En la Internet moderna, más de 630 millones de sitios, pero solo el 6% de ellos contienen contenido en ruso. La barrera del idioma es el principal problema de la difusión del conocimiento entre los usuarios de la red, y creemos que debe resolverse no solo enseñando idiomas extranjeros, sino también utilizando la traducción automática en el navegador.
Hoy le diremos a los lectores de Habr acerca de dos cambios tecnológicos importantes en el traductor Yandex.Browser. En primer lugar, la traducción de palabras y frases seleccionadas ahora utiliza un modelo híbrido, y recordamos cómo este enfoque difiere del uso de redes exclusivamente neuronales. En segundo lugar, la red neuronal del traductor ahora tiene en cuenta la estructura de las páginas web, cuyas características también discutiremos debajo del corte.
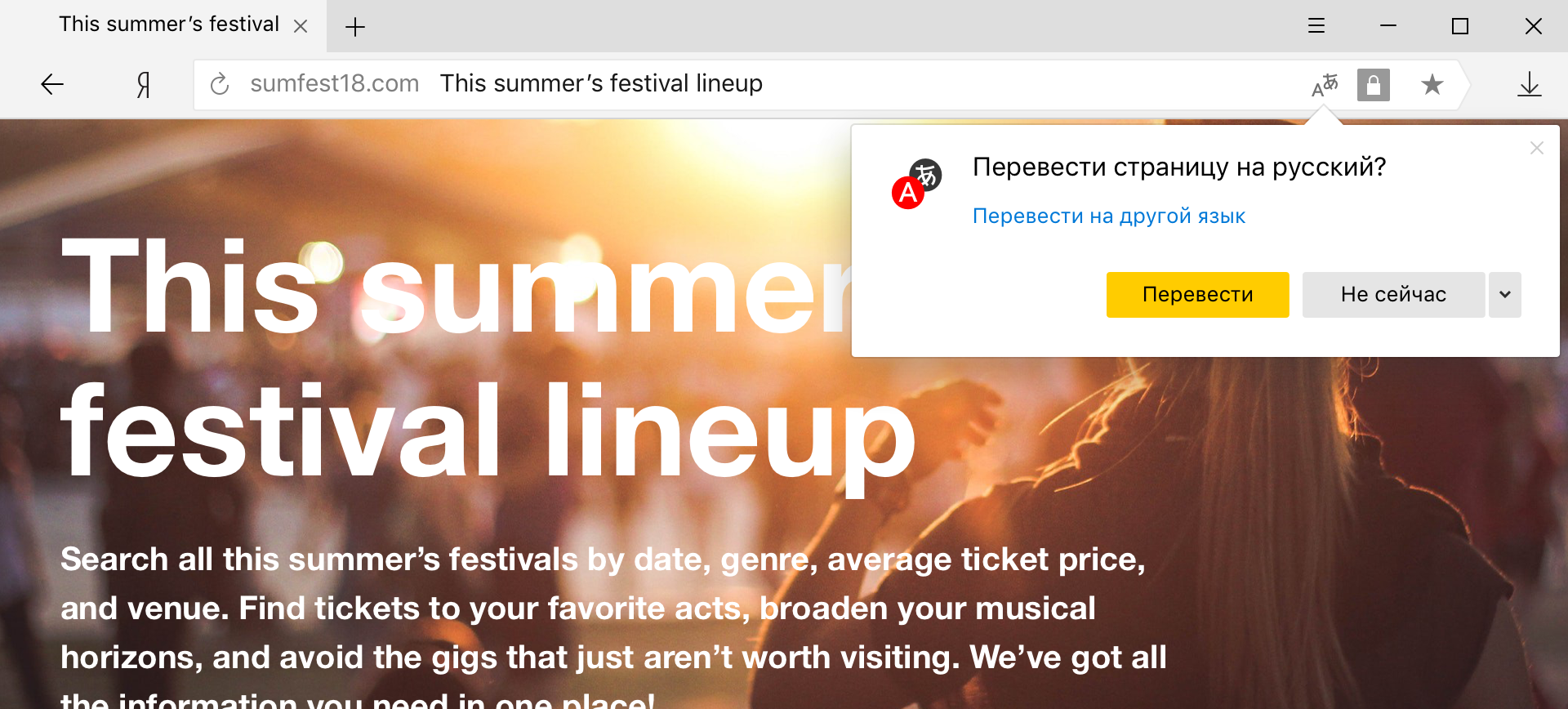
Traductor híbrido de palabras y frases
Los primeros sistemas de traducción automática se basaron en
diccionarios y reglas (de hecho, regulares escritos a mano), que determinaron la calidad de la traducción. Los lingüistas profesionales han trabajado durante años para elaborar reglas manuales cada vez más detalladas. Este trabajo consumió tanto tiempo que se prestó mucha atención solo a los pares de idiomas más populares, pero incluso en el marco de ellos, las máquinas funcionaron mal. El lenguaje vivo es un sistema muy complejo que obedece mal las reglas. Es aún más difícil describir las reglas de correspondencia de dos idiomas.
La única forma en que la máquina puede adaptarse constantemente a las condiciones cambiantes es aprender de forma independiente en una gran cantidad de textos paralelos (idénticos en significado, pero escritos en diferentes idiomas). Este es el enfoque estadístico de la traducción automática. La computadora compara textos paralelos y revela patrones independientemente.
Un
traductor estadístico tiene ventajas y desventajas. Por un lado, recuerda bien palabras y frases raras y complejas. Si se encontraron en textos paralelos, el traductor los recordará y continuará traduciendo correctamente. Por otro lado, el resultado de la traducción puede ser similar al rompecabezas ensamblado: la imagen general parece ser comprensible, pero si observa detenidamente, puede ver que está compuesta de piezas separadas. La razón es que el traductor presenta palabras individuales en forma de identificadores, que de ninguna manera reflejan la relación entre ellos. Esto no corresponde a cómo las personas perciben el lenguaje cuando las palabras están determinadas por cómo se usan, cómo se relacionan con otras palabras y cómo difieren de ellas.
Las redes neuronales ayudan a resolver este problema. La representación vectorial de palabras (incrustación de palabras) utilizada en la traducción automática neuronal, por regla general, hace coincidir cada palabra con un vector de varios cientos de números. Los vectores, en contraste con los identificadores simples de un enfoque estadístico, se forman durante el entrenamiento de una red neuronal y tienen en cuenta la relación entre las palabras. Por ejemplo, un modelo puede reconocer que dado que "té" y "café" a menudo aparecen en contextos similares, ambas palabras deberían ser posibles en el contexto de la nueva palabra "derrame", que, por ejemplo, solo uno de ellos se encontró en los datos de capacitación.
Sin embargo, el proceso de enseñar representaciones vectoriales es claramente más exigente estadísticamente que memorizar mecánicamente ejemplos. Además, no está claro qué hacer con esas palabras de entrada raras que a menudo no se conocían lo suficiente como para que la red construyera una representación vectorial aceptable para ellas. En esta situación, es lógico combinar ambos métodos.
Desde el año pasado, Yandex.Translator ha estado utilizando un
modelo híbrido . Cuando el traductor recibe texto del usuario, lo entrega a ambos sistemas, tanto a la red neuronal como al traductor estadístico. Luego, un algoritmo basado en el método de entrenamiento
CatBoost evalúa qué traducción es mejor. Al puntuar, se tienen en cuenta docenas de factores, desde la longitud de la oración (el modelo estadístico traduce mejor las frases cortas) hasta la sintaxis. La traducción reconocida como la mejor se muestra al usuario.
Es el modelo híbrido que ahora se usa en Yandex.Browser, cuando el usuario selecciona palabras y frases específicas en la página para traducirlas.
Este modo es especialmente conveniente para aquellos que generalmente hablan un idioma extranjero y desean traducir solo palabras desconocidas. Pero si, por ejemplo, en lugar del inglés habitual, te encuentras con chino, entonces aquí será difícil prescindir de un traductor de páginas. Parecería que la diferencia está solo en el volumen del texto traducido, pero no es tan simple.
Traductor de red neuronal web
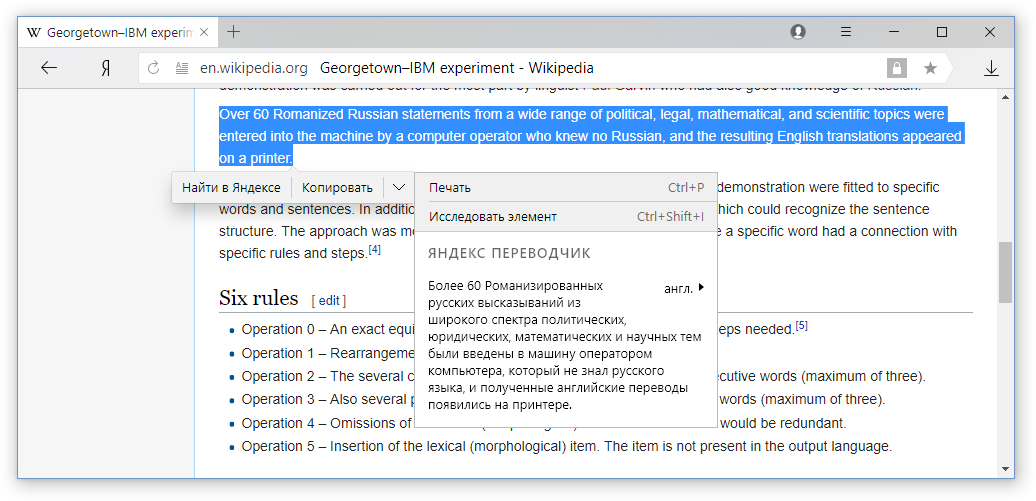
Desde el momento del
experimento de Georgetown hasta casi hoy, todos los sistemas de traducción automática han sido entrenados para traducir cada oración del texto fuente individualmente. Mientras que una página web no es solo un conjunto de oraciones, sino un texto estructurado en el que hay elementos fundamentalmente diferentes. Considere los elementos básicos de la mayoría de las páginas.
Rumbo . Por lo general, texto brillante y grande que vemos de inmediato cuando va a la página. El titular a menudo contiene la esencia de las noticias, por lo que es importante traducirla correctamente. Pero esto es difícil de hacer, porque el texto en el título es pequeño y sin comprender el contexto, puede cometer un error. En el caso del idioma inglés, es aún más complicado, porque los encabezados en inglés a menudo contienen frases con gramática no tradicional, infinitivos o incluso verbos errados. Por ejemplo, se
anunció la precuela de Game of Thrones .
La navegación Palabras y frases que nos ayudan a navegar por el sitio. Por ejemplo, no vale la pena traducir
Inicio ,
Atrás y
Mi cuenta como "Inicio", "Atrás" y "Mi cuenta", si se encuentran en el menú del sitio y no en el texto de publicación.
El texto principal . Todo es más simple con él; difiere poco de los textos y oraciones comunes que podemos encontrar en los libros. Pero incluso aquí es importante garantizar la coherencia de las traducciones, es decir, garantizar que dentro de la misma página web los mismos términos y conceptos se traduzcan de la misma manera.
Para una traducción de alta calidad de páginas web, no es suficiente usar una red neuronal o un modelo híbrido; también debe tener en cuenta la estructura de las páginas. Y para esto necesitábamos lidiar con muchas dificultades tecnológicas.
Clasificación de segmentos de texto . Para hacer esto, nuevamente usamos CatBoost y factores basados tanto en el texto como en el marcado HTML de documentos (etiqueta, tamaño de texto, número de enlaces por unidad de texto, ...). Los factores son bastante heterogéneos, por lo tanto, es CatBoost (basado en el aumento de gradiente) el que muestra los mejores resultados (la precisión de la clasificación es superior al 95%). Pero la clasificación por segmentos por sí sola no es suficiente.
Desequilibrio en los datos . Tradicionalmente, los algoritmos Yandex.Translator aprenden sobre textos de Internet. Parecería que esta es una solución ideal para capacitar a un traductor de páginas web (en otras palabras, la red aprende de textos de la misma naturaleza que los textos en los que vamos a usarlo). Pero tan pronto como aprendimos a separar diferentes segmentos entre sí, encontramos una característica interesante. En promedio, el contenido ocupa alrededor del 85% de todo el texto en los sitios web, mientras que los títulos y la navegación representan solo el 7.5% cada uno. Recuerde también que los encabezados y elementos de navegación en estilo y gramática son notablemente diferentes del resto del texto. Estos dos factores juntos conducen al problema del sesgo de datos. Es más rentable para una red neuronal simplemente ignorar las características de estos segmentos muy mal representados en el conjunto de entrenamiento. La red aprende a traducir bien solo el texto principal, por lo que la calidad de la traducción de los encabezados y la navegación se ve afectada. Para neutralizar este efecto desagradable, hicimos dos cosas: para cada par de oraciones paralelas, atribuimos uno de los tres tipos de segmentos (contenido, título o navegación) como metainformación y elevamos artificialmente la concentración de los dos últimos en el edificio de capacitación al 33% debido al hecho de que comenzó a mostrar ejemplos similares a la red neuronal de aprendizaje con más frecuencia.
Aprendizaje multitarea . Dado que ahora somos capaces de separar textos en páginas web en tres clases de segmentos, podría parecer una idea natural entrenar tres modelos separados, cada uno de los cuales se encargará de la traducción de su propio tipo de textos: encabezados, navegación o contenido. Esto realmente funciona bien, pero el esquema funciona aún mejor cuando entrenamos una red neuronal para traducir todo tipo de textos a la vez. La clave para comprender radica en la idea del
aprendizaje multitarea (MTL): si hay una conexión interna entre varias tareas de aprendizaje automático, ¡un modelo que aprende a resolver estos problemas al mismo tiempo puede aprender a resolver cada uno de los problemas mejor que un modelo especializado de perfil estrecho!
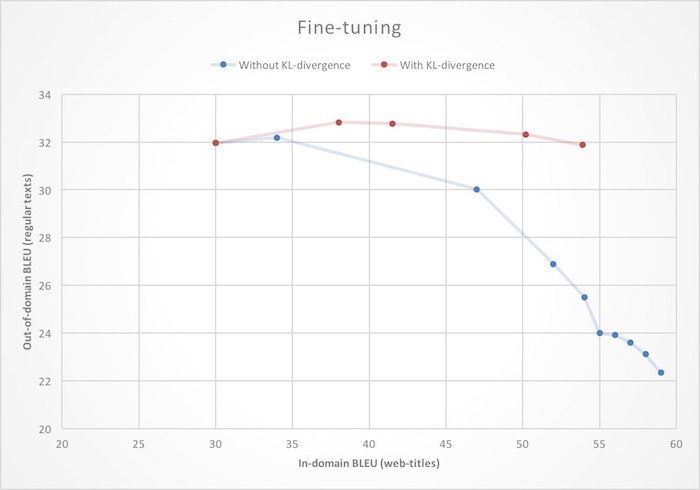
Afinando . Ya teníamos una muy buena traducción automática, por lo que no sería razonable capacitar a un nuevo traductor para Yandex. Es más lógico tomar un sistema básico para traducir textos ordinarios y volver a entrenarlo para trabajar con páginas web. En el contexto de las redes neuronales, esto a menudo se denomina ajuste fino. Pero si aborda esta tarea de frente, es decir solo para inicializar los pesos de la red neuronal con los valores del modelo terminado y comenzar a aprender sobre nuevos datos, puede encontrar el efecto de un cambio de dominio: a medida que aprenda, la calidad de la traducción de páginas web (dentro del dominio) aumentará, pero la calidad de la traducción de la traducción ordinaria (fuera del dominio) ) los textos caerán. Para deshacerse de esta característica desagradable, durante el reentrenamiento, imponemos una restricción adicional en la red neuronal, prohibiéndole cambiar demasiado los pesos en comparación con el estado inicial.
Matemáticamente, esto se expresa agregando el término a la función de pérdida, que
es la distancia Kullback - Leibler (divergencia KL) entre las distribuciones de probabilidad de la siguiente palabra generada por las redes fuente y reentrenada. Como puede ver en la ilustración, esto lleva al hecho de que el aumento en la calidad de la traducción de páginas web ya no conduce a la degradación de la traducción de texto sin formato.
 Pulido de frases de frecuencia de navegación
Pulido de frases de frecuencia de navegación . En el proceso de trabajar en un nuevo traductor, recopilamos estadísticas sobre los textos de varios segmentos de páginas web y vimos una interesante. Los textos que se relacionan con elementos de navegación están bastante estandarizados, por lo que a menudo son las mismas frases de plantilla. Este es un efecto tan poderoso que más de la mitad de todas las frases de navegación que se encuentran en Internet representan solo 2 mil de las más frecuentes.
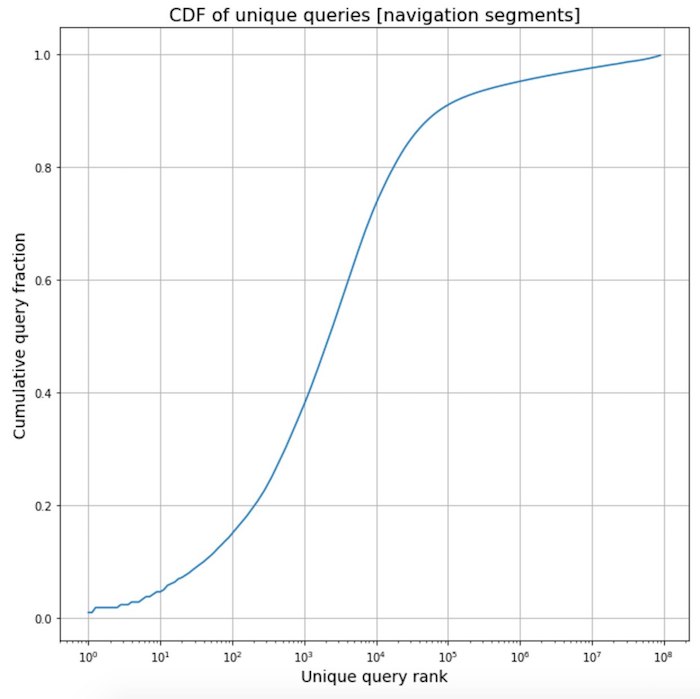
Por supuesto, aprovechamos esto y dimos varios miles de las frases más frecuentes y sus traducciones a nuestros traductores para que la verificación sea absolutamente segura de su calidad.
Alineamientos externos. Había otro requisito importante para un traductor de páginas web en el navegador: no debía distorsionar el marcado. Cuando las etiquetas HTML se encuentran fuera de las oraciones o en sus bordes, no surgen problemas. Pero si hay, por ejemplo,
dos palabras subrayadas dentro de la oración, entonces en la traducción queremos ver "dos palabras
subrayadas ". Es decir Como resultado de la transferencia, se deben cumplir dos condiciones:
- El fragmento subrayado en la traducción debe corresponder al fragmento subrayado en el texto fuente.
- No se debe violar la coherencia de la traducción en los bordes del fragmento subrayado.
Para garantizar este comportamiento, primero traducimos el texto como de costumbre, y luego, utilizando modelos estadísticos de
alineación palabra por
palabra, determinamos la correspondencia entre los fragmentos del texto original y el traducido. Esto ayuda a comprender qué se debe enfatizar (resaltar en cursiva, formatear como hipervínculo, ...).
Observador de intersección . Los poderosos modelos de traducción de redes neuronales que capacitamos requieren significativamente más recursos informáticos en nuestros servidores (tanto CPU como GPU) que los modelos estadísticos de generaciones anteriores. Al mismo tiempo, los usuarios no siempre leen las páginas hasta el final, por lo que parece innecesario enviar todo el texto de las páginas web a la nube. Para ahorrar recursos del servidor y el tráfico de usuarios, le enseñamos al traductor a usar la
API de Intersection Observer para enviar solo el texto que se muestra en la pantalla para la traducción. Debido a esto, pudimos reducir el consumo de tráfico para la traducción en más de 3 veces.
Algunas palabras sobre los resultados de la introducción de un traductor de red neuronal que tiene en cuenta la estructura de las páginas web en Yandex.Browser. Para evaluar la calidad de las traducciones, utilizamos la métrica BLEU *, que compara las traducciones realizadas por una máquina y un traductor profesional, y evalúa la calidad de la traducción automática en una escala del 0 al 100%. Cuanto más cercana sea la traducción automática a la traducción humana, mayor será el porcentaje. Por lo general, los usuarios notan un cambio de calidad cuando la métrica BLEU crece al menos un 3%. El nuevo traductor Yandex.Browser mostró un aumento de casi el 18%.

La traducción automática es una de las tareas más complejas, calientes e investigadas en el campo de las tecnologías de inteligencia artificial. Esto se debe a su atractivo puramente matemático y su relevancia en el mundo moderno, donde cada segundo se crea una increíble cantidad de contenido en Internet en varios idiomas. La traducción automática, que hasta hace poco causaba principalmente risas (recuerde a
los fabricantes de mouse ), hoy en día ayuda a los usuarios a superar las barreras del idioma.
La calidad ideal aún está muy lejos, por lo que continuaremos avanzando a la vanguardia de la tecnología en esta dirección para que los usuarios de Yandex.Browser puedan ir más allá, por ejemplo, Runet y encontrar contenido útil para sí mismos en cualquier lugar de Internet.