A fines del invierno de este año, se llevó a cabo el concurso de identificación de modelos de cámara de la Sociedad de Procesamiento de Señal del IEEE. Participé en esta competencia de equipo como mentor. Sobre un método alternativo de trabajo en equipo, decisión y la segunda etapa bajo el corte.
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
Declaración del problema.A partir de la fotografía, es necesario determinar el dispositivo en el que se obtuvo esta fotografía. El conjunto de datos consistió en imágenes de diez clases: dos iPhones, siete teléfonos inteligentes Android y una cámara. La muestra de entrenamiento incluyó 275 imágenes de tamaño completo de cada clase. En la muestra de prueba, solo se presentó un cultivo central de 512x512. Además, se aplicó uno de los tres aumentos al 50 por ciento de ellos: compresión jpg, cambio de tamaño con interpolación cúbica o corrección gamma. Fue posible utilizar datos externos.
 Esencia (tm)
Esencia (tm)Si intenta explicar la tarea en un lenguaje simple, la idea se presenta en la imagen a continuación. Como regla general, se enseña a las redes neuronales modernas a distinguir objetos en una fotografía. es decir necesitas aprender a distinguir gatos de perros, pornografía de trajes de baño o tanques de carreteras. Al mismo tiempo, siempre debe ser indiferente a cómo y en qué dispositivo se toma una foto de un gato y un tanque.

En el mismo concurso, todo fue todo lo contrario. Independientemente de lo que se muestre en la foto, debe determinar el tipo de dispositivo. Es decir, use cosas como ruido de matriz, artefactos de procesamiento de imágenes, defectos ópticos, etc. Este fue el desafío clave: desarrollar un algoritmo que capture características de bajo nivel de las imágenes.
Características del trabajo en equipoLa abrumadora mayoría de los equipos de kaggle se forma de la siguiente manera: los participantes con una ventaja cercana en la tabla de clasificación se unen en un equipo, mientras que cada uno está aserrando su versión de la solución de principio a fin. Escribí una
publicación sobre un ejemplo típico de tal discurso. Sin embargo, esta vez tomamos el otro camino, a saber: dividimos las partes de la decisión en personas. Además, de acuerdo con las reglas de la competencia, los 3 mejores equipos de estudiantes recibieron un boleto a Canadá para la segunda etapa. Por lo tanto, cuando la columna vertebral se reunió, el personal tenía poco personal para cumplir con las reglas.
SoluciónPara mostrar un buen resultado en esta tarea, fue necesario armar el siguiente rompecabezas según las prioridades:
- Encuentra y descarga datos externos. A esta competencia se le permitió usar un número ilimitado de datos externos. Y rápidamente se hizo evidente que un gran conjunto de datos externo se estaba arrastrando.
- Filtrar datos externos. Las personas a veces publican imágenes procesadas, lo que elimina todas las características del dispositivo.
- Utilice un esquema de validación local confiable. Dado que incluso un modelo mostró precisión en la región de 0.98+, y en la prueba solo hubo 2k disparos, elegir el punto de control del modelo fue una tarea separada
- Modelos de trenes. Se publicó una línea de base muy poderosa en el foro. Sin embargo, sin una pizca de magia, solo permitió plata.
Recogida de datosEsta parte fue ocupada por
Arthur Fattakhov . Para esta tarea, fue bastante fácil obtener datos externos, estas son solo imágenes de ciertos modelos de teléfonos. Arthur escribió un script de Python que usa la biblioteca para analizar convenientemente páginas html llamadas
BeautifulSoup . Pero, por ejemplo, en la página del álbum de flickr, los bloques de fotos se cargan dinámicamente, y para evitar esto tuve que usar
selenio , que emulaba la acción del navegador. Se descargaron un total de más de 500 GB de fotos de yandex.fotki, flickr, wiki commons.
Filtrado de datosEsta fue mi única contribución a la solución en forma de código. Solo miré cómo se veían las fotos en bruto e hice un montón de reglas: 1) el tamaño típico de un modelo en particular 2) la calidad jpg está por encima del umbral 3) la presencia de las metaetiquetas necesarias de los modelos 4) el software correcto que se procesó.
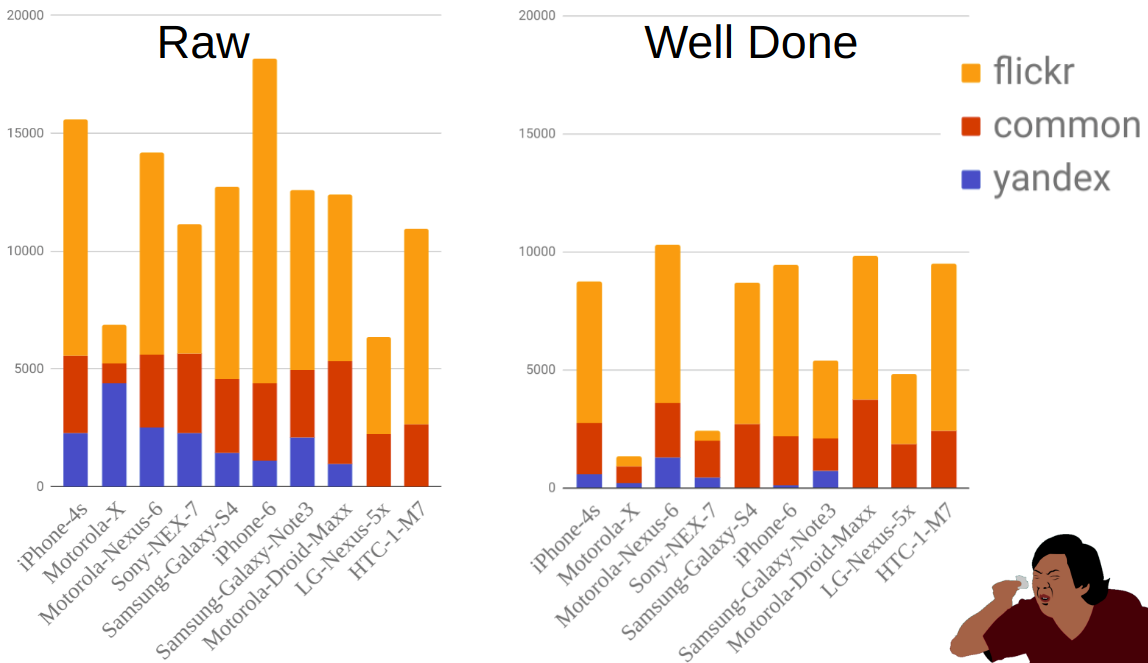
La figura muestra la distribución de fotografías por fuente y móvil antes y después del filtrado. Como puede ver, por ejemplo, Moto-X es mucho más pequeño que otros teléfonos. Al mismo tiempo, había muchos de ellos antes de filtrar, pero la mayoría de ellos se eliminaron debido al hecho de que hay muchas opciones para este teléfono y los propietarios no siempre indicaron correctamente el modelo.
ValidaciónLa implementación de la pieza con capacitación y validación fue realizada por
Ilya Kibardin . La validación en una pieza del tren kaggle no funcionó en absoluto: la cuadrícula eliminó casi una precisión de 1.0, y en la tabla de clasificación fue de aproximadamente 0.96.
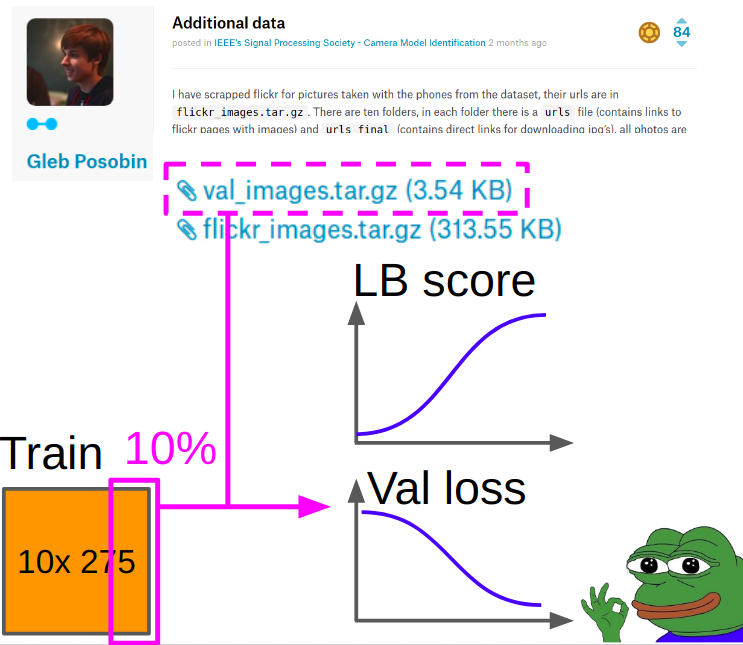
Por lo tanto, la validación se tomó fotos de
Gleb Posobin , que tomó de todos los sitios con reseñas telefónicas. Hubo un error: en lugar del iPhone 6 había un iPhone 6+. Lo reemplazamos con un iPhone 6 real y eliminamos el 10% de las imágenes del tren del kagla para equilibrar las clases.
Al aprender la métrica se consideró de la siguiente manera:
- Consideramos la entropía cruzada y akurasi en el centro del cultivo desde la validación.
- Consideramos la entropía cruzada y akurasi (manipulación + centro de cultivo) para cada una de las 8 manipulaciones, promediando más de ocho manipulaciones con una media aritmética.
- Agregamos la velocidad del ítem 1 y el ítem 2 con pesos 0.7 y 0.3.
Los mejores puntos de control se seleccionaron de acuerdo con la entropía cruzada ponderada obtenida en la Sección 3.
Entrenamiento modeloEn algún lugar en el medio de la competencia,
Andrés Torrubia publicó el
código completo
para su decisión . Fue tan bueno en términos de la precisión de los modelos finales que un grupo de equipos voló con él en la clasificación. Sin embargo, estaba escrito en keras y el nivel de código deseado.
La situación cambió por segunda vez cuando
Ivan Romanov publicó una
versión de pytorch de este código. Fue más rápido y, además, era paralelo a varias tarjetas de video. Sin embargo, el nivel de código todavía no era muy bueno, pero esto no es tan importante.
La tristeza es que estos muchachos terminaron en los lugares 30 y 45, respectivamente, pero en nuestros corazones siempre se mantuvieron en la cima.
Ilya en nuestro equipo tomó el código de Misha e hizo los siguientes cambios.
Preprocesamiento:- De la imagen original se realiza un recorte aleatorio de 960x960.
- Con una probabilidad de 0.5, se aplica una manipulación aleatoria. (Dependiendo de si se usó, se establece is_manip = 1 o 0)
- Se realiza un cultivo aleatorio 480x480
- Había dos opciones de entrenamiento: una rotación aleatoria de 90 grados en una dirección específica (simulando disparos horizontales / verticales para un teléfono móvil), o una conversión aleatoria del grupo D4.
 Entrenamiento
EntrenamientoEl entrenamiento se llevó a cabo completamente por medio del ajuste fino de la red, sin congelar las capas convolucionales del clasificador (teníamos muchos datos + intuitivamente, los pesos que extraen objetos de alto nivel en forma de gatos / perros se pueden expandir, porque necesitamos características de bajo nivel).
 Derramamiento:
Derramamiento:Adán con lr = 1e-4. Cuando la pérdida de validación deja de mejorar durante 2-3 épocas, reducimos lr a la mitad. Entonces a la convergencia. Reemplace a Adam con SGD y aprenda tres ciclos con un lr cíclico de 1e-3 a 1e-6.
Conjunto final:Le pedí a Ilya que implementara mi enfoque de la competencia anterior. Para el conjunto filial, entrenamos 9 modelos, de cada uno seleccionamos los 3 mejores puntos de control, cada punto de control se predijo con TTA y en el final se promediaron todas las predicciones por media geométrica.
 Epílogo de la primera etapa
Epílogo de la primera etapaComo resultado, tomamos el 2do lugar en la clasificación y el 1er lugar entre los equipos de estudiantes. Y esto significa que llegamos a la segunda etapa de esta competencia como parte de la
Conferencia Internacional IEEE 2018 sobre Procesamiento de Acústica, Discurso y Señal en Canadá. De lo notable, el equipo que tomó el 3er lugar también fue formalmente estudiante. Si calculamos la velocidad, resulta que la recorrimos con una imagen predicha correctamente.
Final IEEE Signal Processing Cup 2018Después de recibir todas las confirmaciones, yo, Valery y Andrey decidimos no ir a Canadá para la segunda etapa. Ilya y Arthur F. decidieron ir, comenzaron a organizar todo y no les dieron una visa. Para evitar un escándalo internacional sobre la opresión de los científicos más fuertes de Rusia, se permitió a las orgías participar de forma remota.
La línea de tiempo era así:
03.03 - dados los datos del tren
04.09 - datos de prueba emitidos
12.04 - se nos permitió participar de forma remota
13.04 - comenzamos a mirar qué hay allí con los datos
16/04 - final
Características de la segunda etapa.En la segunda etapa no había tabla de clasificación: era necesario enviar solo una presentación al final. Es decir, incluso el formato de las predicciones no se puede verificar. Además, los modelos de cámara no se conocían. Y esto significa dos archivos a la vez: no funcionará con datos externos y la validación local puede ser muy poco representativa.
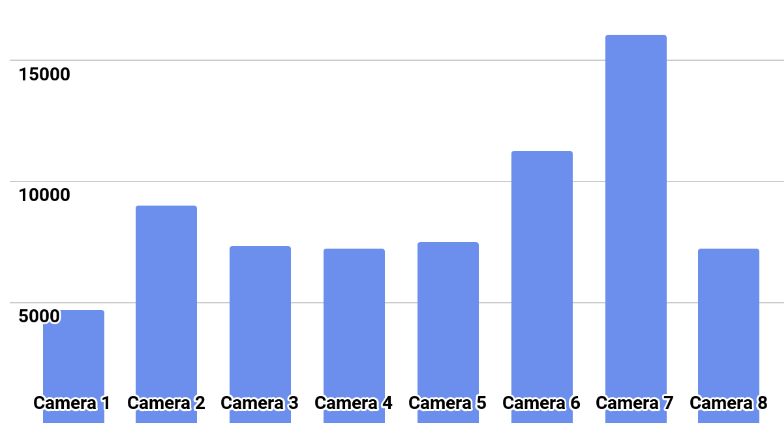
La distribución de la clase se muestra en la imagen.
SoluciónIntentamos entrenar modelos con un plan desde la primera etapa a partir de las escalas de los mejores modelos. Todos los modelos entrenaron alegremente con una precisión de 0.97+ en sus pliegues, pero en la prueba dieron intersección de predicciones en la región de 0.87.
Lo que interpreté como un sobreajuste duro. Por lo tanto, propuso un nuevo plan:
- Tomamos nuestros mejores modelos de la primera etapa como extractores de características.
- Tomamos el PCA de las características extraídas para que todo aprenda de la noche a la mañana.
- Aprendiendo LightGBM.

La lógica aquí es la siguiente. Las redes neuronales ya están capacitadas para extraer características de bajo nivel del sensor, la óptica, el algoritmo de demostración y, al mismo tiempo, no se aferran al contexto. Además, las características extraídas antes del clasificador final (de hecho, la regresión logística) son el resultado de una transformación fuertemente no lineal. Por lo tanto, uno podría simplemente enseñar algo simple, no propenso a la readaptación, como la regresión logística. Sin embargo, dado que los nuevos datos pueden ser muy diferentes de los de la primera etapa, aún es mejor entrenar algo no lineal, por ejemplo, el aumento de gradiente en los árboles de decisión. Utilicé este enfoque en varias competiciones, donde publiqué el código.
Como hubo un envío, no tengo una forma confiable de probar mi enfoque. Sin embargo, DenseNet demostró ser el mejor extractor de funciones. Las redes Resnext y SE-Resnext mostraron un menor rendimiento en la validación local. Por lo tanto, la decisión final se veía así.
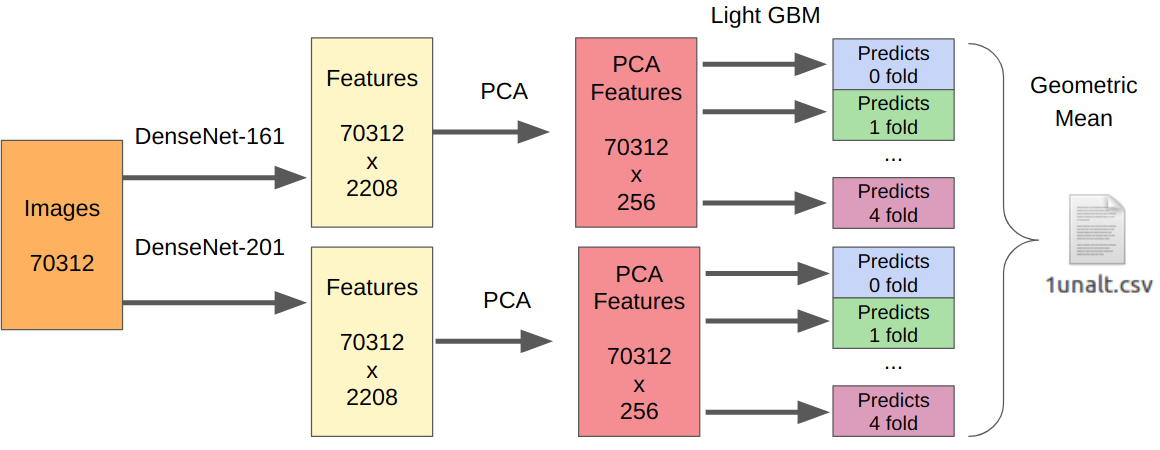
Para la parte con manipulaciones, el número de todas las muestras de entrenamiento debe multiplicarse por 7, ya que extraje las características de cada manipulación por separado.
EpílogoComo resultado, en la etapa final tomamos el segundo lugar, pero hay muchas reservas. Para empezar, el lugar se otorgó no de acuerdo con la precisión del algoritmo, sino de acuerdo con las estimaciones de la presentación del jurado. El equipo, que obtuvo el primer lugar, hizo no solo una preza, sino también una demostración en vivo con el trabajo de su algoritmo. Bueno, todavía no sabemos la velocidad final de cada equipo, y las organizaciones no las revelan en correspondencia, incluso después de preguntas directas.
De las cosas divertidas: en la primera etapa, todos los equipos de nuestra comunidad indicaron en el nombre del equipo [ods.ai] y ocuparon con bastante poder la clasificación. Después de eso, leyendas de Kegle como
inversión y
Giba decidieron unirse a nosotros para ver qué estábamos haciendo aquí.

Realmente disfruté participando como mentor. Basándome en la experiencia de participar en competencias anteriores, pude dar una serie de valiosos consejos para mejorar la línea de base, así como para construir una validación local. En el futuro, tal formato será más que el caso: Kaggle Master / Grandmaster como el arquitecto de la solución + 2-3 Kaggle Expert para escribir código y probar hipótesis. En mi opinión, esto es puro ganar-ganar, ya que los participantes experimentados ya son demasiado vagos para escribir código y tal vez no tanto tiempo, y los principiantes obtienen un mejor resultado, no cometan errores banales por inexperiencia y adquieran experiencia aún más rápido.
→
Código de nuestra solución→
Grabación de rendimiento con entrenamiento ML