La visión artificial es un tema muy candente en estos días. Para resolver el problema de reconocer etiquetas de tienda utilizando redes neuronales, elegimos el marco TensorFlow.
El artículo discutirá exactamente cómo usarlo para localizar e identificar varios objetos en la misma etiqueta de precio de la tienda, así como para reconocer su contenido.
Una tarea similar de reconocer las etiquetas de precio de IKEA ya se ha resuelto en Habré utilizando las herramientas de procesamiento de imágenes clásicas disponibles en la biblioteca OpenCV.
Por separado, me gustaría señalar que la solución puede funcionar tanto en la plataforma SAP HANA junto con Tensorflow Serving como en la plataforma SAP Cloud Platform.
La tarea de reconocer el precio de los bienes es relevante para los compradores que desean "manipular" los precios entre ellos y elegir una tienda para compras, y para los minoristas: quieren conocer los precios de los competidores en tiempo real.
Enough lyrics - ve a la técnica!
Kit de herramientasPara la detección y clasificación de imágenes, utilizamos redes neuronales convolucionales implementadas en la biblioteca TensorFlow y disponibles para el control a través de la API de detección de objetos.
La API de detección de objetos TensorFlow es un metaframe de código abierto basado en TensorFlow que simplifica la creación, capacitación y despliegue de modelos para la detección de objetos.
Después de detectar el objeto deseado, el reconocimiento de texto se llevó a cabo utilizando Tesseract, una biblioteca para el reconocimiento de caracteres. Desde 2006, Tesseract se considera una de las bibliotecas de OCR más precisas disponibles en código abierto.
Es posible que haga una pregunta: ¿por qué no todo el procesamiento se realiza en TF? La respuesta es muy simple: requeriría mucho más tiempo para la implementación, pero no hubo mucho de todos modos. Era más fácil sacrificar la velocidad de procesamiento y ensamblar un prototipo terminado que molestarse con un OCR casero.
Creación y preparación de un conjunto de datos.Para empezar, era necesario recolectar materiales para el trabajo. Visitamos 3 tiendas y tomamos alrededor de 400 fotos de diferentes etiquetas de precios en una cámara de teléfono móvil en modo automático
Fotos de muestra: Fig. 1. Ejemplo de una imagen de etiqueta de precio
Fig. 1. Ejemplo de una imagen de etiqueta de precio Fig. 2. Ejemplo de imagen de etiqueta de precio
Fig. 2. Ejemplo de imagen de etiqueta de precioDespués de eso, debe procesar y marcar todas las fotos de las etiquetas de precio. En el proceso de recopilación de imágenes, tratamos de recopilar imágenes de alta calidad (sin artefactos): etiquetas de precio de aproximadamente el mismo formato, sin desenfoque, rotaciones significativas, etc. Esto se hizo para facilitar una mayor comparación del contenido en la etiqueta de precio real y su imagen digital. Sin embargo, si entrenamos la red neuronal solo en las imágenes de alta calidad disponibles, esto conducirá muy naturalmente al hecho de que la confianza del modelo en la identificación de ejemplos distorsionados disminuirá significativamente. Con el fin de entrenar a la red neuronal para que sea resistente a tales situaciones, utilizamos el conocido procedimiento para expandir el conjunto de entrenamiento con versiones distorsionadas de imágenes (aumento). Para complementar la muestra de entrenamiento, aplicamos algoritmos de la biblioteca Imgaug: turnos, giros pequeños, desenfoque gaussiano, ruido. Se agregaron imágenes distorsionadas a la muestra, lo que la aumentó en aproximadamente 5 veces (de 300 a 1.500 imágenes).
Para marcar la imagen y seleccionar objetos, se utilizó el programa LabelImg, que está disponible en el dominio público. Le permite seleccionar los objetos necesarios en la imagen con un rectángulo y asignar cada clase al cuadro delimitador. Todas las coordenadas y etiquetas de los marcos creados para cada foto se guardan en un archivo XML separado.
Los siguientes objetos se destacaron en cada foto: etiqueta de precio del producto, precio del producto, nombre del producto y código de barras del producto en la etiqueta del precio. En algunos ejemplos de imágenes, donde estaba lógicamente justificado, las áreas estaban marcadas con superposición.
 Fig. 3. Un ejemplo de una fotografía de un par de etiquetas de precio marcadas en LabelImg. Se resaltan las áreas con descripción del producto, precio y código de barras.
Fig. 3. Un ejemplo de una fotografía de un par de etiquetas de precio marcadas en LabelImg. Se resaltan las áreas con descripción del producto, precio y código de barras. Fig. 4. Un ejemplo de una fotografía de una etiqueta de precio marcada en LabelImg. Se resaltan las áreas con descripción del producto, precio y código de barras.
Fig. 4. Un ejemplo de una fotografía de una etiqueta de precio marcada en LabelImg. Se resaltan las áreas con descripción del producto, precio y código de barras.Después de que todas las fotos hayan sido procesadas y marcadas, preparamos el conjunto de datos con la separación de todas las fotos y archivos de etiquetas en una muestra de entrenamiento y prueba. Por lo general, tome el 80% de la muestra de entrenamiento al 20% de la muestra de prueba y mezcle al azar.
Luego, en la máquina donde se entrenará el modelo, es necesario instalar todas las bibliotecas necesarias. En primer lugar, instalamos la biblioteca de aprendizaje automático TensorFlow. Dependiendo del tipo de su sistema y necesita instalar una biblioteca adicional para computar en la GPU. A continuación, instale la biblioteca de la API de detección de objetos de Tensorflow y bibliotecas adicionales para trabajar con imágenes y gráficos. A continuación hay una lista de bibliotecas que utilizamos en nuestro trabajo:
TensorFlow-GPU v1.5, CUDA v9.0, cuDNN v7.0
Protobuf 3+, Python-tk, Pillow 1.0, lxml, tf Slim, cuaderno Jupyter, Matplotlib
Tensorflow, Cython, Cocoapi; Opencv-python; PandasCuando se completen todos los pasos de instalación, puede proceder a preparar los datos y establecer los parámetros de aprendizaje.
Entrenamiento modeloPara resolver nuestro problema, utilizamos dos versiones de la red neuronal pre-entrenada MobileNet V2 y Faster-RCNN V2 en el conjunto de datos de coco como extractores de propiedades de imagen. Los modelos fueron reentrenados en 4 nuevas clases: etiqueta de precio, descripción del producto, precio, código de barras. Como el principal, elegimos MobileNet V2, que es un modelo relativamente simple que nos permite proporcionar una calidad aceptable a una velocidad agradable. MobileNet V2 le permite implementar el reconocimiento de imágenes incluso en un dispositivo móvil.
Primero, debe informar a la biblioteca de la API de detección de objetos de Tensorflow el número de etiquetas, así como los nombres de estas etiquetas.
Lo último que debe hacer antes de entrenar es crear un mapa de acceso directo y editar el archivo de configuración. El mapa de etiquetas informa el modelo y asigna los nombres de clase a los números de identificador de clase para cada objeto.

Finalmente, debe configurar las fuentes de aprendizaje para la detección de objetos para determinar qué modelo y qué parámetros se utilizarán para la capacitación. Este es el último paso antes de comenzar a entrenar.

El procedimiento de entrenamiento se inicia con el comando:
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/mobilenet.config
Si todo está configurado correctamente, TensorFlow inicializa el reentrenamiento de la red neuronal. La inicialización puede tardar hasta 30 segundos antes de que comience el entrenamiento real. A medida que la red neuronal se vuelve a entrenar en cada paso, se mostrará el valor de la función de error del algoritmo (pérdida). Para MobileNet V2, el valor inicial de la función de pérdida es de aproximadamente 20. El modelo debe entrenarse hasta que la función de pérdida caiga a un valor de aproximadamente 2. Para visualizar el proceso de aprendizaje de la red neuronal, puede usar la práctica utilidad TensorBoard.
: tensorboard
El comando inicializa la interfaz web en la máquina local, que estará disponible en localhost: 6006. Después de detenerse, el procedimiento de entrenamiento se puede reanudar más tarde utilizando puntos de control que se guardan cada 5 minutos.
Reconocimiento de etiquetas de precio y sus elementos.Cuando se completa el entrenamiento, el último paso es crear un gráfico de red neuronal. Esto se realiza mediante el comando de consola, donde debajo de los asteriscos debe especificar la mayor cantidad de archivos cpkt existentes en el directorio de capacitación.
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2.config --trained_checkpoint_prefix training/model.ckpt-**** --output_directory inference_graph
Después de este procedimiento, el clasificador de detección de objetos está listo para funcionar. Para verificar el reconocimiento de imágenes, es suficiente ejecutar un script que viene con la biblioteca de detección de objetos de Tensorflow que indica el modelo que se entrenó previamente y las fotos para el reconocimiento.
Aquí se proporciona un ejemplo de script Python estándar.
En nuestro ejemplo, lleva aproximadamente 1,5 segundos reconocer una foto usando el modelo ssd mobilenet en una computadora portátil simple.
 Fig. 5. El resultado del reconocimiento de imágenes con etiquetas de precio en la muestra de prueba
Fig. 5. El resultado del reconocimiento de imágenes con etiquetas de precio en la muestra de prueba Fig. 6. El resultado del reconocimiento de imágenes con etiquetas de precio en la muestra de prueba
Fig. 6. El resultado del reconocimiento de imágenes con etiquetas de precio en la muestra de pruebaCuando estamos convencidos de que las etiquetas de precios se detectan normalmente, es necesario enseñar al modelo a leer información de elementos individuales: el precio de los productos, el nombre de los productos y un código de barras. Para esto, hay bibliotecas disponibles en Python para reconocer caracteres y códigos de barras en fotografías: Pyzbar y Tesseract.
Antes de comenzar a reconocer caracteres y códigos de barras en una foto, debe cortar esta foto en los elementos que necesitamos, para aumentar la velocidad y no reconocer información innecesaria que no está incluida en el precio. También es necesario "extraer" las coordenadas de los objetos que el modelo reconoció junto con sus clases.

Luego usamos estas coordenadas para cortar nuestra foto en partes para reconocer solo el área necesaria.


 Fig. 7. Un ejemplo de partes resaltadas de la etiqueta de precio
Fig. 7. Un ejemplo de partes resaltadas de la etiqueta de precioA continuación, transferimos todas las áreas recortadas a las bibliotecas: el nombre del producto y el precio del producto se transfieren a tesseract, y el código de barras a pyzbar, y obtenemos el resultado del reconocimiento.

 Fig. 8. Un ejemplo de contenido reconocido es el área de etiqueta de precio.
Fig. 8. Un ejemplo de contenido reconocido es el área de etiqueta de precio.En este punto, el reconocimiento de texto y código de barras puede causar problemas si la imagen original estaba en baja resolución o borrosa. Si el precio puede reconocerse normalmente debido a los grandes números en la etiqueta de precio, entonces el nombre del producto y el código de barras estarán mal definidos o no estarán definidos en absoluto. Para hacer esto, se recomienda no usar fotos pequeñas para el reconocimiento, y también subir imágenes sin ruido y una fuerte distorsión, por ejemplo, sin la falta de enfoque adecuado.
Ejemplo de mal reconocimiento de imagen:



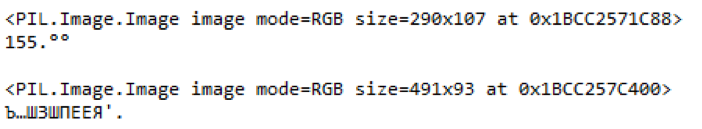 Fig. 9. Un ejemplo de partes resaltadas de una etiqueta de precio borrosa y contenido reconocido
Fig. 9. Un ejemplo de partes resaltadas de una etiqueta de precio borrosa y contenido reconocidoEn este ejemplo, puede ver que si el precio de los productos se reconoce más o menos correctamente en la imagen de mala calidad, la biblioteca no podría hacer frente al nombre de los productos. Y el código de barras no está sujeto a reconocimiento en absoluto.
El mismo texto en buena calidad.

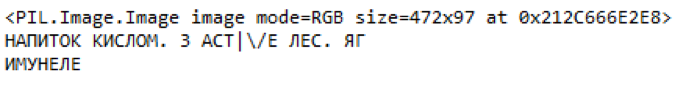 Fig. 10. Ejemplo de partes destacadas de etiquetas de precio y contenido reconocidoConclusiones
Fig. 10. Ejemplo de partes destacadas de etiquetas de precio y contenido reconocidoConclusionesAl final, logramos obtener un modelo de calidad aceptable con un bajo porcentaje de errores y un alto porcentaje de detección de objetos relevantes. Faster-RCNN Inception V2 tiene una mejor calidad de reconocimiento que MobileNet SSD V2, pero tiene un orden de magnitud inferior en velocidad, lo cual es una limitación significativa.
La precisión obtenida del reconocimiento de etiqueta de precio en una muestra retrasada de 50 imágenes es del 100%, es decir, todas las etiquetas de precio se identificaron con éxito en todas las fotos. La precisión de reconocimiento de áreas con código de barras y precio fue del 90%. La precisión del reconocimiento del área de texto es del 85%. La precisión de la lectura de precios fue de aproximadamente el 95%, y el texto - 80-85%. Además, como experimento, presentamos el resultado del reconocimiento de la etiqueta de precio, que es completamente diferente de las etiquetas de precio en la muestra de capacitación.
 Fig. 11. Un ejemplo de reconocimiento de etiquetas de precio atípicas que no están en el conjunto de capacitación.
Fig. 11. Un ejemplo de reconocimiento de etiquetas de precio atípicas que no están en el conjunto de capacitación.Como puede ver, incluso con etiquetas de precio que son significativamente diferentes de las etiquetas de precio de capacitación, los modelos no están exentos de errores, pero se pueden reconocer objetos significativos en la etiqueta de precio.
¿Qué más se puede hacer?1) Recientemente se ha publicado un artículo interesante sobre el aumento automático, cuyo enfoque se puede utilizar
2) El modelo entrenado terminado puede y debe estar sustancialmente comprimido
3) Ejemplos de publicación de servicios terminados en SCP y TFS
Al preparar el prototipo y este artículo, se utilizaron los siguientes materiales:1.
Trayendo Machine Learning (TensorFlow) a la empresa con SAP HANA2.
SAP Leonardo ML Foundation - Traiga su propio modelo (BYOM)3.
TensorFlow Object Detection Repositorio de GitHub4.
Artículo de reconocimiento de cheques de IKEA5.
Artículo sobre los beneficios de MobileNet6.
Artículo de detección de objetos TensorFlowEl artículo fue preparado por:
Sergey Abdurakipov, Dmitry Buslov, Alexey Khristenko