A una gran empresa minera se le ocurrió una tarea interesante: hay muchos sitios con sistemas de TI. Están ubicados tanto en ciudades como en depósitos. Estas son varias docenas de oficinas regionales más empresas mineras. 500 kilómetros en la taiga sin carretera, ¡fácil! En cada instalación hay equipos que deben "plegarse" en una infraestructura común y determinar qué y en qué condiciones funciona.
Lo que se necesitaba aquí no era solo un inventario técnico de todos los dispositivos en la red (números de serie, versiones de software, etc.), sino un sistema de monitoreo completo. Por qué Para identificar las causas raíz de los accidentes y advertirlo rápidamente, construir mapas de red, establecer conexiones entre equipos, monitorear el estado del hierro y los canales de comunicación, hacer advertencias sobre cómo dejar el soporte o encender nuevos equipos no contabilizados, etc. Además, se requería integración. con CMDB (teniendo en cuenta las unidades de configuración), de modo que todo el hierro que "encontró" el sistema de monitoreo se compara con lo que está registrado en una rama particular, es decir, de hecho está en la red.
Otro sistema de monitoreo tenía que ser "amigo" de la telefonía Asterisk, para que este último
En el caso de algunas situaciones de emergencia graves, como un corte de energía en el sitio en Krasnoyarsk, podría llamar rápidamente a las personas responsables. También existía la tarea de distinguir entre la visibilidad de los objetos de monitoreo y los poderes de los grupos de usuarios. Los operadores se ocupan del equipo, Moscú - Moscú, ingenieros en el campo, solo su campo.
El cliente eligió entre varios sistemas de monitoreo: 1) producto shareware; 2) una de las soluciones comerciales; 3) Sistema Infosim StableNet. Como resultado de las pruebas, las desventajas del producto shareware quedaron claras para el cliente: era largo y difícil de configurar, además no tenía la cantidad de funcionalidad que se requería (en la misma parte, por ejemplo, renderizar conexiones entre dispositivos en la red). Fuera de la caja, él no sabe cómo hacer esto, pero con los complementos resulta regular. El producto comercial no tenía agentes de monitoreo distribuidos; estos se instalan en un sitio específico y controlan solo su "arbusto". En consecuencia, nos detuvimos en Infosima: cerró toda la lista de deseos. Y por eso.
Así es como se ve la pantalla principal del administrador de InfoSim StableNet (este no es un proyecto mineral, sino una infraestructura de prueba).
La pantalla principal en la que se muestra el estado actual de la red:

El panel de control está visible a la izquierda, en el que podemos configurar el sistema y mostrar las estadísticas que necesitamos. Por ejemplo, el botón Analizador le permite mostrar estadísticas de cualquier parámetro que recopilemos, en particular, el tiempo de ida y vuelta durante un período de una hora para una pieza de hierro en particular.

El botón Inventario muestra los datos de inventario de objetos de monitoreo, vecinos, la tabla MAC para cada dispositivo que está en el sistema. Increíblemente conveniente: se facilita el proceso de encontrar cualquier parámetro de equipo en la red por números de serie, tipos de equipo, versiones del sistema operativo, etc.

Cuando, en algún lugar lejos de la taiga, los empleados locales, por ejemplo, instalaron un nuevo interruptor y no se lo contaron a nadie, inmediatamente se hizo visible en el sistema. Este equipo cae en una rama especial en el árbol de dispositivos "Nuevos dispositivos" y automáticamente en CMDB.

Los objetos de monitoreo se sondean no solo para modelos en serie y modelos, sino también para cargar memoria, interfaces, etc. Hay soporte para muchos proveedores, en particular, servidores, almacenamiento, equipos de telecomunicaciones, máquinas para usuarios finales. Si falta algo, el cliente nos escribe a nosotros o al vendedor directamente y se agregan nuevas piezas de hierro. Todo es simple

El sistema se integra con los servidores MS Active Directory y RADIUS para la autorización general y la aplicación de políticas grupales. Así es como se ve la arquitectura del sistema:
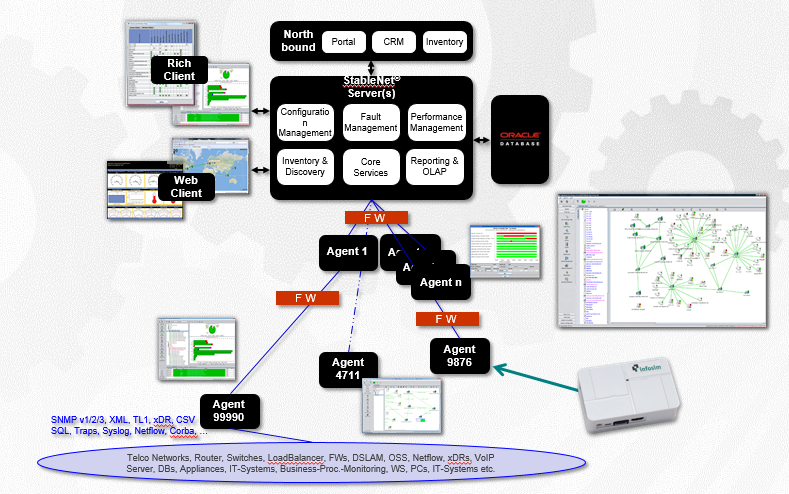
El servidor central es responsable de procesar y mostrar las estadísticas recopiladas del hardware.
El segundo componente importante es el agente responsable de interrogar el equipo y verificar la disponibilidad de hierro. Puede haber varios agentes (software remoto), tenemos un tema distribuido geográficamente, con un agente para cada sitio. Esto es necesario para no dirigir el tráfico de telemetría sin procesar a la organización matriz: el cliente tiene una gran cantidad de sitios conectados a través de costosos canales satelitales, por lo que solo se envía el resultado de la medición. Y una base de datos para almacenar todo lo que se recopila.
Si el sitio remoto no está disponible, los empleados en el sitio pueden conectarse directamente al agente y ver el estado de su "bush" de la red, incluso sin acceso al servidor central.
Un agente puede ser un servidor x64 / x86 que ejecuta RedHat, CentOS, Ubuntu, Windows Server (para plataformas grandes) o un micro agente basado en computadoras ARM pequeñas como Raspberry PI (para plataformas pequeñas). No cargamos el canal con pings de hierro, el agente lo hace y ya agrega paquetes con estadísticas.

También podemos eliminar las variaciones de retardo, fluctuación de fase, fluctuación de fase para equipos Cisco (IP SLA) y Huawei (NQA). Por lo tanto, si en el futuro el cliente agrega algún otro hierro, la compañía no tendrá ningún problema: también podemos ayudar a medir los indicadores de calidad del canal, realizar pruebas sintéticas y probar los canales de comunicación de prueba entre los agentes.
El sistema de monitoreo puede recibir mensajes de syslog, trampas SNMP de hierro, filtrarlos y generar mensajes de alarma. Construye automáticamente la topología en los niveles L2 y L3, y en base a esto, las dependencias de situaciones de emergencia (análisis de causa raíz) se configuran automáticamente. Esto es muy bueno, ya que permite a los administradores estar informados de la causa raíz del accidente, reduciendo así el tiempo requerido para resolverlo. Por ejemplo, si en una cadena de cinco interruptores se cae uno en el medio, recibiremos un mensaje de que el tercer interruptor (causa raíz) se ha caído, y el cuarto y el quinto son inaccesibles debido a esto.

La solución funciona de forma inmediata, pero el proceso se puede personalizar. Entonces, por ejemplo, para facilitar el trabajo de nuestro soporte técnico, "agregamos" el estado del suministro de energía ininterrumpible y el estado de la energía: si la energía en el sitio está apagada, entonces en lugar de 30 alarmas obtenemos una para la energía. La correlación ocurre según la topología, los usuarios y las reglas.
Hay una configuración grupal de equipos, no solo puede sondear pasivamente el hardware, sino también implementar configuraciones como configuraciones en los conmutadores. ¿Registrar vlan o ntp en 40 conmutadores? Fácil!
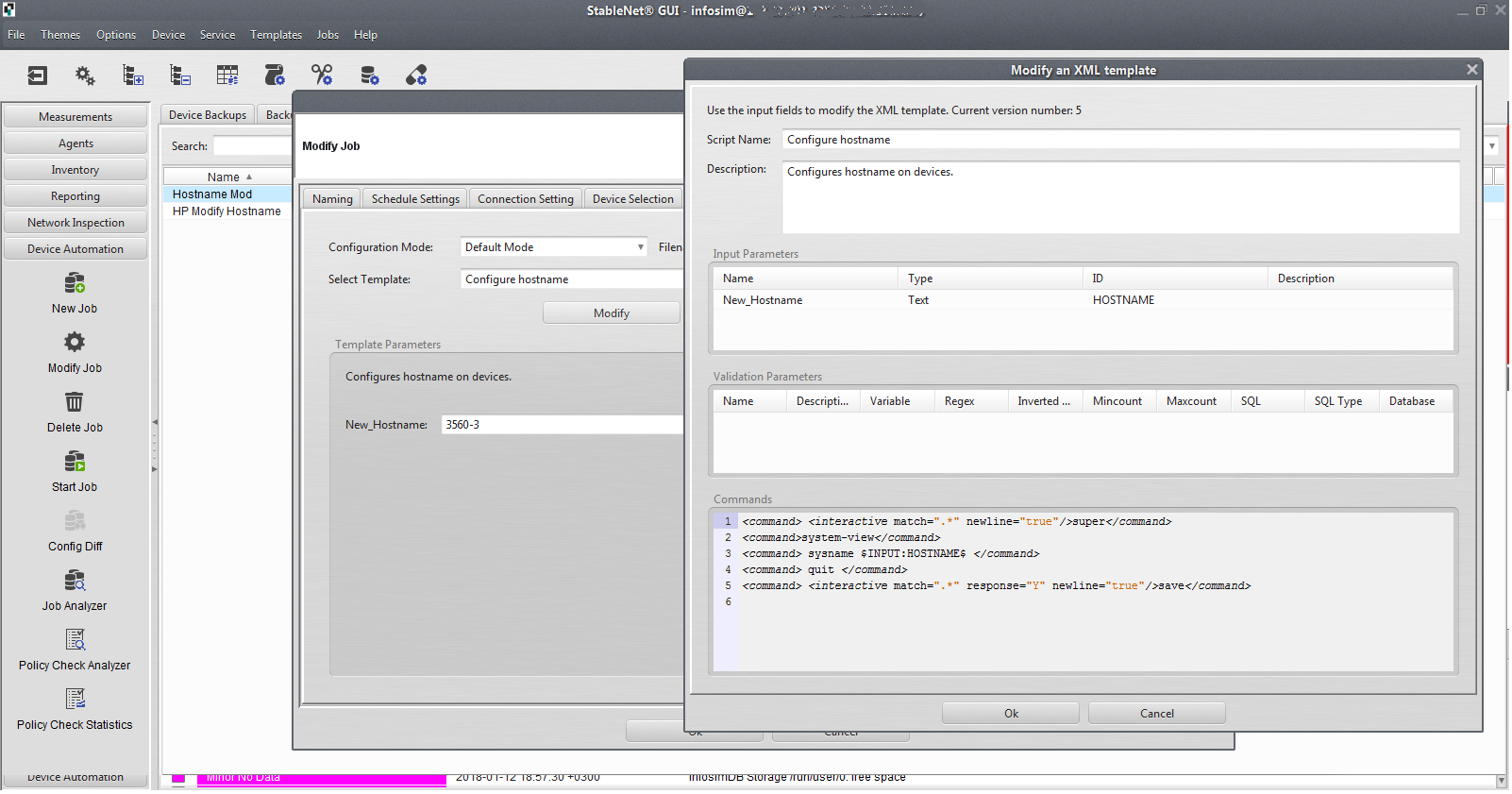
También es muy bueno que el sistema permita al cliente hacer una copia de seguridad de la configuración del equipo en un horario: recopile las configuraciones una vez al día o durante un evento (por ejemplo, aparece un mensaje sobre un cambio de configuración; puede configurar una tarea que funcionará en el momento en que ocurra el evento y recopilar la configuración modificada). Lo mismo es para las rampas, para eventos de emergencia. Esto será de gran ayuda con el "informe" y la búsqueda de los principales culpables de los cambios de configuración. Además, de hecho, se crea una base de datos actualizada de todas las configuraciones de dispositivos en la red.
Hay una API para la integración. En nuestro proyecto, se realizó la integración de monitoreo con CMDB 1C: ITIL Gestión de tecnología de información empresarial para almacenar toda la información sobre equipos (activos tangibles). La información de la encuesta se compara con lo que hay en los activos, cuando detecta equipos no contabilizados, el sistema dice: "Aquí hay un interruptor incomprensible". Descubra qué es, obstruyen todos los campos necesarios: la ubicación de instalación, el nombre, etc. El número de serie, el nombre, el número de pieza y la versión del firmware se obtienen del hardware. A continuación, la tarea se envía para monitoreo: se cambia el nombre de la pieza de hierro en el sistema, se establece en la posición correcta en el árbol de ubicación, la configuración de monitoreo se aplica según el tipo de pieza de hierro (por ejemplo, el equipo de límite debe ser interrogado con más frecuencia que el resto), el nombre de host en el dispositivo cambia, y d.
Proceso de campo
En primer lugar, configuramos la integración con AD. Esto nos facilitó la vida durante la implementación, así como en la operación posterior. No es necesario crear y eliminar cuentas para los usuarios cada vez. El sistema recibirá automáticamente todas las cuentas activas de AD. Si de repente alguien renuncia, entonces el sistema desactiva esta cuenta en casa y nadie más puede ingresar.
Para los administradores y la gerencia media, una tarea muy urgente era obtener muchos informes. Durante el lanzamiento, se configuraron informes sobre la utilización y accesibilidad de los canales, sobre la disponibilidad de glándulas en los sitios, situaciones de emergencia principales, informes sobre tipos específicos de accidentes, versiones del sistema operativo, informes sobre cambios en la configuración del equipo y otros.
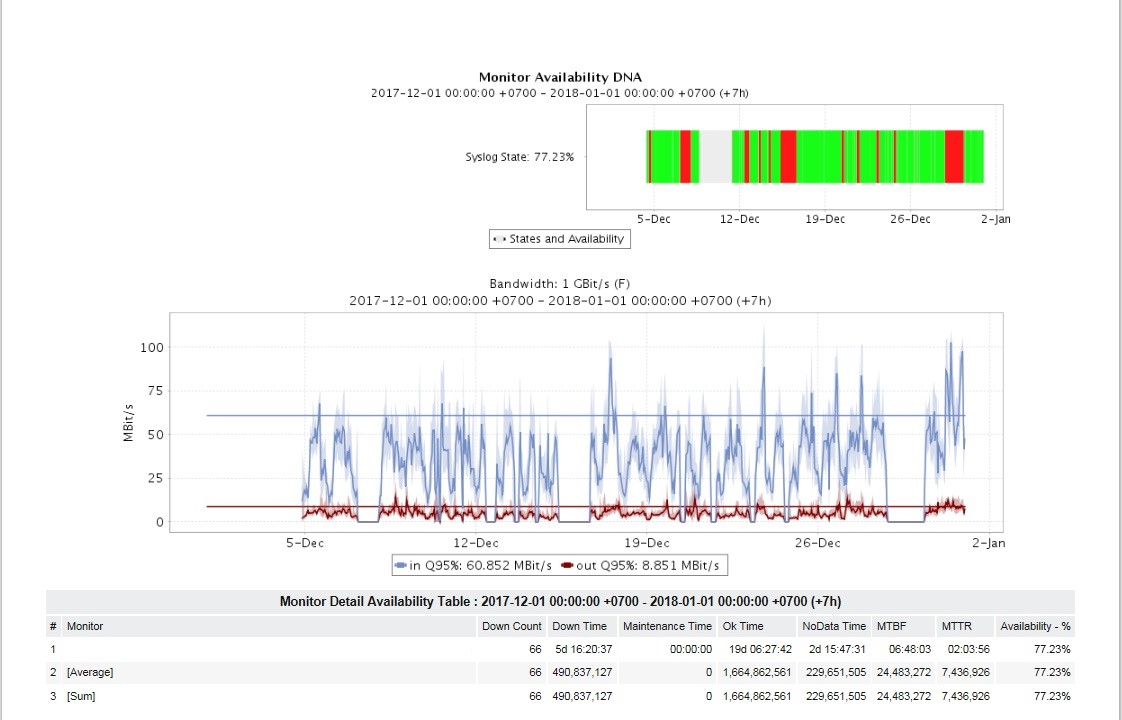
Los informes se pueden ver en formato HTML, recibidos por correo en formato PDF y XLSX con la frecuencia deseada (una vez al día, semana, mes, etc.). Para diferentes informes, se estableció su propia frecuencia y orientación personal del consumidor de informes.
El sistema también tiene la flexibilidad de notificar y realizar acciones personalizadas en caso de emergencia, puede enviar mensajes de correo electrónico, mensajes SMS (utilizando una puerta de enlace externa de SMS), además de escribir sus propios scripts que se lanzarán. Por ejemplo, hemos creado un bot de Telegram en nuestro servicio de monitoreo en la nube, que notifica a los empleados responsables de nuestro servicio operativo sobre situaciones de emergencia. También puede ser interrogado por varios parámetros: "CPU, 10.1.1.100" devuelve "95%", pero dado el soporte de una aplicación móvil, esto puede parecer un poco redundante, aunque conveniente.
Luego, escribimos un script para la integración con la central telefónica. Ahora, cuando surge una situación megacrítica (falla de energía en sitios críticos o centros de datos), el sistema llama a las personas responsables en los teléfonos móviles y en una voz como Siri dice: "El voltaje en dicho objeto está por debajo de un nivel crítico". Se hace de manera bastante simple: el accidente se duplica en una carpeta específica en la central telefónica, donde es procesado por el servicio de telefonía; solo necesita especificar de antemano los números a los que llamar automáticamente. De hecho, automatizamos el proceso de notificación a los administradores o gerentes responsables en caso de accidente. En otras palabras, reemplazaron a la persona que debería llamar e informar el accidente.
Función de búsqueda muy conveniente para usuarios y glándulas. El usuario llama y dice: "Mi red no funciona". Por su dirección IP, puede ver inmediatamente dónde está conectado (qué conmutador, qué puerto, qué amapola) y dónde está conectado antes:

Puede crear diferentes tipos de topologías gráficas que faciliten la vida de los ingenieros. Necesita, por ejemplo, para ver dónde tenemos algún tipo de cambio. Es simple: lo encontraron en la rama derecha (o usaron la búsqueda) y abrieron sus vecinos. Se admiten varios niveles de vecindario (el primero es vecinos inmediatos, el segundo es vecinos de vecinos, etc.). Y puede ver de inmediato dónde se encuentra nuestro conmutador en la topología, qué puertos y dónde está conectado, qué direcciones poppy hay en los puertos. O mire el mapa de protocolo OSPF, BGP, EIGRP, STP, PIM, MPLS: el sistema procesará y dibujará todo esto por sí mismo.

O vea visualmente cómo se siente la red en uno de los sitios. Para mayor comodidad, dividimos las partes de los sitios WAN y LAN y las dibujamos con tarjetas separadas. Todos los indicadores y enlaces son interactivos. Cuando pasa el cursor sobre ellos, puede ver el estado actual y caer en cualquier dispositivo en particular. También me gustaría llamar la atención sobre el hecho de que el esquema de Microsoft Visio, elaborado por el propio ingeniero, se utiliza como sustrato para dicho informe. Él vio este esquema muchas veces como una imagen estática en papel o en una pantalla. Ahora "cobra vida" y proporciona comentarios en tiempo real. Muy comodo

De acuerdo con los requisitos del cliente, se delimitaron los derechos de acceso de los usuarios. Hay muchos roles, pero están configurados de manera flexible. Dada la diferencia en las zonas horarias entre los objetos, la función de las horas de trabajo en los roles fue muy útil: a qué hora, para qué accidentes, a quién SMS, etc.
InfoSim StableNet recopila estadísticas de incidentes. Según nuestra experiencia, en tales casos hay problemas con el trabajo planificado: estropean los informes y causan preocupaciones innecesarias. Se puede observar aquí que aquí y allá habrá trabajo: entonces las alarmas se activarán en modo silencioso y el informe indicará en un color diferente que este tiempo de inactividad es un plan. Sí, las actividades planificadas no se anuncian retroactivamente.

Si no hay suficientes oportunidades listas para usar, puede crear plantillas autoescritas. Por ejemplo, había puntos de acceso de Motorola en el proyecto. No había plantillas listas para ellos. Usando el "asistente" incorporado, creamos plantillas y monitoreamos los parámetros que el cliente quería ver (nivel de señal, relación señal / ruido).
Hubo otro caso cuando el sistema "no entendió" un fabricante ruso y mostró el código del fabricante en lugar de un nombre. Para este caso, el sistema tiene una funcionalidad que le permite agregar nuevos proveedores y modelos de hardware en cuestión de segundos.
Aquí está la lista de características que el sistema de monitoreo actualmente permite que el cliente realice:
- Monitoree la disponibilidad utilizando pings ICMP.
- Recopila información utilizando SNMP.
- Escanee subredes en busca de nuevo hardware.
- Enviar informes por período.
- Implementar configuraciones de respaldo.
- Analizar disponibilidad.
- “Haga sonar la alarma” sobre la falta de disponibilidad de equipos o la salida de indicadores fuera del rango normal.
- Las capturas de script SNMP como disparadores, datos de syslog y cualquier entrada.
- Integrar con AD.
- Detecta automáticamente la conectividad del dispositivo (CDP, LLDP, vecindario L3) y, según esto, dibuja automáticamente un mapa de red.
- Cree "mapas meteorológicos" para visualizar el estado de la red con la capacidad de utilizar sustratos gráficos.
- Cree pantallas de trabajo (paneles) para mostrar información operativa sobre el estado de la red y los dispositivos.
- Lleve a cabo un inventario de equipos (tipo de equipo, fabricante, modelo, versión de software, cuando llegue la fecha de EoS / EoL, etc.)
- Existe una API REST para una integración profunda con CMDB 1C y otros sistemas externos.
- Realice la configuración grupal del equipo desde el sistema de monitoreo.
- Verifique la configuración del dispositivo para conocer las políticas de la compañía
Referencias
-
Bicicletas de apoyo de primera línea.-
Canales de comunicación para depósitos minerales.- Mi correo: DDrozhzhin@croc.ru