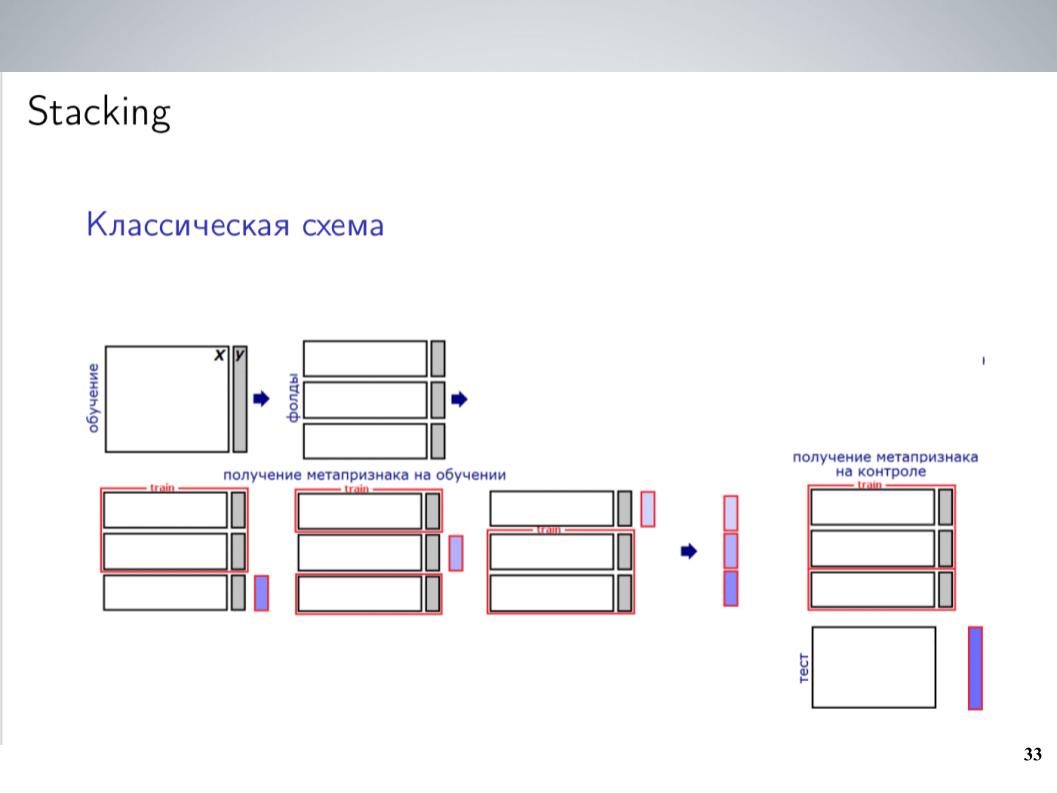
Este es un esquema de apilamiento clásico. Como regla general, durante la mayor parte de la competencia, antes de combinar, solía mezclar simplemente todos mis modelos sin pesas. Esto dio los mejores resultados. Pero después de la fusión, pude obtener un esquema un poco más complejo, que al final dio un buen impulso.

Tenía una gran cantidad de modelos. ¿Solo tirarlos a todos en algún tipo de apilador? No volvió a funcionar muy bien, volvió a entrenar, pero dado que los modelos eran grupos que estaban muy correlacionados, simplemente los uní en estos grupos, dentro de cada grupo promedié y recibí 5-7 grupos de modelos muy similares, de los cuales como características para El siguiente nivel utilizó valores promediados. Entrené a LightGBM en esto, probé 20 lanzamientos con varias muestras, cargué un poco de metafuncionalidad similar a lo que hizo Atanas, y al final finalmente comenzó a funcionar, dando un impulso sobre el promedio simple.

Sobre todo, agregué la API que Andrei encontró y que contiene un conjunto similar de etiquetas. Los organizadores construyeron modelos para ellos inicialmente. Como originalmente era diferente, los participantes no lo usaron, era imposible simplemente compararlo con los que necesitábamos predecir. Pero si se lanzó a un apilamiento que funciona bien como una meta-característica, entonces daría un impulso maravilloso, especialmente en la clase TOXIC, que, aparentemente, fue la más difícil en la tabla de clasificación, y nos permitió saltar a varios lugares al final, literalmente el último día. .

Dado que descubrimos que el apilamiento y la API funcionaron tan bien para nosotros, antes de las presentaciones finales, teníamos pocas dudas sobre qué tan bien se portaría a privado. Funcionó muy sospechosamente bien, por lo que elegimos dos presentaciones de acuerdo con el siguiente principio: uno: una combinación de modelos sin una API que se recibió antes de eso, además de apilar con metafísica de la API. Aquí resultó 0.9880 en público y 0.9874 en privado. Aquí mis marcas son confusas.

Y el segundo es una combinación de modelos sin API, sin usar apilamiento y sin usar LightGBM, porque existía el temor de que esto fuera algún tipo de reentrenamiento menor para el público, y podríamos volar con eso. Sucedió, no volaron, y como resultado, con el resultado de 0.9876 en privado obtuvimos la décima posición. Eso es todo.