Me informaron que en las computadoras nuevas, algunas pruebas de regresión se hicieron más lentas. Una cosa común, sucede. Configuración incorrecta en algún lugar de Windows o no los valores más óptimos en el BIOS. Pero esta vez no pudimos encontrar la misma configuración "derribada". Como el cambio es significativo: 9 frente a 19 segundos (en la tabla, el azul es el hierro viejo y el naranja el nuevo), tuve que cavar más profundo.
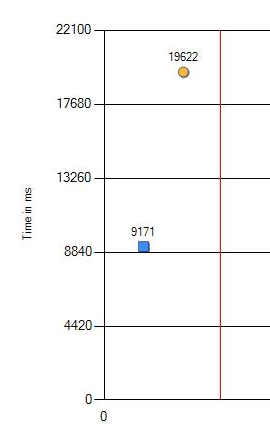
Mismo sistema operativo, mismo hardware, procesador diferente: 2 veces más lento
La caída en el rendimiento de 9.1 a 19.6 segundos definitivamente se puede llamar significativa. Realizamos comprobaciones adicionales con un cambio en las versiones de los programas probados, la configuración de Windows y BIOS. Pero no, el resultado no ha cambiado. La única diferencia apareció solo en diferentes procesadores. A continuación se muestra el resultado en la última CPU.
Y aquí está el que se usa para comparar.

Xeon Gold se ejecuta en una arquitectura diferente llamada Skylake, común a los nuevos procesadores Intel desde mediados de 2017. Si compra el hardware más reciente, obtendrá un procesador con la arquitectura Skylake. Estos son buenos autos, pero, como lo han demostrado las pruebas, la novedad y la velocidad no son lo mismo.
Si nada más ayuda, entonces necesita usar el generador de perfiles para una investigación en profundidad. Probemos en equipos viejos y nuevos y obtengamos algo como esto:
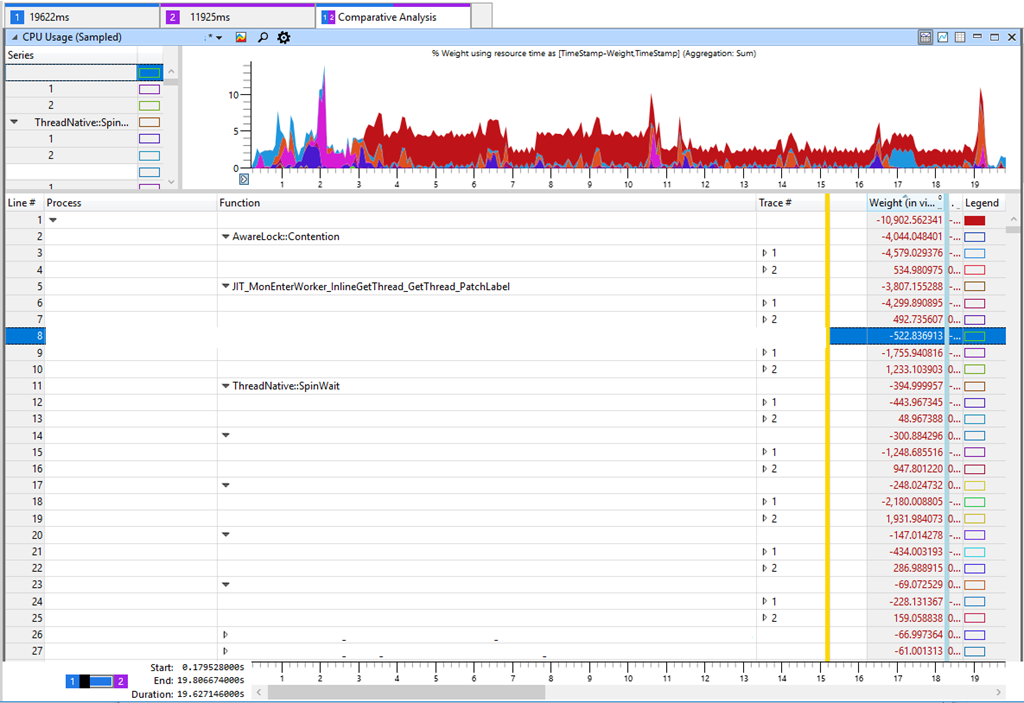
La pestaña en Windows Performance Analyzer (WPA) muestra en la tabla la diferencia entre Trace 2 (11 s) y Trace 1 (19 s). Una diferencia negativa en la tabla corresponde a un aumento en el consumo de CPU en una prueba más lenta. Si observa las diferencias más significativas en el consumo de CPU, veremos
AwareLock :: Contention ,
JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel y
ThreadNative.SpinWait . Todo indica un "giro" en la CPU [giro - un intento cíclico para obtener un bloqueo, aprox. per.], cuando los hilos luchan por el bloqueo. Pero esta es una marca falsa, porque el giro no es la razón principal de la disminución de la productividad. El aumento de la competencia por las cerraduras significa que algo en nuestro software se ha ralentizado y mantenido la cerradura, lo que como resultado condujo a un mayor giro en la CPU. Verifiqué el tiempo de bloqueo y otros indicadores clave, como el rendimiento del disco, pero no pude encontrar nada significativo que pudiera explicar la degradación del rendimiento. Aunque esto no es lógico, volví a aumentar la carga en la CPU en varios métodos.
Sería interesante encontrar exactamente dónde se atasca el procesador. WPA tiene columnas de archivos y líneas, pero solo funcionan con caracteres privados, que nosotros no tenemos, porque este es el código de .NET Framework. Lo mejor que podemos hacer es obtener la dirección dll donde se encuentra la instrucción llamada Image RVA. Si carga este dll en el depurador y hace
u xxx.dll+ImageRVAentonces deberíamos ver la instrucción que quema la mayoría de los ciclos de la CPU, porque será la única dirección "activa".
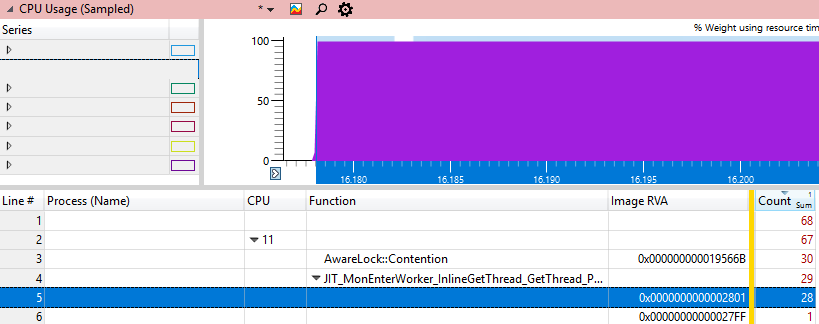
Examinaremos esta dirección utilizando varios métodos de Windbg:
0:000> u clr.dll+0x19566B-10
clr!AwareLock::Contention+0x135:
00007ff8`0535565b f00f4cc6 lock cmovl eax,esi
00007ff8`0535565f 2bf0 sub esi,eax
00007ff8`05355661 eb01 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)
00007ff8`05355663 cc int 3
00007ff8`05355664 83e801 sub eax,1
00007ff8`05355667 7405 je clr!AwareLock::Contention+0x144 (00007ff8`0535566e)
00007ff8`05355669 f390 pause
00007ff8`0535566b ebf7 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)Y con varios métodos JIT:
0:000> u clr.dll+0x2801-10
clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x124:
00007ff8`051c27f1 5e pop rsi
00007ff8`051c27f2 c3 ret
00007ff8`051c27f3 833d0679930001 cmp dword ptr [clr!g_SystemInfo+0x20 (00007ff8`05afa100)],1
00007ff8`051c27fa 7e1b jle clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x14a (00007ff8`051c2817)
00007ff8`051c27fc 418bc2 mov eax,r10d
00007ff8`051c27ff f390 pause
00007ff8`051c2801 83e801 sub eax,1
00007ff8`051c2804 75f9 jne clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x132 (00007ff8`051c27ff)Ahora tenemos una plantilla. En un caso, la dirección activa es una declaración de salto, y en el otro caso, es una resta. Pero ambas instrucciones importantes están precedidas por la misma declaración de pausa general. Diferentes métodos ejecutan la misma instrucción de procesador, que por alguna razón lleva mucho tiempo. Midamos la velocidad de ejecución de la declaración de pausa y veamos si razonamos correctamente.
Si el problema está documentado, se convierte en una característica.
| CPU | pausa en nanosegundos |
| Xeon E5 1620v3 3.5 GHz | 4 4 |
| Xeon® Gold 6126 @ 2.60 GHz | 43 |
La pausa en los nuevos procesadores Skylake toma un orden de magnitud más largo. Por supuesto, cualquier cosa puede ser más rápida y, a veces, un poco más lenta. ¿Pero
diez veces más lento? Es más como un error. Una pequeña búsqueda en Internet sobre las instrucciones de pausa conduce al
manual de Intel , que menciona explícitamente la microarquitectura Skylake y las instrucciones de pausa:

No, esto no es un error, esta es una función documentada. Incluso hay una
página que indica el tiempo de ejecución de casi todas las instrucciones del procesador.
- Puente de arena 11
- Ivy Bridege 10
- Haswell 9
- Broadwell 9
- SkylakeX 141
El número de ciclos de procesador se indica aquí. Para calcular el tiempo real, debe dividir el número de ciclos por la frecuencia del procesador (generalmente en GHz) y obtener el tiempo en nanosegundos.
Esto significa que si ejecuta aplicaciones altamente multiproceso en .NET en el último hardware, entonces pueden funcionar mucho más lentamente. Alguien ya notó esto y en agosto de 2017
registró un error . El problema se
solucionó en .NET Core 2.1 y .NET Framework 4.8 Preview.
Spin-wait mejorado en varias primitivas de sincronización para un mejor rendimiento en Intel Skylake y microarquitecturas posteriores. [495945, mscorlib.dll, error]
Pero dado que aún falta un año para el lanzamiento de .NET 4.8, solicité que las soluciones se respalden para que .NET 4.7.2 vuelva a la velocidad normal en los nuevos procesadores. Como hay bloqueos mutuamente excluyentes (spinlocks) en muchas partes de .NET, debe realizar un seguimiento del aumento de la carga de la CPU cuando funcionan Thread.SpinWait y otros métodos de spinning.

Por ejemplo, Task.Result usa internamente spinning, por lo que anticipo un aumento significativo en la carga de la CPU y un menor rendimiento en otras pruebas.
Que tan malo es
Miré el código .NET Core durante cuánto tiempo el procesador continuará girando si no se libera el bloqueo antes de llamar a WaitForSingleObject para pagar el cambio de contexto "costoso". Un cambio de contexto lleva a un microsegundo o mucho más si muchos hilos esperan el mismo objeto del núcleo.
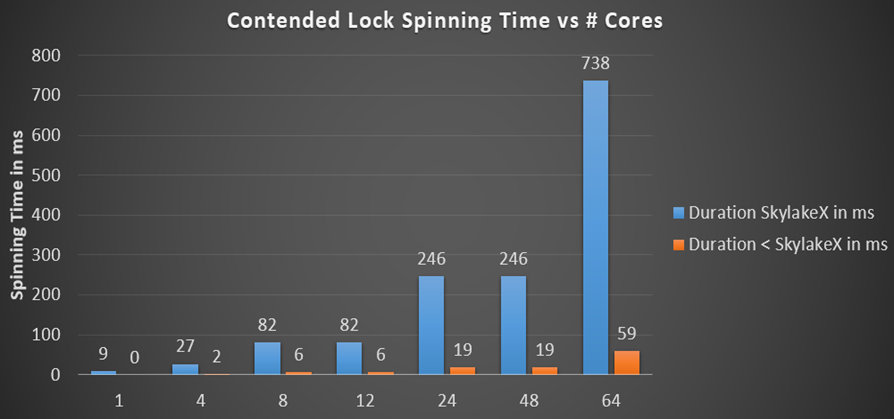
Los bloqueos .NET multiplican la duración máxima de giro por el número de núcleos, si tomamos el caso absoluto de que el hilo en cada núcleo espera el mismo bloqueo y el giro continúa el tiempo suficiente para que todos trabajen un poco antes de pagar la llamada del núcleo. Girar en .NET usa un algoritmo de envejecimiento exponencial cuando comienza con un ciclo de 50 llamadas de pausa, donde cada número de vueltas se triplica hasta que el siguiente contador de vueltas excede su duración máxima. Calculé la duración total del giro por procesador para varios procesadores y un número diferente de núcleos:
A continuación se muestra el código de giro simplificado en .NET Locks:
/// <summary> /// This is how .NET is spinning during lock contention minus the Lock taking/SwitchToThread/Sleep calls /// </summary> /// <param name="nCores"></param> void Spin(int nCores) { const int dwRepetitions = 10; const int dwInitialDuration = 0x32; const int dwBackOffFactor = 3; int dwMaximumDuration = 20 * 1000 * nCores; for (int i = 0; i < dwRepetitions; i++) { int duration = dwInitialDuration; do { for (int k = 0; k < duration; k++) { Call_PAUSE(); } duration *= dwBackOffFactor; } while (duration < dwMaximumDuration); } }
Anteriormente, el tiempo de rotación estaba en el intervalo de milisegundos (19 ms para 24 núcleos), que ya es mucho en comparación con el tiempo de cambio de contexto mencionado anteriormente, que es un orden de magnitud más rápido. Pero en los procesadores Skylake, el tiempo de rotación total para el procesador simplemente explota hasta 246 ms en una máquina de 24 o 48 núcleos, simplemente porque la instrucción de pausa se ralentizó 14 veces. ¿Es esto realmente así? Escribí un pequeño probador para verificar el giro general en la CPU, y los números calculados están en línea con las expectativas. Aquí hay 48 subprocesos en una CPU de 24 núcleos que esperan un bloqueo, al que llamé Monitor.PulseAll:
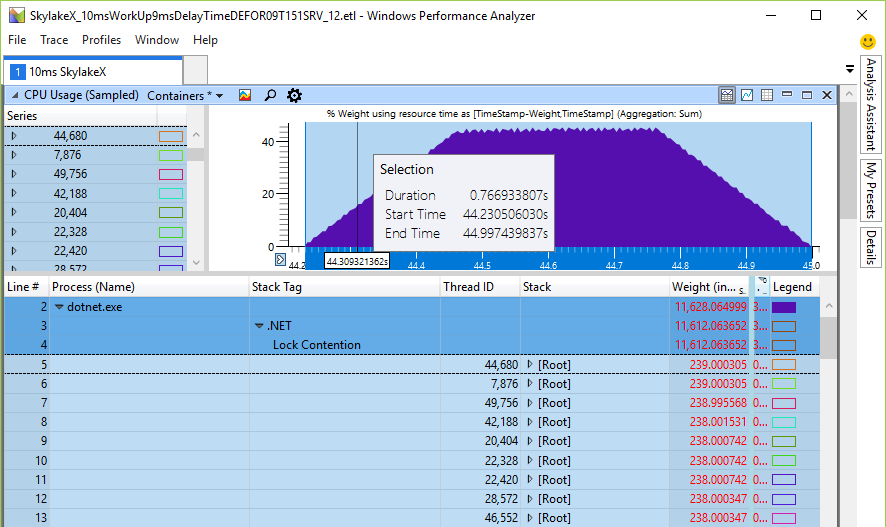
Solo un hilo ganará la carrera, pero 47 continuará girando hasta que pierdan la frecuencia cardíaca. Esta es una evidencia experimental de que realmente tenemos un problema de carga de CPU y que el giro muy largo es real. Socava la escalabilidad, porque estos ciclos van en lugar del trabajo útil de otros subprocesos, aunque la instrucción de pausa libera algunos de los recursos compartidos de la CPU, lo que proporciona un sueño durante más tiempo. La razón para girar es un intento de obtener un bloqueo más rápido sin acceder al núcleo. Si es así, aumentar la carga en la CPU sería solo nominal, pero no afectaría en absoluto el rendimiento, porque los núcleos se dedican a otras tareas. Pero las pruebas mostraron una disminución en el rendimiento en operaciones de un solo subproceso, donde un subproceso agrega algo a la cola de trabajo, mientras que el subproceso de trabajo espera un resultado y luego realiza una determinada tarea con el elemento de trabajo.
La razón es más fácil de mostrar en el diagrama. El giro adversario se produce con un triple de giro en cada paso. Después de cada ronda, el bloqueo se verifica nuevamente para ver si el hilo actual puede recibirlo. Aunque spinning trata de ser honesto y cambia de vez en cuando a otros hilos para ayudarlos a completar su trabajo. Esto aumenta las posibilidades de liberar el bloqueo en la próxima comprobación. El problema es que la comprobación de una toma solo es posible al final de una vuelta completa:

Por ejemplo, si al comienzo de la quinta vuelta, una cerradura indica disponibilidad, solo puede tomarla al final de la vuelta. Habiendo calculado la duración del giro de la última ronda, podemos estimar el peor caso de retraso para nuestro flujo:

Muchos milisegundos de espera hasta que finalice el giro. ¿Es esto un problema real?
Creé una aplicación de prueba simple que implementa una cola de fabricantes de consumidores, donde el flujo de trabajo realiza cada elemento de trabajo durante 10 ms, y el consumidor tiene un retraso de 1-9 ms antes del siguiente elemento de trabajo. Esto es suficiente para ver el efecto:
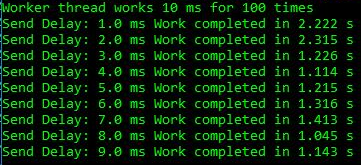
Vemos retrasos de 1-2 ms, la duración total es de 2.2-2.3 s, mientras que en otros casos el trabajo es más rápido hasta 1.2 s. Esto muestra que el giro excesivo en la CPU no es solo un problema cosmético en aplicaciones sobreenhebradas. Realmente daña el simple subproceso del productor-consumidor, que incluye solo dos subprocesos. Para la ejecución anterior, los datos de ETW hablan por sí mismos: es el aumento en el giro que causa el retraso observado:
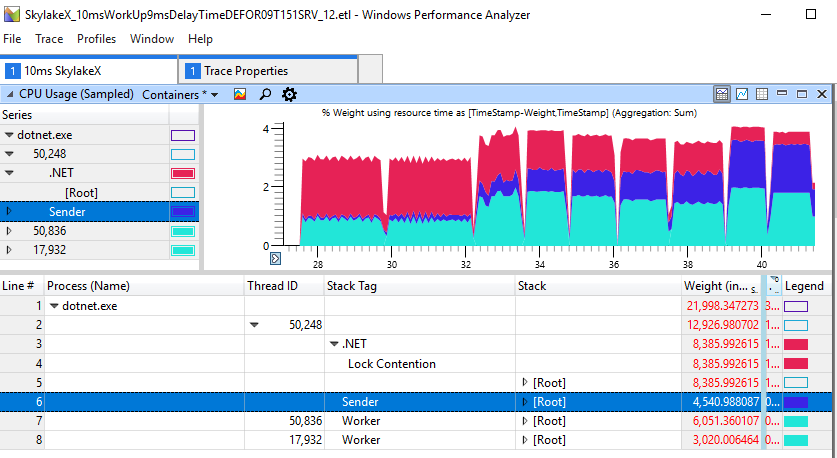
Si observa cuidadosamente la sección con "frenos", veremos 11 ms de giro en el área roja, aunque el trabajador (azul claro) ha completado su trabajo y ha dado la cerradura hace mucho tiempo.
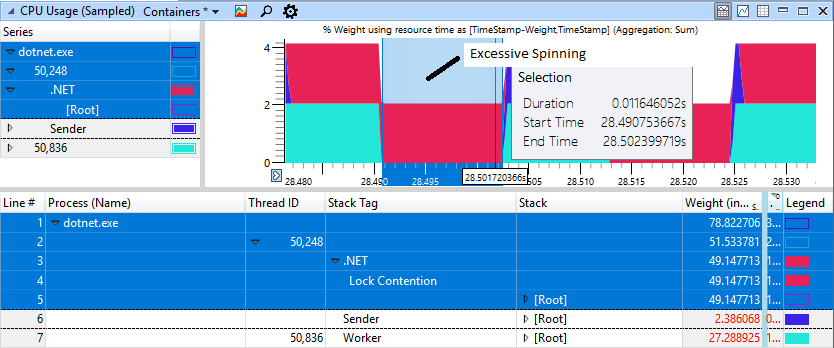
Un caso rápido no degenerativo se ve mucho mejor, aquí solo se gasta 1 ms en girar para bloquear.
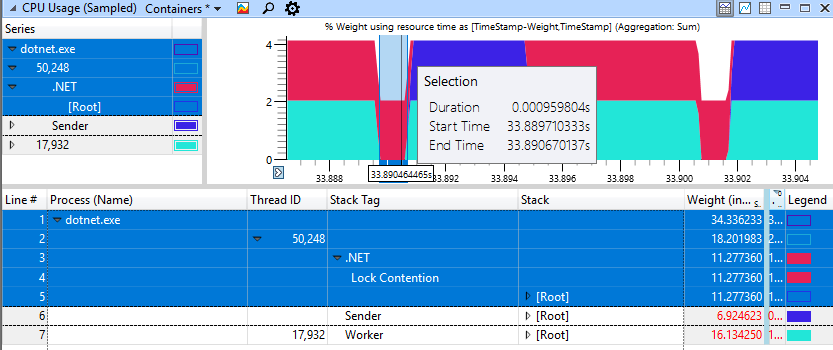 Usé la
Usé la aplicación de prueba
SkylakeXPause . El
archivo zip contiene código fuente y binarios para .NET Core y .NET 4.5. A modo de comparación, instalé .NET 4.8 Preview con correcciones y .NET Core 2.0, que aún implementa el comportamiento anterior. La aplicación está diseñada para .NET Standard 2.0 y .NET 4.5, produciendo tanto exe como dll. Ahora puede comprobar el comportamiento de giro antiguo y nuevo lado a lado sin la necesidad de arreglar nada, es muy conveniente.
readonly object _LockObject = new object(); int WorkItems; int CompletedWorkItems; Barrier SyncPoint; void RunSlowTest() { const int processingTimeinMs = 10; const int WorkItemsToSend = 100; Console.WriteLine($"Worker thread works {processingTimeinMs} ms for {WorkItemsToSend} times"); // Test one sender one receiver thread with different timings when the sender wakes up again // to send the next work item // synchronize worker and sender. Ensure that worker starts first double[] sendDelayTimes = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; foreach (var sendDelay in sendDelayTimes) { SyncPoint = new Barrier(2); // one sender one receiver var sw = Stopwatch.StartNew(); Parallel.Invoke(() => Sender(workItems: WorkItemsToSend, delayInMs: sendDelay), () => Worker(maxWorkItemsToWork: WorkItemsToSend, workItemProcessTimeInMs: processingTimeinMs)); sw.Stop(); Console.WriteLine($"Send Delay: {sendDelay:F1} ms Work completed in {sw.Elapsed.TotalSeconds:F3} s"); Thread.Sleep(100); // show some gap in ETW data so we can differentiate the test runs } } /// <summary> /// Simulate a worker thread which consumes CPU which is triggered by the Sender thread /// </summary> void Worker(int maxWorkItemsToWork, double workItemProcessTimeInMs) { SyncPoint.SignalAndWait(); while (CompletedWorkItems != maxWorkItemsToWork) { lock (_LockObject) { if (WorkItems == 0) { Monitor.Wait(_LockObject); // wait for work } for (int i = 0; i < WorkItems; i++) { CompletedWorkItems++; SimulateWork(workItemProcessTimeInMs); // consume CPU under this lock } WorkItems = 0; } } } /// <summary> /// Insert work for the Worker thread under a lock and wake up the worker thread n times /// </summary> void Sender(int workItems, double delayInMs) { CompletedWorkItems = 0; // delete previous work SyncPoint.SignalAndWait(); for (int i = 0; i < workItems; i++) { lock (_LockObject) { WorkItems++; Monitor.PulseAll(_LockObject); } SimulateWork(delayInMs); } }
Conclusiones
Este no es un problema .NET. Todas las implementaciones de spinlock que usan la declaración de pausa se ven afectadas. Revisé rápidamente el núcleo de Windows Server 2016, pero no existe tal problema en la superficie. Parece que Intel fue lo suficientemente amable e insinuó que se necesitan algunos cambios en el enfoque del giro.
Se informó un error para .NET Core en agosto de 2017, y en septiembre de 2017 se lanzó
un parche y una versión de .NET Core 2.0.3. El enlace muestra no solo la excelente reacción del grupo .NET Core, sino también el hecho de que hace unos días el problema se solucionó en la rama principal, así como una discusión sobre optimizaciones de giro adicionales. Desafortunadamente, Desktop .NET Framework no se está moviendo tan rápido, pero frente a .NET Framework 4.8 Preview, tenemos al menos pruebas conceptuales de que las correcciones allí también son implementables. Ahora estoy esperando el backport para .NET 4.7.2 para usar .NET a toda velocidad y en el último hardware. Este es el primer error que encontré que está directamente relacionado con los cambios de rendimiento debido a una instrucción de la CPU. ETW sigue siendo el principal generador de perfiles en Windows. Si pudiera, le pediría a Microsoft que porte la infraestructura ETW a Linux, porque los perfiladores de Linux actuales todavía son una mierda. Recientemente agregaron características interesantes del kernel, pero todavía no hay herramientas de análisis como WPA.
Si está trabajando con .NET Core 2.0 o el .NET Framework de escritorio en los últimos procesadores que se han lanzado desde mediados de 2017, en caso de problemas con la degradación del rendimiento, definitivamente debe verificar sus aplicaciones con un generador de perfiles y actualizar a .NET Core y, con suerte, pronto Escritorio .NET Mi aplicación de prueba le informará sobre la presencia o ausencia de un problema.
D:\SkylakeXPause\bin\Release\netcoreapp2.0>dotnet SkylakeXPause.dll -check
Did call pause 1,000,000 in 3.5990 ms, Processors: 8
No SkylakeX problem detectedo
D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>SkylakeXPause.exe -check
Did call pause 1,000,000 in 3.6195 ms, Processors: 8
No SkylakeX problem detectedLa herramienta informará un problema si está trabajando en .NET Framework sin la actualización adecuada y en el procesador Skylake.
Espero que hayas encontrado la investigación de este problema tan emocionante como yo. Para comprender realmente el problema, debe crear un medio para reproducirlo que le permita experimentar y buscar factores influyentes. El resto es solo un trabajo aburrido, pero ahora soy mucho mejor para comprender las causas y consecuencias de un intento cíclico de bloquear la CPU.