Más recientemente, buscamos un científico de datos en el equipo (y encontramos: ¡hola,
nik_son y Arseny!). Mientras hablamos con los candidatos, nos dimos cuenta de que muchas personas quieren cambiar sus trabajos porque están haciendo algo "en la mesa".
Por ejemplo, asumen el pronóstico complejo que propuso el jefe, pero el proyecto se detiene porque la empresa no comprende qué y cómo incluir en la producción, cómo obtener ganancias, cómo "recuperar" los recursos gastados en el nuevo modelo.

HeadHunter no tiene una gran potencia informática, como Yandex o Google. Entendemos lo difícil que es poner ML complejo en producción. Por lo tanto, muchas compañías piensan en el hecho de que los modelos lineales más simples se están introduciendo en la producción.
En el proceso de la próxima implementación de ML en el sistema de recomendación y en la búsqueda de vacantes, encontramos una serie de "rastrillos" clásicos. Preste atención a ellos si tiene la intención de implementar ML en casa: tal vez esta lista lo ayudará a no seguirlos
y encontrar su propio rastrillo personal .
Rastrillo No. 1: Científico de datos - Artista libre
En cada empresa que comienza a introducir el aprendizaje automático, incluidas las redes neuronales, en su trabajo, existe una brecha entre lo que el científico de datos quiere hacer y lo que beneficia a la producción. Incluso porque el negocio no siempre puede explicar qué beneficio es y cómo puede ayudar.
Nos ocupamos de esto de la siguiente manera: discutimos todas las ideas emergentes, pero solo implementamos lo que beneficiará a la empresa, ahora o en el futuro. No investigamos en el vacío.
Después de cada implementación o experimento, consideramos la calidad, los recursos y los efectos económicos y actualizamos nuestros planes.
Rastrillo número 2: actualización de bibliotecas
Este problema ocurre en muchos. Aparecen muchas bibliotecas nuevas y convenientes de las que nadie había oído hablar hace un par de años, o ninguna. Me gustaría usar las últimas bibliotecas, porque son más convenientes.
Pero hay varios obstáculos:
1. Si el producto usa, por ejemplo, el decimocuarto Ubuntu, lo más probable es que simplemente no haya nuevas bibliotecas en él. La solución es transferir el servicio a Docker e instalar las bibliotecas de Python usando pip (en lugar de paquetes deb).
2. Si se utiliza un formato dependiente del código para el almacenamiento de datos (como pickle), esto congela las bibliotecas utilizadas. Es decir, cuando el modelo de aprendizaje automático se obtuvo utilizando la biblioteca scikit-learn versión 15 y se guardó en formato pickle, entonces para la recuperación correcta del modelo, se necesitará la biblioteca de quince versiones scikit-learn. No puede actualizar a la última versión, y esta es una trampa mucho más insidiosa que la descrita en el párrafo 1.
Hay dos formas de salir de esto:
- Utilice un formato independiente del código para almacenar modelos.
- Siempre podrá volver a entrenar cualquier modelo. Luego, al actualizar la biblioteca, será necesario entrenar todos los modelos y guardarlos con la nueva versión de la biblioteca.
Hemos elegido el segundo camino.
Rastrillo número 3: trabajar con modelos antiguos
Hacer algo nuevo en un modelo antiguo y aprendido es menos útil que hacer algo simple en uno nuevo. A menudo, al final resulta que la introducción de modelos más simples pero más frescos es más útil, y la cantidad de esfuerzo es menor. Es importante recordar esto y siempre tener en cuenta la cantidad de esfuerzos comunes en la búsqueda de patrones.
Rastrillo número 4: solo experimentos locales
A muchos expertos en ciencia de datos les gusta experimentar localmente en sus servidores de aprendizaje automático. Solo los productos no tienen tanta flexibilidad: como resultado, se revelan muchas razones por las cuales es imposible arrastrar estos experimentos a la producción.
Es importante configurar la comunicación entre el especialista de DS y los ingenieros de ventas para una comprensión común: cómo funcionará este o aquel modelo en la producción, si existe la potencia y la capacidad física necesarias para implementarlo. Además, cuanto más complejos son los modelos y los factores, más difícil es hacerlos confiables y poder capacitarlos nuevamente en cualquier momento. A diferencia de las competencias de Kaggle, en la producción a menudo es mejor sacrificar diez milésimas en métricas locales e incluso un pequeño KPI en línea, pero implementar la versión de modelos es mucho más simple, estable en resultados y fácil en recursos informáticos.
La copropiedad del código (los desarrolladores y los científicos de datos saben cómo funciona el código escrito por otros desarrolladores), la reutilización de signos y metaatributos en varios modelos tanto en el proceso de aprendizaje como cuando se trabaja en productos (nos ayuda us framework), unit-and autotests, que manejamos muy a menudo, integración de código con retesting. Ponemos los modelos finales en repositorios git y también los usamos en producción.
Rastrillo número 5: prueba solo prod
Cada uno de nuestros desarrolladores y científicos de datos tiene su propio banco de pruebas, a veces no uno. Los componentes principales de la producción HH se implementan en él. Es costoso, pero paga por la calidad y la velocidad de desarrollo. Es necesario, pero no suficiente. No solo cargamos los modelos que ya están en producción, sino también los que estarán allí pronto. Esto ayuda a comprender a tiempo que los modelos que funcionan perfectamente en máquinas locales, bancos de prueba o en producción para el 5% de los usuarios, y cuando se encienden al 100%, son demasiado pesados.
Usamos varias etapas de prueba. Verificamos el código muy rápidamente (este es el punto clave): al agregar o cambiar componentes en el repositorio, el código se recopila, la unidad y las pruebas automáticas se ejecutan en los componentes correspondientes, si es necesario, también los volvemos a probar manualmente, y si algo está mal, responda "El tuyo está roto, decide."
Rastrillo número 6: cálculos largos y pérdida de enfoque
Si un modelo requiere, por ejemplo, una semana para entrenar, es fácil perder la concentración en la tarea debido al cambio a otro proyecto. Intentamos no dar a los desarrolladores y científicos de datos más de dos tareas en una mano. Y no más de uno urgente para que pueda cambiar a él tan pronto como se completen los cálculos o experimentos A / B. Esta regla es necesaria para no perder el enfoque y por temor a que algunas de estas tareas generalmente corran el riesgo de perderse, y otra parte que se implementa mucho más tarde de lo necesario.
Pisamos un rastrillo pero no nos rendimos
Recientemente completamos un experimento sobre la introducción de redes neuronales en un sistema de recomendación. Comenzó con el hecho de que en dos días el hackathon interno escribió un modelo para pronosticar las respuestas por currículum, lo que facilitó enormemente la búsqueda de vacantes adecuadas.
Pero más tarde aprendimos: para ponerlo en producción, debe actualizar casi todo, por ejemplo, transferir el sistema de doble uso, que considera signos y enseña modelos, a Docker, así como actualizar las bibliotecas de aprendizaje automático.
Como fue
Utilizamos el modelo DSSM con una red neuronal de una sola capa. En el artículo original de Microsoft, se utilizó una red neuronal de tres capas, pero no observamos mejoras de calidad con un aumento en el número de capas, por lo que nos decidimos por una capa.

En resumen:
- El texto de la consulta y el encabezado de la vacante se convierten en dos vectores trigrama de símbolos. Usamos 20,000 trigramas de caracteres.
- El vector trigrama se alimenta a la entrada de una red neuronal de capa única. En la entrada de la capa de red neuronal, hay 20,000 números, en la salida, 64. Esencialmente, la red neuronal es una matriz de 20,000 x 64 por la cual se multiplica el vector trigrama de entrada de dimensión 1 x 20 000. Se agrega un vector constante de dimensión 1 x 64 al resultado de multiplicación. La salida de dicha red neuronal corresponde a la solicitud (o el título de la vacante).
- Se calcula el producto escalar del vector dssm de consulta y el vector dssm del encabezado de vacante. La función sigmoidea se aplica al trabajo. El resultado final es el meta-signo dssm.
Cuando intentamos incluir este modelo por primera vez, las métricas locales mejoraron, pero cuando intentamos incluirlo en la prueba A / B, vimos que no había ninguna mejora.
Después de eso, tratamos de aumentar la segunda capa de neuronas a 256, desplegada por el 5% de los usuarios: resultó que el sistema de recomendación y la búsqueda mejoraron, pero cuando activó el modelo al 100%, de repente resultó que era demasiado pesado.
Analizamos por qué el modelo es tan pesado, eliminamos la derivación y volvimos a experimentar con esta red neuronal. Y solo después de eso, habiendo recorrido todo el camino nuevamente, descubrieron que el modelo es útil: el número de respuestas en el sistema de recomendaciones aumentó en 700 por día, y en la búsqueda, después de todos los recuentos, en 4200.
La introducción de una red neuronal tan poco compleja permite a nuestros clientes contratar a varias docenas de empleados adicionales todos los días a través de hh.ru, y durante la implementación hemos derrotado a una parte importante de los grandes problemas. Por lo tanto, planeamos desarrollar nuestras redes neuronales aún más. Los planes son intentar la derivación general, la lematización adicional, procesar los textos completos de la vacante y reanudar, realizar experimentos con la topología (capas ocultas y, posiblemente, RNN / LSTM).
Lo más importante que hemos hecho con este modelo:
- No deje caer el experimento en el medio.
- Calculamos los indicadores de aumento de la respuesta y descubrimos que el trabajo en este modelo valió la pena. Es muy importante comprender cuánto beneficio aporta cada implementación.
Curiosamente, el modelo que hicimos y finalmente agregamos al producto es muy similar al método del componente principal (PCA) aplicado a la matriz [texto de la consulta, título del documento, si hubo un clic]. Es decir, a una matriz en la que una fila corresponde a una consulta única, una columna a un encabezado de vacante único; el valor en la celda es 1 si después de esta solicitud el usuario hizo clic en una vacante con este encabezado y 0 si no hubo clic.
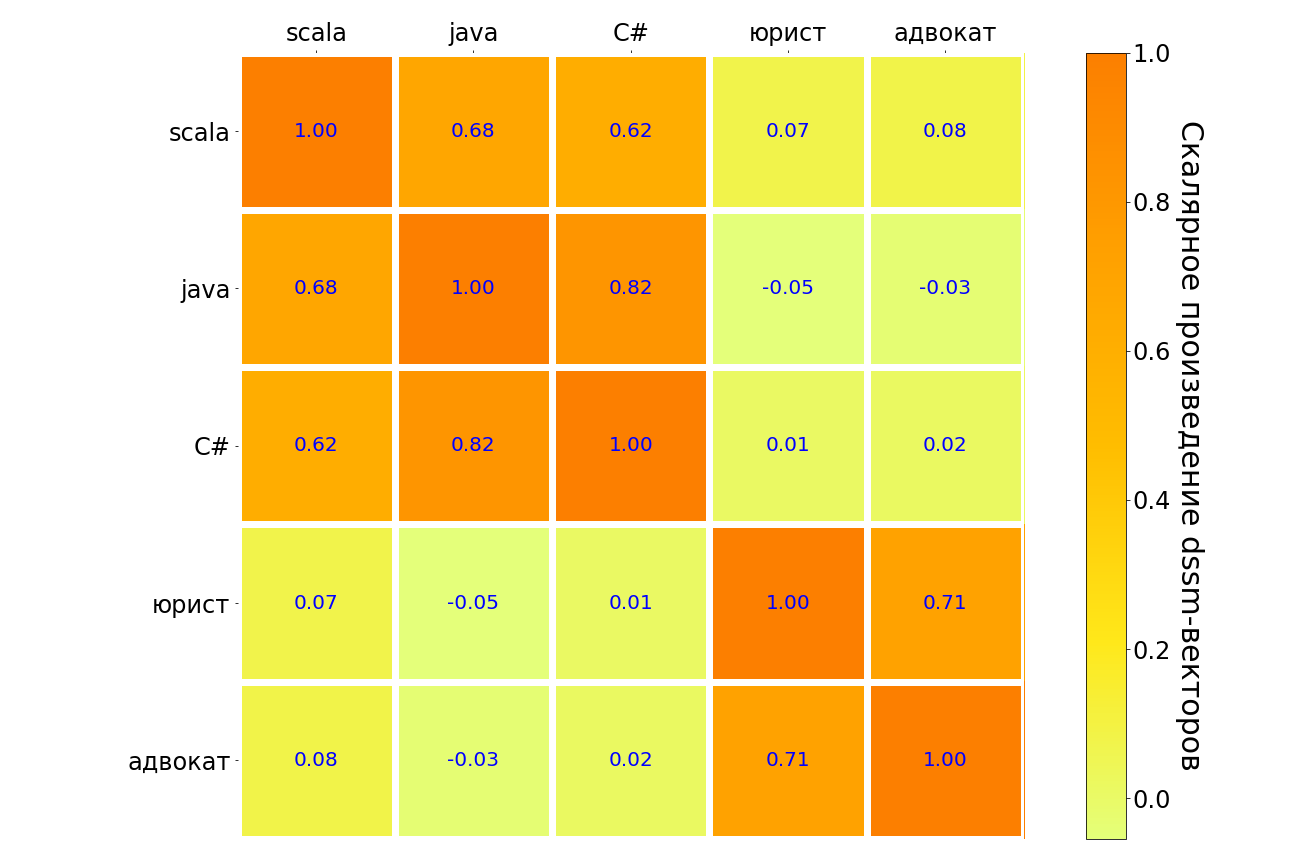
Los resultados de la aplicación de este modelo a las solicitudes de scala, java, C #, "abogado", "abogado" se encuentran en la tabla a continuación. Los pares de consultas de significado similar se resaltan en la oscuridad, a diferencia de la luz. Se puede ver que el modelo comprende la conexión entre diferentes lenguajes de programación, hay una fuerte conexión entre la solicitud "abogado" y "abogado". Pero entre el "abogado" y cualquier lenguaje de programación, la conexión es muy débil.
En algún momento, realmente quiero rendirme: los experimentos continúan, pero no se están "encendiendo". En este punto, un científico de datos puede encontrar útil apoyar al equipo y una vez más calcular los beneficios: puede valer la pena "enterrar a la azafata" y no tratar de "montar el caballo muerto", esto no es un fracaso, sino un experimento exitoso con un resultado negativo. O, después de sopesar los pros y los contras, realizará otro experimento que "disparará". Entonces nos pasó a nosotros.