 Foto: Alexander Korolkov / WG
Foto: Alexander Korolkov / WGEl 3 de junio, en el último día del Festival del Libro de Moscú en la Plaza Roja, el lingüista
Alexander Pipersky habló sobre lingüística informática. Habló sobre traducciones automáticas, redes neuronales, mapeo vectorial de palabras y planteó preguntas sobre los límites de la inteligencia artificial.
Diferentes personas escucharon la conferencia. A mi derecha, por ejemplo, una turista china le picoteó la nariz. Alexander, por supuesto, también entendió: un par de números adicionales, fórmulas y palabras sobre algoritmos, y la gente huiría a la siguiente tienda para escuchar a los escritores de ciencia ficción.
Le pedí a Alexander que preparara para Habr la "versión de director" de la conferencia, donde no se recortaba nada que pudiera calmar a los turistas al azar. Después de todo, la mayoría de la presentación carecía de una audiencia con preguntas sensatas y, en general, una buena discusión. Creo que podemos desarrollarlo aquí.
¿Dónde comienza la IA?
Desde hace poco, nos comunicamos constantemente con las computadoras en voz, y todo tipo de voz de Alice, Alexa y Siri nos responde. Si mira desde un lado, parece que la computadora nos comprende, entrega listas de sitios relevantes, informa la dirección del restaurante más cercano e indica cómo llegar.
Parece que estamos tratando con un dispositivo bastante inteligente. Incluso podría decir que este dispositivo tiene lo que se llama inteligencia artificial (IA). Aunque nadie realmente entiende lo que esto significa y hacia dónde van las fronteras.
Cuando se nos dice, "la IA realiza funciones creativas que se consideran prerrogativas del hombre", ¿qué significa? ¿Qué son las características creativas? ¿Qué función es creativa y cuál no? ¿Elegir el restaurante chino más cercano es una característica creativa? Ahora parece que lo más probable es que no.
Estamos constantemente inclinados a negar la inteligencia artificial a una computadora. Tan pronto como nos acostumbramos a las manifestaciones intelectuales que hace una computadora, decimos: "esto no es IA, esto es una completa tontería, tareas de plantilla, nada interesante".
Un ejemplo simple: desde nuestro punto de vista, no hay nada más tonto que una calculadora de bolsillo. Se vende en cualquier puesto por 50 rublos. Tome la calculadora habitual de ocho bits, presione los botones y obtenga el resultado en segundos. Bueno, piensas, él piensa algunas cosas. Esto no es inteligencia.
E imagina una máquina así en el siglo XVIII. Parecería un milagro, porque el cálculo era prerrogativa del hombre.
Lo mismo sucede con la lingüística informática. Tendemos a despreciar todos sus logros. Entro en Google una consulta "Versículos de Pushkin", encuentra una página que dice "A.S. Pushkin - Poemas ". Parecería que esto? Comportamiento absolutamente normal. Pero los lingüistas informáticos tuvieron que pasar docenas de años para que la palabra poema se encontrara en la palabra poemas, para que la palabra Pushkin se encontrara en la palabra Pushkin y no se encontrara en Pushkin.
Ajedrez por computadora y traducción automática
La lingüística informática nació al mismo tiempo que el ajedrez informático, y el ajedrez también fue una prerrogativa del hombre. Claude Shannon, uno de los fundadores de la informática, escribió
un artículo en 1950
sobre cómo programar una computadora para jugar al ajedrez. Según él, podemos desarrollar dos tipos de estrategias.
A - con búsqueda exhaustiva de secuelas. Es necesario probar todos los movimientos posibles en cada etapa.
B: repita solo las extensiones que se evalúan como prometedoras.
La persona, obviamente, usa la estrategia B. El gran maestro, muy probablemente, pasa por las opciones que son razonables en su opinión, y en un tiempo bastante rápido da un buen movimiento.
La estrategia A es difícil de implementar. Según el cálculo de Shannon, para contar tres movimientos, debe ordenar 10
9 opciones, y si la posición se estima en un microsegundo (que era súper optimista a mediados del siglo XX), le llevará 17 minutos hacer un movimiento. Y tres movimientos hacia adelante es una profundidad de predicción insignificante.
Toda la historia posterior del ajedrez consiste en el desarrollo de técnicas que nos permitirán no resolver todo, sino comprender lo que se debe resolver y lo que no se necesita. Y la victoria sobre el hombre ya se ha logrado, finalmente e irrevocablemente. La computadora pasó por alto al campeón mundial de ajedrez hace unos 20 años, y desde entonces solo ha mejorado.
El mejor programa fue considerado Stockfish. El año pasado, AlphaZero jugó 100 juegos con ella.
| Los blancos | Negro | Victoria blanca | Dibujar | Victoria del negro |
|---|
| AlphaZero | Stockfish | 25 | 25 | 0 0 |
| Stockfish | AlphaZero | 0 0 | 47 | 3 |
AlphaZero es una red neuronal artificial que solo jugó ajedrez durante cuatro horas consigo misma. Y aprendió a jugar mejor que todos los programas anteriores.
Algo similar está sucediendo ahora en la lingüística informática: un aumento en el modelado de redes neuronales. Comenzaron a trabajar en ajedrez automático simultáneamente con traducciones automáticas, a mediados del siglo pasado. Desde entonces, se han distinguido tres etapas de desarrollo.
- Traducción automática basada en reglasEstá diseñado de manera muy simple: algo así como en las lecciones de gramática, la computadora selecciona el tema, el predicado y la suma. Entiende con qué palabras todo esto se traduce a otro idioma, aprende a expresar allí sujeto, predicado, suma y todo.
Dicha traducción se desarrolló durante 30 años, sin tener mucho éxito.
- Traducción estadística (frase)La computadora se basa en una gran base de datos de textos traducidos por humanos. Selecciona las palabras y frases que corresponden a las palabras y frases del original, las recoge en oraciones en el idioma de destino y da el resultado.
Cuando están en Internet escriben sobre las próximas “20 traducciones automáticas más estúpidas”, lo más probable es que se trate de traducción de frases. Aunque logró algo de éxito.
- Traducción de red neuronalHablaremos más sobre él. Entró en uso masivo ante nuestros ojos: Google activó la traducción de redes neuronales a finales de 2016. Para Rusia, apareció en marzo de 2017. Yandex lanzó a finales de 2017 un sistema híbrido basado en redes neuronales y estadísticas.
Redes neuronales
La traducción de la red neuronal se basa en la siguiente idea: si simula matemáticamente y reproduce el trabajo de las neuronas en la cabeza de una persona, se puede suponer que una computadora aprenderá a trabajar con un idioma como una persona.
Para hacer esto, eche un vistazo a las células en el cerebro humano.
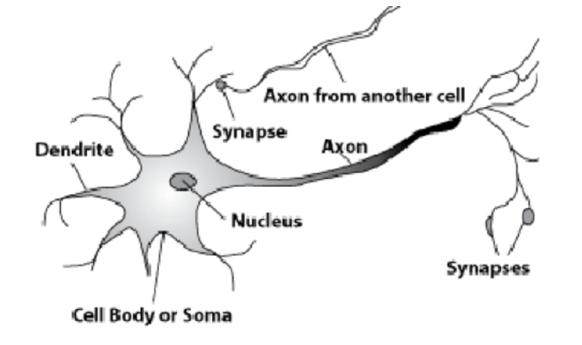
Aquí hay una neurona natural. Un proceso largo, un axón, parte del núcleo. Se adhiere a procesos de otras células: sinapsis. Según los axones, la información sobre algunos procesos electroquímicos se transmite a las sinapsis de las células celulares. Solo un axón emerge de cada celda, y pueden entrar muchas sinapsis. Las señales se propagan, y así es como se transmite la información.
Algunas células están conectadas al mundo exterior. Reciben señales que son procesadas por la red neuronal.
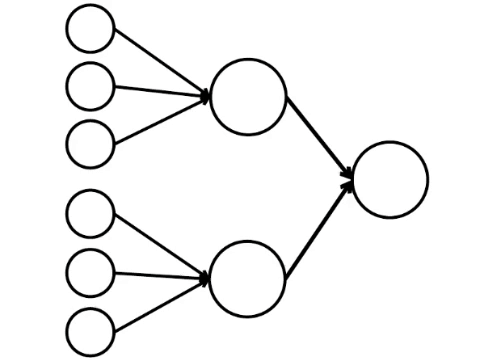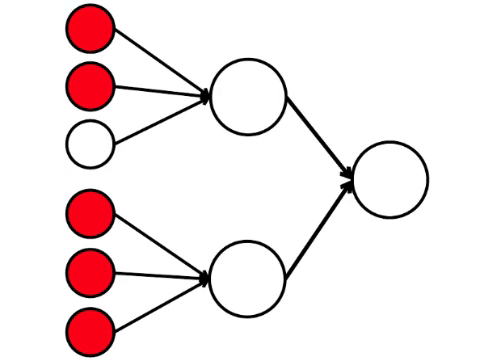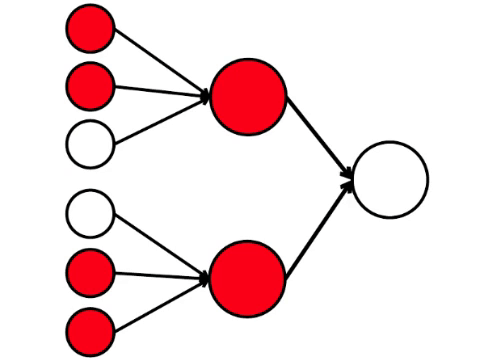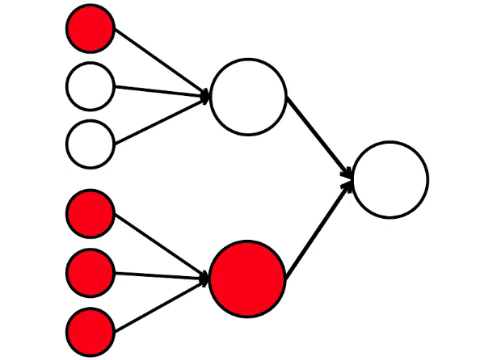
Y aquí está el modelo matemático más simple de lo que podemos hacer aquí. Dibujé nueve círculos conectados. Estas son las neuronas.

Las seis neuronas de la izquierda son la capa de entrada, que recibe una señal del entorno externo. Las neuronas de la segunda y tercera capa no tocan el medio ambiente, sino solo con otras neuronas. Introducimos la regla: si al menos dos flechas de las neuronas activadas ingresan a la neurona, entonces esta neurona también se activa.
La red neuronal procesa la señal recibida en la entrada y, en última instancia, la salida derecha, la neurona se ilumina o no se ilumina. Con esta arquitectura, para activar la neurona derecha, necesita al menos cuatro neuronas activadas en la fila izquierda. Si 6 o 5 está iluminado, definitivamente se iluminará, si de 0 a 3, definitivamente no se iluminará. Pero si se queman cuatro, entonces se iluminará solo si se distribuyen uniformemente: 2 en la mitad superior y 2 en la inferior.
Resulta que el esquema más simple de nueve círculos conduce a un argumento bastante ramificado.
Las redes neuronales artificiales funcionan de la misma manera, pero generalmente no con cosas tan simples como "iluminado / no iluminado" (es decir, 1 o 0), sino con números reales.
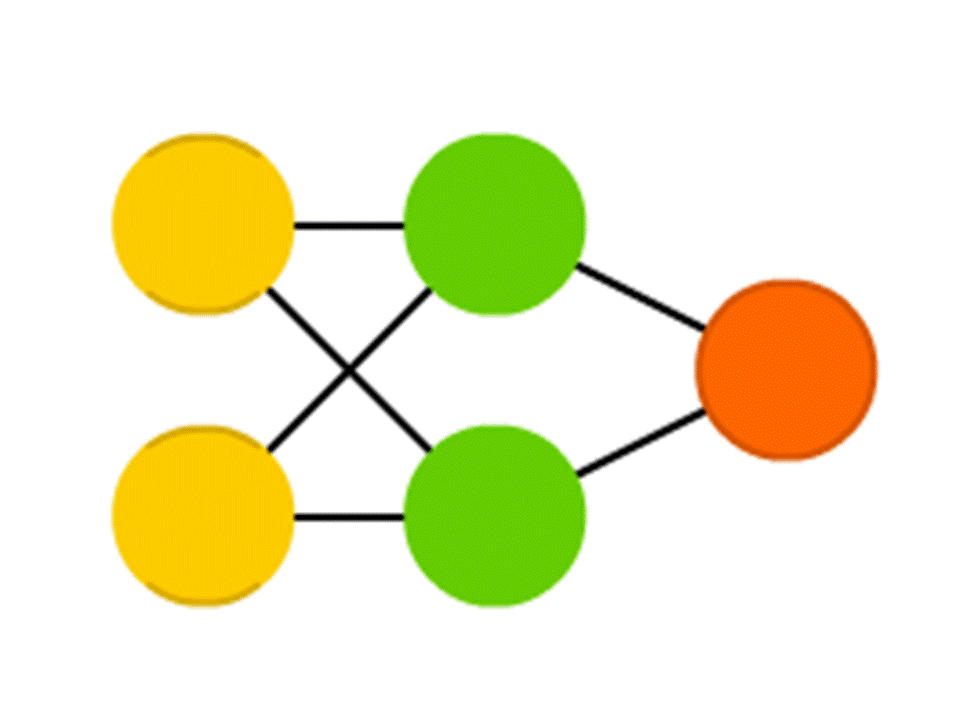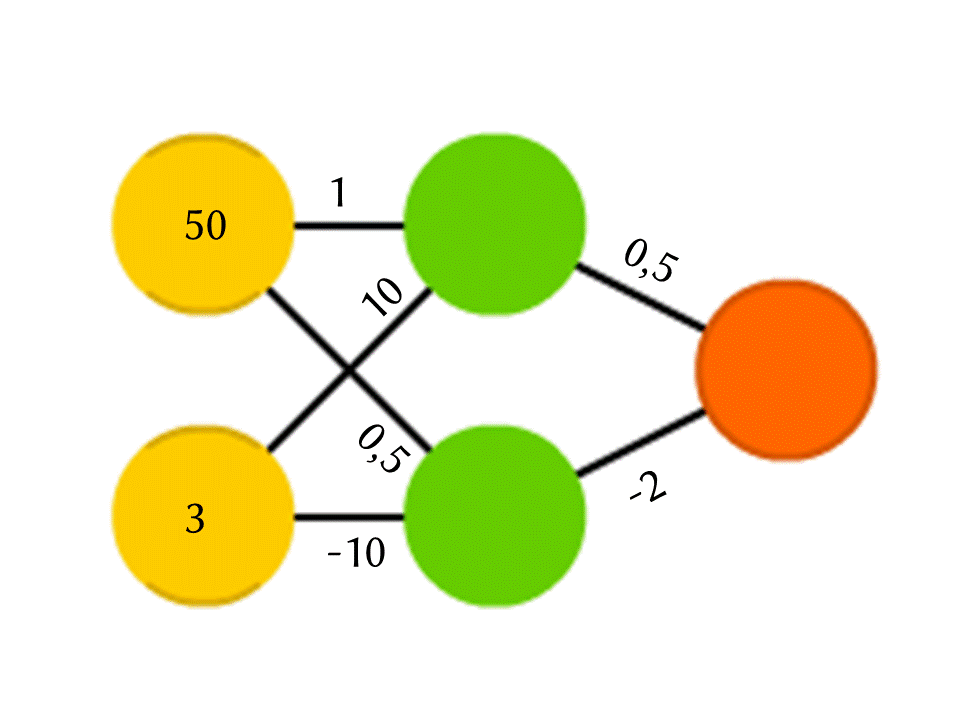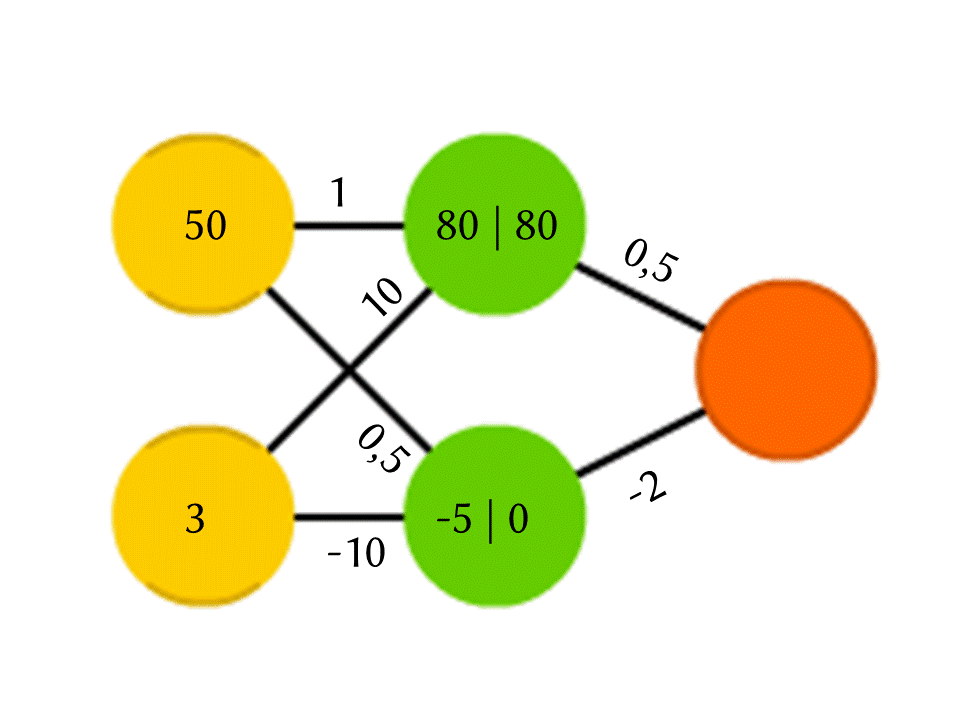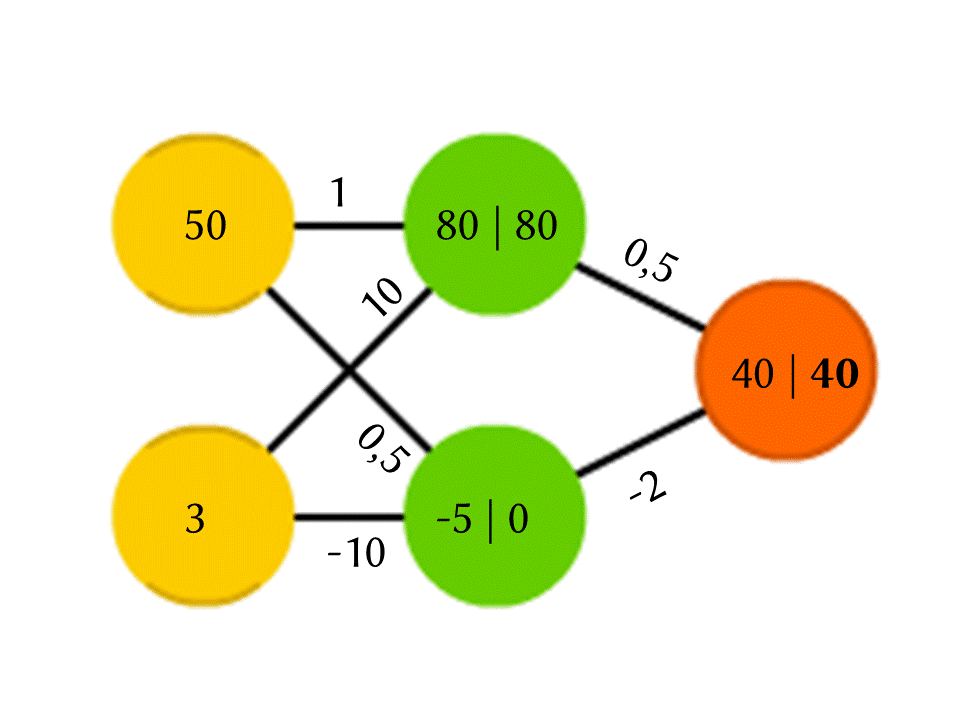
Tomemos, por ejemplo, una red de 5 neuronas: dos en la capa de entrada, dos en el medio (ocultas) y una en la salida. Entre todas las neuronas de las capas vecinas hay conexiones a las que se asignan números: pesos. Para averiguar qué sucede en una neurona aún vacía, hagamos algo muy simple: veamos qué conexiones conducen a ella, multipliquemos el peso de cada conexión por el número que está escrito en la neurona de la capa anterior de la que proviene esta conexión, y resumiremos todo esto. En la neurona verde superior en el diagrama, se obtiene 50 × 1 + 3 × 10 = 80, y en la inferior - 50 × 0.5 - 3 × 10 = −5.
Es cierto, si hace exactamente eso, la salida será simplemente el resultado de calcular una función lineal de los valores de entrada (en nuestro ejemplo, saldrá 25 Y - 0.5 X, donde X es el número en la neurona amarilla superior e Y está en la inferior), por lo que estaremos de acuerdo Algo más está sucediendo dentro de la neurona. La función más simple y al mismo tiempo que da buenos resultados es ReLU (Unidad lineal rectificada): si se obtiene un número negativo en una neurona, la salida 0, y si no es negativa, la salida no cambia.
Entonces, en nuestro esquema, −5 a la salida de la neurona verde inferior se convierte en 0, y es este número el que se usa en cálculos posteriores. Por supuesto, la arquitectura de las redes neuronales reales utilizadas en la práctica es mucho más complicada que nuestros ejemplos de juguetes, y los pesos no se toman del techo, sino que se seleccionan por entrenamiento, pero el principio en sí mismo es importante.
¿Qué tiene esto que ver con el lenguaje?
El más directo, siempre que representemos el idioma en forma de números. Codificamos cada palabra y nos encontramos con una red neuronal.
Aquí, un logro muy importante de la lingüística informática viene al rescate, que apareció en términos de ideas hace 50 años, y en términos de implementación, los últimos 10 años se han desarrollado activamente: la representación vectorial de palabras.
 esta y las siguientes dos imágenes son de una presentación de Stefan Evert
esta y las siguientes dos imágenes son de una presentación de Stefan EvertEsta es una representación de palabras como una matriz de números basada en una consideración muy simple. Para averiguar el significado de una palabra, no miramos el diccionario, sino una gran variedad de textos y consideramos al lado de qué palabra es más común.
Por ejemplo, ¿conoces la palabra silenciador? Si no, intente adivinar mirando los textos donde la palabra está amortiguada.
- Un abrigo negro y una gorra blanca. Bueno, y todavía algún silenciador indispensable ...
Junto a él hay prendas de vestir, un abrigo y una gorra, y probablemente un silenciador entre ellos. Es apenas comida, apenas un elemento de la arquitectura.
- Por alguna razón, en su cuello en una noche cargada, se roció un silenciador viejo y rayado.
En el cuello, esto significa que no son calcetines. Puede atraparlo: aparentemente es flexible, está hecho de tela y no, por ejemplo, de madera o piedra.
- Una toalla de waffle kutsey húmeda que Nerzhin colgaba de su cuello como un silenciador.
Reabastecemos y reabastecemos el banco de ejemplos y, al mirarlos, comprenderemos gradualmente lo que está amortiguado, algo así como una bufanda. La computadora hace exactamente lo mismo, que mira el texto y hace algo simple: captura las palabras que están cerca.
Aquí están los jeroglíficos egipcios.
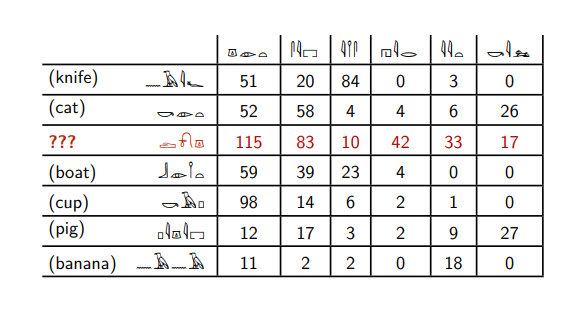
Suponga que conoce los significados de seis de ellos y quiere comprender qué tipo de palabra está resaltada en rojo. Esta tabla dice cuántas veces se encuentran estas palabras junto a otros jeroglíficos egipcios.
La palabra roja aparece con la sexta palabra, al igual que las palabras
gato y
cerdo . Y otras palabras no ocurren con él en absoluto.
La palabra roja se encuentra con la segunda palabra con mucha más frecuencia que con la tercera, en contraste con las palabras
cuchillo y
plátano . Las palabras
gato, bote, cerdo y
copa se comportan igual.
Basado en tal razonamiento, podemos decir que la palabra roja es más similar a las palabras
gato y
cerdo : solo que se encuentran con la sexta palabra, tienen una proporción similar de la segunda y la tercera.
Y no nos equivocaremos, porque la palabra roja es la palabra
perro .

De hecho, estos no son jeroglíficos egipcios, sino sustantivos y verbos en inglés, para los cuales se indica cuántas veces aparecen juntos en una gran colección de textos en inglés. Esa sexta palabra es el verbo
kill .
Las palabras
gato, perro y
cerdo a menudo se encuentran a la derecha de la palabra
matar . Cuchillos, barcos y plátanos rara vez se matan. Aunque en ruso, si lo desea, puede decir: "Maté mi barco", pero esto es algo raro.
Exactamente lo que hace una computadora cuando procesa texto. Simplemente cree que se encuentra con algo, y no más obras maestras de comprensión.
Además, la computadora presenta las palabras en forma de un cierto conjunto de números: en el ejemplo anterior, la palabra
perro corresponde a los números (115; 83; 10; 42; 33; 17). De hecho, debemos calcular cuántas veces ocurre no con seis palabras, sino con todas las palabras que están en nuestros textos: si todos tenemos 100,000 palabras diferentes, entonces asociamos la palabra
perro con una matriz de 100,000 números. Esto no es muy conveniente en la práctica, por lo tanto, los métodos para reducir la dimensión generalmente se utilizan para convertir los resultados de cada palabra en una matriz de varios cientos de elementos de longitud (se puede encontrar más sobre esto
aquí ).
Hay bibliotecas
listas para
usar para los lenguajes de programación que le permiten hacer esto: por ejemplo,
gensim para Python. Al enviarle el
corpus en inglés browniano con un volumen de aproximadamente 1 millón de palabras, en unos segundos puedo construir un modelo en el que la palabra
gato se verá así:

Representamos un animal, con pelo, cola, maúlla. Mi computadora, que enseñé inglés, representa la palabra
gato en forma de cien números que provienen de las palabras a su lado.
Aquí hay un ejemplo en material ruso del
sitio web
RusVectōres . Tomé la palabra
cuervo y le pedí a la computadora que me dijera qué palabras son más similares o, en otras palabras, los conjuntos de números para los que las palabras son más similares al conjunto de números para la palabra
cuervo .

8 de cada 10 palabras resultaron ser nombres de pájaros. Sin saber nada, la computadora produjo un excelente resultado: me di cuenta de que los pájaros parecen un cuervo. Pero, ¿de dónde vienen las palabras al rojo vivo y ruchenka?
Puedes adivinarCon los tres, la palabra blanco a menudo se usa: al calor blanco, debajo de las asas blancas, cuervo blanco.
Al recibir conjuntos de números y pasarlos a través de ellos mismos, las redes neuronales dan un resultado increíblemente bueno. Aquí hay un texto filosófico bastante complicado de un discurso del académico Andrei Zaliznyak sobre el estado de la ciencia en el mundo moderno. Fue traducido al inglés por un traductor hace un mes y requiere una intervención editorial mínima.

Aquí es donde surge la pregunta filosófica global.
Este es el problema de la llamada sala china: un experimento mental sobre los límites de la inteligencia artificial. Fue formulado por el filósofo John Searle en 1980.
En la sala se sienta un hombre que no sabe chino. Le dieron instrucciones, tiene libros, diccionarios y dos ventanas. En una ventana se le dan notas en chino, y en otra ventana da respuestas, también en chino, actuando exclusivamente de acuerdo con las instrucciones.
Por ejemplo, las instrucciones pueden decir: “aquí tienes una nota, busca el personaje en el diccionario. Si es el jeroglífico n. ° 518, coloque el jeroglífico n. ° 409 en la ventana derecha; si el jeroglífico n. ° 711 ha llegado, coloque el jeroglífico n. ° 35 en la ventana derecha y así sucesivamente ". Si la persona en la habitación sigue bien las instrucciones y si estas instrucciones están bien escritas, entonces la persona en la calle que da y recibe notas puede asumir que la habitación o la persona en ella sabe chino. Después de todo, no es visible desde el exterior lo que sucede dentro.
Todos sabemos que este es un hombre al que simplemente se le dieron instrucciones estúpidas. Realiza algunas operaciones con ellos, pero no sabe chino en absoluto. Aunque desde el punto de vista del observador es conocimiento del lenguaje.
La pregunta filosófica: ¿cómo nos relacionamos con esto? ¿La habitación habla chino? ¿Quizás el autor de estas instrucciones conoce el idioma chino? Y tal vez no, porque puede emitir instrucciones basadas en una serie de preguntas y respuestas preparadas.
Por otro lado, ¿qué sabe el chino? Aquí sabes el idioma ruso. Que puedes hacer ¿Qué está pasando en tu cabeza? Algún tipo de reacción bioquímica. Las orejas u ojos reciben una cierta señal, causa algún tipo de reacción, entiendes algo. Pero, ¿qué significa "entender"? ¿Qué haces cuando entiendes?
Y una pregunta aún más complicada: ¿estás haciendo esto de manera óptima? ¿Es cierto que trabaja con el idioma mejor que cualquier máquina con el idioma? ¿Te imaginas que hablarás ruso peor que cualquier computadora? Siempre comparamos a Siri, Alice con la forma en que hablamos nosotros mismos, y nos reímos si hablan incorrectamente desde nuestro punto de vista. Por otro lado, usted y yo le dimos a la computadora mucho de lo que antes se consideraba una prerrogativa del hombre. Ahora los autos son mucho mejores para contar y jugar ajedrez, pero antes no podían. Quizás sucedan cosas similares con las computadoras parlantes: en 100, 10 o incluso 5 años, reconocemos que la máquina ha dominado el idioma mucho mejor, entiende mucho más y, en general, es un hablante nativo mucho mejor que nosotros.
¿Qué hacer entonces con el hecho de que una persona se utiliza para definirse a sí misma a través del lenguaje? Después de todo, dicen que solo una persona habla el idioma. ¿Qué sucederá si reconocemos la victoria en la computadora en esta área?
Deja tus preguntas en los comentarios. Quizás un poco más tarde podamos hacer una entrevista con Alexander. O tal vez él mismo hará un comentario sobre nuestra invitación y hablará con todos los interesados.