
En marzo, nuestro equipo de desarrollo con el orgulloso nombre de "Hands-Auki" luchó con vigilia durante dos días en los campos digitales del hackathon AI.HACK. En total, se propusieron cinco tareas de diferentes empresas. Nos centramos en la tarea de Gazpromneft: pronosticar la demanda de combustible de los clientes B2B. Según datos anónimos, era necesario aprender a predecir cuánto comprará un cliente en particular en el futuro, de acuerdo con la región de compra de combustible, el número de combustible, el tipo de combustible, el precio, la fecha y la identificación del cliente. Mirando hacia el futuro: nuestro equipo resolvió este problema con la mayor precisión. Los clientes se dividieron en tres segmentos: grande, mediano y pequeño. Y además de la tarea principal, también elaboramos un pronóstico del consumo total para cada uno de los segmentos.
La descarga contenía datos sobre compras de clientes para el período comprendido entre noviembre de 2016 y el 15 de marzo de 2018 (para el período comprendido entre el 1 de enero de 2018 y el 15 de marzo de 2018, los datos NO incluyeron volúmenes).
Datos de muestra:
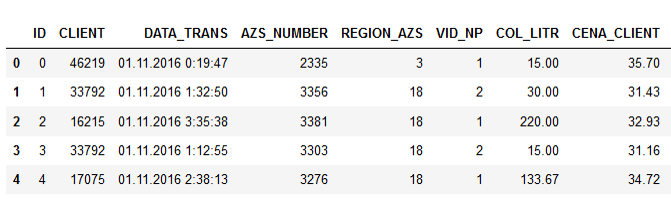
Los nombres de las columnas hablan por sí mismos, creo que no tiene sentido explicarlo.
Además de la muestra de capacitación, los organizadores proporcionaron una muestra de prueba durante tres meses de este año. Los precios son para clientes corporativos, teniendo en cuenta descuentos específicos, que dependen del consumo de un cliente en particular, de ofertas especiales y otros puntos.
Después de recibir los datos iniciales, nosotros, como todos los demás, comenzamos a probar los métodos clásicos de aprendizaje automático, tratando de construir un modelo adecuado, para sentir la correlación de algunos signos. Intentamos extraer características adicionales, construimos modelos de regresión (XGBoost, CatBoost, etc.).
La declaración del problema en sí inicialmente implicaba que el precio del combustible influye de alguna manera en la demanda, y es necesario comprender con mayor precisión esta dependencia. Pero cuando comenzamos a analizar los datos proporcionados, vimos que la demanda no se correlaciona con el precio.

Correlación de signos:
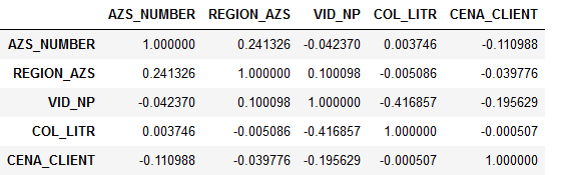
Resultó que la cantidad de litros prácticamente no depende del precio. Esto se explicó de manera bastante lógica. El conductor va por la carretera, necesita repostar. Tiene una opción: cargar combustible en una estación de servicio con la que coopera la compañía o en alguna otra. Pero al conductor no le importa cuánto cuesta el combustible: la organización lo paga. Por lo tanto, simplemente se apaga a la estación de servicio más cercana y llena el tanque.
Sin embargo, a pesar de todos los esfuerzos y modelos probados, no fue posible lograr la precisión de pronóstico mínima aceptable (línea de base), que se calculó utilizando esta fórmula (error de porcentaje absoluto simétrico medio):
Probamos todas las opciones, nada funcionó. Y luego se nos ocurrió escupir en el aprendizaje automático y recurrir a las viejas estadísticas: simplemente tome el valor promedio para el tipo de combustible, valide y vea qué precisión obtiene.
Entonces, primero excedimos el valor umbral.
Comenzamos a pensar cómo mejorar el resultado. Intentamos tomar valores medios por grupos de clientes, tipos de combustible, regiones y números de estaciones de servicio. El problema era que en los datos de la prueba faltaba aproximadamente el 30% de las ID de clientes que estaban en la muestra de capacitación. Es decir, aparecieron nuevos clientes en la prueba. Esto fue un error que los organizadores no verificaron. Pero tuvimos que resolver el problema nosotros mismos. No conocíamos el consumo de nuevos clientes y, por lo tanto, no pudimos hacer pronósticos para ellos. Y aquí el aprendizaje automático simplemente ayudó.
En la primera etapa, los datos faltantes se completaron con el valor promedio o mediano de toda la muestra. Y luego surgió la idea: ¿por qué no crear nuevos perfiles de clientes basados en datos existentes? Tenemos recortes por región, cuántos clientes compran combustible allí, con qué frecuencia, qué tipos. Agrupamos clientes existentes, compilamos perfiles específicos para diferentes regiones y capacitamos a XGBoost en ellos, que luego "completaron" los perfiles de nuevos clientes.
Esto nos permitió entrar en primer lugar. Todavía quedaban tres horas antes de resumir los resultados. Estábamos encantados y comenzamos a resolver el problema de la bonificación: pronósticos por segmentos con tres meses de anticipación.
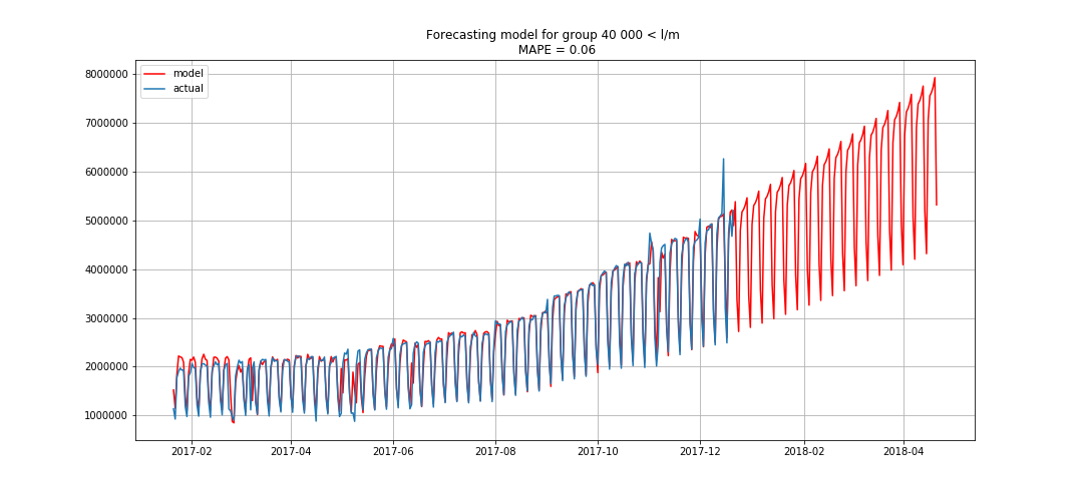
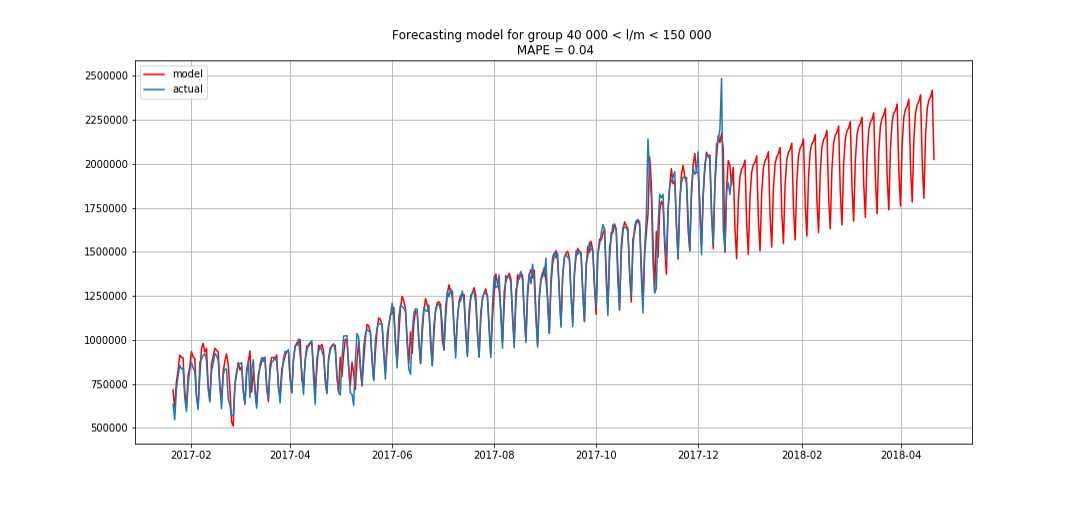
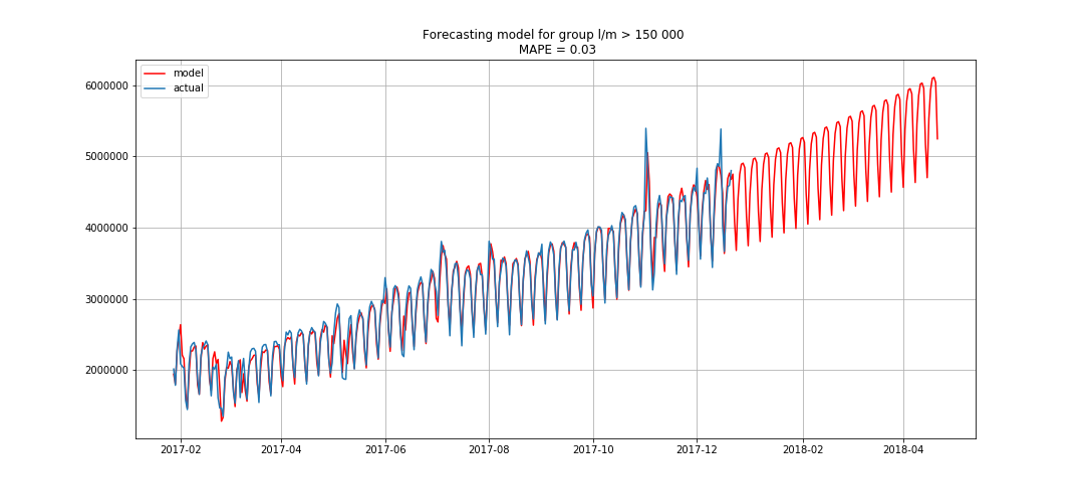
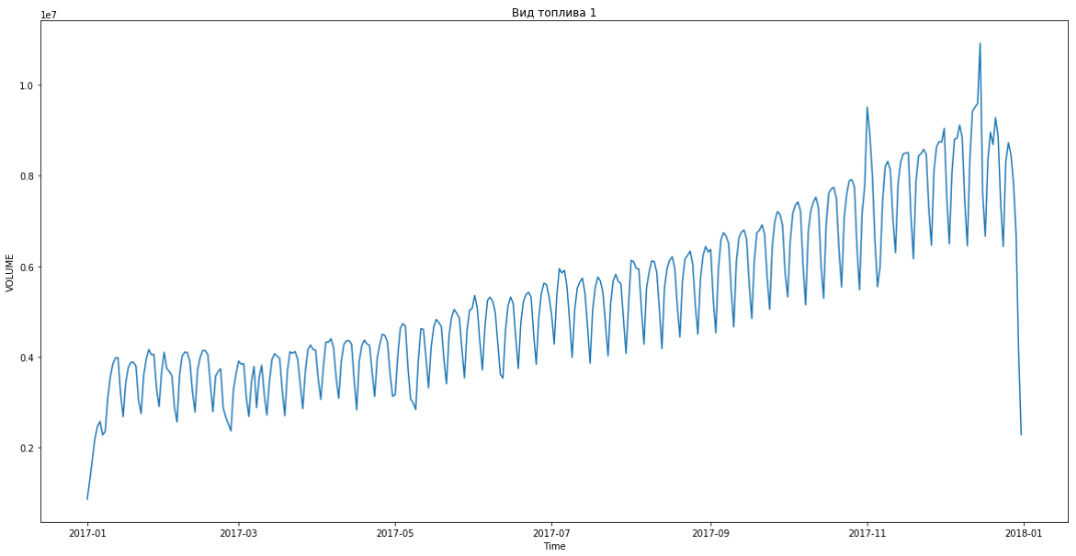
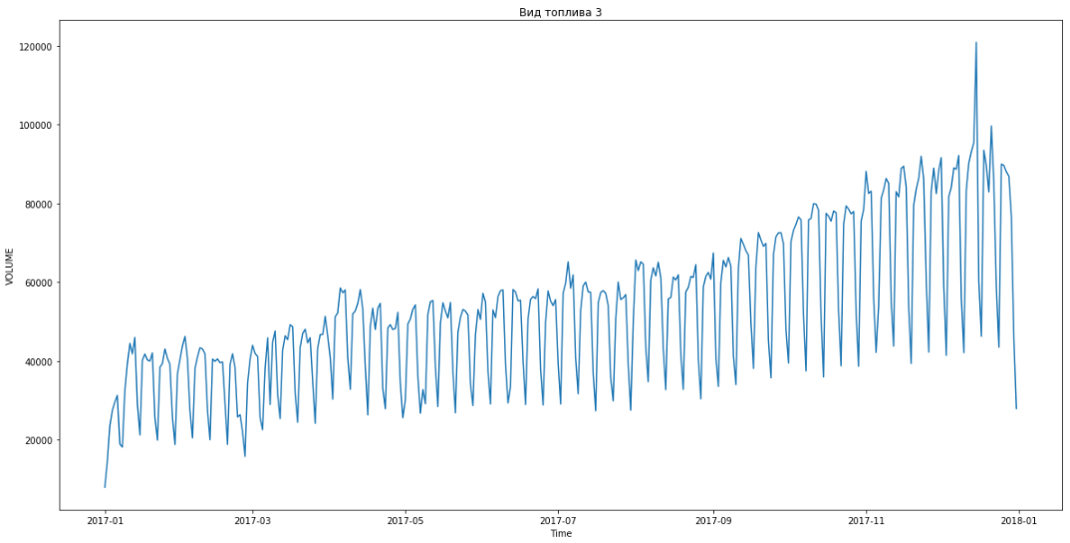
Azul muestra datos reales, rojo - pronóstico. El error varió de 3% a 6%. Podría calcularse con mayor precisión, por ejemplo, teniendo en cuenta los picos estacionales y las vacaciones.
Mientras hacíamos esto, un equipo comenzó a ponerse al día con nosotros, mejorando nuestro resultado cada 15-20 minutos. Nosotros también comenzamos a preocuparnos y decidimos hacer algo en caso de que nos alcancen.
Comenzaron a hacer otro modelo en paralelo, que clasificaba las estadísticas por grado de importancia, su precisión era ligeramente inferior a la del primero. Y cuando los competidores nos vencieron, intentamos combinar ambos modelos. Esto nos dio un ligero aumento en la métrica: hasta el 37,24671%, como resultado, recuperamos nuestro primer lugar y lo mantuvimos hasta el final.
Para la victoria, nuestro equipo Ruki-Auki recibió un certificado por 100 mil rublos, honor, respeto y ... lleno de autoestima, ¡fui al spa! ;)
Equipo de desarrollo de Jet Infosystems