 Hola Mi nombre es Marco, trabajo para Badoo en el departamento de Plataforma. Tenemos muchas cosas escritas en Go, y a menudo son críticas para el rendimiento del sistema. Es por eso que hoy te ofrezco una traducción de un artículo que realmente me gustó y, estoy seguro, te será muy útil. El autor muestra paso a paso cómo abordó los problemas de rendimiento y cómo los resolvieron. Incluyendo que se familiarizará con las ricas herramientas disponibles en Go para dicho trabajo. Que tengas una buena lectura!
Hola Mi nombre es Marco, trabajo para Badoo en el departamento de Plataforma. Tenemos muchas cosas escritas en Go, y a menudo son críticas para el rendimiento del sistema. Es por eso que hoy te ofrezco una traducción de un artículo que realmente me gustó y, estoy seguro, te será muy útil. El autor muestra paso a paso cómo abordó los problemas de rendimiento y cómo los resolvieron. Incluyendo que se familiarizará con las ricas herramientas disponibles en Go para dicho trabajo. Que tengas una buena lectura!Hace unas semanas, leí el artículo "
Código bueno contra código malo en Go "
, donde el autor, paso a paso, demuestra la refactorización de una aplicación real que resuelve problemas comerciales reales. Se enfoca en convertir el "código malo" en "código bueno": más idiomático, más comprensible, utilizando plenamente los detalles de Go. Pero el autor también declaró la importancia del rendimiento de la aplicación en cuestión. La curiosidad se apoderó de mí: ¡intentemos acelerarlo!
El programa, en términos generales, lee el archivo de entrada, lo analiza línea por línea y llena los objetos en la memoria.
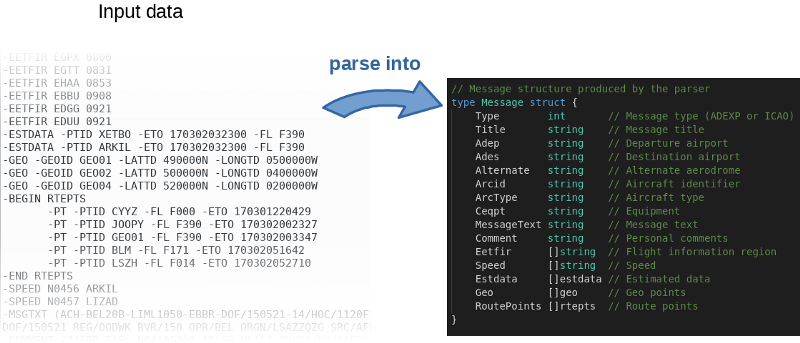
El autor no solo publicó el
código fuente en GitHub , sino que también escribió un punto de referencia. Esta es una gran idea De hecho, el autor invitó a todos a jugar con el código y tratar de acelerarlo. Para reproducir los resultados del autor, use el siguiente comando:
$ go test -bench=.
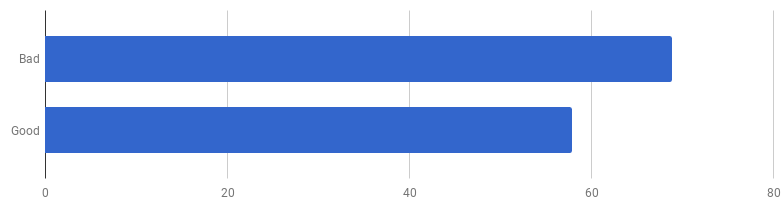 μs por llamada (menos - mejor)
μs por llamada (menos - mejor)Resulta que en mi computadora el "buen código" es un 16% más rápido. ¿Podemos acelerarlo?
En mi experiencia, existe una correlación entre la calidad del código y el rendimiento. Si refactorizó con éxito el código, lo hizo más limpio y menos conectado, probablemente lo hizo más rápido porque se volvió menos abarrotado (y no hay más instrucciones innecesarias que se ejecutaron previamente en vano). Quizás durante la refactorización notó algunas oportunidades de optimización, o ahora solo tiene la oportunidad de aprovecharlas. Pero, por otro lado, si desea que el código sea aún más productivo, probablemente tenga que alejarse de la simplicidad y agregar varios hacks. Realmente ahorras milisegundos, pero la calidad del código se verá afectada: será más difícil leerlo y hablar sobre él, se volverá más frágil y flexible.
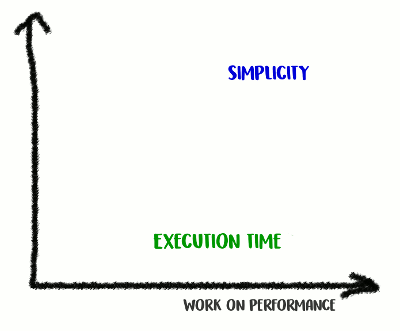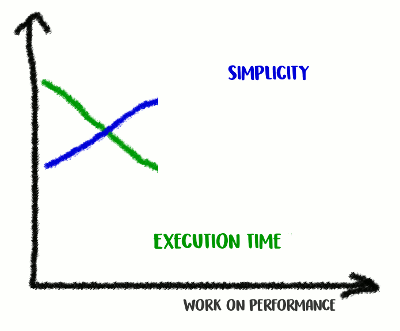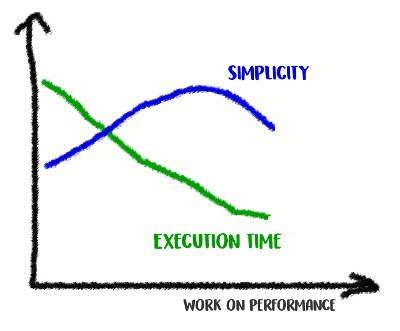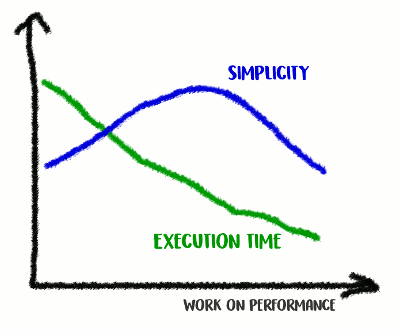 Subimos la montaña de la simplicidad, y luego bajamos de ella
Subimos la montaña de la simplicidad, y luego bajamos de ellaEsto es una compensación: ¿hasta dónde estás dispuesto a llegar?
Para priorizar adecuadamente el trabajo de aceleración, la estrategia óptima es encontrar cuellos de botella y concentrarse en ellos. Para hacer esto, use las herramientas de creación de perfiles.
pprof y
trace son tus amigos:
$ go test -bench=. -cpuprofile cpu.prof $ go tool pprof -svg cpu.prof > cpu.svg
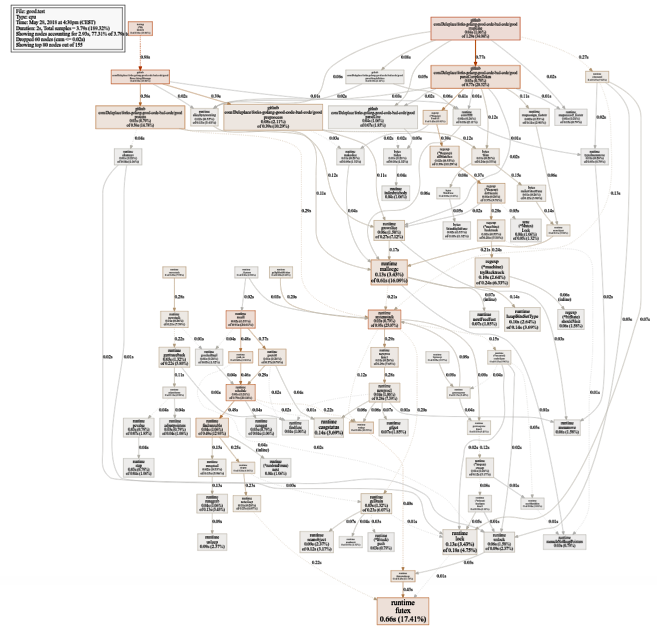 Un gráfico bastante grande del uso de la CPU (haga clic para SVG)
Un gráfico bastante grande del uso de la CPU (haga clic para SVG) $ go test -bench=. -trace trace.out $ go tool trace trace.out
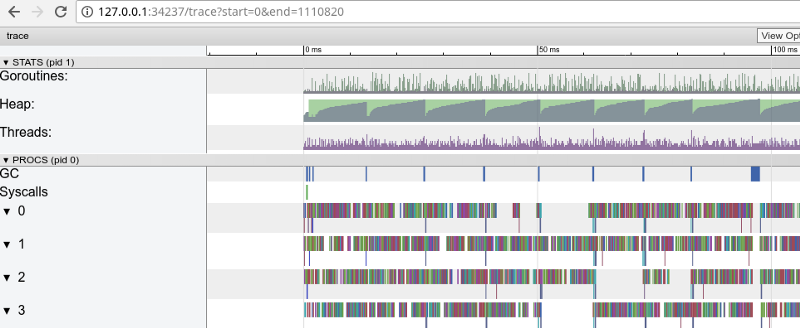 Seguimiento del arco iris: muchas tareas pequeñas (haga clic para abrir, solo funciona en Google Chrome)
Seguimiento del arco iris: muchas tareas pequeñas (haga clic para abrir, solo funciona en Google Chrome)El seguimiento confirma que todos los núcleos de procesador están ocupados (líneas por debajo de 0, 1, etc.) y, a primera vista, esto es bueno. Pero también muestra miles de pequeños "cálculos" de colores y varias áreas vacías donde los núcleos estaban inactivos. Vamos a acercarnos:
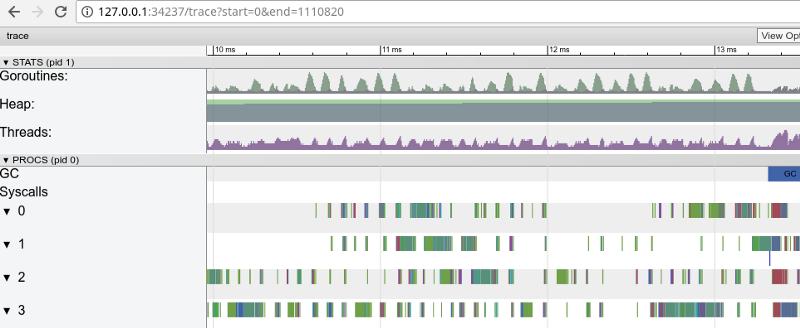 "Ventana" en 3 ms (haga clic para abrir, solo funciona en Google Chrome)
"Ventana" en 3 ms (haga clic para abrir, solo funciona en Google Chrome)Cada núcleo está inactivo durante bastante tiempo y también "salta" entre micro tareas todo el tiempo. Parece que la granularidad de estas tareas no es muy óptima, lo que lleva a una gran cantidad de
cambios de
contexto y a la competencia debido a la sincronización.
Veamos qué nos dice el
detector de vuelo . ¿Hay algún problema en el acceso síncrono a los datos (si hay alguno, entonces tenemos problemas mucho mayores que el rendimiento)?
$ go test -race PASS
Genial Todo esta correcto. No se encontraron vuelos. Las funciones de prueba y las funciones de referencia son funciones diferentes (
consulte la documentación ), pero aquí llaman a la misma función
ParseAdexpMessage , por lo que lo que verificamos para vuelos de datos por pruebas está bien.
El modelo competitivo en la versión "buena" consiste en procesar cada línea desde el archivo de entrada en una rutina diferente (para usar todos los núcleos). La intuición del autor aquí funcionó bien, ya que las gorutinas tienen fama de características fáciles y baratas. Pero, ¿cuánto ganamos con la ejecución paralela? Comparemos con el mismo código pero sin usar goroutines (solo elimine la palabra go que viene antes de la llamada a la función):

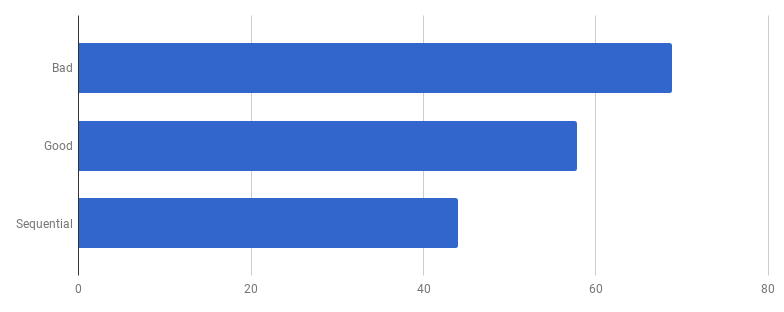
Vaya, parece que el código se ha vuelto más rápido sin usar concurrencia. Esto significa que la sobrecarga (distinta de cero) para lanzar gorutinas excede el tiempo que ganamos al usar varios núcleos al mismo tiempo. El siguiente paso natural debería ser eliminar la sobrecarga (que no sea cero) para usar canales para enviar los resultados. Vamos a reemplazarlo con un corte regular:
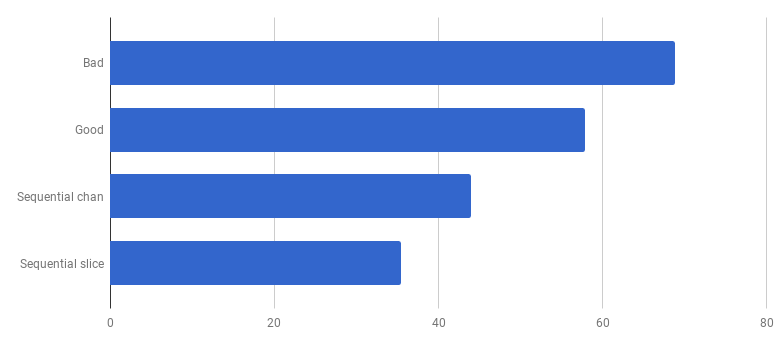 μs por llamada (menos es mejor)
μs por llamada (menos es mejor)Obtuvimos aproximadamente un 40% de aceleración en comparación con la versión "buena", simplificando el código y eliminando la competencia (
diff ).
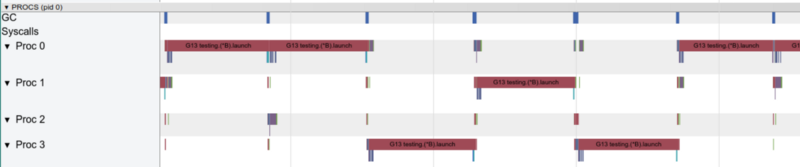 Con una gorutina, solo un núcleo funciona a la vez
Con una gorutina, solo un núcleo funciona a la vezVeamos ahora las funciones activas en el gráfico pprof:
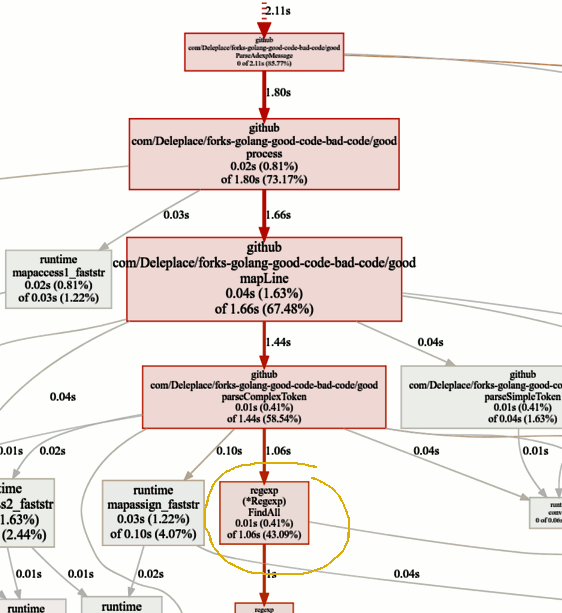 Buscando cuellos de botella
Buscando cuellos de botellaEl punto de referencia de la versión actual (operación secuencial, cortes) pasa el 86% del tiempo analizando mensajes, y esto es normal. Pero notaremos rápidamente que el 43% del tiempo se gasta en usar expresiones regulares y la función
(* Regexp) .FindAll .
A pesar de que las expresiones regulares son una forma conveniente y flexible de obtener datos de texto plano, tienen inconvenientes, incluido el uso de una gran cantidad de recursos y un procesador y memoria. Son una herramienta poderosa, pero a menudo su uso es innecesario.
En nuestro programa, una plantilla
patternSubfield = "-.[^-]*"
Su objetivo principal es resaltar los comandos que comienzan con un guión (-), y puede haber varios en la línea. Esto, después de haber extraído un pequeño código, se puede hacer usando
bytes . Adaptemos el código (
commit ,
commit ) para cambiar las expresiones regulares a Split:
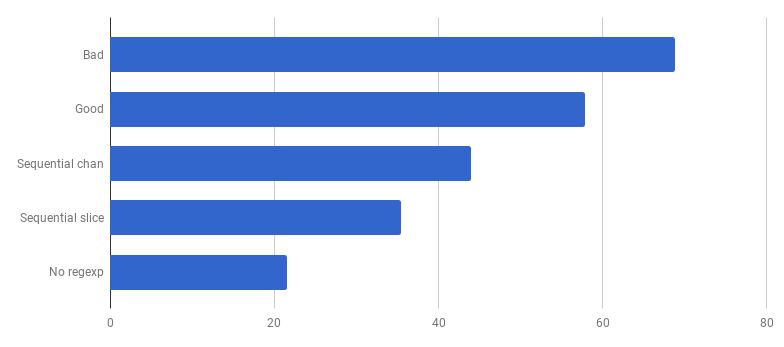 μs por llamada (menos
μs por llamada (menos es
mejor)Wow! ¡Código 40% más productivo! El gráfico de consumo de CPU ahora se ve así:
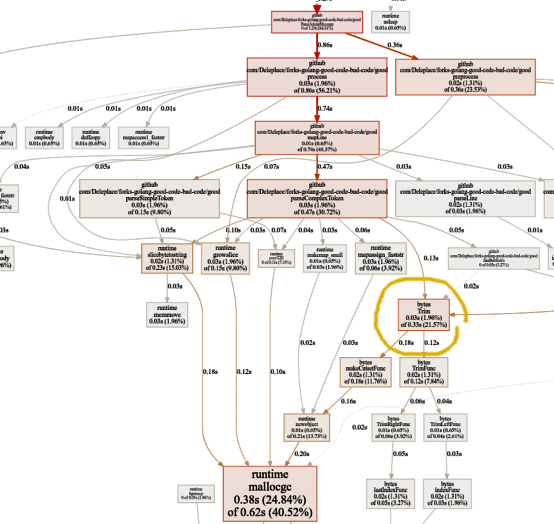
No más tiempo perdido en expresiones regulares. Una parte importante (40%) se destina a la asignación de memoria de cinco funciones diferentes. Curiosamente, ahora el 21% del tiempo se dedica a los
bytes. Función de
recorte :
 Esta característica me intriga. ¿Qué podemos hacer aquí?
Esta característica me intriga. ¿Qué podemos hacer aquí?
bytes.Trim espera una cadena con caracteres que "corta" como argumento, pero como esta cadena pasamos una cadena con un solo carácter: un espacio. Este es solo un ejemplo de cómo puede obtener la aceleración debido a la complejidad: creemos nuestra función de recorte en lugar de la estándar. Nuestra función de
recorte personalizado funcionará con un solo byte en lugar de una línea completa:

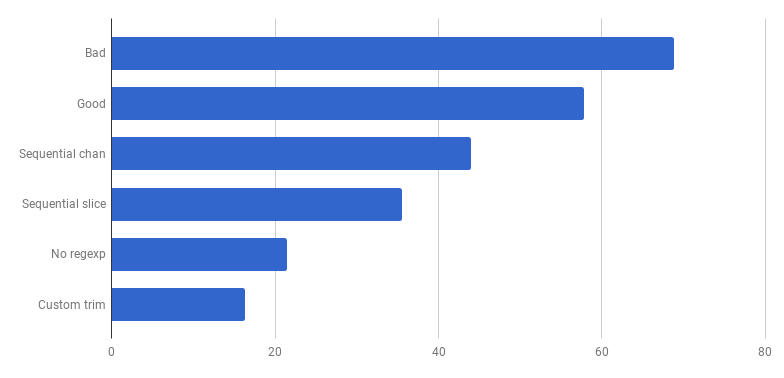 μs por llamada (menos es mejor)
μs por llamada (menos es mejor)¡Hurra, otro 20% de descuento! La versión actual es cuatro veces más rápida que la original "mala" y al mismo tiempo usa solo un núcleo. No esta mal!
Anteriormente, abandonamos la competitividad en el nivel de procesamiento de línea, pero sostengo que la aceleración se puede lograr utilizando la competitividad en un nivel superior. Por ejemplo, procesar 6,000 archivos (6,000 mensajes) es más rápido en mi computadora si cada archivo se procesa en su propia rutina:
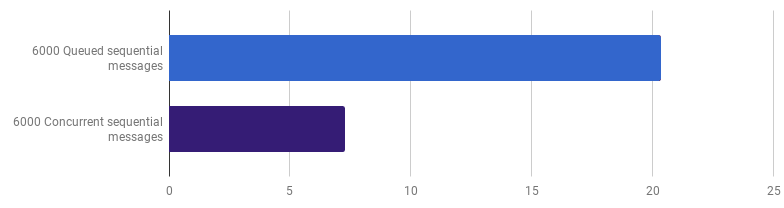 μs por llamada (menos es mejor; el morado es una solución competitiva)
μs por llamada (menos es mejor; el morado es una solución competitiva)La ganancia es del 66% (es decir, aceleración tres veces). Esto es bueno, pero no mucho, teniendo en cuenta que se utilizan los 12 núcleos de procesador que tengo. Esto puede significar que el nuevo código optimizado que procesa todo el archivo sigue siendo una "pequeña tarea", para la cual la sobrecarga para crear gorutinas y el costo de sincronización no son insignificantes. Curiosamente, aumentar el número de mensajes de 6,000 a 120,000 no tiene ningún efecto en la versión de subproceso único y reduce el rendimiento en la versión de "una rutina por mensaje". Esto se debe a que, a pesar del hecho de que crear una cantidad tan grande de gorutinas es posible y a veces útil, trae su propia sobrecarga en el área del
programador de tiempo de
ejecución .
Podemos reducir aún más el tiempo de ejecución (no 12 veces, pero aún así) creando solo unos pocos trabajadores. Por ejemplo, 12 gorutinas de larga vida, cada una de las cuales procesará parte de los mensajes:
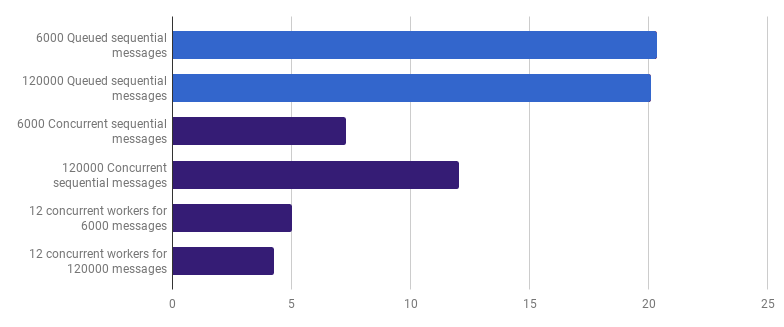 μs por llamada (menos es mejor; el morado es una solución competitiva)
μs por llamada (menos es mejor; el morado es una solución competitiva)Esta opción reduce el tiempo de ejecución en un 79% en comparación con la versión de subproceso único. Tenga en cuenta que esta estrategia solo tiene sentido si tiene muchos archivos para procesar.
El uso óptimo de todos los núcleos de procesador es usar varias gorutinas, cada una de las cuales procesa una cantidad significativa de datos sin ninguna interacción o sincronización antes de que se complete el trabajo.
Por lo general, toman tantos procesos (goroutine) como los núcleos del procesador, pero esta no siempre es la mejor opción: todo depende de la tarea específica. Por ejemplo, si está leyendo algo del sistema de archivos o haciendo muchas llamadas de red, para obtener más rendimiento, debe usar más goroutines que sus núcleos.
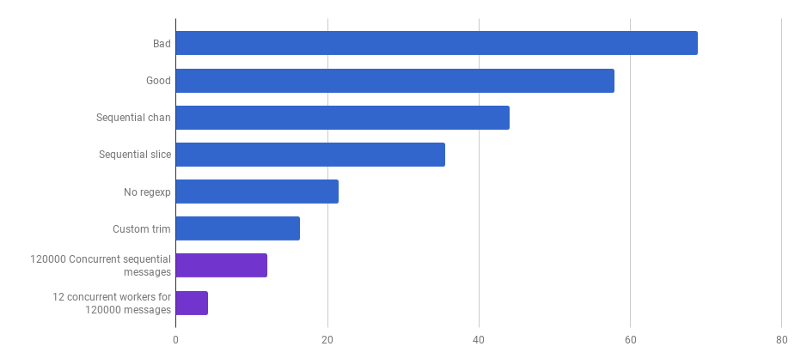 μs por llamada (menos es mejor; el morado es una solución competitiva)
μs por llamada (menos es mejor; el morado es una solución competitiva)Hemos llegado al punto en que el rendimiento del análisis es difícil de aumentar con algunos cambios localizados. El tiempo de ejecución está dominado por el tiempo para la asignación de memoria y la recolección de elementos no utilizados. Esto suena lógico ya que las funciones de administración de memoria son bastante lentas. Una mayor optimización de los procesos asociados con las asignaciones sigue siendo una tarea para los lectores.
El uso de otros algoritmos también puede conducir a una gran ganancia de rendimiento.
Aquí me inspiró una conferencia de Lexical Scanning en Go de Rob Pike,
para crear un lexer personalizado (
fuente ) y un analizador personalizado (
fuente ). Este código aún no está listo (no proceso un montón de casos de esquina), es menos claro que el algoritmo original y, a veces, es difícil escribir el manejo correcto de errores. Pero es pequeño y 30% más rápido que la versión más optimizada.
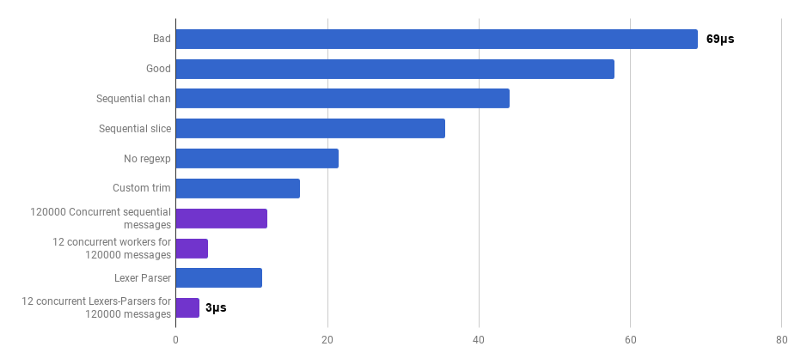 μs por llamada (menos es mejor; el morado es una solución competitiva)
μs por llamada (menos es mejor; el morado es una solución competitiva)Si Como resultado, obtuvimos una aceleración de 23 veces en comparación con el código fuente.
Eso es todo por hoy. Espero que hayas disfrutado esta aventura. Aquí hay algunas notas y conclusiones:
- La productividad se puede mejorar en varios niveles de abstracción, utilizando diferentes técnicas, y la ganancia a menudo se incrementa.
- El ajuste debe comenzar con abstracciones de alto nivel: estructuras de datos, algoritmos, el desacoplamiento correcto de los módulos. Tome abstracciones de bajo nivel más adelante: E / S, procesamiento por lotes, competitividad, uso de la biblioteca estándar, trabajo con memoria, asignación de memoria.
- El análisis Big O es muy importante, pero generalmente no es la herramienta más adecuada para acelerar un programa.
- Escribir puntos de referencia es un trabajo duro. Use perfiles y puntos de referencia para encontrar cuellos de botella y obtener una comprensión más amplia de lo que está sucediendo en el programa. Tenga en cuenta que los resultados de referencia no son los mismos que sus usuarios experimentarán en el trabajo de la vida real.
- Afortunadamente, un conjunto de herramientas ( Bench , pprof , trace , Race Detector , Cover ) hace que la investigación sobre el rendimiento del código sea asequible e interesante.
- Escribir buenas pruebas relevantes no es una tarea trivial. Pero son muy importantes para no ir a la naturaleza. Puede refactorizar, asegurándose de que el código siga siendo correcto.
- Detente y pregúntate qué tan rápido es "lo suficientemente rápido". No pierdas tu tiempo optimizando algunos guiones únicos. No olvide que la optimización no es gratuita: el tiempo, la complejidad, los errores y la deuda técnica del ingeniero.
- Piénselo dos veces antes de complicar el código.
- Los algoritmos con complejidad Ω (n²) y superiores suelen ser demasiado caros.
- Los algoritmos con complejidad O (n) u O (n log n) y a continuación generalmente están bien.
- Varios factores ocultos no pueden ser ignorados. Por ejemplo, todas las mejoras en el artículo se realizaron al reducir estos factores y no al cambiar la clase de complejidad del algoritmo.
- La E / S suele ser un cuello de botella: consultas de red, consultas de bases de datos, sistema de archivos.
- Las expresiones regulares son a menudo demasiado caras e innecesarias.
- Las asignaciones de memoria son más caras que los cálculos.
- Un objeto asignado en la pila es más barato que un objeto asignado en el montón.
- Los cortes son útiles como una alternativa a los costosos movimientos de memoria.
- Las cadenas son efectivas cuando son de solo lectura (incluida la reorganización). En todos los demás casos, [] byte son más efectivos.
- Es muy importante que los datos que procesa estén cerca (cachés del procesador).
- La competitividad y el paralelismo son muy útiles, pero difíciles de preparar.
- Cuando caves profundo y bajo, recuerda el "piso de vidrio" en el que no quieres entrar. Si sus manos están ansiosas por probar las instrucciones del ensamblador, las instrucciones SIMD, es posible que necesite usar Go solo para la creación de prototipos y luego cambiar a un idioma de nivel inferior para obtener el control total del hardware y cada nanosegundo.