Las grandes empresas y las empresas sangrientas han encontrado durante mucho tiempo un reemplazo para los rdbds adultos para DWH y análisis. DWH se está moviendo masivamente hacia DataLake y Hadoop. Parece que las pequeñas empresas ya no tienen mucho sentido lanzar análisis en un rsbd serio. Con el creciente número de núcleos disponibles incluso para pequeñas empresas, tratar de obtener una licencia de una versión completa de un subtipo para adultos como Oracle no tiene mucho sentido. Standard Edition Oracle, aunque tiene licencia para sockets, pero al mismo tiempo elimina la funcionalidad más importante. En primer lugar, en la edición estándar no hay particionamiento
, solo hay una vista de partición: el intercambio de tablas a la manera de Postgres, que solo puede ayudar en algunas situaciones. En segundo lugar, no hay un modo de espera completo, se cortan las operaciones paralelas. El clúster RAC está limitado a cuatro sockets. Como resultado, con el crecimiento de los datos modernos, rápidamente comienza a toparse con las limitaciones de la edición Standard, y el precio de licencia de la edición Enterprise hace que esta tarea no tenga sentido. En Oracle es necesario licenciar no solo el servidor de batalla, sino también el servidor en espera, mientras que la edición Enterprise tiene licencia de core. Las opciones de clúster, particionamiento y DataGuard / Standby requieren licencias separadas y también núcleo. Como resultado, incluso un servidor de nivel de entrada con 16 núcleos y que ya está en espera de licencias EE está tirando por cientos de miles de dólares, e incluso se desmaya la gestión empresarial sangrienta.
Tenemos que buscar una alternativa en Khadupov. Traté de comparar algunas solicitudes para un escaparate de datos construido sobre archivos de parquet en una copia de seguridad, con Oracle Standard en 8 núcleos xeon, marcos de 196 GB, una cierta tienda empresarial con HDD y caché SSD, que se puede revolver con varios sistemas más. La primera consulta afecta a 4 tablas, en Oracle ocuparon 62, 12, 6.5 y 3.5 GB. En una placa de más de 880 millones de líneas. En un plan de solicitud fue tal:
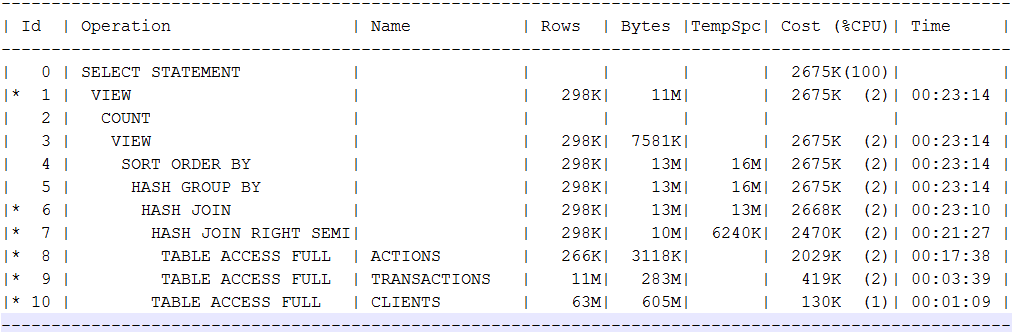
En el plan, específicamente quería ver los escaneos completos y los hashjoins que son típicos en mis consultas analíticas. En realidad, una solicitud de una edición estándar de Oracle lleva unos 7 minutos. Spark 2.3 lanzado a través de spark2-submit a 14 ejecutores con 4 núcleos / marcos de 16 GB da una respuesta a casi la misma solicitud de 10k discos HDD en un minuto. Cloudera Impala empujando con hilo y chispa en el mismo grupo (impalad en 8 nodos, recursos comparables a 14 ejecutores con 4 núcleos) da una respuesta estable en 11-12 segundos. Al mismo tiempo, Impala se ejecuta constantemente en paralelo con la carga, lo que debería lavar los datos almacenados en caché.
Los juegos con tamaño de bloque, que se trasladan a la edición Oracle EE con su paralelismo y partición para adultos probablemente habrían reducido el tiempo de ejecución varias veces, pero dudo un poco de que el tiempo sea comparable incluso con lo que obtuve en Spark. Por otro lado, solo de 3 a 4 nodos del Cloudera Hadoop prácticamente gratuito le permiten esencialmente acceder al SQL habitual, la velocidad para la que Oracle tendría un dinero incomparablemente grande.
Oracle debería pensar seriamente en la política de licencias, si los grandes fanáticos, como yo, no encuentran ninguna razón para pagar la edición Enterprise.